边缘引导的双注意力图像拼接检测网络
2024-02-24吴晶辉严彩萍李红刘仁海
吴晶辉,严彩萍*,李红,刘仁海
1.杭州师范大学信息科学与技术学院,杭州 311121;2.杭州启源视觉科技有限公司,杭州 311121
0 引言
由于互联网的快速发展和大量简单易用且功能强大的图像编辑软件被开发出来,网络上被编辑修改过的图像已经呈现出爆炸式的增长。这些被修改过的图像虽然会带来一部分的收益,但同时也给人们的生活带来了许多负面影响,如伪造交易记录、发布虚假新闻。修改一幅图像的方法有很多种。目前来看,图像处理技术大致可以分为图像复制移动操作、图像拼接操作和图像对象去除操作。本文的主题是关于图像拼接操作的检测,所以,后续的所有内容都围绕这一点展开。图1 给出了两个拼接图像的示例。其中,黑色的是真实部分,白色的是篡改部分。图像拼接指从供体图像中选择一个特定的区域,并将该区域粘贴到宿主图像上。在粘贴前,可以通过改变粘贴对象的对比度、饱和度等属性,使粘贴区域的特征分布接近于宿主图像,从而提高检测的难度。因为经过这些方法处理的图像很难被人眼识别出来,所以有必要开发一种有效的图像拼接检测算法。

图1 两个通过拼接方式伪造的图像Fig.1 Two tampered images by splicing((a)splicing images;(b)host images;(c)donor images;(d)the corresponding labels of splicing images)
图像拼接检测的原理是通过提取图像中的某些特征来区分被篡改的部分和真实的部分。在早期阶段,通常使用图像的传感器模式噪声(sensor pattern noise,SPN)(Mahdian 和Saic,2009;Lyu 等,2014)、JPEG(joint photographic experts group)压缩痕迹(Lin等,2009;Bianchi 和Piva,2012)、色彩滤波阵列(color filter array,CFA)插值方式(Ferra 等,2012)等特定属性作为判断图像是否被篡改的依据。由于这些方法大多集中于图像的某一特定属性,因此在实际任务中,它们很难取得良好的效果。最近,随着深度学习技术的发展,很多基于神经网络的方法也相继提出。然而,目前的大多数方法不同程度上都存在着一些缺点。例如,基于块Patch 的篡改定位(Zhang 等,2016;Bappy 等,2017)效果在显示精细度上不如基于像素的方法。块级输出的显示效果很粗糙,无法很好地勾勒出篡改图像中具体的篡改区域;而像素级的显示相比于块级的显示,因其结果更加准确和清晰,所以有效地解决了上述问题。基于单尺度的方法(Bayar和Stamm,2018;Salloum 等,2018)只考虑图像某一尺度上的信息,忽略了图像多种尺度信息的融合,所以它们只能处理尺度变化有限的拼接区域。基于多尺度的方法(Bi 等,2019;Wu 等,2019)意识到要使用来自不同尺度的特征信息,但它们采用的特征融合方式是简单直接地合并,没有认识到不同尺度的特征信息的重要性是不同的。
根据上述分析,本文提出一种边缘引导的具有双重注意力的图像拼接检测网络(boundary-guided dual attention network,BDA-Net)。该网络同时考虑了全局特征和细节特征,能够实现像素级定位。该网络由预测分支、注意力模块和边缘引导分支组成。其中,预测分支是BDA-Net的主干,它通过融合不同尺度的特征信息,获得被篡改区域的定位结果。为了捕获特征内部多维度的依赖关系,使特征更好地融合,本文设计了一个坐标—空间注意力模块(coordinate-spatial attention module,CSAM),并将其嵌入到预测分支中。此外,要想精确地分割被篡改区域,通常还依赖于被篡改区域边界上的视觉痕迹。因此,利用边缘引导分支来提高模型对边缘痕迹的关注,并使用GT标签和边缘标签来进行端到端的训练。在4 个拼接数据集上的实验结果表明,与现有的拼接伪造检测方法相比,BDA-Net 具有更强的检测能力和更好的稳定性。
