基于改进YOLO v8n的甜菜杂草检测算法研究
2024-02-14黄友锐王小桥韩涛宋红萍王照锋











摘要:农作物生长过程中其伴生杂草的及时清除能够有效提高农作物的产量和质量。针对当前对于甜菜杂草检测精度较低、小目标漏检等问题,提出了基于改进YOLO v8n的甜菜杂草检测算法。首先,在检测头部分增加一个小目标检测层,提高模型对生长初期甜菜和杂草的检测能力。其次,在主干部分引入感受野坐标注意力卷积(receptive-field coordinated attention convolutional operation,RFCAConv),更好地识别图像中的边缘、纹理、形状等低级特征,并且所增加的计算开销极小。最后,引入损失函数PIoU v2替换YOLO v8n原来的损失函数,增强对中等质量锚框的聚焦能力,加快收敛速度,并提高检测精度。通过公开的Lincolnbeet数据集进行试验,试验结果表明,改进后的YOLO v8n模型总的mAP@0.5达到了0.902,对比YOLO v8n原模型提高了0.035,甜菜和杂草分别提升了0.026、0.041,参数量减少了3.3%,平均每幅图片的检测时间为4.1 ms,能够满足实时检测的要求。
关键词:甜菜;杂草识别;YOLO v8n;感受野坐标注意力卷积;小目标检测
中图分类号:S126;TP319.41" 文献标志码:A
文章编号:1002-1302(2024)24-0196-09
收稿日期:2024-07-08
基金项目:安徽省高校协同创新项目(编号:GXXT-2023-068)。
作者简介:黄友锐(1971—),男,安徽淮南人,博士,教授,主要从事智能控制、智能制造研究。E-mail:hyr628@163.com。
通信作者:王小桥,硕士研究生,主要从事图像处理研究。E-mail:2022200878@aust.edu.cn。
甜菜作为一种重要的农业作物,不仅是蔬菜和糖制品的原料[1],还用于生产生物燃料和饲料,主要种植于内蒙古、新疆和黑龙江等地区[2]。杂草在生长过程中与作物争夺水、阳光、肥料和空间[3],同时促进害虫和病原体的生长传播,影响作物产量和质量[4-5]。传统的杂草管理方法依赖化学或机械手段,如均匀施用除草剂,但因杂草分布不均,导致农药过量使用,不仅造成环境问题,还易导致杂草产生抗药性[6-7]。随着精准农业的发展,自动化、智能化的杂草检测技术受到了广泛关注,这些技术旨在提高杂草管理的效率和准确性,有助于减少田间农药的使用,保护农业生态环境,因此,杂草识别和检测至关重要[8-10]。
