面向图像拼接检测的自适应残差算法
2024-02-24张玲穆文鹏陈北京
张玲,穆文鹏,陈北京
1.南京信息工程大学数字取证教育部工程研究中心,南京 210044;2.南京信息工程大学江苏省大气环境与装备技术协同创新中心,南京 210044;3.南京信息工程大学计算机学院,南京 210044
0 引言
近年来,数字媒体已经成为日常生活信息交流的主要形式,每天都会产生大量的图像不断扩大社交媒体网络(何沛松 等,2022)。在当今社会,即使没有经验的伪造者也可以借助用户友好型的图像编辑工具对照片进行任意修改,而不会留下太明显的篡改痕迹,如Photoshop(adobe photoshop)、CorelDraw(CorelDRAW graphics suite)等。其中图像拼接是最常见的图像篡改类型之一。它复制一幅或多幅源图像中的一块区域(往往包含一个目标)粘贴到另外一幅目标图像的某个位置,并在粘贴后对拼接区域采用模糊、平滑、润饰和融合等后处理操作来掩盖篡改痕迹,从而达到篡改图像内容的目的(张婧媛 等,2023)。图像拼接篡改的目的不少情况下是恶意的,如伪造司法证据、伪造银行电子票据、伪造虚假新闻等,这可能会导致严重的安全问题(Hadwiger 和Riess,2022;杨少聪 等,2022)。因此,有效地检测拼接伪造具有重要意义。
与复制—移动及修复等篡改方式仅需单源图像不同,图像拼接篡改通常涉及多幅图像。由于来源图像复杂,拼接篡改通常会引入一些痕迹,比如拼接区域与原始区域的相机噪声差异、光照差异、色彩差异和纹理差异等。因此,检测这些操作痕迹是图像拼接检测的关键(Jain 和Goel,2021)。现有的图像拼接伪造检测工作根据其特征提取方法,主要可分为两类:基于传统特征提取的检测方法和基于卷积神经网络的检测方法。前者主要利用相关技术提取上述痕迹中的一种或多种特征,但是这些特征容易在后续处理后(如压缩、变形、边缘软化、模糊和平滑等)变得难以检测。后者则依靠深度学习强大的特征学习能力获得了更好的性能(Chen 等,2021)。但是,利用卷积神经网络直接进行图像拼接检测时,往往倾向于学习图像的表征内容,容易忽略一些细微的拼接篡改痕迹(Rao 和Ni,2016)。因此,一些工作(Rao 和Ni,2016;Zhang 和Ni,2020)利用常用滤波器在检测前进行预处理,虽然也取得了较好的结果,但这些参数固定的滤波器仅能提取到固定滤波特征,没有考虑图像之间的差异,忽视了待检图像的个性化细节。
因此,本文以在图像分类领域获得卓越性能的EfficientNet(high-efficiency network)为骨干网络,通过由多次拼接及残差操作构建的自适应残差模块(adaptive residuals module,ARM)凸显拼接篡改痕迹,并使用通道注意力SE(squeeze and excitation)模块来减少由ARM 提取残差特征产生的通道之间的冗余,提出一种新的图像拼接检测算法。
