基于多标记深度森林算法的冷鲜羊肉新鲜度无损检测方法
2024-02-06徐子洋姜新华张文婧
徐子洋, 姜新华*, 白 洁, 张文婧, 李 靖
1. 内蒙古农业大学计算与信息工程学院, 内蒙古 呼和浩特 010018 2. 内蒙古自治区农牧业大数据研究与应用重点实验室, 内蒙古 呼和浩特 010018
引 言
羊肉因其含有丰富的营养物质, 成为人们重要的饮食组成部分, 羊肉品质的管理和监测也受到了人们的高度关注。 羊肉品质会受到自身成分、 贮藏环境和微生物的相互作用发生腐败变质现象, 给羊肉食品的品质和安全带来极大的影响, 使得羊肉新鲜度检测成为肉类食品监测和管理的重要内容之一[1]。 传统检测方法以感官评价和实验室检测为主, 感官评价通过视觉、 嗅觉和剪切力度等方法分析样本的色泽、 气味和嫩度, 但受主观影响较大, 且缺乏对样本内部成分变化的准确判断[2]; 实验室检测可以分析样本内部成分, 但操作复杂, 实验周期较长, 且需要破坏样本, 不易实现快速检测[3]。 高光谱成像技术是一种融合了传统光谱学和计算机视觉的新型无损检测技术, 被广泛应用到农畜产品品质检测研究中[4-5]。 利用高光谱成像技术可以采集到肉类食品的内外变化信息[6-7], 且不破坏样本本身的物理结构。 许多学者研究采用化学计量学方法检测冷鲜羊肉中挥发性盐基氮(total volatile basic nitrogen, TVB-N)含量, 通过与高光谱成像技术的结合以实现冷鲜羊肉品质的无损检测[8-10]。 还有学者通过检测肉类腐败过程中的微生物繁殖数量, 利用高光谱成像技术建立肉类新鲜度评价模型[11]。 但是羊肉的腐败变质是一个复杂的变化过程, 采用单一指标构建无损检测模型, 很难反应羊肉的新鲜状态, 限制了模型的性能和泛化能力[12]。
多标记学习[13]是一类多语义学习建模方法, 该类算法用一组特征描述每个实体对象, 具有多个类别标记, 算法学习的目标是将所属的类别标记赋予待分类对象, 综合反映对象的本质属性。 近年来, 许多学者提出了大量的多标记学习算法, 在自然语言处理[14], 生物信息分析[15]以及场景分类[16]等领域取得了丰硕成果。 常见的多标记学习方法有多标记k近邻法[17], 多标记支持向量机[18], 多标记神经网络[19]等。 多标记学习算法在高光谱无损检测方面的研究成果较少。 有学者将多元线性回归、 典型相关分析和主成分分析思想结合起来提出偏最小二乘法, 应用于食品新鲜度无损检测的特征提取和分类识别中[20], 但此类算法在特征提取过程中, 没有充分考虑标记之间的相关性, 限制了算法的性能。 