基于ConvLSTM 的移动边缘计算服务器能耗模型
2024-02-18李小龙杨凌峰
李小龙,李 曦,杨凌峰,黄 华
1.湖南工商大学计算机学院,湖南 长沙 410205
2.湖南工商大学前沿交叉学院,湖南 长沙 410205
随着智能交通[1]、智能医疗[2]、人工智能[3]和虚拟现实[4]等数字产业的进一步发展,计算能力的需求也在不断增加。作为信息产业的支柱,边缘数据中心的数量不断扩大。最新研究[5-6]表明,数据中心的能源需求预计将从2014 年全球总电力消耗的1%增加到2025 年的3%。数据中心频繁产生大量冗余服务,用来维护服务的稳定性和可靠性。然而,服务器的使用具有周期性,这会导致大量资源的浪费[7]。节约数据中心能耗[8-10]不仅可以节约资源和降低数据中心成本,还有助于减少二氧化碳排放。在数据中心的能源消耗中,约52% 用于提供IT设备,38% 用于提供支持IT 设备的冷却系统[11]。冷却系统和支持设施的能源消耗易于管理,而IT 设备的能源消耗占比最多,且随着运行条件的变化而变化。对数据中心的能源消耗进行有效监测和预测可以提高资源利用率和服务质量,节省系统资源。实时的数据中心能耗建模可以为节能优化算法提供指导和依据。
建立一种能够实时准确预测服务器能耗的模型有助于提前了解服务器状态,这对于优化服务器能耗至关重要[12-13]。目前,开发服务器能耗模型的方法主要分为两类:基于资源利用率的建模方法[14-17]和基于性能监测计数器的建模方法[18-25]。
基于资源利用率的能耗模型主要是利用服务器组件(如CPU 和内存)的利用率来构建的。文献[14] 提出了一种边缘服务器的能耗模型,指出服务器的总能耗由处理器、内存、磁盘等组件的能耗组成。CPU 的能耗模型根据处理器的不同状态建立。文献[15] 认为能耗模型可以通过提取处理器、内存、磁盘等组件的主要参数来构建。文献[16] 提出了一种基于基本功率和有功功率确定能耗的预测方法,通过云监测计算获得有功功率,通过硬件测量获得基本功率。实验结果表明,该方法在CPU 测试中的平均误差率为4.22%。文献[17] 提出了虚拟机迁移算法,使虚拟机从主机服务器迁移到客户服务器,降低服务器的总能耗。以上网络的优点是简单方便且易于实现。然而,这些网络仅考虑了服务器的少数参数,缺乏对服务器整体状况的考虑。
