基于层一致性平均教师模型的半监督岩石薄片图像分类
2024-02-18严子杰
严子杰,王 杨,陈 雁,张 翀
西南石油大学计算机科学学院,四川 成都 610500
岩性识别是地质学、资源勘查、岩土勘察、岩石力学与工程等领域非常重要而基础的问题[1-2]。岩石薄片识别是地质学中应用最早且较为普遍的岩石岩性鉴定方法之一,它利用显微照相技术,对岩石薄片中有代表性、具有显著意义的区域进行多物镜、多光性、多视域的拍摄成像,然后通过观察不同岩石薄片图像的矿物形态和内部结构来识别岩性[3]。深度学习方法可以自动挖掘岩石薄片图像的复杂特征,学习到比传统图像分类方法更大的特征量,从而得到更高的分类准确度和更良好的泛化能力。其自主学习的特点更好地发挥了大数据的优势,更符合当前地质工作智能化的发展趋势[4]。
构建用于分类的岩石薄片图像数据集往往需要花费大量的人工标记成本,且依赖于标记人员的经验和能力[4]。基于监督学习的深度学习方法本身就限制在各自的数据集中,若想扩展到其他数据集中,则需要大量重复性工作[5]。半监督学习方法可以通过标记样本的空间分布,确定未标记样本的所属类别,增强数据集并提升训练模型的准确度和泛化能力[6]。但半监督学习方法在岩石薄片图像分类中还没有较多的应用,目前仅有的研究都是使用简单的伪标记方法对标记数据集进行增强[7],尚未探索更多更有效的半监督岩石薄片图像分类方法。
本文使用层一致性正则化方法改进了平均教师(mean teacher,MT)模型,通过设计分层无监督一致性组件约束了师生网络的层次结构,以实现对未标记数据信息的有效利用。实验结果表明:层一致性平均教师(hierarchy consistency mean teacher,HCMT)模型增强了对未标记数据中有效信息的提取能力,使其拥有了与全监督方法相似的分类能力;半监督学习算法展现出了通过大量未标记岩石薄片图像数据增强模型分类性能的潜力。
1 相关研究
目前,针对岩石薄片图像的自动化分类方法主要有两种:基于特征的分类方法和基于图像的分类方法。基于特征的分类方法的本质是构造和提取出能够定量描述目标独特性和稳定性的图像特征,并基于这些图像特征进行自动分类[8]。基于图像的分类方法的思想是利用计算机分析图像特点自动提取图像特征,然后进行分类,其中最常用的是以卷积神经网络为代表的深度学习方法。