基于幅度和相位混合特征交叉的语音增强方法
2024-02-22卿朝进付小伟唐书海
卿朝进,付小伟,唐书海
(西华大学 电气与电子信息学院,四川 成都 610039)
0 引 言
近年来,基于深度学习的语音增强方法[1-4],展示出了优于经典方法的语音增强效果[5-7]。然而,这些深度学习语音增强方法大都基于语音幅度信息构建神经网络架构,语音的相位信息并没有得以充分开发。事实上,语音的相位信息对语音质量和语音可懂度有较大的影响[8]。为此,本文从融合幅度与相位信息的视角出发,提出基于幅度和相位混合特征交叉的语音增强方法。首先,将含噪语音信号变换到时-频域,提取对数功率谱和相位特征。其次,将提取到的对数功率谱和相位依次交叉排列形成混合交叉特征。最后,为充分利用特征的帧间相关性,对得到的混合交叉特征进行特征扩张。特别地,本文将复数掩模(complex ideal ratiomask,cIRM)作为网络的学习目标,并将cIRM的实部和虚部依次交叉排列形成新的学习标签。在此基础上,本文基于幅度和相位混合交叉特征构建幅度相位深度编解码器网络(amplitude phase deep encoder decoder network,APDEDN),从而改善语音质量感知评估(perceptual evaluation of speech quality,PESQ)评分和短时目标可懂度(short time objective intelligibility,STOI)。PESQ为ITU-T(国际电信联盟电信标准化部)推荐的语音质量评价指标,得分区间为[-0.5,4.5],得分越高代表语音质量越好[9];STOI为短时可懂度与人类对语音可懂度的主观评价高度相关,得分区间为[0,1],得分越高代表语音可懂度越好[10]。

1 时频掩模语音增强系统模型
在单通道语音增强系统中,时域含噪语音信号y[k] 可表示为
y[k]=s[k]+n[k]
(1)
其中,s[k] 和n[k] 分别为时域干净信号和噪声信号,k表示为时域样本索引。时域含噪语音信号y[k] 经过短时傅里叶变换(short time fourier transform,STFT)后,其时-频域形式为
Yt,f=St,f+Nt,f
(2)
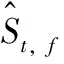
(3)
2 基于幅度和相位特征交叉的语音增强
本节详述基于幅度和相位特征交叉的语音增强方法。首先,在2.1小节展示混合特征提取过程。随后,在2.2节详述标签设计过程。最后,在2.3小节给出APDEDN网络。
2.1 混合特征提取
混合特征提取流程如图1所示。首先,利用STFT将时域含噪语音信号转换到频域,并根据频域含噪语音信号提取对数功率谱和相位特征。随后,将提取到的对数功率谱和相位依次交叉排列,形成混合交叉特征。最后,将混合交叉特征进行特征扩张,得到特征扩张后的特征矩阵。混合特征提取算法伪代码见表1。

表1 混合特征提取算法伪代码
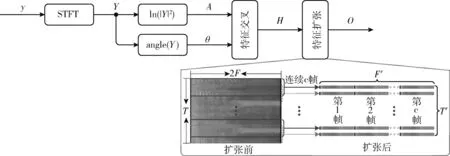
图1 特征提取
下面,详述混合特征提取过程。
(1)特征提取
长度为N的时域含噪语音信号y经STFT到时-频域,得到时-频域含噪语音信号Y∈T×F。 其中,T=N/Nr+1表示含噪语音信号在时域的帧数,Nr为滑动步长;F=(NSTFT/2)+1表示频点个数,NSTFT为STFT长度。Y∈T×F的第 (k,m) 的元素Y[k,m] 可表示为
(4)
其中,k=1,2,…,T,m=1,2,…,F;w(n) 为窗函数,Nr为滑动步长。当窗函数为汉明窗时,w(n) 可表示为
(5)
其中,Nl为窗长。为放大幅度谱特征,根据时-频域含噪语音信号Y计算对数能量谱A∈T×F, 其索引为 (k,m) 的元素可表示为
A[k,m]=log(|Y[k,m]|2)
(6)
根据时-频域含噪语音信号Y提取含噪信号相位θ∈T×F, 其索引为 (k,m) 的元素可表示为
θ[k,m]=arctan2(Re(Y[k,m]),Im(Y[k,m]))
(7)
(2)特征交叉
将对数能量谱和相位进行交叉处理,可得到混合交叉特征H∈T×2F, 表示为
(8)

