基于不完备混合序信息系统的增量式属性约简
2024-02-02陈宝国陈金林
陈宝国,陈 磊*,邓 明,陈金林,2
(1.淮南师范学院 计算机学院,安徽淮南 232038;2.南京航空航天大学电子与信息工程学院,江苏南京 211106)
属性约简是粗糙集理论在模式识别下的最重要应用之一[1–2]。粗糙集理论通过对数据集的属性子集构建二元关系,实现了属性子集的不确定评估,从而可以删除数据集中的无效属性。针对不同的数据类型和数据环境,学者们基于粗糙集理论提出了大量的属性约简算法,使得属性约简成为粗糙集理论最为活跃的研究内容[1]。
当今大数据环境下,数据常常呈现出快速更新变化的特性[3],一些传统的属性约简算法暴露出了计算效率低的缺陷。为了解决此问题,增量式属性约简的方法近几年不断地被研究和探索[4–15]。针对离散型的信息系统,常用知识粒度[4]、区分矩阵[5–6]、依赖度[7]和遗传算法[8]等方法;针对连续型的信息系统,常用覆盖粒度[9]、邻域粗糙集[10]和模糊粗糙集[11]等方法;针对离散型和连续型混合类型的信息系统,常用混合邻域粗糙集[12]、邻域知识粒度[13]、邻域区分度[14]和邻域正区域[15]等方法。目前为止,增量式属性约简的研究已经涵盖了多种类型的数据。
然而,数据类型总是复杂多样的,某些情形下信息系统的属性值满足一定的偏序关系,这类信息系统被称为有序信息系统,其中,优势粗糙集是处理该系统的常用模型[16]。有序信息系统的研究近年来受到了越来越多的关注[17–19],Sang等[20–22]学者分别在离散型和连续型有序信息系统下基于优势粗糙集提出了多种增量式属性约简算法。然而,目前还未有不完备混合型有序信息系统增量式属性约简的提出和设计。以此为研究动机,本文进行了该类型信息系统的增量式属性约简研究和探索。
首先,提出一种邻域容差优势关系,实现不完备混合型有序信息系统的信息粒化和粗糙近似。其次,在所提出二元关系的框架下,建立了对应的信息熵、联合熵以及条件熵,利用条件熵的单调性设计了非增量式属性约简算法。然后,当不完备混合型有序信息系统的对象出现了动态增加和减少,建立邻域优势条件熵的增量式学习框架。最后,根据该框架提出了不完备混合型有序信息系统的增量式属性约简算法,实验分析结果证明了本文增量式算法的有效性。
1 邻域优势粗糙集基本理论

假设属性子集B={a1,a2},图1展示了对象xk在邻域优势关系下优势集和劣势集的示意图,G1~G5代表了不同的区域,不同形状的点隶属于不同的区域,五角星形状的点隶属于G1区域,十字形状的点隶属于G2区域,三角形的点隶属于G3区域,正方形的点隶属于G4区域,圆形的点隶属于G5区域。从图1中可以看出,对象xk的优势集=G2,对象xk的劣势集=G4。