近年来,一些学者使用神经网络进行边缘服务器能耗建模和定量评估,因为神经网络可以在复杂条件下提取数据特征,并具有非线性拟合的优势[18-19]。文献[20] 提出了使用长短期记忆循环神经网络(long short-term memory recurrent neural network,LSTM-RNN)模型进行电力生产预测的方法,对光伏电站的发电量进行建模,取得了良好的效果。文献[21] 提出了结合特征选择和神经网络构建能耗模型的方法,将服务器的日常工作模式划分为CPU 密集型、I/O 密集型和WEB 密集型,并通过构建这3 种场景的网络模型验证了模型的有效性。文献[22] 验证了使用反向传播(back propagation,BP)神经网络、Elman 神经网络和长短期记忆神经网络构建的模型在CPU 密集型、内存密集型、I/O 密集型和混合任务类型的工作负载下比多元线性回归和支持向量回归具有更好的性能。文献[23] 提出了一种基于Elman 神经网络的服务器能耗预测模型,可以根据服务器运行过程中的参数预测服务器的能耗。文献[24]使用改进和优化的BP 神经网络对目标用户信用体系进行预测,以完成能源管理系统的现代化改造。文献[25] 基于神经网络和参数选择构建了一种新型的能耗模型,实验结果表明,该模型具有良好的性能。文献[26] 提出基于支持向量机的实时能耗预测方法,可以有效处理工作负载类型的变化,在CPU 密集型、WEB 密集型和I/O 密集型任务上对所提出的模型进行了广泛而全面的评估。
为了有效地测量和评估数据中心的能耗,传统方法使用传感器和其他硬件来监测能耗,但由于可扩展性差且成本高,难以应用于异构数据中心[27-28]。基于软件的监测系统由于经济高效和易于扩展的特点,适用于数据中心复杂的设备环境[29]。本文使用软件收集相关参数,并基于卷积长短期记忆(convolutional long short-term memory,ConvLSTM)神经网络构建服务器能耗模型。具体的工作如下:
1)基于服务器状态建立了一种细粒度的功率模型。与其他仅考虑单一任务状态的功率模型不同,本文考虑了4 种类型,即CPU 密集型、I/O 密集型、内存密集型和混合型。