(9)
(3)特征扩张
为充分利用时-频域信号的帧间相关性,根据文献[12]方法对混合交叉特征H进行特征扩张,得到特征扩张后的特征矩阵O∈T′×F′, 可表示为
(10)
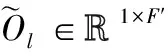
(11)


(12)
(4)特征交叉与特征扩张示例
对于给定特征扩张系数c, 帧数T和频点数F的含噪语音信号,其对数功率谱和相位经过特征交叉后,形成混合交叉特征H∈T×2F可表示为
(13)
特征扩张后的特征矩阵O∈T′×F′为
(14)
其中,T′=T-c+1,F′=2cF。
2.2 标签设计
在增强时域语音信号时,为降低采用含噪信号相位重构带来的影响,本文采用cIRM作为网络学习的目标,标签设计流程如图2所示。根据设计流程,计算cIRM、压缩复数掩模并对cIRM进行实部和虚部交叉。

图2 标签处理流程
(1)cIRM计算
含噪语音信号y和干净语音信号s∈N×1经过STFT后得到Y和S∈T×F, 将Y和S按实虚部展开获得维度均为T×F的实数矩阵:Yr=Re(Y),Yi=Im(Y),Sr=Re(S),Si=Im(S); 根据Y和S计算时-频域复数掩模M∈T×F。
将S[k,m]=M[k,m]Y[k,m] 展开后可分别计算出复数掩模的实部Mr∈T×F和虚部Mi∈T×F, cIRM的具体推导过程详见文献[13],有
(15)
(2)复数掩模压缩
为提高网络的收敛能力,根据文献[13]的方法,对Mr和Mi进行压缩。压缩复数掩模的实部或虚部Rx∈T×F可表示为
(16)
其中,下标x代表r或i; 压缩复数掩模实部或虚部Rx∈[-K,K];C为压缩系数,控制着曲线的陡峭程度。
(3)cIRM实部和虚部交叉

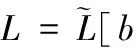
(17)
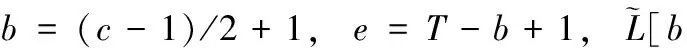
对于给定的特征扩张系数c、帧数T和频点数F, 计算得到的交叉压缩cIRM矩阵L∈T′×2F可表示为
(18)
其中,b=(c-1)/2+1,e=T-b+1。 最后,对标签设计算法流程进行总结,见表2。