本文的主要贡献如下:1)提出了一种边缘引导的双注意力图像拼接检测方法。该方法通过将空间通道依赖和边缘预测集成到特征中,实现像素级定位。2)设计了一个新的注意力模块,即坐标—空间注意力模块。该模块可以有效地捕获特征内不同维度的依赖关系,从而提高网络提取细节的能力。3)设计了一种边缘引导机制。该机制能够有效地捕获被篡改图像中真实区域与被篡改区域交界处的微小边界痕迹,从而更好地辅助预测分支进行分割。4)实验结果表明,与现有的拼接检测方法相比,本文模型具有更强的检测能力和更好的鲁棒性。
1 相关工作
图像篡改检测即通过提取图像的篡改特征来定位被篡改的区域。目前,图像拼接篡改的检测方法大致可以分为两类。一种是传统的基于手工特征提取的检测方法;另一种是基于神经网络进行特征提取的检测方法。
对于传统的基于手工特征提取的方法,它们主要利用图像的传感器模式噪声SPN(Mahdian 和Saic,2009;Li和Li,2012;Lyu等,2014)、JPEG压缩痕迹(Lin 等,2009;Bianchi 和Piva,2012;Wang 等,2020)、图像的CFA 插值方式(Goljan 和Fridrich,2015)等属性的差异来识别潜在的篡改图像并定位图像中的篡改区域。传统的定位技术通常集中在某个特定的图像特征上,因此这些方法在实际任务上常常受到限制。例如,若拍摄宿主照片和供体照片的设备是相同的,则基于SPN的方法将不起作用;基于JPEG 压缩痕迹的方法只能检测JPEG 格式的拼接图像;如果设备使用相同的CFA 插值算法,则基于CFA的方法也会失效。
近年来,深度学习技术,特别是卷积神经网络(convolutional neural network,CNN)在目标检 测(Bochkovskiy 等,2020;Wu 等,2021;Li 等,2023)、三维建模(Qi 等,2017;Olutomilayo 等,2021)等计算机视觉领域取得了相当好的成果。同时,由于神经网络具有强大的抗干扰能力、泛化能力和从输入数据中自动提取抽象复杂特征(这是识别篡改区域所必需的)的能力,一些研究者意识到可以借助神经网络来处理图像拼接篡改检测任务。
Zhang 等人(2016)首次将深度学习技术应用于图像伪造任务并且取得了块级的粗略定位结果。他们提出了一种两阶段深度学习方法来学习特征,以检测不同格式的篡改图像。为了识别被篡改区域,Bappy 等人(2017)设计并实现了一个混合CNNLSTM(convolutional neural network-long short term memory)模型来捕捉被篡改区域和真实区域之间的异常特征。该方法首先将图像分割为图像块,然后将分割后的图像块作为后续CNN 的输入。在此之后,CNN 生成的特征图也被分割成块,并依次输入到长短期记忆网络(long short term memory,LSTM)中,用于学习不同块之间的边界差异。通过网络最后一个CNN 得到最终的分割结果,它的输入来源于LSTM 网络(Hochreiter 和Schmidhuber,1997)的输出。这两种检测方法只是初步的尝试。由于使用图像斑块作为网络的输入,因此他们的检测结果较差。随后,Salloum 等人(2018)将全卷积网络(fully convo⁃lutional network,FCN)(Shelhamer 等,2017)应用于图像拼接检测任务,并提出了多任务全卷积网络(multi-task fully convolutional network,MFCN)框架。他们的方法实现了像素级细粒度的分割。这种方法只使用图像的深层特征,却忽略了包含更详细信息的浅层特征。
