基于仿真数据的无监督域适应轴承故障诊断方法*
2024-02-10陈钧钖袁逸萍陈彩凤
陈钧钖 袁逸萍 陈彩凤
(新疆大学机械工程学院,新疆 乌鲁木齐 830046)
随着工业互联网、物联网技术的迅速发展,机械设备能够提取的监测数据不断增加,相应的数据采集量也与日俱增,为设备状态监测提供了坚实的数据基础。旋转机械作为工业设备的关键设备,其中轴承是旋转机械的关键组成部件,其一旦发生故障则会严重造成企业的经济损失甚至人员伤害[1]。因此对轴承进行状态监测与故障识别对保证设备安全稳定运行具有重要意义。
在实际情况下,诊断任务难以获取满足诊断模型训练的数据样本。针对缺乏充足故障样本数据的问题,文献[2]采用两个同结构、参数共享的卷积网络以及双向门控循环单元构成孪生网络进行故障分类,取得良好的诊断结果;文献[3]在生成对抗网络中引入条件梯度惩罚机制的轴承故障诊断方法,其能够生成与真实样本高度相似的生成样本,有效地提高了故障诊断的准确率。文献[4]采用有限元方法得到不同工况下轴承故障样本并且利用冗余属性投影并结合支持向量机进行轴承故障诊断。虽然数据增强以及仿真的方法在一定程度上解决了数据样本缺乏的问题,但数据间的差异性会导致诊断方法的精度下降。针对数据之间存在差异问题,迁移学习中领域自适应解决了数据特征之间存在差异的问题。文献[5]在故障诊断过程中引入最小化最大均值差异(max mean discrepancy,MMD),进而减小不同域之间的分布距离。文献[6]通过对不同域特征的多层域适配,以及利用伪标签学习方法,使不同域之间的条件分布差异进一步减小,进一步提升了故障诊断精度。
上述文献所提方法在一定程度上解决了数据样本不足的问题。建立故障仿真模型得到相应仿真数据可在一定程度上得到设备故障样本数据,但仿真数据和实际数据的依旧存在一定差异性。因此利用数值仿真得到故障数据并采用迁移学习领域自适应方法降低仿真数据与真实数据的差异性,能够为缺少故障数据的诊断任务提供一种解决思路,有望在一定程度上解决故障诊断的实际问题。
