利用跨模态信息检索的鲁棒隐蔽通信
2024-02-24张晏铭陈可江丁锦扬张卫明俞能海
张晏铭,陈可江,丁锦扬,张卫明,俞能海
中国科学技术大学网络空间安全学院,合肥 230000
0 引言
隐蔽通信(covert communication)是信息安全领域一个重要的研究方向,为了保护通信用户的隐私数据和防止窃听机密数据传输事件的发生,需要构建一个隐蔽性强、安全性高(李凤华 等,2022)的网络隐蔽信道(covert channel,CC)完成敏感数据的传输。
Tian 等人(2020)系统总结了现有的隐蔽通信方法和技术,将构建网络隐蔽信道的关键技术分为通信内容层(基于信息隐写)和传输网络层(基于代理和匿名通信技术)两个方面。虽然传输网络层的隐蔽信道技术较为成熟,但是其部署难度较高,因其依赖网络协议的特点,也更容易受到窃听者或审查者(下文统称攻击者)针对协议的攻击。这类通信技术的安全性依赖于协议本身加密的安全性,虽然通过加密保护了明文信息的机密性,但它们传输的数据很容易被识别为加密流量,从而引起攻击者的注意,因此损失隐蔽性。而对于通信内容层的隐蔽信道技术,一般在数据层面应用隐写技术嵌入需要传输的机密数据,具有较高的隐蔽性,但是传统的隐写算法受限于经验安全,易受到隐写分析的攻击(郎荣玲等,2004),因此安全性不足。
通信内容层的隐蔽通信方法,相比于传输网络层通常具有更高的隐蔽性,其中部分方法的数据隐写算法不依赖于特定的通信协议,又具有相对更大的可扩展性。此类方法目前国内研究较少,国外的工作主要选择常见的流数据应用作为部署的对象,如VoIP 网络语音通话服务,YouTube 流视频媒体平台,WebRTC(web real-time communications)网络音视频通话软件等。例如FreeWave(Houmansadr 等,2013)将客户的互联网流量调制成声音信号,通过VoIP 连接传输。SkypeLine(Kohls 等,2016)利用直接序列扩频(direct-sequence spread spectrum,DSSS)为基础的隐写技术在VoIP 语音流中隐藏信息。这两种方法未曾考虑网络波动异常状况对数据传输过程的影响,当网络延迟较大和出现较多网络数据包丢失等情况时,隐蔽信道则会失效。Saenger 等人(2020)利用许多客户端接口中可用的语音活动检测功能来产生假沉默数据包(silence packets),以该数据包作为隐藏数据的载体完成信息隐蔽传输。此方法考虑了网络波动问题对数据传输可能造成的错误,但当丢包率在5%时隐蔽信道依然会失效。Peng等人(2021)针对PCM(pulse code modulation)编解码器设计了一种主动语音周期检测算法,用于检测VoIP 数据包中是否携带活跃或不活跃的语音数据,并根据逻辑混沌映射生成的随机序列随机选择VoIP 流中的数据嵌入位置,在VoIP 数据流中隐写机密数据。该方案对网络波动异常不够鲁棒。
另外有使用流媒体平台进行隐蔽传输的方法,如CovertCast(McPherson 等,2016)将机密数据编码为图像序列并通过YouTube 等直播流媒体服务传输给用户。此方案安全性依靠于流媒体平台的HTTPS(hypertext transfer protocol secure)协议的安全性,但是缺乏隐蔽性,对消息接收用户不做限制,而且长时间的无意义视频是一种容易识别的异常行为。此外,还有基于网络音视频通话服务的方法,如Proto⁃zoa(Barradas 等,2020)通过钩取WebRTC 堆栈,用IP(internet protocol)数据包的有效载荷替换编码的视频帧数据来实现隐蔽信道。此方法与CovertCast 一样,安全性依赖于WebRTC 网络传输协议对数据的加密,但是当攻击者设法获取数据流加密的密钥,可以对加密的数据流进行解密时,则可以完整获得传输的机密数据。而对于通信端,被机密数据替换的视频帧本身是无意义的图像,存在易被识别的异常行为,因此该方法欠缺隐蔽性。Stegozoa(Figueira等,2022)在Protozoa 的基础上应用视频隐写技术将机密数据嵌入到WebRTC 视频信号中,防止通过直接视频内容检查检测到隐蔽的有效载荷。这个方法改进了Protozoa 的隐蔽性,引入视频隐写技术在有意义的视频中嵌入人类难以识别的机密数据而不改变视频质量,符合行为安全要求,使得攻击者更难检测隐蔽通信的过程,但是所使用的隐写方法仍然存在被隐写分析攻击的可能性。
