面向知识发现的图书馆数字资源多粒度跨模态语义挖掘研究
2024-02-08胡秀丽

摘要:知识经济时代,图书馆传统服务方式向知识服务方式转变,用户也对图书馆知识服务方式提出了更高的要求。文章在了解知识发现和语义挖掘研究现状的基础上,从粗、中、细粒度对多模态数字资源化进行了层级分割,同时建立起多粒度数字资源与知识元、知识子集和知识集合的关系,接着利用知识元、知识关联技术构建了面向知识发现的图书馆数字资源多粒度跨模态语义挖掘模型,最后以数字图书资源为例进行了案例分析,旨在为图书馆创新知识服务内容和方式提供参考借鉴。
关键词:知识发现;数字资源;跨模态;多粒度;语义挖掘
中图分类号:G203 ""文献标识码:A
DOI:10.13897/j.cnki.hbkjty.2024.0078
互联网时代,“数据泛滥”与“知识饥渴”并存。知识服务概念的出现,打破了图书馆传统意义上以图书和文献借阅为主的简单服务模式,使得图书馆不断思考和完善知识服务方式,提高知识服务效率。与此同时,互联网技术以及移动通信设备的兴起,用户更多喜欢利用碎片化时间获取知识,这促成了碎片化阅读方式的兴起。碎片化阅读方式给图书馆知识服务提出了更高的要求,以文献、图书等为最小服务单元的服务方式已不能满足当前用户需求,迫切需要图书馆创新资源服务内容和方式。随着数字化技术的发展,图书馆数字资源数量迅猛上涨,如何从多模态、多粒度的数字资源中发现新的知识也是图书馆当前需要解决的问题之一[1]。
知识的粒度决定了知识的利用程度和知识服务的效率。目前,图书馆数字资源在语义挖掘和知识发现方面的研究主要面临以下问题[2]:(1)不同模态之间的语义挖掘不充分,未进行全面的特征表示;(2)多粒度之间的信息使用不充分,未能充分挖掘不同粒度的文献单元的信息。在已有的研究中,学者们在充分思考上述面临的问题后,以粗粒度的文献资源或者细粒度的内容资源单独进行了语义挖掘和知识发现[3],但未能综合考虑数字资源的模态和粒度特征。因此,为进一步挖掘不同模态、不同粒度数字资源间的有效信息,实现资源增值服务,本文在深入分析语义挖掘技术和知识发现技术的基础上,提出将数字资源进行粒度层级分割,利用知识元、知识聚类和知识关联技术对数字资源进行语义挖掘,以实现资源增值,为图书馆创新知识组织方式和知识服务方式提供参考借鉴。
1 相关概念解析
1.1 图书馆数字资源
