人脸深度伪造主动防御技术综述
2024-02-24瞿左珉殷琪林盛紫琦吴俊彦张博林余尚戎卢伟
瞿左珉,殷琪林,盛紫琦,吴俊彦,张博林,余尚戎,卢伟
1.中山大学计算机学院,广州 510006;
2.广东省信息安全技术重点实验室,广州 510006;
3.教育部机器智能与先进计算重点实验室,广州 510006
0 引言
人脸深度伪造(Deepfake,deep learning 和fake的合称,下文简称深度伪造),指的是一种基于深度学习的人脸操纵技术,它可以对图像、视频中的人脸进行有目的的操纵,包括人脸面部替换、人脸属性编辑等。随着生成对抗网络(generative adversarial net⁃work,GAN)(Mirza 和Osindero,2014)技术的飞速发展,深度伪造的性能得到了极大的提升,伪造出的人脸也越来越逼真。一方面,这种技术广泛应用于娱乐软件,例如美图秀秀、FaceApp 等,这大大地丰富了人们的娱乐生活(Gaur,2022);另一方面,深度伪造也应用于一些可能造成不良影响的场景:例如一些色情软件(如DeepNude)将明星的脸替换到色情演员上(Yeh 等,2020),或者将政治人物换脸到其他人物的演讲等行为场景中(Li 等,2023;Ahmed 等,2022)。这些对深度伪造技术的滥用不仅给公民特别是公众人物的名誉权、肖像权造成了十分严重的危害,同时也加速了虚假新闻和伪造图像、视频的扩散(Mirsky 和Lee,2021;Wang 等,2022),给国家安全和社会稳定带来了潜在的威胁(周文柏 等,2021)。因此,为了减轻深度伪造带来的隐患,越来越多的研究人员展开了对深度伪造防御方法的研究,并取得了一定的成果。
深度伪造技术主要包括面部替换、属性编辑、人脸生成等类型(He 等,2022b;曹申豪 等,2022)。其中面部替换的任务是使用原始人脸的面部替换目标人脸的面部区域,这种技术涉及到目标身份属性的篡改,当前较为主流的面部替换模型有FSGAN(face swapping GAN)(Nirkin 等,2019)、Faceshifter(Li 等,2020a)和SimSwap(simple swap)(Chen 等,2020)等。属性编辑任务可进一步分为面部表情编辑(又称为面部重现)和面部属性编辑(He 等,2022b),这种伪造方式不涉及个人身份信息的改变,而是尝试修改人脸的特定属性,如表情、发色、年龄、性别等。现有的较为主流的面部表情编辑模型有NeuralTextures(Thies 等,2019)、GANImation(anatomically-aware facial animation)(Pumarola 等,2018)和Icface(inter⁃pretable and controllable face)(Tripathy 等,2020)等,面部属性编辑模型有StarGAN(star GAN)(Choi 等,2018)和AttGAN(attribute editing GAN)(He 等,2019)等。人脸生成技术与上述两种技术不同,其主要使用生成对抗网络来生成完全不存在的人脸图像,目前主流的人脸生成模型包括ProGAN(progres⁃sively growing of GAN)(Karras 等,2018)和StyleGAN(style-based generator architecture for GAN)(Karras等,2019)等。图1 展示了上述几种典型深度伪造技术的视觉效果。

图1 不同深度伪造技术的示例Fig.1 Samples of different deepfake technologies((a)face swapping;(b)face expression editing;(c)face attribute editing)
考虑到深度伪造技术造成的不良影响,目前学术界已经提出了一些防御策略来对抗深度伪造。这些防御技术主要可以分为两大类:检测(被动防御)和主动防御(Huang 等,2022;Sun 等,2022a)。其中检测技术的主要目标是判断一个视频或图像是否属于深度伪造样本(杨少聪 等,2022;李颖 等,2023),尽管一些基于检测的方法在事后取证中取得了相当高的准确性(Zhang,2022;Nguyen 等,2022),但它们无法做到“事前防御”(Hu 等,2020),所以仍然无法消除恶意人脸伪造在广泛传播中造成的影响(Huang 等,2021),同时也有研究指出这类检测方法可以很轻易地被伪造者所规避(Gandhi 和Jain,2020;Hussain 等,2022)。因此,研究人员提出了人脸深度伪造主动防御技术,这类技术的核心思想是在图像或视频发布到互联网上之前向其中注入特定的对抗扰动或水印,当恶意用户尝试使用这些图像或视频进行深度伪造时,注入的保护信息一方面将对伪造模型输出的伪造结果造成视觉性破坏,另一方面能使相关人员通过伪造图像开展溯源工作,并对图像进行真伪认证。目前主流的思想认为主动防御的方法比检测的方法具有更强的“事前”防御能力(Chen 等,2021;Wang 等,2022)。与周文柏等人(2021)、王任颖等人(2022)以及曹申豪等人(2022)近期发表的综述不同,本文主要侧重于对当前提出的深度伪造主动防御技术进行整理、归纳和总结,并对深度伪造主动防御面临的挑战和未来的发展前景提出思考。
本文的主要工作包括以下3 点:1)对现有人脸深度伪造主动防御方式进行系统性归纳总结,包括不同防御算法的分类、破坏目标、优缺点和鲁棒性性能等;2)对现有深度伪造主动防御技术论文中使用的评估指标和常用数据集进行介绍;3)对人脸深度伪造主动防御面临的技术难题与应用挑战进行阐述,以此为更强大的主动防御方法提供参考,并对其未来的发展前景和方向进行讨论。
1 人脸深度伪造技术简介
传统的人脸伪造和篡改主要通过人脸变换(face morphing)和计算机图形学(computer graphics,CG)技术来实现,但这些技术的使用往往需要大量的软硬件设备作为支撑,同时需要专业人员进行较为复杂的后期渲染工作,这不仅对技术条件有着较高要求,而且成本也十分高昂(周文柏 等,2021;Gaur,2022)。随着深度学习技术的不断进步,自编码器(autoencoder,AE)(Kingma 和Welling,2022)和生成对抗网络(Mirza 和Osindero,2014)的提出使得人脸深度伪造技术在人脸伪造领域得到了飞速的发展和广泛的应用。
生成对抗网络GAN 包含一个生成器和一个鉴别器,通过两者的博弈训练可以使网络学习到人脸样本的数据分布,并生成训练数据集以外的全新人脸图像。精心设计过的GAN 模型可以生成具有良好视觉质量的人脸图像,同时不依赖具体的先验知识(王任颖 等,2022),因此广泛地运用于人脸深度伪造之中,这也使得人脸伪造的成本和门槛大大降低。
2 深度伪造主动防御技术
2.1 技术简介和分类
人脸深度伪造主动防御的概念由Li 等人(2019)提出,通过向人脸素材中注入对抗扰动来破坏深度伪造中人脸检测器对人脸数据的提取,从而降低提取到的用于训练深度伪造模型的人脸数据集的质量,以此来阻止恶意用户生成伪造人脸。Ruiz等人(2020)首次系统性地将对抗攻击引入到深度伪造的防御之中,他们尝试在原始的人脸图像中加入一些难以被察觉的对抗扰动,来直接破坏深度伪造模型的性能,进而导致深度伪造模型的输出存在明显的失真,这种主动防御的思想也为之后的工作奠定了基础。
随着越来越多防御方法的提出,如图2 所示,深度伪造主动防御技术可以概括为:在用户将含有人脸的图像或视频发布至互联网公共平台之前,便在其中添加一定程度的扰动或水印信息,从而破坏恶意用户使用这些人脸素材进行深度伪造的伪造结果,使得人类观察者可以轻易地发现这些伪造人脸的异常,降低其可信度;或者即使恶意用户能够实现难辨真假的伪造,在伪造图像或视频发布后也能对其顺利进行溯源或真伪认证,以此来实现“事前防御”的目标。因此从防御目标的角度来说,深度伪造主动防御可以分为基于主动干扰的防御技术和基于主动取证的防御技术。其中基于主动干扰的防御技术通过注入的扰动破坏深度伪造模型的伪造性能,从技术手段的角度又可以分为基于数据中毒的防御方法、基于对抗攻击的防御方法和基于隐空间的防御方法。基于主动取证的防御技术不要求破坏深度伪造模型的性能,而是通过添加的水印信息实现对成功伪造图像的溯源或认证(Lin等,2022)。对于深度伪造主动防御技术的分类具体如图3所示。
