大区域场景下基于无人机视角的目标计数方法
2024-02-18张守龙丁来辉胥志伟杨晓刚王胜科
谢 婷,张守龙,丁来辉,胥志伟,杨晓刚,王胜科
1.中国海洋大学信息科学与工程学院,山东 青岛 266100
2.山东巍然智能科技有限公司,山东 青岛 266100
在无人机场景中,对某一区域进行目标计数是一项非常具有挑战性的任务。当无人机超过一定飞行高度时可以获得更广阔的视野,捕获更多的目标,但也意味着采集到更多更小的目标。无人机采集到的目标由于尺寸过小且易与背景相混淆而难以被检测到,从而影响计数的准确性。同时,目前的计数工作大多基于单帧图,如何利用无人机采集的多视角图像去统计某一区域中真实的目标数量,如何确保多视角图像中同一目标不重复计数,是目前多视角目标计数领域所面临的问题。
目标检测的精度决定了目标计数的基础,进而影响最终的计数结果。因此,为了促进无人机在大区域场景中目标计数的智能应用,需要设计出一个满足航拍图像高精度要求的目标检测框架。该目标检测框架需融合最新的科学理论,能够大幅度提升小目标的检测精度。VisDrone[1]是目前流行的用于物体检测的无人机数据集,本文整理并制作了无人机目标检测和计数数据集OUC-UAV-CC 作为其补充。使用最新的优秀物体检测器进行了一系列的实验,结果显示小物体的检测精度远远小于中型和大型物体的检测精度,这意味着开发适用于航拍领域的目标检测器是目前面临的巨大挑战。
本文提出了一个大区域场景下基于多视点的目标计数策略以实现对某场景的计数工作,进而全面了解某一场景的真实情况。具体步骤为:1)无人机在规定的飞行航线下,按照一定高度和角度,对区域场景进行连续帧的拍摄来采集数据,然后将采集到的数据送入检测器进行检测;2)把采集到的数据根据特征点和定位信息进行匹配拼接还原场景,利用本文设计的相似性度量拼接损失函数迭代优化;3)根据本文提出的映射公式,将目标检测结果映射到地理坐标系内并统计整个区域的目标数量,同时要确保多视角图像中同一目标不重复计数。
1 相关工作
1.1 无人机目标检测
当无人机在高空进行目标检测应用时很难识别出小目标,所以在无人机目标检测任务中,小目标检测一直以来都是具有挑战性的工作。目前,针对提高小目标检测精度的策略主要归为特征增强和数据增强两大类。
特征增强是解决小目标包含像素信息过少而难以形成有辨别性的特征信息的问题,希望通过改进小目标的特征表达能力来提高对小目标的识别能力。特征增强策略主要包含特征融合和运用生成式对抗网络(generative adversarial network,GAN)生成高分辨率图像或特征两个方面。一方面,特征金字塔网络(feature pyramid networks,FPN)[2]作为一种典型代表,有效地结合了高层的语义信息和低层的空间信息。基于FPN,又进一步发展出了路径聚合网络(path aggregation network,PANet)[3]等加强版FPN结构。另一方面,基于多任务GAN的细小物体检测(small object detection via multi-task GAN,SOD-MTGAN)方法[4]通过GAN 生成高分辨率图像,而感知生成式对抗网络方法[5]则运用GAN 生成高分辨率特征。特征融合与注意力机制结合的单阶段目标检测[6]借助于小目标周围的信息以及注意力机制,解决小目标判别特征少的问题。