图书馆数字资源可分为广义和狭义的数字资源。广义的数字资源是指图书馆一切以数字代码形式存在的信息资源,狭义的数字资源主要是指图书馆的电子资源或者电子出版物[4]。一般来说,图书馆数字资源包括自建数字资源(如图书馆自建数据库等)和从外界获取的数字资源(如购买的商业数据库等)。图书馆数字资源具有共享程度高、不受时空限制、管理成本低等特征[5]。
目前,关于图书馆数字资源的研究主要集中在服务现状、资源组织和资源评价等方面。如,肖宗花等[6]利用文献调研、官网数据以及问卷调研三种方式调研分析了图书馆数字资源的建设现状,总结了目前资源服务存在的问题并提出了解决措施;魏明坤等[7]提出了面向语义关联的数字资源聚合框架模型,解决了数字资源多源异构的问题,提高了数字资源的利用效率;王虎等[8]从技术层、功能层和应用层构建了数智时代数字资源的评价指标模型,以期为图书馆数字资源的开发和设计提供参考借鉴。
1.2 数字资源跨模态处理研究
数字资源包含文本、图像、数字等模态,不同模态具有不一样的特征属性。为提高资源的处理效率,学者们开始进行数字资源的跨模态处理研究。目前,关于数字资源跨模态处理的研究主要集中在数字资源特征分析、实践应用等方面,其中数字资源特征分析包含底层特征分析和语义分析两个维度。如,张甜甜[9]通过分析文本和图像的特征,提出了一种跨模态的自动标引系统;强子珊等[10]将社交媒体分为文本、图片、用户三种模态,构建了跨模态信息检测模型。实践应用研究包括跨模态检索、内容编辑器设计等,如,明均仁等
[11]提出一种跨媒体的检索方法,提高了跨媒体检索的效率;钱锋等
[12]设计了多模态数智内容编辑器,该编辑器可以实现跨模态内容的编辑和共享。
1.3 知识发现
知识发现是指利用工具从大量数据中挖掘出新知识,并对知识进行评估的过程
[13],其核心是数据挖掘,具体工具包括机器学习、规则推理等。目前,图情领域关于知识发现的研究主要从数据、知识和系统三个方面开展研究:数据层面主要是算法研究,如Sharma G等[14]提出一种数据预处理算法,利用实时数据集改进知识发现过程;知识层面主要是知识融合研究,如Baldwin E等[15]将知识融合分为数据融合、模型融合和混合融合,并介绍了不同类别下知识融合的原理和应用;系统层面主要是系统设计和平台搭建的研究,如袁虎声等[16]充分利用生成式人工智能技术,从交互层、服务层和引擎层搭建了知识发现平台。
1.4 语义挖掘