为了实现田间杂草的精确检测和识别,国内外许多学者采用机器视觉、图像处理等技术手段,进行了大量杂草检测研究[11-14]。近年来,随着深度学习在各种视觉任务中的巨大成功,许多基于图像的深度学习算法已经被开发出来[15]。例如,两阶段算法:Faster-RCNN[16]、Mask-RCNN[17];单阶段算法:SSD[18]、You Only Look Once(YOLO)系列算法[19]。其中,YOLO系列算法因其快速、准确的检测性能而广受欢迎,它由不同的版本组成,在2016年首次推出YOLO,后几年又推出了YOLO v2、YOLO v3、YOLO v4、YOLO v5、YOLO v6、YOLO v7和YOLO v8版本。许多研究人员将YOLO系列应用于杂草检测和其他农业目标识别任务[20]。Ying等应用YOLO v4改进了一个轻量级的杂草检测模型,用于检测胡萝卜幼苗中的杂草,研究结果为杂草检测、机器人除草和选择性喷洒提供了参考[21]。Wang等构建了一种结合YOLO v5和注意力机制的模型,用于检测茄子的沙丘种子,经过多尺度训练后,其检测速度和检测效果可应用于入侵杂草长喙龙葵幼苗的田间实时检测[22]。亢洁等提出一种基于多尺度融合模块和特征增强的杂草检测方法,对小目标作物与杂草以及叶片交叠情况的检测能力均有提高[23]。邓天民等为了解决无人机(UAV)航拍图像检测存在的小目标检测精度低和模型参数量大的问题,提出轻量高效的航拍图像检测算法 FS-YOLO,该算法泛化能力较强,较其他先进算法更具竞争力[24]。
上述研究虽然能够在特定环境下达到较好的检测效果,但是,当应用于复杂的农田环境中,尤其是在检测小型或密集分布的杂草时,仍然有一定的局限性。因此,本研究基于最新的YOLO v8n算法,提出了一种改进的甜菜杂草检测模型。为了更好地识别图像中的边缘、纹理、形状等低级特征,使用RFCAConv替换主干部分的普通卷积。为了提高模型对生长初期的甜菜和杂草的检测能力,在检测头部分增加了一个小目标检测层。为了增强对中等质量锚框的聚焦能力,提升模型的检测精度以及收敛速度,引入了一个损失函数PIoU v2。
1 材料与方法
1.1 YOLO v8概述
YOLO v8是ultralytics公司在2023年1月发布的,可以进行图像分类、物体检测和实例分割,该模型易于部署和操作,因此被应用于各种不同的实际场景中[19]。算法的模型结构包括:Backbone、Head、Neck。Backbone 和Neck部分参考了YOLO v7 ELAN设计思想,将C3模块与ELAN结构结合起来构成C2f模块;Head部分是目前主流的解耦头结构,将分类和检测头分离,同时也将Anchor-Based换成了Anchor-Free。另外,Loss计算方面采用了CIoU Loss和Distribution Focal Loss作为回归损失函数[25]。在数据增强方面,引入了YOLOX中所提出的最后10epoch关闭Mosiac增强的操作。
1.2 改进YOLO v8n模型结构
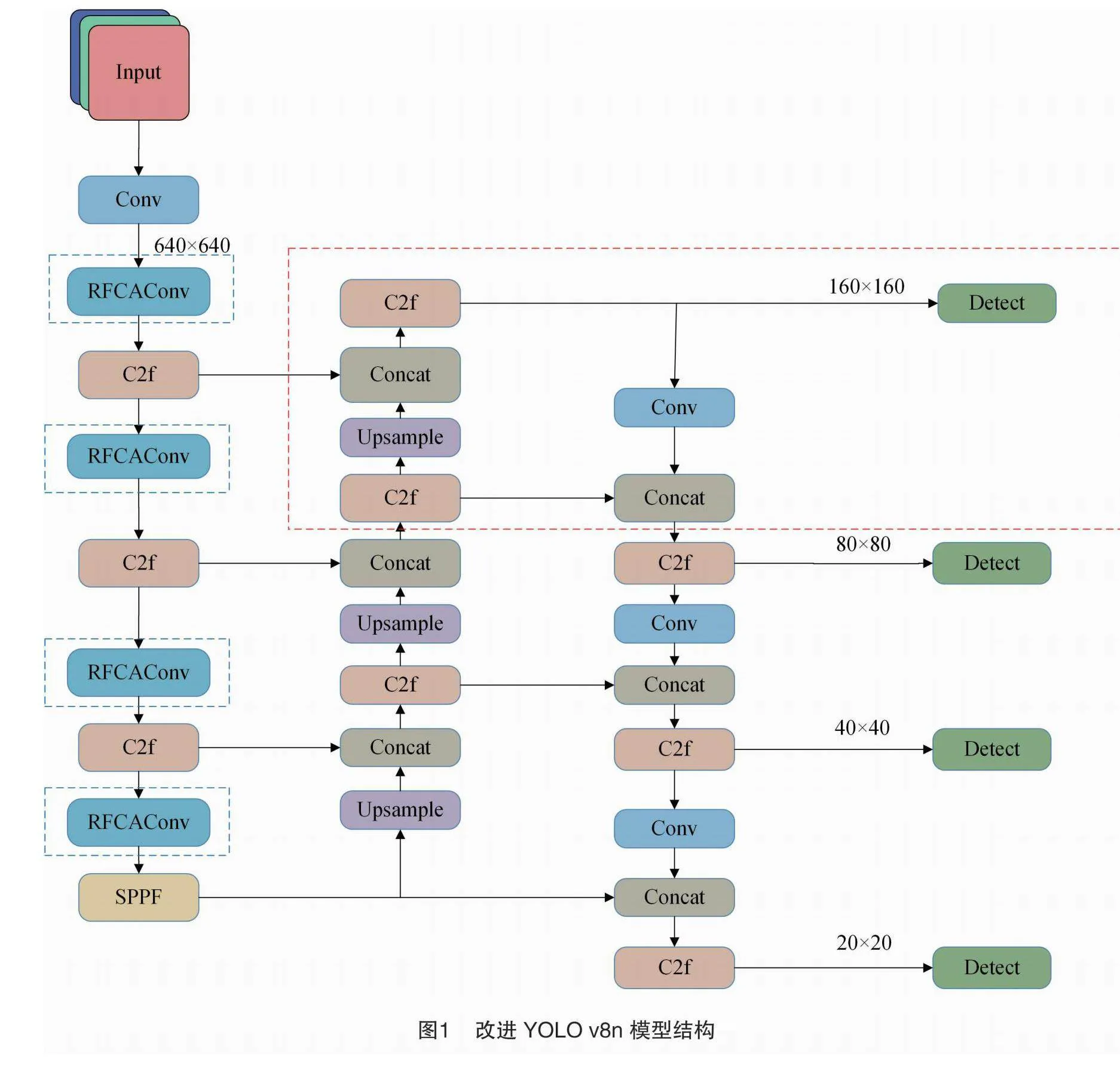