Balboa(Rosen 等,2021)在TLS(transport layer security)层拦截传出的网络流量并将其重写为嵌入数据。为了避免引入与预期应用程序行为的任何可区分的差异,Balboa 只重写与通信各方之间预先共享的外部指定流量模型匹配的流量。流量模型捕获网络流量的某些子集(例如,音频流服务器流的音乐的某些子集),发送方使用此模型将传出的数据替换为指向模型中相关位置的指针,并在释放的空间中嵌入数据。然后,接收器提取数据,在将数据传递给应用程序之前,用模型中的原始数据替换指针。Balboa 提供了一种可以部署在任意受TLS 保护的协议或者应用程序上构建隐蔽信道的框架,具有很大的可扩展性,在音频流和网络流量中构建隐蔽信道时,应用层面上维持程序行为不变,确保了行为安全性。但是其安全性依赖于TLS 层的加密算法,对于有权限获得密钥的攻击者,这种通信将丧失安全性。
同时,在生成模型逐渐普及的时代,人工智能生成的信息变得更加常见,比如深度合成模型、AI(artificial intelligence)绘画、智能语音助手、智能聊天机器人等,多种模态数据包括视频、图像、音频、文本都可以由AI模型合成,并应用隐写术嵌入秘密消息(张卫明 等,2022)。AI 生成的数据量不断增长,并与正常人类生成的数据相互交错混合,想要区分数据的来源,技术要求高而且代价高昂。同时,随着生成模型的进步,可证明安全隐写(Hopper 等,2002)已经投入实际应用。Chen 等人(2022)基于音频生成模型Waveglow 设计了基于可逆采样的信息嵌入方法,实现可证明安全的音频隐写方法。Ding等人(2023)则提出基于分布式副本的可证明安全的隐写方法,可以应用到图像、音频、文本生成模型,分别实现可证明安全的图像、音频、文本隐写。
接着,根据人类语言语义的特点,在语音通信过程中丢失部分数据信息时,语音信号仍然可以保留大部分语义信息。因此,考虑借助成熟的语音合成和识别技术,利用这个规律构造基于文本到语音的模态转换的鲁棒隐蔽信道。但是实验表明现有语音识别方法无法完全准确识别语音中的语义信息,因此该方案鲁棒性不足。此外,如果只采用文本单模态数据作为载体进行隐蔽通信,会出现不能满足隐蔽信道实时性要求的问题,另外大量文本的端到端传输容易被攻击者识别,会损害通信行为的安全性。其次,如果采用音频模态数据作为载体构建隐蔽信道,实验表明其不具备抵抗网络传输过程信息丢失的鲁棒性。
因此,现有隐蔽通信方法无法同时满足强隐蔽性、高安全性和强鲁棒性的要求。针对上述方案存在的缺陷和利用现有的可证安全隐写及跨模态技术成果,本文提出一种利用跨模态信息检索技术的强鲁棒性隐蔽通信方法。假设机密数据发送方为Alice,接收方为Bob,Alice 与Bob 共享相同的生成模型及生成数据的设置参数,Alice 会将需要传输的机密数据通过可证安全隐写技术嵌入到生成的文本数据,并发布到公开可检索的网络数据库中。双方只能通过存在网络数据包丢失的VoIP 网络语音通话方式进行直接通信。Bob 根据保留下来的语义信息,到公共数据库中进行跨模态信息检索,可以找到对应的载密数据,接着用相同的生成模型恢复出隐写文本中的机密数据。实验结果表明,所提方案满足强隐蔽性、高安全性以及在网络异常状态下进行消息传递的强鲁棒性,且实时传输率为73~136 bps,缓冲扩展的传输率可以到达300 kbps以上。
本文的主要创新点包括:1)提出利用跨模态数据构建隐蔽信道的思想。具体而言,借助模态转化中语义基本不变的特点,将跨模态语义信息作为载体,进行隐蔽信息传递。基于上述思想,本文提出了一个名为RoCC 的全新隐蔽通信框架,通过模态转化来克服信道对数据的有损传输。2)以文本语音转化为例,将可证安全隐写方法引入到跨模态语义信息中,实现安全的信息传输。同时,还提出了利用语义相似度分析方法来解决音频语义提取精度不够的问题。本文所提隐蔽通信方法克服现有技术方案改变协议行为模式和依靠流量加密的缺陷,具有高隐蔽性、高安全性和语音协议间的通用性。3)最后,在实验上对所提方案进行跨模态信息恢复准确率、抗信息丢失鲁棒性、性能效率分析和横向对比实验,证明了本方案与现有方案对比中具有高隐蔽性、高安全性的优势,且性能效率上符合行为安全性,与正常用户行为难以区分,抗信息丢失的信息恢复准确率在1 k 大小的候选池中Recall@1 指标可达0.992 以上,Recall@2指标可达到1.0。实时传输率约有100 bps,在实际应用中可以实现小数据量的传输,而在缓冲扩展模式下可以达到300 kbps 以上,可以短时间内传输文件数据。
1 相关知识
1.1 隐写术
1.1.1 信息隐写
