高光谱成像的黄瓜病虫害识别和特征波长提取方法
2024-02-06李翠玲范鹏飞李余康翟长远
李 杨, 李翠玲, 王 秀, 范鹏飞, 李余康, 翟长远, 3*
1. 江苏大学农业工程学院, 江苏 镇江 212013 2. 北京市农林科学院智能装备技术研究中心, 北京 100097 3. 国家农业智能装备工程技术研究中心, 北京 100097
引 言
黄瓜是我国重要农业经济作物, 市场需求量大, 经济效益高, 在全国各地均有种植[1]。 黄瓜生长过程中病虫害较多且传染速度快, 如果不及时正确防治, 会造成严重经济损失。 霜霉病是温室黄瓜生产中最严重的流行性病害之一, 可以使黄瓜叶片在短期内迅速枯干, 然后全株枯死, 导致黄瓜质量和产量大大降低[2]。 斑潜蝇是黄瓜上危害最严重的害虫之一, 成虫会刺伤叶片吸取汁液并在叶片中产卵, 孵化出的幼虫取食叶片和叶柄, 造成叶片水分散失和叶绿素受损, 使黄瓜严重减产[3]。 传统黄瓜生产过程中, 病虫害识别主要依赖于人工识别, 通过种植人员和专业人员的经验来判断病虫害种类。 这种方式主观性强, 易混淆病情, 可能导致防治不及时和错误用药。 因此, 准确识别病虫害对黄瓜生产和环境安全有着重要意义。
高光谱成像技术能同时获得作物的图像信息和光谱信息, 目前已广泛用于作物病虫害检测的研究。 Susic等[4]利用高光谱成像对番茄植株的线虫侵害和水分缺水胁迫进行了早期检测, 采用偏最小二乘判别分析(PLS-DA)和偏最小二乘支持向量机(PLS-SVM)分类方法, 最终得到PLS-SVM模型对水分充足植株和缺水植株识别准确率达到100%, 对线虫侵害的植株识别准确率达到90%以上。 Li等[5]针对黄瓜炭疽病和褐斑病的识别问题, 提出一种基于扩展协同表示(ECR)的分类模型, 对黄瓜无症状叶片、 炭疽病叶片、 褐斑病叶片的识别准确率高于94%。 白雪冰[6]等针对黄瓜白粉病的识别问题, 提出一种基于可见光谱图像联合区间的偏最小二乘回归判别模型(SI-PLSR), 校正集和验证集的相关系数分别达到0.975 2和0.919 5, 实现了白粉病的快速无损检测。 秦立峰等[7]针对黄瓜霜霉病早期检测问题, 采集不同感染天数的黄瓜叶片高光谱图像, 提出了Dis-CARS-SPA-LSSVM模型, 对染病早期的黄瓜叶片识别率达到95%以上。 谢传奇等[8]使用格拉姆斯密特(MGS)模型和贝叶斯罗蒂斯克回归(BlogReg)提取特征波段, 建立最小二乘-支持向量机(LS-SVM)和线性判别分析(LDA)模型, 对健康番茄叶片和早疫病番茄叶片识别率达到96%以上。 上述研究表明高光谱成像用于作物病虫害识别已取得较好的效果, 但目前针对黄瓜病虫害一体化识别的研究较少, 同时, 利用高光谱成像识别黄瓜斑潜蝇虫害的研究还鲜有报道。