有学者研究了典型相关分析(canonical correlation analysis, CCA)的多标记特征提取和分类算法及其核化方法[21], 但在CCA核展开中需要通过引入正则项来解决平凡解的问题, 增加了问题求解的复杂性。 有学者研究了基于神经网络的无损检测算法, 将特征信息和标记信息嵌入到潜在的特征空间中, 可获取标记中的相关性, 但是需要精确选择模型的深度, 并且不适合小规模数据集。
深度森林[22]是近年来提出的一种在广度和深度上集成树模型的学习框架, 能够充分表征数据之间的差异性, 同时算法设置的超参数少, 在训练过程中可自动调节模型的结构与大小, 适合用来解决多标记学习问题。 为了研究冷鲜羊肉多指标新鲜度无损检测方法, 提出一种基于随机树构造的多标记深度森林算法, 通过特征筛选挖掘冷鲜羊肉多个指标与高光谱成像数据之间的相关性, 利用层增长控制探索光谱数据中的潜在流型结构, 实现自适应分类, 增强了光谱特征信息的类内紧致性和类间可分性, 提高了新鲜度无损检测模型的适用性和鲁棒性。
1 基于深度森林的多指标新鲜度评价模型
1.1 多标记深度森林模型
预测聚类树(predictive clustering tree, PCT)[23]是一种基于决策树的学习方法, 样本x会根据节点上的规则落到决策树的某一叶子结点上, 叶子结点预测x对应的标记的概率值, 按照概率值可确定样本x属于哪一个类别。 考虑到单棵决策树的性能有限, 可将决策树集成得到森林应用于多标记分类问题中, 如基于PCT的随机森林(random forest of predictive clustering trees, RF-PCT)[24], RF-PCT通过平均每棵树的预测结果输出一个概率向量, 按照其中概率值大小, 确定样本属于某个类别, 如图1所示。
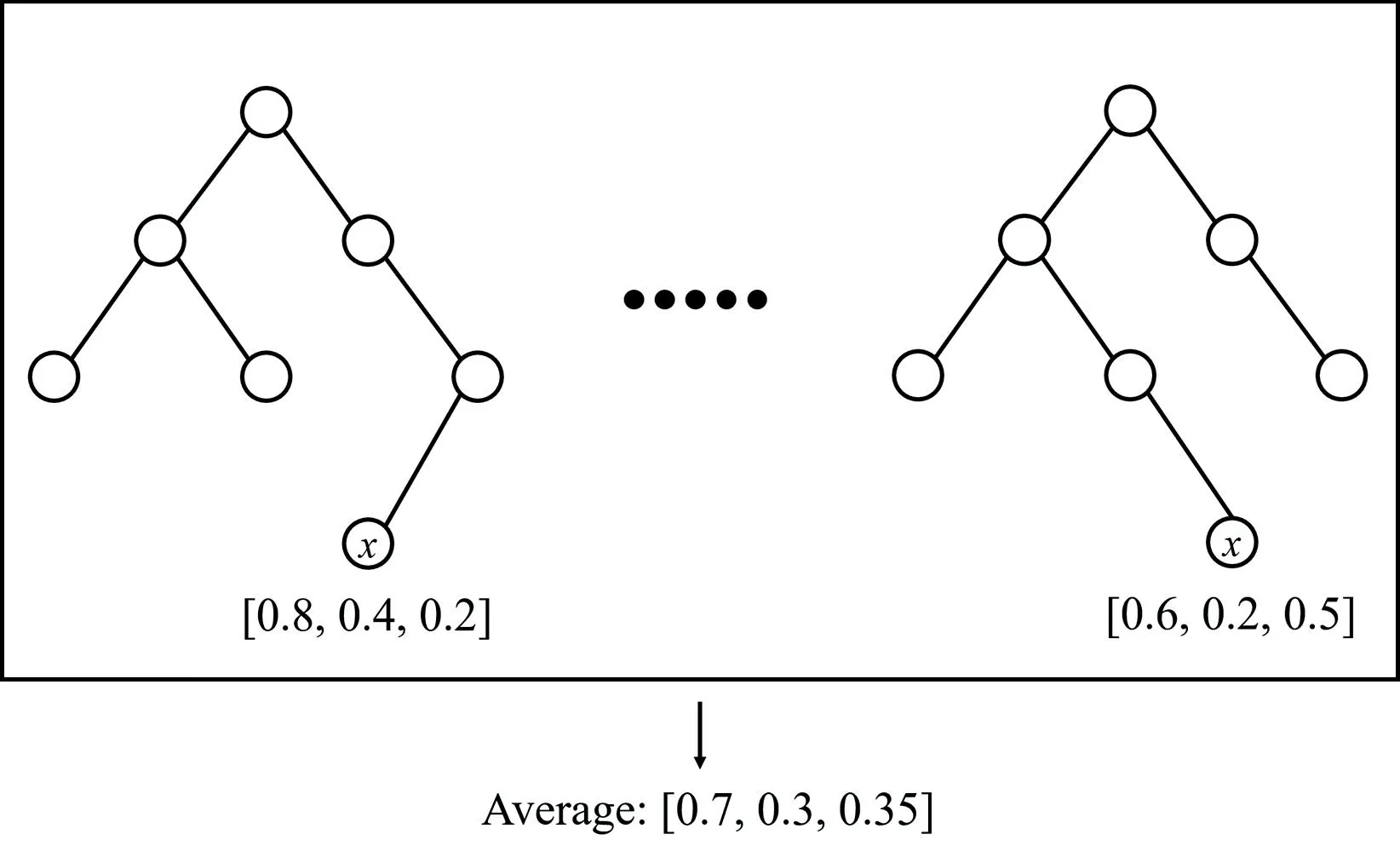
图1 基于PCT的随机森林
深度森林用于多标记分类问题, 需要考虑如何利用标记之间的相关性以提高分类器的性能。 将RF-PCT作为基分类器嵌入到深度森林中, 可以在逐层特征学习中挖掘多个标记之间的相关关系。
利用聚类树构造层森林, 每层包含2个完全随机森林和2个普通随机森林, 再用层森林构造layer-by-layer多层级联的深度森林模型, 模型结构如图2所示。 模型第一层随机森林的输入是经过预处理的冷鲜羊肉样本特征光谱数据, 输入数据经过第一层中各森林的计算输出不同的结果, 将结果拼接形成候选特征空间Ht, 特征筛选用于充分挖掘多个新鲜度评价指标的相关性, 将上一层的候选特征空间Ht经过度量指标的判定, 保留相关性较大的元素, 筛选后的特征空间为Gt。 由于模型训练到第一层时, 还未形成上一层的候选特征空间, 故在第一层Gt=Ht。 为保证原始特征, 每一层筛选后的特征空间Gt都与预处理后的特征光谱数据拼接共同作为下一层的输入。 层增长控制通过度量指标计算每一层的分类性能来判断模型是否充分学习, 进而确定层数来控制模型的复杂度。 最后模型的输出为概率值, 依据概率值确定所属类别。