1 相关工作
1.1 基于传统特征提取的图像拼接检测算法
基于传统特征提取的方法通常利用图像自身遗留的痕迹,其大致可以分为4类。
1)基于图像本质属性的检测方法(孙鹏 等,2017;Wang 等,2009)通常利用图像自身属性进行检测,例如色彩差异,纹理及边缘差异等。Wang 等人(2009)利用图像色度阈值边缘图像的灰度共生矩阵进行彩色图像拼接检测;孙鹏等人(2017)根据伪造图像中拼接区域与原始区域之间存在的色彩偏移量的差异,提出一种基于偏色估计的图像拼接检测算法。
2)基于成像设备属性的检测方法(Mahdian 和Saic,2008;张旭 等,2019)通常利用图像拍摄设备遗留的特征进行检测。Mahdian 和Saic(2008)利用拼接图像中的噪声不一致性进行检测;张旭等人(2019)使用光照的不一致性揭示图像篡改痕迹。
3)基于图像压缩属性的检测方法(Lin 等,2009;Ye 等,2007)通常关注图像经过压缩后的特有变化。Lin 等人(2009)针对JPEG(joint photographic experts group)图像通过检测隐藏在离散余弦变换系数中的双量化效应来检测篡改图像。
4)基于图像哈希技术的检测方法(Wang 等,2015;Yan 等,2016)通常将图像映射成二进制或数字指纹序列,然后观察序列间的差异进行检测。Yan 等人(2016)提出了一种基于四元数的图像哈希算法来检测图像篡改。
传统检测方法一般只关注某一特定的图像属性,因此在现实任务中算法泛化性有待提升。
1.2 基于卷积神经网络的图像拼接检测算法
卷积神经 网络(convolutional neural network,CNN)在计算机视觉的研究领域取得了很大的成功。CNN 强大的特征提取和映射也促使其应用于图像拼接伪造检测。基于卷积神经网络的方法大致可以分为两类:
1)直接利用高效分类网络进行检测(Nath 和Naskar,2021;张玉林等,2023)。Nath 和Naskar(2021)采用深度卷积残差网络架构作为主干,并与全连接的分类器网络结合,以实现真实图像和拼接图像的分类;张婧媛等人(2023)利用Transformer 进行图像拼接检测。
2)传统特征提取手段与卷积网络结合的方法(Abd El-Latif 等,2020;Pomari 等,2018;Rao 和Ni,2016)。该方法提取传统特征作为网络输入,如结合特殊富模型(special rich model,SRM)滤波器、成像设备属性等进行预处理。Rao 和Ni(2016)率先采用SRM 提取图像高频信息,然后将预处理后的图像输入深度卷积神经网络;Pomari 等人(2018)利用图像拍摄时遗留的光照不一致传统特征并结合卷积神经网络进行检测,获得了较好的结果;Abd El-Latif 等人(2020)提出了一种结合卷积神经网络和哈尔小波变换的算法。