随着安全通信需求的不断增长,传统的加密通信方式已经愈发难以满足要求。而隐写术则是一种以数字图像、音频、视频或文本等载体为基础,将秘密信息巧妙地嵌入其中以实现秘密通信的技术。与传统的密码学相比,隐写术不仅能够保护秘密数据的安全,更能够隐藏秘密通信的存在,使其具备更高的通信隐蔽性。形式化表达为,一个隐写系统(stegosystem)ΣD具有通道分布D(偏差为Pc),这个系统可以用一个概率算法三元组表示ΣD=(KeyGenD,EncodeD,DecodeD)。
1)KeyGenD(1λ)接受长度为λ的输入,生成一个共享密钥K∈{0,1}k,长度为k,用于编码与解码过程。
2)EncodeD(K,m,H) 接受密钥K,秘密消息m∈{0,1}*,以及一个通道历史H作为输入,返回载密对象s=s1‖s2‖…‖sl,长度为l。
3)DecodeD(K,s,H) 接受密钥K,载密对象s∈{0,1}*,以及一个通道历史H作为输入,返回从s中提取的秘密消息m。
与密码学一样,隐写术需要满足Kerckhoffs原理(Kerckhoffs,1883),即攻击者知道除密钥以外的任何信息。
1.1.2 可证安全隐写
语言隐写术(linguistic steganography,LS)是最常用的隐写术之一。受益于生成模型,Kaptchuk 等人(2021)研究了使用生成模型作为隐写采样器,因为它们代表了最著名的近似人类交流的技术,以生成模型作为隐名采样器生成的文本,可证明与诚实模型生成的正常本文不可区分。Hopper 等人(2002)提出了隐写安全的复杂性理论定义,该定义通过区分oracle(OD)和EncodeD输出的概率博弈来建立。当其对所有概率多项式时间(probabilistic polynomial time,PPT)的敌手AD都满足以下条件,称隐写系统是对选择载密对象攻击(chosen hiddentext attacks,CHA)安全的
式中,OD是一个从数据分布D随机采样的oracle。
目前,先进的可证安全隐写技术是Ding 等人(2023)提出的基于分布式副本的Discop。以文本生成任务为例,文本生成利用计算语言学和人工智能知识自动生成近似人类编写的文本。自回归语言模型,如GPT 系列模型(Brown 等,2020)是这个领域最有代表性的生成模型,可以给定前一个上下文(con⁃text)x<t预测下一 个token 的概率分 布P(t)=Pr[xt|x<t]。
对于预测分布,采用随机采样策略。随机抽样生成文本的整个过程为:首先,使用伪随机数生成器(pseudo-random number generator,PRNG)生成一系列伪随机数r={r(0),r(1),…},满足在区间 [0,1) 上的均匀分布,即r(t)∼U[0,1)。对于每个时间步t,生成模型M预测P(t),然后每个在词汇表V中的token 根据P(t)分配一个在 [0,1) 中的左闭右开区间。然后,使用一个伪随机数r(t),并选择对应于r(t)所处区间的token 作为下一个标记xt,并将其附加到context 中。重复这个过程,直到达到终止条件(例如,生成的令牌序列的长度达到预设的最大长度)。
Discop 的原理是,在生成过程中,可以构建生成模型预测的概率分布的多个副本(即区间分配方案),称为“分布副本”(distribution copies),并使用“分布副本”的索引来表达信息。例如,假设只有两个标记,“a”和“b”,概率分别为0.4 和0.6。将[0,0.4)和[0.4,1.0)赋值给“a”和“b”,或者将[0.6,1)和[0,0.6)赋值给“a”和“b”。因为每个令牌在几个“分布副本”中的概率是相同的,这意味着这些“分布副本”的分布是相同的。通过这种方式,发送方可以创建多个“分布副本”,并根据消息决定从哪个副本中采样令牌。只要发送方和接收方处于相同的设置下,包括PRNG、种子、生成模型和上下文,就可以同步它们的所有状态,其中种子是用于初始化PRNG的数字(或向量),可以视为密钥的一部分。相应地,接收方可以通过确定从哪个“分布副本”中采样令牌来提取消息。因此,Discop 从原理上满足可证明安全的理论条件,详细证明过程可见Ding 等人(2023)的论文。
1.2 语音合成与识别
文本转语音(text-to-speech,TTS)的目的是合成给定文本的自然的、可理解的语音。基于神经网络的TTS采用(深度)神经网络作为语音合成的模型主干。一些端到端模型,如Tacotron(Wang 等,2017)和FastSpeech(Ren 等,2019)简化了文本分析模块,直接将字符/音素序列作为输入,并使用梅尔频谱(Mel spectrogram,MS)简化了声学特征,从而加快了语音合成的过程。在语音识别方面,一些语音识别应用已经非常成熟,如微软亚洲研究院发布的语言处理模型SpeechT5(Ao 等,2022)集成了语音合成与识别等功能。成熟的语音合成和识别技术为跨模态转换带来了很多便利。