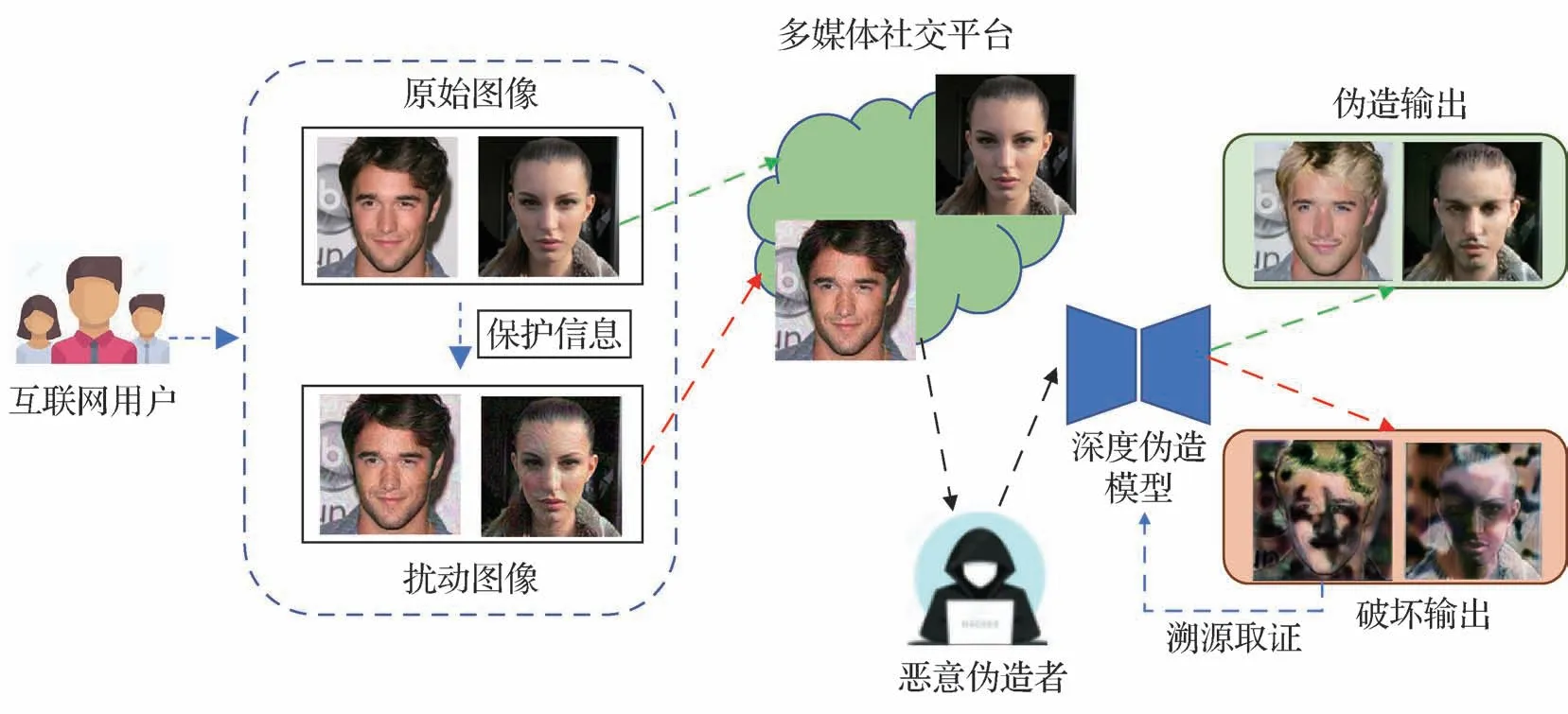
图2 深度伪造主动防御示意图(Wang等,2022)Fig.2 Illustration of deepfake proactive defense(Wang et al.,2022)
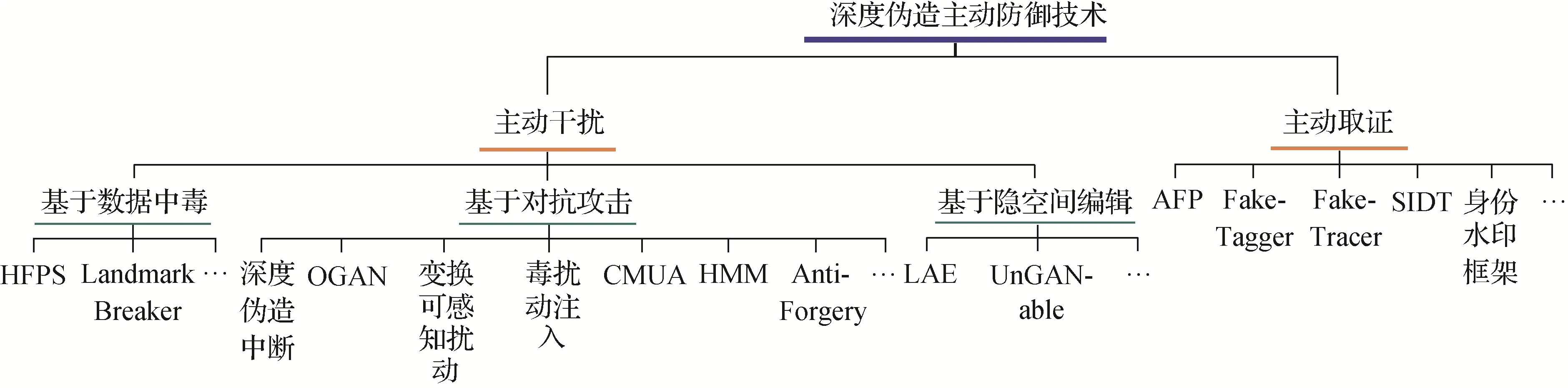
图3 深度伪造主动防御技术的分类导图Fig.3 Classification of deepfake proactive defense methods
基于主动干扰的防御技术更为常见,其目标是使得伪造模型的输出在视觉上与真实的伪造输出存在较大差异,从而让伪造者无法获得理想的伪造结果。这种技术方案对于具有特殊需求的互联网用户具有较高的使用价值和较低的防御成本(周文柏等,2021;Lin 等,2022)。例如,部分媒体或公众人物希望所发布的带有人脸的图像或视频素材不被恶意使用,则可以通过主动干扰技术对素材进行保护后再发布,这样在预防深度伪造的同时不需要进行后续的溯源、认证工作。
在3 种基于主动干扰的防御技术中,数据中毒的防御方法对深度伪造的防御发生在伪造模型的训练阶段,其需要伪造者使用中毒图像作为训练数据来训练深度伪造模型(陈晋音 等,2020)。而对抗攻击的防御方法对伪造的破坏则发生在测试(推理)阶段,当伪造者使用训练有素的深度伪造模型对添加了扰动的人脸素材进行伪造时,输出结果将被破坏。在现有的研究中,这种基于对抗攻击的思想使用最为广泛。基于隐空间的防御方法不是直接在原始人脸图像上添加扰动,而是首先将需要保护的人脸样本映射到隐空间,然后通过在隐空间里对图像映射进行特定的编辑和变换,从而让伪造者无法得到理想的、可用于伪造的人脸隐空间映射,进而使人脸图像免受深度伪造的威胁。基于隐空间的防御方法首先需要将待保护人脸图像映射到GAN 的隐空间中,因此其十分依赖GAN反演(GAN inversion)技术(Xia等,2023)的效果(He等,2022b)。
2.2 基于主动干扰的防御技术
从本质上来说,主动干扰防御技术的思想是利用对抗扰动来破坏以GAN 为代表的生成网络(Ruiz等,2020)。对抗样本(adversarial examples)由Good⁃fellow等人(2015)提出,即尝试在图像中添加微小的对抗性扰动,这些加入了扰动的图像在肉眼观察时和原始图像并没有明显的区别,但却能影响分类器对图像的分类结果。Tabacof 等人(2016)首次将对抗样本引入到图像生成领域,尝试对自编码器(Kingma 和Welling,2022)进行对抗攻击,发现当注入对抗扰动的图像被输入到自编码器中时,其输出与目标图像完全不同的结果。Kos 等人(2018)深入研究了在深度生成模型上生成对抗性样本的方法,他们将对抗样本压缩到隐空间中,然后将其重建为与原始图像具有不同语义类别的图像。Bashkirova等人(2019)研究了循环一致性图像翻译网络中的对抗攻击问题。Wang 等人(2020)将对抗攻击运用到pix2pixHD(Wang 等,2018)和CycleGAN(cycleconsistent GAN)(Zhu 等,2017)网络上的图像翻译任务中,取得了一定的成果。然而,当前的深度伪造模型主要依赖于有条件的图像生成网络,在此基础上,Ruiz等人(2020)首次提出基于图像对抗攻击的深度伪造主动防御方案,即通过在图像中加入对抗扰动的手段来破坏深度伪造。
深度伪造主动防御的根本目的是使用户发布到互联网上的包含人脸的图像、视频等免受深度伪造模型的恶意伪造,但用户最初的目的仍然是希望自己所发布的图像或视频起到多媒体传播的效果(Sun等,2022b),这也要求主动防御算法不能使采取了保护措施的人脸和用户希望分享的原始人脸之间存在过大的视觉偏差,如存在噪声或失真等。综上所述,Huang 等人(2021)对深度伪造主动防御的目标进行了系统性的总结,主要包括两个目标:1)添加了保护信息的人脸数据在视觉上应尽可能与干净人脸保持一致;2)采取了保护措施的人脸可以大大降低目标深度伪造模型的性能,使其伪造失败。
对于目标1),当前主流方法采用的策略是限制对抗扰动的扰动阈值,从而尽可能地使被保护图像与原始图像保持视觉上的一致性。对于目标2),虽然当前不同防御方法所采取的方式不尽相同,但从总体上来说使得深度伪造“失败”的攻击目标可以分为两类(Yeh 等,2020):扭曲攻击(distorting attack)和无效攻击(nullifying attack)。其中,扭曲攻击的目标是干扰深度伪造模型的输出,使得伪造人脸图像上存在明显的视觉上的失真或扭曲,从而可以被容易察觉,具体为
式中,x为输入的人脸图像,η为向图像上加入的扰动信息,ϵ为扰动阈值,G为深度伪造模型,Ldist表示扭曲攻击的距离函数。可知扭曲攻击尝试在原始图像中加入精心设计的扰动,以最大化深度伪造模型对原始图像的输出和对扰动图像的输出之间的距离,同时将扰动信息的无穷范数限制在扰动阈值内,以确保扰动图像的视觉质量。而无效攻击的目标是使得深度伪造模型的输出图像和原始的输入图像在视觉上尽可能保持一致,即让人脸操纵无法达到理想的伪造效果,具体为
式中,LNull表示无效攻击的距离函数,无效攻击尝试最小化深度伪造模型对扰动图像的伪造输出和原始图像之间的距离。两种攻击目标的防御效果如图4所示。

图4 深度伪造主动防御不同防御目标的效果图Fig.4 Visual examples of different defense targets of deepfake proactive defense((a)original face;(b)fake face(age);(c)result of distorting attack;(d)result of nullifying attack)
2.2.1 基于数据中毒的防御方法
Li 等人(2019)提出了面部隐藏(hiding faces in plain sight,HFPS)算法,尝试向待保护的人脸图像中加入对抗扰动,当恶意伪造者利用这些人脸素材来训练他们的深度伪造模型时,这些中毒的人脸素材可以分散深度伪造过程中人脸检测器的注意力,使得基于深度神经网络的检测器模型无法正确地检测到扰动图像中的人脸,从而降低所获得的作为深度伪造模型训练数据的人脸数据集质量,致使恶意伪造者无法完成理想的伪造,如图5 所示。作者通过在原始人脸图像上执行梯度上升优化,使得每一轮迭代都有更多的错误检测数据包含在检测集中。同时,面部隐藏一方面通过随机化梯度来减少对抗扰动的生成对人脸检测器网络参数值的依赖,以此来提升中毒图像的灰盒性能;另一方面,考虑到人脸检测器将遵循相同的趋势,因此尝试在多个具有不同网络架构的人脸检测器上执行对抗扰动,选取损失值最大的模型所对应的扰动人脸作为最终的中毒图像,以此来提高黑盒性能。

图5 数据中毒防御方法破坏深度伪造系统中的人脸检测器(Li等,2019)Fig.5 Poisoning defense method distracts face detector in deepfake system(Li et al.,2019)
Sun 等人(2020)提出了一种直接攻击人脸关键点定位提取器的方案:Landmark 破坏者(Landmark breaker)。基于深度神经网络的深度伪造生成模型的训练依赖对齐人脸输入作为训练数据,而人脸关键点定位是提取人脸的重要步骤。作者通过在人脸图像中添加对抗扰动的方式来攻击人脸关键点提取器,从而降低提取器所提取的训练数据的质量。Landmark 破坏者通过最大化提取器对人脸的预测热图(heat-maps)和原始热图之间的误差,改变面部关键点的最终位置。为了实现这一目标,提出了损失函数,具体为
