基于APF-LSTM-DDPG算法的移动机器人局部路径规划
2024-02-15李永迪李彩虹张耀玉张国胜周瑞红梁振英
李永迪,李彩虹,张耀玉,张国胜,周瑞红,梁振英
(山东理工大学 计算机科学与技术学院,山东 淄博 255049)
近年来,深度学习DL(deep learning)[1]和强化学习RL(reinforcement learning)[2]成为人工智能领域的热门。传统的强化学习用于机器人路径规划时,不能适应环境复杂度高的状况;而深度学习具有较强的感知能力,能够适应更加复杂的问题,但是决策能力稍欠缺。将深度学习和强化学习相结合的深度强化学习DRL( deep reinforcement learning)[3]算法, 取长补短,具有二者的感知优势和决策优势[4],目前在移动机器人路径规划[5]技术中得到了广泛应用。
DDPG[6]是将DPG(deterministic policy gradient)和神经网络相融合的策略方法。DDPG算法具有多维特征提取能力,能从样本中习得避障经验,具备一定的泛化能力,可根据不同的环境选择合适的避障策略[7-8]。周盛世等[9]在DDPG算法的基础上结合人工势场法设计了回报函数,但并未对模型收敛效果进行探讨;Wang等[10]在Q学习[11]中添加LSTM层用于Q函数的近似过程,提高了算法的鲁棒性;Lobos-Tsunekawa等[12]基于DDPG算法和LSTM,记忆地图障碍物位置并实现双足机器人避障,但在算法收敛速度方面讨论较少;袁帅等[13]在算法感知端引入LSTM,将障碍物状态信息作为输入,提高了记忆和认知障碍物的能力,但未对复杂环境进行验证;杨秀霞等[14]采用基于LSTM和速度障碍法的DDPG避障方法,解决了算法无法表示不同数量障碍物的状态信息的问题,提高了泛化能力,但未对算法训练效率进行讨论。
本文针对上述问题,对DDPG算法进行改进。引入LSTM结构,将移动机器人搭载的激光雷达的探测信息、机器人的状态信息以及机器人当前位置与目标点的距离和角度作为网络的输入,角速度和线速度作为输出,遗忘和记忆样本信息;结合人工势场法[15],赋予目标点和障碍物对机器人的引力和斥力,设计势场奖惩函数,解决环境奖励稀疏的缺点;利用势场的合力对机器人的角速度进行调节,减少路径冗余路段。
1 算法原理分析
1.1 DDPG算法原理
DDPG算法基于Actor-Critic算法[16]框架,与DQN算法结合,使用卷积神经网络[17]模拟策略函数和价值函数,算法训练使用深度学习的方法,准确模拟非线性函数,并且在高维度动作空间下有较好的收敛性。