语义挖掘是指利用自然语言处理技术,从数字资源中挖掘出隐性知识的过程。语义挖掘关键技术包含文本表示模型、特征选择、特征抽取等技术。目前,关于数字资源语义挖掘的研究主要集中在算法研究、文本分析、应用研究等方面。如,Blei等[17]提出潜在狄里克雷分布概率主题模型,该模型可以将文本描述成低维度的主题向量;刘妍[18]利用语义挖掘技术实现了文本的情感分析,构建了文本的情感分析模型;叶光辉等[19]基于标签语义挖掘构建了城市画像模型,为城市治理提供参考借鉴。
2 图书馆数字资源多粒度跨模态知识层级分割分析
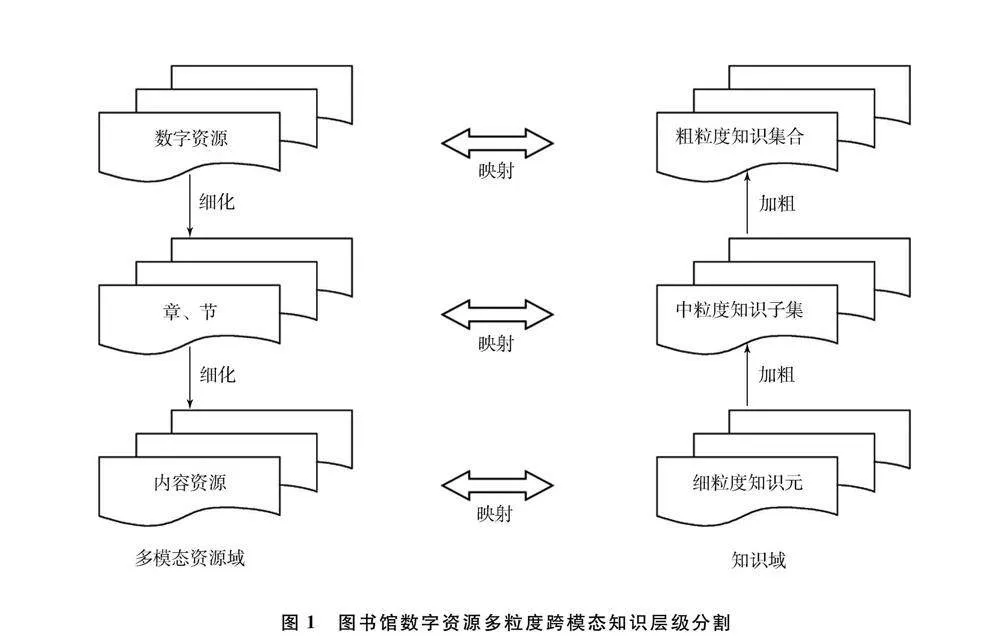
2.1 数字资源粒度及模态的划分
目前,学者普遍将数字资源的粒度划分为粗粒、细粒和中粒三种粒度,其中粗粒度是指最大的父粒,细粒是指不能再划分的粒,而中粒是介于粗粒、细粒之间的粒
[20]。图书馆数字资源的模态基本包含文本、数字、图片三种模态,结合已有研究成果以及数字资源的不同模态特征,本文将数字资源的粒度也划分为:粗粒度即知识集,细粒度即知识元,中粒度即知识子集。以一篇期刊文献为例,涵盖文本、图片和数字的期刊文献本身即一个知识集,被称为粗粒度;文献的某段文字或某个数字或某张图片即知识元,被称为细粒度;文献中的一章、一小节、一段落即一个知识子集,被称为中粒度。
2.2 数字资源多粒度跨模态知识层级分割
本文将存储图书馆数字资源的数据库统称为多模态数字资源域,在此基础上设计了不同粒度数字资源的分割模式以及与知识的映射关系(如图1所示),为后续数字资源的语义挖掘奠定基础。
首先,对多模态的数字资源进行细化。不管是期刊论文还是专利、图书等文献,其文献结构均包含章、节、段落。因此,第一步是将数字资源进行章、节、段落的划分,形成知识子集。
其次,利用知识元模型描述细粒度的数字资源,在知识元与内容资源知识元之间建设映射关系,然后对知识元进行合并、分类、关联,再次形成不同粒度的知识集合,即知识域的细粒度知识元、中粒度知识子集和粗粒度知识集合。
最后,对知识域中形成的知识集进行整理、建立关联关系,实现数字资源的语义挖掘,发现隐性知识和显性知识,为后续知识服务奠定基础。
3 面向知识发现的图书馆数字资源多粒度跨模态语义挖掘模型设计