1.3 文本语义相似度
文本语义相似度是自然语言处理(natural lan⁃guage process,NLP)领域的重要研究方向,并且拥有许多成熟的研究成果。基本的衡量文本差异的方法之一,即编辑距离(Levenshtein distance,LD)(Li 和Liu,2007),是文本a转换为文本b所需要的最少单字符编辑操作次数,形式化定义为
式中,a,b为两个字符串,ai为a的前i个字符,bj为b的前j个字符,leva,b(i,j)是ai与bj之间的编辑距离。
对于传统方法,如搜索引擎的基本技术之一,以词频—逆文本频率(term frequency-inverse document frequency,TF-IDF)(Salton 和Buckley,1988)作为词向量进行文本信息检索。两段文本之间的相似度,可以用词向量之间的距离衡量。
BERT 系列模型(Devlin 等,2019)实现了当前最好的文本相似度任务的效果,BERT 模型将文本嵌入到高维向量空间中,通过衡量文本的嵌入向量之间的距离,来判断文本语义之间的相似度。
2 威胁模型
多媒体隐蔽流(multimedia covert streaming,MCS)工具的一般系统模型如图1 所示。它代表两个用户,一个作为客户端(Alice),另一个作为代理(Bob)。客户端位于互联网开放区域,代理位于受国家级别对手控制的限制区域。攻击者能够观察、存储、干扰和分析其管辖范围内的所有网络数据,并阻止区域外用户对区域内网络服务的普遍访问。审查策略可以基于目的IP 地址或目的域名、通信中使用的协议(例如,BitTorrent 或Tor),或列入黑名单的内容(例如,通过关键字和图像过滤)。

图1 抗审查隐蔽通信的多媒体隐蔽流工具的系统模型Fig.1 System model of a multimedia covert streaming tool for censorship-resistant covert communication
MCS 工具旨在使客户端能够通过利用以下3 个条件,与代理端构建实时性的隐蔽信道:1)由受信任的限制区域内部用户(Bob)操作的代理服务器的合作;2)由加密流服务(例如Skype)组成的运营商应用程序,其流量由攻击方授权越过审查区域边界;3)攻击方允许的限制区域内用户可以访问的特定网站或平台,这类网站或平台不提供用户间隐私交流功能,所发布的信息为透明公开。
客户端和代理用户需要在各自的本地计算机上运行MCS 软件,通过运营商应用程序管理的媒体流来创建隐蔽信道。这个信道将允许客户端在受限网络区域中访问机密数据。在此,对威胁模型做出以下假设:
1)通信双方仅能通过语音通话方式进行直接沟通,例如常用的VoIP 服务。这是网络受审查地区内常见的被允许的通信方式之一。同时也可以通过文本形式进行通信,例如邮件和聊天室,但通信频率会受到限制(行为合理的要求),并且审查者有权随意审查所有通信内容。
2)通信双方可以访问多个(用户匿名的)公开网络数据库,例如公开的文字论坛、社交媒体平台等。这些数据库会受到审查者的监控,但由于经济因素和服务质量的考虑,审查者不会禁止正常数据的发布,即只禁止敏感或有害的数据发布。通信双方可以使用相似的文本进行搜索,以查找对方发布的文本数据。然而,在这些网络数据库下,无法安全地进行点对点的信息传输,因为所有的通信行为在平台上都是透明可见的,直接的通信将会失去隐蔽性。
3)通信双方事先共享相同的生成模型和隐写参数设置,但彼此不知道对方在隐写时所使用的con⁃text。审查者没有相同的模型,因此该模型和参数设置为隐蔽通信的密钥。通信双方需要在不暴露该模型和参数的情况下完成隐蔽通信过程。
4)语音通信过程中,允许网络存在波动等常见的异常状态,即存在数据包丢失,语音信息会因丢包率的不同存在相应程度的丢失。这是现实条件下经常会发生的事情,因为网络语音服务通常是基于UDP(user datagram protocol)协议进行数据传输,一方面是为了降低通话延迟,另一方面是为了减轻SIP(session initiation protocol)服务器的通信负担,因此语音通话过程中很可能存在信息丢失的问题。
3 系统框架
本节详细描述系统设计的框架结构、工作流程,以及每个模块的具体作用与要求。
3.1 总体框图
本文的系统框架如图2 所示,整体设计由两个通信用户Alice 和Bob、一条直接通信的VoIP 数据流通道以及一条借由公开网络数据库(open network database,OND)连接的间接信道组成。