式中,Iadv为待求的对抗图像,I为原始人脸图像,{h1,h2,…,hk}是以原始图像为输入提取的人脸关键点,是以对抗图像为输入提取的人脸关键点。通过优化该损失函数,最大化预测热图与原始热图之间的误差,同时将像素失真限制在一定的阈值内,以保证图像的视觉质量。通过实验验证,Landmark 破坏者在破坏人脸关键点定位、阻止深度伪造方面表现良好。
然而,通过破坏人脸检测器降低用于训练深度伪造模型的数据集质量的方法存在一定问题:一方面,攻击者仍然可以依靠手动提取面部区域或使用更加鲁棒的面部提取器来获取良好的训练数据训练深度伪造模型(Yang 等,2021);另一方面,当前已经有许多通用的深度伪造模型相继提出,例如Sim⁃Swap(Chen 等,2020)等,它们不需要使用目标人脸数据集进行伪造模型的训练即可完成伪造任务。因此,上述基于数据中毒的防御策略难以对人脸图像提供足够的保护(Yang等,2021)。
2.2.2 基于对抗攻击的防御方法
Ruiz等人(2020)首次尝试向图像中添加对抗扰动来中断深度伪造的输出,以达到破坏伪造模型性能的目的,原理如图6 所示。对于对抗扰动η的求解,他们指出可以使用目前已提出的对抗攻击算法来求解,例如迭代快速梯度符号法(iterative fast gra⁃dient sign method,I-FGSM)(Kurakin 等,2017)、投影梯度下降法(projected gradient descent,PGD)(Madry等,2019)等。同时,作者指出这种直接添加对抗扰动的破坏方式可以十分轻易地被对抗训练(adver⁃sarial training)、图像模糊等对抗防御操作所规避。在此基础上,进一步提出了扩频对抗攻击,以此来提高防御的鲁棒性。在I-FGSM 下的扩频对抗攻击求解式为
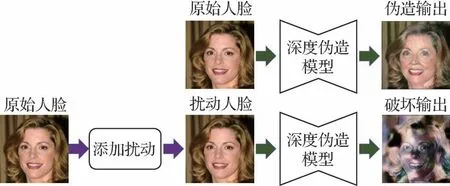
图6 破坏深度伪造模型输出的示意图Fig.6 Illustration of deepfake disruption with a real example
式中,为第t次迭代的扰动图像,α为更新步长,L为定义的距离函数,clip(∙)为截断函数;fk是一个模糊卷积运算,共有K种不同大小和类型的模糊方法。
Yeh 等人(2020)的工作和Ruiz 等人(2020)的工作同步,他们在CycleGAN(Zhu 等,2017)、pix2pix(Isola 等,2017)和pix2pixHD(Wang 等,2018)模型上进行了深度伪造中断。在验证了扭曲攻击的基础上,进一步研究了无效攻击对于深度伪造的破坏情况,并对两者的防御效果随对抗扰动阈值的变化情况进行了探究。如图7 所示,本文节选了研究中针对“微笑表情”和“佩戴眼镜”两个属性所训练的CycleGAN网络(Zhu等,2017)的深度伪造破坏结果,其中扭曲攻击的破坏效果由破坏输出和伪造输出之间的目标距离衡量,距离越大则破坏效果越明显;无效攻击的破坏效果由破坏输出和原始图像之间的目标距离衡量,距离越小则破坏效果越明显。通过研究发现,扭曲攻击的破坏效果和对抗扰动的大小呈现正相关,且随着扰动大小的增大会趋于饱和;而无效攻击的破坏效果随对抗扰动的变化是高度非线性的,并且从图7(c)(d)可以看出,针对不同属性的破坏之间的行为差异很大。
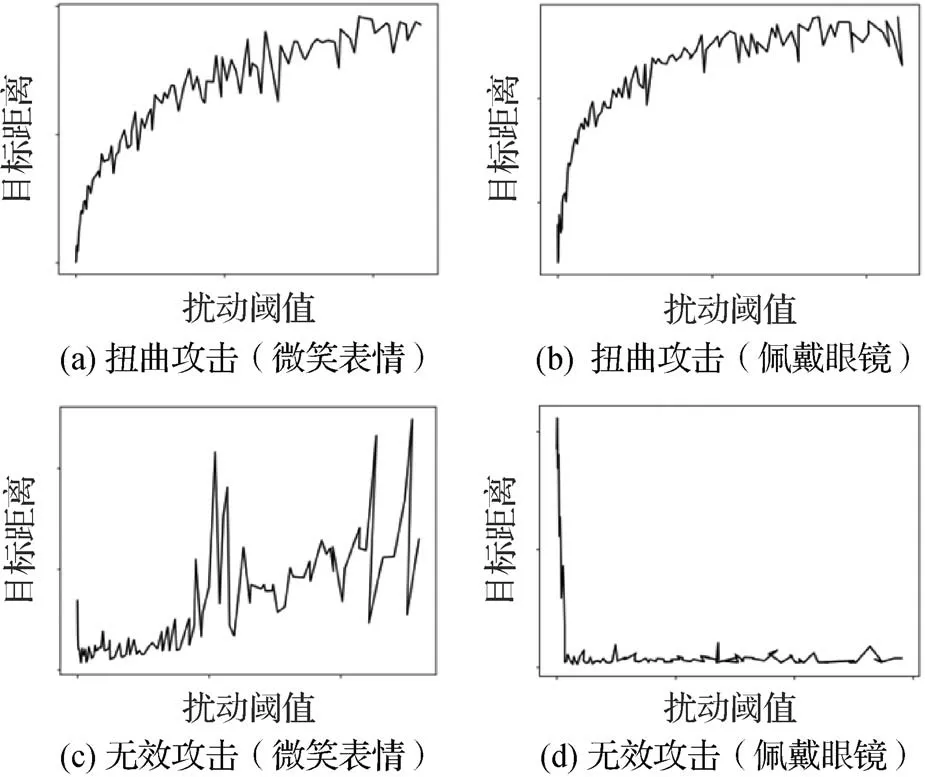
图7 扭曲攻击和无效攻击的破坏效果随扰动阈值的变化情况(Yeh等,2020)Fig.7 The disrupting effect of distorting attack and nullifying attack changes with the maximum magnitude of the perturbation(Yeh et al.,2020)((a)distorting attack(smile);(b)distorting attack(glass);(c)nullifying attack(smile);(d)nullifying attack(glass))
上述方法在针对深度伪造模型的对抗攻击上进行了早期深入研究,并为后续在鲁棒性性能上及复杂化场景上的对抗攻击主动防御方法的研究奠定了理论基础。下面针对不同性能需求和应用场景下的典型算法设计进行进一步的介绍。
1)基于抗对抗训练的典型方法。Segalis 和Galili(2020)指出,如果恶意伪造者使用含有上述对抗扰动的图像重新训练深度伪造模型,那么扰动对深度伪造的防御能力将大大减弱。在一些假新闻场景中,伪造者可能会在政治人物的视频上从头开始训练伪造模型,以便与另一个人进行“换脸”。在这种情况下,注入对抗扰动的视频素材可能会成为伪造者用于重新训练深度伪造模型的训练数据,从而规避防御。为了解决这个问题,提出了一种抗训练(training-resistant)的对抗攻击方法:振荡GAN(oscil⁃lating GAN,OGAN)攻击。OGAN 是一种更强的对抗攻击形式,当深度伪造模型使用被OGAN 攻击的图像时,无论这些含有对抗扰动的素材是否包含在训练数据中,都会产生错误的输出。OGAN 针对面部替换模型Faceswap 设计,其目标是训练一个扰动图像生成器G*,具体为
式中,x为输入图像,Nx为x对应的仿射变换,用于提高模型的泛化性能,mx为x的掩码,G为一个生成器,用于生成对抗样本,Ladv为对抗损失函数,A、B为人脸,fA为人脸A的自编码器输出,DA、DB为用于训练Faceswap 模型自编码器的人脸A、B的数据集,LA、LB为人脸A、B的Faceswap损失值由以DA的子集PA为输入的生成器G生成的扰动图像和DA的其余图像组成。总的来说,OGAN 通过交替优化迭代来训练生成器G网络,保证迭代训练的过程中训练数据中含有中间生成的对抗图像。实验结果证明了抗训练对抗攻击的存在和其有效性,这种方法也可以迁移到更加广泛的领域。
2)基于鲁棒性性能的典型方法。上述一些方法虽然成功破坏了深度伪造的输出,但它们存在鲁棒性较弱的问题:在真实的伪造场景下,伪造者所使用的人脸素材可能会经过若干种图像变换操作(例如图像的裁剪、拉伸、重映射等),而这些操作会使得扰动图像的对抗性被破坏(Chakraborty 等,2018;Chen 等,2021)。因此,Yang 等人(2021)提出了一种变换可感知的对抗攻击策略来破坏深度伪造。其目标为
式中,η为添加的扰动,Tr为随机变换函数,变换操作包括图像裁剪、仿射变换和图像重映射等。这种随机性提高了所生成扰动图像的鲁棒性,同时变换函数也可以根据具体的应用保护场景进行定制,只需要保证变换的可微性即可。该方案在白盒环境下展现了良好的防御效果和更加强健的鲁棒性,但在灰盒和黑盒环境下,其防御能力有所下降。
3)基于黑盒场景的典型方法。上述这些简单直接地针对特定深度伪造模型进行对抗攻击的方式虽然取得了良好的破坏效果,但是其基于白盒环境的性质限制了它们的实用性和通用性:一方面,造成破坏需要防御者对伪造者所使用的人脸操纵模型的网络架构、参数、梯度等内部信息有所了解,但在实际使用场景中,这些信息往往是无从得知的(Dong 等,2022);另一方面,这些方法只能通过单独的训练过程来破坏特定的伪造模型,而为大量的人脸图像生成这种泛化能力较低的扰动的成本是十分昂贵的(Huang 等,2022)。为解决这些问题以提高模型的泛化性和鲁棒性,一些基于黑盒攻击的主动防御方法相继提出。Huang 等人(2021)提出了一种两阶段训练框架的扰动生成器,在第1 阶段中,训练一个代理模型(surrogate model,SM)来模仿目标人脸操纵模型的行为;第2 阶段的目标是训练一个扰动生成器(perturbation generator,PG),用于给人脸图像添加对抗扰动来破坏深度伪造。同时,为了解决使用训练好的SM来训练PG时存在的因深度神经网络非凸性导致的局部最优问题,作者提出了一种交替训练策略来逐步地训练SM 和PG:在训练过程中,只有扰动生成器PG的更新受代理模型SM的影响,而SM则以独立的方式定期更新。各项实验表明了该主动防御框架在属性编辑任务上的有效性和在黑盒环境下的鲁棒性。该方法为黑盒场景下的主动防御提供了值得借鉴的思路,但将其泛化到面部替换任务中时遇到了困难,因为面部替换任务难以找到一个通用的代理模型来生成扰动(Wang等,2022)。