与传统方法相比,基于卷积神经网络的方法获得了更好的检测性能。但是其更倾向于学习图像的表征内容,容易忽略细微的拼接篡改痕迹,检测结果有待进一步提升。
1.3 EfficientNet
本文以EfficientNet 作为骨干网络,该模型是由谷歌在ICML2019(Tan 和Le,2019)上提出。在Ima⁃geNet(ImageNet large scale visual recognition chal⁃lenge)分类问题中,EfficientNet 模型以66 M 的参数量取得84.4%的准确率,是现有较为先进的深度模型之一。与其他先进的模型不同,EfficientNet 很好地平衡了网络深度、宽度和分辨率,通过一种新的缩放方法来提高性能。这种方法可以获得简单而高效的复合系数。它还使用了新的激活函数sigmoid 线性单元(sigmoid weighted linear unit,SiLU),也称为Swish,以取代ReLU(rectified linear unit)来提高网络的准确性。
本文主要使用EfficientNetB0 模型作为整体算法构建的骨干。EfficientNetB0 网络的结构如图1 所示。该网络共分为9个模块,其中3 × 3或5 × 5表示深度可分离卷积(mobile inverted residual block,MBConv)的卷积核大小,每个MBConv后面都有一个乘数因子n(1 或6),代表MBConv 中的第1 个1×1 卷积层把输入特征矩阵的通道扩展n次。模块1 是一个普通的卷积层,其内核大小为3 × 3,模块2—模块8为图1(b)所示的MBConv的重复堆叠,模块9由一个普通的1 × 1 卷积、一个平均池化层和一个全连接层组成。值得注意的是,仅利用EfficientNet 进行图像拼接检测时(Ahmed 和Naskar,2021;朱新同 等,2021),难以学习到一些细微的拼接篡改痕迹,从而导致检测性能不能令人满意,故本文将该模型作为骨干模型进行改进。
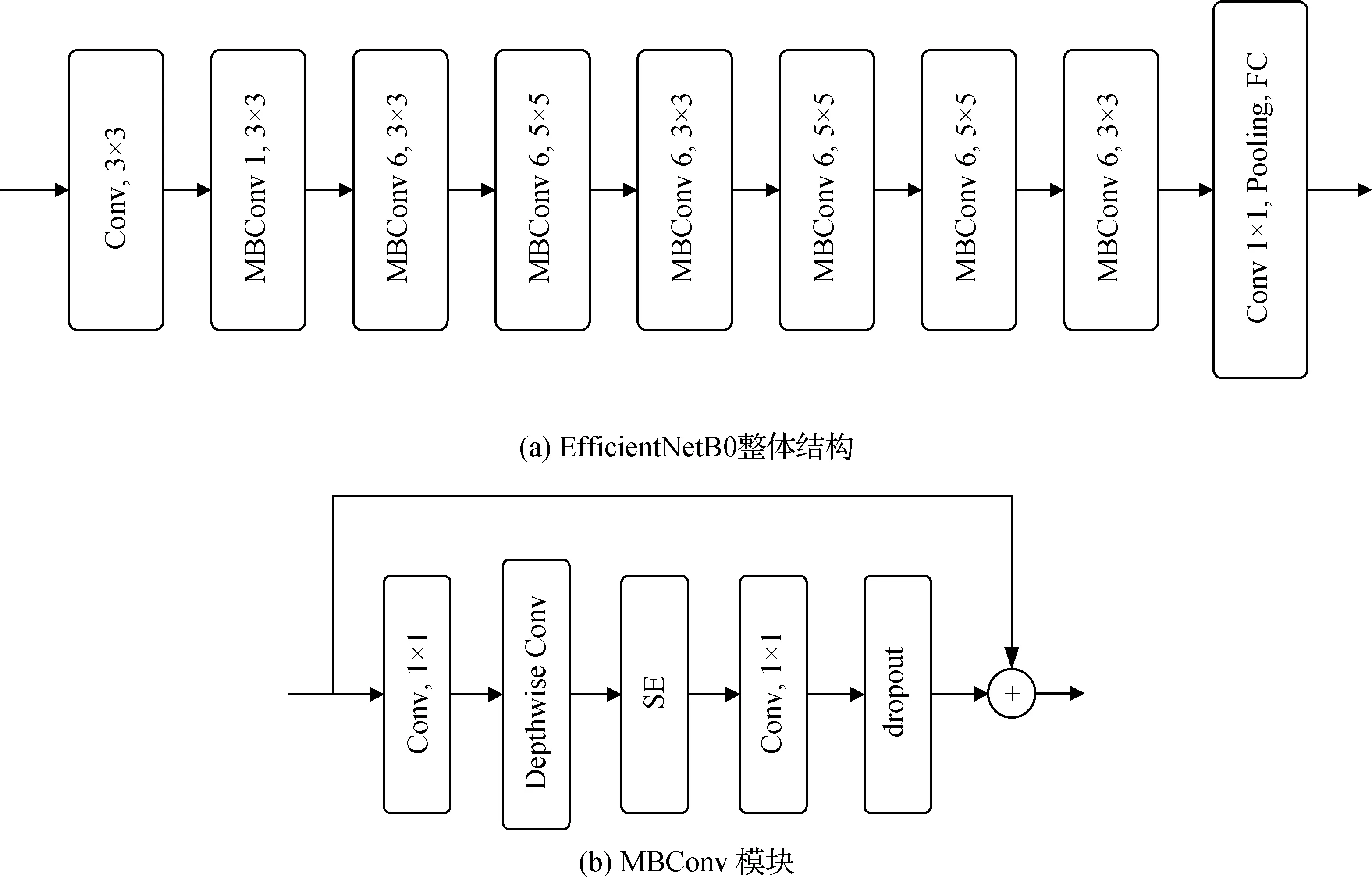
图1 EfficientNetB0 模型的体系结构Fig.1 Architecture of the EfficientNetB0 model((a)overview of the EfficientNetB0 model;(b)MBConv block)
2 提出算法