策略π是动作概率分布的映射,而确定性策略π去掉了概率分布,只取最大概率的动作,定义为
πθ(s)=a,
(1)
式中θ为确定性策略π的参数,目标是寻找一个θ使动作策略π的选择最优。
在DDPG算法中,智能体与当前环境进行交互从而获取当前时刻的状态信息,通过神经网络对获取的信息进行分析,输出智能体要执行的动作策略,智能体行动后与环境交互获得反馈,再对反馈后的各个动作策略进行评价,最后更新神经网络的参数。DDPG算法框架如图1所示。
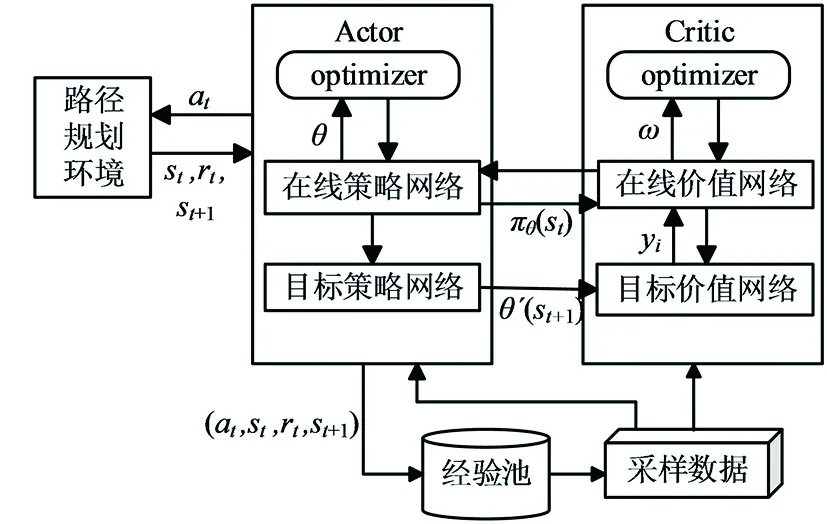
图1 DDPG算法框架
在Actor网络中,在线策略网络负责根据当前的状态信息st选择要执行的动作at,智能体执行动作后生成下一时刻的st+1和奖励rt;目标策略网络负责根据从经验池中抽取的采样数据选择下一步执行的动作at+1,并更新网络参数θ。计算公式为
θt+1=θt+αθπ(st,θ)[∇atQ(st,at,ω)]a=πθ(s)。
(2)
在Critic网络中,在线价值网络负责根据获取的当前时刻的状态st和动作at计算网络的Q值,并更新目标价值yi和网络参数ω;目标价值网络负责更新网络参数ω′,计算st+1的Q值Q(st+1,at+1,ω′)。网络参数ω和目标Q值yi的更新公式为:
ωt+1=ωt+αω[yi-Q(st,at,ω)]∇ωQ(st,at,ω),
yi=rt+γQ(st+1,at+1,ω′)。
(3)
1.2 人工势场法
人工势场法是移动机器人路径规划常用的方法,其原理是在环境中设置人工引力和斥力,使目标点和障碍物分别产生对机器人的引力和斥力,越靠近目标点引力越大,方向始终朝向目标点;越靠近障碍物斥力越大,方向从障碍物指向机器人。通过引力和斥力的合力作用使机器人在运动过程中有方向引导,最终避开障碍物,到达目标点。
引力势场函数Uatt表示为
(4)
式中:ηa为引力系数,始终大于0;ρ(qgoal,q)为当前机器人与目标点的距离。
斥力势场函数Urep表示为
(5)
式中:ηr为斥力系数;ρ(q,qobs)为机器人与障碍物的实时距离;ρ0为障碍物的安全距离,当障碍物进入这个范围就会受到斥力势场影响。
总势场U和机器人受到的合力F为:
(6)
2 APF-LSTM-DDPG算法设计