数据增强是针对小目标数量和尺寸不具备中目标及大目标优势使得小目标得不到充分训练的问题,通过加强检测器对小目标的学习与训练来提高小目标检测的精度。文献[7] 提出的增强机制通过粘贴复制小目标实现了直接增加小目标实例个数的目的,文献[8] 提出的拼接机制则通过损失函数中小目标损失占比的反馈来调节输入图像的方式,提高小目标的损失对总损失的影响,间接地增加了小目标的数量。
1.2 无人机图像拼接
由于单幅图像的视野有限,要精确地获取整个临海区域目标分布信息需要对无人机拍摄的影像进行拼接。图像拼接是将多个重叠图像组合成高分辨率的覆盖广阔视野的单个图像的过程。已有的图像拼接算法主要是拼接两个图像[9-10]或是拼接同一方向拍摄的多个图像生成全景图像[11-15]。无人机在现实应用场景中通常需要在广阔区域拍摄大量图像进而生成拼接图像[16-21]。虽然近年来出现了许多图像拼接技术[13,22-23],但这些方法不能同时满足无人机图像拼接的实时性、鲁棒性和准确性要求。目前已经提出了许多用于无人机图像拼接的算法,其中,基于无地面控制点的自动图像拼接方法[24]不仅可以获得广阔区域的全景图像,还可以获得相应的三维地形模型。基于单目标的实时增量无人机图像拼接[17]利用运动恢复结构(structure from motion,SFM)的方法估计相对相机姿态,并将多个无人机图像拼接成一个无缝图像。通常,基于SFM 的拼接算法可以生成精确的正射图像,但SFM 方法的时间复杂度非常高,不适合实时和增量使用。文献[25] 提出了一种以增量方式进行实时拼接大型航空图像的方法,该方法使用单眼同步定位与建图系统(simultaneous localization and mapping,SLAM)生成3D 点云地图,需要利用GPS 数据优化拼接效果,对于非平面环境其拼接图像质量难以保证。
1.3 无人机目标计数
目标计数是指统计给出的图像或视频内目标的种类及其对应的数目。本文从计数对象依托介质的角度主要介绍单视角目标计数和多视角目标计数。单视角图像的目标计数可以分为基于目标检测的、基于回归估计的和基于密度图估计的图像计数方法[26]。基于目标检测的计数方法可以根据实际应用场景选择检测器,利用深度学习的目标检测器相比于传统的检测器在精度和速度方面更具优势,然而,这类方法需要对所有目标进行人工标注及检测,不适用于目标密集或者相互遮挡的场景。基于回归估计[27]的目标计数是指通过建立图像特征与目标数目的回归模型来估计图像中的目标总数,其中图像特征包括尺度不变特征变换(scale-invariant feature transform,SIFT)[28]和方向梯度直方图(histogram of oriented gradient,HOG)[29]等传统方法提取的全局特征,回归模型包括简单的线性回归或者混合高斯回归。这类方法不需要对目标进行严格标注,适合目标数量多的计数任务,能够有效降低遮挡对计数精度的影响,但其缺乏对图像的整体理解。基于密度图估计的目标计数由文献[30]首次提出。这类方法实现了逐像素回归计数,适用于分布密集的人群计数领域。近年来,基于深度学习的相关方法不断涌现。文献[31] 提出了一个基于多列卷积神经网络的人群计数框架,将提取到的多尺度特征映射为密度图,提高了计数精度。文献[32] 提出了一个新颖的计数框架,通过自适应膨胀卷积网络有效解决了透视现象造成目标尺度变化大问题,并通过自校正监督模块修正了目标的错误标注。基于密度图估计的方法一方面能够获取对图像的整体理解,另一方面能够有效解决目标遮挡的问题。