直接利用卷积神经网络进行图像拼接检测时,往往倾向于学习图像的表征内容,容易忽略细微的拼接篡改痕迹。先前的一些研究工作(Rao 和Ni,2016;Zhang 和Ni,2020;Zhao 等,2015)表明被篡改的图像包含特定的噪声特征,因此使用残差滤波器对输入图像进行预处理,如SRM(Rao 和Ni,2016)、结合相减像素邻接模型(subtractive pixel adjacency model,SPAM)的滤波器(Zhao 等,2015)。这些滤波器可以充分将图像边缘和轮廓信息保留,并抑制图像中一些不必要的细节,从而凸显篡改痕迹。但是,这些滤波器使用的参数固定,没有充分考虑到图像之间的差异,忽视了图像的个性化细节,从而影响了检测性能。因此,本文构建了一种面向图像拼接检测的自适应残差,在预处理阶段凸显拼接篡改痕迹,并基于此提出一种新的图像拼接检测算法。
2.1 算法整体框架
本文算法以EfficientNet 为骨干网络,设计ARM模块将图像进行预处理,引入通道注意力模块抑制因ARM 扩充图像通道数而产生的冗余信息,整体架构如图2 所示。在骨干网络EfficientNet 前添加ARM 模块及SE 模块以希望通过稳定的残差提取丰富的拼接篡改特征。图2(b)为ARM 模块的具体细节。
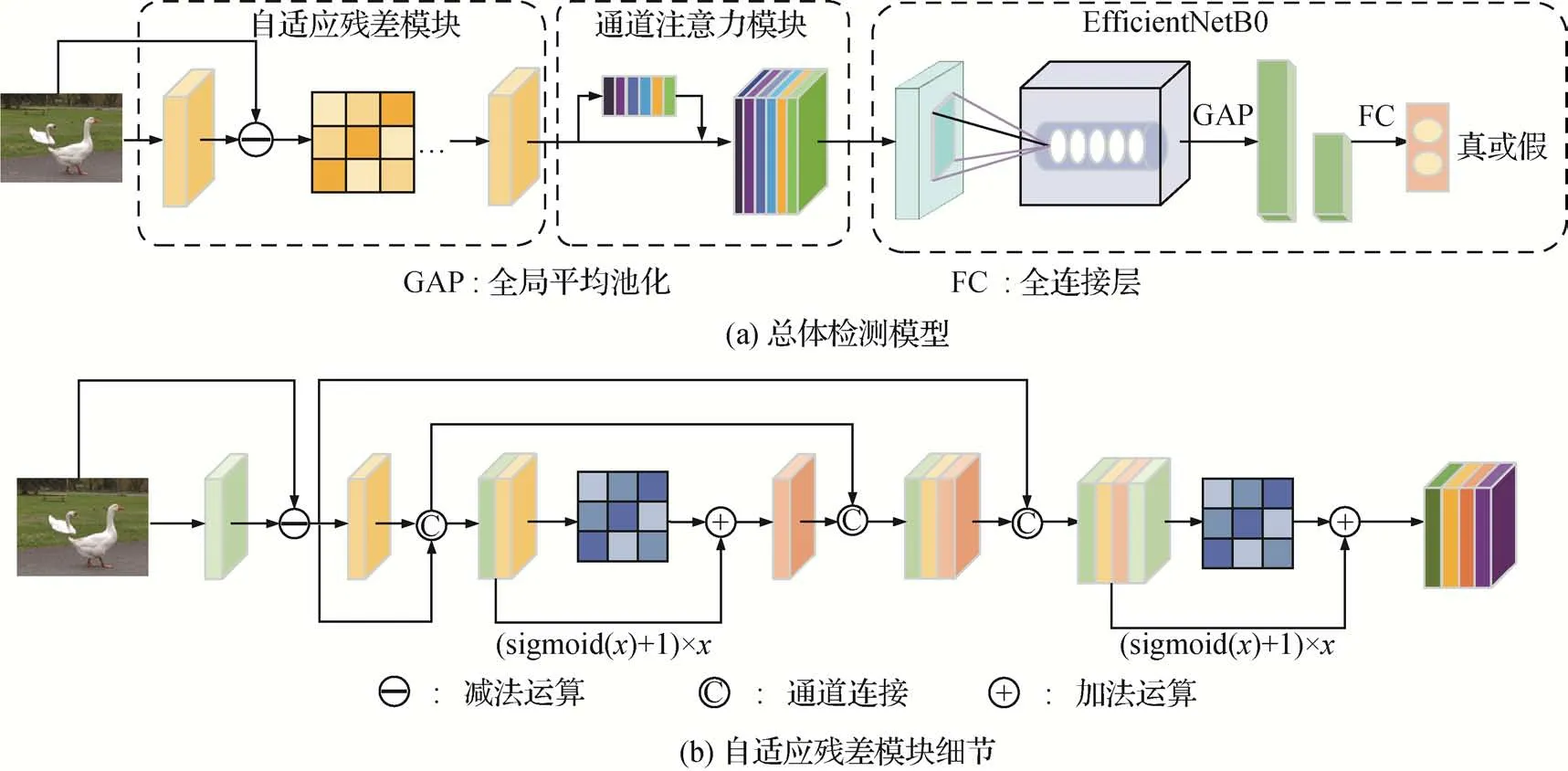
图2 基于自适应残差的图像拼接检测Fig.2 Image splicing detection algorithm based on adaptive residuals((a)overview of the proposed model;(b)details of the proposed ARM )
2.2 自适应残差提取模块
为了获得稳定有效的残差信息,ARM 借鉴了DenseNet(densely connected convolutional network)(Huang 等,2017)特征重用的思想,即通过多次拼接以获得稳定的残差。对初始获得的残差和经过卷积运算处理后的残差进行多次拼接,并且在每次拼接后再利用残差反馈中的注意力机制(Bi 等,2019)实现通道之间的非线性交互,以凸显未篡改区域和篡改区域之间的内在属性差异。与常见的滤波器使用固定参数不同,ARM 模块充分依赖残差的特征重用和注意力机制保留并放大拼接的细节,以达到更好的预处理结果。图3 展示了自适应残差与常见滤波器的可视化比较。从图3 可以发现,经过ARM 模块后的特征图更好地保留了拼接痕迹,放大了篡改区域与未篡改区域之间的差异。而其他滤波器无差别地提取了图像中几乎所有的纹理信息。例如,这两幅篡改图像的拼接区域为动物,对比的滤波器无差别地提取了纹理信息,包含山的边缘、栅栏等信息,而经过ARM 的特征图尽可能地弱化了真实区域的纹理信息,对拼接区域的动物纹理信息进行了凸显,从而引导后续的检测。

Fig.3 自适应残差与常见滤波可视化比较Fig.3 Comparison of adaptive residuals and common filtering visualizations((a)original images;(b)high pass filter;(c)SRM;(d)SPAM;(e)ARM)
