混沌自适应非洲秃鹫优化算法训练多层感知器
2024-02-22申晋祥鲍美英张景安周建慧
申晋祥,鲍美英,张景安,周建慧
(1.山西大同大学 计算机与网络工程学院,山西 大同 037009;2.山西大同大学 网络信息中心,山西 大同 037009)
0 引 言
神经网络是目前的研究热点,可以处理科学和工程领域的许多问题。多层感知器(multi-layer perceptron,MLP)是前馈神经网络的一种,目前应用广泛,在许多实际问题,如数据分类、预测和函数近似等方面都有应用。早期训练MLP参数的算法具有收敛速度慢和局部极值停滞的缺陷,研究发现启发式算法在训练MLP的参数时,不易陷入局部极小值且收敛速度快。目前,已经有许多启发式算法[1-13]用于训练MLP。
本文将混沌映射和自适应权重系数引入非洲秃鹫优化算法,提出改进算法IAVOA并用于对MLP的连接权重和偏差进行训练,训练好的MLP用于4个数据集XOR、Baloon、Cancer和Heart的分类。为验证IAVOA算法的有效性,与其它6种元启发算法训练MLP进行了比较。
1 非洲秃鹫优化算法
非洲秃鹫优化算法(African vultures optimization algorithm,AVOA)[14]是2021年提出的群智能优化算法,AVOA的数学模型如下:
(1)秃鹫种群分组
(1)
(2)
(2)秃鹫的饱食率
AVOA算法根据秃鹫的饱食率F进行勘探和开发的转化,数学公式如式(3)和式(4)
gt=ht×(sinω(πt/2T)+cos(πt/2T)-1)
(3)
(4)
其中,rd1、z和h分别是随机数,ω是开发概率,设置为2.5。T是最大迭代次数,t是当前迭代次数。
(3)秃鹫的勘探阶段
当 |F| 大于等于1时,秃鹫进行勘探,如式(5),勘探阶段有两种勘探方式
(5)
(6)
其中,P是秃鹫的位置,C是随机移动位置,C∈[0,2] 区间,c1是勘探概率随机数,范围[0,1],rd2、rd3、rdc1是随机数,ub和lb分别是搜索空间的上下界。