以黄瓜叶片霜霉病和斑潜蝇虫害为研究对象, 通过无症状叶片、 霜霉病叶片和斑潜蝇虫害叶片的高光谱图像, 研究识别黄瓜病虫害的方法, 探究黄瓜病虫害识别的特征波长。 利用直接正交信号校正、 多元散射校正、 移动窗口平均平滑三种方法对原始光谱数据进行预处理, 采用空间迭代收缩法、 竞争性自适应重加权算法、 迭代保留信息变量法、 随机蛙跳算法对预处理后的光谱数据进行特征波长提取, 然后使用连续投影算法分别对特征波长光谱数据进行二次降维, 分别对全波段光谱数据、 一次降维光谱数据、 二次降维光谱数据进行支持向量机、 Elman神经网络、 随机森林建模, 以期为开发实用性强、 成本低的黄瓜病虫害识别设备提供科学基础。
1 实验部分
1.1 材料
样品来自国家精准农业研究基地温室, 品种为春秋绿8号, 黄瓜植株在自然状态下感染霜霉病和斑潜蝇。 采集60片无症状叶片, 58片霜霉病叶片, 60片斑潜蝇虫害叶片, 存放于恒温箱, 快速运回实验室进行高光谱图像采集。
1.2 高光谱成像系统及图像采集
高光谱成像系统如图1(a)所示, 主要由计算机、 高光谱相机、 光源等组成。 高光谱相机采用美国SOC公司的SOC710Enhanced, 波长范围为400~1 000 nm, 光谱分辨率为2.3 nm, 光谱波段数为260。 相机内置推扫装置。 光源为两个135W的卤素灯。

图1 高光谱成像系统
高光谱图像采集时的物距为45 cm, 光圈为f/5.6, 曝光时间为35 ms, 采集的图像大小为696×696。 采集后将高光谱图像原始数据的像元亮度值(digital number, DN)转化成光谱反射率供后续处理。 图2为三类黄瓜叶片RGB显示下的高光谱图像, 图2(a)为无症状叶片、 图2(b)为霜霉病叶片、 图2(c)为斑潜蝇虫害叶片。

图2(a) 无症状叶片
1.3 高光谱数据提取
使用ENVI5.1对高光谱图像进行数据提取后将数据导入float文件, 显示464、 513和660 nm三个波段图像合成的RGB图像, 如图3所示, 根据病斑区域大小选择若干个10×10的感兴趣区域(region of interest, ROI), 提取每个ROI的平均反射率数据作为叶片的原始光谱数据, 共提取2 656组数据。 