多视角图像下的目标计数可以分为3 类方法,分别是基于检测或跟踪的方法[33-36]、基于回归的方法[37-38]和基于3D 圆柱体的方法[39]。但这些多视角目标计数方法有以下局限性:1)需要利用前景提取技术将人群从背景中分割出来,因此前景提取步骤的有效性限制了最终的计数性能;2)手工制作的特征都用于人群检测或人群计数回归,手工制作的特征缺乏表征能力,降低了方法的鲁棒性和性能;3)这些方法主要在基准数据集PETS2009[40]上进行测试,PETS2009 是一个多视图数据集,人群数量少,人群行为分阶段。文献[41] 提出了一种基于深度神经网络的多视图计数方法和一个新的更大的多视图计数数据集CityStreet。该计数方法提取相机视图信息,使用给定的相机参数将其投射到3D 场景中的平均高度平面上,对投影的特征进行融合和解码,在平均高度平面上预测场景级密度图。文献[42] 提出了一种基于三维高斯核的多视图融合的三维计数方法。该方法没有使用平均高度投影,而是使用多高度投影对人物的头部、身体和脚的等特征进行空间对齐,使用三维高斯核生成三维人群密度图,提供人群在三维空间的分布。将三维密度预测图反投影到每个相机视图,并与相机视图的二维地面真实密度图进行比较,定义投影一致性损失来提高准确性。
2 大区域场景下基于无人机的目标计数方法设计
本文的方法结构如图1 所示。在特定场景下进行数据采集,将采集到的多帧连续图像输入到配备有空间转深度(space to depth,STD)机制方法的检测器的主干和颈部,该方法专门用于检测非常小的物体。然后设计了一种针对临海区域图像特点的拼接方法,应用该方法有效解决临海区域图像拼接出现的问题。最后,根据本文提出的公式,将二维目标检测信息投影映射到拼接图像中进行目标计数。
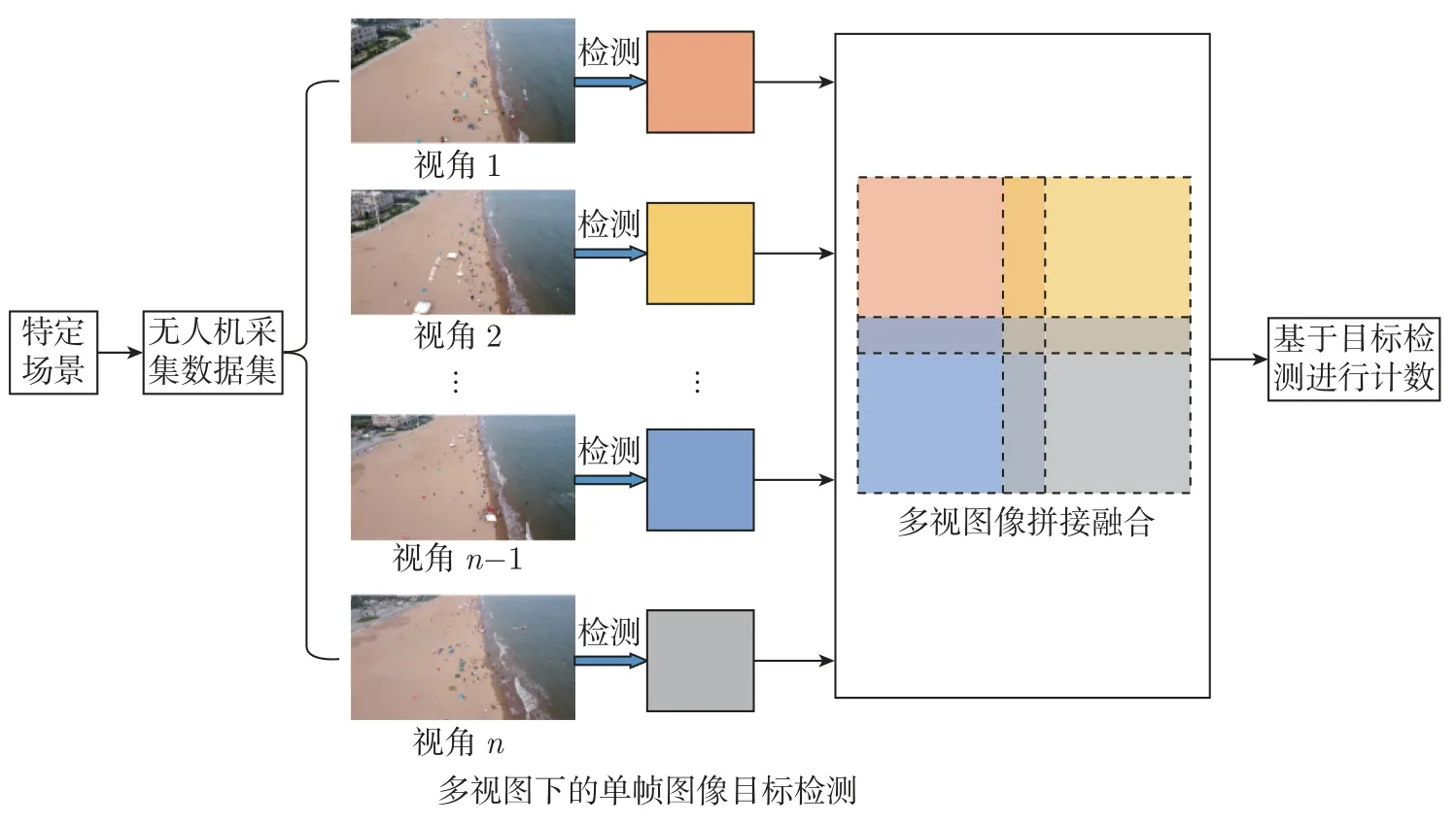
图1 广域多视角目标计数方法的总体过程Figure 1 Overall process of the wide-area multi-view object counting method
2.1 无人机目标检测网络设计
卷积神经网络在物体检测等许多计算机视觉任务中取得了巨大成功。然而,在无人机目标检测任务中卷积神经网络的性能会迅速下降。这是因为,当无人机超过一定飞行高度拍摄图像时会捕获更多更小的目标,且航拍图像分辨率高,包含大量无关的背景信息。同时,现有的卷积神经网络架构使用跨步卷积或池化层,导致细粒度信息的丢失和无效特征表示的学习,直接影响对小目标的检测。
本文针对无人机数据存在目标小且清晰度低的问题,引入STD-Conv[43]模块来取代每个跨步卷积层和每个池化层,加强对细粒度信息的学习,一定程度提升模型的小目标对象检测性能。STD-Conv 是由一个空间到深度的层和一个非跨步卷积层组成。本文所引入的STD-Conv组件将原始图像转换技术[44]推广到卷积神经网络内部和整个卷积神经网络中的特征图下采样部分,如图2 所示。将该方法应用于YOLOv5 方法中,只需用STD-Conv 构建块替换YOLOv5 中步长为2 的卷积。因为在YOLOv5 中主干网络使用了4 个步长为2 的卷积,颈部使用了2 个步长为2 卷积,所以需要替换6 个卷积。