Dong 等人(2022)在针对深度伪造模型的黑盒攻击上展开研究,提出了一种可转移的循环对抗生成对抗网络(transferable cycle adversary generative adversarial network,TCA-GAN),来针对未知的人脸操纵模型产生对抗扰动,以实现黑盒环境下对深度伪造的破坏。在训练阶段,考虑到深度伪造中面部替换、属性编辑等任务可以视为面部重建任务的近似工作,作者构建了一个基于深度自编码器的网络替代模型来模拟面部重建过程,然后对该可访问的替代模型进行对抗攻击,以此来训练TCA-GAN。具体来说,训练过程主要基于添加和删除对抗扰动来模拟对抗攻击和防御。在应用阶段,TCA-GAN 可以基于单个人脸图像生成针对未知深度伪造模型的对抗扰动。为了获得更好的泛化性能,在生成对抗样本的过程中引入了后正则化操作(post-regularization)以增强其泛化能力。在CelebA(celebfaces attribute)数据集(Liu等,2015)上的实验结果显示,具有破坏替代模型能力的扰动图像可以成功扰乱未知的人脸操纵模型,如StarGAN(Choi 等,2018)、AttGAN(He 等,2019)等。TCA-GAN 虽然实现了完全黑盒环境的主动防御,但其在伪造人脸上产生的失真较为有限,防御效果仍然存在提高的空间。
4)基于跨模型对抗的典型方法。除了通过研究黑盒对抗攻击方式来提高算法的泛化性外,Huang等人(2022)提出了一种白盒环境下的跨模型通用对抗水印(cross-model universal adversarial watermark,CMUA-Watermark)来提高对抗扰动的通用性能。将当前的防御方法分为3个类别:1)单图像对抗水印(single-image adversarial watermark,SIA-Watermark),可以保护单幅图像免受单个模型的伪造;2)跨图像通用对抗水印(cross-image universal adversarial watermark,CIUA-Watermark),可以保护多个图像免受单个伪造模型的影响;3)跨模型通用对抗性水印(CMUA-Watermark),可以保护多个图像免受多个深度伪造模型的影响。论文指出,每个训练好的人脸操纵网络都有自己可接受的输入数据分布,这意味着只有满足网络可接受分布的面部图像才能被正确修改。论文首先实现了CIUA水印:对于特定目标模型,通过在每次迭代中输入批大小数量的面部图像来计算对应数量的扰动,然后为了缓解这些扰动的冲突并使水印关注人脸的共同属性,通过计算这些扰动的平均值来得到平均扰动作为该模型的CIUA水印,它可以将原始人脸图像引导到该目标模型的真实输出分布之外。最后CMUA水印由基于不同目标模型的CIUA水印叠加更新得到,如图8所示,G1-G3为不同的目标深度伪造模型,MSE 为均方误差(mean squared error),avg 为取平均操作。在针对多种深度伪造目标模型的测试实验中,CMUA 展现了良好的跨模型防御能力,且十分高效。但是,其必须针对新出现的深度伪造模型不断地迭代更新,这会增加对抗水印的训练开销。
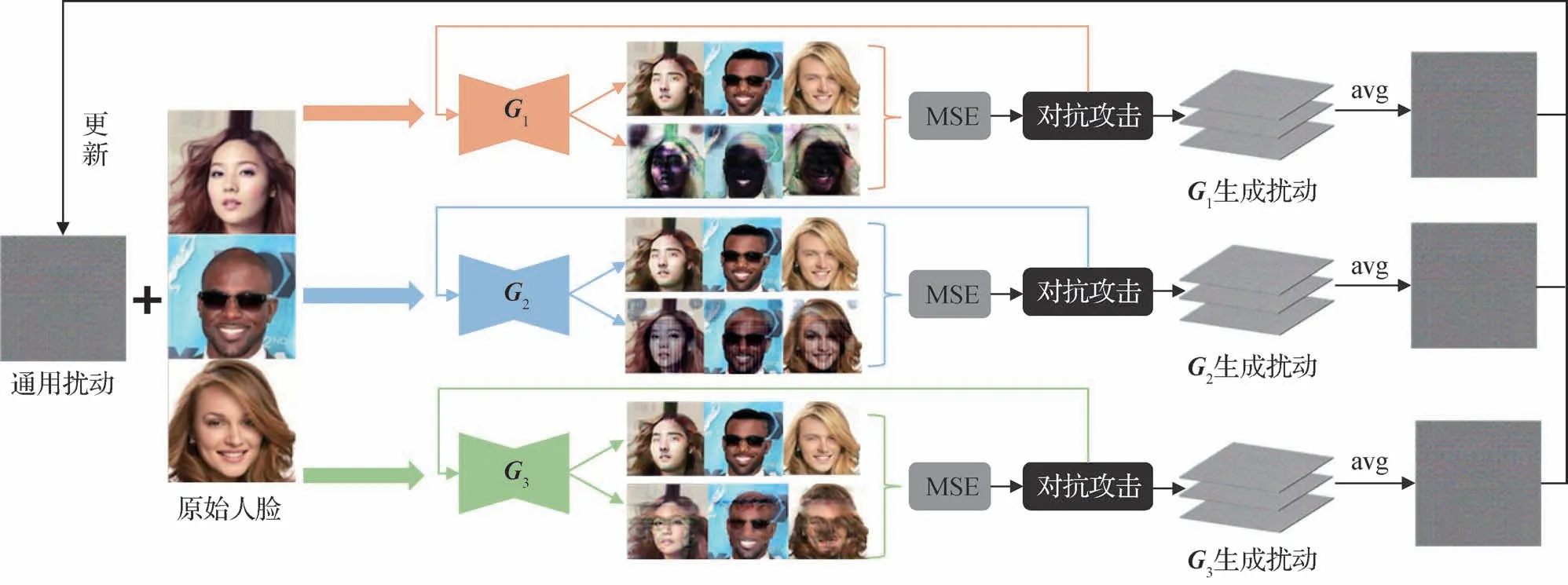
图8 跨模型通用对抗攻击(CMUA)的算法原理框图(Huang等,2022)Fig.8 Framework of the cross-model universal adversarial attack(CMUA)(Huang et al.,2022)
5)基于硬模型挖掘的典型方法。为了缓解人脸伪造模型的多样性带来的对抗梯度不一致性问题,以及解决优化后的对抗扰动倾向于破坏更易受攻击模型的问题,Guan 等人(2022)提出了一种名为硬模型挖掘(hard model mining,HMM)的集成防御策略。该策略使添加的扰动在优化过程中专注于最难破坏的模型,它没有追求良好的平均性能,而是在每个迭代步骤中提高扰动破坏最难攻击模型的性能来使其具有破坏所有深度伪造模型的能力,具体为
式中,x为原始人脸图像,Mk为不同的人脸操纵模型,ηx为所求的对抗扰动,ck为模型Mk所需要的引导信息,y为伪造图像,满足y=Mk(x,c),D为距离函数,“—”表示取平均值。这些距离中最小值所对应的Mi即为最难被破坏的伪造模型,通过最大化该模型的破坏距离,从而提高整体的防御性能。同时,为了减少优化过程中人脸图像背景的干扰,使用了人脸注意力模块(face attention module,FAM)将破坏集中在图像的人脸面部区域。
6)基于Lab 色彩空间对抗的典型方法。一般的对抗扰动存在脆弱性问题,即一些图像变换操作,例如压缩、高斯模糊、输入重建等会使得对抗样本对目标模型的攻击性能大大降低(Chen 等,2021);同时,这些扰动会或多或少地导致人脸图像存在一定的视觉失真。为解决这些问题,Wang 等人(2022)受Lab色彩空间感知均匀、更能满足人类对外界的感知等优点的启发,提出了一种针对Lab 色彩空间生成对抗感知敏感扰动(perceptual-aware perturbations)的主动防御方法:Anti-Forgery。论文尝试在Lab 色彩空间的a、b 通道进行操作,产生更为自然的色彩扰动。与在RGB 颜色空间上添加稀疏对抗扰动的方式不同,这种基于Lab 色彩空间的扰动是以一种不间断的方式产生的,即使很小的扰动也可以实现对深度伪造模型的破坏。各项实验表明,基于Lab 的对抗攻击可以尽可能地保持扰动图像的视觉质量,并且对不同的输入变换操作具有良好的鲁棒性。
2.2.3 基于隐空间的防御方法
前文在主动干扰防御的目标中提到,扰动图像不仅需要对深度伪造具有破坏能力,同时还应该尽可能地保持添加了扰动的人脸图像的视觉质量,从而减少对作为保护对象的互联网用户在多媒体和社交应用上分享图像、视频的影响(Sun 等,2022b)。而基于对抗攻击的主动防御方式虽然利用扰动阈值限制了所添加的对抗扰动的大小,但仍然会导致人脸视觉质量的损失和轻微的失真。同时,随着对抗样本检测算法和对抗攻击防御模型的提出,这些基于像素层面的对抗扰动可以轻易地被检测或规避(Chen等,2021;He等,2022b)。
基于此,He 等人(2022b)提出了一种基于隐空间映射变换的主动防御方法:隐空间对抗探索(latent adversarial exploration,LAE)。LAE 的基本原理如图9 所示,E为一个预训练的编码器,其作用是将人脸图像反演到隐空间,G为一个预训练的生成器网络,它以隐空间的映射作为输入,输出该映射所对应的图像;F为伪造者所使用的深度伪造模型,当对原始图像x0进行深度伪造时,可以得到具有良好伪造效果的伪造图像F(x0)。LAE的做法是,首先将原始图像x0反演到潜在空间中,得到其在潜在空间中的映射z0,并以z0作为初始点迭代更新z,z所对应的重现图像为x;接着在隐空间中寻找z在ϵ范围内的相邻映射z′,该相邻映射满足两个条件:1)由z′通过生成器生成的重构图像x'=G(z′)在视觉上与原始图像x0十分相似;2)深度伪造模型无法对重构图像x'成功攻击,即F(G(z′))无法成功得到视觉上的伪造效果。LAE 选择了无效攻击作为破坏目标,即使得深度伪造的输出结果在视觉上接近原始人脸图像。同时,作者将搜索到的映射z′和z的距离限制在ϵ内,以确保搜索到的映射是原始图像映射的“邻居”。
由于LAE 对图像的对抗变换过程发生在隐空间中,所以不会造成图像层面的微小扰动,如图10(b)(c)所示。相比LAE,基于深度伪造中断(Ruiz等,2020)的防御方式所生成的扰动图像放大后存在明显的失真。但需要注意的是,由于LAE 在隐空间对图像的变换在一定程度上改变了图像的语义,故该方法会略微改变人脸图像的外观。如图10(a)(b)所示,LAE 轻微地改变了人脸的嘴部,这对于一些以分享个人照片或视频为目的的互联网用户来说是不可接受的,因此对人脸图像影响更小的隐空间防御方式亟待提出。