由于光谱曲线的两边缘区噪声较大, 故去除保留450~850 nm的159个波段作为有效光谱范围, 图4为所有叶片原始光谱曲线图, 图5为三类叶片的平均光谱曲线, 由图5可知三类叶片的平均光谱曲线整体走势相似, 由于叶绿素对蓝紫光和红光吸收能力强, 对绿光吸收能力弱, 光谱曲线在450nm处反射率最低, 在550 nm处形成波峰, 在680 nm处形成波谷。 曲线在680~750 nm反射率急剧上升, 在750~850 nm具有较高的反射率。 病虫害叶片在400~700 nm波段反射率高于无症状叶片, 在720~850 nm波段反射率低于无症状叶片, 分析原因是病虫害导致叶片叶绿素和细胞结构受损。 由于斑潜蝇侵害叶片后会留下白色虫道, 所以斑潜蝇叶片在400~700 nm波段反射率更高。

图3 ENVI中叶片ROI提取

图4 样本原始光谱曲线

图5 三类叶片平均光谱曲线
1.4 光谱数据预处理
高光谱图像采集过程中, 受高光谱相机性能和测量环境的影响, 光谱信号会受到杂散光、 噪声、 基线漂移等因素的干扰。 为了消除干扰, 建立稳定、 可靠的模型, 需要对光谱数据进行预处理。 利用直接正交信号校正(direct orthogonal signal correction, DOSC)、 多元散射校正(multiplicative scatter correction, MSC)、 移动窗口平均平滑(moving average, MA)3种方法对光谱数据进行预处理。
1.5 特征波长提取
高光谱图像的光谱数据量大, 存在冗余信息, 会增加判别模型的计算量, 降低模型的计算效率和精度[9], 所以需要对光谱数据进行降维处理, 提取其中和样品类型相关性强的波长数据。 采用空间迭代收缩法(variable iterative space shrinkage approach, VISSA)、 竞争性自适应重加权算法(competitive adaptive reweight sampling method, CARS)、 迭代保留信息变量法(iteratively retains informative variables, IRIV)、 随机蛙跳算法(shuffled frog leaping algorithm, SFLA)进行特征波长提取, 使用连续投影算法(successive projections algorithm, SPA)对特征波长光谱数据进行二次降维。
1.6 模型建立
1.6.1 支持向量机