(4)秃鹫的开发阶段
当 |F| 小于1,秃鹫进行开发,分为两个阶段,每个阶段使用两种不同的策略。开发中期,由c2确定秃鹫执行攻击策略或盘旋飞行策略,公式如式(7)。开发后期,由c3确定秃鹫执行攻击策略或聚集策略,公式如式(10)
(7)
(8)
(9)
(10)
(11)
AVOA算法开发阶段增加了勘探功能,勘探阶段也具有开发功能,收敛速度快且不易陷入局部最优[15]。
2 改进的秃鹫优化算法
AVOA算法具有优点,该算法引入的随机数较多,根据不同的随机数区分勘探方式,以及选择不同的开发阶段。但AVOA也具有缺点,算法随机初始化种群,导致种群多样性不足,对收敛速度和全局最优解产生不利影响。AVOA有明确的勘探和开发阶段,开发阶段分为开发中期和开发后期两个阶段,通过随机数划分秃鹫的两种行为,聚集行为和攻击行为。聚集行为中认为最优秃鹫和次优秃鹫对其它秃鹫的引导作用是一样的,但这样无法平衡算法的勘探和开发能力。
针对AVOA的缺陷,本文提出改进的秃鹫优化算法(improved African vultures optimization algorithm,IAVOA),从两个方面对AVOA算法进行改进:①为了使IAVOA在优化阶段有更强的全局勘探能力,种群初始化阶段引入Logistic混沌映射;②设计了自适应系数,调整最优秃鹫和次优秃鹫对普通秃鹫的影响,保证勘探和开发的平衡。
2.1 Logistic混沌映射初始化种群
AVOA随机初始化种群,混沌映射生成的种群比随机生成的种群多样性更好,解均匀分布在空间中的各个位置,可以提升勘探能力,避免陷入局部最优解且收敛精度高。Logistic混沌映射产生的混沌序列位于[0,1]区间内,该混沌序列更均匀,公式如式(12)
xn+1=4xn(1-xn)xn∈(0,1),n=1,2,…
(12)