Bayar 和Stamm(2018)提出了一种使用约束卷积层的新型CNN,该CNN 可以通过抑制图像内容自适应地学习图像篡改特征。由于该方法在最终预测阶段使用了全连接层,从而导致模型计算复杂度显著增加。Zhou 等人(2018)提出了基于Faster R-CNN(faster region-convolutional neural network)模型(Ren等,2017)的双流网络。网络由一个RGB 流和一个基于隐分析富模型(steganalysis rich model,SRM)(Fridrich 和Kodovsky,2012)的噪声流组成。该方法通过融合双流的特征来定位被篡改的区域。由于RGB-N 是基于区域卷积(region-CNN,R-CNN)模型的网络,所以其定位结果以矩形框的形式呈现,而通常的篡改区域是不规则的。因此,在进行定位操作时,该方法可能会同时选择一些无用的区域。此外,Wu 等人(2019)提出了一种可以同时进行检测和定位任务而无需额外进行图像预处理和后处理的网络框架Mantra-Net(manipulation tracing network)。该方法将图像篡改检测任务视为局部异常检测任务,根据Z-Score 特征捕获局部异常。尽管该网络可以实现像素级的预测,但是,当处于伪造图像被重新生成,伪造图像被故意用高度相关的噪声污染,并且在一幅图像中有多个区域被不同的方式篡改的情况时,该方法容易出错。
Bi 等人(2019)提出了一种可以强化CNN 学习风格的环残差U-Net(ringed residual U-Net,RRUNet)。这种方法通过CNN 中的残差传播和残差反馈过程,使网络模拟人脑的回忆和巩固机制。虽然可以较好地检测到被篡改区域,但检测结果会有一些莫名的噪声。Bappy 等人(2019)扩充了之前的工作(Bappy 等,2017),提出了一种利用频域特征和空间上下文信息来定位被篡改区域的方法。由于该网络使用了LSTM 模块,所以整个网络的计算量较大。随后,Hu 等人(2020)提出了空间金字塔注意网络SPAN(spatial pyramid attention network)。该网络通过类似金字塔的层次结构对“垂直”关系进行建模,并使用局部自注意力模块对空间关系进行建模。自注意力模块的加入导致这个模型的训练非常耗时。Kwon等人(2021)提出了一个端到端的全卷积神经网络,包括RGB 流和离散余弦变换(discrete cosine transform,DCT)流。该网络的RGB流学习视觉图像篡改痕迹,DCT 流学习图像压缩后留下的篡改痕迹(即图像的DCT 系数分布)。该网络的一个问题是,非JPEG 图像送入到网络之前需要进行JPEG 压缩,在这个过程中,图像丢失了很多有意义的信息。
2 提出的方法
2.1 网络架构
本文模型是一个用于图像拼接检测任务的端到端统一框架,其结构如图2 所示。以往大多数篡改检测方法都是采用普通的编解码器结构来提取特征,这些方法没有充分考虑被篡改区域存在着尺寸大小和形状不同的问题。由于在分割任务中,存在大量经典的特征提取网络(Simonyan 和Zisserman,2014;Shelhamer等,2017;Ronneberger 等,2015)。受它们启发,本文提出一个作为预测分支的编解码器网络,该分支作为BDA-Net的主干,可以融合不同分辨率的特征图。
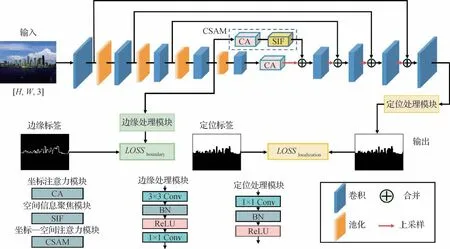
图2 BDA-Net网络框架图Fig.2 The proposed BDA-Net framework for image splicing detection