2)利用熵值法[30]筛选对服务器能耗影响更大的参数,并将其用于后续的能耗建模。
3)利用ConvLSTM 神经网络,提出了一种用于移动边缘计算的服务器智能能耗模型(intelligence server energy consumption model,IECM)。实验结果证实了该模型的准确性和有效性。
1 相关工作
1.1 熵值法
特征数据的选择有多种方式,熵值法是一种客观的权重方法,它根据指标观测值所提供的信息来确定指标的权重。该方法可以用于确定参数的权重,消除一些主观因素的干扰,使结果更加科学和合理。使用熵值法进行综合评估的步骤如下:
步骤1初始值归一化
正向指标为
负向指标为
步骤2计算第j个指标中第i个指标的占比
每个评价指标的熵值可以定义为
式中:k=1/lnm,m为评价对象的数量。如果Yij=0,则排除指标j的评价对象i。
步骤3计算熵的冗余度,其公式为
步骤4计算每个评价指标的权重,其公式为
1.2 LSTM
LSTM 是为解决循环神经网络(recurrent neural network,RNN)长期依赖问题及其可能带来梯度消失和爆炸问题而提出的。LSTM 通过输入门、输出门和遗忘门这3 个关键门单元实现数据传输和处理,旨在保护和控制信息的流动。LSTM 的计算公式为
式中:it、ft和ht分别为输入门、遗忘门和输出门;Wi和bi分别为输入门的权重和偏差;Wf和bf分别为遗忘门的权重和偏差;Wo和bo对应于输出门的权重和偏差;xt、ht-1和ct-1分别表示LSTM 网络中当前单元的输入、上一个单元的输出和状态,运算符“◦”表示Hadamard乘积,σ表示非线性激活函数。
1.3 ConvLSTM
本文使用的ConvLSTM 神经网络与LSTM 具有相同的结构,计算公式为
式中:Xt表示当前单元的输入;Ct-1和Ht-1分别对应于上一个单元的状态和输出;“*”为卷积运算;W表示核为k*k的2D 卷积滤波器;k为卷积核的大小。Wi、bi、Wf、bf、Wo和bo的定义与LSTM 的计算公式类似,但数据维度和处理方法不同。
2 IECM-服务器能耗模型