面向知识发现的图书馆数字资源多粒度跨模态语义挖掘的核心是从不同粒度、不同模态的资源中抽取出知识元,并对知识元进行标引、聚类和关联,再次形成多粒度的知识元库,实现语义挖掘和知识关联,以满足不同用户的知识需求,实现数字资源增值服务。为此,本文提出利用知识元、知识聚类和知识关联技术实现不同模态、不同粒度的数字资源的语义挖掘。该模型包含以下几方面(见图2):(1)数字资源分析;(2)知识元抽取;(3)知识元标引;(4)知识聚类与关联;(5)知识服务与应用。首先对图书馆数字资源进行粒度层级分割,生成细粒度片段;其次抽取细粒度片段中的知识元;接着对知识元进行分类标引和主题标引;然后基于标注结果和关联规则进行知识聚类和关联,实现知识发现和语义挖掘;最后利用上述知识关联结果为用户提供精准的知识服务。
3.1 数字资源分析
数字资源分析主要从资源的逻辑结构和语义结构两方面展开。图书馆数字资源的逻辑结构主要由正文及正文相关信息构成,正文基本由章、节、段落、图表等元素构成,正文相关信息基本由标题、作者、作者单位、摘要、关键词、参考文献等元素构成。数字资源的语义结构是指与逻辑结构建立对应关系的知识单元,全文章、节均可作为一个知识单元。通过对数字资源逻辑结构和语义结构的分析,为后续知识元抽取奠定数据基础。
3.2 知识元抽取
知识元抽取的首要步骤是对数字资源进行预清洗,剔除无关信息。由于数字资源是多模态和多来源的,需要对数字资源进行格式统一,将图像、表格等其他类型资源统一为文本格式资源;其次采用分段式方式读取文本信息,对文本进行分词、排序并赋权,筛选出候选主题词;接着建立抽取规则,如元数据标准等,根据所筛选的候选主题词提取候选句子,再从句子中获取知识元的概念、属性等信息;最后把以上提取的信息按照知识元描述模型进行描述,构成完整的知识单元。
3.3 知识元标引
实现跨模态、多粒度数字资源语义挖掘的关键环节是对知识元进行标引,而知识元标引主要是解决如何对标识组和关系组进行内容描述的问题。首先关于标识组,图书馆应根据上文所抽取的知识元,对其进行标引和编码,为后续知识元的存储与利用提供便利;其次关于关系组,一方面,图书馆需要制定关联算法规则,利用其进行知识元关联,另一方面,图书馆需要注明知识元与数字资源之间的联系,以便为后续关联检索服务提供数据支撑。
知识元标引可从分类和主题两方面进行标引,分类标引可参考借鉴已有分类体系对知识元进行分类,充分揭示知识元间的关系;主题标引可采用粗、中、细粒度相结合的主题标引方法,揭示知识单元间隐含的内部关系,深入挖掘知识元的潜在特征。
3.4 知识聚类与关联
知识聚类即通过建立的规则将碎片化的知识组织起来,从而实现知识发现及知识关联,发现更多隐性知识。本文主要通过建立知识链接,将具有联系的知识聚类成知识集合,这种知识链接既包含显性知识链接,又包含隐性链接。对于显性知识链接,可以通过关系组直接获取;对于隐性知识链接,可利用关联范式挖掘出知识单元间的隐性关系。