在预测分支的编码器中,有5 个特征提取块。除第1 个特征提取块仅由卷积层构成,其余每个特征提取块都由最大池化层和卷积层组成。从左到右,每个特征提取块进行卷积运算的次数分别为2、2、3、3、3,每个卷积层使用的卷积核大小均为3 × 3。每个最大池化层的输出特征图大小为其输入大小的一半。在神经网络的处理过程中,随着网络变深,特征图的语义信息密度会变高,但保留的细节信息变得越来越少。为了保留这些丰富的细节,模型不仅将最后一层编码器生成的特征图送入解码器,还将其他特征提取块输出的特征图送入解码器。
在预测分支的解码器中,有4 个对应的上采样块。每个上采样块的输入由两部分合并得到。一部分是与该上采样块处于同层级的编码器中的特征提取块输出的特征图;另一部分是对该上采样块的前一个上采样块的输出进行二倍上采样操作得到的特征图。这样,不同尺度之间的紧密联系可以实现有效的信息交换。经过这些上采样块处理后,得到与原始输入大小相同的特征图;然后将其送入定位模块中,用于生成预测结果。为了捕捉特征内部多维度的依赖关系,使特征更好地融合,在预测分支的编码器的最后两个特征提取块中嵌入了两个注意力模块。此外,倒数第2 个特征提取块的输出特征图不仅送到后续的上采样块,还送到边缘引导分支中,以捕获被篡改区域和未被篡改区域之间的微小边缘痕迹,进而帮助预测分支得到更好的分割结果。
2.2 注意力单元
在深度学习领域,注意力机制可以被认为是一种根据输入信息来自适应提取重要区域并抑制不相关区域的动态权重调整过程。目前,注意力机制在多种计算机视觉任务中已被证明有效,如图像超分辨率(Mei 等,2021)、人脸识别(Li 等,2021)、人体姿态检测(Newell等,2016)等领域。在本文中,将两种注意力模块应用到图像取证领域中。
2.2.1 坐标注意力模块
一个比较常用的注意力就是压缩激励网(squeeze-and-excitation network,SE-Net)(Hu 等,2018)。SE-Net 利用全局上下文信息对不同通道进行权值重标定,在抑制噪声的同时发挥着强调重要通道的作用。由于SE-Net 的结构较为简单,可以很方便地集成到各类网络中。然而,SE 模块也存在一些缺点。在压缩子模块中,所采用的全局平均池化操作过于简单,无法捕获复杂的全局信息;在激励子模块中,采用的全连接层则增加了模型的复杂性和计算量。SE-Net在建模跨通道关系之前使用全局池化来聚合全局空间信息,这使得图像的位置信息被忽略。基于此,在网络中引入了坐标注意力机制(coordinate attention,CA)(Hou 等,2021)。该模块的详细结构如图3所示,其中r是缩小系数。坐标注意力机制分为两个步骤,坐标信息的嵌入和坐标注意力的产生。首先,给定一个通道数为C、高度为H、宽度为W的输入F,其格式为F∈RC×H×W。接着使用两个平均池化核,使它们分别沿着X坐标和Y坐标对每个通道进行水平编码和垂直编码。这两个变换分别沿着两个空间方向聚集特征,生成一对特征图Fx∈RC×H×1,Fy∈RC×1×W。对生成的这对特征图做拼接处理得到Fz∈RC×1×(W+H),并应用一个卷积核尺寸为1 的卷积层来降低维度以达到减少计算量的目的。在经过批归一化和非线性激活函数H-Swish()的处理后,将得到的中间张量Fm∈R(C/r)×1×(W+H)拆分回两个单独的张量,并对它们各自再应用1 × 1卷积变换。此处的卷积变换是为了将这两个单独的张量转换成与输入特征图通道数相同的张量以方便后续的运算。最后,经过sigmoid 激活函数的处理,得到一对具有方向感知和位置敏感的注意力图Fo1∈RC×1×W,Fo2∈RC×H×1。这样,特征图中每一个位置的权值就等于Fo1中对应列值和Fo2中对应行值的积。从坐标注意力模块的结构中,可以发现它能够捕获特征内沿水平和垂直两个维度的长程依赖关系。