本文根据轴承几何参数建立滚动轴承故障动力学仿真模型,进而得到充足的轴承故障仿真数据构建迁移学习源域,然后利用迁移学习中领域自适应方法在实现不同域特征全局分布对齐的基础上,对目标域样本引入最大最小化分类器差异的对抗训练方法,使不同域的特征实现更精确的子领域对齐,进一步提高了模型的泛化能力和对目标域的故障诊断精度。
1 轴承故障动力学仿真模型建立
轴承动力学模型建立参考文献[7]方法。其依据轴承的几何参数建立轴承动力学模型,然后引入轴承故障参数,通过解析轴承动力学方程获得的振动数据。通过验证仿真数据与凯斯西储大学(CWRU)轴承实验数据集数据在时频域的差异对仿真模型的合理性进行验证。
1.1 轴承动力学模型
滚动轴承运动系统可视为四自由度运动系统,在轴承运动过程中仅考虑轴承内外圈在水平方向和竖直方向的位移,根据其动力学模型如图1 所示,并对轴承的运动系统进行以下的简化:(1) 在建立动力学模型时,忽略由于非线性因素导致的轴承非线性接触力以及弹性流体润滑的刚度和阻尼。(2) 轴承只在单一平面内运动,内圈与以定角速度ω转动与轴一起绕z轴转动,外圈固定。(3) 假定滚动体与内外滚道之间的接触为Hertz接触。(4) 不考虑滚动体以及保持架的质量以及转动惯量。

图1 轴承动力学简化模型
考虑制造和安装时误差所导致的离心力对轴承动力学建模,得到动力学系统的动力学方程为
式(1)~式(4)中:min与mout分别为内外圈与其相连接部分质量之和,kg;cin与cout分别为内外圈等效阻尼,N·s/m;kin与kout分别为内外圈与其相连接部分的等效刚度,N/m;FX与FY为滚动体弹性力在x和y方向的分量,N;e为偏心距,m;ω为轴承内圈旋转的角频率,rad/s;g为重力加速度,m/s2;t为运动时间,s。