图2 基于多标记深度森林的新鲜度评价模型结构
1.2 特征筛选
特征筛选根据不同的度量指标计算每一层随机森林输出的置信度, 通过比较置信度, 重新组成特征输入到下一层中。 特征筛选的核心是定义置信度计算方法。
假设评价模型中每一层的输出为Ht, 该值由若干森林的输出拼接得到, 通过森林数量对Ht求平均值得到该层的预测概率矩阵P,P的行数为样本数, 列数为标记数。 当度量指标基于实例时, 把矩阵P的每一行元素按照从大到小排序; 当度量指标基于标记时, 把矩阵P的每一列元素按照从大到小排序。
Hamming loss用来判断P上的分类是否正确。 假设阈值θ=0.5,pij>0.5时预测结果为1, 该值越大, 证明预测为1的概率越大, 故置信度越大;pij≤0.5时预测结果为0, 该值越小, 证明预测为0的概率越大, 故置信度越大。 因此Hamming loss置信度可以定义为
(1)
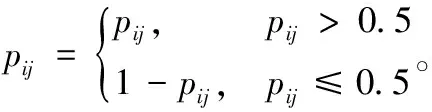
One-error用来判断相关标记中预测的最大概率, 故One-error置信度可以定义为预测最大概率值
αi=maxpij
(2)
Ranking loss用来判断样本的所有标记的排列顺序, 由Ranking loss定义可知, Ranking loss为0时, 模型性能最佳, 故在定义置信度时, 需要列出Ranking loss为0时的各种组合。 若存在4个标记, 则可能的组合有{0000, 1000, 1100, 1110, 1111}五种, 通过计算这些组合的概率之和得到Ranking loss置信度。
(3)
Macro-AUC用来判断标记上所有样本的排列顺序, 与Ranking loss类似, Macro-AUC为1 时, 模型性能最佳, 故在定义置信度时, 需要列出Macro-AUC为1 时的各种组合, 计算这些组合的概率之和, 得到Macro-AUC置信度。
(4)
通过置信度对特征进行筛选, 表1为特征筛选过程。

表1 特征筛选过程


图3 特征筛选
根据森林的输出Ht和标记集Y计算当前层的度量值, 在计算度量值时也需要将基于实例的度量和基于标记的度量分开计算。 每一层的阈值将由该层的度量值和置信度决定, 若当前层特征上的度量值小于前一层特征上的度量值, 则将当前层特征上的置信度存储到集合S中, 最后对S中的置信度求平均值作为当前层的阈值。