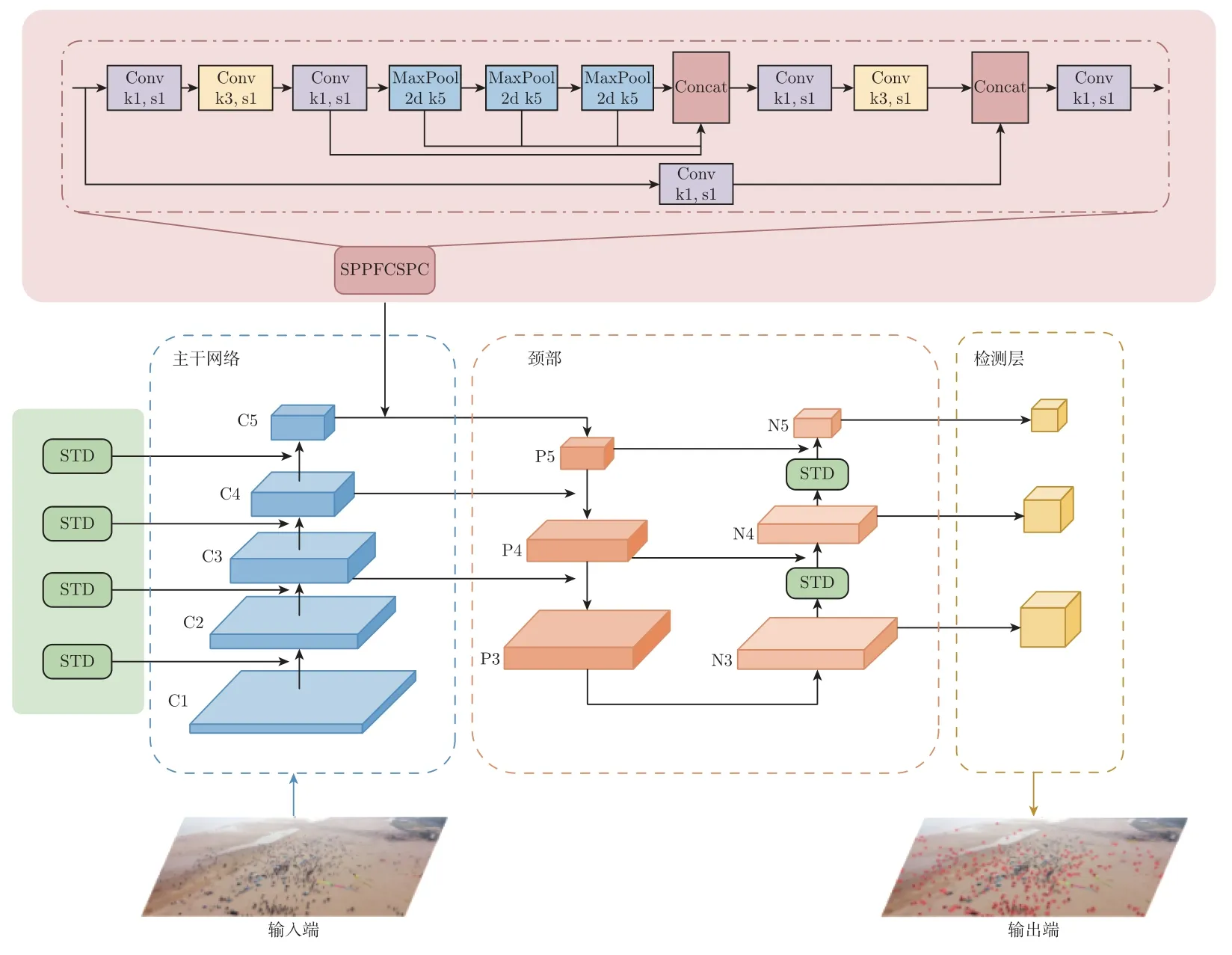
图2 无人机目标检测网络结构Figure 2 Structure of UAV target detection network
针对无人机图像背景信息冗余和图像特征重复提取的问题,本文借鉴快速空间金字塔池化(spatial pyramid pooling-fast,SPPF)结构的设计思想,将空间金字塔池化交叉阶段局部连接(spatial pyramid pooling cross stage partial connection,SPPCSPC)结构模块优化得到快速空间金字塔池化交叉阶段局部连接(spatial pyramid pooling fast cross stage partial connection,SPPFCSPC)结构,即在最后一个卷积层上添加一个SPPFCSPC 层来消除网络固定大小的约束。SPPFCSPC 层汇集图像特性并生成固定长度的输出至完全连接的层或其他分类器。换句话说,在卷积层和完全连接层之间执行一些信息“聚合”,以避免在开始时进行裁剪或缩放。图2 展示了SPPFCSPC 层的具体结构。在保持感受野不变的情况下,有效避免了因对航拍图像区域裁剪、缩放操作导致的图像失真等问题,解决了卷积神经网络对图像相关特征重复提取的问题,大大提高了产生候选框的速度,节省了计算成本。
2.2 临海区域图像拼接
受无人机高度和相机参数的限制,无人机拍摄的单幅图像视野有限。要获取临海区域的全面情况就需要对无人机拍摄的图像进行拼接,得到全景图像。拼接算法通常需要对图像的特征点进行提取,再进行特征匹配,但由于受风和海浪的影响,靠海区域表面不同时刻具有不同的表面形态,且临海区域(如沙滩)表面高度相似,特征不明显,与建筑物等其他地表物体相比有着巨大差异,在特征匹配时不同图像中的特征点很难匹配成功,从而导致拼接错误或失败。为此本文设计了针对无人机临海区域图像特点的拼接算法,根据相似性度量拼接融合损失迭代的方法优化拼接结果。在多视角的拼接过程中,首先提取每幅影像的特征点,引入无人机拍摄图像中的定位信息进行特征匹配拼接,多视图中特征点的匹配是其中的关键步骤。如图3 所示,EXIF 标签是指图像中的GPS 或者更高精度的实时动态差分定位(real-time kinematic,RTK)定位信息,利用其中的位置信息可以减少大量不必要的图像之间的匹配,减少匹配错误,提高匹配精度以及效率。然后根据Loss 函数调整优化,不断迭代得到最终的拼接图像。最后,将图像映射到地图的实际位置上进行定位。
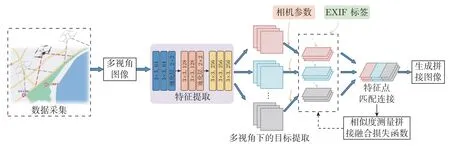
图3 图像拼接流程Figure 3 Image stitching process
2.3 目标计数统计
本文提出将航拍图像中的二维目标检测结果映射到地理位置坐标,定位目标在区域中的分布情况,并利用最大值选择算法保留同一目标的一次映射结果,进而统计场景中的目标数量。
2.3.1 二维目标检测信息映射至全局图像
首先,通过GPS、惯性测量单元(inertial measurement unit,IMU)和相机的标定参数等获取航拍图像的位置和姿态信息。本文已知航拍图像的位置坐标和姿态信息,航拍高度为30 m,相机俯仰角为30°,方位角为0°。其次,利用相机的内外参数和地面控制点等信息使用摄影测量技术计算出每个像素点在地理坐标系下的坐标,将航拍图像转换为地理坐标系下的影像。最后,使用提出的检测算法在航拍图像中检测目标,并得到其在像素坐标系下的边界框坐标(xmin,ymin,xmax,ymax),进而将二维目标检测结果映射到地理坐标系下的坐标,公式为