卷积神经网络使用二维图像卷积运算作为图像特征提取的通用模板,以数据驱动的方式,在训练样本的指引下自动寻找到有效的卷积滤波器(即图像特征提取器),从而使传统的数字图像分析模式由人工特征工程转变为自动特征工程[9]。但上述监督学习方法依赖于大量有标记的岩石薄片图像,往往需要花费大量的人工标记成本,且依赖于标记人员的经验和能力[4]。
半监督学习方法只依靠少量人工标注的数据对模型迭代式自训练,通过不断增强数据集数量最终将其扩展到整个数据集,从而建立整个数据集的分类模型。半监督学习方法主要包括:自训练方法[6]、生成式方法[7]、一致性训练[10-12]、熵最小化[13]、深度学习方法[14-15]等,并已在医疗诊断[11]、遥感地物识别[12]、语音识别[15]等领域进行了大量的应用。但岩石薄片图像具有极少的背景信息、极复杂的目标信息、斑块尺度差异大、成分不稳定等特点[4],因此常规的半监督学习方法在半标记岩石薄片图像中无法取得满意的分类效果。目前,基于半监督学习的岩石薄片图像分类使用简单的伪标记方法对标记数据集进行增强[7],仍需探索更多可应用的半监督学习方法以解决岩石薄片图像可扩展式预测的问题。
针对上述问题,本文提出HCMT 模型,用以解决模型可扩展式预测的问题并增强模型的泛化能力。本文的研究思路为:1)构建开放多元岩石薄片图像数据集;2)使用层一致性正则化方法改进MT 模型,通过设计分层无监督一致性组件,鼓励师生网络在分层特征空间中的预测一致性,旨在提升其对未标记数据有效信息的利用;3)通过消融实验和对比试验证明层一致性方法的分类能力。
2 方法
2.1 MT 模型
近年来,MT 模型[9]在半监督分类中取得了巨大的成功,该模型在学生模型和教学模型之间加强了不同扰动输入下学生模型和教师模型结果预测的一致性,从而提高了模型的鲁棒性。MT 模型的核心思想是将模型分为师生模型,其中教师模型用来生成学生模型的学习目标,学生模型用教师模型提供的目标进行学习,教师模型的权重是通过学生模型时间记忆的加权平均得到的。MT 算法结构如图1 所示,算法流程描述如下:
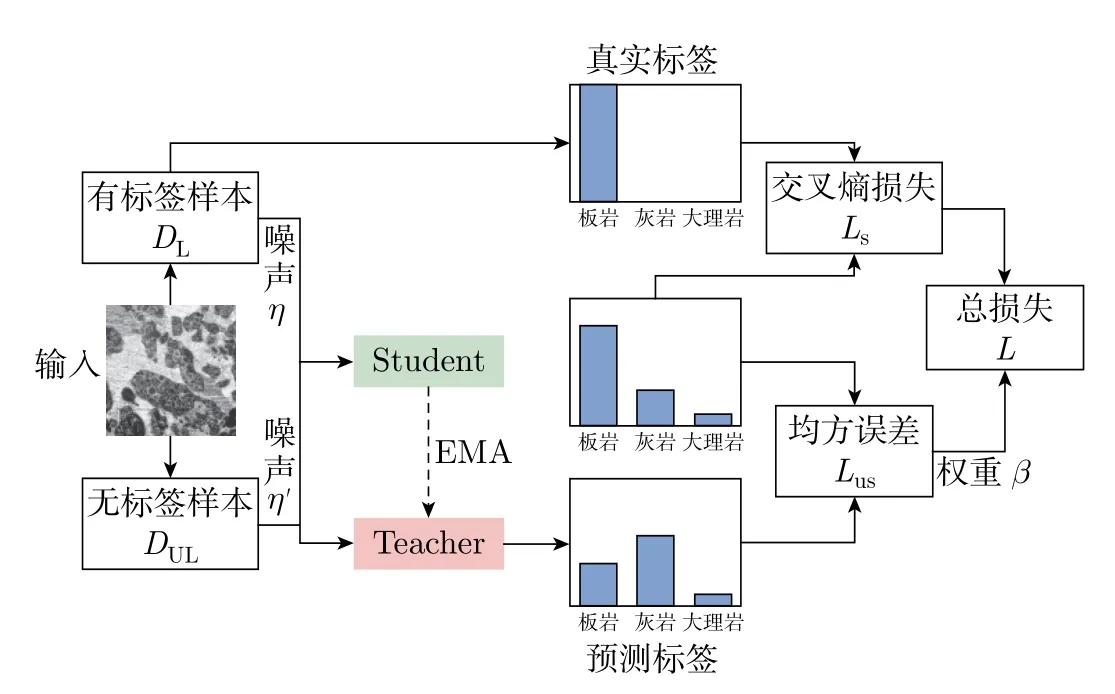
图1 MT 模型结构Figure 1 MT model structure
步骤1定义有标签样本x1、标签y1、无标签样本x2,分别对x1和x2添加噪声,以下x1和x2均是已经添加噪声的数据;