图2 所示为滚动轴承的故障示意图,其中滚动体故障包含滚动体分别与内外圈接触,只列出内圈接触情况,外圈接触情况相似。
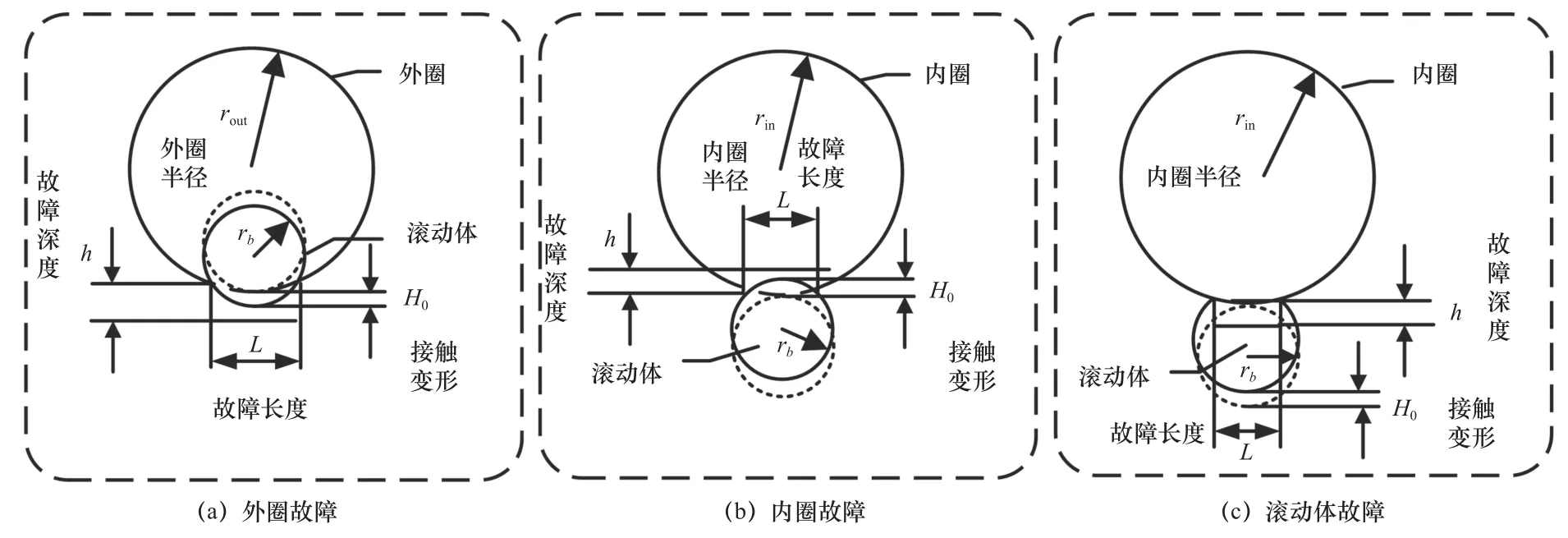
图2 滚动轴承的故障示意图
以内圈故障为例,滚动体在进入故障区域到离开故障区域时,滚动体与滚道之间的接触相应会由突然消失到恢复[8]。接触的变化也会造成接触变形δi的变化。当引入故障后,滚动体i处的 δi为
利用游隙的瞬时变化来表征故障。如当内圈故障时:
式中: θin为内圈故障的角位置; ϕdi为内圈故障缺陷角。
当滚动体进入故障区域时,其产生的接触变形H0实际是内圈与滚动体圆心的距离变化。
式中:rb为滚动体半径;L为故障宽度;Dt内圈直径;h为故障深度。由式(5)~式(7)可以求出轴承径向变形 δi。由Hertz 接触理论可知,第i个滚动体变形引起的弹性恢复力为
1.2 仿真结果处理
利用动力学方程求解出来的加速度信号与标准数据集的振动加速度信号进行对比,分别从时域和频域信号进行对比。
利用Matlab 对动力学仿真模型进行建模,并利用ode45 方法对动力学方程进行求解,进而得到滚动轴承各种状态下振动响应。如图3 所示,为了更好地观察时域数据的冲击特性,对仿真与实际数据取100 ms 数据进行时频域对比。在进行对比时,仅需定性分析时域数据的冲击特性和频域特性,所以将数据归一化至[-1,1]。以内圈故障为例,由图3a与图3c 可知,实际与仿真的时域信号中单个故障周期为6.27 ms 和6.25 ms,相对偏差为0.32%,二者比较接近;当滚动体经过故障区域并且滚动体承受较大载荷时,冲击较大,其周期分别为31.19 ms和31.17 ms,相对偏差为0.64%,二者比较接近。由图3b 与图3d 可知,在频域中仿真数据与实际数据均包含转频(29.60 Hz、29.50 Hz)及转频的二倍频、故障频率(160.10 Hz、160.30 Hz)以及其二倍频和两侧边频,二者关键特征频率均较为接近。