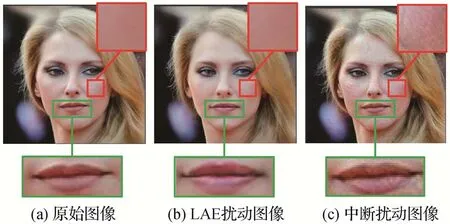
图10 基于LAE的扰动图像(He等,2022b)和基于深度伪造中断的扰动图像(Ruiz等,2020)Fig.10 The adversarial images of LAE(He et al.,2022b)and deepfake disrupting(Ruiz et al.,2020)((a)clean image;(b)the adversarial image of LAE;(c)the adversarial image of deepfake disrupting)
Li等人(2023)提出了一种最大化原始图像和扰动图像之间的隐空间差异和特征空间差异的方法:UnGANable。以基于优化的反演(Abdal 等,2019)为例,在白盒环境下,UnGANable 首先利用反演模型Io来反演目标图像x以获得其隐空间编码z=Io(x)。为了最大化隐空间差异,提出了一个端到端的编码器模型Es,用来反演每一步用于防御深度伪造的扰动图像,并通过最大化Es()和真实隐空间编码z的距离来训练Es;为了最大化特征差异,提出可以使用第三方预训练模型作为特征提取器F来获得原始人脸和扰动人脸的特征;在黑盒环境下,由于对深度伪造模型是不可知的,因此防御者只能使用已知的特征提取器F来对图像的特征空间进行变换,即最大化x和之间的特征差异。在DCGAN(deep con⁃volution GAN)(Radford 等,2016)、WGAN(Wasser⁃stein GAN)(Gulrajani 等,2017)、StyleGAN(Karras等,2019)等伪造模型上的实验表明,UnGANable 具有良好的防御效果。
2.2.4 复现实验
为了进一步展示上述各类针对不同性能需求和应用场景的主动干扰防御算法的关键设计和算法性能,本文选择了其中较有代表性的若干种算法进行复现和实验对比。主要关注黑盒场景的跨模型防御性能和防御鲁棒性性能两方面,分别在白盒环境、黑盒环境和鲁棒性白盒环境下测试所选取的防御算法,其中鲁棒性操作选择QF(quality factor)因子为90 的JPEG 压缩。所有复现实验均使用StarGAN(Choi等,2018)作为目标模型,选择金发、棕发、性别和年龄4 种人脸属性作为目标属性,并使用CelebA(celebfaces attribute)(Liu 等,2015)作为测试数据集,在破坏目标上均选择扭曲攻击,扰动阈值ϵ设置为0.05。实验使用L2范数距离、结构相似性(struc⁃ture similarity index measure,SSIM)(Wang 等,2004)和防御成功率(defense success rate,DSR)(Ruiz 等,2020)3项指标进行评估,有关评估指标的定义等内容将在第3节中进行详细介绍。
复现实验结果如表1 所示。典型的主动干扰防御技术在白盒环境下均能取得良好的防御效果;在黑盒环境下,针对黑盒场景设计的防御算法和跨模型对抗防御算法均展现了对深度伪造的防御能力;在鲁棒性实验中,基于图像处理设计的鲁棒性防御方法和基于Lab 色彩空间对抗的防御算法在总体上取得了较好的效果,但考虑到现实场景中的图像处理手段复杂而多样化,因此其在实际应用中存在一定的局限性。图11 展示了上述实验的可视化结果。
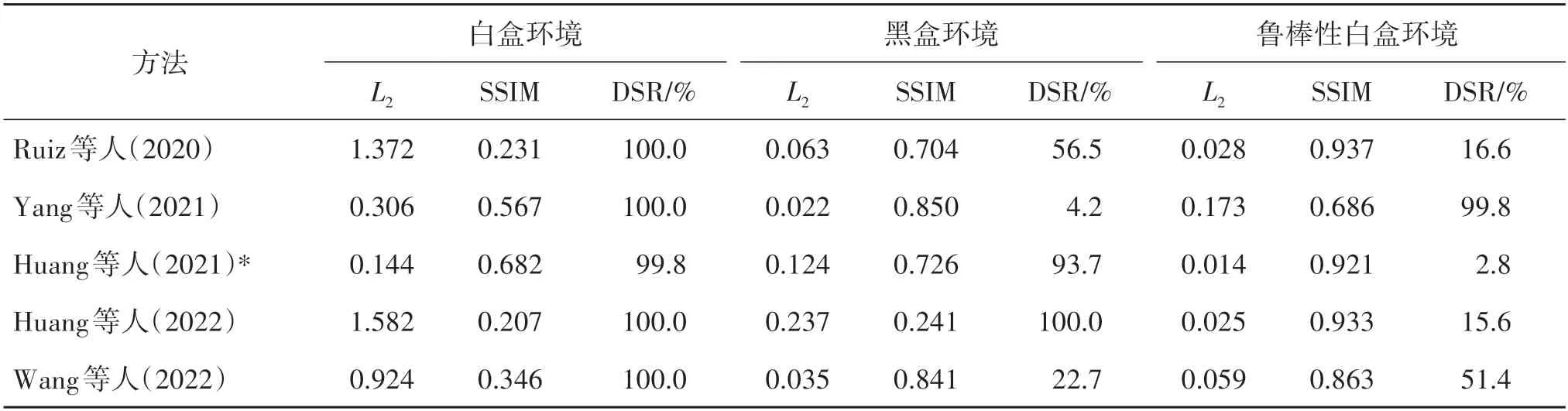
表1 典型的主动干扰防御方法的防御效果比较Table 1 Comparison results on typical proactive disruption defense methods

图11 典型的主动干扰防御方法防御效果的可视化结果Fig.11 Visualization results of typical proactive disruption defense methods((a)white-box scenarios;(b)black-box scenarios;(c)robustness white-box scenarios)
2.2.5 小结
本文对常见的基于对抗攻击和基于隐空间的主动防御方法从环境设置、破坏目标、适用任务和核心思想等方面进行了总结,如表2 所示。对于环境设置,在白盒环境下,假定防御者知晓恶意伪造者所使用的一切信息,包括伪造模型的网络架构、参数、梯度、选择编辑的条件域等;在黑盒环境下,防御者仅能对目标伪造模型进行查询(Dong 等,2022);灰盒环境有许多不同的定义,本文将其定义为防御者仅知晓伪造模型的架构和训练过程,无法访问目标模型的参数和梯度等信息。
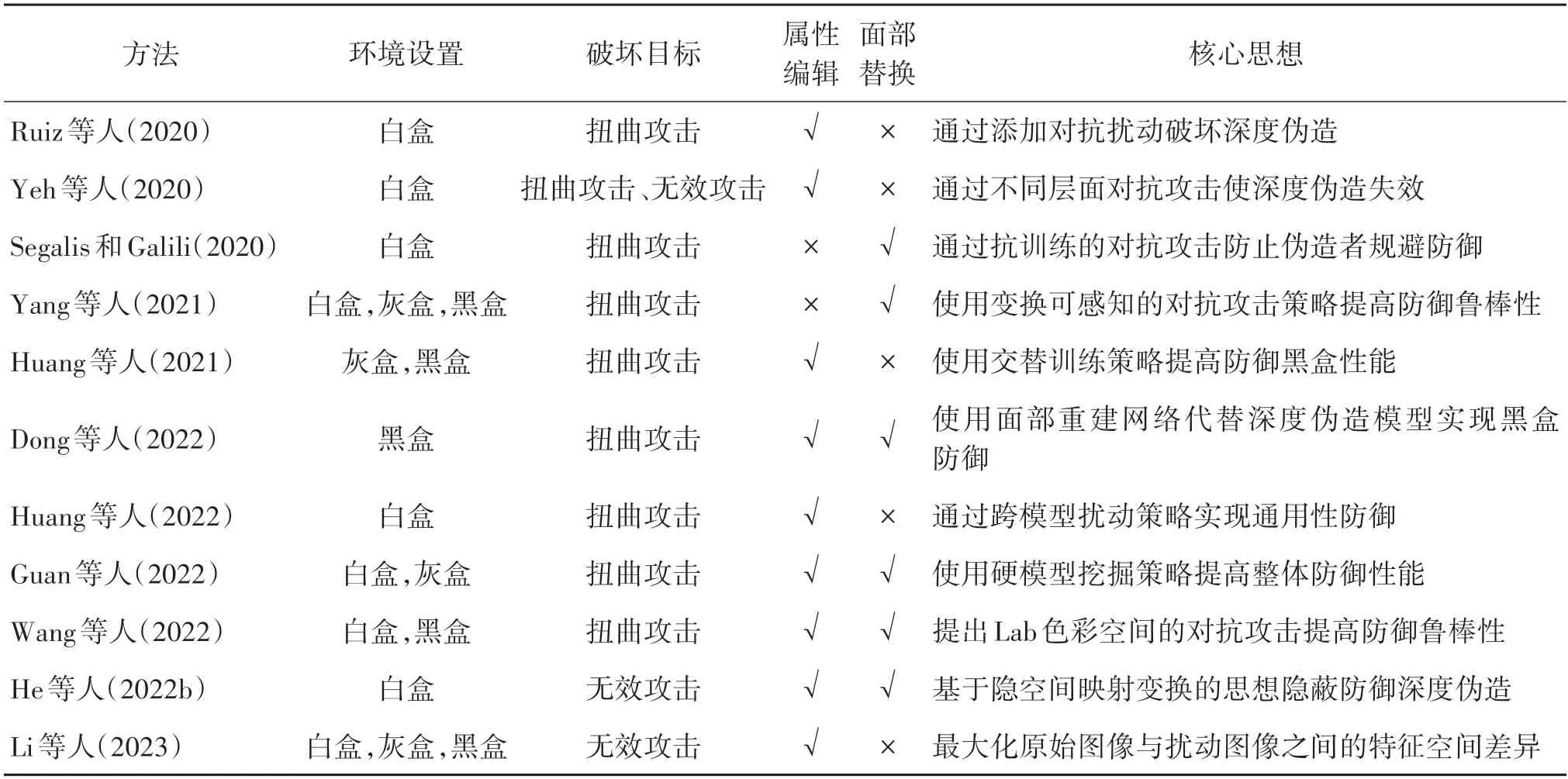
表2 基于对抗攻击和基于隐空间的主动防御方法总结Table 2 Summary of proactive defense methods based on adversarial attack or latent space
2.3 基于主动取证的防御技术
2.3.1 典型算法
与基于主动干扰的防御技术不同,基于主动取证的防御方法不要求破坏深度伪造模型的性能,而是尝试对成功伪造的图像进行溯源工作或对难以判断真伪的图像进行身份认证。
Yu 等人(2020)将图像隐写技术运用到深度伪造主动取证之中,提出了人工GAN 指纹(artificial GAN fingerprints,AFP)。该方法首先将指纹嵌入到人脸图像中,当使用含有人工指纹的人脸图像作为训练数据训练深度伪造模型后,使用该伪造模型所伪造的人脸图像将含有特定的人工指纹。在应用阶段,如果某图像含有与所嵌入指纹相匹配的人工指纹,则判断为伪造图像,以此来实现深度伪造的初步检测。当为不同的GAN 训练分配不同的指纹时,即可实现深度伪造模型的溯源分析。然而该方法存在一定的局限性,因为AFP 需要假设互联网上所有的图像或视频都有其特定的指纹。
Wang 等人(2021a)提出了一种通过使用图像标记来保护人脸安全和隐私的方案:FakeTagger。他们尝试将认证消息嵌入到待保护的图像中,并在深度伪造后恢复它们,以验证它们是否被恶意操纵。他们指出,主动取证的防御方法存在以下3 个关键问题:1)对不同类型的GAN 具有泛化性:在进行深度伪造时,攻击者可能会使用具有不同架构的GAN网络(例如,整体合成、部分合成),因此主动取证应该具有从未知的GAN 所伪造的图像中恢复嵌入标签的能力;2)对图像变换具有鲁棒性。在现实世界的场景中,嵌入的图像在基于GAN 的操作之后会经历常见的图像变换;3)嵌入标签的隐蔽性。嵌入标签对于人类来说应该是难以察觉的。FakeTagger 基于一种简单但有效的编码器和解码器架构,通过信道编码来生成冗余消息以提高其鲁棒性,使被保护图像在基于GAN的图像变换之后也可以有效地恢复消息;同时使用一个GAN 模拟器连接编码器和解码器,以模拟GAN对编码图像的各种操作。FakeTagger的基本流程如图12 所示,消息生成器(X generator,Xgen)首先将给定的嵌入消息编码为冗余消息标签Tag,然后由编码器对输入图像和冗余消息进行编码以生成编码图像。伪造者则会操纵编码图像生成各种深度伪造图像。解码器从深度伪造图像中将冗余消息提取出来并输入信道解码器(X decoder,Xdec),最终由Xdec恢复嵌入的认证消息。在面部替换、属性编辑和人脸生成等不同类型的深度伪造下的实验结果表明,FakeTagger在嵌入和恢复认证消息上具有良好的性能,但是该方法只针对特定模型的推理阶段进行设计,并不能影响伪造模型本身(Sun等,2022a)。
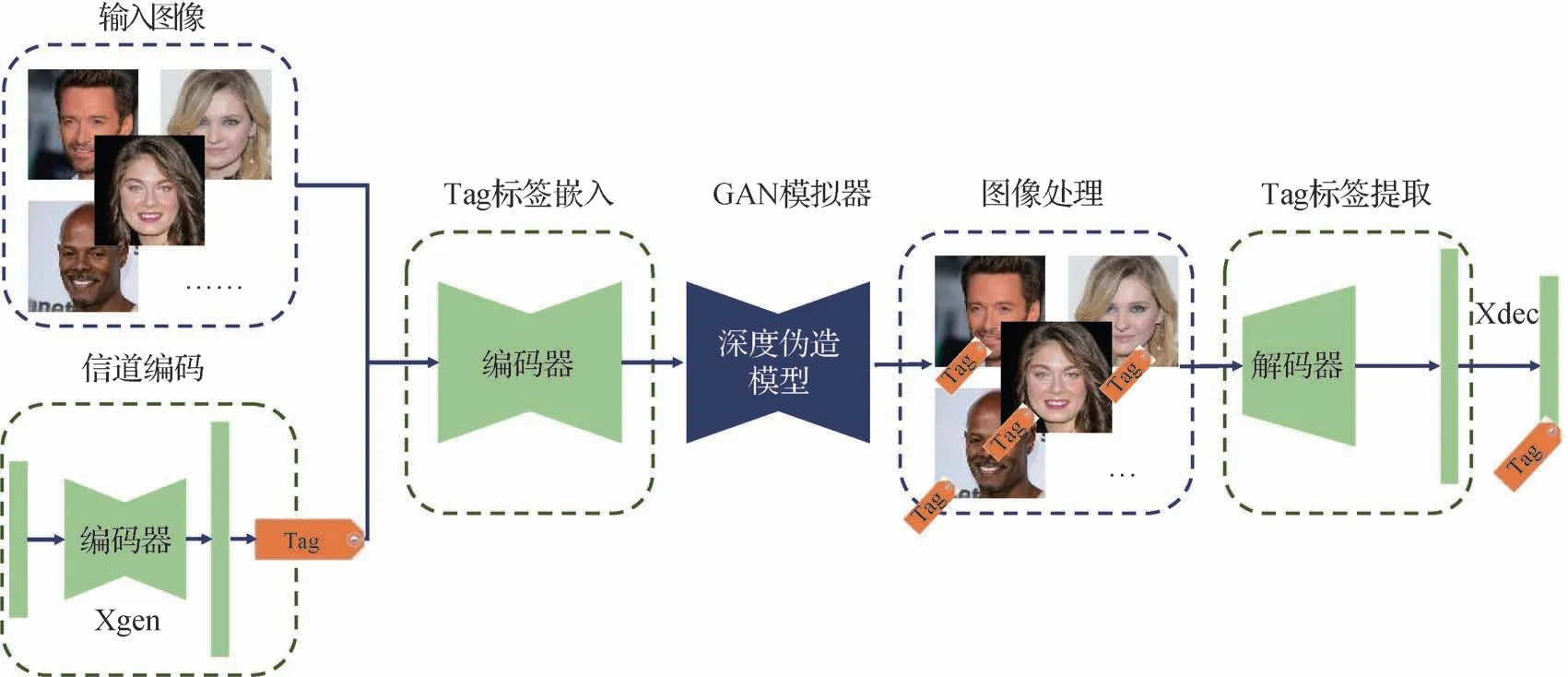
图12 FakeTagger的算法原理框图(Wang等,2021a)Fig.12 Framework of FakeTagger(Wang et al.,2021a)