支持向量机(SVM)建立在机器学习理论的结构风险最小化原则上, 能够在小样本情况下获得最优解。 SVM的主要思想是在n维空间中寻找能区分正例和反例的最佳分类面, 面对非线性问题时, 借助核函数将输入空间变换到一个高维空间, 然后在这个新空间中求取最佳分类面。 选择适当的核函数可以提高分类效率, 并且使样本的划分更为清晰, 选择径向基核函数(radical basis function, RBF)作为核函数。
1.6.2 Elman神经网络
Elman神经网络是一种典型的动态递归神经网络, 由输入层、 隐含层、 承接层和输出层构成[10]。 基于Elman神经网络的四层结构, Elman神经网络具有全局稳定性高, 计算速度快, 自适应和学习能力强的优点。 选择Elman神经网络的激活函数为tansig, 输出层激活函数为purelin。
1.6.3 随机森林
随机森林(random forests, RF)是将多棵决策树集成的一种算法。 面对分类问题时, 每棵决策树都是一个分类器。 每颗决策树都随机且有放回地从训练集中抽取样本作为该树的训练集。 对于一个输入样本, 每棵树会产生一个分类结果, 随机森林将投票次数最多的类别指定为最终的输出结果[11]。 随机森林具有不容易陷入过拟合, 抗噪能力强的优点。
1.7 模型评价
采用测试集的总分类精度(overall accuracy, OA)和Kappa系数作为模型评价标准。 测试集的OA是测试集所有分类准确的样本占测试集全部样本的比例。 Kappa系数为检验预测结果和实际分类结果是否一致的指标。
2 实验部分
2.1 样本划分
本研究共提取2 656组光谱数据, 使用Kennard-Stone算法将数据集以3∶1比例划分为训练集和测试集, 划分结果如表1所示。

表1 样本划分
2.2 基于全波段数据建模


表2 全波段光谱数据建模结果
2.3 特征波长提取和建模
2.3.1 基于VISSA的特征波长提取
VISSA基于模型集群分析(model population analysis, MPA)的思想, 利用加权二进制采样法构造变量子空间, 每一次迭代过程满足变量空间逐渐收缩和变量空间逐渐优化两个准则[12]。 设定VISSA的加权二进制矩阵采样数为5 000, 选择子模型比率为0.05, 交叉验证次数为5, 最终选择出53个特征波长, 如图6(a)所示, VISSA提取出的特征波长主要分布于450~700和725~850 nm。
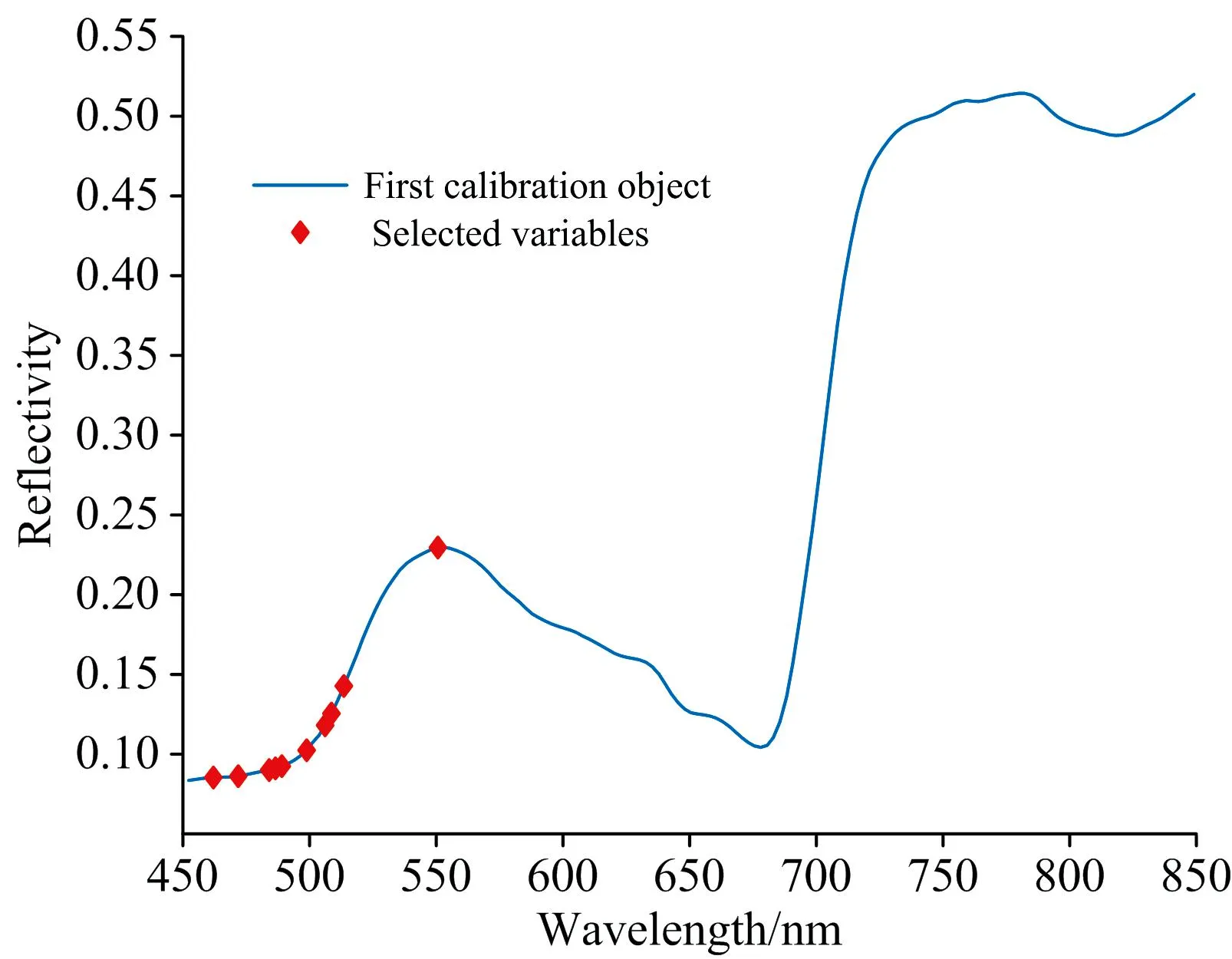
图6(d) SFLA提取特征波长
2.3.2 基于CARS的特征波长提取