为提高训练速度和稳定性,本文提出了APF-LSTM-DDPG算法。基于DDPG算法,结合LSTM和人工势场法,设计势场奖惩函数作为前期的辅助,加快训练速度;利用人工势场法调整算法的动作选择策略,提升所规划路径的平滑程度,并减少路径长度。APF-LSTM-DDPG算法包含了连续的状态空间和动作空间[18]、奖惩函数以及网络结构的设计。
2.1 连续的状态空间和动作空间设计
移动机器人模型如图2所示。

图2 Turtlebot3机器人模型
使用两轮差分的Turtlebot3作为移动机器人仿真模型,搭载全方位的雷达传感器,机器人结构和其激光雷达数据采集结构如图3的(a)和(b)所示。

(a) Turtlebot3机器人结构图
图3(a)中θ是机器人当前行进方向Or_head与目标点方向Ogoal的夹角,θ∈[-π, π];机器人与周围环境中的障碍物相关信息通过激光雷达获取,使用机器人前方180°的探测范围和10个方向上的雷达数据。
在仿真环境中,机器人当前位置、行驶角度和速度信息由定位系统获取,机器人的位姿信息由激光雷达测距信息di以及机器人与目标点之间的距离ρ(qgoal,q)和角度θ组成,状态空间st定义为
st=(d1~d10,ρ(qgoal,q),θ)。
(7)
机器人在行驶过程中遇到障碍物需改变方向来避障,通过改变线速度和角速度来控制转弯幅度,线速度的取值范围为[0.0, 0.22],单位m/s;角速度的取值范围为[-2.0, 2.0 ],单位rad/s。机器人的运动过程如图4所示。
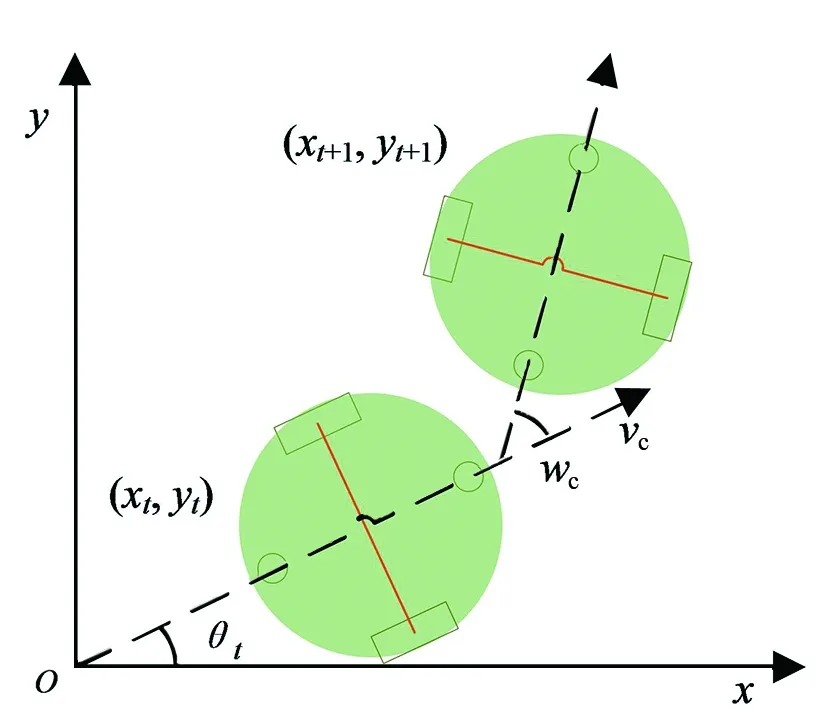
图4 机器人运动过程
图4中,(xt,yt)为在t时刻机器人的坐标,θt为t时刻机器人行进朝向和x轴正方向的夹角,当前时刻的机器人位姿信息pt定义为
pt=[xt,yt,θt]T,
(8)
机器人的运动学模型为
(9)
式中:T为机器人采样周期,(xt+1,yt+1,θt+1)是根据t时刻的位姿信息和运动信息计算而来,[vc,wc]表示当前机器人的线速度和角速度。则移动机器人动作空间A定义为
A=(vc,wc)。
(10)
2.2 势场奖惩函数设计
在训练初期,DDPG算法会选择随机动作策略而探索不必要的区域,致使算法收敛时间长且不稳定,设计连续的势场奖惩函数,以提高学习效率。
当机器人与目标点的距离ρt小于目标点范围cg,或离最近障碍物距离minx小于障碍物碰撞距离co时给予相应奖励:
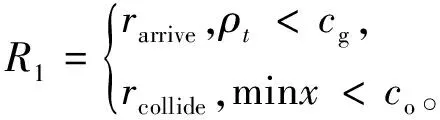
(11)
根据机器人在运动过程中与目标点的距离dt变化量给予相应奖励:
(12)