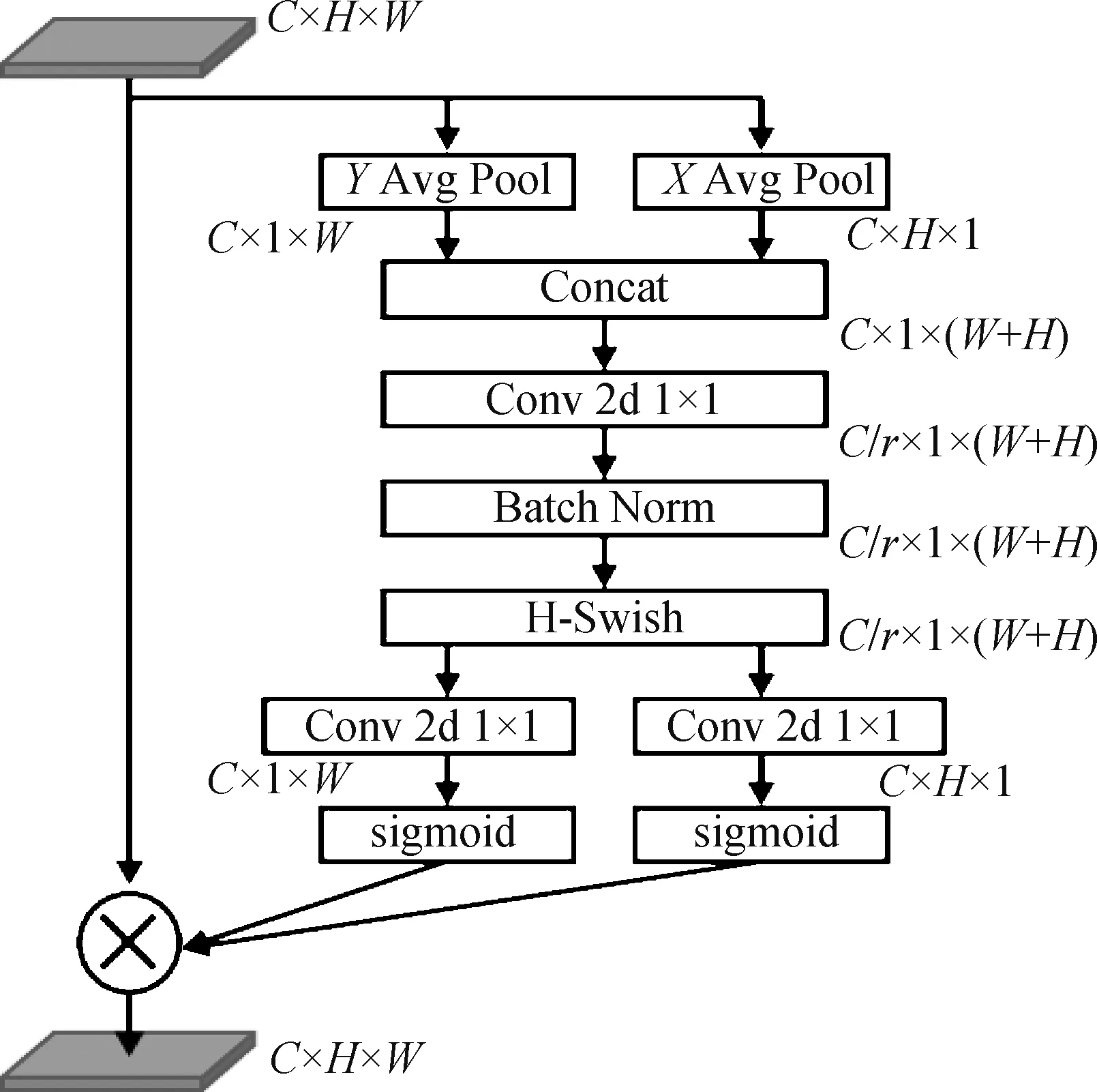
图3 CA模块Fig.3 CA module
2.2.2 坐标—空间注意力模块
坐标注意力模块将通道注意力分解为两个一维特征编码过程,分别沿着两个空间方向聚集特征。它们可以互补地应用于输入的特征图,提高网络对感兴趣区域的提取能力。从坐标注意力的权重计算过程中,可以发现该注意力为了减少计算量,使得同一通道中同一列的元素或同一行元素共享同样的权重。这样,对于在同一列或在同一行的元素来说,它们之间的列区分度和行区分度就消失了。为了解决这个问题,受卷积块注意力模块(convolutional block attention module,CBAM)(Woo 等,2018)结构的启发,构建了一个空间信息聚焦模块(spatial informa⁃tion focus,SIF)。该模块先对输入特征F沿通道方向分别做最大池化和平均池化,得到Fp1∈R1×H×W和Fp2∈R1×H×W两个特征图。然后将这两者拼接,并对拼接后的特征执行一个卷积核尺寸为7 的卷积变换和ReLU 操作,生成最终的注意力图Fo3∈R1×H×W。空间信息聚焦模块利用特征的空间关系来生成一个空间注意力图,使网络明确哪个位置的信息更加丰富,从而加强网络对细节信息的感知能力。它可以作为CA模块的一个补充,用来解决CA模块中存在的问题。在本文中,将CA模块和SIF模块结合起来,形成一个坐标—空间注意力模块(CSAM),具体结构如图4 所示,其中r是缩小系数。基于以上分析,可以发现CSAM 从水平、垂直和通道3 个不同的维度来捕捉特征间的依赖关系。实验表明,CSAM 有效地增强了学习特征的表示能力并提高了网络的检测性能。
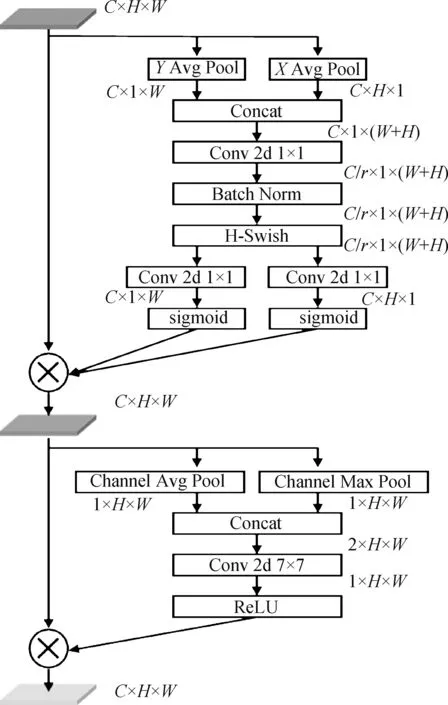
图4 CSAM模块Fig.4 CSAM module
2.3 边缘引导分支
在制作拼接图像的过程中,在被篡改的区域周围会不可避免地留下一些不自然的痕迹。如果能利用这些边缘痕迹,就可以得到更好的检测结果。因此,在提出的网络中添加了一个边缘引导分支。
该边缘引导分支与篡改区域预测分支共用一个编码器,并利用编码器提取的特征来预测被篡改区域的边缘。具体来说,就是将编码器的第4 个特征提取块的输出特征图作为边缘引导分支的输入。将该输入送入边缘处理模块以得到被篡改区域的边缘。边缘处理模块包括一个核尺寸为3 的卷积层、批归一化层、ReLU 层和一个核尺寸为1 的卷积层。经该分支得到的篡改区域边缘预测图会与其对应的边缘标签共同作为边缘损失函数的输入。该损失函数可以辅助网络更好地进行分割。本文中的标签边缘是通过Canny(Canny,1986)方法获得的,这种图像边缘提取方法具有低失误率和高位置精度两个优点。低失误率即尽可能多地标识出图像中的实际边缘;高位置精度即标识出的边缘与实际图像中的边缘尽可能接近。在应用Canny 算法前,会对标签进行高斯滤波以便更好地提取标签边缘。
2.4 损失函数
在本节中,设计了一个多任务损失函数来约束网络。所提出的损失由两部分组成,一个是像素级的定位损失Llocalization,用于提高模型对像素级篡改检测的灵敏度;另一个是整个图像的边缘损失Lboundary,用于引导网络发现图像中篡改区域周围的微小边缘痕迹。
2.4.1 定位损失
通常,在篡改图像中,篡改区域(正样本)和非篡改区域(负样本)的占比是不一样的。篡改区域的比例相对非篡改区域的比例会小一些,这就会产生正负样本不平衡的问题。带权重的交叉熵损失函数可以为不同的训练样本设置不同的权重,提高模型对权重高的训练样本的关注度(本研究中,正样本权重高)。Dice 损失函数注重预测结果和真实结果之间的像素级别的相似度,对于类别不平衡的情况,可以自适应地调整权重值,提高分割模型的准确率和鲁棒性。因此。联合使用带权重的交叉熵损失函数和Dice损失函数来作为定位损失函数。定位损失函数的具体形式为