步骤2将有标签样本x1输入至学生模型,并计算与标签y1之间的交叉熵损失Ls;
步骤3将无标签样本x2输入至学生模型,得到学生模型输出label1,同时将无标签样本x2输入至教师模型,得到教师模型输出的目标label2,通过计算两个输出的均方误差值得到label1与label2之间的损失
式中:x为输入数据;θ′ 和η′ 分别为教师模型的参数和输入扰动;θ和η分别为学生模型的参数和输入扰动。
步骤4计算模型的总损失L=Ls+Lus;
步骤5用梯度下降法更新学生模型的权重,教师模型的权重则用学生模型历史权重的指数移动平均法更新,公式为
2.2 HCMT 模型
MT 算法仅使用每个样本的最终输出,而未探索网络结构中隐藏层的丰富信息。同时,学生模型对教师模型预测结果的拟合情况仍受到岩石薄片图像复杂信息的制约。文献[16-17] 从不同的层获得多尺度预测以提高网络性能。受此启发,本文希望利用不同尺度的预测进一步分层规范化MT 模型。
基于上述思路,本文提出了HCMT 模型,该模型按照MT 模型的基本思想,以不同扰动下的岩石薄片图像作为输入,并鼓励分层预测的一致性。学生网络和教师网络采用相同的骨干结构,将教师网络的多级网络结构同样作为学生网络的学习目标,通过层次一致性对其进行正则化,以有效利用未标记数据。基于VGG16 模型的HCMT 模型结构如图2 所示。
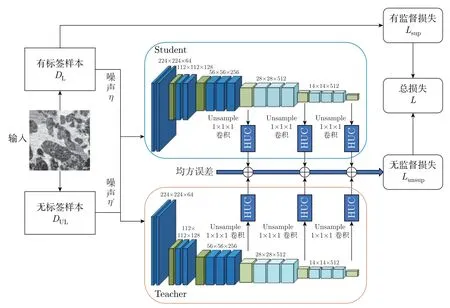
图2 基于VGG16 模型的HCMT 模型结构Figure 2 HCMT model structure based on VGG16 model
具体来说,对于未标记数据,我们期望学生网络和教师网络的分层预测结果是一致的。为了进一步加强两个网络之间的一致性,本文设计了一个分层无监督一致性(hierarchy unsupervised consistency,HUC)组件来鼓励隐藏特征空间中的预测一致性。HUC 组件由一个降采样层和一个1×1×1 卷积层组成,其中降采样层是为了统一不同层次所包含的图层元素数量,1×1×1 卷积层是为了师生网络的部分通道一致性并增强网络的鲁棒性。基于HUC 组件生成了多尺度预测的均方误差损失,作为无监督损失项,公式为