表2 标签设计算法伪代码
2.3 APDEDN网络
(1)网络架构
APDEDN由输入层、编码器、LSTM层、解码器,以及输出层组成。其中,编码器和解码器分别由3个不同维度的子编码器和子解码器组成。APDEDN具体架构如图3所示。
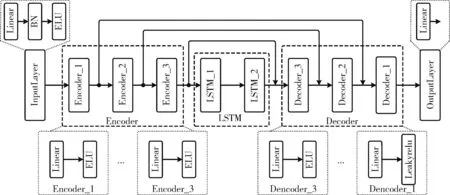
图3 APDEDN架构
输入层由BN、ELU和线性激活组成,将一帧语音信号转换到编码器所需的输入维度。输出层采用线性激活。编码器提取语音信号特征,两层LSTM则对输入信号在时间轴方向上的建模以捕获语音信号时间上的相关性,解码器为编码器的逆操作,以还原降噪后的语音信号。APDEDN的一个实施实例的各层参数见表3。
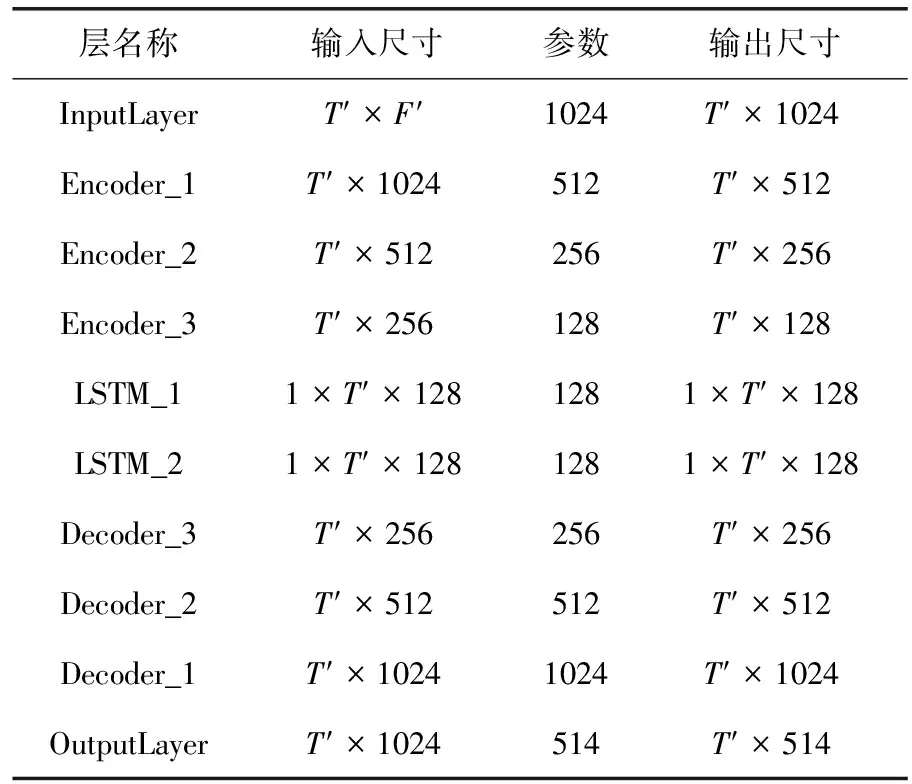
表3 APDEDN参数示例
(2)网络离线训练
1)数据集生成
训练和测试所用的干净语音信号均来自于TIMIT数据集,该数据集分为训练集和测试集两部分。TIMIT数据集是记录8个不同区域的630名说话人(男性438名,女性192名)特定语句的语音集合。训练所用的干净语音信号从TIMIT训练集中的8个区域中随机选择380句干净语音信号,测试所用干净语音信号从TIMIT测试集中随机选择10句。训练和测试所用的噪声数据集来自NOISEX-92数据库,选择其中的6种噪声(Babble,Buccaneer,Factory,Destoryerengine,Volvo,White)。
将上述的训练和测试所用干净语音信号和6种噪声在6种不同信噪比(SNR,Signal-to-Noise Ratio){-5,0,5,10,15,20} dB条件下叠加,最终可得到13 680句的训练集和360句测试集。
根据收集到的含噪和干净语音信号集合 {y,s}, 并按式(4)~式(7)计算相应的训练样本集合 {O,L}。
2)训练参数设置
取短时傅里叶变换长度NSTFT=512,F=(NSTFT/2)+1=257, 窗长Nl=512, 窗移Nr=128; 计算cIRM时,根据文献[13]常数K取值为K=10, 压缩系数C=0.1; Batchsize取值为32,学习率取值为lr=10-4, 优化器为Adam[14]参数为默认参数。
3)模型训练
根据训练样本集合 {O,L}, 将扩张后的特征O输入到APDEDN网络中训练,训练的损失函数为均方误差损失函数,可表示为
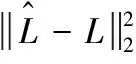
(19)
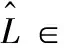
(3)网络在线运行
根据含噪语音信号y, 按式(4)~式(12)计算扩张后的特征O∈T′×F′; 将扩张后的特征O输入已训练的APDEDN网络得到估计交叉压缩复数掩模根据得到估计压缩复数掩模实部T′×F和估计压缩复数掩模虚部T′×F, 可分别表示为
(20)
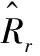
(21)

(22)