图2 RoCC的系统框图Fig.2 Framework of RoCC system
每个通信方计算机段会安装RoCC 应用程序,包括4 个组件:RoCC 客户端(client)/RoCC 代理端口(socket),负责与用户数据交互;可证明安全隐写组件(provably secure steganography,PSS),这里采用Discop 技术实现,包含编码器(encoder)和解码器(decoder),负责生成载密文本与提取机密数据;音频处理组件(audio processor,AP),其中包含语音合成模型和语音识别模型(speech recogni⁃tion,SR),分别负责实时合成音频流数据并通过VoIP 通道发送,以及将接收到的音频流数据转换为文本m';搜索引擎组件(search engine,SE),包含相似度分析模块(similarity analyzer,SA)用以分析识别的文本m'与搜索引擎获取的文本池(text pool,TP)两两之间的语义相似度,找出原文本从而还原文本语义信息,以及内容发布模块(pub⁃lisher,Pu)负责将载密文本通过正常用户行为发布到OND 中。
通信双方由VoIP 通话方式取得直接联系,该通道在部分时间存在数据包丢失,并受攻击者的审查,攻击者可以解密VoIP 数据流,对其内容进行窃听,且可以对数据流进行隐写分析,试图找出其中隐藏的机密数据。此外,Alice 和Bob 还可以借由受审查的公开网络数据库进行数据传输,但由于平台的局限性,无法隐蔽地完成点对点数据传输,因此该通信过程只能采取间接通信形式。即Alice(Bob)在OND上以匿名形式发布公开的数据内容,让网络内容用户可见,接着,Bob(Alice)设法找出对应的数据并从网络上拉取至本地。整个间接通信过程保持双方匿名,因此具有很高的隐蔽性。
3.2 工作流程
3.2.1 总体流程
系统的整体流程分为两条通信方式进行描述,称语音传输的VoIP 数据流通道为信道A,称借由OND 进行间接数据传输的通道为信道B。整个RoCC 的隐蔽信道则是由A 结合B 构成,两条信道同时传输消息,延迟在可控范围内。下面以Alice 向Bob 发送秘密消息为例,Bob 向Alice 发送机密数据的流程则与之类似。
信道A:Alice 经由RoCC client 输入需要传输的秘密消息(secret message)记为m,经由PSS的编码器生成的载密文本(stegotext)记为c。接着,c输入到AP,生成音频流(audio stream)记为st。st经由VoIP数据流通道传输至Bob 的计算机,由其内的AP 识别转换为文本c′,由于语音识别的误差和网络传输过程可能丢失信息,c和c′的语义存在差异。最后c′输入到SE 的SA,还原出文本c。载密文本c经过PSS的解码器解码提取m。此时,Bob 通过client 接收到秘密消息m,或者经由代理端口RoCC Socket,自动化访问机密计算机(secret computer,SC)获取目标机密数据。
信道B:Alice 输入的秘密消息m,经过PSS 的编码器生成载密文本c后,转入SE 的Pu,自动向OND发布完整的载密文本c,并记发布完成时间为tb,即从Pu 传输数据开始至OND 发回确认反馈的时间。此时Alice 端在信道B 的操作结束。Bob 端,当从信道A 接收到c′之后,设音频流信号有效时间为ta,则Bob 端的SE 会获取tw=max(ta,tb)时间窗口内新发布的数据内容到本地,然后通过SA分析还原出真正的c,最后输入PSS 的解码器提取秘密消息m,将其送入RoCC Socket完成全部通信流程。
时间ta通常会比tb更长,所以Bob 端只需要取tw=ta,不需要得知tb的具体数值,如果出现OND 网络异常,那么Alice 端尝试重传即可,这里假设通信所需要的网络服务是可用状态。引入参数tw可以对系统性能提供有效的优化,可以解决实际ODB 文件池过大,增加文本语义分析时间,导致传输效率不足的问题。
对于信道A 和信道B 的通信过程,可以形式化表述为
信道A:
1)c←Encoderdis(m);
2)st←APTTS(c);
4)c′←APASR(as);
7)m←Decoderdis(c)。
信道B:
3)ODBTP←SEPu(c);
5)TP←SE(ODB,tw);
6)c←SESA(c,TP)。
其中,Encoderdis和Decoderdis分别为可证明安全隐写Discop 模块的编码及解码函数;APTTS和APASR分别为音频处理模块的语音合成及识别函数;SEPu是搜索引擎的发布模块,负责将生成的载密文本c发布到ODB,SE(ODB,tw)将ODB 上tw时间窗口内的文本集TP下载到本地,SESA通过相似度分析从TP中还原有损载密文本c′的原文本c。