3.5 知识服务与应用
通过上文对不同模态、不同粒度的数字资源处理,图书馆可实现语义挖掘和知识发现,为用户提供精准知识服务奠定数据基础。知识服务与应用层是指图书馆通过将用户需求与语义挖掘、知识发现结果建立匹配关系,为用户提供知识检索、推荐和咨询等服务。其中关联性知识检索是指系统通过用户所输入的检索词自动推荐相关联的检索词,系统可自动实现检索词与文献、图片和表格数字的精确匹配,
或者图书馆利用知识导航栏目实时推荐热点主题词,用户可根据主题词推荐,掌握某领域的近期热点研究主题。场景化知识推荐是指将用户所处情境与知识发现结果建立关联,为用户提供情境知识服务,满足用户实时知识服务需求。智能咨询服务是指图书馆提供的一对一咨询服务,用户通过系统提交需求,系统自动将用户需求与知识库匹配,为用户提供实时咨询服务,以满足用户的知识需求。
4 面向知识发现的图书馆数字资源多粒度跨模态语义挖掘案例分析
数字图书资源包含文本、表格、图片等信息,逻辑结构包含章、节、段落等内容,具有多粒度和多模态的特征。因此,本文以图书馆的数字图书馆藏为例进行案例分析。首先对馆藏图书进行多粒度层级分割,筛选出候选主题词;其次构建知识元库,建立知识关联关系,实现图书语义挖掘和知识发现;最后通过关联式检索方式为用户提供知识服务。
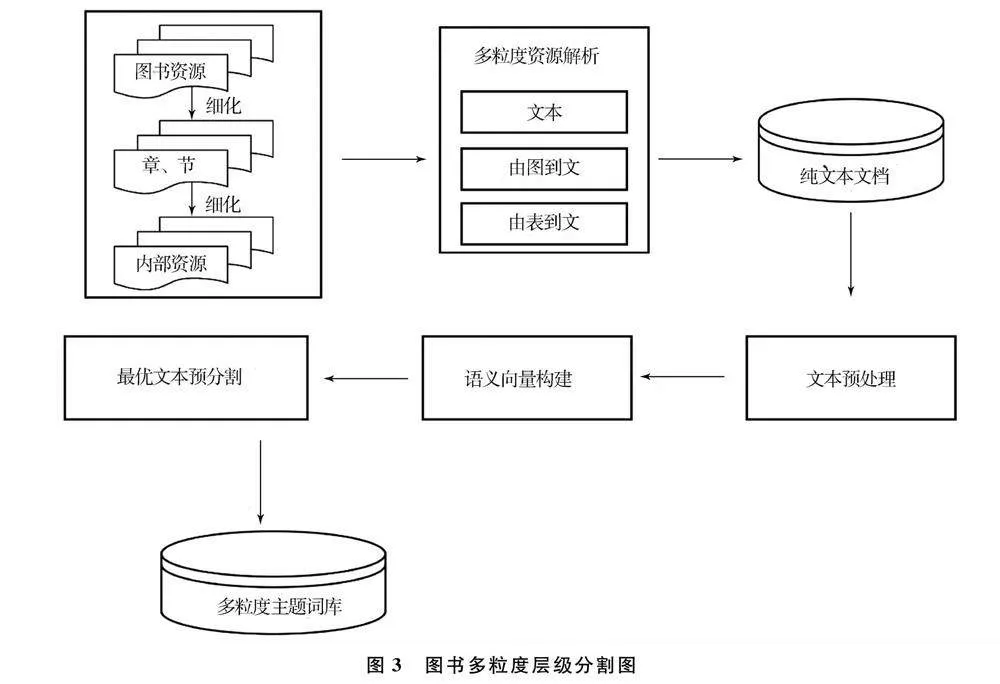
4.1 图书多粒度和跨模态层级分割
本文将图书划分为三个粒度,其中整本图书的标引为粗粒度,图书的章节及段落为中粒度,段落中所包含的内容为细粒度。针对不同粒度和不同模态的信息,本文首先把图书的文本、图像和表格信息统一为文本信息,并对文本进行分词、标注等处理,通过语义向量构建和最优文本预分割后,计算TF-IDF权重,最终确定候选主题词,生成多粒度主题词库,具体如图3所示。
4.2 构建知识元库
首先将候选的主题词作为向导,在特定的图书文本位置进行主题句提取。接着对主题句进行分词等处理,借用依存句法理论界定句子、词、短语间的关系(如主谓宾关系),实现对图书语义的理解,为后续图书知识关联奠定数据基础。
4.3 知识聚合和关联
图书的知识聚合是指利用一定的工具,对存在隐性关系和显性关系的知识进行聚集,从而构建互相关联的知识体系。图书馆通过提取出的知识元,利用知识关联技术,建立知识元间的显性和隐性链接,揭示不同粒度、不同模态图书资源间的概念关系、映射关系、从属关系等,以实现图书语义关联。