图3 仿真数据时域图及包络谱图
图4 为仿真数据中内圈故障与实际数据进行正态分布拟合,拟合参数均值和标准差分别为实际数据为0.003 9 和0.165 3、仿真数据为-0.122 4 和0.165 2,标准差较为接近但均值相差较大,其主要原因可能是:① 在建立动力学仿真模型时进行了较多简化,如忽略了保持架和滚动体的影响,仿真时仅考虑较大的影响因素并不能与实际设备完全一致;② 在滚动体经过缺陷区域时,相应地载荷会有所变化;③ 实际环境中的不确定因素如噪声的影响并不能在准确在仿真数据体现。实际数据与仿真数据的特征分布存在一定的差异,因此采用迁移学习进行故障诊断十分有必要。
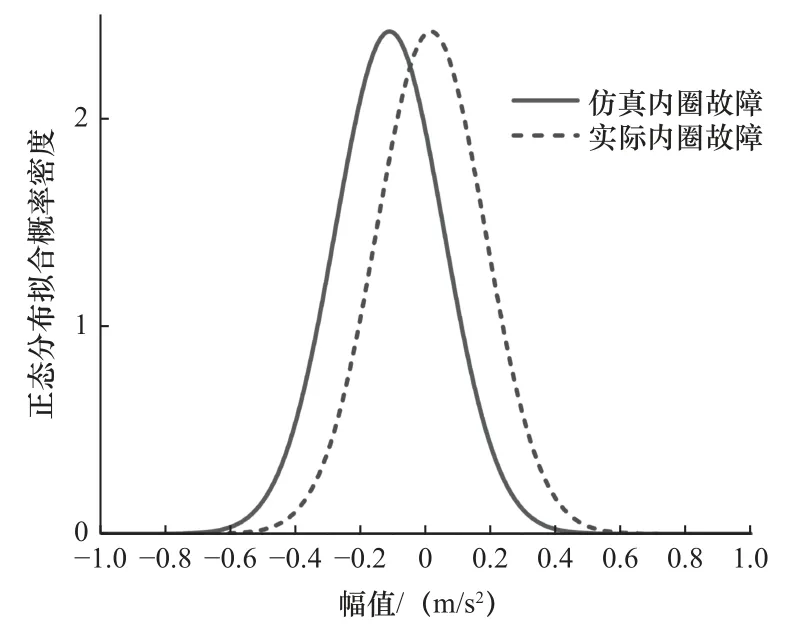
图4 仿真数据和实际数据正态分布拟合图
2 无监督领域自适应迁移学习
无监督领域自适应是迁移学习的一种方法,通过学习源域和目标域共享的特征并且在源域和目标域之间进行知识迁移,进而改善诊断模型在目标域上的学习能力。分布不同的数据样本,源域样本为和目标域样本可以分别表示为与Yt=其中xi为第i个源域样本,yi为其对应的标签,ns为源域样本个数,xk为第k个目标域样本,yk为对应的标签,nt为目标域样本个数[9]。
2.1 特征提取网络
特征提取网络的卷积块中,在开始使用较大卷积核的尺寸来捕捉提取信号的全局特征;随着网络的加深,逐渐减小卷积核的尺寸以捕捉细粒度的局部特征。表1 为特征提取网络的参数。
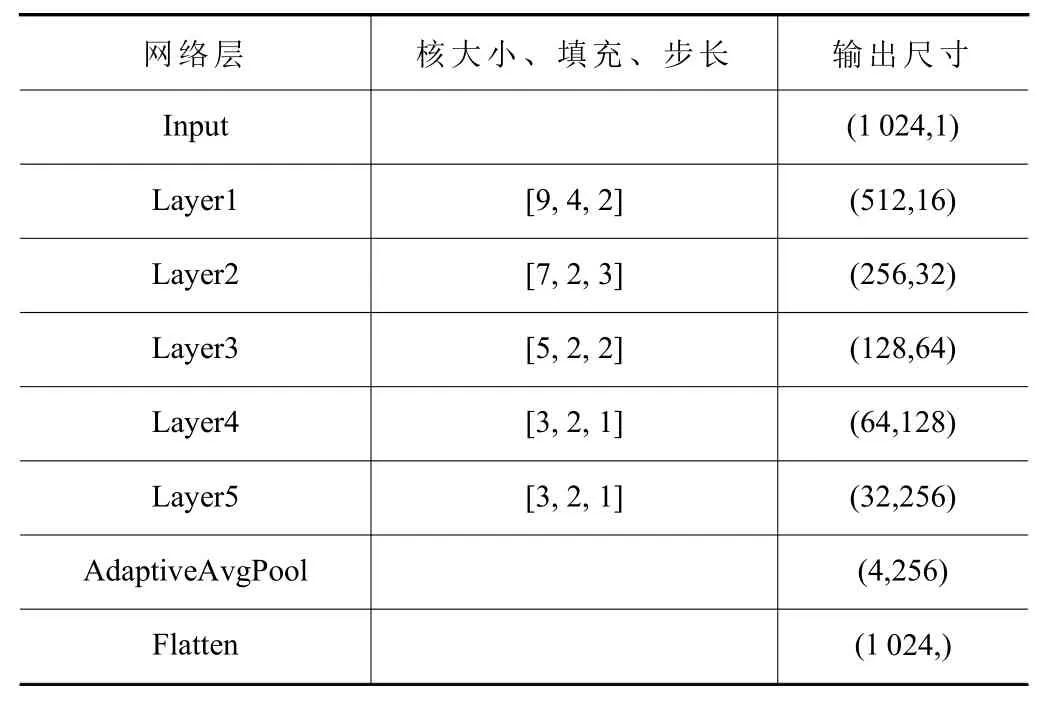
表1 特征提取网络参数
2.2 数据特征自适应
由于本身误差、运行条件以及噪声等因素影响,源域仿真数据与目标域实验数据之间分布存在着较大的差异源域仿真数据与目标域实验数据之间分布存在着较大的差异。为了减小源域和目标域的数据特征差异,可考虑从数据边缘概率分布自适应和条件概率分布自适应入手。