式中:ox和oy是影像左上角像素在地理坐标系下的坐标;xgeo和ygeo是目标在地理坐标系下的坐标;gr是地面分辨率,具体是指航拍图像中一个像素所代表的地面距离,通常用m/像素表示。获取地面分辨率的具体方法取决于航拍系统和传感器的参数设置,可以通过相机的焦距和像素大小计算得到,以无人机航拍为例,获取地面分辨率的公式为
式中:h为无人机相对地面的高度;f为相机的水平视场角;s为相机传感器的对角线长度。在目标检测中,地面分辨率的大小直接影响到目标在图像中的尺寸和位置,因此需要准确地估计地面分辨率。
根据需要可以将地理坐标系下的坐标转换为经纬度坐标系,利用经纬度的唯一性,在多视角的图像中对同一目标检测结果的重复映射进行去重,以满足计数应用的需求。
需要注意的是,这个过程需要精确的相机标定、IMU 数据以及地面控制点等信息,并且需要进行高精度计算以保证结果的准确性。
2.3.2 去重计数
为了更加真实准确地估计出大区域场景中的目标数量,在映射有二维目标检测信息的全局图像中设置非极大值抑制参数。对于每个目标检测框,计算其置信度得分,将所有的目标检测框按照置信度得分从高到低进行排序;选择置信度得分最高的目标检测框,并将其保留作为最终检测结果。遍历剩余的目标检测框,计算其与已选框的重叠率。如果重叠率大于设定的阈值(通常为0.5),则将该框从候选框列表中删除。返回最终保留的目标检测框作为最终的检测结果。具体公式为
式中:parea为重叠率;(Ax1,Ay1) 和(Ax2,Ay2) 分别表示边界框A的左上角和右下角的坐标;(Bx1,By1) 和(Bx2,By2) 分别表示边界框B的左上角和右下角的坐标。
将重叠率与设定的阈值进行比较后决定是否保留该目标检测框。重叠率越大,说明两个边界框重叠程度越高,越可能是同一个目标,因此应该删除其中一个。反之,如果重叠率较小,则可以保留两个边界框作为独立的目标。
通过对检测到的目标进行置信度排序,消除与较高置信度目标有重叠的且置信度较低的目标,可以有效减少重复计数的情况。
3 实验
3.1 无人机目标检测网络
3.1.1 数据集
在常用的无人机公开数据集中大部分图像为低空俯瞰视角,例如Visdrone 数据集,如图4 所示。无人机拍摄高度不够高,并且小目标较少,尺度变化不大,航拍存在的问题并没有完全体现出来。所以本文基于大疆系列无人机平台在不同高度和不同角度进行数据收集,制作了OUC-UAV-CC 数据集作为补充。该数据集主要以沙滩及其海边等场景为主,小目标占比高,具有更高分辨率和更密集的对象分布,能够更好地检验出算法模型的鲁棒性和有效性。图5 展示了数据集中带标注的图像的一些示例。

图4 VisDrone 数据集中图像的低空视图Figure 4 Low altitude view of an image in VisDrone dataset

图5 OUC-UAV-CC 数据集中的标注图像Figure 5 Annotated images in OUC-UAV-CC dataset