把上式生成的混沌序列转化到种群解空间,秃鹫的初始位置由式(13)计算
Xi=lb+(ub-lb)xn
(13)
其中,ub和lb是种群解空间的上下界。
Logistic混沌映射和随机初始化种群分布如图1所示。

图1 随机初始化和混沌初始化对比
对比图1(a)和图1(b),可以发现在[0,1]区间,Logistic混沌映射生成的数比随机生成的数分布更均匀,遍历性更好。
2.2 自适应权重系数
秃鹫的位置更新主要受到最优秃鹫和次优秃鹫的位置、秃鹫饱食率的影响。 |F| 的值越大,越有利于算法的勘探,值越小,越有利于算法的开发。 |F|≥1时,秃鹫处于勘探阶段,|F|<1时,处于开发阶段,开发以0.5为界限分为开发中期和后期两个阶段,[0.5,1)之间是开发中期阶段,开发中期根据随机数分为聚集行为和盘旋飞行行为,式(7)描述这两种行为;[0,0.5)是开发后期,根据概率随机数分为聚集行为和攻击行为,秃鹫位置更新采用式(10),在开发后期的聚集行为中,认为最优秃鹫和次优秃鹫对其它秃鹫的影响是一样的,然而,在开发后期,为了快速并准确收敛到最优解,最优秃鹫和次优秃鹫对普通秃鹫位置的影响效果是不一样的,应该区别对待,这里,对开发后期秃鹫位置的更新进行改进,设置两个自适应权重系数,分别控制最优秃鹫和次优秃鹫,随着迭代的增加,最优秃鹫的引导作用逐渐增强,而次优秃鹫的引导作用逐渐减弱,秃鹫尽快向最优解收敛,提高算法收敛速度,增强算法局部开发的能力,改进公式如式(14)
(14)
ω1=2×e-[2×(T-t)/T]
(15)
ω2=2×e-[2×t/T]
(16)
其中,ω1和ω2分别是最优秃鹫和次优秃鹫的自适应权重系数,变化情况如图2所示,t是当前迭代次数,T是最大迭代次数。
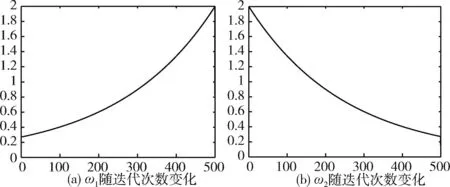
图2 自适应权重系数曲线
2.3 IAVOA算法实现
增加Logistic混沌映射和自适应权重系数,IAVOA算法步骤如下:
步骤1 初始化操作。设置算法初始参数,种群规模N, 搜索空间维度D, 最大迭代次数T, 搜索空间上界ub和下界lb等;使用Logistic混沌映射初始化每只秃鹫的位置Pi(i=1,2,…,N)。




步骤8 根据搜索空间的上下界ub和lb修正越界的秃鹫的位置。
步骤9 若迭代终止条件不满足,则跳转到步骤2。
步骤10 输出最优秃鹫。
3 IAVOA训练MLP
通过元启发式算法训练MLP有3种方法:①MLP的结构固定,通过训练算法寻找MLP的最优权重和偏差的组合,使用最优参数组合的MLP的总体误差最小;②使用启发式算法调整梯度学习算法的参数,如动量和学习速度;③寻找MLP的最优结构。可以改变神经元之间的连接、隐藏层的数量和隐藏层中的节点数,最优结构通过训练算法找出。
本文采用第一种方法训练MLP,结构固定,通过IAVOA算法训练MLP的权重和偏差,找出参数的最优值,提高MLP的精度。首先要对权重和偏差进行编码,采用向量编码,种群个体是一个向量,表示MLP的所有权重和偏差。向量编码方式编码比较容易,但解码复杂。以图3为例,MLP的结构为4-9-3,其中输入层节点为4个,隐藏层节点为9个,输出层节点为3个,该MLP的向量编码方案如下。
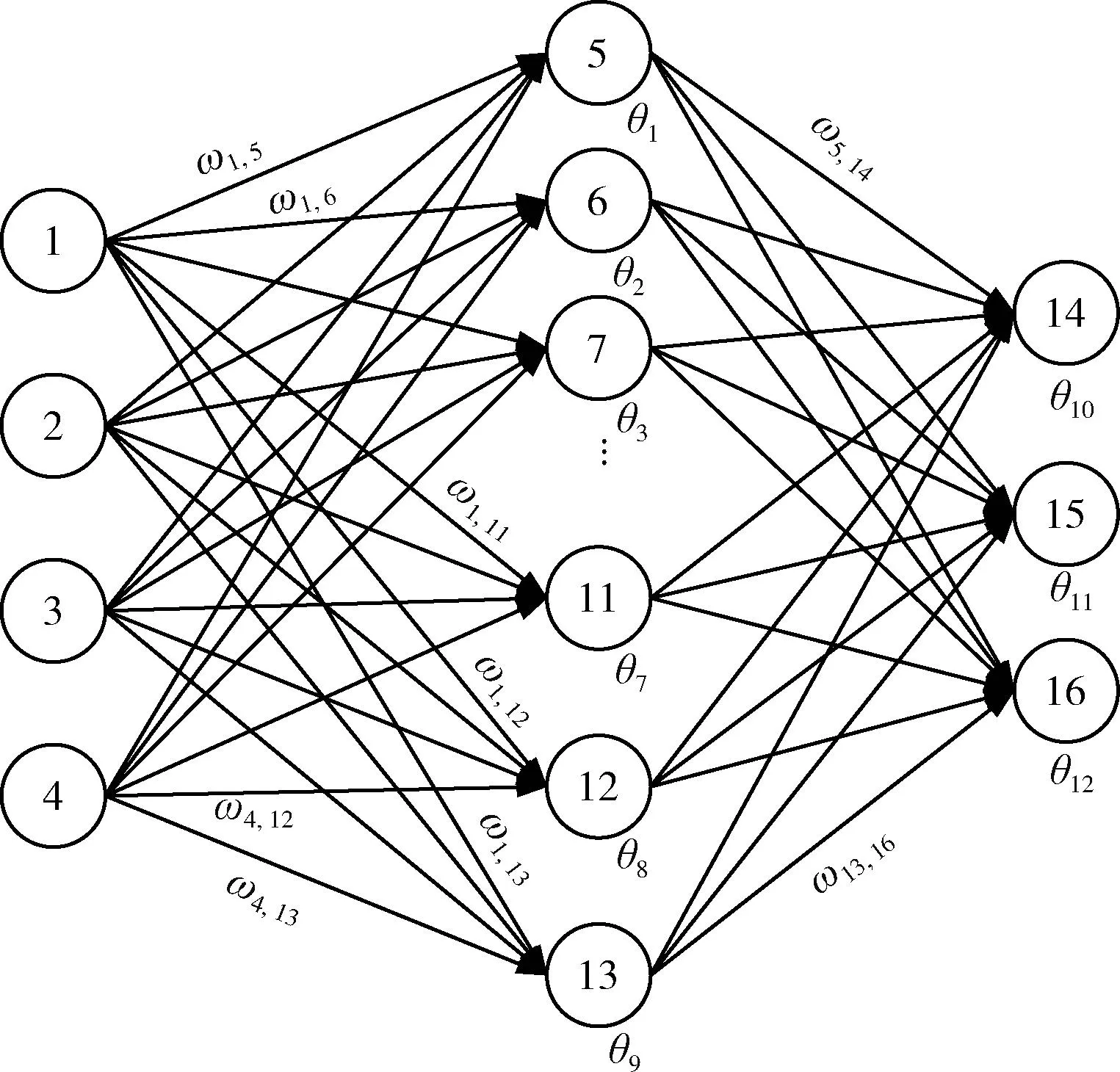
图3 多层感知器(4-9-3)
式(17)是权重和偏差的向量编码

ω13,16,θ1,θ2,…,θ12}
(17)
ωij表示第i个节点到第j个节点的连接权重,θj是节点的偏差。
同样以结构为4-9-3的MLP为例,给出向量编码方式的解码过程,伪代码如下。
//初始化设置。初始化隐藏层和输出层的向量h和o
//隐藏层节点数Hn,输出层节点数On,k←On
//激活函数S(x)
(1)fori←1toHndo
(2)h(i)←S(x1*ω(i)+x2*ω(Hn+i)+x3*ω(2*Hn+i)+x4*ω(3*Hn+i)+θ(i));