另外,为了加速大文件数据传输的过程,在原通信方式上进行扩展,称为缓冲扩展模式。此模式下,在通信双方构建直接通信之前,可以将需要传输的大文件先用隐写组件进行编码,获得文本集合MS,在构建直接通信之后可以直接以音频流传输MS的前缀语义信息,即不需要完整传输所有文本,只需要传输其中前q(< 5)个句子的文本。同时将MS上传至OND。如此可以节省隐写组件对大量数据进行编码的时间,通信的时间消耗主要为语音通话,传输率即可得到很大的提高。
3.2.2 可证安全隐写
可证安全隐写组件由编码器和解码器组成,这里采用Discop 作为实现的技术,当然可以选择其他隐写技术,但若不是可证明安全隐写,则安全性会有损失,易遭受隐写分析攻击。更详细地,Discop 的安全性依赖于通信双方共享的生成模型M,随机数生成器PRNG,以及初始化设置seed的保密性,整个隐写的密钥可以记为一个三元组(M,PRNG,seed),当密钥不被攻击者获得,则整个通信过程理论上是安全的。值得指出的是,本系统的安全性与Protozoa 等方法有所不同,本方案的通信不依赖流量加密所带来的安全性,因为国家级攻击者有权限解密任何网络供应商提供的数据流服务的加密流。
3.2.3 语音通话
Alice 和Bob 之间使用VoIP 网络通话直接通信,比如Skype服务。音频处理模块包含TTS和SR两个模块,从隐写模块输出载密文本c到TTS 模型,实时合成为音频流st,并通过VoIP数据流通道发送,接着被对方的语音识别模块接收,因网络数据包丢失和语音识别模型导致语义有损,识别得到的载密文本信息为c′。
因为隐蔽信道既要求安全性,又要求隐蔽性,所以在通信过程中的行为必须符合正常行为模式,又称为满足行为安全性。需要达到的要求包括如下:1)隐蔽信道的通话内容需要接近正常人类交流的内容,且不包含敏感内容和可疑信息;2)隐蔽信道的通话行为反应时间要与正常用户的通话行为反应时间不可区分,即能够抵抗时间延迟模式的分析攻击;3)VoIP数据流能够抵抗攻击者的隐写分析攻击。
为了满足要求1),采用能够生成接近人类正常文本的GPT系列模型作为可证安全隐写的生成模型M,通过精心构造context,可以使得文本内容符合正常对话逻辑。为了满足要求2),实际部署系统时,选择采用高性能的SpeechT5 模型作为TTS 模块和SR 模块的实现,经过实验检验,该模型可以实现平均0.336 s 生成1 个token,且每个token 的语音识别延迟在0.166 s以内,足够接近人类正常通话行为模式,实验结果详见4.4.1 节。对于要求3),Alice 与Bob 之间传递的语音内容st是从隐写模块生成的载密文本c合成语音得到的,因此VoIP 数据流内本身并没有嵌入秘密消息,故满足该要求。
3.2.4 相似度分析
由语音识别模块输出的语义有损文本c′,输入到相似度分析模块SA,并与从网络公开数据库OND中搜索获取的文本池TP进行相似度比对。这里的实现采用结合式相似性度量,计算式为
式中,α为动态参数,用以设置两种度量公式的权重比例,len(t1)和len(t2)分别表示文本t1和t2的长度,levt1,t2(len(t1),len(t2))为编辑距离,参考式(2),Memb(t1)和Memb(t2)分别表示文本t1和t2经过BERT 系列模型计算的嵌入向量。采用的度量公式,即向量之间的余弦相似度,计算式为
式中,x,y是等维向量,|x|,|y|为向量的模。
3.2.5 信息检索
信息检索过程由搜索引擎SE 模块完成,文本池TP由SE 从OND 获取,设大小为Tsize,经过文本语义相似度分析,排序分析结果,以K个相似度分数最高的匹配结果作为返回。算法1 文本搜索具体计算过程如下:
输入:文本池TP,识别文本m',参数K;
输出:隐写本文候选表CL(size=K)。
1)优先队列q={};
2)embm’=EmbeddingModel(m');
3)embTP=EmbeddingModel(TP);
4)foremb,mcinembTP:
5)q.put(fSimilarity(embm',emb,m',mc),mc);
6)ifq.size >K:
7)q.get();
8)CL={};
9)foremb,mcinq:
10)CL.put(mc);
11)returnCL。
算法1 输入候选文本池TP,识别文本m′,参数K,输出K个候选文本列表。算法过程,维护优先队列q,维持大小在K以内,对文本m′和每个候选池的文本mc计算其嵌入向量emb,遍历所有候选文本通过Similarity 函数计算相似度得分,进入以相似度得分排序的优先队列q,超过K大小时,取出得分低的元素,最后将相似度得分最高的K个文本并入CL,作为结果返回。