1.2.1 增加小目标检测层
在YOLO v8n中本身有3个检测层,位于网络结构的不同深度,从浅层的特征图提取细节信息,从深层的特征图提取更加抽象和语义丰富的信息。然而,较深的特征图很难学习到小目标的特征信息,这会导致对小目标的识别效果下降。所以,针对甜菜杂草数据集中的小目标,在Head部分引入一个小目标检测层P2,对较浅特征图与较深特征图拼接后输出的大小为160×160的特征图进行检测,160×160的特征图保留了较多的细节信息,有利于检测小目标。
改进后的网络结构如图1所示,虚线框为改进模块。
1.2.2 感受野坐标注意力卷积运算(RFCAConv)
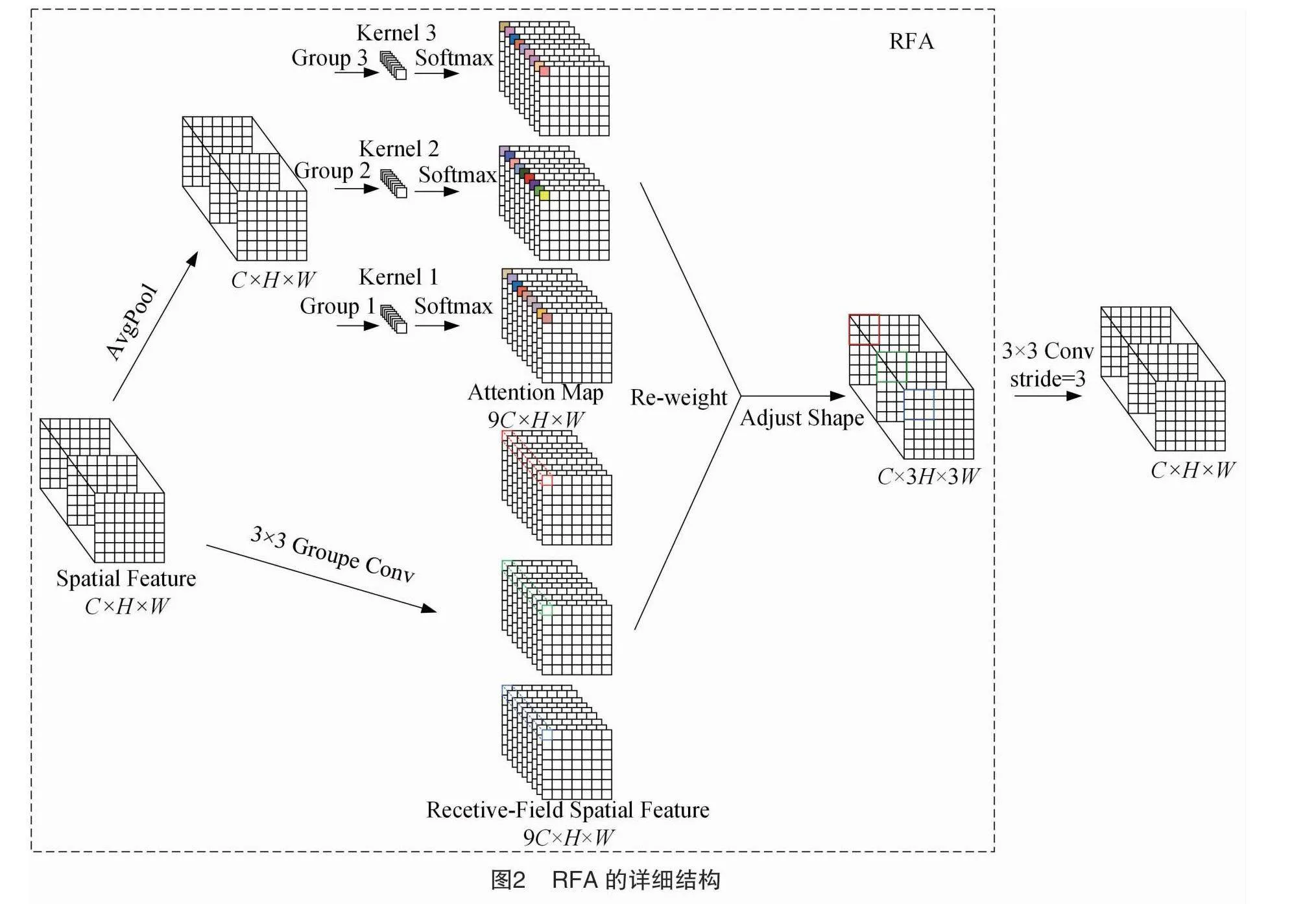
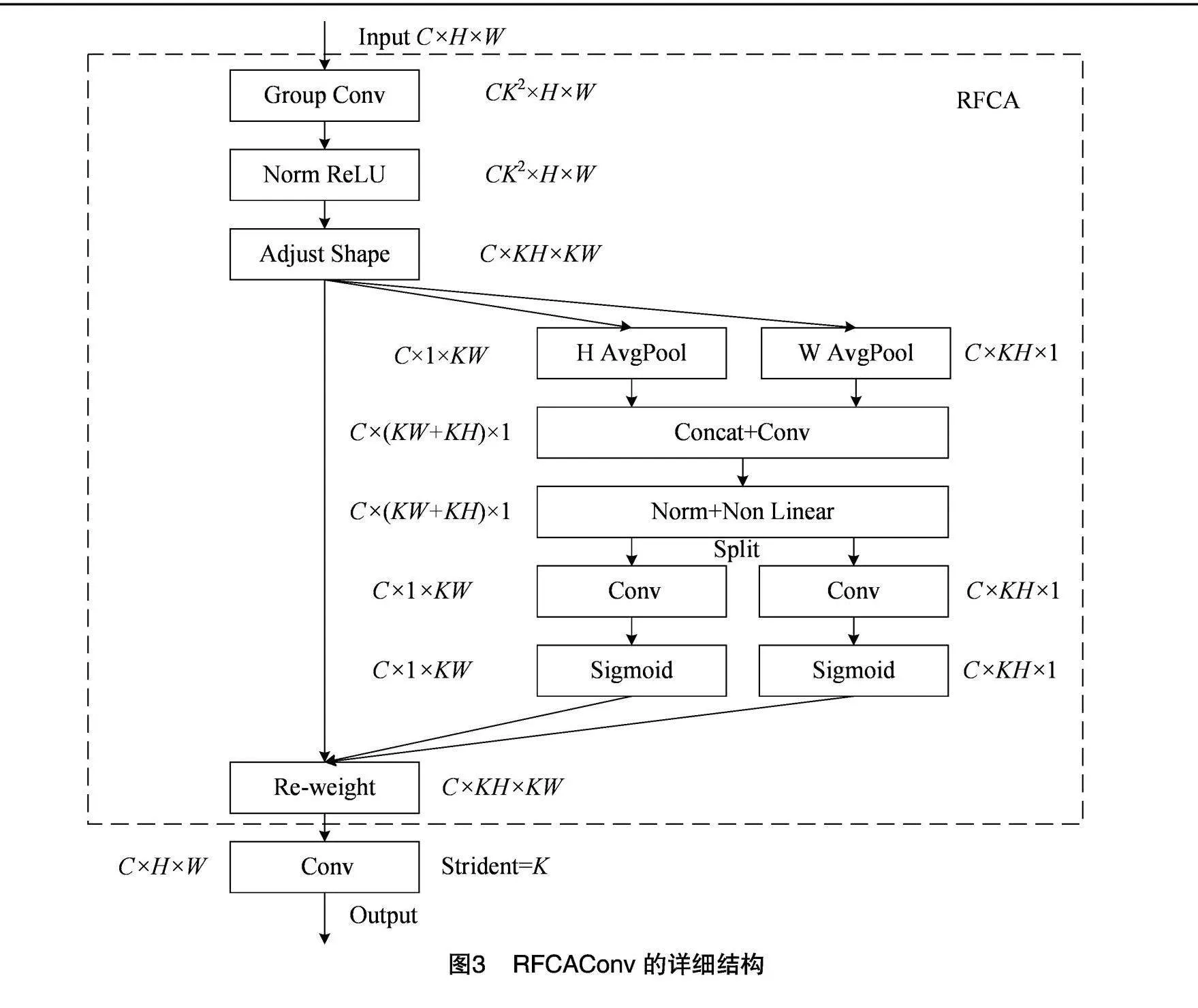
将注意力模块集成到YOLOv8n中 可以增强对图像局部特征的提取,例如引入坐标注意力(coordinated attention,CA)模块[26]。但CA只关注空间特征,不能解决大卷积核参数共享的问题。为此,本研究引入了感受野坐标注意力卷积(receptive-field coordinated attention convolutional operation,RFCAConv)[27],这是一种基于感受野注意力(receptive-field attention,RFA)理念的创新卷积方法,其核心在于整合了CA至感受野注意力卷积(receptive-field attention convolutional operation,RFAConv)中。
感受野空间特征是专门为卷积核设计的,并根据核大小动态生成。由图2可见,以3×3卷积核为例,“Spatial Feature”指的是原始的特征图,“Recetive-Field Spatial Feature”是空间特征根据卷积核大小变换后的特征图,该方法强调了感受野滑块内不同特征的重要性,完全解决了卷积核参数共享的问题,为大尺寸卷积核的应用提供了有效的注意力加权。RFA的计算公式如下:
F=Softmax{g1×1[AvgPool(x)]}×ReLU{Norm[gk×k(x)]}=Arf×Frf。(1)
式中:F是每个卷积滑块获得的值;gi×i是大小为i×i的分组卷积;k是卷积核的大小;Norm是归一化;X是输入特征图;Arf是注意力图;Frf是变换后的感受野空间特征。
RFA将全局和局部信息结合起来,以优化特征提取过程。全局特征聚合步骤通过平均池化和1×1卷积来计算全局注意力权重,强调重要的特征。局部特征归一化与增强步骤通过k×k卷积、归一化和ReLU激活来提取和增强局部特征。
为了进一步提高感受野注意力的性能,将考虑了长距离信息、通过全局平均池化方式获取全局信息的CA引入感受野空间特征,生成RFCAConv,彻底解决了参数共享的问题。RFCAConv的详细结构如图3所示。