(3)fori←1toOndo
(4)k←k+1;
(5)forj←1toOndo
(6)o(i)←o(i)+(h(j)*ω(k*Hn+j));
(7)fori←1toOndo
(8)o(i)←S(o(i)+θ(Hn+i));
其中,xi是输入节点,θ(i) 是节点的偏差,ω(i) 是节点之间的连接权重。
IAVOA训练MLP的适应度函数如式(18)所示
最小值:
F(Vul)=Average(MSE)
(18)
(19)
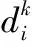
IAVOA训练MLP的流程如图4所示。
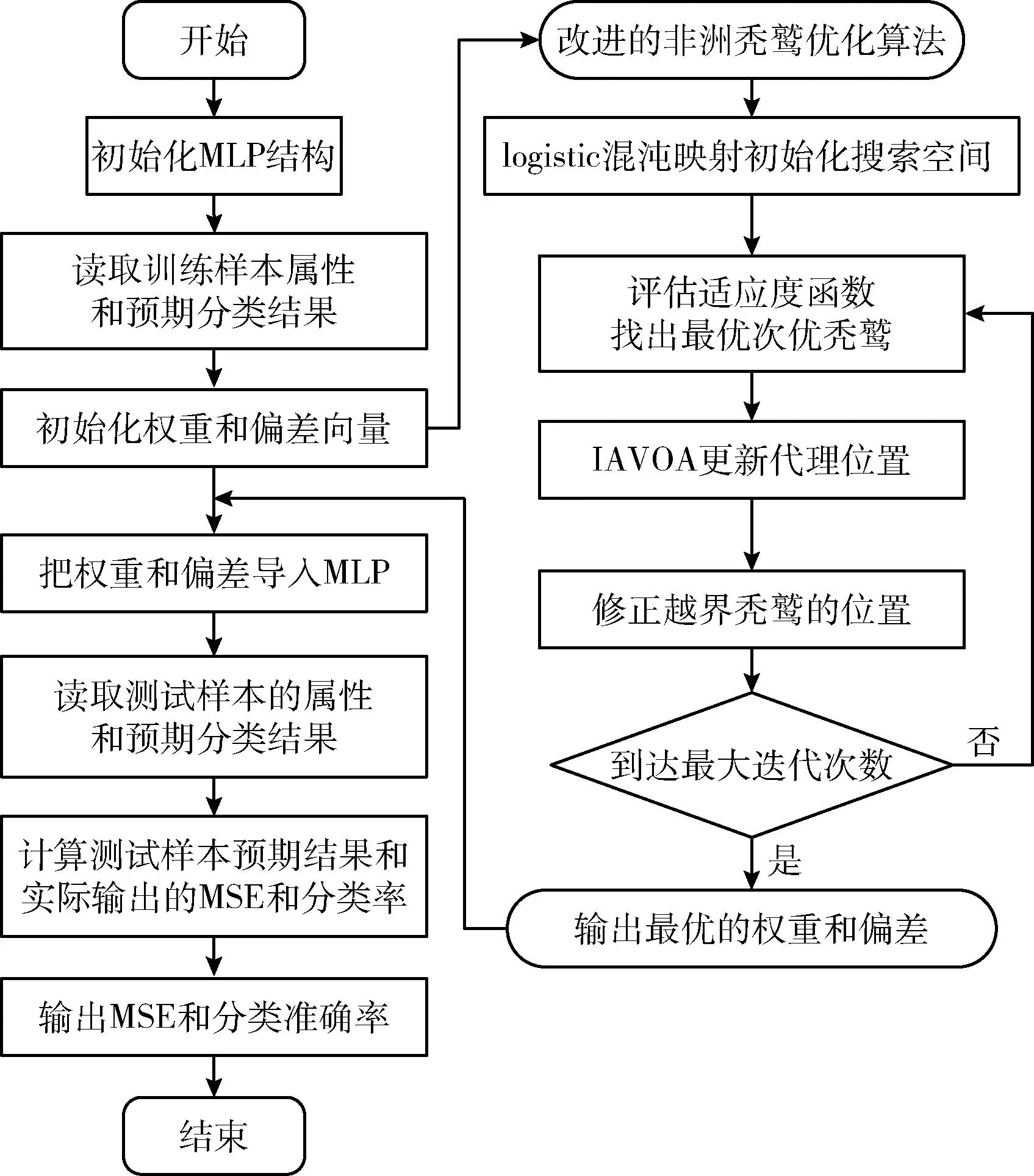
图4 IAVOA算法训练多层感知器
4 结果和讨论
为了研究IAVOA算法的性能,本文采用UCI数据集合中的4个分类数据集异或(XOR)、气球(Baloon)、心脏(Heart)和癌症(Cancer)数据集来测试IAVOA算法的改进效果。
4.1 实验设置和数据集
IAVOA算法与6种启发式算法进行比较,其中包括GSA、BBO、DE、ACO、SSA和AVOA。比较算法所采用的参数均采用原算法的默认值。GSA中精英检查为1,代理之间的距离指数为1;ACO中初始信息素为1E-06,探索常数是1,信息素更新常数是20,局部信息素衰减率0.5,全局信息素衰减率0.9,信息素敏感度是1;DE中缩放因子下界0.2,上界0.8,交叉概率0.8;BBO中突变概率0.005,迁移概率0~1,步长是2,最大迁出率和迁入率均为1。所有算法种群大小设置为50,最大迭代次数设置为500。
表1中给出采用的分类数据集的信息,包含数据名称、属性(属性个数作为MLP的输入个数),训练样本和测试样本,数据集均为二分类数据,表中也给出了MLP的结构,输入层-隐藏层-输出层。MLP结构中隐藏节点h的数量通过式(20)计算得出,n是输入节点的数量随着MLP的规模越来越大,它的权重和偏差也会越来越多,MLP的训练过程会变得复杂,训练时间增加,并且可能找不到合适的权重和偏差。