3 实验仿真
本文采用PESQ和STOI对提出方法的有效性进行验证。对比基线选择文献[4]中的cIRM语音增强方法,文献[16]中编解码器网络架构幅度谱映射方法和文献[17]基于理想比值掩模的深度语音增强方法。
为简化表达,本文采用“文献[4]”,“文献[16]”和“文献[17]”分别表示文献[4]中的基于cIRM语音增强的方法,文献[16]中的基于编解码器网络架构幅度谱映射方法和文献[17]基于理想比值掩模的深度语音增强方法。“Prop_1”和“Prop_2”表示提出的幅度和相位混合特征的语音增强方法(其中,“Prop_2”表示特征幅度和相位交叉,标签cIRM进行实部和虚部交叉;“Prop_1”表示特征先放置幅度后放置相位,标签cIRM先放置实部后放置虚部)。训练过程中本文采用方法和对比文献方法训练损失收敛曲线图,如图4所示。

图4 训练损失收敛曲线
表5和表6分别给出了提出方法与对比基线方法的PESQ评分和STOI。其中,NSTFT=512,F=(NSTFT/2)+1=257, 窗长Nl=512, 窗移Nr=128。 根据文献[15],“文献[4]”,“文献[16]”,“文献[17]”,“Prop_1”和“Prop_2”方法的特征扩张系数取值为c=3, 即“文献[4]”,“献[16]”,“文献[17]”,“Prop_1”和“Prop_2”方法中APDEDN的输入层节点数F′=2cF=2×3×257=1542。
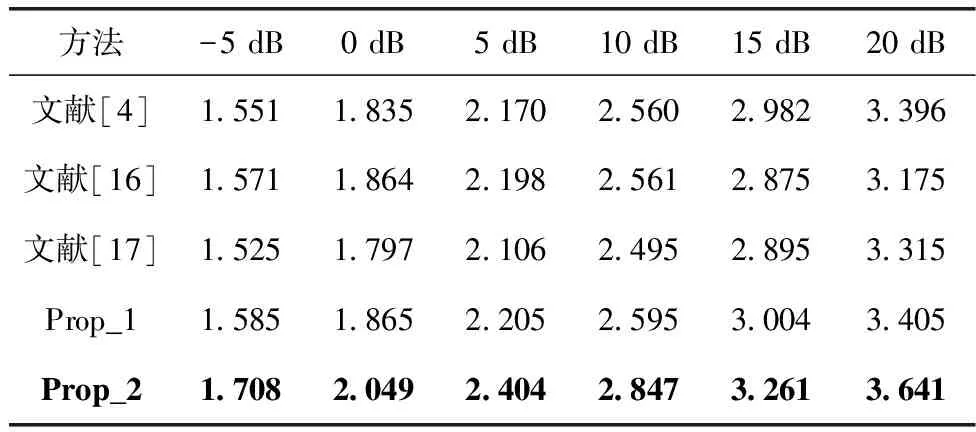
表5 PESQ评分测试结果(F′=1542)