边缘分布自适应通过减小源域和目标域之间的边缘概率分布差异实现不同域之间分布差异。最大均值差异被广泛用于度量迁移学习中源域和目标域的分布差异[10]。其直接从数据本身出发的特点,可以不考虑类别标签,进而实现不同域特征的全局分布对齐。源域和目标域数据在特征提取网络输出层的边缘概率分布分别为p(xs)和p(xt)的MMD 被定义为
式中: H为可再生核希尔伯特空间;ϕ(·)为其相应的映射函数,这里取映射函数为高斯核函数。
条件分布自适应通过减小源域和目标域之间的条件概率分布差异实现不同域之间分布差异。虽然可以采用输出伪标签的方法来减小不同域特征的条件分布差异,但当不同域的数据分布差异过大时,伪标签的准确率会下降,进而对模型的监督训练产生影响[11]。本文最大最小化分类器差异的对抗学习策略,不直接去衡量不同域之间的条件概率分布,而是利用不同的分类器对目标任务的分类决策边界进而实现源域和目标域的条件分布差异的减小。
2.3 深度迁移学习模型构建
本文提出建立特征提取模型并且将上述特征分布适配方法,整合到深度学习模型的训练过程中,以减小仿真样本与实验样本的特征分布差异。网络模型如图5 所示。
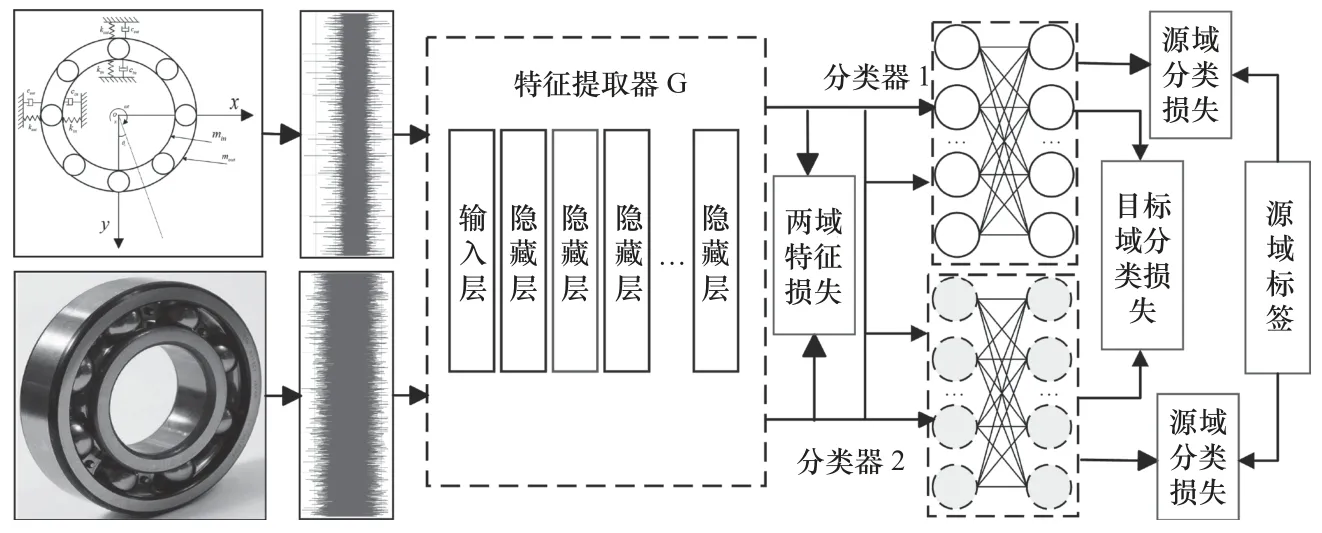
图5 迁移学习网络模型
对于2 个分类器,除了初始化参数不同外,其各自的全连接层采用不同的激活函数,使其输出尽可能具有差异性。分类器网络参数见表2。
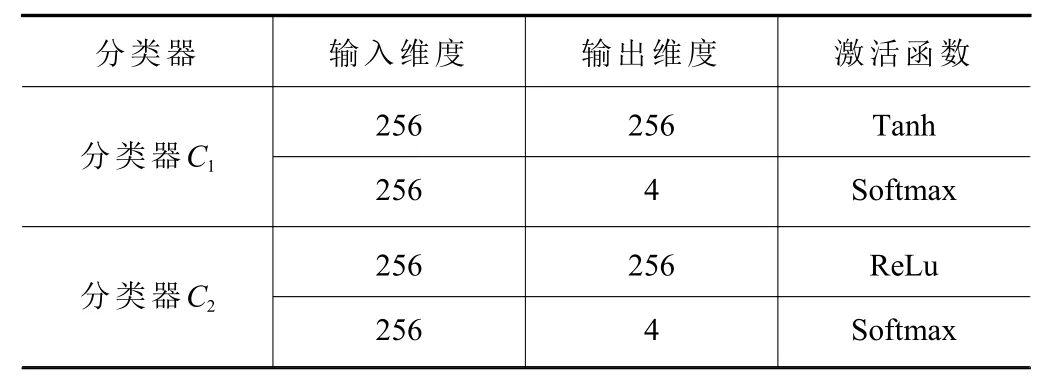
表2 分类器参数
2.4 模型训练过程
针对深度迁移学习模型主要分3 个阶段进行训练。具体流程如下所示:
首先,利用源域和目标域数据对特征提取器G和分类器C1、C2进行训练。保证特征提取器和分类器对源域数据正确分类以及对目标域数据的边缘分布适配。式(10)为该训练过程所优化的目标函数,其中Lc为源域样本上的交叉熵分类损失函数,可按式(11)计算。式(11)中:E()表示对所有源域样本分类损失的期望;K为总类别数;Π[k=ys]表示类别的one-hot 索引值k和标签ys一致时,值为1,否则为0;p(y|xs)为模型对第k个类别的预测概率;Lmmd为源域和目标域在特征层上的mmd 域适应损失。
然后,冻结特征提取器,训练分类器。为了使分类器能够更好地提取除目标域中分歧样本,通过最大化未标记的目标样本的预测差异来寻找源分布支持之外的目标样本,同时最小化标记的源样本的交叉熵来更新两个分类器。此时模型训练优化的目标函数表述为
式中:Ladv为目标域样本在两个分类器上的分类差异损失;其中E(.)表示对所有目标域样本分类差异损失的期望;分类差异d()。
最后,冻结分类器,训练特征提取器。将训练好的分类器固定,训练特征提取器以减小目标域样本的分类差异,让特征提取器在源域特征附近提取目标域样本的相应特征,从而实现对源域与目标域数据的子领域对齐,此时训练优化的目标函数为
3 实验与结果分析
3.1 实验数据
使用滚动轴承仿真数据作为源域样本,凯斯西储大学轴承实验数据作为目标域样本,选取驱动端轴承,型号为SKF 6205-2RS 的实验数据验证上述方法有效性。实验数据采用加速度信号,采样频率为12 kHz,每个样本包含1 024 个采样点。使用重叠采样方法对样本进行分割,每种状态有500 个样本。表3 为各数据样本划分情况以及标签情况。在本方法做领域自适应迁移诊断时,训练样本(仿真数据)除了包括有标签的源域数据样本外,还需要无标签(标准数据集数据)的目标域数据样本参与训练过程进行领域自适应。在训练过程中,其中训练集由不同域80 %的数据样本组成,测试集为剩下20 %的目标域数据。
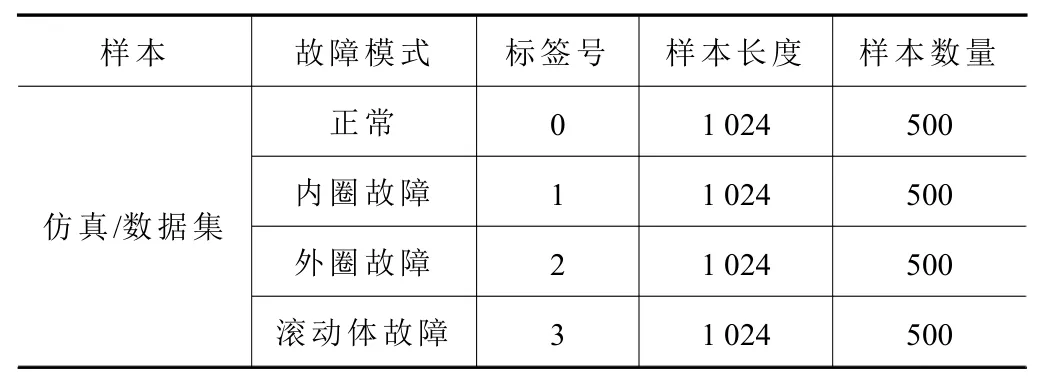
表3 数据样本
3.2 实验设置