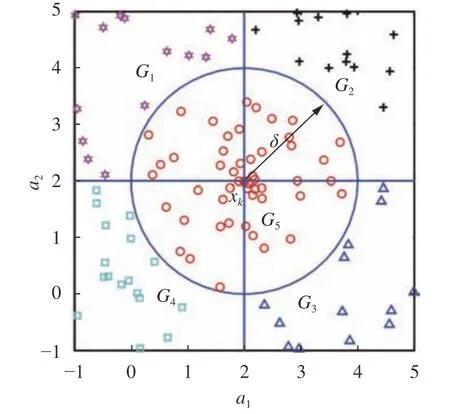
图1 对象优势集与劣势集的示意图Fig. 1 Schematic diagram of object dominating set and dominated set

2 不完备混合型有序信息系统与属性约简
由于实际环境下数据采集难易程度的不同及采集成本等方面的原因,信息系统存在着不完备的特性[7,15–16,23]。考虑到混合型有序信息系统的不完备性,本节将提出不完备混合型有序信息系统的概念,并提出对应的邻域优势粗糙集模型。
2.1 不完备邻域优势粗糙集模型

2.2 不完备邻域优势条件熵与属性约简
Zhao等[24]基于信息熵模型实现了不完备信息系统的不确定性度量与属性约简,本节针对此文所研究的信息系统类型,将该方法进行推广和扩展。

对于∀b∈(C-B)在B下的外部属性重要度定义为
根据定义10和定义11,利用邻域优势条件熵对不完备混合型有序信息系统进行属性约简的实现如算法1所示,由于算法1在进行属性约简时输入的是静态数据集,因此算法1也称为非增量式属性约简算法。
算法1基于邻域优势条件熵的不完备混合型有序信息系统属性约简算法。

3 不完备混合型有序信息系统增量式属性约简
信息系统不断进行更新,当信息系统对象发生增删时,原有约简结果不再有效,因此,需要重新计算新信息系统的属性约简。在已有各种基于信息熵的属性约简算法中,学者们均通过增量式更新信息熵的方法来更新属性约简结果[10,13,21–22],因此本文也采用类似的实现方案完成属性约简的动态更新。
3.1 邻域优势条件熵的矩阵表示
在粗糙集理论中,矩阵是构造模型和算法增量式学习的一种常用工具[3,5–6,18,21–22]。


3.2 基于矩阵的邻域优势条件熵增量式更新



3.3 增量式属性约简算法
第3.2节中实现了不完备混合有序信息系统对象增删情形时邻域优势条件熵的动态更新,本节在其基础上实现对应的增量式属性约简算法,分别如算法2和算法3所示。
算法2对象增加时基于邻域优势条件熵的不完备混合型有序信息系统增量式属性约简算法。


4 实验分析
表1为加州大学欧文分校UCI机器学习数据库中的8个常用分类学习数据集,其中,Chess为离散型属性值的数据集,W ine、Wdbc和Parkinson’s Disease为连续型属性值的数据集,AnuranCalls、DryBean、Magic和M usk为混合型属性值的数据集,本节将在这8个数据集上进行属性约简实验来验证本文增量式算法的性能。所有的算法通过软件Matlab2018b编程实现,计算机型号为CPU Intel(R)Core(TM)i7–7700 4.20 GHz,内存为16.0 GB DDR4,操作系统为W indows10。