1.3 层增长控制
为了降低模型过拟合的风险, 达到控制模型复杂度的目的。 提出的评价模型采用K折交叉验证将训练数据分为K个组, 对于每一组数据, 使用其他所有组的数据进行训练, 并对当前组数据进行预测。 表2为层增长控制流程, 假设模型最大深度为T, 训练集为X, 标记集为Y, 度量指标为M, 以及包含每层度量值的数组q, 其中性能最好的值定义为qbest。 当评价模型通过特征筛选得到第t层的输出Ht之后, 根据度量指标M计算该层的度量值q[t], 若q[t]大于qbest, 则更新qbest值; 若q[t]连续三次小于qbest并且t在T的范围内, 则停止层的增长, 同时保留包括qbest所在的层与前面的所有层, 删除后面所有层。

表2 层增长控制流程
2 实验部分
2.1 试验材料
试验所用冷鲜羊肉样本取自内蒙古锡林郭勒盟苏尼特右旗农贸市场, 选择屠宰后经过排酸的5只羊酮体里脊部位, 去除脂肪和结缔组织, 均匀分割成6 cm×6 cm×1 cm的肉片, 用保鲜袋分3组密封包装、 并编号, 无挤压放置在温度为4 ℃的冰箱中, 存放14 d。 每隔24 h取一次样本, 在室内放置25 min, 挥发掉样本表面的水分, 用于挥发性盐基氮(total volatile basic nitrogen, TVB-N)、 酸碱度(pH值)、 菌落总数(total aerobic count, TAC)、 大肠菌群近似数(approximate number of coliforms, ANC)测定和光谱反射率采集, 试验样本覆盖了新鲜、 次新鲜和不新鲜三个冷鲜羊肉新鲜度等级, 新鲜羊肉表面有光泽, 肉细而紧密; 不新鲜羊肉表面无光泽, 肉色深暗, 肉质松弛无弹性; 次新鲜为过渡阶段, 无论表面情况或触摸手感均处于新鲜与不新鲜之间。
2.2 新鲜度指标实验室测定
样品的TVB-N含量依据GB/5009.228—2016《食品安全国家标准食品中挥发性盐基氮的测定》中的半微量凯氏定氮法测定[25]; pH值依据GB/5009.237—2016《食品安全国家标准食品pH值的测定》中的非均值化试样测定法测定[26]; TAC含量依据GB/4789.2—2022《食品安全国家标准食品微生物学检验菌落总数测定》中单位质量菌落总数标准值进行检测试验[27]。 ANC含量依据GB/4789.3—2016《食品安全国家标准 食品微生物学检验 大肠菌群计数》中单位质量大肠菌群数标准值进行检测试验[28]。