式中,xi,j是图中坐标(i,j)处的像素点,H和W分别为图像的高和宽,M为类别数,wc是相应类别的权重参数,P(xi,j)是xi,j的真实概率分布,Q(xi,j)是xi,j的预测概率分布。
2.4.2 边缘损失
在预测篡改区域的边缘时,会使用边缘标签来引导网络。在边缘标签中,边缘像素(正样本)的数量相比非边缘像素(负样本)的数量少得多,导致类别不平衡情况发生。对于高分辨率的图像,这种情况尤其明显。针对此问题,使用Dice 损失函数作为边缘损失函数,该损失函数对从极其不平衡的数据中学习特征是有帮助的。边缘损失函数的具体形式为
式中,P(xi,j)是xi,j的真实概率分布,Q(xi,j)是xi,j的预测概率分布。
通过以上在两个不同角度上计算的损失,可以得到一个组合损失,具体为
式中,λ1和λ2是超参数。
3 实 验
3.1 实验设置
3.1.1 数据集
实验使用了4 个图像篡改数据集,分别是Columbia、NIST16 Splicing(National Institute of Stan⁃dards and Technology 16 Splicing)、CASIA2.0 Splic⁃ing(Chinese Academy of Sciences Institute of Automa⁃tion Dataset 2.0 Splicing)和IMD2020(Image Manipu⁃lated Datasets 2020)数据集,它们的具体情况见表1。

表1 实验中用到的数据集Table 1 Datasets employed in the experiments/幅
Columbia 数据集(Ng 和Chang,2004)是一个用于篡改检测的数据集。该数据集中所有拼接图像都是使用真实的图像创建的,没有经过任何后期处理,高分辨率且未压缩。NIST16数据集(Guan等,2019)是由美国国家标准与技术研究院(National Institute of Standards and Technology,NIST)提供的一个非常具有挑战性的数据集,它主要包括3 种类型的操作,即复制—移动、拼接和去除。本文只使用它的拼接数据集NC16 Splicing。CASIA 2.0 数据集(Dong 等,2013)是一个流行的图像篡改检测数据集,该数据集中的图像内容十分丰富,包括Copy-Move 和Splicing两个数据集,本文使用它的Splicing 数据集。IMD2020 数据集(Novozamsky 等,2020)是一个比较新的数据集,它包含了2 010幅从网上下载的真实图像及这些图像的对应标签。
3.1.2 评估指标
检测任务可以认为是一个二值分割任务,其中,篡改像素是正样本,用1表示,未被篡改像素是负样本,用0表示。每个输出像素可以标记为真阳性TP、真阴性TN、假阳性FP 和假阴性FN。使用F1 度量、交并比(intersection over union,IoU)作为后续实验的性能指标。这些指标的计算为
式中,TP(true positive)是预测为正且实际为正的像素数量,TN(true negative)是预测为负且实际为负的像素数量,FP(false positive)是预测为正但实际为负的像素数量,FN(false negative)是预测为负但实际为正的像素数量。
3.1.3 实施细节
使用PyTorch 框架来实现网络模型。此网络可以接收任意大小的图像作为输入,这些输入图像在训练中会被调整到256 × 256 像素。同时,使用Adam 优化算法来优化模型。模型的初始学习率设置为1E-4,学习率调度表为余弦退火热重启学习率调度表。批尺寸设置为2。对于组合损失函数中的超参数,设置λ1=1,λ2=1,ω0=1,ω1=2。应用常规的数据增强来进行训练。实验中用的显卡为NVIDIA GeForce RTX 3060。