在训练前期会随机选择多余动作,造成机器人行进方向频繁变化而增加多余训练,增加累计转角和θs的相应奖励:
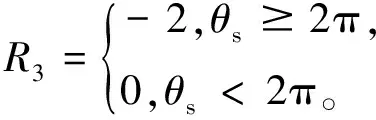
(13)
在机器人进入一个或多个障碍物的斥力势场范围cr时会给予斥力奖励,奖励与距离正相关:
(14)
式中di为机器人与第i个障碍物的距离,当机器人离开斥力势场范围后奖励为0。
奖惩函数包括到达目标点和触碰障碍物的奖励R1、距离变化量奖励R2、转角和奖励R3以及斥力奖励R4,在训练前期势场作为辅助,能够快速学习避障到达目标点,随着训练的增加,权重k逐渐增大。所以总的奖励函数设置为
R=R1+R2+R3+(1-k)R4。
(15)
2.3 基于LSTM的网络结构
APF-LSTM-DDPG算法在Actor网络和Critic网络的基础上增加了LSTM网络层。
如图5所示,LSTM用于处理移动机器人状态信息。在每一时刻t,将机器人状态信息Ct-1=(s1,a1,...,sn,an)作为LSTM的输入序列,经过遗忘门提取关键信息后存储在ht。在经验池中保存数据时将表现较好的样本存入,为后续更新Actor网络和Critic网络提供样本数据。所有障碍物的状态信息输入后,将存储在ht中的数据维度转换为状态向量ht:
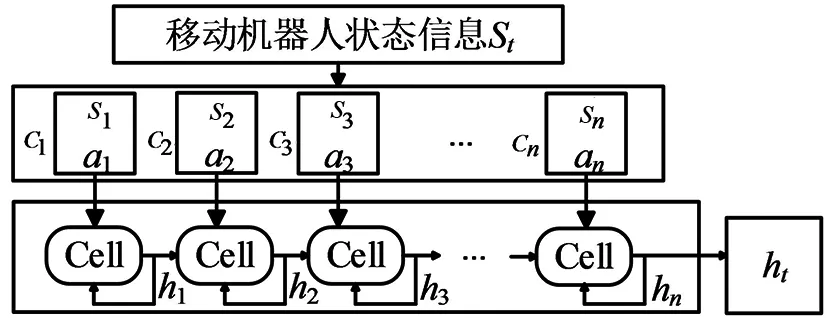
图5 LSTM处理数据模型
(16)
移动机器人的当前状态st经过LSTM处理后作为APF-LSTM-DDPG网络的输入ht,输送给Actor网络和Critic网络的全连接层。
如图6所示,APF-LSTM-DDPG神经网络由四层网络组成。第一层为LSTM层,包含两个隐含的LSTM记忆单元,以获取时间序列信息,对当前状态信息和上一时刻的状态信息的遗忘和记忆;第二、三层为全连接层,包含512个神经元节点,将LSTM处理后的状态信息作为输入;第四层为全连接层,输出发送给机器人的角速度和线速度。Actor网络和Critic网络的隐藏层相同,Critic网络给出机器人当前状态和动作的Q值。

图6 APF-LSTM-DDPG网络结构
APF-LSTM-DDPG算法包含14个输入和2个输出,其中10个方向的雷达信息和线速度、角速度以及与目标点距离和角度为输入,机器人执行的动作为输出。如图7所示。
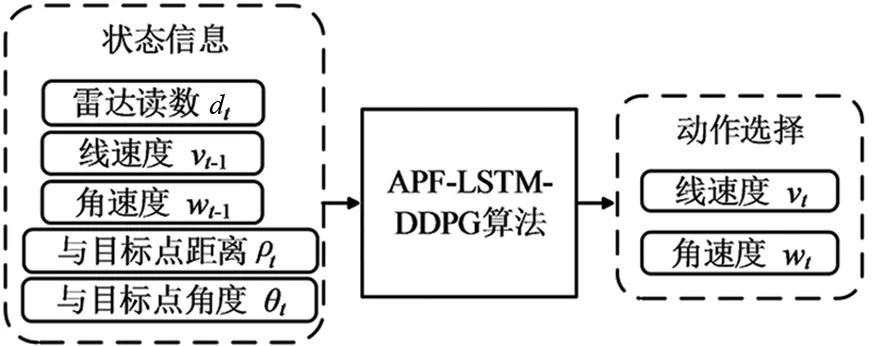
图7 APF-LSTM-DDPG算法的输入输出
2.4 融合路径规划算法