式中:(θ,η) 和(θ′,η′) 分别为学生模型和教师模型在不同噪声下的输入数据;fs(xi;θ′,η′) 表示通过HUC 组件获得的各隐藏层分量;S为隐藏层数;βi为各层损失的权值并作为超参数在训练过程中不断调整。在本文中,HUC 组件使用VGG16 模型的3 个隐藏层作为输入,分别为第3、第4、第5 个max-pooling 层得到的特征映射,具体如图2 所示。
最后,无监督正则化损失与监督损失相结合,共同优化网络,总损失函数定义为
式中:Lsup为监督项,与MT 模型完全一致;Lunsup为无监督层一致性正则化项;λ(t) 是一个时间相关的高斯加权函数,控制监督损失和无监督层一致性正则化项的权重,公式为
式中:t和tmax分别为当前步长和最大训练步长。
3 实验分析
3.1 数据集与预处理
本文使用从科学数据银行网站(https://www.scidb.cn/,访问于2023 年8 月1 日)免费获取的岩石薄片图像作为训练、验证和测试数据集,共包含4 个数据集。其中,训练集和验证集为“南京大学岩石教学薄片显微图像数据集”[18](如图3 所示),并按4∶1 的比例随机分配。该数据集目前可以公开免费获取,涵盖岩石种类最完善、数据量最多、图像质量较好、记录较为完备的岩石薄片图像数据集[4]。测试集包括“新疆塔里木盆地西部晚白垩世-始新世岩石薄片偏光显微图像数据集”[19]“西藏特提斯喜马拉雅早-中侏罗世岩石薄片偏光显微图像数据集”[20]和“鄂尔多斯盆地中寒武统徐庄组岩石薄片显微图像数据集”[21]3 个岩石薄片图像数据集,这些数据集与训练和验证数据集的采样地点、拍摄时间、拍摄设备、操作人员完全不同,因此可以用于测试模型的真实分类能力。数据集详情见表1。
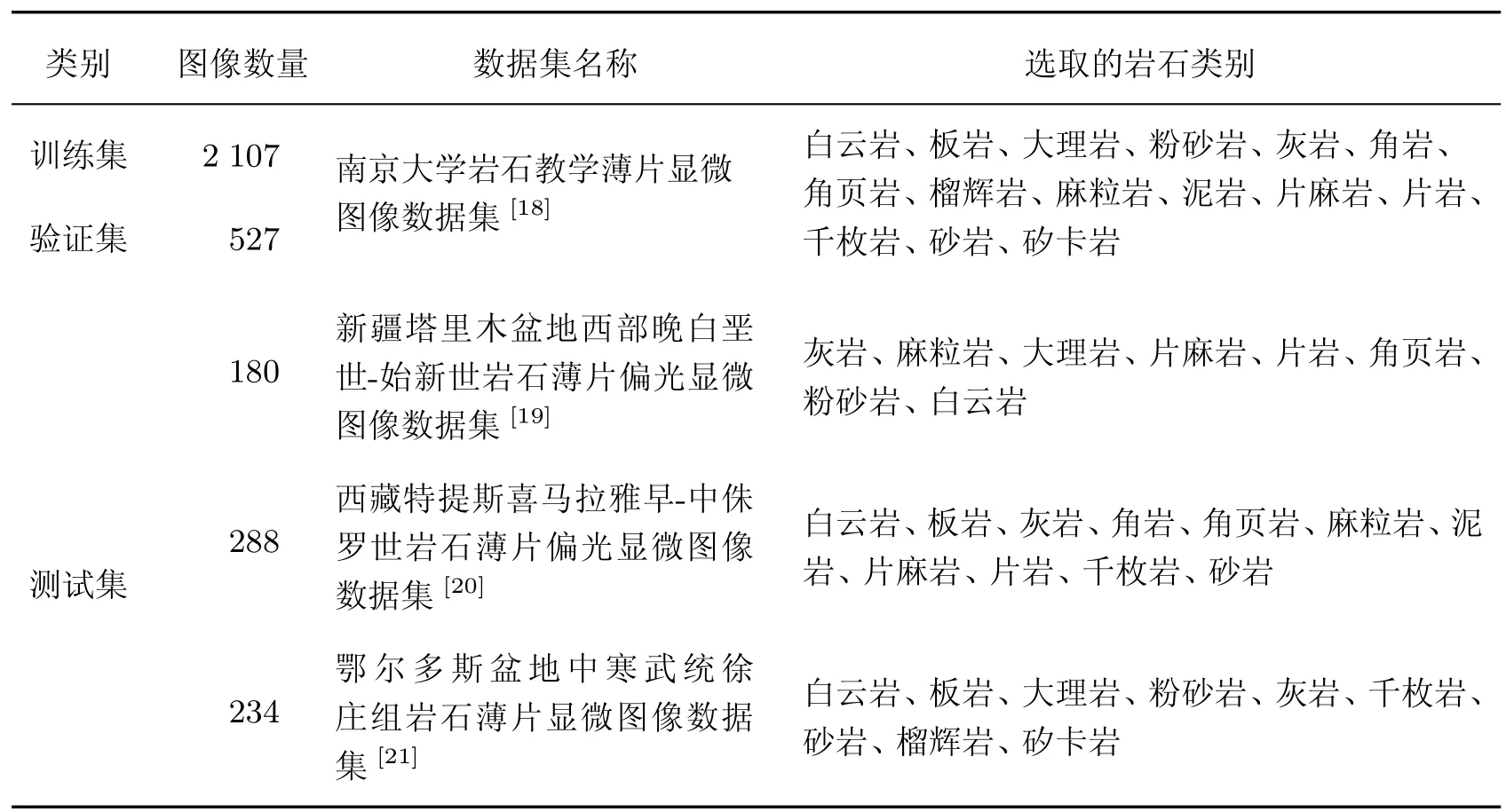
表1 训练、验证、测试数据集详情Table 1 Detail of training,validation and test datasets

图3 训练集的15 种岩石薄片图像Figure 3 15 kinds of rock slice images of the training set