3.2 与其他模型的比较
3.2.1 所比较的方法
为了比较所提出的BDA-Net的性能,选择了4 种基于深度学习的检测方法,分别是U-Net(Ronne⁃berge 等,2015)、DeepLab V3+(deep lab V3+)(Chen等,2018)、RRU-Net(ringed residual U-Net)(Bi 等,2019)和MTSE-Net(multi-task SE-network)(Zhang等,2022)。U-Net是一个经典的语义分割模型,可以适用于多种任务。DeepLab V3+将空间金字塔池化模块与编解码器结构相结合,得到一个可以编码多尺度上下文信息、捕获清晰目标边缘的语义分割模型。RRU-Net 是基于U-Net 提出的一个环状残差网络,通过 CNN 中残差的传播和反馈过程来进行特征强化,使篡改区域和非篡改区域间的差异更加明显。MTSE-Net 是一个具有双分支的编解码结构模型,它通过融合两个分支的信息特征来实现篡改检测。
3.2.2 篡改检测性能比较和分析
根据在验证集上的性能来选择最佳的训练模型。表2 显示了在不同数据集上5 种模型的像素级拼接伪造检测性能。从表2中可以发现,BDA-Net在大部分数据集的指标都高于或接近所比较的模型。在Columbia 数据集上,虽然此模型与第1 名存在差距,但差距较小。在NIST16 数据集上,该模型取得了第2 的成绩。而在CASIA2.0 和IMD2020 这两个检测难度较高的数据集上,BDA-Net均取得了第1名的成绩,且大幅领先于其他模型。
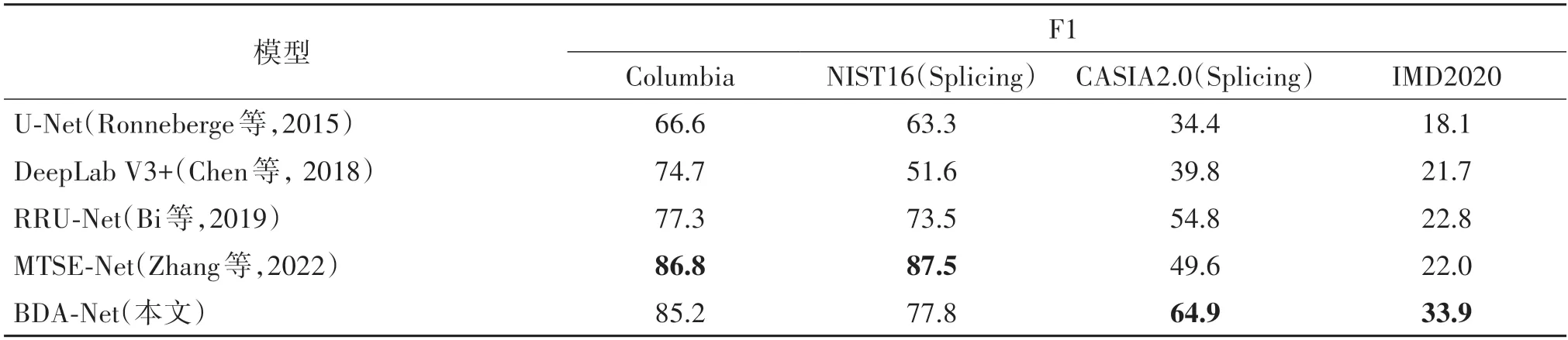
表2 不同模型的像素级拼接检测性能Table 2 Performance on pixel-level splicing forgery detection of different models /%
图5 显示了不同模型的图像拼接检测可视化结果。从结果中可以看到,BDA-Net 的预测结果相比于其他模型的预测结果,它的结果与实际结果是最接近的。比如,在结果图的第1 行,U-Net、RRU-Net和MTSE-Net 不能很好地分割出带云的天空这一篡改区域,DeepLab V3+的预测结果则在拼接的交界处丢失了一部分细节,而BDA-Net 不仅有较好的分割结果,也在拼接的交界处保持了不错的细节。在结果图的第5 行,由于篡改对象与背景融合得很好,其他模型都不能识别出来,只有BDA-Net 能检测出该篡改对象。又比如,在结果图的倒数第2 行,其他模型或者错误地将天空部分当成了篡改区域,或者预测结果存在较多的内容缺失,只有BDA-Net 模型很好地识别出了正确的篡改区域。通过图4 可以看出,本文网络在性能上优于其他网络。

图5 不同模型的图像拼接检测的可视化结果Fig.5 Visualization results of image splicing forgery detection of different models((a)splicing images;(b)ground truth label;(c)U-Net;(d)RRU-Net;(e)DeepLab V3+;(f)MTSE-Net;(g)ours)
3.2.3 稳定性评估