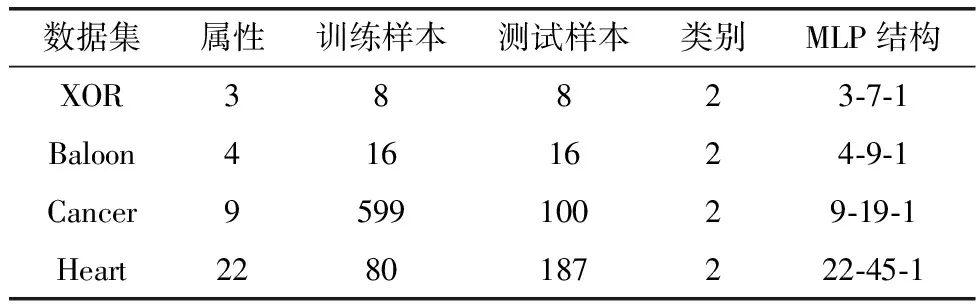
表1 用于分类的UCI存储库数据集
h=2×n+1
(20)
所有算法在数据集上分别独立运行10次,取结果的最大值、最小值、平均值、标准偏差和分类准确率进行比较。分类率表示各个算法训练的MLP对数据分类的准确率,从运行结果中选择参数最优的MLP,对测试样本分类。
4.2 分类问题
分类数据集选择不同的复杂度,数据集的特征由少到多,如果特征太多,启发式算法对数据集分类的难度相应增加,对于太复杂的MLP,启发式算法很难找到正确的权重和偏差值。表1是本文选择的分类数据集的详细情况,XOR数据集是最简单的分类数据集,它的训练样本和测试样本最少,都是8个。Baloon数据集也相对简单,训练样本和测试样本都为16个。Heart数据集最复杂,包含属性22个,测试样本187个,该数据集在进行分类时难度较大。Cancer数据集的训练样本和测试样本较多。不同算法在不同数据集上的运行结果见表2~表5。不同算法在数据集上的均方误差收敛曲线如图5所示。
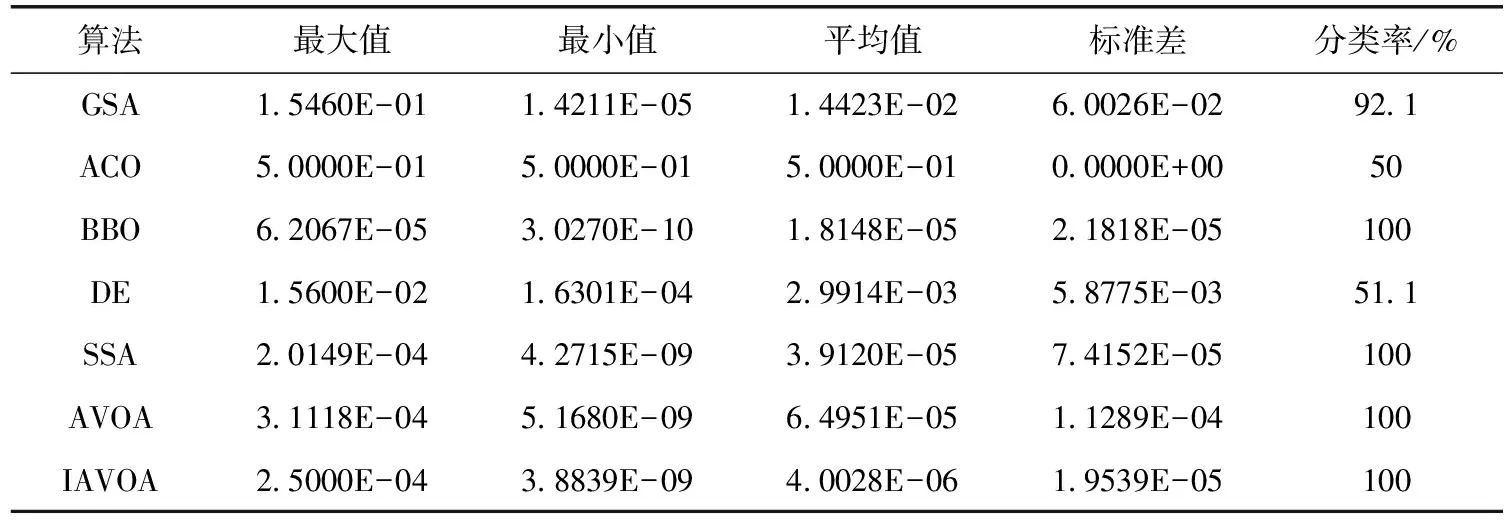
表2 算法在XOR数据集上的仿真结果
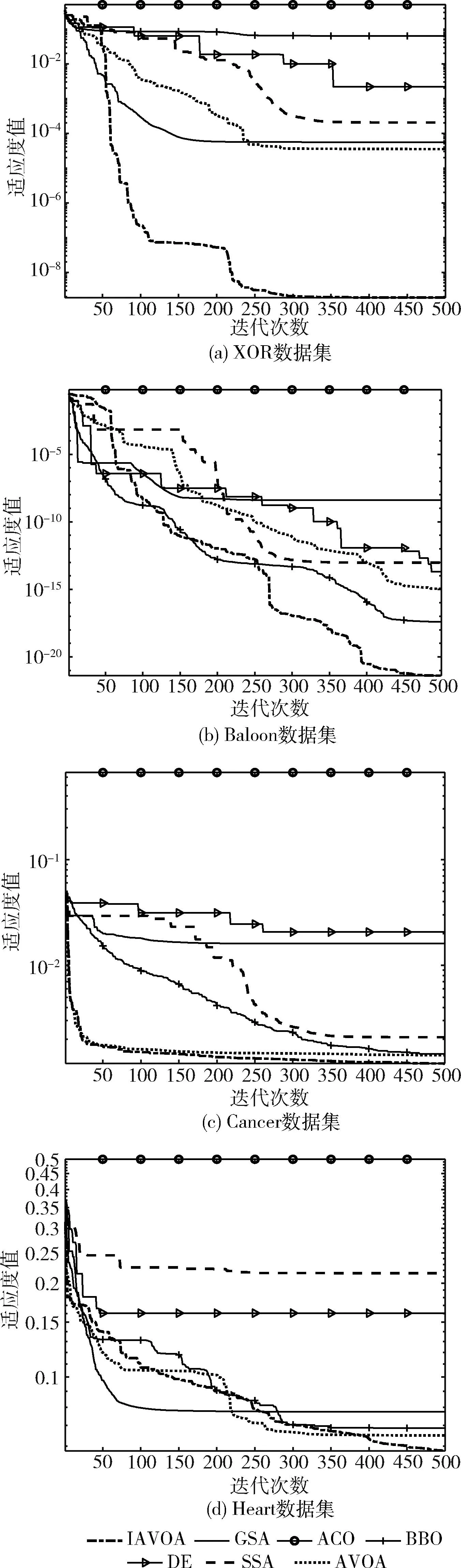
图5 不同算法在4个分类数据集上的MSE收敛曲线
N位异或问题是著名的非线性测试问题,识别输入向量中“1”的个数,若包含奇数个“1”,则输出“1”,否则输出“0”。XOR问题的MLP结构是3-7-1,7个算法在XOR数据集上的运行结果见表2,从表中可以看出,IAVOA算法的平均值最小,其次是BBO、AVOA、DE、SSA、GSA和ACO,说明IAVOA可以解决MLP中局部极小值停滞问题,并且效果较优。