ARM模块整体运算公式为
式中,fARM(·)代表自适应残差模块,θ是模块参数集合,I是输入图像,FARM为输出结果。
ARM 的具体细节如图2(b)所示。该模块首先通过一次卷积和减法,提取不稳定残差特征Fres为
式中,Fconv代表经过卷积运算后的结果。然后,再利用三次拼接和两次注意机制构建稳定的残差用于图像拼接检测。FARM详细运算结果为
式中,[,,…]代表n层特征图的拼接运算,fconv(·)代表卷积运算,fattention(·)代表注意力机制,Fi代表中间运算结果(i=1,2)。ARM 中涉及5 个卷积层,具体网络设置如表1所示。

表1 ARM模块网络设置Table 1 Network settings of the ARM modules
ARM 模块主要利用3 × 3 卷积核在不过度增加参数量的情况下提升模块获得拼接痕迹的表达能力。卷积核的网络设置与一些经典算法(Huang 等,2017;Tan 和Le,2019)类似。该模块的总参数量约占提出算法整体总参数量的万分之二,是一个即插即用的轻量级自适应特征提取模块。具体参数量和FLOPs(floating point operations per second)评估可见表2,表中FLOPs为浮点运算次数。

表2 两项改进措施以及提出算法的参数量和FLOPs统计Table 2 The statistics of parameters and FLOPs for the two improved measures and proposed algorithm
2.3 基于通道注意力的残差提取模块
ARM 对输入图像进行预处理,获得稳定的残差表示,但多次拼接操作容易在通道上生成冗余信息。因此,本文还添加了一个SE 模块(Hu 等,2018)来执行通道级注意力操作。SE模块整体运算公式为
式中,fSE(·)代表SE 模块,θ是模块参数集合,x是输入的特征,FSE是输出结果。该模块首先使用自适应平均池化生成全局空间的通道统计信息,然后采用带有sigmoid 激活函数的门控机制从通道依赖项中学习通道权重,最后,对原始特征信息进行重新校准,将每个特征映射与对应的通道权值相乘,关注具有关键信息的通道特征,抑制非必要信息,消除ARM 造成的冗余。SE 模块的具体参数设置如表3所示。与现有工作(Hu 等,2018)一致,SE 模块先利用全局自适应平均池化将ARM 的输入信息压缩为1 × 1 × 15 的向量,再使用全连接层进行降维和升维。

表3 SE模块网络设置Table3 Network settings of the SE modules
3 实验结果及分析
3.1 实验设置
3.1.1 实验数据