为了评估模型的稳定性,分别对测试图像进行JPEG 压缩、高斯模糊、图像锐化、添加高斯噪声和椒盐噪声的预处理。JPEG 压缩的质量因子设置为QF∈{70,75,80,85,90,95},高斯模糊的核大小设置为K∈{1,3,5,7,9,11,13},图像锐化的锐化半径设置为1,锐化因子设置为S∈{0.50,0.75,1.00,1.25,1.50,1.75,2.00},添加的高斯噪声的均值为0,方差设置为V∈{0.002,0.004,0.006,0.008,0.010,0.020},对图像添加椒盐噪声的比例R∈{0.002,0.004,0.006,0.008,0.010,0.200}。实验中使用的性能指标为F1 度量,数据集为CASIA2.0,实验结果如图6所示。可以看出,对图像添加了不同类型的预处理后,所有模型的性能均出现了不同程度的下降。针对JPEG 压缩,各个模型性能下降程度较低,均保持了不错的稳定性,但本文模型的指标在这些模型中是最好的。针对高斯模糊,在所有模型中,MTSENet下降趋势最为明显,BDA-Net 虽然也呈现出下降趋势,但是其性能指标还是高于其他模型。针对图像锐化处理,DeepLab V3+的性能随着锐化因子的增加出现了较大程度的下降,而BDA-Net 保持了良好的稳定性。针对高斯噪声,可以看到,RRU-Net和MTSE-Net 在方差增大时,性能下降相对较快。针对椒盐噪声,随着替换比例的增加,所有模型都出现了明显的性能下降,但BDA-Net下降幅度较小,保持了较好的性能。从以上分析可以看出,BDA-Net 在这些破坏攻击下表现出更好且更稳定的性能。

图6 不同类型攻击的结果比较Fig.6 Comparison of results among different types of attacks((a)JPEG compression;(b)Gaussian blur;(c)sharpening attack;(d)Gaussian noise;(e)salt and pepper noise)
3.3 消融实验
为了验证每个组件的有效性,在CASIA2.0测试集中评估了5种不同设置的模型性能,结果如表3所示。设置1 为U-Net 网络,用于作为一个基本模型;设置2 是预测分支,是BDA-Net 的主干网络;设置3将坐标注意力模块添加到主干网络的编码器的最后两个特征提取块中;设置4 将边缘引导分支添加到设置3 中;设置5 在设置4 的基础上将编码器的倒数第2 个特征提取块的坐标注意力模块替换为坐标—空间注意力模块。设置5 是最终模型。表3 的结果证明,添加的每个组件都对模型的性能提升有贡献。
4 结论
本文提出了一个边缘引导的双注意力图像拼接检测网络模型(BDA-Net)。该方法可以对拼接图像的篡改区域实现像素级的定位。该网络由一个篡改区域预测分支和一个边缘引导分支组成。预测分支通过融合不同尺度的特征信息,获得被篡改区域的定位结果;边缘引导分支驱使模型跟踪图像中被篡改区域周围微小的边界痕迹,这有助于预测分支更好地进行分割操作。同时,为了捕捉不同维度的依赖关系,还提出了一种名为坐标—空间注意力模块的新型注意力,并将其嵌入到特征提取网络的深层。这样,感兴趣区域的表示可以被增强。
本文使用4 个图像拼接数据集与多种方法进行比较。在Columbia 数据集中,与排名第1 的模型相比,F1 值仅相差1.6%。在NIST16 Splicing 数据集中,F1 值与对比算法中最好的模型略有差距。而在检测难度更高的CASIA2.0 Splicing和IMD2020数据集中,BDA-Net 的F1 值相比排名第2 的模型分别提高了15.3%和11.9%。结果表明,该方法在图像拼接检测任务中有不错的性能。为了验证模型的鲁棒性,还对图像施加JPEG 压缩、高斯模糊、锐化、高斯噪声和椒盐噪声攻击。结果表明,本文模型的鲁棒性明显优于其他模型。可以看到,本文方法在NIST16 Splicing 数据集上没有取得最好的结果。究其原因,是因为该数据集过小,可供模型学习的内容有限。今后将研究无论在小数据集还是大数据集上都能充分提取有效信息的网络模型。