CARS基于达尔文理论中的“适者生存”原则, 以PLS模型中回归系数的绝对值大小作为变量重要性的评价指标, 根据PLS模型交叉验证均方根误差大小选择最优特征变量组合[13]。 设定CARS的蒙特卡洛采样次数为50, 交叉验证次数为5, 最终选择出20个特征波长, 如图6(b)所示, CARS提取出的特征波长主要分布于450~500和530~580 nm。
2.3.3 基于IRIV的特征波长提取
IRIV将变量进行多次随机组合并建立PLS模型, 观察每个变量是否存在于模型中时交互验证预测误差的变化, 根据MPA的思想将变量分为强信息变量、 弱信息变量、 无信息变量和干扰变量, 逐个分析每个变量后去除无信息变量和干扰变量, 进行多次迭代分析, 直到剩下的变量均为强信息变量和弱信息变量, 最终保留的变量即为所需的特征变量[14]。 设定交叉验证次数为5, 最终选择出26个特征波长, 如图6(c)所示, IRIV提取出的特征波长主要分布于450~555 nm。
2.3.4 基于SFLA的特征波长提取
SFLA是一种后启发式群体进化算法, 结合了基于模因进化的模因演算法和基于群体行为的粒子群算法的优点, 计算速度快, 全局搜索寻优能力强[15]。 本研究中SFLA最终选择出10个特征波长, 如图6(d)所示, SFLA提取出的特征波长主要分布于450~515和550 nm。
2.3.5 模型建立
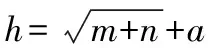
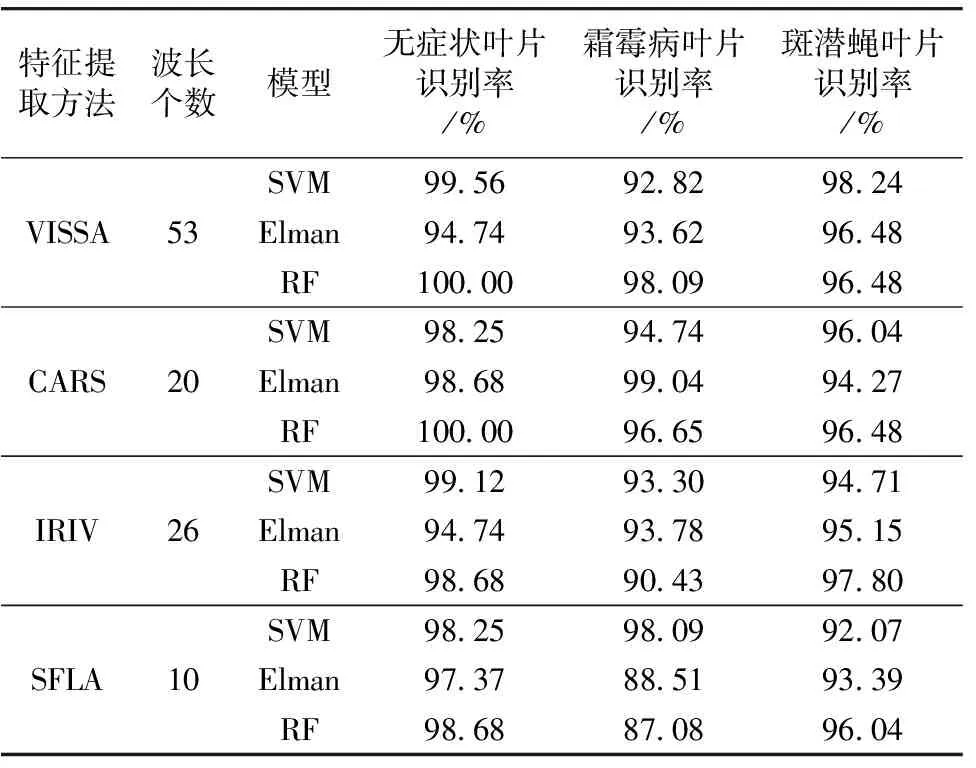
表3 一次降维光谱数据建模结果
由表3可知, 模型对无症状叶片的识别率均能达到94%以上, 对斑潜蝇虫害叶片的识别率均能达到92%以上。 MA-SFLA-Elman神经网络和MA-SFLA-RF模型对霜霉病叶片的识别率较低, 分别为88.51%和87.08%, 其他模型对霜霉病叶片的识别率均能达到90%以上。 所有模型中, MA-VISSA-RF和MA-CARS-RF模型对无症状叶片的识别率最高, 识别率均为100%; MA-CARS-Elman神经网络模型对霜霉病叶片的识别率最高, 识别率为99.04%; MA-VISSA-SVM模型对斑潜蝇虫害叶片识别率最高, 识别率为98.24%。
2.4 二次降维和建模
2.4.1 光谱数据二次降维