机器人通过APF-LSTM-DDPG算法选择动作与环境交互,交互后得到状态信息并存入到经验池中作为样本,在移动过程中受到人工势场法干预。算法在训练时从经验池中随机采样n个样本,经LSTM单元处理数据后进行网络的更新。改进后的算法流程如图8所示。
为减少算法选择冗余动作,利用人工势场法为动作的选择做引导。当移动机器人周围存在障碍物时受到斥力Frep,靠近目标点时受到引力Fatt,通过合力F引导机器人的运动行为。机器人受力分析如图9所示。
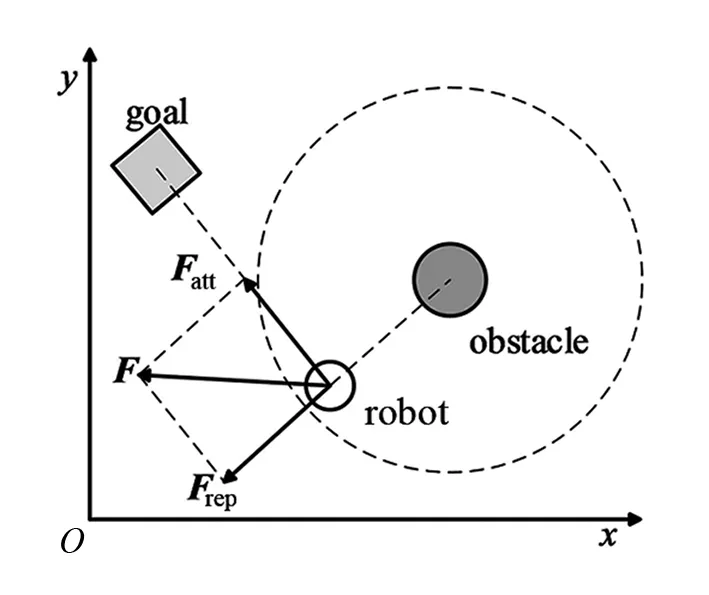
图9 机器人受力分析
如果机器人到达势场区域,基于人工势场法,根据当前移动机器人受到的合力F来修正其角速度,表达式为
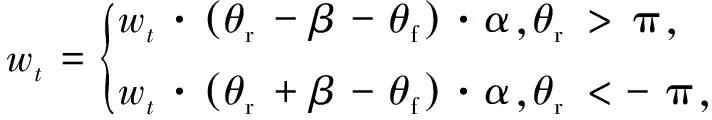
(17)
式中:θf是机器人以自身为坐标受到合力的角度,θr为当前机器人朝向的角度,α=0.3为调节系数,β=2π,(θr-β-θf)和(θr+β-θf)为机器人朝向与合力方向外角的差值。
2.5 迁移学习
局部路径规划中的大部分任务存在相关性,在不同地图环境中利用参数迁移来初始化相关任务中的参数,可以加快移动机器人在不同场景下策略的学习。
训练开始阶段加载初始模型,获取全部的模型参数。通过随机初始化训练获得趋向目标点的模型参数ωi,将ωi初始化为离散场景ωs,再将离散环境下的模型参数初始化为特殊障碍物场景ωt,完善避障规则Vs与Vt,实现局部路径规划。本文所设计的的迁移学习结构图如图10所示。

图10 迁移学习结构图
3 仿真验证
为验证所设计的APF-LSTM-DDPG算法在机器人路径规划中的有效性,基于Python语言,在ROS平台上利用Gazebo搭建不同的3D仿真环境:离散型障碍物、一型障碍物、U型障碍物和混合障碍物环境,进行模型的训练。
为更清晰地观察实验结果,将绘制两种算法训练的每轮平均奖励对比图,横坐标为训练的迭代次数,设为n,纵坐标为迭代到第n轮时本轮的平均奖励,设为r;将机器人和仿真环境实时投影在Rviz软件中显示,并绘制出机器人行走的轨迹。在Rviz中,机器人所在位置为起点,绿色方框代表目标点,黑色圆柱体代表障碍物,蓝色实线代表规划的路径轨迹。
在Gazebo中搭建训练环境,设置并初始化APF-LSTM-DDPG算法的参数,使移动机器人经过训练学习到绕过障碍物的经验,能够到达目标点,部分参数设置见表1。
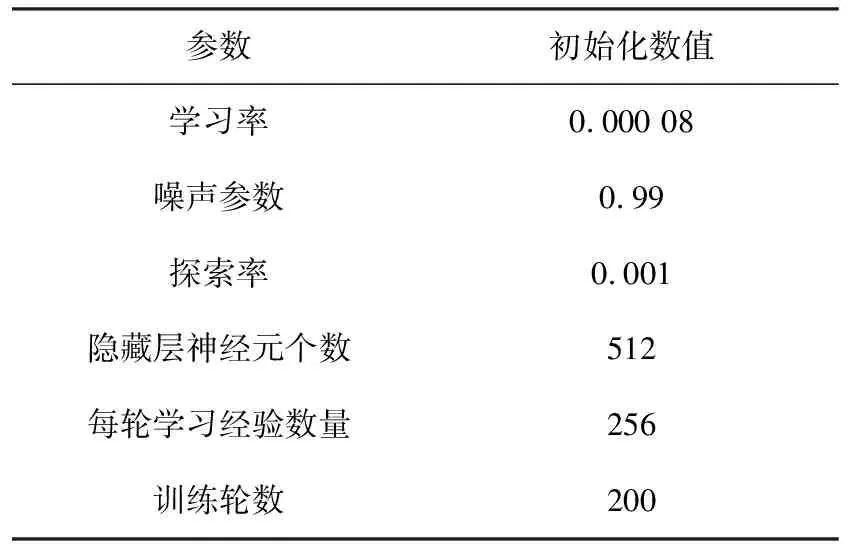
表1 路径规划任务参数设置
