基于语义分割的织物疵点检测算法研究
2024-01-31赵浩铭张团善马浩然任经琦
赵浩铭,张团善,马浩然,任经琦
(西安工程大学机电工程学院,西安 710613)
织物疵点检测在纺织领域中有着关键作用,缺陷较多的织物会对工厂生产效率产生负面影响,所以织物缺陷的快速检测对提升织物质量、提高生产效率都有着重要意义。随着计算机检测技术的发展,机器视觉的应用使织物疵点检测的准确率显著提高。目前主要应用的织物疵点检测方法有基于结构、统计、频谱、网络模型和机器学习的方法[1]。基于结构的方法虽然比较简单,但是基于结构的方法过于局限,只能将疵点从织物纹理中分离出来;基于统计学的方法,灰度共生矩阵所需数据量大,计算量大,在分辨率较高的图像中,其检测效果不好;基于频谱的方法,傅里叶变换只适用于全局检测,在空间上的应用较差,实时性,通用性不佳。针对那些方法的缺点,所以出现了卷积神经网络,基于卷积神经网络的织物疵点检测算法被广泛用于疵点检测[2]。
国内已有学者用卷积神经网络进行织物疵点检测。顾德英等[3]在ResNet50的基础上融入了可变形卷积(Deformable convolutional networks,DCN)结构模型,模型对不规则疵点的检出率得到了提高,使用了BFP-FPN模块使网络中不同层次存在的特征不均衡问题得到了解决。赵树煊等[4]提出一种基于两阶段深度迁移学习的面料疵点检测算法,使用聚类算法及先验知识迁移的方法实现对面料通用特征提取能力的迁移,提高模型训练效率。高敏等[5]在YOLOv5算法的基础上,加入一种轻量注意力模块(Convolutional block attention module,CBAM)和通道注意力机制模块(Squeeze-and-Excitation,SE)增强了图像在通道域和空间域上信息表达能力及特征的提取,使模型聚焦于图像中的关键信息,提高了网络的检测精度。
基于对相关文献的阅读,发现数据集在深度学习中起到了尤为重要的作用,数据集的规模越大,类型越全,越能反映出实际状态下的缺陷分布。但是数据集中难免有些细小疵点的像素占比少,检出精度不高。通过对诸多网络模型的学习,多分类Focal Loss损失函数可提高小疵点类型的权重,增大其比重。Resnet中的残差连接可使网络深度加深,获得更深层次的图片特征,U-net中的Encoder-decoder结构适用于分割问题,下采样时的低分辨率信息和上采样的高分辨率信息填补底层信息以提高分割精度[6]。对疵点中常出现的条带状疵点,模型在每个下采样的过程中加入了多尺度卷积注意力机制(Multi-scale convolutional attention mechanism,MSCA),其条带状卷积可针对性地解决此问题。基于以上,文章提出的CS model可有效解决数据分类不均及小疵点检测精度问题。
1 研究方法
1.1 研究思路
本研究提出的织物疵点检测算法主要工作流程:首先对数据集的图像进行预处理,传入图片及标签;然后进入网络特征提取部分,为了使疵点特征提取更细节,将MSCA注意力机制放到每一个残差连接中,增大其感受野,使小疵点特征及条带状疵点特征更易识别;特征提取完毕后进行上采样,还原图片大小,融合特征,训练时使用Focal Loss损失函数为小疵点目标添加较大权重,使网络注意到更多的小疵点目标;最后进行对比试验,与U-Net、ResNet50、VGG16、DeepLabV3网络模型对比训练结果,得到Loss曲线,准确率曲线,反复调整Focal Loss参数匹配最优实验结果。
1.2 CS model模型结构
网络结构整体采用了类似U-Net网络架构,Encoder-decoder结构,网络的左半部分是卷积操作特征提取,右半部分是反卷积恢复图像特征。Encoder[7]是由卷积层ResLayer ResBlock和MSCA注意力机制组成,逐层提取图像特征,降低维度。Decoder[8]由反卷积和上采样组成,用于还原图像尺寸和分辨率,恢复图像位置特征信息。上采样过程中取6次尺寸不同的特征图,用以评估网络模型分割的效果优劣,将这6次特征图相加,使不同层次的特征进行融合,可得到最终输出图片。模型结构如图1所示。

图1 CS model结构Fig.1 CS model structure diagram
1.2.1 ResLayer、ResBlock模块
随着神经网络的发展,学者为了使网络结构加大,一种深度残差网络ResNet被提出[9],其允许网络可以尽可能地加深,其将一部分输入数据不经过网络训练直接和输出数据相加,保留一部分原始信息,这种结构有效防止了深层网络的退化问题以及梯度消失或爆炸问题,使得网络深度可以达到上百层,ResNet中的残差块对网络更深层次的拼接起到了关键作用,其结构如图2所示。