OUC-UAV-CC 数据集由1 507 幅图像和116 988 个对象实例组成。根据训练集、验证集和测试集的数据相同分布原则,本文在1 507 幅初始图像中以6∶2∶2 的比例随机分割训练集、验证集和测试集中的数据。根据本文的需要,选择了“人”作为标签类别。OUC-UAV-CC 数据集和VisDrone 数据集的比较如表1 所示。由表1 可知,OUC-UAV-CC 数据集和VisDrone数据集的小目标(32×32 像素)和微小目标(16×16 像素)的占比都较高。本文将在VisDrone数据集和构建的OUC-UAV-CC 数据集上评估提出的方法。

表1 VisDrone 和OUC-UAV-CC 的相关属性比较Table 1 Comparison of relative attributes between VisDrone and OUC-UAV-CC
3.1.2 实施细节
所有实验都是在4 卡Nvidia2080ti(12G)上进行的,在训练和评估过程中,受实验环境和硬件条件的限制,所有输入图像的大小都调整为640×640像素。本文选择基于CNN 的目标检测器作为实验算法,实现了FasterR-CNN[45]、CascadeRCNN[46]、LibraRCNN[47]、CenterNet[48]、TridentNet[49]、ATSS[50]、AutoAssign[51]、FCOS[52]、FSAF[53]、Sabl[54]、TOOD[55]、YOLOF[56]和YOLOv5。对于以上方法,本文均使用官方代码,其中YOLOv5 选择了YOLOv5-l 版本。在VisDrone 和OUC-UAV-CC 数据集上训练时,Epoch设置为300。所有检测器既不使用诸如YOLT 中的图像裁剪之类的预处理策略,也不使用诸如模型集成之类的后处理策略。
3.1.3 实验结果与评价指标
在目标检测中,平均精度(average precision,AP)和全类平均精度(mean average precision,mAP)是两个重要的衡量指标,公式为
式中:Nc 为类别数;mAP 指交并比阈值分别在0.50~0.95 之间每隔0.05 的AP 的平均值。文中mAP50值指交并比阈值为0.50 时的mAP,mAP75值指交并比阈值为0.75 时的mAP,mAPS值指小尺寸目标的mAP,mAPM值指中等尺寸目标的mAP,mAPL值指大尺寸目标的mAP。
本文分别在VisDrone 数据集和OUC-UAV-CC 数据集上对STP-Conv 结构和改进的空间金字塔结构SPPFCSPC 的有效性进行了消融实验,并对实验结果进行了分析。实验结果分别如表2 和3 所示。基于YOLOv5,本文首先研究了STP-Conv 结构对小目标检测性能的影响,表3 和4 中数据显示仅加入STP-Conv 结构,包括小目标检测AP 在内的各AP 值显著提高。接着,本文研究了联合使用了STP-Conv 结构和SPPFCSPC 策略对网络影响。如表3和4 中相关数据说明,利用本文提出的SPPFCSPC 进一步激发了检测器的学习能力,使检测精度达到了最高值。与YOLOv5 相比,本文方法可以使目标检测尤其是小目标检测的精度有较明显提升,验证了所提的无人机目标检测网络是有效的。

表2 在VisDrone 验证集上分步改进的性能Table 2 Step-by-step improved performance on VisDrone verification set