为解决上述方法存在的问题,Sun等人(2022a)提出了一种新的主动取证模型:FakeTracer。FakeTracer通过一组自编码器在训练数据上嵌入精心设计的痕迹,深度伪造模型训练完成后将会在伪造图像上嵌入类似的痕迹,以此来暴露深度伪造。具体来说,FakeTracer 会在人脸图像中加入两种类型的痕迹:可持续痕迹(STrace)和可擦除痕迹(ETrace)。一旦用户在个人照片或视频上传到社交网络之前将它们添加到其中,使用这些人脸图像训练的深度伪造模型将生成包含可持续痕迹但不包含可擦除痕迹的伪造输出。因此通过检测人脸图像是否包含可持续痕迹和可擦除痕迹即可判断其是否被伪造。在Celeb-DF 数据集(Li 等,2020c)上的大量实验表明,FakeT⁃racer具有良好的保护效果。
上述方法虽然可以对人脸图像或视频进行认证来保护其身份所有者的权利,但Lin 等人(2022)指出,在某些合法的换脸服务提供商(faceswap ser⁃vices provider,FSP)提供服务的场景中,原始图像或视频中的行为人的权利也应该受到保护。在此基础上,他们提出了SIDT(source-ID-tracker)来跟踪深度伪造视频帧中的原始人脸。受到数据隐藏概念的启发,SIDT 设计了一种端到端的自编码方法,可将原始人脸隐式地嵌入到深度伪造结果中,且不会造成明显的视觉变化。将整个原始人脸嵌入到目标人脸中需要具有高感知质量的高嵌入容量,但社交媒体的共享通信信道是有损的,为了解决这个问题,引入了一个失真模拟层(distortion simulation layer,DSL)来模拟所提出的端到端自编码框架中的社交媒体有损信道。
为了给人脸图像提供语义级别的保护,防止伪造者操纵人脸的身份特征,Zhao 等人(2023)提出了一种基于身份水印的主动防御方法。身份水印框架包括两个主要步骤:水印注入和水印验证。在水印注入阶段,输入的人脸图像首先通过两个专用网络被分解为身份表示和多级属性表示;然后将一个伪随机序列嵌入到身份表示中以生成带水印的身份识别。嵌入序列不依赖于人脸图像,因此可以随机选择,但其将被保留并用于后续的水印验证。另一个生成网络将带水印的身份识别与原始属性相结合以合成带水印的人脸图像,这幅带水印的图像与原始图像具有相似的视觉感知。水印验证步骤旨在验证图像中是否存在水印,以确定深度伪造模型是否对其进行了篡改。使用与水印注入相同的网络来提取图像的身份表示,然后计算其与嵌入水印的相关性以检查水印是否存在。根据伪随机序列的特点,如果相关结果出现峰值,说明水印还在保护的图像中,没有被深度伪造模型所篡改。用户在线分享个人图像之前,可以将个人的身份水印嵌入到这些图像中,一旦有与水印图像具有相似身份的图像出现在互联网上,水印图像的所有者可以根据其水印的存在来验证这些可疑图像的真实性。
2.3.2 小结
本文对上述常见的主动取证防御方法在环境设置、保护目标、水印作用阶段和核心思想等方面进行了总结,如表3所示。其中,水印作用阶段反映了嵌入待保护人脸中的水印影响目标深度伪造模型的阶段。

表3 主动取证防御方法总结Table 3 Summary of proactive forensics defense technology
2.4 小结
本节对介绍的深度伪造主动防御方法中已公开算法实现的部分进行了汇总,包括算法性能测试中所使用的目标深度伪造模型以及算法的代码链接,如表4所示。同时,表5给出了常用做目标模型的深度伪造算法的开源链接,包括DeepFaceLab(Perov等,2021)、Faceswap、FSGAN(Nirkin 等,2019)、Face⁃shifter(Li 等,2020a)、SimSwap(Chen 等,2020)、CycleGAN(Zhu 等,2017)、pix2pix(Isola 等,2017)、pix2pixHD(Wang 等,2018)、NeuralTextures(Thies等,2019)、GANImation(Pumarola 等,2018)、Icface(Tripathy 等,2020)、StarGAN(Choi 等,2018)、Att⁃GAN(He 等,2019)、AGGAN(Tang 等,2019)、STGAN(selective transfer GAN)(Liu 等,2019)、HiSD(hierar⁃chical style disentanglement)(Li 等,2021)、ProGAN(Karras 等,2018)、StyleGAN(Karras 等,2019)和StyleGANv2(Karras等,2020)。

表4 深度伪造主动防御技术开源算法Table 4 Open-source codes for Deepfake proactive defense techniques
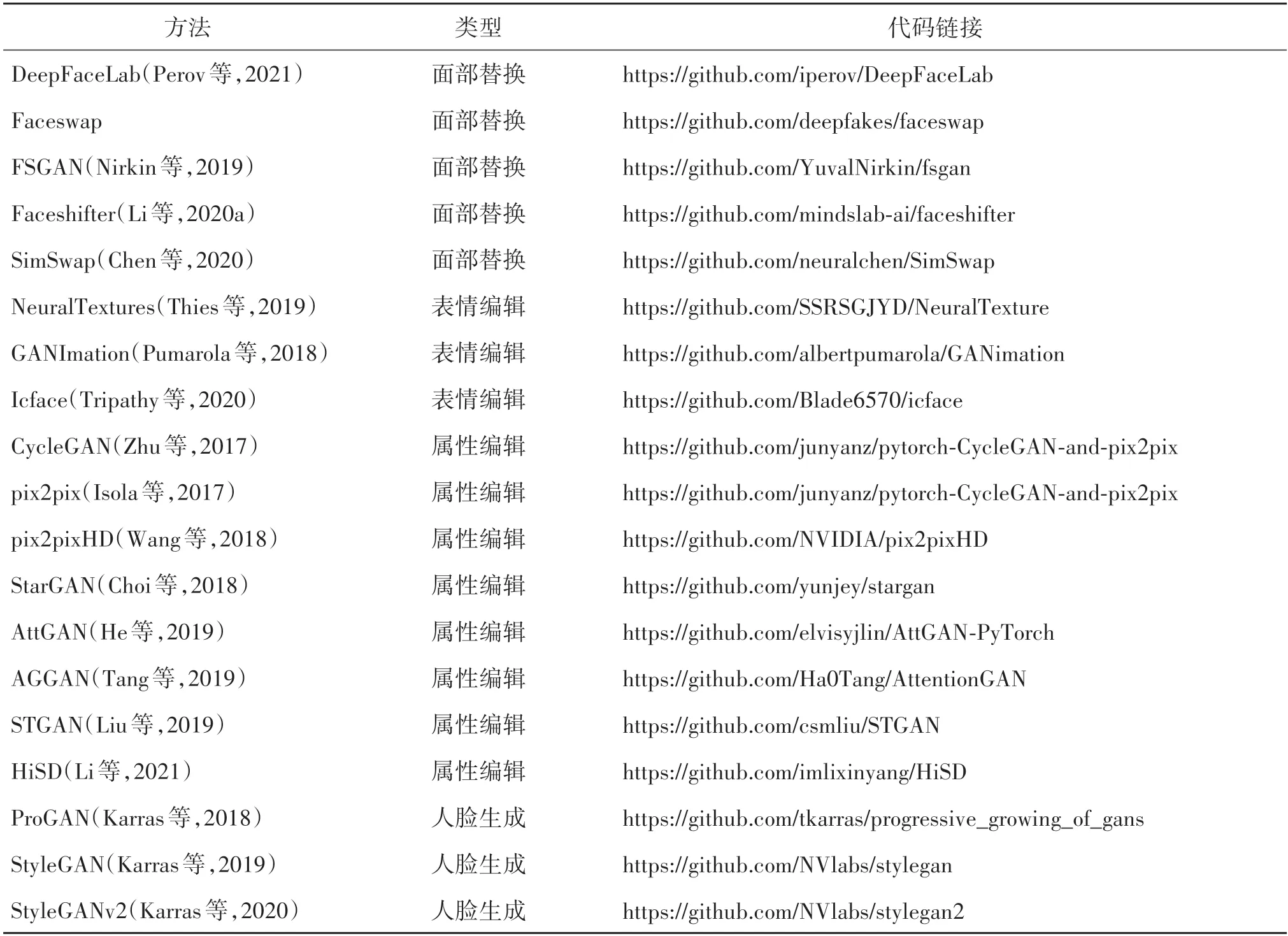
表5 深度伪造开源算法Table 5 Open-source codes for Deepfakes
3 评价指标
由于当前基于主动干扰的防御技术更为主流,且不同的基于主动取证的防御技术所关注问题存在较大差异,因此在本节中主要介绍常见的主动干扰防御方法的防御效果评估指标。由2.2 节的介绍可知,主动干扰的防御方法希望实现两个主要目标,即破坏深度伪造模型的输出和保证采取了保护措施的人脸图像的视觉质量(Huang 等,2021)。因此,对于防御模型的评估往往会从破坏深度伪造模型输出的效果和保持扰动图像视觉质量的效果两个方面分别进行。
3.1 深度伪造模型输出破坏效果的评估
对深度伪造模型性能的破坏目标可以分为扭曲攻击和无效攻击,两者在评估方法上存在一定的差异。其中,扭曲攻击尽可能地使伪造输出失真,因此被成功破坏的输出往往不再具有人脸可识别特征,评估的对象一般为真实的伪造输出图像和被破坏的输出图像;无效攻击则使伪造输出在视觉上尽可能地和原始人脸图像相似,因此其评估的对象一般为原始图像和被破坏的输出图像(Yeh等,2020)。
3.1.1 扭曲攻击的评估
对于扭曲攻击,一方面,一般会采用L2范数距离、结构相似性(structure similarity index measure,SSIM)(Wang 等,2004)、峰值信噪比(peak signal-tonoise ratio,PSNR)、学习感知图像块相似度(learned perceptual image patch similarity,LPIPS)(Zhang 等,2018)等指标来进行评估。其中,LPIPS 的结果更符合人的感知,其计算方法为
式中,x为原始图像的伪造输出,x0为扰动图像的伪造输出,l为神经网络L层的提取特征堆的一层和为l层输出的特征图,Hl、Wl为l层特征图的高度和宽度,向量wl用于放缩激活通道数,“⊙”表示逐元数乘积。
另一方面,Ruiz 等人(2020)为了评估对深度伪造破坏的成功率,提出了防御成功率(DSR)的指标。当真实输出与破坏伪造输出的L2范数距离大于0.05时,则认为该伪造图像被破坏成功。图13展示了防御的L2范数距离随扰动阈值ϵ的变化情况,当L2范数距离大于0.05 时,破坏伪造输出图像的失真将十分明显。

图13 对StarGAN模型进行深度伪造中断防御的扰动图像和被破坏的伪造输出(Ruiz等,2020)Fig.13 Visual examples of perturbed and disrupted images implementing Deepfakes defenses to disrupt StarGAN models(Ruiz et al.,2020)
此外,目前许多商业应用程序都集成了活体检测系统来判断输入图像中的人脸是否为真实人脸,因此保护它们免受伪造人脸图像的危害十分重要,故主动防御模型还应防止伪造人脸通过活体检测的验证。Huang 等人(2022)提出,对于活体检测系统,若置信度得分大于0.95但小于0.99,则认为该人脸是低置信度真实人脸(true face with low confidence,TFLC);而如果置信度分数大于0.99,则认为该人脸是一张高置信度真实人脸(true face with high confi⁃dence,TFHC)。可以通过统计伪造输出的TFLC 率和TFHC率来评估防御算法性能。