3.1 无障碍物下的仿真
Gazebo搭建的仿真环境如图11所示。

图11 无障碍物环境
在训练过程中随机生成目标点,根据奖惩函数给予奖励,经过训练后输出每轮的平均奖励,如图12所示。APF-LSTM-DDPG算法由于人工势场法力的作用对角速度进行调节,会迅速找寻到目标点,得到更多奖励高的样本,算法更快地收敛。从图12中可以看出APF-LSTM-DDPG算法在30轮后开始收敛,原始算法在100轮左右开始收敛,且收敛后APF-LSTM-DDPG算法较为稳定。

图12 无障碍物环境每轮平均奖励对比
设置三个不同的目标点,使机器人按右上、左上和左下的顺序依次寻路,利用训练后的模型进行路径规划的结果如图13所示。APF-LSTM-DDPG算法由于学习到的经验较好,规划的路径更短,转弯角度更小。

(a) DDPG算法 (b) APF-LSTM-DDPG算法图13 无障碍物环境路径规划
3.2 离散障碍物下的仿真
离散障碍物训练环境在Gazebo中显示如图14所示。
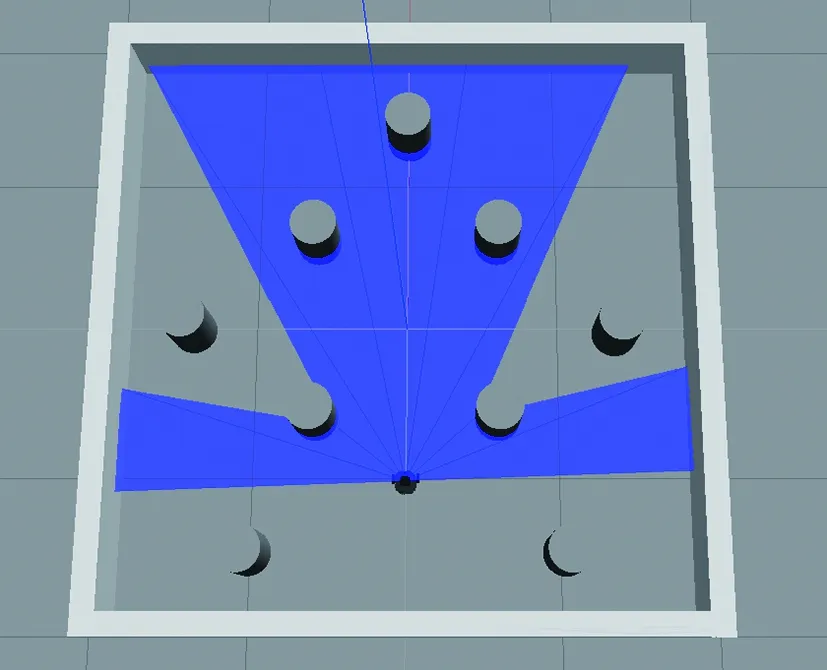
图14 离散障碍物环境
利用迁移学习将具有趋向目标点经验的无障碍物环境模型迁移到离散环境中作为初始化模型,设置实验参数,机器人碰撞障碍物后给予负奖励并立即进入下一轮,缩短训练周期,进行200轮训练后,输出平均奖励,如图15所示。从图15可以看出机器人在离散障碍物场景中获得的平均奖励在训练前期处于正负值交替状态,说明还没有学习到充足的避障经验,每轮的平均奖励随着迭代次数的增加逐渐上升,算法开始逐渐收敛,且APF-LSTM-DDPG算法的收敛速度明显快于原始算法。
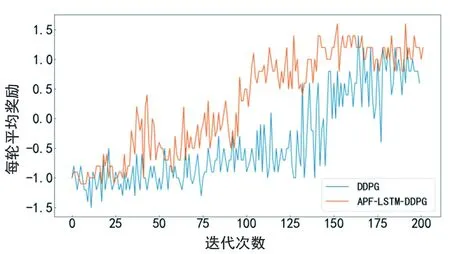
图15 离散障碍物环境每轮平均奖励对比
利用训练得到的模型进行从起点到目标点的路径规划,规划结果如图16所示。从图16可以看出,相比于原始DDPG算法,APF-LSTM-DDPG算法规划的路径更短,冗余路段更少。

(a) DDPG算法 (b) APF-LSTM-DDPG算法图16 离散障碍物环境路径规划
3.3 U型障碍物下的仿真
特殊障碍物包括一型和U型,存在陷入局部最优等问题,通过LSTM单元和人工势场法合力的作用,使机器人更快地绕过障碍物,提高模型收敛的速度。U型障碍物环境如图17所示。

(a) Gazebo中的U型环境 (b) Rviz中的U型环境图17 U型障碍物环境