图像数据预处理操作按照处理顺序包括:比例尺匹配、直方图均衡化、图像白化、图像分块。比例尺匹配是将同岩石类型的图像大小与实际岩石薄片大小的比例尺调整至同一大小,以保证图像特征的空间一致性[2]。直方图均衡化是为了保证图像的亮度均匀分布,图像不会过暗或者过亮。图像白化是为了对过度曝光和低曝光的图像进行处理,消除各维度间的相关性,减少外界拍摄环境等对图像的影响,去除不必要的噪声信息。图像分块是为了增加训练集数据的规模,增强对图像局部特征的提取。本文采用包含24 像素重叠区域的方式,将1 024×1 024 像素的原始图像裁剪为224×224 像素的25 块子图像。
原始数据集中所有样本均包含标签,实验中验证集和测试集数据均为带标签数据,因此直接采用原始带标签样本。训练数据集为部分标记数据集,其中的无标签样本由原始有标签样本随机不放回抽样选取,并去除标签。
3.2 消融实验和对比实验
本文针对提出的HCMT 模型进行消融实验和对比实验,主要包括3 个实验:
1)HCMT 模型在标记比例为30%、50% 和70% 的半标记数据集的实验(标注为HCMT-30、HCMT-50、HCMT-70);
2)MT 模型在标记比例为30%、50% 和70% 的半标记数据集的实验(标注为MT-30、MT-50、MT-70);
3)预训练VGG16 模型在抽样比例为30%、50%、70%、100%的全标记数据集的实验(标注为监督-30、监督-50、监督-50、监督-100),此处抽样比例为从全部标记图像中进行随机抽样的样本比例。
实验1 为了验证不同的标记比例对HCMT 模型的影响;实验1 和2 为消融实验,验证层一致性正则化对MT 模型的提升;实验1 和3 为对比试验,验证HCMT 模型通过未标记数据提升模型的分类能力。
3.3 实验设置
实验均使用Python 的PyTorch 框架实现,分别使用以下硬件配置进行:Intel®CoreTMi5-10400 CPU@2.90 GHz,32 GB RAM,NVIDIA GeForce RTX 2080 SUPER GPU,16 GB内存。
HCMT 模型和MT 模型采用的基础模型均为预训练VGG16 模型。研究表明,采用预训练模型可以通过迁移学习的方式提升模型的表现[5]。大量文献证明VGG16 的小卷积核更适合于提取岩石薄片中岩粒的微小信息[4,22-23],基于岩石薄片图像分类的前序实验对比,在ResNet101、Inception-v3、VGG16 这些经典的卷积神经网络模型中,VGG16 模型的准确度和稳定性最好,故本文选取预训练VGG16 模型作为本实验的基础模型。实验中所有预训练VGG16 模型的冻结层均为前3 层,即只训练VGG-block4、VGG-block5、全连接层、Softmax层参数,如图4 所示。