1.2.3 损失函数改进
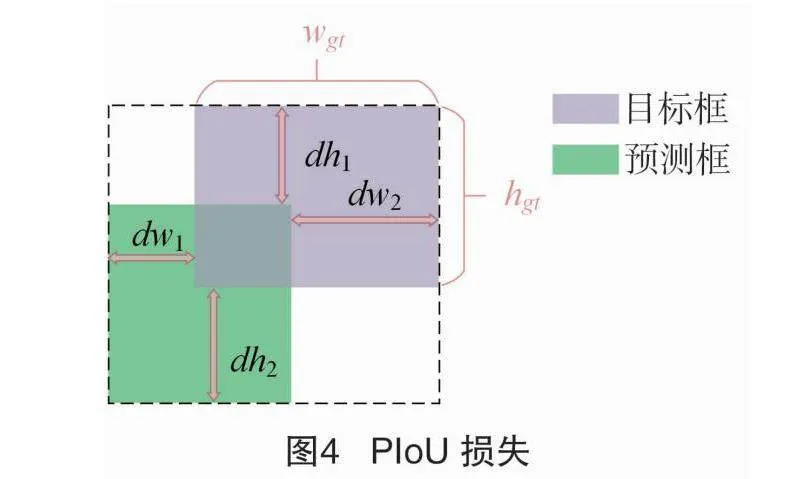
目标检测领域中,边界框定位精度是衡量模型性能的重要指标,它在很大程度上取决于边框回归损失函数的设计和实现。在YOLO v8中计算边框损失采用的是DFL损失和CIoU相结合的方法[25],这种损失函数受到不合理惩罚因子的影响,在回归过程中锚框不断扩大,不利于小目标的定位,导致收敛速度慢。所以本研究使用了Powerful-IoU(PIoU)来解决这一问题[28],PIoU中有适应目标大小的惩罚因子P,其计算公式如下:
P=dw1wgt+dw2wgt+dh1hgt+dh2hgt4。(2)
式中:dw1、dw2、dh1、dh2是预测框和目标框对应边缘之间距离的绝对值;wgt、hgt是目标框的宽度和高度。
从式(2)可以看出,P的大小只取决于目标框的高度和宽度,不会随着锚框的扩大而改变。并且只有当锚框和目标框完全重叠的情况下,P才为0,所以该惩罚因子具有对目标尺寸的适应性。各变量之间的关系如图4所示。
为了进一步提升损失函数的效果,基于上文得到的惩罚因子P,引入了一个适应锚框质量的惩罚函数,其引导锚框沿着更直接、更高效的路径回归,加速收敛并提高检测准确度。其表达式如下:
f(x)=1-e-x2;(3)
LPIoU=LIoU+f(x),1≤LPIoU≤2。(4)
式中:f(x)是惩罚函数;LPIoU是PIoU损失函数;LIoU是IoU损失函数。
函数f(x)能够根据锚框与目标框的差异自动调整梯度幅度,以便在不同阶段进行自适应优化。在锚框与目标框差异显著时,P值较大,导致函数导数f′(p)较小,从而抑制低质量锚框的梯度影响,避免模型过度调整以适应这些质量差的锚框。锚框与目标框差异较小时,P值接近1,导数f′(p)较大,有助于模型更快地调整锚框,加速模型对这些比较接近的锚框的优化过程。当锚框非常接近目标框时,P值接近0,导数f′(p)随锚框质量提升逐渐减小,允许锚框通过较小的梯度调整,稳定优化直至与目标框对齐。
为进一步提高检测模型的性能,提出PIoU v2,它是一个由单个超参数控制的非单调注意力层与PIoU损失相结合形成的,即在PIoU损失中添加了注意力层,增强了集中在中高等质量锚框上的能力。注意力函数和PIoU v2损失的表达式如下:
q=e-P,q∈(0,1];(5)
u(x)=3x·e-x2;(6)
LPIoU v2=u(λq)·LPIoU=3·(λq)·e-(λq)2·LPIoU。(7)
式中:q是代替P作为惩罚因子,范围为(0,1],用来测量锚框的质量;u(x)是非单调注意力函数;λ是控制注意力函数行为的超参数;LPIoU v2是PIoU v2损失函数。