将APF-LSTM-DDPG算法和原始算法在离散障碍物环境下学习到避障经验的算法模型用作U型障碍物环境的初始化模型,同样进行200轮训练,输出每轮平均奖励,如图18所示。APF-LSTM-DDPG算法训练到25轮前后,平均奖励上升到正值,说明算法已经学习到部分避障经验;而在130轮左右时,每轮的平均奖励基本稳定,说明算法趋于收敛。
图19为两个算法在U型障碍物环境中规划的路径。U型环境中,APF-LSTM-DDPG算法从起点到终点所用步数为179,原始DDPG算法为191。从图19可以看出,在人工势场法辅助下训练出的算法模型,能够在激光雷达探测到障碍物时直接绕过,在不触碰障碍物的条件下规划出一条从起点到目标点的较优路线,且APF-LSTM-DDPG算法规划的路径较短。

(a) DDPG算法 (b) APF-LSTM-DDPG算法图19 U型障碍物环境路径规划
3.4 一型障碍物下的仿真
一型障碍物环境将作为U型环境训练模型的泛化测试环境,所以不单独在一型环境下进行训练,将APF-LSTM-DDPG算法在U型环境中的训练模型用于一型障碍物环境的路径规划任务。一型障碍物环境如图20所示。
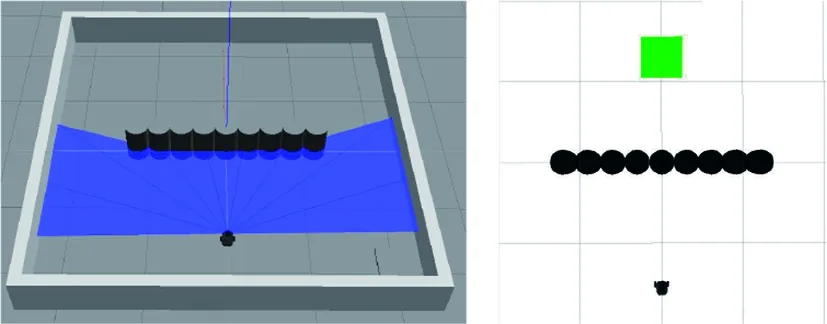
(a) Gazebo中的一型环境 (b) Rviz中的一型环境图20 一型障碍物环境
图21为两个算法在一型障碍物环境中规划的路径。APF-LSTM-DDPG算法从起点到终点所用步数为181,原始DDPG算法为186。从结果可知,该算法具有一定的泛化性。
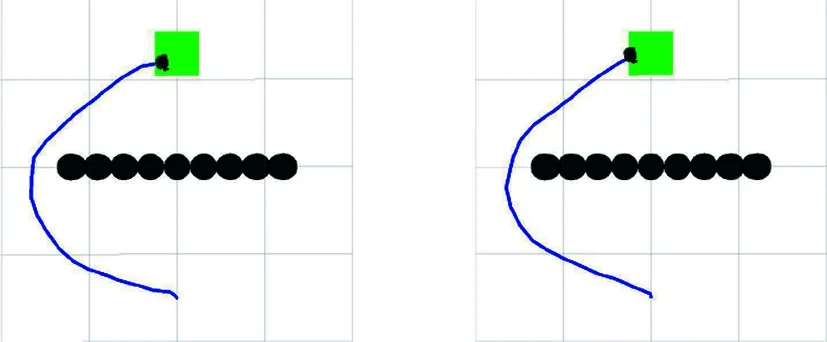
(a) DDPG算法 (b) APF-LSTM-DDPG算法图21 一型障碍物环境路径规划
对两种算法在四种障碍物环境中路径规划时从起点到目标点的步数进行汇总,见表2。从表2可以看出,在每个环境中APF-LSTM-DDPG算法路径规划所用步数均较少。
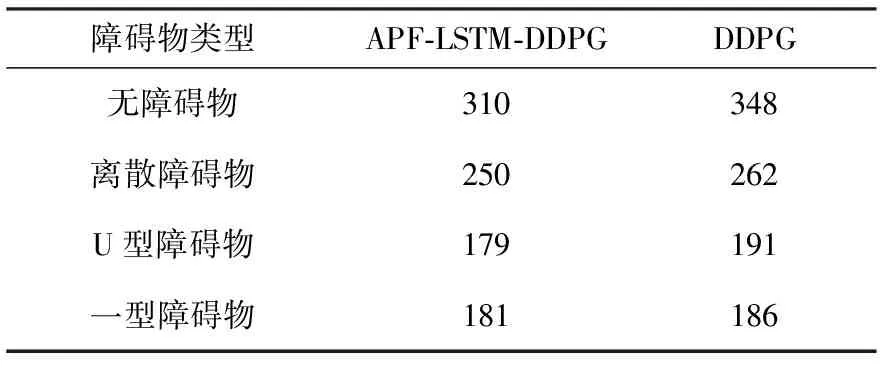
表2 到达目标点所用步数 单位:步
3.5 混合障碍物环境中对比仿真测试
在混合障碍物场景中,分别基于传统DDPG算法、文献[19]复现的算法和本文提出的APF-LSTM-DDPG算法进行仿真验证。为方便称呼,简称文献[19]中的算法为LDDPG算法。LDDPG算法是结合LSTM神经网络并以环境图像作为输入的路径规划算法,将其输入改为与本文设计的算法同样的14个输入,以便进行仿真测试。对比平均奖励和利用收敛模型进行路径规划的成功率,搭建的环境如图22所示。