由于VISSA、 CARS、 IRIV、 SFLA提取出的特征波长仍然较多, 使用SPA对数据进行二次降维。 SPA是一种可以使矢量空间共线性最小化的前向变量选择算法[16], 该方法首先任意选择一个波长投影到其他波长上, 然后将其中最大投影向量对应的波长引入变量组合, 使用变量组合建立多元线性回归分析(MLR)模型, 最终选择MLR模型中交互验证均方根误差最小时的变量组合作为特征波长。 根据实际需要, 将SPA提取特征波长个数范围设定为1~5, 最终在VISSA所选波长中提取出4个特征波长, 如图7(a)所示, 分别为455、 536、 615和726 nm; CARS所选波长中提取出4个特征波长, 如图7(b)所示, 分别为452、 501、 548和578 nm; IRIV提取波长中提取出4个特征波长, 如图7(c)所示, 分别为452、 513、 543和553 nm; SFLA提取波长中提取出4个特征波长, 如图7(d)所示, 分别为462、 484、 500和550 nm。
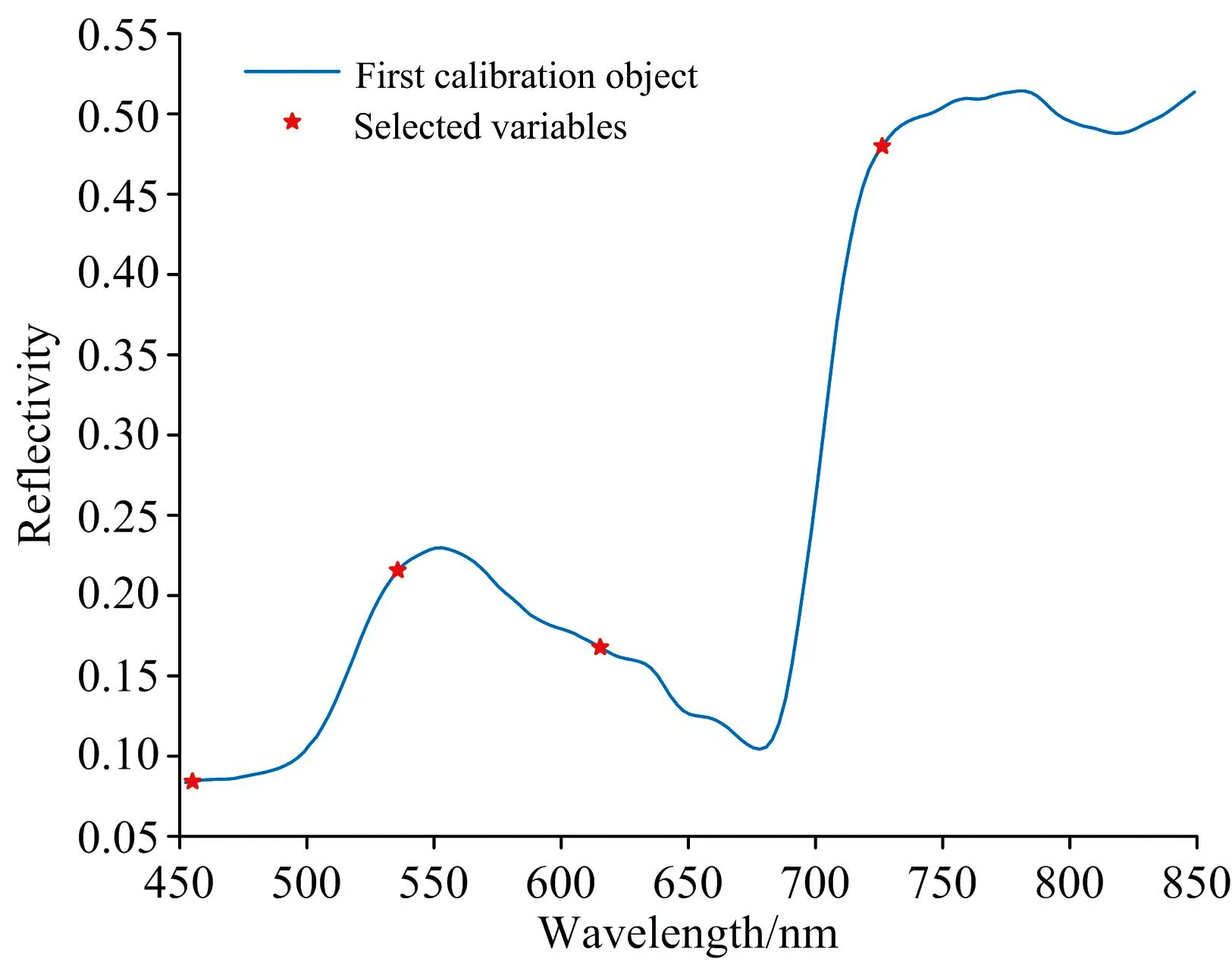
图7(a) VISSA-SPA提取特征波长

图7(b) CARS-SPA提取特征波长
2.4.2 模型建立
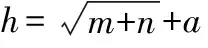

表4 二次降维光谱数据建模结果
2.5 模型效果评价
由特征波长数据所建模型的识别效果如表5所示。 由表5可知, 由一次降维光谱数据所建模型的OA均高于93%, Kappa系数均高于0.89, 其中MA-VISSA-RF模型的OA和Kappa系数最高, 分别为98.19%和0.97, 相较于MA预处理下全波段数据建立的RF模型, OA和Kappa系数均有所提升。 由二次降维光谱数据所建模型中, MA-IRIV-SPA-SVM的OA最高, OA为96.69%; MA-IRIV-SPA-SVM和MA-VISSA-SPA-SVM的Kappa系数最高, Kappa系数均为0.95。 由表4可知, MA-IRIV-SPA-SVM对黄瓜病虫害叶片的识别率相较于VISSA-SPA-SVM更高, 所以MA-IRIV-SPA-SVM模型的效果更好。 相较于MA-VISSA-RF模型, 建立MA-IRIV-SPA-SVM模型所用特征波长减少了49个, OA只降低了1.5%, Kappa系数只降低了0.02, 分类精度仍然较高。 本研究中的MA-IRIV-SPA-SVM模型和文献[7]的Dis-CARS-SPA-LSSVM模型相比, 所用特征波长减少了43个, OA降低了5.26%, 分析原因是为提取霜霉病和斑潜蝇虫害识别共同的特征波长, 损失了对霜霉病识别贡献度较大的波长, 但MA-IRIV-SPA-SVM模型所用特征波长大幅减少, 同时实现了对黄瓜斑潜蝇虫害叶片96.04%的识别率, 可以认为MA-IRIV-SPA-SVM模型具有较好的效果, 452、 513、 543和553 nm可以作为识别黄瓜霜霉病和斑潜蝇虫害的特征波长。