当q为1时,意味着P为0,这时锚框与目标框是完全重合的。从式(5)可以看出,当P增大时,q会逐渐减小,此时代表的是低质量的锚框。式(7)中,PIoU v2只需要λ这一个超参数,简化了调优的过程。
2 结果与分析
2.1 数据集及预处理
本研究使用公开数据集Lincolnbeet[29],数据集中包含4 402张图片,有甜菜和杂草2类目标,分别有16 399、22 847个目标边界框。图像尺寸为1 920像素×1 080像素,数据集中包含的标签为COCOjson、XML和darknets格式。
另外,为了使数据集的样本更加均衡,同时提升模型在面对未知、复杂或噪声数据时的鲁棒性和泛化能力,更好地适应现实世界中的各种应用场景,对其中的部分包含目标较多的图片采用旋转、平移、调节亮度、Cutout以及添加高斯噪声等基础数据增强方式。其中,旋转的角度为35°,平移的距离为最大允许距离的1/3,亮度调节的参数在0.8~1.2之间,Cutout的矩形边框大小为100像素。经过处理后,数据集扩充为5 897张,并按7 ∶2 ∶1的比例将数据集划分为训练集、验证集、测试集,划分后分别为4 127、1 180、590张。处理前后的图片如图5所示。
2.2 试验环境
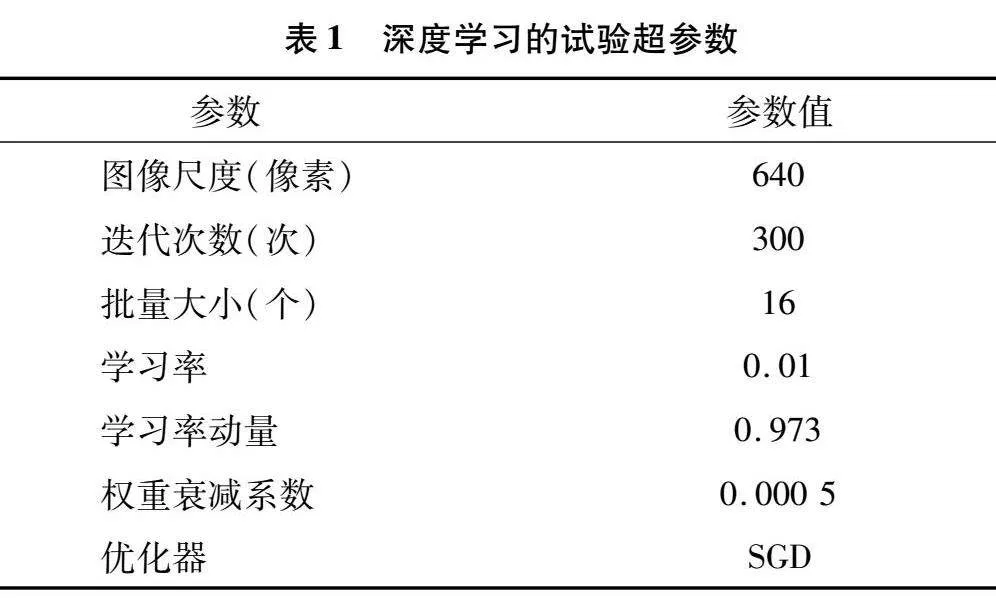
本试验在深度学习服务器下进行,GPU型号为NVIDIA GeForce RTX4090,内存为24 GB,python编译器版本为3.9,深度学习框架为PyTorch-1.10.0,CUDA版本:12.2。试验时间为2023年9月至2024年6月,试验地点为安徽理工大学百川楼。试验具体的超参数设置如表1所示。
2.3 评价指标
采用2类对象的平均精度均值(mAP@0.5)评估模型的整体性能,参数量(Params)反映模型的规模和复杂性,浮点运算次数(GFLOPs)衡量模型计算复杂度,FPS评估模型的检测速度。AP通过计算精度-召回率曲线下的面积来评估模型在检测多个对象类别时的表现,考虑了模型在识别目标时的准确性(P),同时也考虑了模型在实际目标中正确识别的比例(R)。这个PR曲线下的面积提供了模型在各个对象类别中检测性能的综合评估。
AP的计算公式如下:
AP=∫10P(R)dR。(8)
mAP是AP的均值,计算公式如下:
mAP=1N∑ni=1APi。(9)
2.4 对比试验
为了验证本研究所提出的改进后的YOLO v8算法的有效性,将其与当前流行的检测模型进行比较。比较它们在同一数据集上的性能,试验结果如表2所示。