图4为冷鲜羊肉样本在14天内四项指标的变化趋势, 由图可知, 贮藏初期样本中各指标含量较低, 随时间增加, 各指标含量逐渐增加, 其中TVB-N在第5天、 第10天和第14天增幅较大; pH值在第4天和第10天增幅较大; TAC含量在第5天增幅较大; ANC含量在第4天和第9天增幅较大。 可以初步判断冷鲜羊肉样本分别在第4~5天、 第9~14天内新鲜度等级发生变化。

图4 各新鲜度指标变化趋势
根据国家食品卫生监测标准和以往的研究成果, 当TVB-N含量≤15 mg·(100 g)-1时, 为新鲜肉; 当15 mg·(100 g)-1
2.3 样本光谱数据采集
高光谱采集系统包括照明设备、 机械扫描平台、 高光谱成像仪(Hyperspec VNIR N-series)、 反射参考板和图像采集软件, 光谱仪可采集的波长范围在400~1 000 nm, 共有750个光谱通道, 分辨率为2.8 nm。
每次试验时, 提前30 min打开光谱仪预热, 将样本放置在距光谱仪镜头约40 cm处, 设置像元混合次数为6次, 光谱仪曝光时间为3 ms, 调节光谱像元亮度(DN)值小于8 500。 试验时, 利用调焦板调节光谱仪, 设置光谱仪扫描方向、 次数和移动速度, 采集黑白校正光谱图像, 用于获取样本校正光谱数据。 利用ENVI软件, 从样本的每一个光谱图像中随机选取20个感兴趣点作为特征提取和校正模型建立试验数据。 图5为实验样本部分感兴趣区域原始光谱DN值。
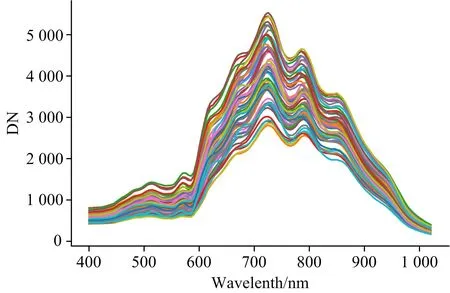
图5 部分感兴趣区域原始光谱反射DN值
黑白校正后的光谱数据仍存在部分噪声且光谱强度有差异, 需要对其进行预处理, 因此, 采用卷积平滑法(Savitzky-Golay)进行平滑滤波, 再采用多元散射校正对平滑滤波后的光谱数据进行处理, 消除光谱中的基线平移或偏移现象, 提高光谱信噪比, 用于后期的特征提取和分类识别。 经过平滑滤波和散射校正后的光谱曲线如图6所示。

图6 预处理后光谱反射DN值
2.4 样本光谱数据特征提取
试验采用连续投影算法对样本光谱数据进行特征提取, 假设数据集X中的样本数为M, 原始特征数为J, 选择的第一个波段为i(0), 算法在每次迭代中合并新的波段, 直到集合中存在N个波段, 算法流程如表3。

表3 连续投影算法
若N和i(0)是未知的, 则对N定义一个范围Nmin≤N≤Nmax, 对每个N, 需要考虑初始波段i(0)从1到J的每一种情况, 进行步骤2—步骤6计算, 根据输出结果i(n)建立多元线性回归分析模型, 以i(n)对应的光谱数据作为测试集, 以TVB-N、 pH、 TAC和ANC含量为标记, 计算均方根误差(root mean square error, RMSE), 其最小值对应的i(0)和N即为最优初始波段和选择的波段数。 试验设置特征波长个数范围为5~30, 共提取了18个特征波段, 如图7所示。