本部分介绍建立基于ConvLSTM 的服务器能耗模型的过程,包括数据收集、数据分析、特征参数选择、神经网络构建和模型评估。
2.1 能耗建模步骤
服务器能耗建模的过程如图1 所示,包括以下5 个步骤:
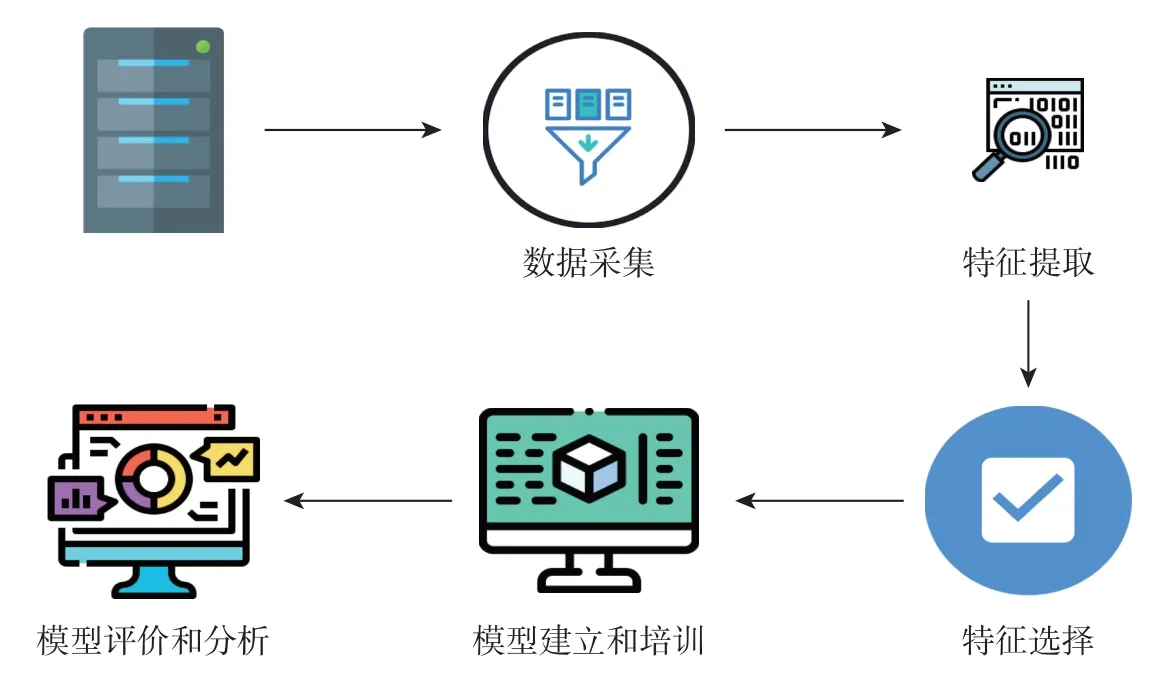
图1 能耗建模过程Figure 1 Process of energy consumption modeling
步骤1在移动边缘计算服务器上安装监控软件,用于实时监测服务器硬件和软件,以获取运行时间数据,此步骤称为数据收集;
步骤2在特征提取阶段,将所需的监测项目保存在监控软件中,并用作后续步骤中的特征参数;
步骤3在特征选择阶段,使用特征选择算法获取特征参数的权重,对于权重极小的参数,若其对结果影响较小,则丢弃,以提高模型准确性;
步骤4在模型建立阶段,使用ConvLSTM 来建立移动边缘计算服务器的能耗模型;
步骤5在模型评估阶段,将服务器工作负载分为CPU 密集型、I/O 密集型、内存密集型和混合型4 种场景,使用建立的模型与其他模型在4 种不同场景下进行比较。
2.2 数据采样过程
为了获取目标服务器的特征数据需要在服务器上设置监测项目。传统的监测项目需要安装硬件监测设备以获取相关参数,这种方法过程复杂、条件受限且代价昂贵。
本文采用软件监测来获取必要的参数。常用的监测软件有Zabbix1、Ganglia2 和Nagios3。Zabbix 支持自定义监测,但在需要传输大量数据时可能会有延迟现象。Ganglia 易于后期大规模扩展,但其没有内置消息系统和告警机制。Nagios 的基础功能较为简单,其监测能力主要由插件提供,需要安装和配置插件拓展功能。基于此,本文选择了具备内置消息系统和警报功能的Zabbix 与支持大规模部署的Ganglia 两个软件进行组合监测,由Zabbix 监测各种系统和应用程序,Ganglia 监测集群中各个节点的状态和性能,以获取全面且完整的监测数据。
2.3 特征数据选择
2.3.1 数据获取
大量的数据不但会增加模型资源开销,而且也会降低模型的准确性。此本文使用熵值法来获取特征选择的参数。在特征选择过程中,如果权重极小,则表示该值对结果影响很小,可以将其移除,以降低服务器负载,提高模型准确性。与其他仅考虑单一任务状态的功率模型不同,本文实验包括的4 种类型(CPU 密集型、I/O 密集型、内存密集型和混合型)涵盖了不同的任务特性和资源需求,能更准确地体现系统在各种场景下的功率消耗情况。实验过程中,将权重低于0.001 的参数丢弃。