图2 ResNet残差块结构Fig.2 ResNet residual block structure
ResNet网络原理是在一个较浅的网络架构[10]基础上添加几个恒等的映射层(Identity mapping,即y=x),其他层从学习的浅层模型复制,既增加了网络的深度,又有效提高网络的表达能力。残差结构计算如式(1)、式(2)所示:
y1=h(xk)+F(xk,Wk)
(1)
xk+1=f(yk)
(2)
式中:x和y分别表示各层的输入和输出向量,F(xk,Wk)表示要学习的残差映射,h(x)=xk表示恒等映射,f表示Relu[11]激活函数。式(2)表示通过一个捷径连接和逐个元素相加,之后使用第2次线性修正,残差结构需要残差映射F(x)与恒等映射X的维度相同才能相加[12]。此网络的残差块结构如图3所示。

图3 ResLayer结构Fig.3 ResLayer structure diagram
ResBlock结构和ResLayer结构相似,将5×5的卷积换为3×3卷积即为ResBlock结构,选取5×5卷积核可以使网络提取不同的感受野以及不同的特征[13],有助于之后3×3的卷积核提取的特征相融合。
1.2.2 卷积模型架构
下采样的卷积架构分为卷积层,批归一化和激活函数三部分。卷积核大小为2×2,步长为2,每次卷积操作后,图片长宽缩小为上一层的1/2,以保留更多的细微疵点特征。为了输入网络中的数据分布尽可能地规范化,采用Batch Normalization[14](批归一化)使数据满足均值为0,方差为1的分布规律,避免梯度消失,减少训练时间。
上采样卷积架构同下采样卷积架构,分为反卷积层,批归一化和激活函数三部分。织物疵点图像有较多细节特征,下采样缩小图片的同时导致图像丢失较多细节,经过上采样,反卷积过程使图像恢复原始尺寸大小,还原图像细节,避免图像失真[15]。
1.3 MSCA注意力机制
MSCA为多尺度卷积注意力机制[16],其结构如图4所示。

图4 多尺度卷积注意力(MSCA)结构Fig.4 Multiscale convolution attention (MSCA) structure diagram
MSCA采用了大卷积核分解,多分支并行架构[17],使得MSCA注意力机制对不同尺度的目标具有很强的适应性,可聚合多尺度通道信息[18]。
MSCA主要包含3个部分:用于聚合局部信息的深度卷积、用于捕获多尺度上下文的多分支深度条带卷积、用于建模不同通道之间关系的1×1卷积。首先用5×5的卷积核对输入的每一个通道进行卷积,然后将每一个通道的信息进行融合,深度卷积减少了网络的参数量,并且先考虑了空间,再考虑了通道,实现了通道和空间的分离,此操作只是对特征图进行了尺寸调整,通道数没有发生变化,于是将前面的特征图进行二次卷积,这时采取的卷积核都是1×1大小的,滤波器包含了和上一层通道数一样数量的卷积核。深度卷积可提取各通道更充分的特征以及更轻量化的计算。
深度条带卷积[19]是轻量级的为了模拟n×n的标准2D卷积,只需要一对1×n和n×1的卷积。疵点中有一些线条状疵点,如断经,断纬等,因此,条带状卷积可以是网格状卷积的补充,有助于提取条带状特征。卷积核在深层次时采用1×3、3×1以及1×5、5×1的组合,在尺寸较小的图中,小尺寸卷积核可更准确细致地采集到图片特征,使得疵点深度特征更清晰。
1×1卷积的输出直接用作注意力权重来重新加权MSCA的输入,更加关注数据集中微小疵点的分割。
2 多类别Focal Loss损失函数
织物疵点数据集中,缺陷样本分类不均衡,且疵点有数量和大小的差距,存在有缺陷样本和无缺陷样本的不均衡性。疵点相对于整幅图像为小样本,像素占比小,上述存在的不均衡性导致像素占比较小的前景(即疵点)容易被背景稀释,导致检出准确率不高。Focal Loss是一种处理样本分类不均衡的损失函数[20],根据样本是否容易区分给样本添加权重,即给易区分的样本添加小权重α1,给难分辨样本添加大权重α2。其数学表达式如式(3)所示:
FL(pt)=-(1-pt)γlog(pt)
(3)
式中:FL为图像中每个像素点的Focal Loss损失函数值;-log(pt)为初始交叉熵函数值;pt表示模型对像素点的分类概率,γ是聚焦系数,取值范围一般为正数。当γ为0时,Focal Loss就是传统的交叉熵损失函数[21]。γ取值越大,它对多数类和少数类之间相平衡的效果就越好,但γ不可选择得过大,过大会降低整个模型的准确率。
本文所用的多类别Focal Loss损失函数的数学表达式如式(4)、式(5):
FL(pt)=-αt(1-pt)γlog(pt)
(4)
(5)
通过αt可抑制正负样本的数量失衡,freq(t)表示第t类疵点在数据集中的出现频率,αt表示损失函数中第t类的初始权重大小,初始权重的大小由加权系数β控制,β越大,低频率出现的类别初始权重越大[22]。γ可控制难/易区分样本的数量失衡。调质因子(1-pt)γ用来减低易分类样本的损失贡献,无论前景还是背景,pt越大,说明该样本越容易被区分,调质因子越小。αt用于调节正负样本损失之间的比例,前景使用αt对应背景使用1-αt[23]。
3 试验与分析
3.1 数据集的构建
实验数据集由课题组根据不同疵点类型的布匹自主构建,约1400张图片包含断经、断纬、结头、跳纱、污渍、破洞6种疵点类型。由于大部分疵点较小,图片中包含背景较多,即各疵点类别像素点占数据集中像素点总数较少,比率较低,通过像素点占比来衡量数据集中的类别不平衡问题,数据集中各疵点类别的出现频率如图5所示。