4.4 知识服务
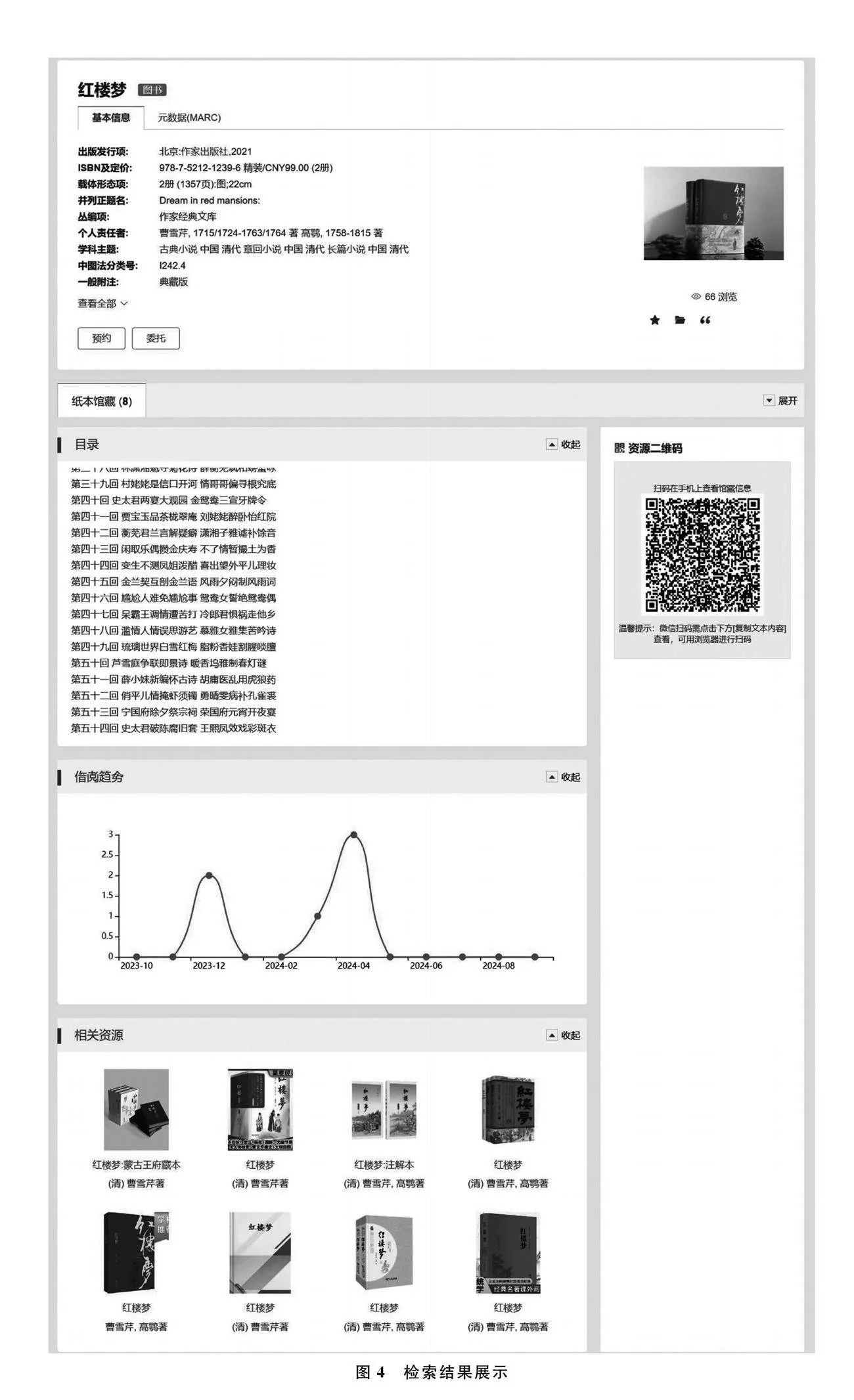
通过对不同粒度图书的语义挖掘,为用户知识服务提供了数据支撑。根据用户不同需求,系统为用户提供了三种检索方式:一是关键词或主题词检索,二是高级检索,三是语句检索。以用户检索《红楼梦》这本书为例,知识关联的检索结果如图4所示,系统为用户提供了不同版本和不同出版社的《红楼梦》书籍推荐,一方面,用户可以找到《红楼梦》这本书的全文,另一方面,用户可以了解到该书的目录、作者简介、书目简介、借阅趋势等信息,页面中还提供相似资源推荐,方便用户更好地理解图书内容。
5 结语
数字资源的多粒度、跨模态的知识组织方式以及资源间的语义挖掘和知识关联,一直是图书馆资源服务工作中的重点,因此,将二者结合,可以有效提高图书馆的知识服务效能。本文在了解知识发现和语义挖掘研究现状的基础上,将多模态数字资源划分为三个粒度:粗粒度即知识集,细粒度即知识元,中粒度即知识子集,并利用知识元、知识关联技术构建了面向知识发现的图书馆数字资源多粒度跨模态语义挖掘模型,最后以数字图书资源为例进行了案例分析。
虽然本文提出了从多粒度角度对数字资源进行语义挖掘,有效提高了数字资源处理效率,创新了图书馆知识服务模式,但未来图书馆数字资源服务中仍需:(1)加强主题分割算法研究。实现数字资源多粒度、跨模态的语义挖掘的关键在于对数字资源进行不同粒度层级的分割,利用工具和方法充分挖掘出数字资源中多粒度知识以及知识之间的关系。因此,未来图书馆仍需不断优化主题分割算法,为后续语义挖掘和知识关联提供更优质的数据支撑。(2)为用户提供动态需求的知识推荐。图书馆加强数字资源知识挖掘的目的是为了给用户提供高质量的知识服务。目前用户的知识服务需求是动态变化的,未来图书馆要在加强用户画像研究的基础上,加强用户动态需求与数字资源语义挖掘和知识发现结果之间的匹配关系研究,提高用户的知识服务体验感。(3)加强知识产权保护。图书馆数字资源均是人类智力劳动的成果,未来图书馆在数字资源加工处理过程中,需要进一步加强知识产权保护,明确规定用户的身份和资源使用限制,切实保护知识产权成果,防止数字资源语义挖掘成果被不正当使用。
参考文献
[1]毕崇武,王忠义,宋红文.基于知识元的数字图书馆多粒度集成知识服务研究[J].图书情报工作,2017,61(4):115-122.