表3 在OUC-UAV-CC 测试集上分步改进的性能Table 3 Step-by-step improved performance on OUC-UAV-CC test set
本文分别在VisDrone 数据集和OUC-UAV-CC 数据集上对提出的方法和其他流行的目标检测算法进行了实验并对实验结果进行了分析。在VisDrone 数据集和OUC-UAV-CC 数据集上的结果分别如表4 和表5 所示。可以看到,无论是在VisDrone 数据集还是在OUC-UAV-CC 数据集,本文提出的算法相比原始的YOLOv5 版本的AP 各指标均有所提高,小目标检测精度的提升较为明显,验证了本文算法的有效性。本文算法的结果同时也超过了其他流行的目标检测算法,进一步说明了本文算法的优越性。
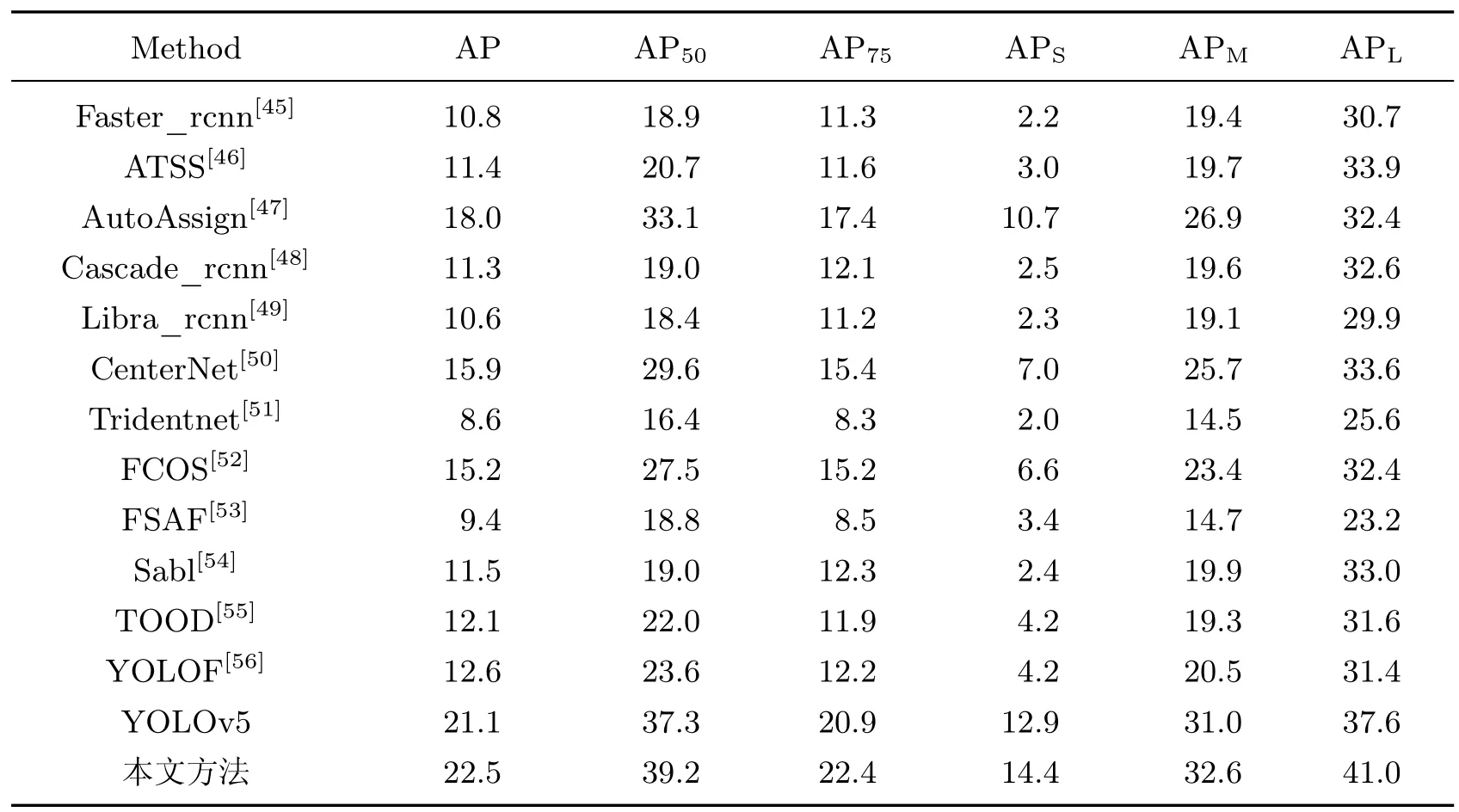
表4 与最先进的探测器在VisDrone 验证数据集上进行比较Table 4 Comparison with state-of-the-art detectors on VisDrone validation dataset

表5 与最先进的探测器在OUC-UAV-CC 数据集上进行比较Table 5 Comparison with state-of-the-art detectors on OUC-UAV-CC test dataset
3.1.4 可视化效果
本文对实验的检测结果进行了部分可视化展示,具体如图6 所示,其中图6(a) 为原始图像;图6(b) 为YOLOv5 的检测结果;图6(c) 为本文方法的结果。与YOLOv5 相比本文的方法可以检测到尺寸更小的目标。

图6 检测结果部分可视化展示Figure 6 Partial visualization display of detection result
3.2 图像的拼接融合
3.2.1 数据集
本节用到的数据是上节构建的目标计数数据集OUC-UAV-CC,同时从公开的无人机数据集VisDroneMOT2021 和数据集UAVDT 中挑选了部分合适的数据作为补充,命名为VisDrone-CC。VisDrone-CC 数据集的部分原图如图7 所示。

图7 来自VisDrone-CC 数据集的图像示例Figure 7 Examples of images from VisDrone-CC dataset
3.3 映射与计数
3.3.1 数据集
本节将上一节中已经成功拼接的图像作为本节实验的数据基础,随后进行一系列的实验,以探索和验证所提算法的有效性,期望能够获得更加准确和全面的研究结果。此外,本节所进行的实验也将帮助后续评估和优化拼接方法,进一步提升其在实际应用中的性能和可靠性。
3.3.2 实验细节
为了统计某场景中的人群数量,该部分将单帧图片的标注信息和目标检测信息分别根据式(1) 和(2) 映射到拼接图像中,进而进行计数。其中由标注信息映射到拼接图像中进行计数的结果作为groundtruth。该部分选择计数精度(Atotal)和计数平均绝对值误差(mean absolute error,MAE)作为评价指标。计数精度(Atotal)是指拼接图像中目标的总数量total的算法预测值c与实际值gt的比值,计数精度描述了计数算法准确度的最终表现性能,公式为
计数MAE 是指拼接图像中目标计数的算法预测值与真实值的累计绝对值误差的平均值,描述了计数算法在拼接图像内准确度的平均值,公式为