基于深度学习的检测方法往往依靠数据驱动。因此,本文基于COCO(common objects in context)数据集(Lin 等,2014),利用Photoshop 制作了8 万幅假图像。这8 万幅假图像与同样来自COCO 数据集的8 万幅真实图像相结合,用于预训练。为了进一步对提出方法进行实验分析,本文使用了5 个标准的公开数据集,即CASIA I(CASIA image tampering detection evaluation database)(Dong 等,2013),CASIA II(Dong 等,2013),COLUMBIA COLOR(Hsu和Chang,2006),NIST16(NIST special database 16 )和FaceForensic++(FF++)(Rossler 等,2019)。CASIA I,CASIA II和COLUMBIA COLOR数据集由普通图像组成,而FF++是人脸视频数据集。表4提供了这5个数据集的一些细节,图4展示了部分数据集样本。

图4 5个数据集样本举例Fig.4 Some samples from five used datasets
由于COLUMBIA COLOR 和CASIA I 数据集只包含拼接篡改,因此实验使用了这两个数据集的所有图像。如表4 所示,CASIA II 数据集中包含了多种篡改方式,如拼接和复制—移动,因此实验仅使用了1 828幅拼接篡改图像和2 000幅随机选择的真实图像。NIST16 数据集中包含拼接、复制—移动和删除3种篡改方式,因此实验仅使用了288幅拼接篡改图像。FF++数据集中包含4 种伪造方法,即Face2Face、FaceSwap、DeepFake 和Neural Textures。这4 种方法本质上都是将面部特征从源图像转移到目标面部图像,可以视为一种广义的图像拼接操作。该数据集将这4 种篡改方式应用于从YouTube 下载的1 000 个视频,以获得原始数据集。此外,每个视频都有原始的版本(RAW image format,RAW),以及两种不同的压缩级别,即C23 和C40。本实验从每个视频中以相等的间隔提取20 帧,然后采用Retina⁃Face 算法(Deng 等,2020)定位人脸区域,并将其调整为相同的大小。
为了加速模型收敛并实现有效的参数初始化,本实验将训练数据的分辨率调整为225 × 225 像素。与Nath 和Naskar(2021)的工作一样,对于4 个自然图像数据集,数据分别以8∶1∶1 的比例分割为训练集、验证集和测试集。对于FF++数据集,与Rossler等人(2019)的工作类似,将每种伪造方法的1 000个视频以720∶140∶140 的比例分割为训练集、验证集和测试集。此外,训练集在训练过程中通过旋转和翻转镜像进行数据增强。
3.1.2 评价指标
在实验分析中,本实验采用准确率(accuracy),精确率(precision)、召回率(recall)和F1 作为评价指标。
3.1.3 实验环境及训练细节