图5 数据集中各类别像素所占比例Fig.5 Proportion of pixels in each category in the dataset
此数据集存在着严重的类别不平衡问题,背景占比过大,最小的破洞像素占比为0.009为断经像素占比0.14的1/15。将数据集按8/1/1分为训练集、验证集和测试集,进行训练和测试。
3.2 实验设计
首先将划分好的数据集分别用当前主流的U-Net 模型、ResNet50模型、VGG16模型、DeeplabV3模型进行训练,训练完成后在测试集上对Acc(准确率)和mIoU(交并比)指标进行测试对比;然后将CS model应用了Focal Loss损失函数进行数据集的训练和测试,再将应用了MSCA注意力机制的CS model进行训练比较,分别测试分析模型的准确率以及泛化性。
3.3 评价指标
Acc作为模型在训练阶段评价其分割能力是否优异的指标,准确率大小基于rIoU的大小变化。其数学表达式如式(6)。
(6)
式中:k表示疵点类别,k+1表示疵点和背景总类别,i表示真实值,j表示预测值,pij表示将i预测为j,pji表示将j预测为i,pii表示将i预测为i。rIoU为每个类别的真实值和预测值的平均交并比[24]。
将数据集取出一部分进行预测,结果可分为以下4种。若一张图片语义标签没有疵点,模型预测其为无疵点,称为真正类(True positive,TP),若一张图片语义标签没有疵点,模型预测其为有疵点,称为假负类(False negative,FN);若一张图片语义标签有疵点,模型预测其为无疵点,成为假正类(False Positive,FP),反之,若模型预测其为无疵点,称为真负类(True Negative,TN)[25]。准确率A的计算如式(7)所示:
(7)
此外,训练过程中的Loss(损失值)也是评价模型是否合理,性能是否优越的一个重要指标,Loss越小,说明其预测值和样本真实值之间的差异程度越小,模型性能越好。
3.4 模型训练
实验室所用的环境配置为Windows 10、处理器为Inter(R)Core(TM)i9-9900K、64 GB内存、显卡为NVIDIAGeForceRTX 2080Ti。程序中设置实验过程每个Batch输出Loss和平均准确率,最高准确率。当最高准确率改变便保存一次权重,训练400次通过Loss值及准确率调整学习率大小,提高网络的稳定性,以免出现过拟合现象,调整Batch-size(批次)大小,防止网络陷入局部最优解或网络难以收敛,增强网络的鲁棒性。为了得到足够准确和泛化能力更好的模型,需要在训练过程中记录训练集损失和验证集损失,以及训练集准确率和验证集准确率。网络训练过程的准确率曲线如图6所示,损失函数曲线如图7所示。 训练准确率和验证准确率都平稳接近于91%;训练损失曲线稳定趋近于0.02,验证损失曲线稳定趋近于0.038,因此模型的泛化性和鲁棒性满足于实验需求。