表6 STOI测试结果(F′=1542)
相对于“文献[4]”,“文献[16]”方法和“文献[17]”,从表5和表6分析可知:
(1)在PESQ评分上,提出的幅度和相位混合特征交叉语音增强方法“Prop_1”和“Prop_2”的PESQ评分性能优于单一特征方法。在PESQ评分方面,“Prop_1”和“Prop_2”相对于“文献[4]”,“文献[16]”方法和“文献[17]”,在各个给定的信噪比下,均获得了更高的PESQ评分。例如,当SNR=15 dB时,“Prop_1”和“Prop_2”方法的PESQ评分分别为3.004和3.261,而“文献[4]”,“文献[16]”方法和“文献[17]”方法PESQ评分分别为2.982,2.875和2.895。特别地,在各个给定的SNR下,“Prop_2”均获得了最大的PESQ评分值。相对于对于“文献[4]”,“文献[16]”方法和“文献[17]”方法,提出方法“Prop_1”和“Prop_2”提高了PESQ评分。此外,在各个给定的SNR下,“Prop_2”均能获得最高的PESQ评分,含噪语音的幅度和相位交叉,以及学习标签实部和虚部交叉带来了更好的特征抽取性能。由此可见,幅度和相位特征混合,不但能更好地捕获幅度特征信息,更有助于开发到不同维度的语音和噪声相位特征信息,从而也更为有效地增强了语音的感知质量。
(2)在STOI性能方面,提出方法“Prop_2”优于“文献[4]”,“文献[16]”方法和“文献[17]”方法。在各给定的SNR下,“Prop_2”均获得了最大的STOI值。例如,当SNR=10时,“Prop_2”方法的STOI值为0.882,而对于“文献[4]”,“文献[16]”方法和“文献[17]”方法STOI值分别0.856和0.829和0.864。在SNR={-5,0,5} 处,“Prop_1”的STOI值略低于“文献[4]”和“文献[16]”方法;除此之外,相对于“文献[4]”和“文献[16]”方法,“Prop_1”均获得了更大的STOI值。由此可见,提出方法“Prop_1”和“Prop_2”较为有效地提高了语音的STOI。特别地,对含噪语音的幅度和相位交叉,标签cIRM进行实部和虚部交叉,也即是“Prop_2”方法,特别有助于改善STOI性能。因此,本文提出的幅度和相位特征混合,在增强语音的可懂度上是有效的。
(3)“Prop_2”方法PESQ评分和STOI性能优于“Prop_1”方法。幅度和相位特征交叉且cIRM实虚部交叉方法(即“Prop_2”)在语音增强性能PESQ评分和STOI方面优于幅度和相位不交叉且cIRM实虚部不交叉方法“Prop_1”。如,在SNR=5 dB处,“Prop_2”方法的PESQ评分和STOI值分别为2.404和0.825;而“Prop_1”方法PESQ评分和STOI值分别为2.205和0.791。“Prop_2”方法无论是PESQ评分还是STOI值均能在各给定的SNR下获得最大值(最好性能)。因此,本文提出的幅度和相位交叉排列,更能充分利用含噪语音信号的特征以及特征之间的相关性与统计特性。除幅度特征外,本文还开发了语音信号的相位特征,从而更能有效地提高语音的感知和可懂度质量。
此外,我们增大了对于“文献[4]”,“文献[16]”方法和“文献[17]”方法中的APDEDN输入节点数,验证提出网络可以更为轻型化。保持“Prop_1”和“Prop_2”方法的APDEDN输入节点数为F′=1542, 而对于“文献[4]”,“文献[16]”方法和“文献[17]”方法中的APDEDN输入节点数为F′=1799。 PESQ评分和STOI值分别在表7和表8中给出。

表7 PESQ评分测试结果

表8 STOI测试结果
从表7和表8的测试结果中可以看出,即使“文献[4]”,“文献[16]”方法和“文献[17]”方法的APDEDN网络输入层节点数增大到F′=1799,提出方法“Prop_1”和“Prop_2”在保持网络输入为F′=1542时仍能获得相当或更好的语音增强性能。如,当SNR=0 dB时,“Prop_1”和“Prop_2”的PESQ评分分别为1.865和2.049,而“文献[4]”,“文献[16]”方法和“文献[17]”的PESQ评分分别为1.995和1.869和1.831。特别地,提出方法“Prop_2”在各给定的SNR下仍然获得了最大的PESQ评分和STOI测试值。由此可见,提出方法“Prop_1”和“Prop_2”能在F′=1542情况下(更小的网络输入)获得“文献[4]”、“文献[16]”方法和“文献[17]”方法F′=1799时相当或更好的语音增强质量(PESQ评分和STOI值)。因此,提出方法在保持相当的语音质量的情况下,由于抽取到了语音的交叉特征,可使语音增强网络更加轻量化。
4 结束语
本文从融合幅度与相位信息的视角出发,提出一种基于幅度和相位特征交叉的语音增强方法。本文提出方法旨在充分利用含噪语音信号的相位信息及其与幅度信息之间的相关性。实验结果表明,提出的混合特征交叉方法语音增强性能优于单一特征方法且能在网络具有更少输入节点的情况下,保持相当或更好的语音质量和可懂度。此外,幅度和相位交叉排列能充分利用幅度和相位之间的相关性,有助于进一步提高语音质量。