根据表2可知,将改进后的算法与YOLO系列算法:YOLO v8n、YOLO v3-tiny、YOLO v5n、YOLO v7-tiny,以及SSD进行对比,改进模型mAP@0.5指标显著超越了YOLO v3-tiny、YOLO v5n、YOLO v8n,并且检测时间为4.1 ms,能够满足实时检测的要求。与YOLO v8n相比,改进模型不仅在mAP@0.5上提高0.035,而且在参数量上减少了3.3%,所以整体性能上显著高于YOLO v8n。改进模型参数量较小,仅次于参数量最小的YOLO v5n,但mAP@0.5提高了0.038。YOLO v3-tiny、YOLO v7-tiny模型在识别中的mAP@0.5均比较高,分别达到0.834、0.859,但他们的参数量和计算量都比较大,检测时间也更长,不适合在资源有限的嵌入式设备上部署和运行。SSD算法具有较大的参数量和计算量,并且mAP@0.5值很低,远不如其他几个算法。综合比较模型的复杂性、检测的准确性以及实际的使用环境,改进模型在多个目标检测模型中表现优秀,能够保证较高的检测精度和检测速度,更适用于具有不同大小目标的甜菜杂草检测。
从表2可以看出,YOLO v3-tiny、YOLO v5n、YOLO v7-tiny、YOLO v8n这4个模型mAP@0.5相对较高,比较接近改进模型。以上模型在训练300轮的过程中,mAP@0.5随着训练批次的变化图如图6所示。从图中可以看出,改进后的算法从开始训练后,曲线始终处于最上方,并且整体呈上升趋势,当训练到150轮之后趋于平稳,mAP@0.5基本达到顶峰,模型逐步收敛。变化曲线图更加直观地说明了改进的模型在检测精度和收敛速度上相对于其他模型表现更优,正确识别和定位目标的能力更强。
2.5 消融试验
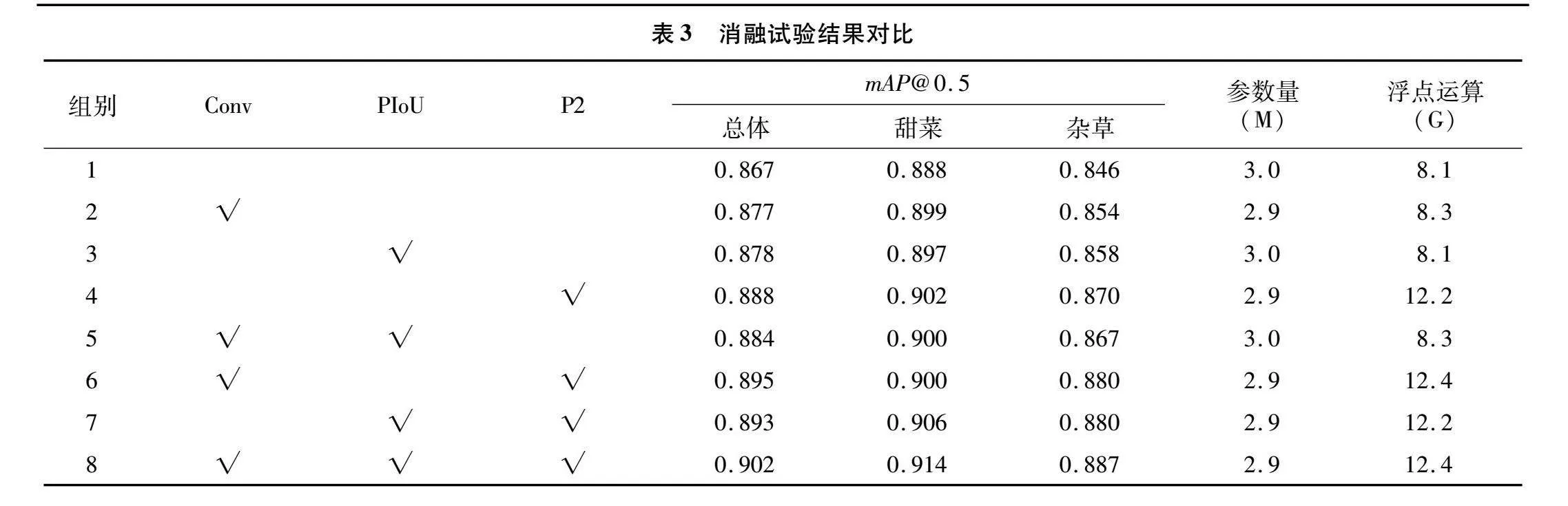
为了验证模型改进的3个模块的效果,进行了针对单一改进以及两两组合改进措施的有效性对比试验,试验结果如表3所示。
通过分析表3的数据,可以观察到,第4组试验引入了针对小尺寸目标的检测层P2,模型的mAP@0.5相较于原始模型上升了0.021。具体来看,甜菜提高了0.014,而杂草则提高了0.024,对于标注框较小的杂草来说,有显著的提升,展示了添加小目标检测层所带来的积极效果。第2、3、4组试验均是单一改进模块,对比YOLO v8n模型,mAP@0.5分别提升了0.01、0.011、0.021。第5、6、7组试验是3个改进措施中的任意2种组合,相较于单一改进措施,均有性能上的提升,因此,证明了本研究3个改进模块的有效性。最后一组试验同时融合这3个模块,对比YOLO v8n模型,整体的mAP@0.5得到了0.035的提升,其中,甜菜提升了0.026,杂草增加了0.041,参数量没有增大。从这些结果可以看出,改进后的模型在识别甜菜和杂草方面效果很好。
2.6 改进算法性能分析
在相同的试验环境下,对改进前后的算法进行试验,图7展示了2种模型在训练300轮的过程中各类损失值的变化情况。