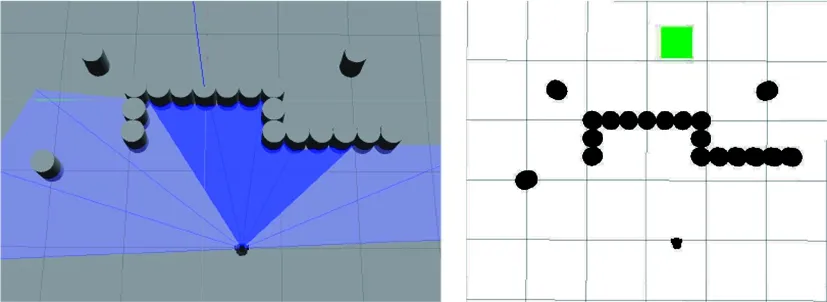
(a) Gazebo中的混和环境 (b) Rviz中的混和环境图22 混合障碍物环境
图23给出了三种算法在混和障碍物下训练所获得的平均奖励。
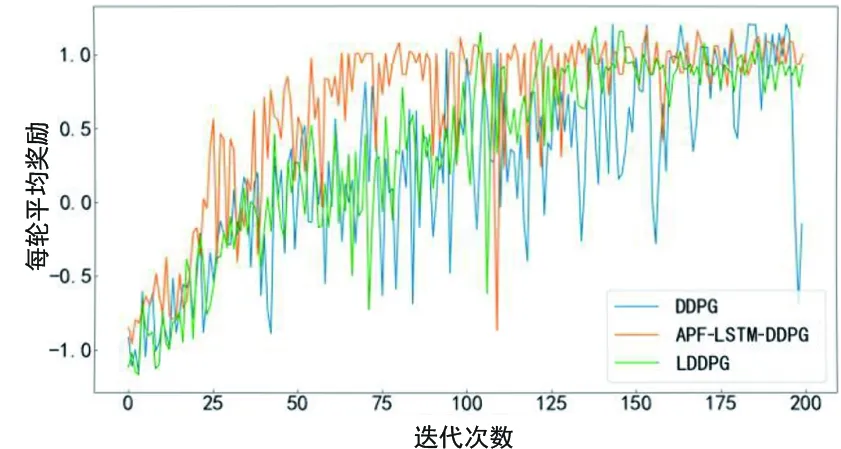
图23 混合障碍物环境每轮平均奖励对比
LDDPG算法由于具有LSTM结构,对于时序输入数据有记忆功能,能够更好地学习状态信息,相较于原始DDPG算法能够更快学习到经验,加快收敛;APF-LSTM-DDPG算法在具有LSTM结构的基础上引入了人工势场法作为辅助策略,获取更多有效的状态信息,所以收敛速度最快。
利用三种算法的收敛模型进行路径规划,如图24所示。显然,传统DDPG算法模型规划出的路径更加冗余;LDDPG算法模型规划的路径相比传统DDPG算法较短,但避障策略不充足;而本文提出的APF-LSTM-DDPG算法模型可以规划出一条较优路径。
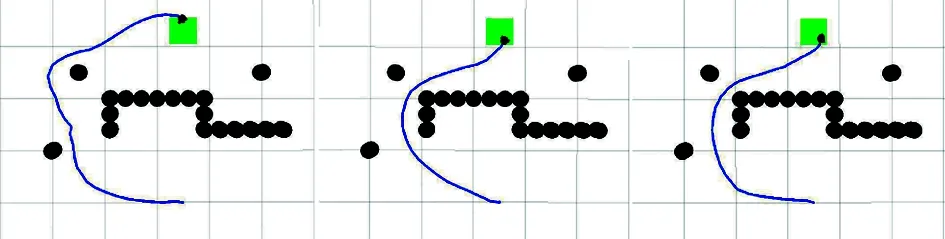
(a) DDPG算法(b) APF-LSTM-DDPG算法(c) LDDPG算法图24 路径规划对比
将算法收敛模型在混合障碍物场景中重复进行100轮路径规划,统计到达目标点的成功率,见表3。相较于其他两种算法,APF-LSTM-DDPG算法的成功率更高、鲁棒性更强。

表3 算法成功率对比
4 结论
本文提出了一种基于DDPG算法,引入LSTM结构和人工势场法的融合路径规划算法,利用合力调节动作策略的选择,通过LSTM的记忆功能提高学习的效率,并且在ROS中搭建不同环境进行仿真,验证了该算法的有效性。APF-LSTM-DDPG算法具有以下特点:
1)算法分别赋予目标点和障碍物引力和斥力,设计相应的势场函数加快学习避障策略,通过合力的作用调节角速度,引导机器人更快到达目标点。
2)在神经网络中增加一层LSTM网络,通过对状态信息的遗忘和记忆功能加快算法收敛速度,使训练好的模型具有更强的泛化性能。
3)算法的在线运行时间和训练时间没有关联,并且算法充分训练后得到的收敛模型,实际运行时不需要再进行训练。机器人通过传感器实时感知当前环境信息,经训练模型可以求出一条合理的局部规划路径,满足运行的实时性需求。
算法在简单的混合障碍物环境中可以实现路径规划任务,考虑到实际应用中,障碍物环境会更复杂且存在动态障碍物,所以之后的工作是设计训练效率更高的神经网络模型,应对机器人更加复杂多变的工作环境。