表5 特征波长光谱数据建模结果
使用VISSA-SPA和IRIV-SPA提取的特征波长建立的SVM模型实现了对黄瓜霜霉病和斑潜蝇虫害94%以上的识别率, 说明通过VISSA-SPA和IRIV-SPA方法提取特征波长具有良好的效果, 但总体来看, 模型对霜霉病叶片和斑潜蝇虫害叶片的识别率要明显低于无症状叶片, 为了提高模型的鲁棒性和准确性, 未来可以使用光谱特征结合病斑的形态特征等建立识别模型。 在实际生产中, 还可以结合黄瓜的发病时间、 发病叶片的位置等进行病虫害种类的判断, 提高对病虫害识别的准确率。 本研究中只选择了典型的黄瓜病虫害叶片进行光谱特征提取和建模, 将来可以选择更多的黄瓜病虫害种类建立黄瓜全病虫害类型的识别模型, 为设计专用的黄瓜病虫害一体化识别设备提供基础。
3 结 论
为了研究快速识别黄瓜病虫害的方法, 探究黄瓜病虫害识别的特征波长, 利用高光谱成像技术获取黄瓜无症状叶片、 霜霉病叶片、 斑潜蝇虫害叶片的高光谱图像, 使用ENVI5.1提取ROI的平均反射率数据。 采用MSC、 DOSC、 MA对光谱数据进行预处理, 使用VISSA、 CARS、 IRIV、 SFLA提取特征波长, 然后使用SPA对特征波长光谱数据进行二次降维, 分别对全波段光谱数据、 一次降维光谱数据、 二次降维光谱数据进行SVM、 Elman神经网络、 RF建模, 得到结论如下:
(1)MA预处理方法下全波段光谱数据建立的模型效果最优, 各模型总分类精度均可达到95%以上, Kappa系数均可达到0.91以上。
(2)VISSA、 CARS、 IRIV、 SFLA分别提取出53、 20、 26、 10个特征波长, 提取的特征波长光谱数据所建模型中, VISSA-RF模型的OA和Kappa系数最高, 分别为98.19%和0.97。
(3)VISSA-SPA、 CARS-SPA、 IRIV-SPA、 SFLA-SPA分别提取出4个特征波长, 提取的特征波长光谱数据所建模型中, IRIV-SPA-SVM模型的效果最好, OA和Kappa系数分别为96.69%和0.95。 452、 513、 543和553 nm可以作为黄瓜霜霉病和斑潜蝇虫害识别的特征波长, 为研发黄瓜病虫害快速识别设备提供了理论依据。