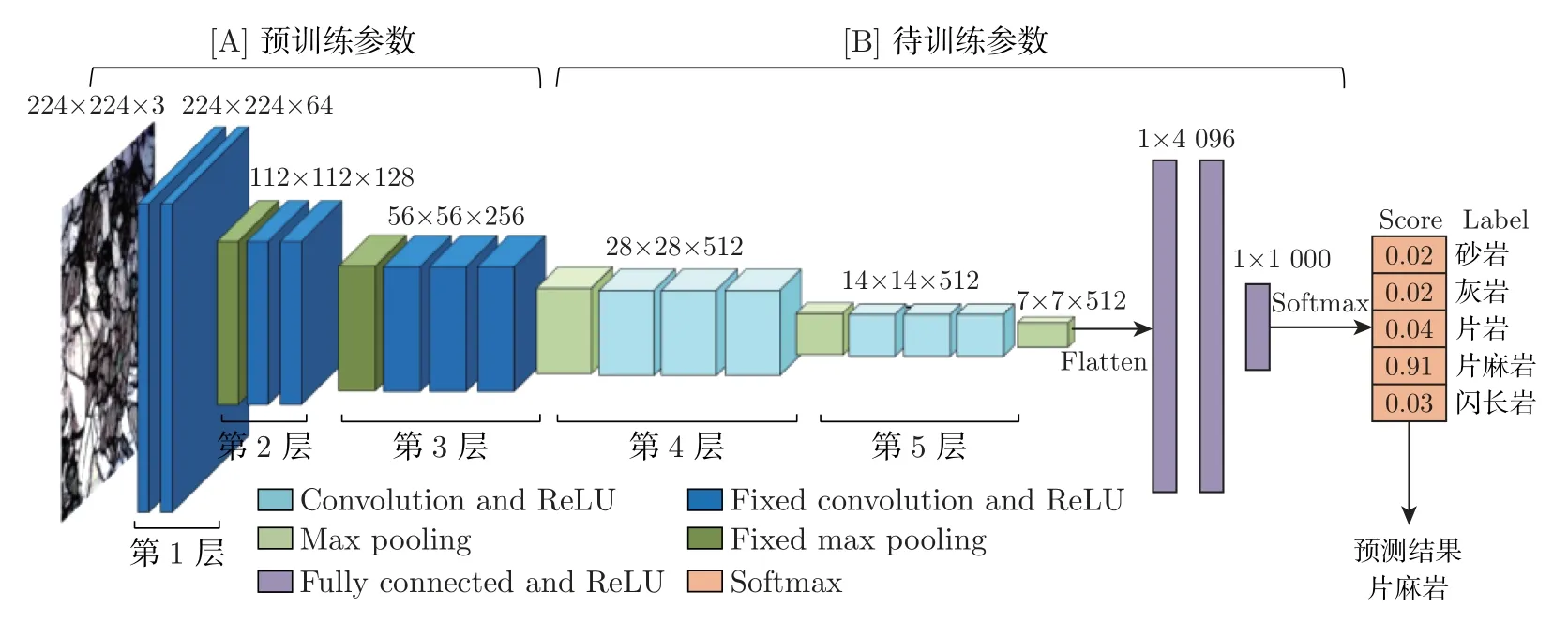
图4 冻结前3 层的预训练VGG16 模型网络结构Figure 4 Pre-trained VGG16 model when the first three layers were frozen
对于每个模型的训练过程,均采用交叉熵损失作为损失函数,选择Adam 作为优化器。通过网格搜索调整超参数,设置学习率为0.01、0.001、0.000 1,批大小为128、256、512、1 024、2 048,最大轮次为100。交叉熵损失公式为
使用3 种评价指标准确率Accuracy、F1 和Kappa 系数来衡量模型总体性能。它们的计算公式为
式中:TP、TN、FP、FN 分别为每一类的真阳率、真阴率、假阳率、假阴率;Kappa 系数K通过混淆矩阵计算;Po为对角线元素和与矩阵所有元素和之比;Pe为实际与预测数量的乘积和与矩阵所有元素和的平方之比。F1 综合了精确率和召回率指标,准确率代表包括正样本和负样本在内的整体分类正确率。
3.4 实验结果
表2 展示了实验训练的全部模型在测试集的评估得分,图5 展示了HCMT-50、MT-50、监督-50、监督-100 模型在测试集的混淆矩阵,图6 展示了按标记比例递增的HCMT 模型、MT 模型和监督模型在测试集的准确率变化。
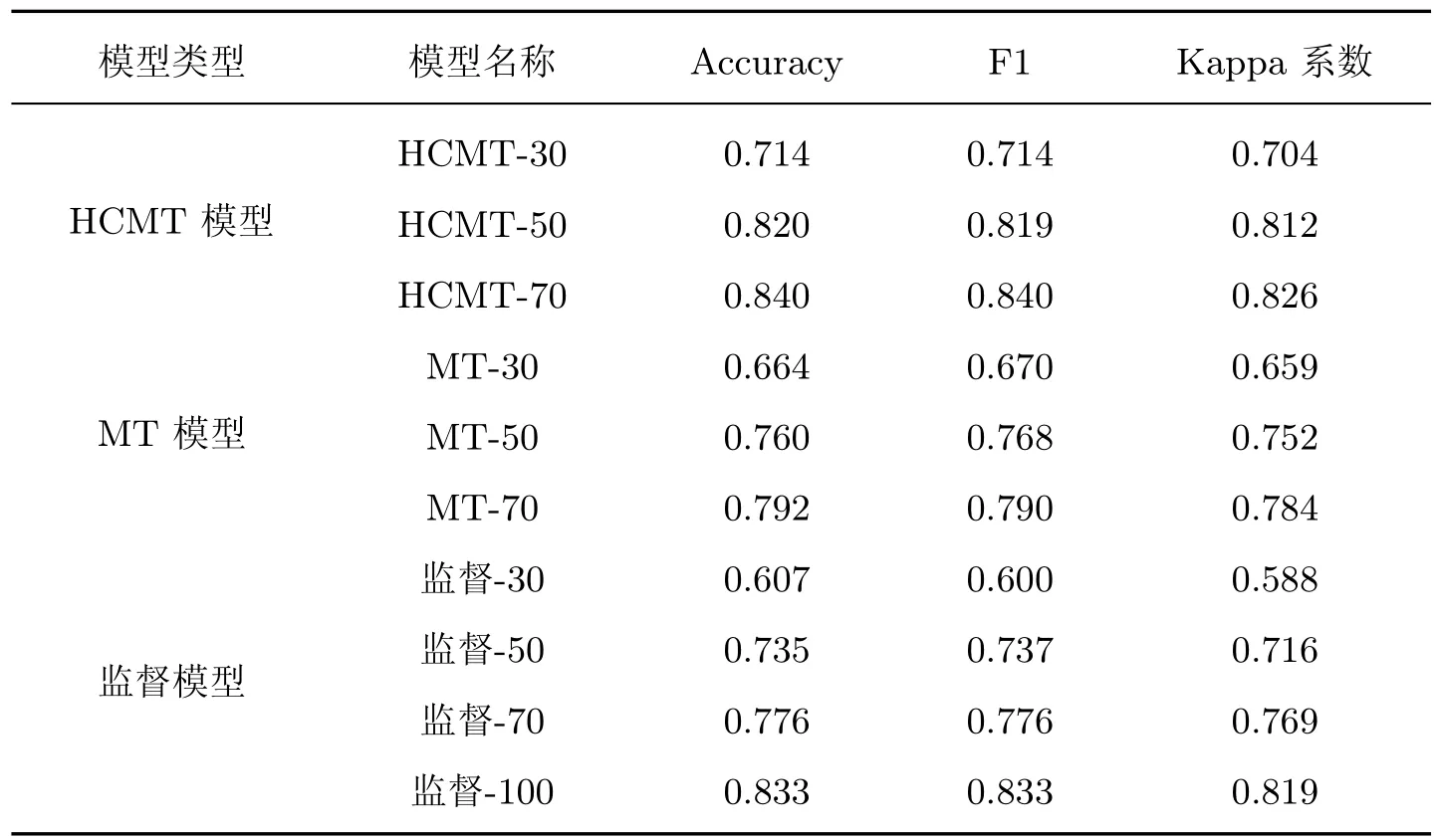
表2 模型评估得分对比Table 2 Comparison of model evaluation scores

图5 HCMT-50、MT-50、监督-50、监督-100 的混淆矩阵Figure 5 Confusion matrixes of HCMT-50,MT-50,supervised-50 and supervised-100 model
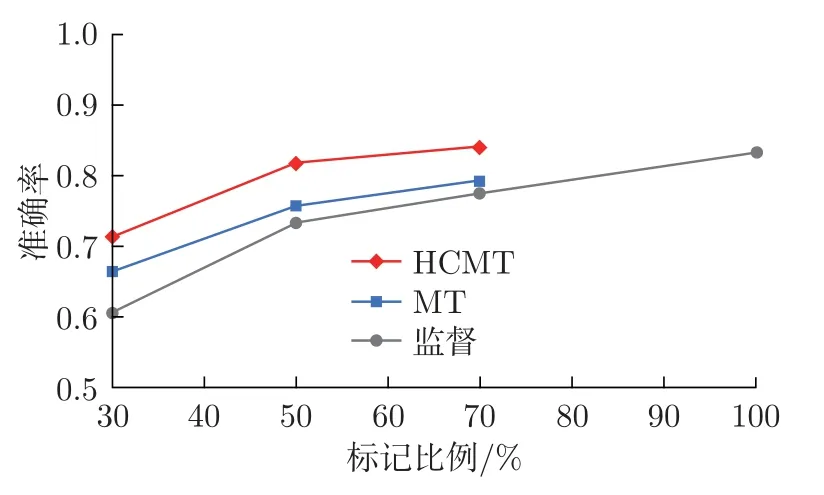