边界框损失(Box_loss)的作用是评估模型预测的边界框与真实边界框之间的差异。从图7中可以看出,改进后的模型在训练集和验证集上都表现出更低的损失值和更快的收敛速度。这表明,引入的PIoU v2损失函数显著提升了模型定位目标物体的精度。此外,改进模型的分类损失(cls_loss)和分布焦点损失(dfl_loss)曲线均低于原模型,表明改进模型在识别目标物体类别方面表现更佳。上述结果表明,通过优化这些损失函数,改进后的模型在训练过程中能够更快速、更准确地定位和分类目标,实现了高效且精确的目标检测。
为了测试模型在复杂环境下的检测性能,使用包含甜菜和杂草的4种不同场景的测试集图片,对YOLO v8n和改进模型进行分析。试验结果如图8、图9所示。
第1类图像(a)具有较高的光照强度,从中可以观察到,经过优化的模型在检测置信度上显著优于YOLO v8n。这表明模型在训练了经过数据增强处理的数据集之后,对高亮度图像的检测能力得到了显著提升。在第2类图片(b)里,甜菜的特征与背景有着显著的对比,使得2种模型都能较好地识别图片中的大目标,但改进模型的检测置信度高于YOLO v8n,并且不存在小目标漏检的情况,而改进后的模型能够完全检测。在第3类图片(c)中,由于目标之间的相互遮挡,YOLO v8n未能完全检测出目标,而经过改进后的模型对此类复杂场景进行了优化,因此可以准确地辨识并区分相互重叠的目标,显著提升了对遮挡情况下物体识别的能力。第4类图片(d)中,包含较多小目标,YOLO v8n出现了漏检的情况,相比之下,改进后的模型通过增加一个专门针对小目标的检测层,从而在小目标的识别上展现了更佳的性能,这一改进使得模型在小尺寸目标的检测方面表现更为出色。总的来看,改进后的模型在目标检测方面的表现超过了YOLO v8n,这表明该网络能够捕捉到浅层的局部信息和更加丰富的语义特征,从而具有更优秀的性能表现。
3 结论
为了解决现有研究对于甜菜杂草检测精度较低、存在小目标漏检等问题,本研究基于最新的YOLO v8n算法,提出了一种改进的甜菜杂草检测模型。首先,通过在YOLO v8n模型的主干部分引入RFCAConv,提高了模型识别图像特征的能力。其次,在检测头部分增加了一个小目标检测层,提高了模型对生长初期的甜菜和杂草的检测能力。最后,引入了PIoU v2损失函数,加快了收敛速度,并且提高了检测精度。通过使用公开的Lincolnbeet数据集进行试验,试验结果表明,改进YOLO v8n模型总的mAP@0.5达到了0.902,对比YOLO v8n原模型提高了0.035,平均每幅图片的检测时间为 4.1 ms,能够满足实时检测的要求。与其他4种主流模型比较,改进后的模型参数量较小,识别模型精度最高,减少了小目标漏检现象,在甜菜杂草检测方面具有较好的性能。
研究使用的数据集主要包括生长早期的杂草。未来的研究将集中在收集甜菜和杂草在其他生长阶段的数据,以提高模型在现实场景中的性能。
参考文献:
[1]周艳丽,李晓威,刘 娜,等. 内蒙古甜菜制糖产业发展探析[J]. 中国糖料,2020,42(2):59-64.