4 实验结果
4.1 跨模态检索
本节是跨模态方法的准确率实验结果,所用指标 为SER(sentence error rate)和CER(characters error rate),SER 即识别出错的句子数除以句子总数,CER 的值为(S+D+I)/N,其中,S是字符替换的个数,D是字符删除的个数,I是字符插入的个数,C是正确的字符数,N是引用中的字符数(N=S+D +C)。文本相似度检测的准确率所用指标为Recall@K=TP@k/(TP@k+FN@k),其中,TP@k是前k个返回结果中正确分类的正样本数,FN@k是前k个返回结果中错误分类的正样本数。
4.1.1 语音识别准确率
总共测试了14 种开源模型的语音识别准确率,取5 种模型作为代表性结果。测试所用中文数据集为THCHS-30(T-30),英文数据集为Librispeech Asr Datasets(LA)和Discop 生成的载密文本合成语音Stegotext Dataset(SD)。
结果如表1 所示。其中,Uniasr 具体指模型uni⁃asr_8k_common_vocab8358,8 k 为参数,词汇表大小为8 358,是中英语言通用模型。Para_large 即Para⁃former_large 模型,相比于Paraformer 模型采用了更深更大的模型结构,在多个中文公开数据集上取得SOTA(state-of-the-art)效果。Transformer 模型,即Transformer-LM,是基于Transformer(Vaswani 等,2017)的decoder 架构构建。具有代表性的预训练模型,依然存在很高的词错率,而句错率最低的只有0.612 5,因此如果采用直接跨模态方法构建隐蔽信道,必然存在文本语义丢失的问题。因语义丢失而导致秘密消息提取失败。

表1 语音识别准确率Table 1 Recognition accuracy of the speech recognition models
4.1.2 文本相似度分析
相似度任务的实验设置,文本池的大小Tsize=1 000,测试了3 种开源文本嵌入模型的Recall 指标,这里设置一个阈值参数threshold,表示排除文本tokens 数目差距超过该阈值的候选对象,是一种启发式的剪枝策略,实验设置threshold=5。
实验结果如表2 所示,其中bert-mt 表示bertbase-nli-mean-tokens 模型,bert-cl表示bert-base-nlicls-token模型,mulLM表示paraphrase-multilingual-MiniLM-L12-v2 模型,3个模型均 由Reimers 和Gur⁃evych(2019)提出,α参数是调节相似度函数的权重,详见算法1。

表2 文本相似度分析准确率Table 2 Text similarity analysis accuracy
可以看出,mulLM 模型可以在Recall@1 上达到0.992 7,Recall@2 上达到1.0,即用语音缺失文本c'在SA 的前2 个返回结果中可以找到原文本c,因此文本语义的恢复率可以达到100%。
4.2 鲁棒性实验
本节中,对比本文方案与StegoTTS 方法(Chen等,2022),Saenger 等人(2020)方法,以及朴素的基于直接跨模态数据转换构建隐蔽信道(direct crossmodel,DCM)的方法,对网络异常状态消息传输的鲁棒性。其中,DCM 是基于文本语音跨模态的隐蔽通信方案,其思想是发送方在文本中嵌入秘密消息,通过语音合成获得对应的音频数据,在语音通话信道上传输,接收方应用语音识别将音频数据还原回文本数据,再对文本数据提取秘密消息。如表3 所示,DCM 因为语音识别效果的不完美,导致语义的丢失成为无法避免的问题,因此缺失鲁棒性。对于StegoTTS 方案,因为音频隐写基于自回归模型,当消息序列出现丢失,则提取秘密消息就会失败,对于Saenger 的方案,因为在通话静默期进行隐蔽传输,所以丢包率较低时,并不会破坏隐蔽信道功能。可以看到,RoCCk=2方案对抗丢包现象,具有很强的鲁棒性,在k=2 时,比Saenger 的方案高出至少5%的丢包率抵抗能力。而且当丢包率超过10%时,依然可以通过取更大的k值,增加消息恢复率。
4.3 实时性实验
本节主要验证整个系统的性能效率能否满足隐蔽信道对实时性的要求。从3 个组件的效率进行实验,包括语音合成与识别、可证安全隐写和文本相似度分析。