图6 HCMT、MT、监督模型随标记样本比例的准确率变化Figure 6 Accuracy of the HCMT,MT and supervised model varied with the proportion of labeled samples
3.5 实验分析
为了验证层一致性正则化的引入对MT 模型性能的提升,以及验证HCMT 模型利用未标记数据提升分类准确率的能力,本文进行了消融实验和对比试验。
消融实验表明,HCMT 模型在各个部分标记数据集中都表现出了比MT 模型更优秀的分类能力。在30%、50%、70% 标记比例的部分标记数据集中,HCMT 模型相较于MT 模型准确率分别提升5.0%、6.0%、4.9%,在50% 标记数据集中提升最大。从各模型的混淆矩阵来看,HCMT-50 模型相较于MT-50 模型在绝大部分类别的分类准确度有了一定程度的提升,主要体现在:1)大部分类别分类准确度得到大幅度提升,尤其体现在白云岩(17%)、板岩(7%)、灰岩(6%)、泥岩(8%)、片麻岩(7%)、矽卡岩(15%);2)难分类别误分误差的减少,尤其体现在白云岩、板岩、大理岩、灰岩、泥岩组类(减少5%~10%),片岩和片麻岩组类(减少约3%),以及矽卡岩与其他类别组类(减少约3%)。而MT-50 模型相较于监督-50 模型的提升很小,MT 模型似乎无法利用未标记数据集减少难分类别的误分误差。
难分类别是指因其岩石薄片图像具有较小的颜色、纹理、形状差别而难以被人工和深度学习方法准确分类的类别,难分类别误分误差的减少是提升模型准确度的主要因素。MT 模型似乎不能通过未标记数据提升模型的分类准确度,在较难分类的类别如白云岩、灰岩、泥岩、大理岩等中,MT 模型的预测结果尤其不佳。这可能是由于这些难分类别具有相似的图像特征,半监督学习模型往往在已标记样本数量较少且图像特征不明显时无法表达类别之间的细微差异,因而导致未标记样本被大量误分类。HCMT 模型在部分标记数据集中取得了更优秀的分类结果,模型测试结果逼近全标记监督模型,这与其他研究[11,15]所得到的结果相似。原因可能如下:一方面,层一致性方法在无监督损失项限制了师生模型,使得学生模型可以更好地拟合教师模型的网络结构,并根据未标记数据的特点寻找其最佳的所属类别,因而提升了模型对未标记数据的学习能力。另一方面,本文所提出的层一致性方法使用1×1×1 卷积层将每一个隐藏层平面化,并根据该平面获得无监督损失,因而释放师生模型网络结构的部分自由度。这种方法可能增强了模型对未标记数据独特特征的提取能力,使得模型在带标记数据的基础上增强了对未标记数据有效差异特征的提取能力。