将所提方法与无迁移学习模型以及其他主流的深度迁移学习模型进行结果对比分析,进而验证所提方法的有效性。对比模型分别为:模型1 无迁移、模型2 DeepCoral[12]、模型3 深度自适应网络(deep adaptation network,DAN)[13]、模型4 域对抗神经网络(domain-adversarial training of neural networks,DANN)[14]、模型5 深度子领域自适应网络(deep subdomain adaption network, DSAN)[15]。每个模型均进行10 次重复实验取平均值,进而减小初始化模型的随机误差对诊断模型的影响。
采用深度学习框架Pytorch 构建诊断网络,训练时模型迭代轮数保持一致,设置训练轮数为200轮,样本个数batch 为32,采用Adam 梯度优化方法,学习率为0.005。
3.3 实验结果
以模型在测试集上的平均诊断精度和某次结果混淆矩阵来比较各方法的诊断性能。见表4 和图6 所示,在混淆矩阵中横纵坐标分别为诊断模型预测的标签信息和样本真实的标签,其中0、1、2、3 与表4 中标签号对应。使用迁移学习的方法普遍高于无迁移学习模型。其中,DeepCoral、DAN、DANN 方法的平均诊断精度分别为56.42%、75.17%、72.67%,DSAN 方法的平均诊断精度为84.53%,高于前4 类方法,因为其将局部最大均值差异引入模型训练,利用目标域伪标签减小条件分布差异进而实现子领域自适应。本文所提方法的平均诊断精度为87.53%,且标准差相较于其他方法更低,模型稳定性较好,原因其在全局领域适配的基础上,引入最大最小化分类器差异的对抗学习策略,进一步减小了源域和目标域特征的条件分布差异,更好地实现子领域的对齐。但各方法的准确率的标准差都较大,可能由于仿真数据相较于实验数据的分布差异过大,导致模型训练结果不稳定。
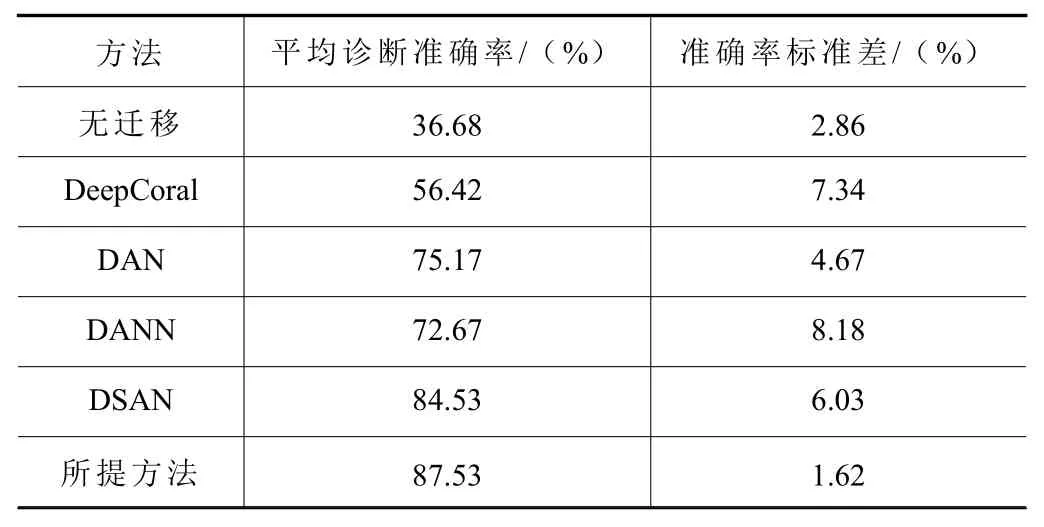
表4 不同方法平均诊断精度