图7 提取特征波段
2.5 建立分类模型
采用本文提出的深度森林建立冷鲜羊肉新鲜度评价模型, 将280个光谱样本按照3∶1的比例划分为训练集和测试集, 训练集和测试集样本个数分别为196个和84个, 表4为训练集和测试集的新鲜、 次新鲜和不新鲜样本数统计结果。

表4 冷鲜羊肉不同新鲜度样本数统计
将理化微生物实验方法测得的TVB-N、 pH、 TAC和AVC四项新鲜度评价指标按照国家食品卫生监测标准和前人研究成果, 分别划分出新鲜、 次新鲜和不新鲜的区间, 并组成标记, 图8为建立新鲜度分类模型所用的冷鲜羊肉样本标记。

图8 某冷鲜羊肉样本标记
其中三种不同的颜色对应三个新鲜度等级, 绿色表示新鲜区间, 黄色表示次新鲜区间, 红色表示不新鲜区间。 新鲜度分类模型中的所有标记均按照此规则产生, 若将其视为一个长度为12的数组Z。 当样本新鲜度为新鲜时, 绿色单元格所在的标记为属于该样本的标记, 其数组为[1, 0, 0, 1, 0,0, 1, 0, 0, 1, 0, 0]; 当样本新鲜度为次新鲜时, 橙色单元格所在的标记为属于该样本的标记, 其数组为[0, 1, 0, 0, 1, 0, 0, 1, 0, 0, 1, 0]; 当样本新鲜度为不新鲜时, 红色单元格所在的标记为属于该样本的标记, 其数组为[0, 0, 1, 0, 0, 1, 0, 0, 1, 0, 0, 1]。
在新鲜度等级预测过程中, 若四项新鲜度评价指标含量都处于新鲜区间, 则表明样本为新鲜; 若其中一项或多项处于次新鲜区间, 则表明样本为次新鲜; 若其中一项或多项处于不新鲜区间, 则表明样本为不新鲜。
试验建立的深度森林参数设置如下, 将最大层数设置为10, 每层的森林数为2, 分别为PCT组成的一个随机森林和一个极端随机森林, 其中每一个森林设置5棵树, 后面的每一层都比前一层多5棵树, 该方法可以保证模型在每一层都能学习到不同的表示。 同理, 森林的最大深度为3, 后面的每一层都比前一层的森林最大深度多3个单位。 最后设置5折交叉验证以防止过拟合。
3 结果与讨论
使用hamming loss、 one-error、 ranking loss和macro-AUC四个度量指标对冷鲜羊肉多指标新鲜度分类模型进行评价。 将本文提出的深度森林评价模型与ML-kNN, RF-PCT相比较, 其在测试集上的各项度量指标如表5所示。 “↓”表示该指标值越小, 模型性能越好; “↑”表示该指标值越大, 模型性能越好。

表5 不同多标记分类算法下建立的冷鲜羊肉新鲜度分类模型性能