对比实验表明,HCMT 模型在50% 标记数据集中达到了接近于监督模型在100% 标记数据集中取得的分类能力。HCMT 模型相较于监督模型,在30%、50%、70% 标记比例的部分标记数据集中,准确率提升了10.7%、8.5%、6.4%,这说明随着未标记数据量的增加,HCMT模型可以提取到更多有用的信息并用于提升模型分类能力。在标记比例大于50% 之后,更多带标记数据对于HCMT 模型、MT 模型的提升并不明显,这说明较少的带标记数据就可以使半监督模型达到较好的分类效果,而大量的未标记数据是进一步提升半监督模型分类结果的最重要因素。这符合半监督学习方法的普遍规律[5-6],适合的半监督模型可以在少数标记的情况下获得较高的性能,且可以通过大量的未标记数据丰富模型细节和提升泛化能力。值得注意的是,HCMT-70 模型在部分标记数据集中,取得了较监督-100 更优秀的综合评价指标,这体现出了半监督模型在泛化能力上的优越性。这可能是监督模型对数据的过拟合使得无法展现数据集的真实特征分布,而HCMT 和MT 模型通过添加噪声正则化的方式减轻了对数据的过拟合现象。
综上所述,HCMT 模型将层一致性正则化引入MT 模型,通过增强师生网络的层一致性有效利用了未标记数据信息,减少了难分类别的误分误差并提升了模型的泛化能力,使得HCMT 模型可以在50% 标记数据集中获得如全标记数据集相似的分类能力。
4 结语
传统的岩石薄片图像分类依赖于大量人工标记的图像样本,这种方式受制于标记人员的经验和能力,且无法通过不断增加的未标记岩石薄片图像样本实现分类能力的可扩展式增强。为解决该问题,本文提出HCMT 模型,通过在无监督损失中添加层一致性正则化项,约束师生模型的层次结构,以实现对未标记数据信息的有效利用。消融实验和对比实验结果表明,层一致性正则化方法的引入,增强了MT 模型对未标记数据中有效信息的提取能力,提升了MT 模型的分类准确率,使其达到了与全监督方法相似的分类能力。半监督学习模型表现出了利用大量未标记岩石薄片图像数据提升模型分类能力的潜力,未来计划探索更多分层细节信息以增强半监督模型对分层特征的充分利用。