表1 实验数据集Tab.1 Experimental data sets
4.1 实验设置与参数确定
在表1所示的数据集中,对于离散类型的属性值(也包括决策属性值),按照数据集样本的序号,将离散型属性值替换成依次递增的整数型数值,例如:对于属性值v1、v2和v3,将其替换为1、2和3;对于连续型属性值,为了消除属性量纲带来的影响,采用极差正规化的方法进行数据标准化。整个实验中,统一按照属性值的递增来定义优势关系中的偏序关系,即属性值大的对象优势于属性值小的对象。此外,本文研究的是不完备信息系统下的属性约简问题,表1中的数据集均为完备型,本实验对决策属性以外的属性值随机选择3%进行删除,从而构造数据集的不完备性。
在本文所提出的算法中,入参邻域半径 δ取值的不同会影响到最终的属性约简结果以及分类性能。因此,为了得到最优的邻域半径值,将邻域半径 δ在区间[0.01,0.20]内以0.01为间隔分别作为输入参数输入算法1,选择出对应的约简集结果,记录属性约简结果中属性的个数,同时利用两种分类器(支持向量机(SVM)和邻近点参数k设3的k邻近(kNN))分类训练获得约简集结果的分类精度。对所有邻域半径的结果进行归纳确定最优邻域半径 δ值。图2为表1中部分数据集的实验结果。由图2可知,当邻域半径增大,约简集长度呈现出减小趋势,分类精度呈现出先稳定后减小的趋势,邻域半径在[0.06,0.10]的范围内均具有较高的分类精度水平。属性约简旨在找到属性集较小且分类精度较高的属性子集,因此,经综合比较,选择邻域半径δ=0.10进行实验较为合适。
4.2 信息系统对象增加时增量式与非增量式算法性能比较
4.2.1属性约简结果有效性比较
对于表1中的各个数据集,从完整的论域选择50%对象作为初始信息系统,剩余50%的论域对象作为动态增加的对象集。然后,利用增量式与非增量式算法分别进行动态属性约简,记录两种算法的详细结果,并利用SVM和kNN(k为3)获得约简结果的分类精度。所有实验结果如表2所示,其中,“{*}”为属性集结果,“(*)”为属性的数量。