图6 CS model准确率曲线Fig.6 CS model accuracy curve
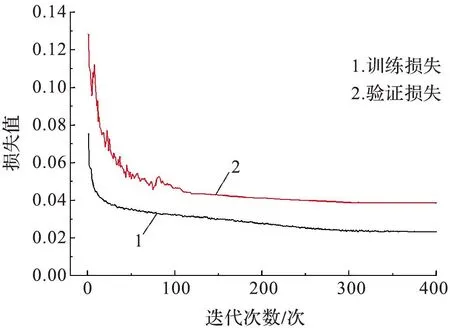
图7 CS model损失值曲线Fig.7 CS model loss value curve
3.5 实验分析
针对所构建的网络模型进行参数调整,对不同聚焦系数和加权系数组合下的多类别Focal Loss损失函数进行训练,实验中分别选取如下值进行训练:
聚焦系数γ取2和5,比较像素占比大或小的样本权重不同对训练效果的影响。
加权系数β取0和1,比较各种初始化权值对训练效果的影响。
训练结果如表1所示。
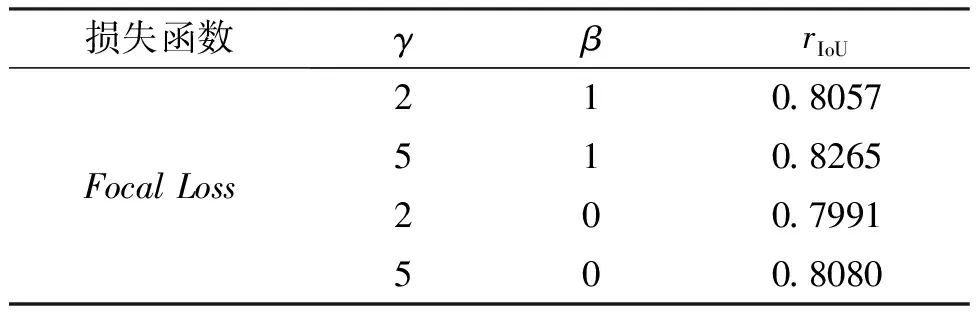
表1 不同超参数下网络mIoU值Tab.1 mIoU value of network under different hyperparameters
由表1可看出在所有超参数组合中,组合γ=5,β=1的训练效果最好,说明给易区分样本权重取小值,难分类样本权重取较大值可使模型分割效果变优, 使网络得到优化。
聚焦系数γ、加权系数β的不同取值对训练结果的影响如下。
a)聚焦系数γ对训练结果的影响。
从模型训练结果rIoU来看,γ取值较大时网络模型在难区分样本中的表现优越,类别趋于平衡,根据rIoU指标可知在织物疵点检测语义分割任务中,取γ=2最合适。
b)加权系数β对训练结果的影响。
比较两种β取值的训练结果,可以看出在聚焦系数γ不变的情形下,取β=1时,模型的各种训练性能指标都比β=0时的训练指标好。说明对于小类别给予较大的初始权重效果较好,在损失函数中根据类型出现频率赋予不同的初始权值可以提高模型的分割能力并且减少类别不均衡现象。
利用训练好的模型及其他主流分割模型在分割好的数据集上分别进行实验验证,实验结果如表2所示。

表2 其他主流分割模型与本研究模型在数据集上对比结果Tab.2 Comparative results of other mainstream segmentation models and this research model on data sets
由表2可知,CSmodel算法性能优异,较U-Net测试精度提高了2.98%,rIoU较DeepLabV3提高了6.04%,性能得到了大幅提高。
表3所示为不同网络模型对6种类型疵点的分割结果。对比U-Net、ResNet50、VGG16和DeepLabV3网络的分割结果,可发现CS model网络模型分割结果的准确度和分割边缘的平滑程度要优于其他4个网络,可看出使用Focal Loss损失函数和MSCA注意力机制得到的分割效果优于其余网络。小类别疵点类型不平衡现象得到了优化。

表3 6种疵点类型在不同网络的对比效果Tab.3 Comparative effect of six defect types in different networks
4 结 论
针对织物缺陷检测中的数据集每类样本分布不均及分割精度问题,文章设计了CS model网络模型,依照主流的ResNet网络设计成模块,组成网络的基本模块,将网络设计成U-net架构,提取疵点特征。应用了多类别Focal Loss损失函数,该损失函数可在训练过程中根据出现频率分配相应的权值,出现频率小的赋予大权值。通过Acc和mIoU指标衡量模型对小类别疵点分割的准确率,分析了多类别Focal Loss对模型数据集分类不均衡问题的影响,通过调节Focal Loss超参数对比分析对模型准确率的影响。实验结果表明,CS model网络应用多类别Focal Loss损失函数可将疵点分割准确率达到91%,对织物疵点检测领域有实际的意义。