采用t分布领域嵌入将降维过后的特征进行数据并实现特征可视化。图7 中源域为S,目标域为T,NO、OF、IF、BF 分别代表正常、外圈故障、内圈故障、滚动体故障4 种故障状态。上述对比方法的特征可视化结果可知,由于源域的训练样本带有标签,因此在采取迁移策略或不迁移时,源域数据不同故障类别的特征都可以得到有效区分。由图7a 可知,在不使用迁移策略时,目标域的内外圈故障样本大部分都混淆在一起,导致分类精度低。由图7b~图7d 可知,DeepCoral、DAN、DANN 这3 种方法可以将目标域类别的故障特征分得更加清晰,但仍存在混叠区域。由图7e 可知,DSAN 考虑了目标域不同类别的子领域对齐,使特征类间距更小,不同类之间间距更大。由图7f 可知,本文方法由于采用最大最小化分类器差异的域适配方法,能够有效区分目标域不同类别之间的差异。但是也可以看出,源域目标域之间存在部分样本的特征混叠和分类失败结果,其主要原因是实际数据与仿真数据之间由于实际运行中不确定因素的影响导致分布差异过大。
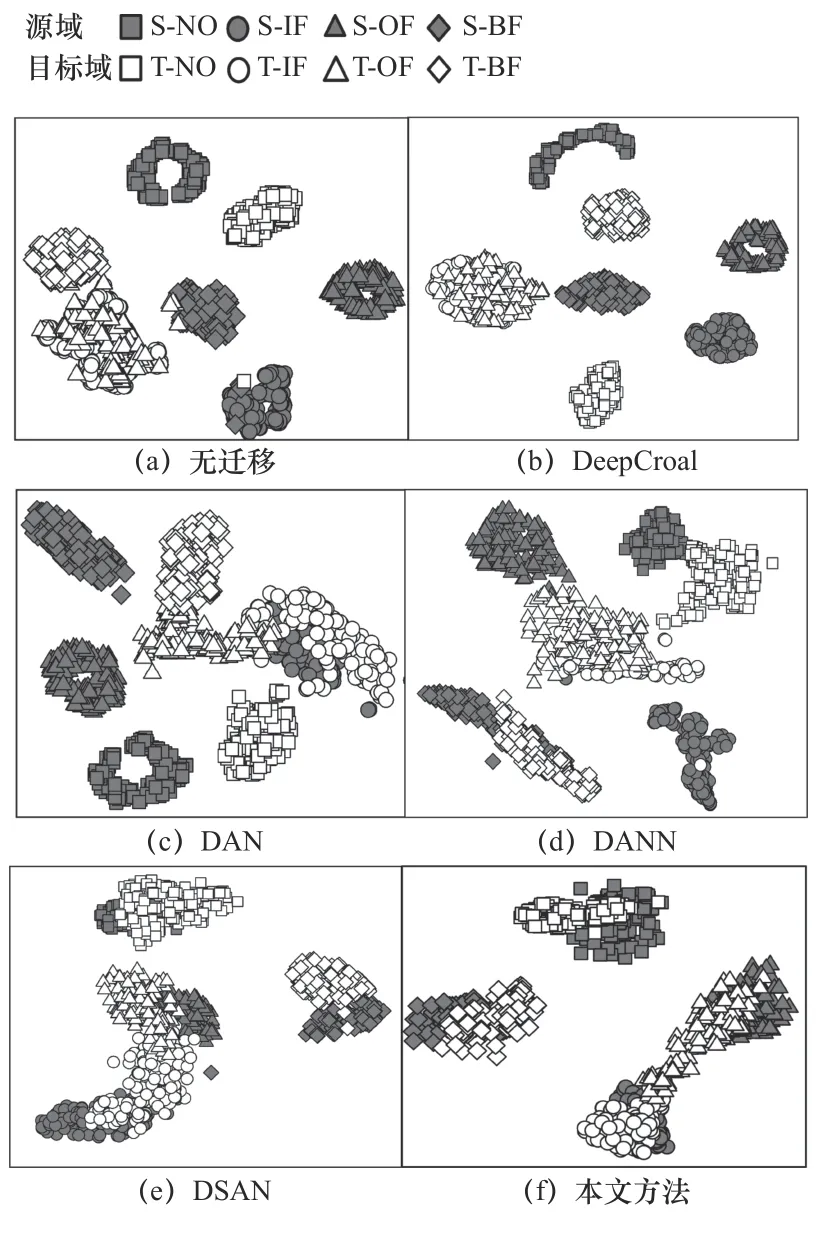
图7 各方法的特征可视化
4 结语
本文针对实际工业生产中轴承故障样本较少的问题,建立了滚动轴承动力学仿真模型,提出基于仿真数据和无监督领域自适应的轴承故障诊断方法。得到了以下结论:
(1) 采用动力学仿真的方法获取源域数据实现对实际数据进行故障诊断,降低了对试验台的依赖,具有一定的实际意义。
(2) 通过无监督领域自适应方法,在实现不用域特征分布对齐基础上,在目标域上引入最大最小分类器差异的对抗学习方法,进一步缩小了不同域特征的条件分布差异,增强了网络模型的预适应能力。
(3) 通过在CWRU 轴承数据集上进行验证并与不同的诊断方法进行对比,结果表明本文方法优于DAN、DANN、DSAN 等方法,但由于数据分布差异,模型诊断精度和稳定性依旧有可改进的空间。