[2]李昂.基于多模态多粒度相关性学习的图文检索研究[D].济南:山东财经大学,2024.
[3]任萍萍.国内图书馆知识服务研究综述(1999-2011)[J].图书情报工作,2012,56(7):5-10.
[4]张盛强.国内外数字资源评估指标体系概述[J].图书馆理论与实践,2007(3):26-28.
[5]董克.数字文献资源多元深度聚合研究[D].武汉:武汉大学,2014.
[6]肖宗花,李梅,于欢.图书馆智慧检索与数字资源建设对策研究[J].产业与科技论坛,2024,23(1):249-251.
[7]魏明坤,滕闻轩,冯昌扬.基于语义关联的数字图书馆馆藏资源聚合研究[J].图书馆理论与实践,2022(5):85-89.
[8]王虎,王景.数智时代数字资源评价模型的构建与应用策略[J].图书馆界,2023(1):5-12.
[9]张甜甜.基于人工智能的图书馆跨模态数字资源自动标引系统设计[J].图书情报导刊,2022,7(11):38-43.
[10]强子珊,顾益军.基于多模态异质图的社交媒体谣言检测模型[J].数据分析与知识发现,2023,7(11):68-78.
[11]明均仁,何超.基于语义关联挖掘的数字图书馆跨媒体检索方法研究[J].图书情报工作, 2013,57(7):101-105.
[12]钱锋,董毅敏,张铁明,等.元宇宙多模态、跨模态内容时代的科技出版理论探讨与实践研究[J].中国科技期刊研究,2023,34(7):902-908.
[13]陆泉,刘婷,张良韬,等.面向知识发现的模糊本体融合与推理模型研究[J].情报学报,2021,40(4):333-344.
[14]Sharma G, Tripathi V. Effective knowledge discovery using data mining algorithm[C]//ICT Analysis and Applications: Proceedings of ICT4SD 2020, Volume 2. Springer Singapore, 2021: 145-153.
[15]Baldwin E, Han J, Luo W, et al. On fusion methods for knowledge discovery from multi-omics datasets[J]. Computational and structural biotechnology journal, 2020(18): 509-517.
[16]袁虎声,唐嘉乐,赵洗尘,等.ChatLib:重构智慧图书馆知识服务平台[J].大学图书馆学报,2024,42(2):72-80.
[17]Blei D M, Andrew Y Ng, Michael I Jordan. Latent Dirichlet Allocation[J].Journal of Machine Learning Research, 2003(3): 993-1022.
[18]刘妍.基于语义挖掘的文本情感分析[D].成都:电子科技大学, 2023.
[19]叶光辉,毕崇武.基于标签语义挖掘的城市画像研究评述[J].现代情报,2021,41(2):162-167.
[20]李成龙.科技报告中粒度关联数据的创建与发布研究[D].武汉:华中师范大学,2014.
作者简介:
胡秀丽,女,硕士,玉林师范学院图书馆副研究馆员。研究方向:图书馆资源建设与服务。
(收稿日期:2024-08-02 责任编辑:侯鹏娟 )
Research on Multi-Granularity Cross-Modal Semantic Mining of
Library Digital Resources for Knowledge Discovery
Hu" Xiuli
Abstract:
In the era of knowledge economy, the traditional service mode of libraries has shifted towards knowledge service mode, and users have also put forward higher requirements for the knowledge service mode of libraries. Based on understanding of the current research status of knowledge discovery and semantic mining, this paper divides multimodal digital resources into coarse, medium, and fine levels, and establishes the relationship between multimodal digital resources and knowledge elements, knowledge subsets, and knowledge sets. Then, using knowledge elements and knowledge association techniques, a multi granularity cross modal semantic mining model for library digital resources oriented towards knowledge discovery is constructed. Finally, digital book resources are taken as an example for case analysis, aiming to provide reference and guidance for innovative knowledge service content and methods in libraries.
Keywords:
Knowledge Discovery; Digital Resources; Cross-modal; Multi-granularity; Semantic Mining