在标准差上可以看出ACO算法是最好的,其次是IAVOA算法,但ACO算法的收敛精度不如IAVOA算法。比较分类准确率发现,IAVOA、AVOA、BBO、SSA的分类准确率均为100%,GSA的分类准确率为67.3%,DE和ACO的分类准确率较低,分别是51.1%和50%。从图5(a)可以看出IAVOA的收敛速度比其它算法快且均方误差更小。
Baloon数据集有4个属性,MLP结构是4-9-1,7个算法在在Baloon数据集上运行的结果见表3,IAVOA的平均均方误差值最小,说明IAVOA可以解决局部极小值问题,其次是BBO、AVOA、DE、SSA、GSA和ACO。对比分类准确率,IAVOA、AVOA、SSA、BBO和GSA的分类准确率都是100%,ACO的分类准确率最差,仅为40%。IAVOA的标准差是7个算法中最小的,说明IAVOA具有很强的鲁棒性。比较均方误差的收敛曲线,图5(b)显示,IAVOA的曲线最陡,远远超越其它算法,收敛速度最快,说明IAVOA在寻找全局最小值方面的性能最好。
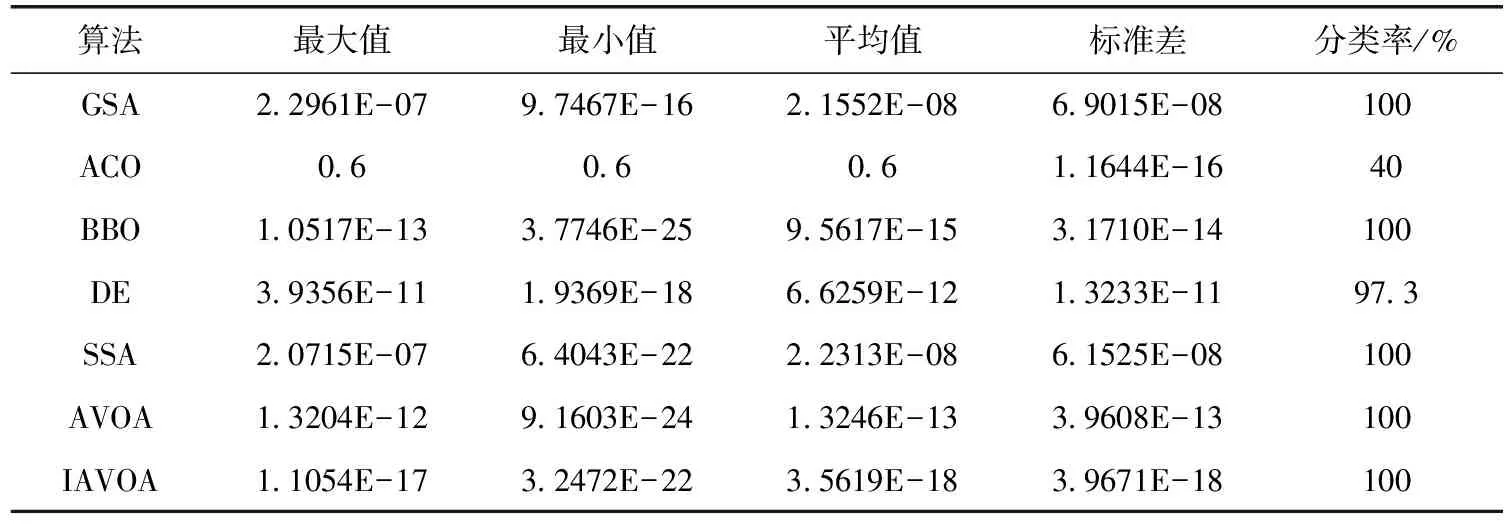
表3 算法在Baloon数据集上的仿真结果
Cancer数据集是对乳腺癌良性和恶性的分类,该数据集的MLP结构采用9-19-1。该数据集的复杂性和难度更高,如果算法对该数据集分类效果好,说明算法的性能较优。表4是各算法的运行结果,其中IAVOA的分类准确率为99%,BBO和SSA算法的分类准确率均为97.7%,AVOA的分类准确率是97%,GSA的分类准确率为67.33%,DE的分类率为4%,ACO的分类率为0。说明IAVOA对高维数据的处理效果较好。IAVOA的标准差比BBO略差,但收敛速度更快,收敛精度远高于其它算法。从图5(c)可以看出,IAVOA与AVOA、BBO的收敛曲线贴近,幅度虽然不大,但也可以看出有所改进。充分验证了IAVOA的鲁棒性强、效率高和分类准确性高。