3.1.2 无效攻击的评估
相较于扭曲攻击,无效攻击在伪造输出上造成的失真较小,对图像的改变较为稀疏,同时可以保持被破坏伪造输出的人脸特征。基于此,除L2范数距离外,一般会采用更为稀疏的L1范数距离对面部的变化进行度量(He等,2022b)。
He 等人(2022b)还指出,对于属性编辑任务,可以采用属性识别模型(He 等,2017)的平均置信度差(mean confidence difference,MCD)进行度量;对于表情编辑任务,可以通过计算Hourglass网络(Jourabloo和Liu,2015)得到的人脸关键点的归一化平均误差(normalized mean error,NME)来评估防御效果,计算方法为
式中,N为提取的人脸关键点个数,d为两眼瞳孔间距离(inter-pupil distance)或两眼外眼角间距离(inter-ocular distance),xi为原始人脸图像的第i个关键点坐标为伪造输出图像的第i个关键点坐标。对于面部替换任务,可以使用人脸识别模型Arcface(Deng 等,2022)计算身份嵌入的余弦相似度(cosine similarity)来评估防御模型的性能。
3.2 扰动图像视觉质量保持效果的评估
对于添加了防御措施的人脸图像视觉质量的评估,一般情况下会使用经典的图像生成质量评价指标,如PSNR、SSIM 和FID(Frechet inception distance)(Heusel等,2018)等。其中,FID指标的计算为
式中,μ0和μf分别是使用Inception v3 网络(Szegedy等,2016)提取的原始图像和伪造图像的特征均值,Σ0和Σf分别是原始图像和伪造图像的特征协方差矩阵。除此之外,还有NIMA(neural image assess⁃ment)(Talebi 和Milanfar,2018)、DBCNN(deep bilin⁃ear convolutional neural network)(Zhang 等,2020)、BRISQUE(bind/referenceless image spatial quality evaluator)(Mittal 等,2012)等指标用于扰动图像视觉质量的评估。
同时,He 等人(2022b)提出,添加了防御措施的图像本质上是一个对抗样本,因此可以使用对抗样本检测器来评估扰动图像的视觉质量。该评估方法使用多种对抗样本检测器,如LID(local intrinsic dimensionality)(Ma 等,2018)、Deep KNN(K-nearest neighbors)(Papernot 和McDaniel,2018)、Deep Maha⁃lanobis(Lee 等,2018)等进行交叉验证,以平均检测精度作为衡量指标。检测精度越低,表示该图像越难被检测器识别,则图像的视觉质量越好。
4 常用数据集
深度伪造主动防御方法论文中实验的开展主要使用常见的人脸图像和视频数据集,这些数据集常用于深度伪造模型的训练、测试或检测任务。
1)LFW(labeled faces in the wild)数据集(Huang等,2007)最初是一个为人脸识别任务提出的数据集。LFW 一共含有13 000 多幅从互联网上搜集的人脸图像,每幅图像都被标识出对应的人的名字,大约有1 680个人包含两幅以上的人脸。
2)CelebA(celebfaces attribute)数据集由Liu 等人(2015)提出,包含10 177个不同身份的202 599幅人脸图像,数据集中的每幅图像都包含人脸标注框、5个人脸特征点坐标以及40个属性标记。CelebA 常用于属性编辑任务。
3)CelebA-HQ 数据 集(Karras 等,2018)是对CelebA 数据集的升级,是一个公共人脸数据集,包含30 000 幅不同分辨率的人脸图像,如256 ×256 像素、512 × 512像素和1 024 × 1 024像素等。
4)CelebAMask-HQ 数据集(Lee等人,2020)由超过30 000 幅512 × 512 像素分辨率的人脸图像组成,其中每幅图像都带有19 个属性特征,包括鼻子、眼睛、眉毛、耳朵、嘴巴、嘴唇、头发等面部部位和帽子、眼镜、耳环、项链、脖子、布等装饰配件。
5)FFHQ(flickr-faces-high-quality)数据集由Kar⁃ras 等人(2019)提出,是一个高质量的人脸数据集,包含70 000幅1 024 × 1 024像素的PNG格式高清人脸图像,这些人脸在年龄、种族上存在明显差异,同时拥有十分丰富的人脸属性,如性别、肤色、表情、发型和人脸姿态等,此外人脸图像中也包含眼镜、墨镜、帽子、发饰及围巾等多种配件。
6)Faceforensics++数据集是Rössler 等人(2019)提出的一个深度伪造数据集,该数据集使用了Face2Face(Thies 等,2020)、Faceswap、DeepFakes 和NeuralTextures(Thies 等,2019)4 种深度伪造算法对1 000 个真实视频进行伪造处理。视频数据来源于977个YouTube视频,所有视频均包含一个没有被遮挡的人物正脸。
7)Celeb-DF 数据集(Li等,2020c)是一个用于深度伪造取证的大规模、具有挑战性的数据集。该数据集包括从YouTube 上收集的590 个具有不同年龄、种族和性别的拍摄者的真实视频,以及5 639 个相应的深度伪造视频。视频中人脸的分辨率为256 × 256像素。
表6汇总了上述常用数据集的公开链接。

表6 深度伪造主动防御技术常用公开数据集Table 6 The mainstream datasets for deepfake proactive defense techniques
5 深度伪造主动防御的前景
5.1 主动防御面临的挑战
深度伪造主动防御技术初步实现了深度伪造的“事前防御”,当用户希望自己上传到互联网的人脸图像或视频不被恶意用户用于伪造,则可以在上传之前对这些图像或视频嵌入特定的保护性扰动或水印(Zhao 等,2023)。然而,深度伪造的主动防御仍然面临一些挑战:一方面,随着一些防御规避算法的提出,主流的主动防御方法十分容易失效(Chen 等,2021);另一方面,深度伪造主动防御的实用性也是非常值得考虑的问题(Huang 等,2022)。
5.1.1 主动防御的规避
在2.2 节中提到,当前主流的深度伪造主动防御方法基于向待保护图像中添加对抗扰动,然而,添加了扰动的对抗样本本身就具有一定的脆弱性(Chen 等,2021)。一方面,一些基本的图像变换操作可以很轻易地破坏对抗扰动的性能,例如图像的模糊、仿射、重映射等,虽然Ruiz 等人(2020)、Yang等人(2021)尝试在添加扰动的过程中通过提前的图像变换来增强扰动的防御鲁棒性,但在更加复杂或强度更大的变换下这些方法的作用十分有限;另一方 面,LID(local intrinsic dimensionality)(Ma 等,2018)、对抗攻击识别器(赵俊杰 等,2023)、基于不一致性检测(Li等,2020b)等对抗样本检测方法的提出,使得嵌入了防御扰动的人脸图像可以被恶意伪造者所检测到(Metzen等,2017),同时这些伪造者可以使用Defense-GAN(Samangouei 等,2018)、Me-net(Yang 等,2019)、Super-Resolution(Mustafa 等,2020)等先进的对抗样本防御算法破坏被保护人脸样本中的对抗扰动,进而成功进行伪造。此外,如果伪造者使用含有对抗扰动的人脸素材对自己的深度伪造模型进行对抗训练,这些伪造模型将具有更强大的鲁棒性(Ruiz 等,2020),进而难以被主动防御算法所破坏。