由表2可知,两种算法的约简结果非常接近。例如:数据集AnuranCalls有着相同的属性约简结果;对于数据集W ine、Chess、M usk和Parkinson’s Disease,增量式属性约简算法的约简结果更小一些,同时有着更高的分类精度;数据集Wdbc和DryBean有着属性数量相同但属性不完全一样的约简集,其分类精度也很接近;对于数据集M agic,虽然增量式算法约简得到的属性稍多一些,但是分类精度更高一些。表2的结果表明,两种算法都是可行且有效的;相比非增量式算法,增量式算法的属性约简结果更优异。

表2 对象增加时两类算法的属性约简和分类精度比较Tab.2 Comparison of attribute reduction and classificatioaccuracy between the two algorithms when objects are added
4.2.2属性约简算法的效率比较
从所有数据集中随机选择40%的对象作为初始数据集,然后,将剩余60%的对象集随机平均分成6份,随后依次将每份往初始数据集中添加,相当于每次增加10%的对象,这样便构造出数据集6次数据量相同的增加更新。将本文的增量式属性约简算法与非增量式算法分别基于这种数据更新方式进行属性约简,统计每次属性约简的计算时间,重复进行30次实验,其平均实验结果如图3所示。在图3中,随着更新次数的增加,两种算法的属性约简运行时间整体上呈逐步上升趋势,但增量式算法的运行时间明显更低,尤其对于大规模的数据集AnuranCalls、Dry-Bean和M agic,两类算法的效率差异更加明显。因此,对于信息系统数据量相同的增加更新,增量式的属性约简要更加高效。
同时,为了比较信息系统不同数据量增加时两类算法的更新效率,同样随机选择40%的对象作为初始数据集,剩余60%的对象集随机平均分成6份;然后,每次分别往初始数据集添加不同量的剩余对象,其中,第1次随机选择1份对象集添加至初始数据集,第2次随机选择2份对象集进行添加,依次类推,直至最后一次性添加6份对象集,这相当于初始数据集分别添加了10%、20%、···、60%的对象,因此,构造出了信息系统6次数据量不同的增加。基于这种更新方式,让两类算法分别进行属性约简更新计算,重复进行实验30次,其平均计算时间实验结果如图4所示。在图4中,同样可以发现增量式算法的计算时间更低,因此,对于不同数据量的增加更新,增量式的属性约简方法也更加高效。