实验在一台Intel(R)Core(TM)i76900K CPU @3.20 GHz,62 GB RAM 和单个GPU(GTX 1080Ti)的机器上进行。网络优化器采用AdamW(adam with decoupled weight decay)算法。初始学习率设置为1.0E-4,训练的批大小为32,其他参数设置均使用PyTorch中的默认值。
在训练所提算法时,本实验采用常用的交叉熵损失作为损失函数。交叉熵损失函数表示为式中,N表示样本数量,K表示类别数量,pic表示第i个样本属于类别c的概率,yic∈{0,1}表示第i个样本标签是否为c,是为1,否则为0。所使用的4 个数据集的训练损失曲线如图5 所示。可以看出,该模型在前150个迭代内收敛良好。

图5 4个数据集的训练损失曲线Fig.5 Curves of training loss for the four used datasets
3.2 消融实验
为了验证对EfficientNetB0 模型的两项改进(ARM 和SE)的有效性,在CASIA II数据集上进行了消融实验,结果如表5 所示。可以看出,这两个额外的模块均提高了EfficientNetB0 的性能,尤其是ARM,其准确率提高了3.94%以上,精确率提高了3.10%以上,召回率提高了4.50%以上,F1 提高了3.81%以上。

表5 在CASIA II数据集上的消融实验结果Table 5 Results of ablation study on the CASIA II dataset/%
3.3 对比实验
在5 个通用自然数据集上,本实验比较了所提算法与其他算法(Abd El-Latif 等,2020;Guo 等,2021;Jalab 等,2022;Liu 等,2021;Nath 和Naskar,2021;Pomari 等,2018;Rao 和Ni,2016;Shang 等,2021;张婧媛 等,2023;Zhang 和Ni,2020)的检测结果。其中,FF++数据集包括3 个不同压缩级别的子数据集,即原始质量(RAW)、高质量(C23)和低质量(C40)。对比结果如表6 和表7 所示,其中对比算法的结果均来自其相应的原始论文。值得注意的是,由于部分参与对比的论文中仅展示检测准确率,故此处也仅展示准确率对比结果。
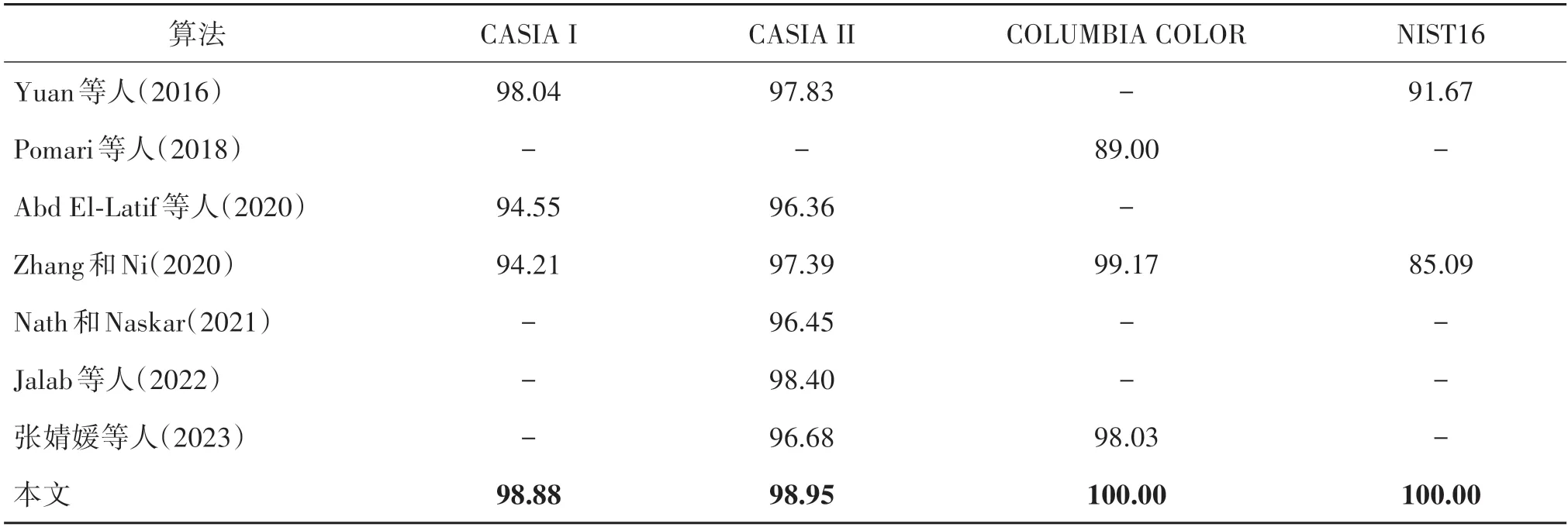
表6 不同算法在4个普通图像数据集上的检测准确率Table 6 Detection accuracy of different algorithms on four ordinary image datasets/%

表7 不同算法在人脸图像FF++数据集上的检测准确率Table 7 Detection accuracy of different algorithms on the face image FF++dataset/%