特别地,Chen 等人(2021)提出了一种名为掩码引导检测和重建(mask-guided detection and recon⁃struction,MagDR)的框架,如图14 所示,MagDR 可以有效地规避大部分基于主动干扰的深度伪造主动防御方法。MagDR 由检测器和重构器两部分组成,其中检测器用于检测深度伪造模型的输入是否包含对抗扰动,为了检测不同的损坏模式,检测器包含两个子检测器:失真检测器和一致性检测器。深度伪造模型通常会修改人脸图像的条件属性区域,因此对于添加扰动的输入图像,其所对应破坏输出的失真也会集中在特定域上。失真检测器运用了这个原理,它会对输出图像的各个域与输入图像进行距离的计算,当距离大于某个阈值时,则判断该输出图像添加了扰动。一致性检测器主要针对整个输出图像都被扭曲而非某个域时的情况,利用对抗扰动的脆弱性,作者对输入图像进行多种图像变换处理,通过对比各个变换图像的伪造输出间的一致性来判断输入图像是否添加了扰动。重构器的任务是减少对抗扰动对输入图像的影响来恢复深度伪造模型的正确输出,其通过基于条件域的图像恢复技术来净化被破坏的图像。尽管Wang 等人(2022)的工作尝试在MagDR 的规避下保持主动防御的鲁棒性性能,并取得了一定的成果,但对抗样本自身脆弱性的问题依然存在。
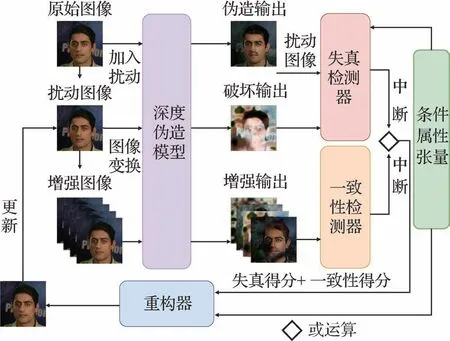
图14 MagDR的基本流程图(Chen等,2021)Fig.14 Basic flowchart of MagDR(Chen et al.,2021)
5.1.2 实用性问题
深度伪造主动防御的实用性是其面临的另外一个问题。一方面,Wang 等人(2021a)和Dong 等人(2022)指出,在真实的互联网环境下,对于恶意伪造者所使用的深度伪造模型是不可知的,任何未经保护的人脸图像或视频都有可能被用于各种不同类型的深度伪造。虽然当前学术界提出了一些基于黑盒环境的主动防御方法,但由于其通用性的限制,防御效果十分有限,伪造者可以通过简单的后期修复手段继续达到伪造的目的。另一方面,Huang 等人(2022)则指出,为互联网上海量的人脸图像都添加这种泛化性较弱的水印成本巨大,且不具有实际的防御意义。跨模型通用对抗水印的方法虽然一定程度上提高了对抗水印防御的泛化性和通用性,但随着深度伪造技术的不断发展,越来越多不同架构、不同功能的伪造模型将在未来继续提出,迭代地更新跨模型对抗水印的成本和耗时也将不断增长。这些问题都对深度伪造主动防御的实用性发出了挑战。
5.2 未来工作
从深度伪造主动防御面临的挑战和其防御目标的角度出发(Huang 等,2021),未来的工作主要可以分为两个方面:其一是研究具有更强鲁棒性性能和黑盒场景防御性能的防御方法;其二是尽可能地保持被保护图像或视频的视觉质量。
5.2.1 性能更强的防御
深度伪造主动防御通过在人脸图像或视频中加入特定的扰动或水印,从而达到破坏深度伪造模型的性能或对伪造图像溯源、认证的目的。从对抗扰动自身脆弱性的角度考虑,当前已有一些具有更强大鲁棒性的对抗攻击算法相继提出,为了防止扰动被基本的图像变换操作所破坏或被对抗样本检测器、防御算法所规避,这些算法的思想可以较为适配地迁移到基于自编码器或GAN 的深度伪造模型的主动防御之中,如He 等人(2022a)提出了一种基于l0范数约束的可迁移稀疏对抗攻击框架,该方法只需修改图像中少数几个像素即可攻击成功;同时,一些基于不可学习样本的算法在抵御对抗训练方面展现了良好的性能,例如,Fu 等人(2022)提出了一种通过鲁棒误差最小化噪声防止图像被用于对抗训练的方法。从提高主动防御算法的通用性和实用性的角度考虑,一些具有更强大的黑盒性能的攻击算法为性能更强的主动防御提供了可借鉴的思路(Zhang等,2022),如Chen 等人(2020)提出了一种基于注意力攻击(adversarial attack on attention,AoA)的对抗方法,该方法尝试攻击图像的注意力热图,其在不同的神经网络间拥有共同的语义特征;Wang等人(2021b)提出了一种特征重要性感知(feature importanceaware,FIA)的可迁移对抗攻击,通过最大化图像非重要特征、最小化图像重要特征的方式,提高对抗的泛化能力。
5.2.2 视觉质量
每天有上亿的个人用户或官方媒体在互联网多媒体应用中分享、传播各种包含人脸的图像或视频(Gaur,2022),虽然保护这些人脸样本免受恶意用户的深度伪造对于维护公民的合法权益十分重要,但大部分分享者都希望他们所发布的图像和视频具有良好的视觉质量,而不会因为所采取的防御措施影响个人的分享体验(Wang等,2022)。因此尽可能地保证添加了对抗扰动或水印的人脸的视觉质量也是深度伪造主动防御中不能忽略的目标(Huang 等,2021)。当前已有一些针对对抗样本视觉质量的研究工作,例如Sun 等人(2022b)提出了一种基于最小显着差异(minimum noticeable difference,MND)的人脸隐私保护的对抗攻击方法,MND 可以定义为人类视觉系统区分干净图像和扰动图像的最小感知差异,因此若尝试在深度伪造主动防御算法的优化过程中加入类似的视觉损失进行约束,则可以在一定程度上提高图像的视觉质量;王杨等人(2022)提出了一种通过约束对抗扰动的空间面积和分布来降低人眼对样本中扰动的视觉感知的方法,他们尝试提取深度模型更加关注的图像关键区域,并利用所提取的区域作为约束条件限定添加扰动的位置,以此来引导具有更低感知性的对抗样本的生成。基于隐空间的防御方法(He 等,2022b;Li 等,2023)也为保持图像视觉质量提供了思路,因为其对人脸图像映射到隐空间的变量进行编辑来实施保护,而非直接在像素层面添加扰动,但解决因隐空间变量的改变而造成人脸微小变化的问题也是未来工作之一。
6 结语
本文对当前学术界所提出的深度伪造主动防御技术进行了系统性的总结和归纳,并对各类算法的技术原理、实现方法、防御目标、环境设置和存在的优缺点等进行了深入的阐述;从不同角度介绍了深度伪造主动防御所面临的挑战和存在的局限性,对其未来的发展方向进行了思考和展望。
首先对人脸深度伪造技术以及基于检测的深度伪造防御方法所存在的局限性进行了简要的介绍,目前常见的深度伪造技术可以分为面部替换、属性编辑、人脸生成3 种类型(王任颖 等,2022;曹申豪等,2022)。深度伪造技术的滥用给公民的个人隐私权和名誉权造成了危害,同时对社会稳定甚至国家安全带来了威胁。然后,对深度伪造主动防御技术的分类、技术手段和基本原理等进行了详细的阐述。深度伪造主动防御的思想是在用户将人脸图像或视频发布至互联网或公共平台之前,在其中加入微小的对抗扰动或水印,这些加入的保护信息可以破坏深度伪造模型的性能,使其输出的伪造结果被破坏,或者可以对伪造人脸进行溯源以及真伪验证工作。由以上防御目标的不同,可以将深度伪造主动防御技术分为基于主动干扰的防御方法和基于主动取证的防御方法,其中以基于主动干扰的防御更为常见,其又可以分为3 种不同的技术手段:基于数据中毒、基于对抗攻击和基于隐空间编辑。同时,深度伪造主动防御应保证采取保护措施的图像和原始图像尽可能相似,并保持良好的视觉质量。接着,对深度伪造主动防御技术特别是基于主动干扰的防御方法中使用的评估指标和常用数据集进行了说明。其中对防御模型的评估往往会从防御效果和扰动图像视觉质量两个方面进行(He 等,2022b)。深度伪造主动防御技术的相关论文主要使用常见的人脸图像和视频数据集,这些数据集常用于深度伪造模型的训练、测试或检测任务。最后,对深度伪造主动防御所面临的挑战和难题以及未来的工作进行了思考和总结。一方面,由于对抗扰动自身的脆弱性,深度伪造主动防御容易被对抗样本检测器和对抗攻击防御算法所规避(Chen 等,2021),且一些针对主动防御模型的规避算法也相继提出;另一方面,主动防御方法较弱的黑盒性能和跨模型水印日益增长的训练成本限制了其实用性(Dong 等,2022)。基于深度伪造主动防御技术所面临的挑战和希望实现的目标,其将向着更强的鲁棒性能、黑盒性能以及更好的视觉质量两方面发展。随着未来研究的深入,深度伪造主动防御技术将有望在实际的社交多媒体场景中使人脸图像和视频免受深度伪造的威胁,构建更加安全和健康的互联网环境。