4.3.1 语音合成与识别效率
对于语音合成,测试1 000 个句子的合成时间,总tokens数目为17 144,平均单位时间合成tokens数为2.97。对于语音识别,测试1 000 个句子的识别时间,总tokens 数为16 799,平均单位时间识别tokens 数为6.06。所以音频处理组件的性能满足语音流实时通信的要求。
4.3.2 可证安全隐写效率
如表4 所示,Tokens 指生成文本的tokens 个数。Bits 指嵌入文本的秘密消息的比特数。可证安全隐写的编解码效率随着生成文本的tokens 长度不同而有所差别,平均单位时间生成tokens数为47。
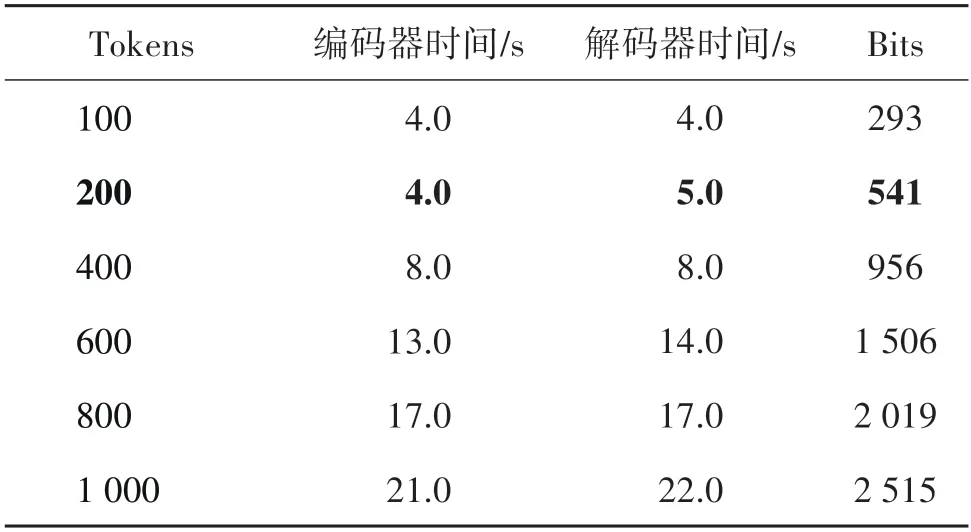
表4 可证安全隐写效率Table 4 Provably secure steganography efficiency
4.3.3 文本相似度分析效率
在改变文本池大小Tsize∈{100,200,400,800},在K值取1和5时,进行相似度分析效率测量,如表5所示,检测单文本对象的相似度平均时间在0.02 s以内,表明信息检索时间非常短,对通信整体过程的性能的影响可以忽略不计。
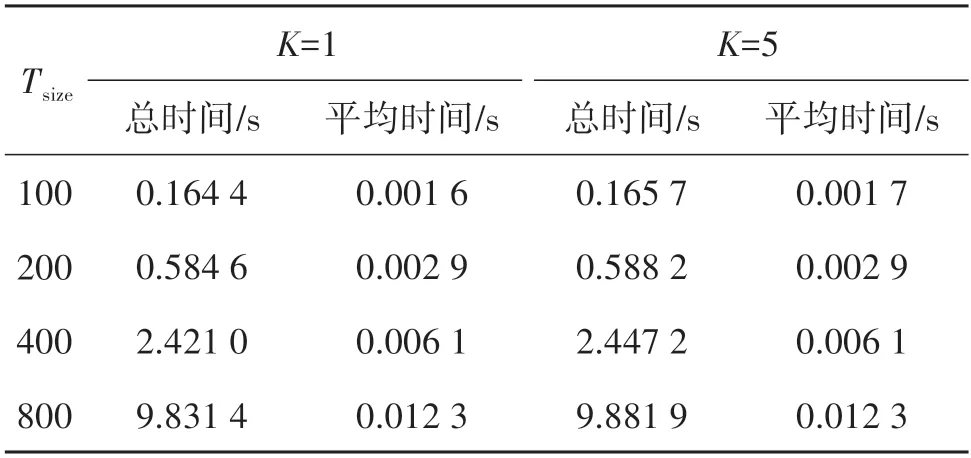
表5 文本相似度分析效率Table 5 Text similarity analysis efficiency
4.4 对比讨论
本节将RoCC 系统与现有的具有代表性的多媒体数据流构建隐蔽信道的方法进行多个角度的对比分析,如表6所示。其中,“标准协议”是指那些不改变协议行为的方法。“未修改二进制”表示那些在底层运行时,未修改目标协议实现的二进制程序。“不需要加密”表示那些方法不依赖于加密。“应用隐写”是指利用隐写方法的方法。“通用性”是指那些为支持各种应用程序/协议提供框架的方法,可以扩展其他协议。“可证明安全”是指那些达到最优计算安全性的方法。“传输率”表示方法的传输速率。需要特别说明的是,CovertCast 的方案通过网站视频流传输数据,主要与网络速度相关,所以表6 内不标明传输率。可以看到,在维持协议行为不变,不修改底层二进制程序这两个条件同时满足时,只有Saenger的方法、Peng 的方法、Balboa 和RoCC。这两个条件决定了通信的隐蔽性,其他方案或者改变协议行为,或者修改底层二进制代码,使得隐蔽通信过程出现异常行为模式,易被攻击者识别。在不依靠加密这个条件上,只有SkypeLine、Peng 的方法和RoCC 满足,这意味着当攻击者可以解密数据流审查其内容时,依靠加密流的隐蔽信道则会暴露,失去安全性。Sky⁃peLine、Saenger 的方法、Peng 的方法、Stegozoa 和RoCC都应用了隐写术,可以在加密无效时提供更进一步的数据保护。在通用性上,只有Balboa和RoCC达到这个条件,即这两个方案的设计均非针对特定协议,Balboa 可以适用于所有受TLS 保护的通信协议,RoCC可以适用于所有语音通信协议。在可证明安全条件上,只有RoCC 满足,因为RoCC 是第1个将可证安全隐写技术应用到构建隐蔽信道上,同时确保了隐蔽性和安全性。在传输率上,RoCC的实时传输率为70~140 bps,满足少量秘密消息的传输需求,而在缓冲扩展模式下传输率达到300 kbps以上,可以用来传输少量文件数据等。

表6 多媒体数据流隐蔽信道方案对比Table 6 Comparison of covert channel schemes for multimedia data streams
5 结论
本文研究了现有多媒体数据流隐蔽通信方法的不足,并提出了一种名为RoCC 的隐蔽通信方法,具备高隐蔽性、高安全性和强鲁棒性。RoCC 是第1 个以跨模态方法构建隐蔽信道的工作,直接跨模态方案的缺点在于语音识别无法完全还原文本语义。为解决通信过程和跨模态模型的缺陷导致的文本语义丢失问题,通过文本语义的相似度分析,实现了在常见网络异常状态下的鲁棒通信。相较于现有的具有鲁棒性的Saenger 方法,RoCC 的丢包率抵抗能力提高了5%以上。此外,本文是第1个将可证安全隐写技术引入构建隐蔽信道的工作。面对国家级攻击者时,RoCC能够在无需流量加密的情况下保持高隐蔽性和高安全性。在长时间实时通信中,RoCC的传输率可达到约100 bps,适合用于少量秘密消息的传输。通过缓冲扩展模式,传输率可达到300 kbps 以上,适用于少量文件数据的传输。未来的研究方向可以将跨模态技术扩展至图像、视频等数据模态。例如,引入文本图像检索技术,实现以载密图像为数据传输媒介、以文本作为数据索引的隐蔽信道。