图3和4中两类算法表现出的计算效率差异,主要是由于这两类算法的计算架构不同,算法1表明,非增量式算法每次对新的信息系统重新进行属性约简的搜索,其计算量与信息系统当前的规模正相关。在算法2中,增量式算法以旧信息系统的属性约简为基础,对变化的对象进行增量式计算,即算法所产生的计算量大部分来源于属性约简结果中变化的属性,不必对原先属性约简中的属性进行重复搜索计算,大幅提高了计算效率,因此,更新属性约简的时间会更少。部分数据集的增量式算法计算时间出现了一定波动,主要是由增量式算法的计算架构决定的,当旧的信息系统更新至新的信息系统,如果旧的约简集能直接继承作为新信息系统的约简,那么增量式算法可以直接返回无需搜索新的属性,此时,增量式算法所需的耗时很短;如果旧的约简集不能作为新信息系统的约简,那么需要选择新属性更新约简结果,此时增量式算法就会产生一定的运行时间,所以,出现用时波动的情况。
4.3 信息系统对象减少时增量式与非增量式算法性能比较
4.3.1属性约简结果有效性比较
首先将表1中的各个完整数据集作为初始数据集,然后随机选择论域的50%作为动态减少的对象,利用增量式算法与非增量式算法分别进行动态属性约简,并使用SVM和KNN(k为3)分别获得属性约简的分类精度,所有实验结果如表3所示,其中“{*}”为属性集结果,“(*)”为属性的数量。
在表3中,数据集DryBean下两类算法的约简结果完全一致,而在数据集W ine和Chess中,增量式算法的约简集稍大一点,数据集W dbc、AnuranCalls和Magic拥有相同的属性约简集大小,但增量式算法分类精度更高。因此,对于信息系统对象减少的情形,增量式架构的属性约简算法在约简的分类精度方面更加占据优势,这主要是由于增量式算法能够保留旧信息系统中的有效属性,提升新信息系统的分类性能。
4.3.2属性约简算法的效率比较

表3 对象减少时两类算法的属性约简和分类精度比较Tab.3 Comparison of attribute reduction and classification accuracy between the two algorithms when objects are removed
首先将表1中的每个完整的实验数据集作为初始数据集,然后对每个数据集随机选择60%的对象集,并平均分成6份,随后依次进行移除操作,相当于每次减少10%的对象,这样便构造出数据集6次相同数据量的减少。将本文的增量式属性约简算法与非增量式算法分别基于这种数据更新方式进行属性约简,统计每次属性约简的计算时间,重复进行30次实验,其平均时间实验结果如图5所示。在图5中,随着更新次数增加,两种算法的属性约简运行时间均逐渐减小,但是增量式算法的运行时间更短,尤其在数据集AnuranCalls、DryBean和Magic中,两种算法的差异更加明显。