本文的实验硬件环境如表1 所示,测试数据集如表2 所示。CPUGrab-Ex 和Mem Test64是常用的服务器CPU 和内存压力测试软件。IOzone 是一个文件系统测试工具,用于测试不同操作系统下系统的读写性能。PCMARK10 中包含了现代工作场所中各种任务的综合测试项目集。表3 列出了所有选定的参数。

表1 实验环境Table 1 Experimental environment

表2 测试数据集Table 2 Data set for the test
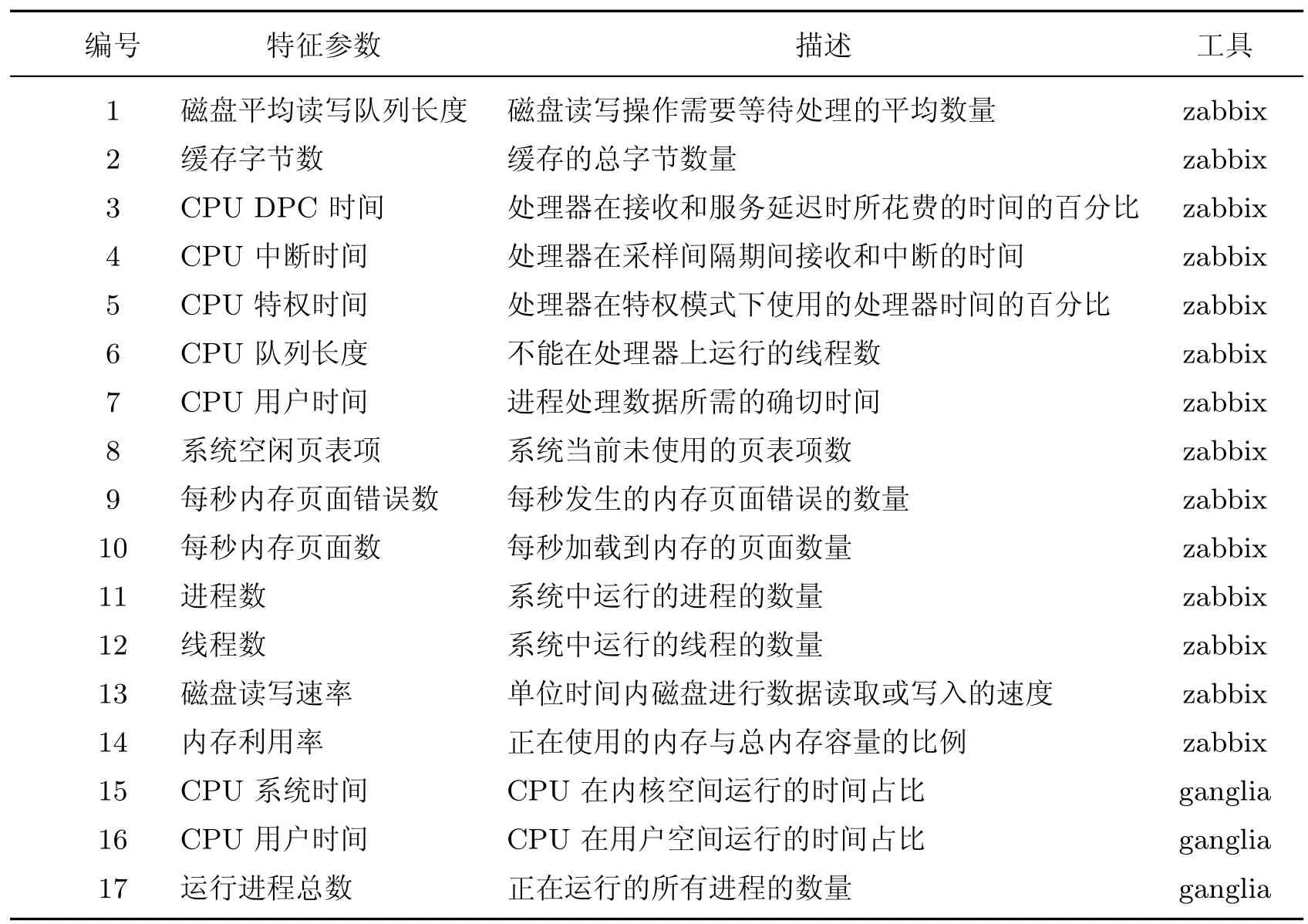
表3 参数解释Table 3 Parameters explanation
2.3.2 数据分析
获取相关实验数据后,通过熵值法进行特征分析和选择。虽然每个实验的特征数据不同,但大多数特征参数都有一定的规律。
表4 显示了4 个实验中权重值前10 的特征参数。在实验中,CPU 利用率和内存利用率表示CPU 和内存的状态,磁盘读写速率表示磁盘的工作状态。
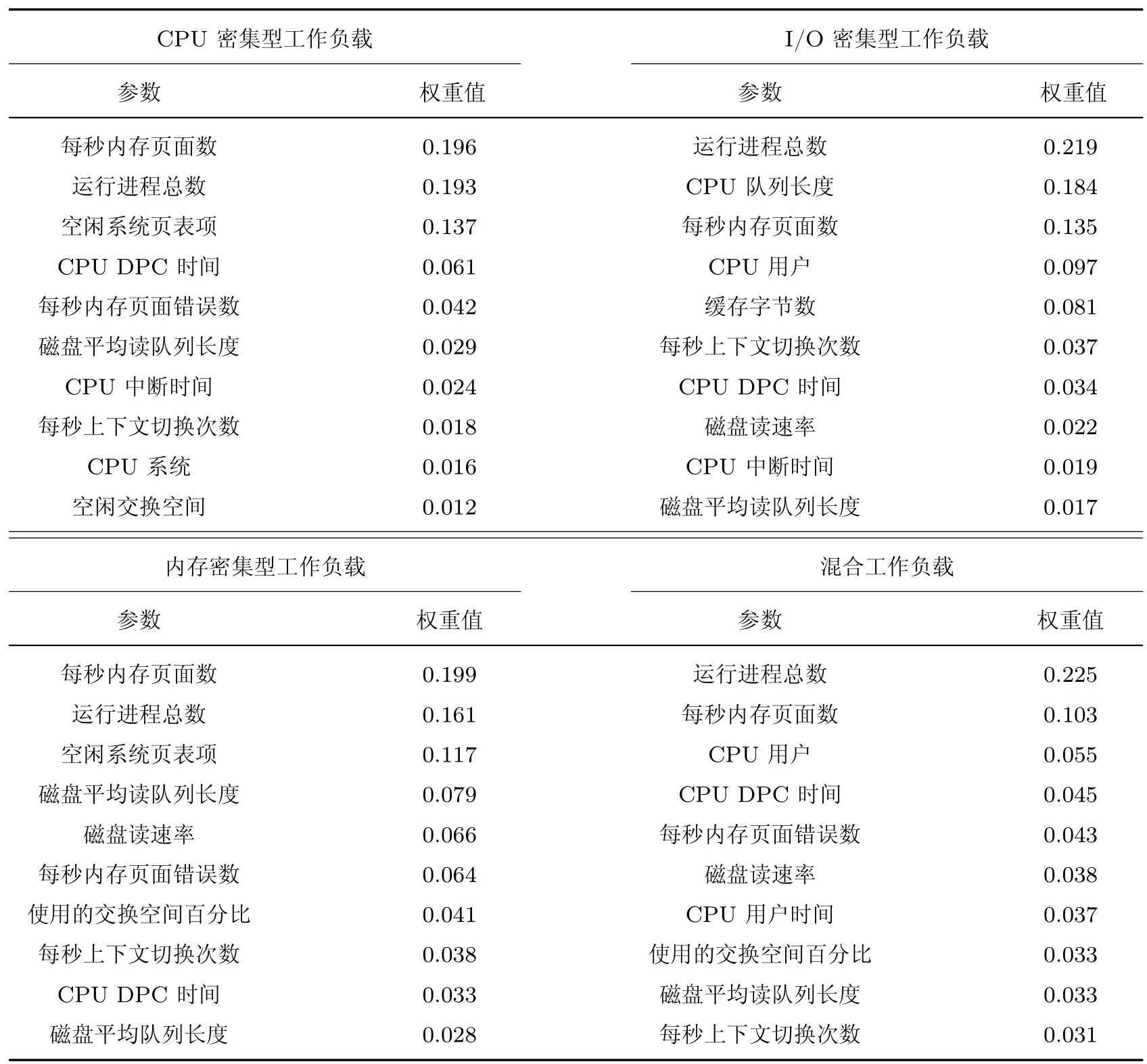
表4 4 种类型工作负载下权重排列前10 的参数Table 4 Parameters of the top ten weights in the four types of workloads
图2 展示了在CPU 密集型负载下3 个主要特征参数和能耗值的趋势。图3 展示了在I/O密集型负载下3 个主要特征参数和能耗值的趋势。图4 展示了在内存密集型负载下3 个主要特征参数和能耗值的趋势。图5 展示了在混合型负载下3 个主要特征参数和能耗值的趋势。
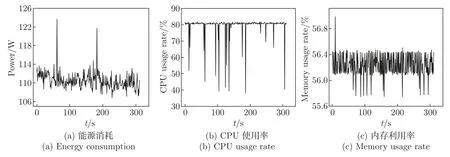
图2 CPU 密集型负载下每个组件的参数值Figure 2 Parameter values of each component under CPU-intensive load