[2]刘晓雪,蒙威宇,谢由之. 甜菜生产大幅波动的原因探究:基于199份农户调查问卷[J]. 中国糖料,2024,46(2):92-102.
[3]汤雷雷,万开元,陈 防. 养分管理与农田杂草生物多样性和遗传进化的关系研究进展[J]. 生态环境学报,2010,19(7):1744-1749.
[4]袁洪波,赵努东,程 曼. 基于图像处理的田间杂草识别研究进展与展望[J]. 农业机械学报,2020,51(2):323-334.
[5]李 彧,余心杰,郭俊先. 基于全卷积神经网络方法的玉米田间杂草识别[J]. 江苏农业科学,2022,50(6):93-100.
[6]孟庆宽,张 漫,杨晓霞,等. 基于轻量卷积结合特征信息融合的玉米幼苗与杂草识别[J]. 农业机械学报,2020,51(12):238-245,303.
[7]毛文华,张银桥,王 辉,等. 杂草信息实时获取技术与设备研究进展[J]. 农业机械学报,2013,44(1):190-195.
[8]姜红花,张传银,张 昭,等. 基于Mask R-CNN的玉米田间杂草检测方法[J]. 农业机械学报,2020,51(6):220-228,247.
[9]苗中华,余孝有,徐美红,等. 基于图像处理多算法融合的杂草检测方法及试验[J]. 智慧农业,2020,2(4):103-115.
[10]胡 炼,刘海龙,何 杰,等. 智能除草机器人研究现状与展望[J]. 华南农业大学学报,2023,44(1):34-42.
[11]翁 杨,曾 睿,吴陈铭,等. 基于深度学习的农业植物表型研究综述[J]. 中国科学(生命科学),2019,49(6):698-716.
[12]Li Y,Guo Z Q,Shuang F,et al. Key technologies of machine vision for weeding robots:a review and benchmark[J]. Computers and Electronics in Agriculture,2022,196:106880.
[13]胡盈盈,王瑞燕,郭鹏涛,等. 基于近地光谱特征的玉米田间杂草识别研究[J]. 江苏农业科学,2020,48(8):242-246.
[14]化春键,张爱榕,陈 莹. 基于改进的Retinex算法的草坪杂草识别[J]. 江苏农业学报,2021,37(6):1417-1424.
[15]李柯泉,陈 燕,刘佳晨,等. 基于深度学习的目标检测算法综述[J]. 计算机工程,2022,48(7):1-12.
[16]Ren S Q,He K M,Girshick R,et al. Faster R-CNN:Towards real-time object detection with region proposal networks[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence,2015,39(6):1137-1149.
[17]He K M,Gkioxari G,Dollár P,et al. Mask R-CNN [C]//Proceedings of the IEEE International Conference on Computer Vision. Italy:IEEE Press,2017:2961-2969.
[18]Liu W,Anguelov D,Erhan D,et al. SSD:single shot MultiBox detector[C]//Computer Vision-ECCV 2016. Cham:Springer International Publishing,2016:21-37.
[19]Kumar P,Misra U. Deep learning for weed detection:exploring YOLO v8 algorithms performance in agricultural environments[C]//Proceedings of the 2024 2nd International Conference on Disruptive Technologies (ICDT). Greater Noida:IEEE Press,2024:255-258.
[20]Gallo I,Rehman A U,Dehkordi R H,et al. Deep object detection of crop weeds:performance of YOLO v7 on a real case dataset from UAV images[J]. Remote Sensing,2023,15(2):539.
[21]Ying B Y,Xu Y C,Zhang S,et al. Weed detection in images of carrot fields based on improved YOLO v4[J]. Traitement Du Signal,2021,38(2):341-348.
[22]Wang Q F,Cheng M,Huang S,et al. A deep learning approach incorporating YOLO v5 and attention mechanisms for field real-time detection of the invasive weed Solanum rostratum Dunal seedlings[J]. Computers and Electronics in Agriculture,2022,199:107194.
[23]亢 洁,刘 港,郭国法. 基于多尺度融合模块和特征增强的杂草检测方法[J]. 农业机械学报,2022,53(4):254-260.
[24]邓天民,程鑫鑫,刘金凤,等. 基于特征复用机制的航拍图像小目标检测算法[J]. 浙江大学学报(工学版),2024,58(3):437-448.
[25]Zheng Z H,Wang P,Liu W,et al. Distance-IoU loss:Faster and better learning for bounding box regression[C]//Proceedings of the AAAI Conference on Artificial Intelligence,2020,34(7):12993-13000.
[26]Hou Q B,Zhou D Q,Feng J S. Coordinate attention for efficient mobile network design[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Nashville:IEEE Press,2021:13713-13722.
[27]Zhang X,Liu C,Yang D,et al. RFAConv:innovating spatial attention and standard convolutional operation [EB/OL]. arxiv preprint,arxiv:2304.03198v6(2023-04-06) [2024-04-07]. https://doi.org/10.48550/arXiv.2304.03198.
[28]Liu C,Wang K G,Li Q,et al. Powerful-IoU:more straightforward and faster bounding box regression loss with a nonmonotonic focusing mechanism[J]. Neural Networks,2024,170:276-284.
[29]Salazar-Gomez A,Darbyshire M,Gao J,et al. Beyond mAP:towards practical object detection for weed spraying in precision agriculture [C]//Proceedings of the 2022 IEEE/RSJ International Conference on Intelligent Robots and Systems. Kyoto Japan:IEEE Press,2022:9232-9238.