同时,为了比较信息系统不同数据量减少时两种算法的更新效率,将完整的数据集作为初始数据集,随机选择60%的对象集平均分成6份,然后每次分别选择不同量的对象集进行移除,其中第一次移除1份对象集,第二次移除2份,依次类推,直至最后一次性移除6份对象集,这相当于在初始数据集中分别移除10%、20%、···、60%的对象,因此构造出了信息系统6次不同数据量的减少,基于这种更新方式,让两种算法分别进行属性约简,重复进行30次实验,其平均计算时间实验结果如图6所示。在图6中,同样可以发现增量式算法的计算时间更少,即增量式算法对动态数据有着更高的属性约简效率。
图5和图6表现出的效率差异同样是由于增量式属性约简算法的架构决定的。在算法3中,当信息对象减小时,增量式算法在旧的约简集上更新属性信息,避免对已选择的属性进行重复计算,极大地提高了动态数据环境下属性约简的效率,由于非增量式算法重复地选择属性,使得属性约简的耗时大幅高于增量式算法。
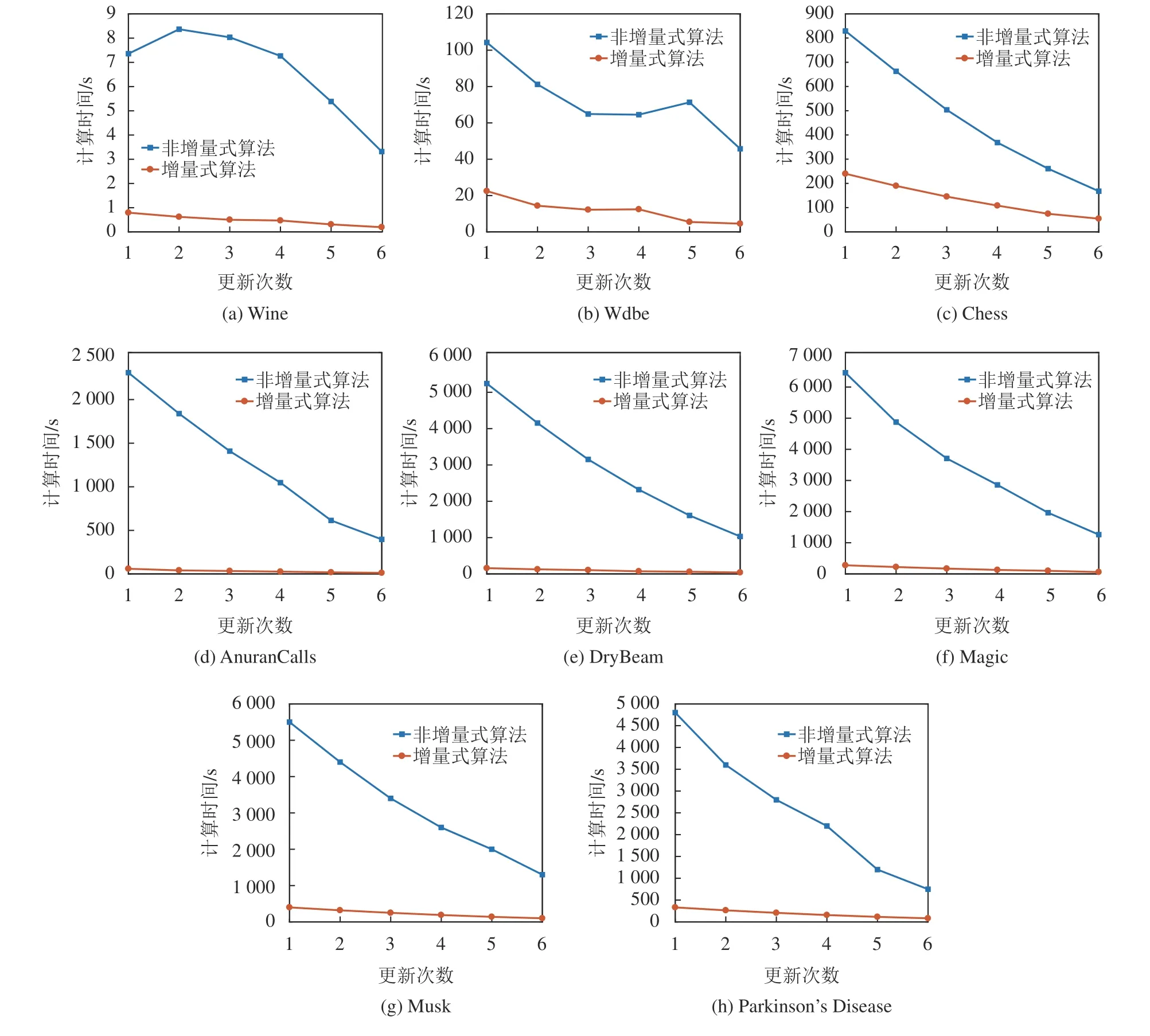
图5 减少相同数据量时更新属性约简的用时比较Fig. 5 Time comparison of updating attribute reduction when removing the same amount of data

图6 减少不同数据量时更新属性约简的用时比较Fig. 6 Time comparison of updating attribute reduction when removing the different amount of data
4.4 本文增量式算法与同类型增量式算法比较
本小节所选择的比较算法分别为:1)优势粗糙集模型的增量式属性约简[20];2)混合型有序信息系统邻域熵的增量式属性约简[22];3)量化邻域自信息熵的增量式属性约简[25],这3种算法分别简记为对比算法1、2、3。其中,对比算法1是一种建立在离散型有序信息系统下的增量式属性约简,在进行实验时需将表1的数据转换成标记型类型,同时这3种对比算法都只适用于完备型的有序信息系统,而本实验选择的数据集均为不完备类型,采用平均值的方法对这些数据集进行缺失值填充,即对属性下所有对象的属性值求取平均值并用平均值对该属性下的缺失值进行填充。随后,将所有增量式算法分别进行信息系统动态属性约简实验。
4.4.1信息系统对象增加时增量式属性约简比较
按照第4.2.2节对数据集构建6次增加相同数据量的更新方式,将所有增量式算法分别进行属性约简实验。统计每次更新时所有算法的计算用时,重复实验30次,其平均计算时间结果如图7所示。当数据集完成最后一次动态增加,所有算法的约简集长度比较结果见表4,约简集的分类精度比较结果见表5。