图3 I/O 密集型负载下每个组件的参数值Figure 3 Parameter values of each component under I/O-intensive load
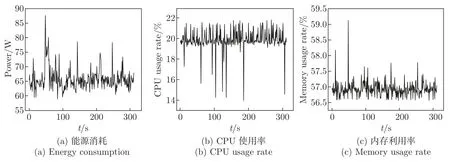
图4 内存密集型负载下每个组件的参数值Figure 4 Parameter values of each component under memory intensive load

图5 混合负载下每个组件的参数值Figure 5 Parameter values of each component under hybrid intensive load
从图2~5 可以看出,服务器的能耗、CPU、内存和磁盘利用率随着负载的波动而变化。然而,这些变化并不满足特定的关系。为了更好地预测和量化服务器的能耗,考虑到ConvLSTM神经网络具有良好的非线性拟合特性[31],选择ConvLSTM 神经网络来对服务器的能耗进行建模。
2.4 IECM 模型
IECM 模型旨在基于LSTM 的数据集中添加学习空间信息的功能。该模型将LSTM 单元中状态与状态之间的矩阵乘法替换为卷积运算,使算法能够处理时空数据,并使用来自本地邻居和先前状态的输入来确定网格中特定单元的未来状态。ConvLSTM 的内部结构和模型图如图6 和7 所示。
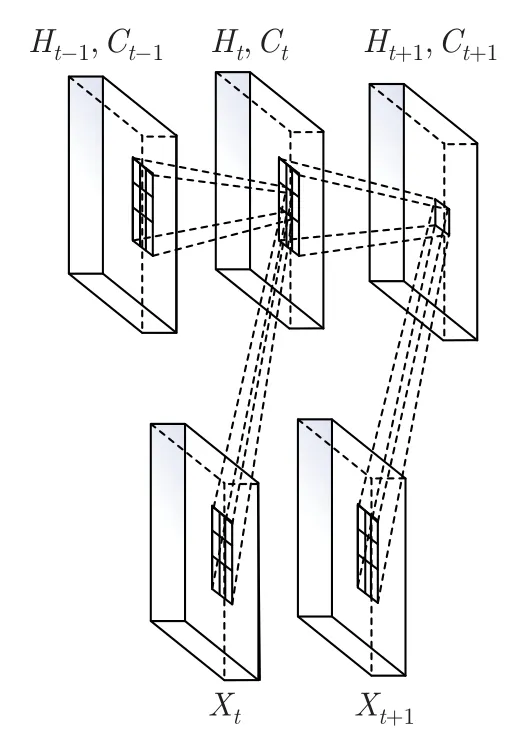
图6 ConvLSTM 的内部结构图Figure 6 Internal structure diagram of ConvLSTM
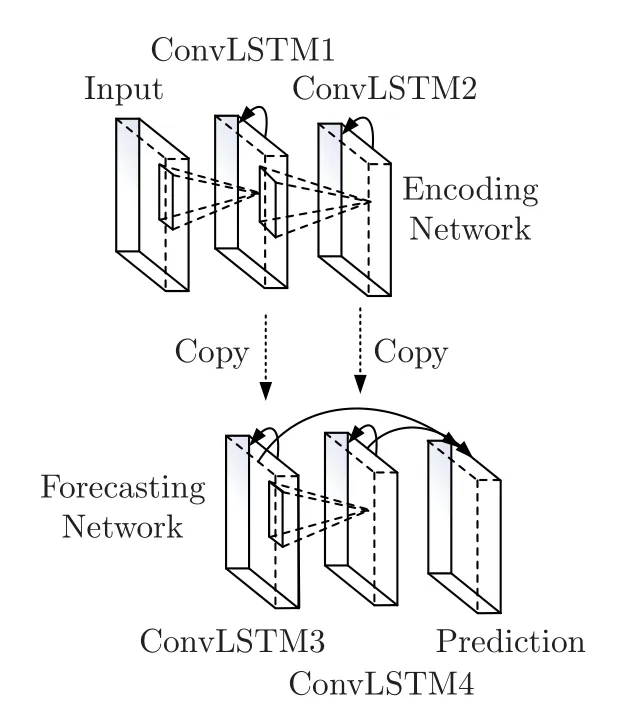
图7 ConvLSTM 的模型图Figure 7 Model diagram of ConvLSTM
3 实验结果与分析
3.1 实验环境