试验设置ML-kNN模型参数k值为10。 RF-PCT模型中, 设置森林最大深度为3, 树的总数为100。 试验分别在以上算法中, 记录了10次测试集的度量值和偏差, 并取平均度量值用于模型性能比较。 由表5可知, 本文提出的算法在每个度量指标上均优于ML-kNN和RF-PCT, 验证了多指标新鲜度评价模型在冷鲜羊肉高光谱数据集上的有效性。
图9、 图10分别为评价模型在训练集和测试集上的分类结果图, 其中横坐标表示样本数, 纵坐标表示分类值, 纵坐标上的“1”, “2”, “3”分别代表新鲜、 次新鲜和不新鲜三个新鲜度等级, “o”表示样本的实际新鲜度等级, “+”表示模型预测结果。 从图中可以看出模型取得了较好的分类结果。 由本文提出的评价模型得到的冷鲜羊肉新鲜度分类结果混淆矩阵如表6所示。
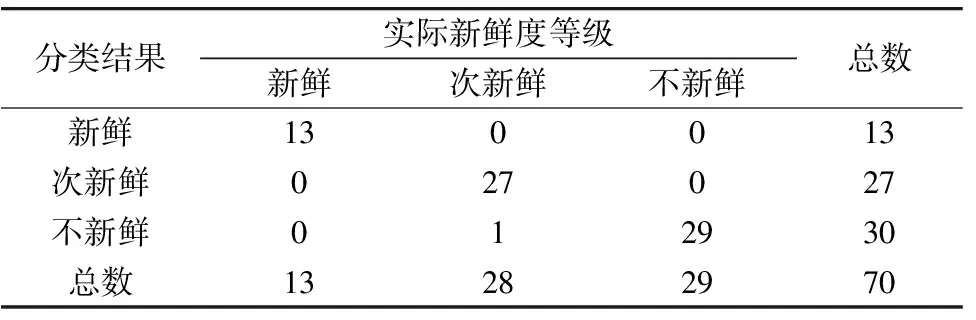
表6 冷鲜羊肉新鲜度分类结果混淆矩阵
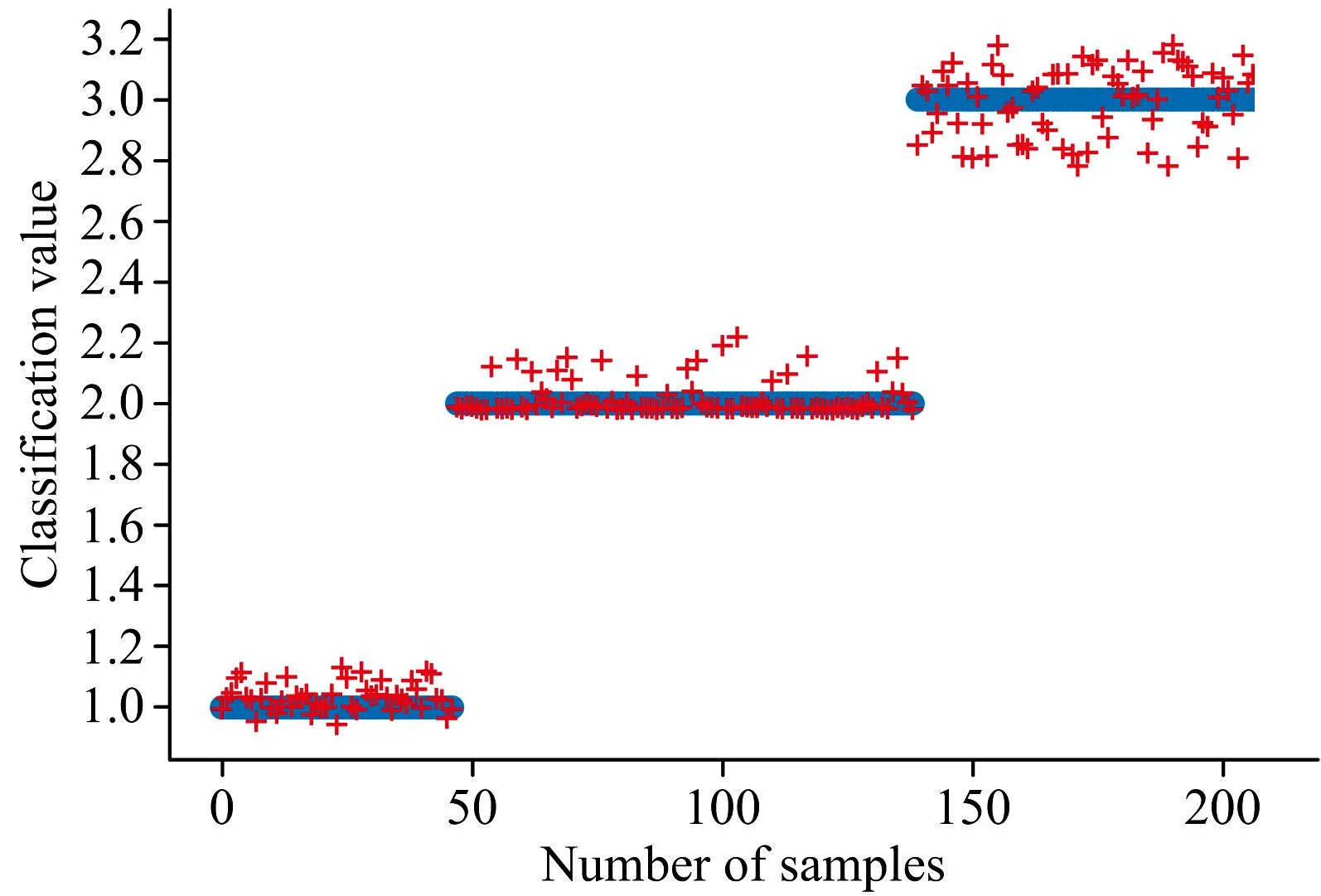
图9 本文提出的算法在训练集上的分类结果图
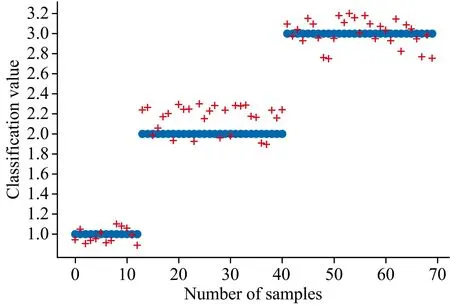
图10 本文提出的算法在测试集上的分类结果图
通过分析混淆矩阵可知, 模型在分类过程中产生了一定的误差, 原本属于次新鲜等级的样本有1个样本点被分类为不新鲜等级。 从冷鲜羊肉新鲜度变化的角度, 冷鲜羊肉的腐败是一个渐进的过程, 尤其是在新鲜度为次新鲜与不新鲜的区域, 两者的新鲜度指标值比较接近且样本基数相比于新鲜样本较多, 故导致模型存在误差。 从高光谱成像仪采集冷鲜羊肉光谱数据的角度, 由于环境等因素也会导致光谱数据上的新鲜度信息存在一定的误差, 故导致模型分类结果存在误差。
4 结 论
以冷鲜羊肉为研究对象, 采用高光谱成像技术和实验室方法, 获取冷鲜羊肉样本的TVB-N、 pH、 TAC和ANC新鲜度评价指标值, 并采集样本高光谱成像数据, 选择感兴趣区域, 采用多元散射校正法和平滑滤波法对原始光谱图像进行预处理。 使用连续投影法提取光谱的特征波段, 利用基于PCT的随机树构建深度森林模型, 建立冷鲜羊肉新鲜度的多指标无损检测模型, 模型识别准确率达到98.57%。 利用hamming loss、 one-error、 ranking loss和marc-AUC等度量指标筛选每层计算得到的特征信息, 控制模型的复杂度。 通过实验与其他多标记分类算法ML-kNN、 RF-PCT进行比较。 结果表明, 本文提出的深度森林模型在冷鲜羊肉高光谱数据集上分类效果更好, 证明了深度森林用于冷鲜羊肉新鲜度多指标分类上的有效性和可适用性。