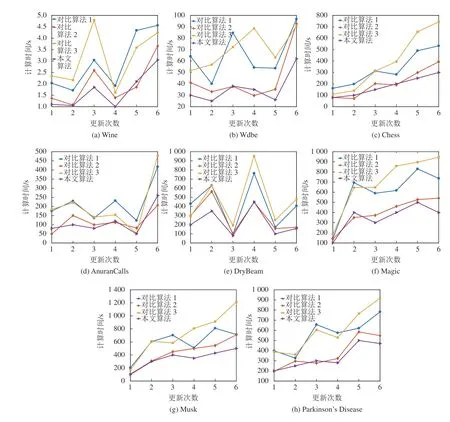
图7 对象增加时增量式属性约简算法的用时比较Fig. 7 Time comparison of the incremental attribute reduction algorithms when objects are added
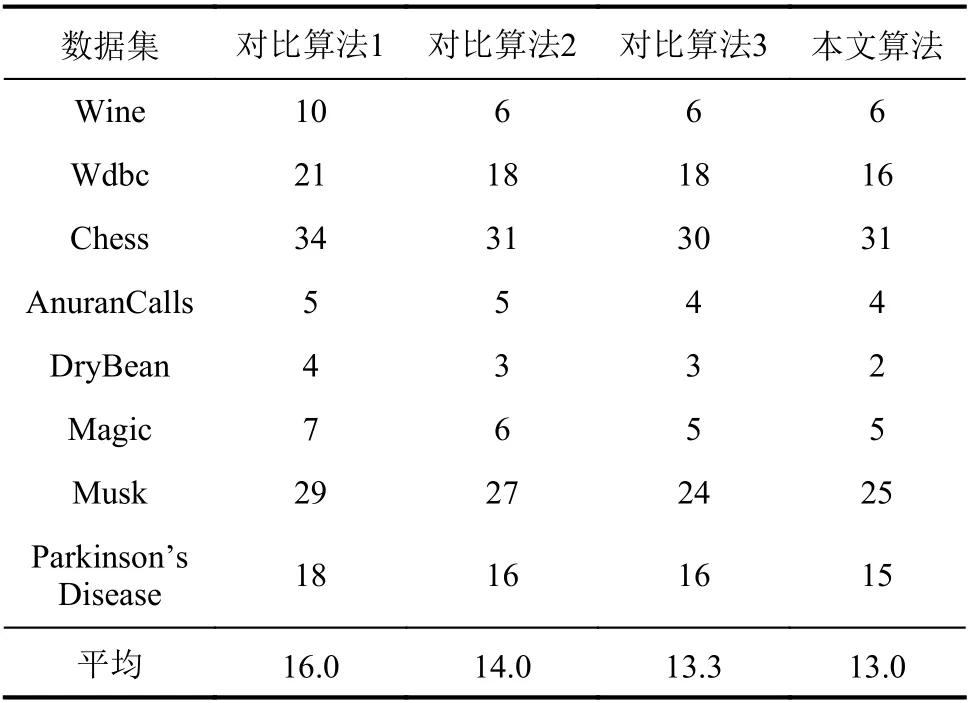
表4 对象增加时增量式算法的属性约简集长度比较Tab.4 Length comparison of attribute reduction set for incremental algorithms when objects are increased
在表4中,除数据集Chess和M usk外,本文增量式算法有着更小的属性约简集长度。在表5中,除数据集W dbc和DryBean外,本文增量式算法的SVM分类精度高于其余算法;除数据集Chess、DryBean和M agic外,本文增量式算法的kNN分类精度高于其余算法。在图7中,本文增量式算法的用时整体上低于其余算法。表4、5和图7的实验结果表明,本文增量式算法有着更高的属性约简性能。其原因为对比算法1进行实验时需将数据集进行离散化,这一处理丢失了连续型属性的数据结构信息,因此,对最终的属性约简结果造成了一定的偏差。对比算法2和3是两种适用于完备型信息系统的增量式属性约简方法,而本实验的数据集均为不完备类型,因此,对属性约简的效果产生了一定影响。在增量式约简效率方面,本文增量式算法通过矩阵策略直接更新每个对象的邻域优势类,并进一步更新邻域优势条件熵,跳过了对邻域优势上下近似集的增量式更新,因此,所需的计算量最少,效率整体最高。
4.4.2信息系统对象减少时增量式属性约简比较
按照第4.3.2节对数据集构建6次减少相同数据量的更新方式,将所有增量式算法分别进行属性约简,当数据集完成最后一次动态减少后,所有算法的约简集分类精度见表6,约简集长度比较结果见表7。统计数据集每次更新时增量式属性约简的计算用时,重复进行实验30次,其平均实验结果如图8所示。
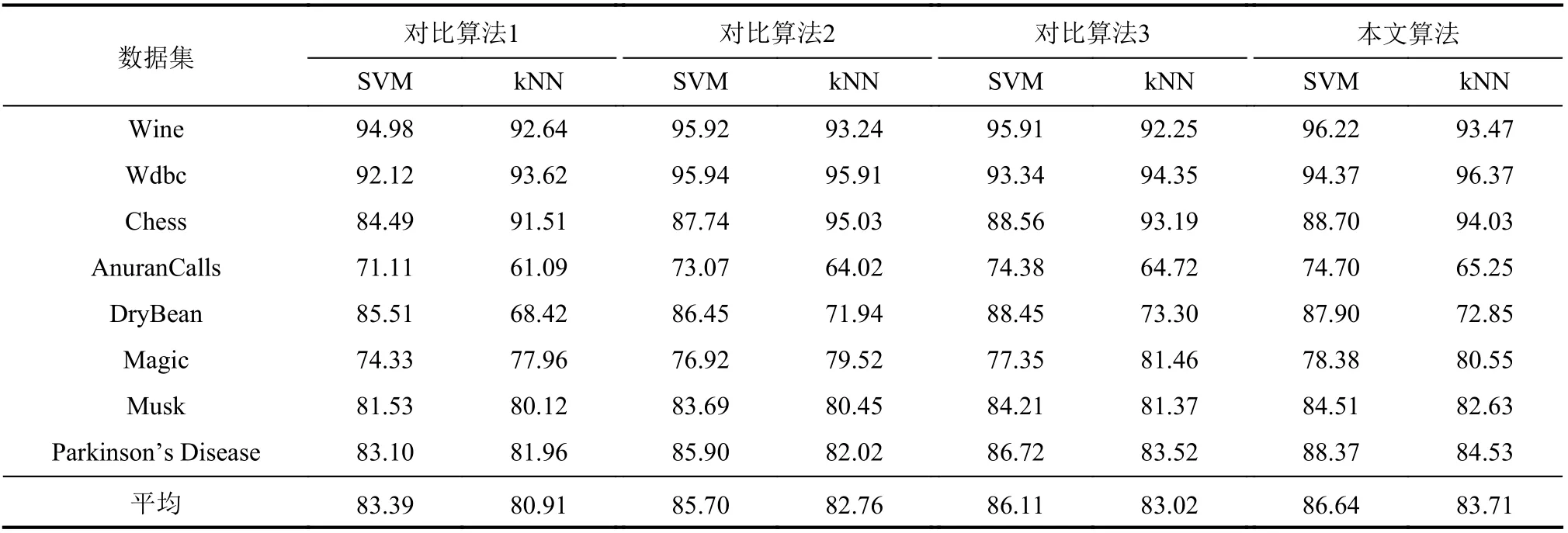
表5 对象增加时增量式算法的属性约简集分类精度比较Tab.5 Comparison of classification accuracy of the attribute reduction set of the incremental algorithms when objects are increased