本文实验在CPU 密集型、I/O 密集型、内存密集型和混合型负载下进行。监测软件每秒记录1 次数据,共获得40 个服务器数据项。实验首先使用熵值法计算每个特征数据的权重,并排除一些权重较小的数据;其次对数据进行归一化处理;然后按比例将数据分为训练集和测试集;再使用Python 中Keras 库的ConvLSTM2D 包构建神经网络模型;最后,使用测试集评估模型并验证其性能。为了更好地评估IECM 模型的性能,本文将其与BP[32]、LSTM[33]和多层感知机(multilayer perceptron,MLP)模型[34]进行比较。
3.2 实验结果
为验证提出模型IECM 的优势,图8~11 展示了4 种环境下每个神经网络模型预测值和实际值。可见:CPU 密集型任务的服务器能耗最高,因为处理器消耗的能量比内存和I/O 组件多;BP 和LSTM 模型主要提取数据的时空特征,预测性能相对理想;MLP 模型的准确性处于中等水平,其深度学习速度较慢,容易陷入局部最优。IECM 模型整合了时间性和空间性,在4 个实验中比其他3 个模型的性能效果更佳。此外,IECM 模型采用熵值法选择了更多的参数,提高了模型的准确性。

图8 在CPU 密集型工作负载下4 种算法的能耗比较Figure 8 Energy consumption comparison of the four algorithms under the CPU-intensive workload
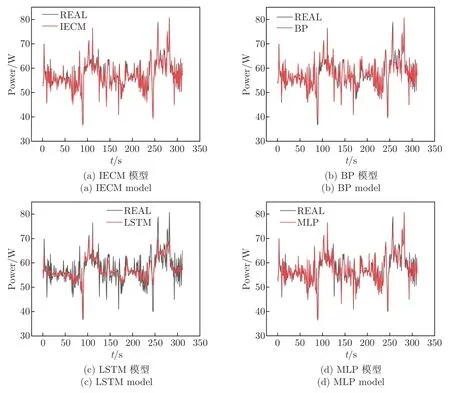
图9 在I/O 密集型工作负载下4 种算法的能耗比较Figure 9 Energy consumption comparison of the four algorithms under the I/Ointensive workload

图10 在内存密集型工作负载下4 种算法的能耗比较Figure 10 Energy consumption comparison of the four algorithms under the memory-intensive workload
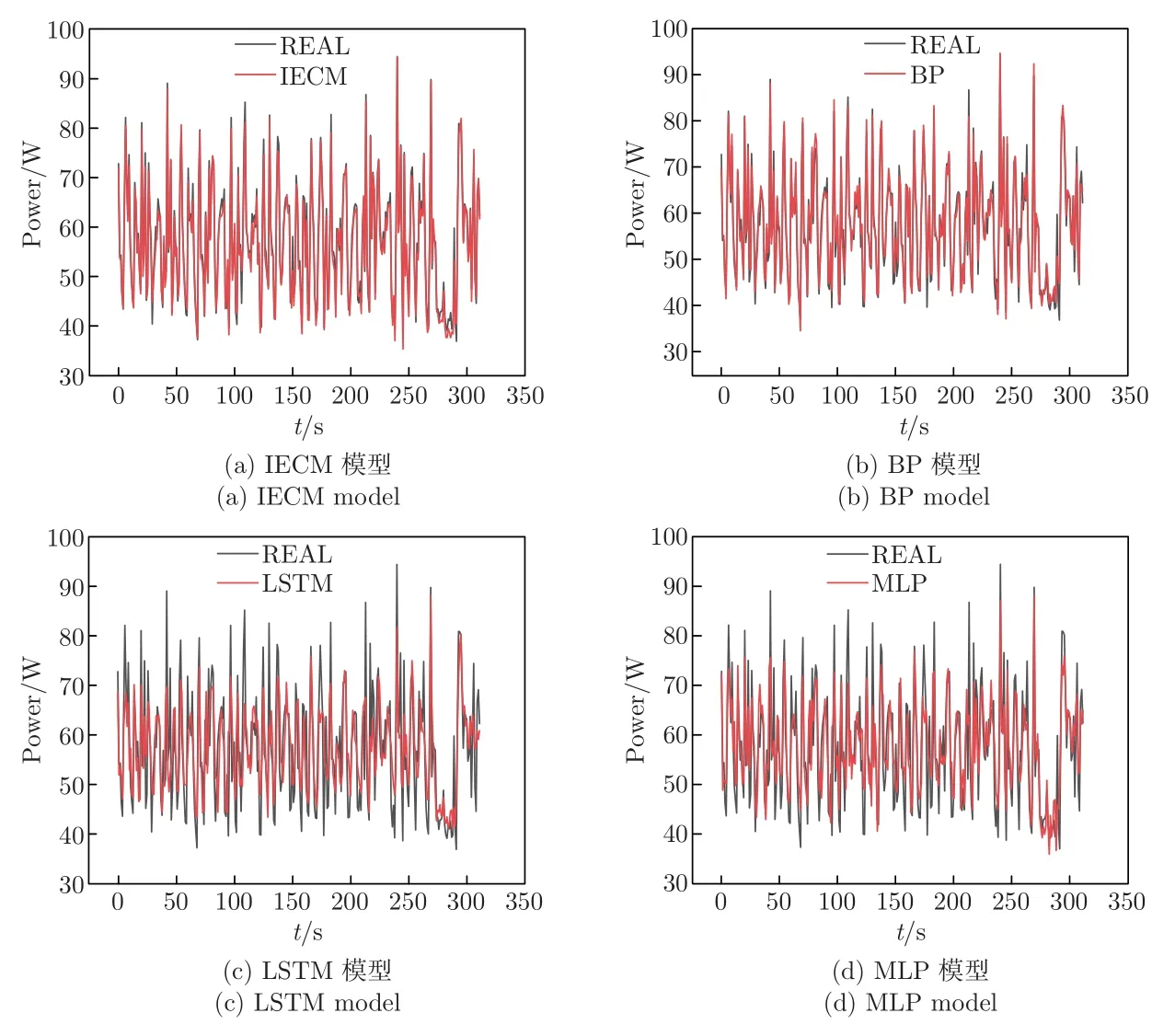
图11 在混合工作负载下4 种算法的能耗比较Figure 11 Energy consumption comparison of the four algorithms under the hybrid workload