表6和表7的实验结果表明:1)提出算法在所使用的5 个数据集上的性能都明显优于其他算法;2)虽然FF++数据集除了拼接之外还包含其他类型的图像伪造,但提出算法仍然在4 个最近工作中获得了最好的性能;3)在表7 中,随着压缩强度的增大,所有对比算法的检测准确率都有所下降,而提出算法仍然优于其他算法。准确率下降的主要原因是FF++数据集中的视频进行了高压缩,导致篡改痕迹显著损失,难以检测。提出算法在表6和表7中较对比算法具有更好的性能,主要归功于EfficientNet 骨干网络和提出的两项改进,即ARM 和SE。Efficient⁃NetB0 是较为先进的通用图像分类模型之一,而ARM 专注于自适应学习图像伪造特定的残留特征。
此外,还将所提算法和EfficientNetB0 以及现有一些工作(Nath 和Naskar,2021;Rao 和Ni,2016;张婧媛 等,2023)在CASIA II 数据集上进行了时间复杂度对比。这4 个对比工作均为可在本地复现的近期工作,以减少耗时对比的环境误差。训练耗时统计的是单个轮次(epoch)的训练时间,测试耗时统计的是单幅图像在算法中的测试时间。结果如表8 所示。从表8 可以看出,所提算法无论是训练耗时还是测试耗时均比这些对比工作(Nath 和Naskar,2021;Rao和Ni,2016;张婧媛 等,2023)更短,主要原因是两项改进措施ARM 和SE,以及骨干网络Effi⁃cientNetB0 的参数量和算法复杂度都比较低;其次,从所提算法与其骨干网络EfficientNetB0 对比可以明显看出,ARM 和SE 对骨干网络的耗时影响很少,训练耗时增加了不足20 s,实际使用相关的测试耗时仅增加了0.001 s。
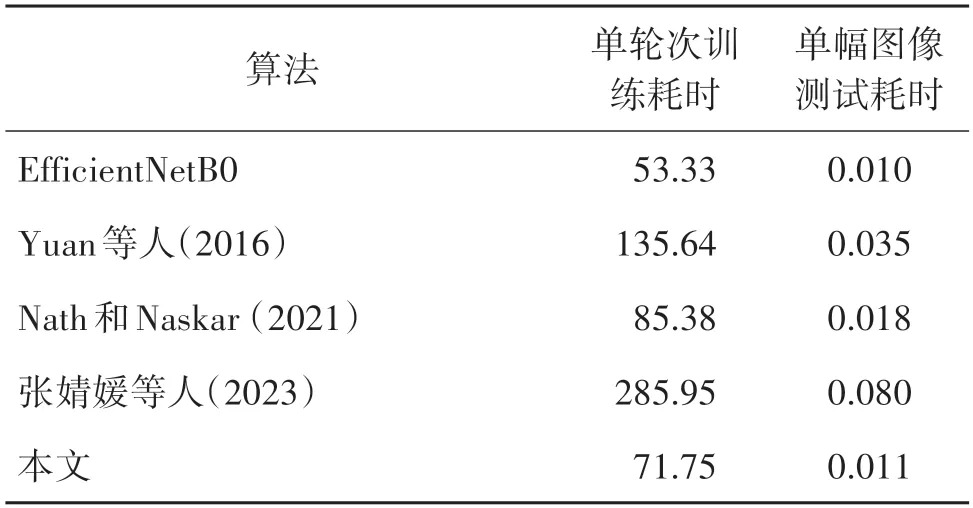
表8 不同算法在CASIA II数据集的训练和测试耗时对比Table 8 Comparison of training and testing time among different algorithms on the CASIA II dataset/s
4 结论
本文提出了一种基于ARM 的图像拼接检测算法。该算法以在图像分类领域获得卓越性能的Effi⁃cientNet 为骨干网络,设计了ARM 模块,将输入的拼接图像在网络中进行预处理以凸显未篡改区域和篡改区域图像的本质属性差异。此外,算法中使用SE模块抑制ARM 扩充图像通道数而产生的冗余信息。实验表明,所提算法在5 个公开数据集上均取得了更好的检测结果。设计的ARM 是一个即插即用的轻量级自适应特征提取模块,可以在其他模型上进行迁移,例如Xception,ResNet 等。此外,由于当前先进的算法(包括本文提出的算法)都专注于针对明文图像进行拼接检测,因此未来可考虑设计针对加密图像的拼接检测算法,以保护用户个人图像的隐私。