表4 算法在Cancer数据集上的仿真结果
Heart数据集是诊断心脏的计算机扫描图像。心脏数据集有22个属性,难度最大,该数据集的MLP结构是22-45-1。算法运行结果见表5,IAVOA、AVOA、BBO的平均均方误差值最好。比较分类准确率,SSA的分类准确率最高80.8%。其次是BBO,分类准确率为79.6%,DE的分类准确率是75.4%,IAVOA的分类准确率为74.2%,优于AVOA、ACO和GSA算法。这充分说明在处理节点较多的MLP问题时,IAVOA稳定性更高,同时MLP的测试样本的分类准确率也表现良好。从图5(d)可以看出,IAVOA算法的收敛速度最快,说明在处理复杂的Heart数据集时,IAVOA算法所用的时间最少。
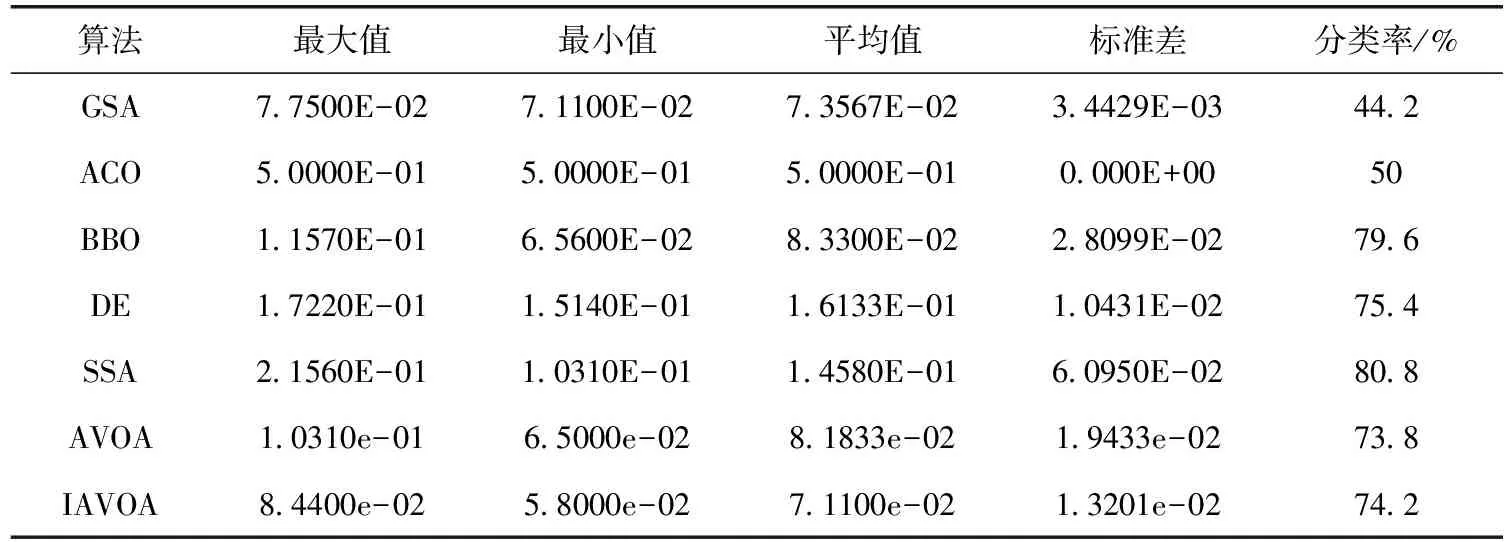
表5 算法在Heart数据集上的仿真结果
从图5(a)、图5(b)、图5(c)、图5(d)可以看出,ACO在所有图中,收敛速度和收敛精度都是最差的。IAVOA不管是在简单的数据集还是复杂的数据集上,都比其它算法的效果更好,收敛速度更快,具有较高的开发率,表明IAVOA可以为MLP提供最优的连接权重和偏差,算法的训练速度和寻优能力也大大提高。
5 结束语
本文将最近提出的AVOA算法改进后用于训练MLP,为了验证IAVOA算法的性能,选用6个启发式算法,在4个分类数据集上进行测试,评估IAVOA训练MLP的有效性。仿真结果显示,与GSA、BBO、ACO、DE、SSA、AVOA相比,IAVOA对XOR和Baloon两个分类数据集给出了最优结果。在Cancer和Heart数据集中也表现良好,IAVOA能更好地避免局部极小值,在分类准确率和收敛速度方面具有优越性。
在未来研究中,可以将IAVOA应用于训练其它类型的神经网络,如卷积神经网络、径向基函数神经网络、模块化神经网络和长/短期记忆网络。