式中:Ci表示第i幅人群图像经过人群计数模型处理后输出的人数估计值;为第i幅人群图像的实际真实人数;N为参与此次评估的人群图像数;MAE 反映模型的准确度,指标越小越好。
3.3.3 可视化效果
图8 展示了该部分利用所提方法进行拼接的效果,其中图8(a) 展示了拍摄的单帧图像,图8(b) 展示的是将这些单独的图像经过精细处理后无缝拼接成的一个连续且统一视角的全景图像,可以清楚地看到所提方法在处理多帧图像时的优势。

图8 图像拼接效果显示Figure 8 Display of image stitching effect
3.3.4 结果
本节实验旨在比较本文提出的目标检测算法与YOLOv5 算法的最终计数精度。分别在OUC-UAV-CC 数据集和VisDrone-cc 数据集进行了对比实验,并对实验结果进行分析。表6和7 分别展示了2 个数据集上的对比实验结果。可以看出,在任一数据集上,利用本文提出的检测算法进行计数时所得精度均高于YOLOv5 的精度。这说明了本文检测算法的优越性,并验证了检测精度越高,计数效果越好的结论。

表6 不同检测算法在VisDrone-CC 数据集上的计数表现Table 6 Counting performance of different detection algorithms on VisDrone-CC dataset %

表7 不同检测算法在OUC-UAV-CC 数据集上的计数表现Table 7 Counting performance of different detection algorithms on OUC-UAVCC dataset %
3.4 实验分析
在本文的实验中,我们分别使用YOLOv5 和YOLOv7 对数据集进行测试。通过可视化实验结果发现,与YOLOv5 相比,YOLOv7 在沙滩场景下的检测不够精准,甚至出现了大量误检的现象,这是由于数据集本身存在的问题造成的。与自然数据集相比,本文构建的航拍数据集中目标较小且密集,容易与背景混淆且有大量相似干扰,增加了检测的难度,使得YOLOv7 在该数据集上更容易过拟合。此外,针对实际应用出现的问题,使用基于YOLOv5的网络结构进行改进更为准确。因此,本文提出的方法是在YOLOv5 的基础上进行改进的。
4 结论
本文提出了一种多视点目标计数策略,突破了单帧图像计数的局限性,将目标计数的研究从固定摄像机推进到多视图设置,通过实验也验证了本文方法的有效性。主要工作有以下几点:
1)提出了一种无卷积步长或池化的方法,同时改进空间金字塔结构,设计了新的网络结构,该网络结构更适合于对航拍图像的预测。
2)基于沙滩海域的图像特点,设计了新的图像拼接方法,提出相似性度量剪接融合损失。
3)提出了二维检测信息映射到地理坐标的公式,通过映射到场景级图像中进行计数统计。
4)在VisDrone 数据集上进行实验。新的网络结构在图像尺寸较大且小目标丰富的情况下,将mAP 全部提升1.4%。所提出的计数策略在VisDrone-CC 数据集上进行了实验验证,计数精度提升1.5%。作为VisDrone 的补充,本文构建了一个丰富场景且更能体现航拍图像特征的数据集OUC-UAV-CC。在该数据集上进行实验,所提出的网络结构将mAP 提升了2.2%,计数精度提升了1.7%,证明了所提方法的有效性。