表6 对象减少时增量式算法的属性约简集分类精度比较Tab.6 Comparison of classification accuracy of attribute reduction set of incremental algorithms when objects are reduced
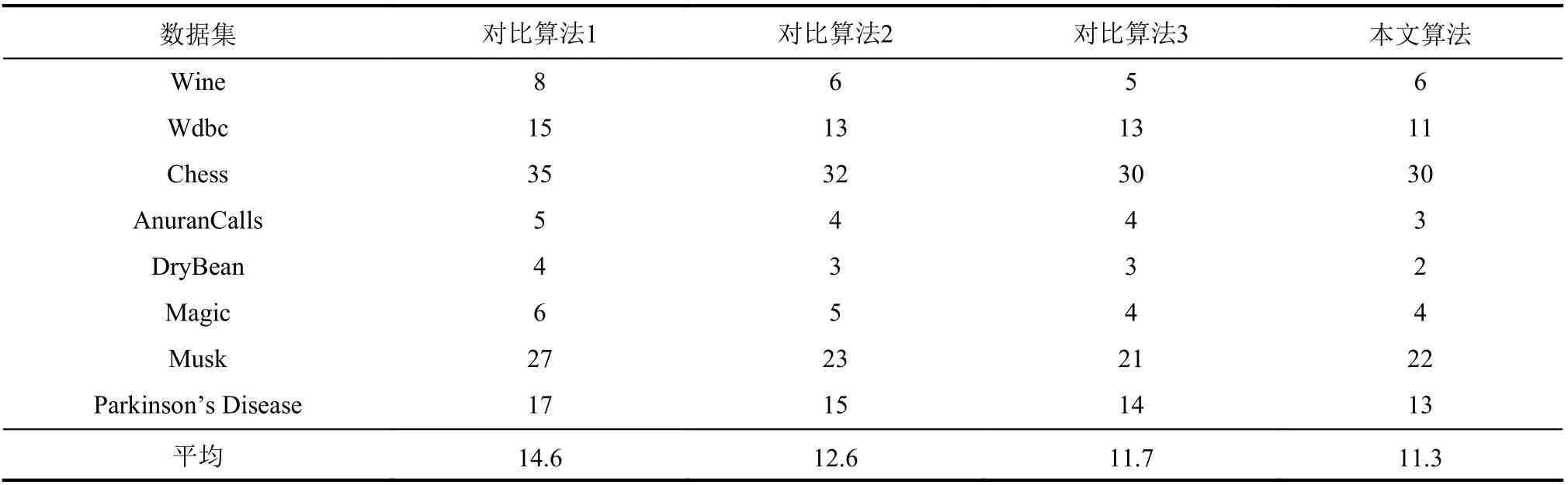
表7 对象减少时增量式算法的属性约简集长度比较Tab.7 Length comparison of attribute reduction set for incremental algorithms when objects are reduced
在表7的实验结果中,除数据集W ine和M usk外,本文增量式算法有着更小的属性约简集长度。在表6的实验结果中:除数据集W ine外,本文增量式算法的SVM分类精度高于其余算法;除数据集Chess和Musk外,本文增量式算法的kNN分类精度高于其余算法。图8的实验结果与图7类似,本文增量式算法整体上有着最少的增量式属性约简用时。表6、7和图8的实验结果表明,在不完备混合型有序信息系统对象减少的情形下,本文增量式算法同样有着更高的增量式属性约简性能,其原因也与第4.4.1节类似。

图8 对象减少时增量式属性约简算法的用时比较Fig. 8 Time comparison of the incremental attribute reduction algorithms when objects are reduced
5 结 论
增量式属性约简是当前属性约简研究的重点方向,针对有序信息系统的不完备性和混合性,通过邻域优势条件熵作为启发式函数提出一种增量式属性约简算法。提出不完备混合型有序信息系统下的邻域优势粗糙集模型,并设计出一种邻域优势条件熵的非增量式属性约简算法;分别研究了对象增加和减少情形下邻域优势条件熵的增量式学习框架;提出了不完备混合型有序信息系统的增量式属性约简算法。综合不完备混合型有序信息系统下对象变化的动态属性约简实验,证明了本文提出的增量式属性约简算法具有更高的属性约简性能。同时,通过与同类型增量式属性约简算法相比,证明了本文增量式属性约简算法具有更高的优越性。在未来的工作中,将尝试对不完备混合型有序信息系统属性的变化进行增量式属性约简的研究。
附录见本刊网络版(http://jsuese.ijournals.cn/jsuese_cn/ch/reader/view_abstract.aspx?file_no=202201214&flag=1),扫描标题旁的二维码可阅读网络全文。