通过4 个实验的比较,在混合型实验中每个网络的表现都不如其他3 个网络,因为混合型实验具有更多的变量,更难预测。
图12 和13 展示了4 种模型(BP,LSTM,MLP 和IECM)在不同负载下的平均绝对误差(mean absolute error,MAE)和平均相对误差(mean relative error,MRE)。如图12 所示,IECM 在4 个实验环境中的MAE 值分别为0.72、0.76、0.92 和1.50,MAE 方面IECM 优于其他3 个能耗模型。如图13 所示,IECM 在4 个实验环境中的MRE 率分别为0.69%、1.33%、1.41% 和0.03%,与其他3 个能耗模型相比IECM 更好。BP 模型主要用于提取数据的空间特征,而LSTM 主要用于提取数据的时间特征。在CPU 密集型条件下,BP 模型的效果与LSTM 相似。然而,在I/O 密集型和内存密集型工作负载下,BP 模型的效果明显优于LSTM。MLP 模型由于其学习速度慢、容易陷入局部最优而处于中等水平。IECM 模型采用熵值法且选择了更多的参数,整合了时间性和空间性以提高模型的准确性和鲁棒性。

图12 MAE 比较Figure 12 Comparison of MAE
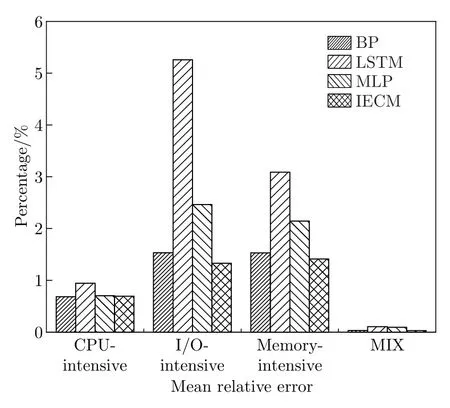
图13 MRE 比较Figure 13 Comparison of MRE
4 结语
本文针对现有能耗模型对动态工作负载波动的低敏感性和低精度问题,提出了一种基于ConvLSTM 神经网络的移动边缘计算服务器能耗模型,有效评估和量化边缘数据中心服务器的能耗。该模型使用熵值法筛选影响服务器能耗的参数,以此消除主观因素的干扰,提高结果的合理性和科学性。针对服务器工作负载动态变化的问题,利用熵值法选定的参数使用ConvLSTM 神经网络训练和构建准确的功率模型。在CPU 密集型、I/O 密集型、内存密集型和混合型4 个数据集上的实验结果表明:IECM 具有高精度和良好的鲁棒性。基于本文工作,未来的研究点在于实时监测和控制服务器能耗,以提高服务器性能和效率为目标,构建准确、稳定的多目标模型,在此基础上扩充多种硬件环境下的对比实验,使模型的建立更加全面科学。
