基于BERT与生成对抗的民航陆空通话意图挖掘
2024-01-30孟诗君吴志军
马 兰, 孟诗君, 吴志军
(1. 中国民航大学空中交通管理学院, 天津 300300; 2. 中国民航大学电子信息与自动化学院,天津 300300; 3. 中国民航大学安全科学与工程学院, 天津 300300)
0 引 言
不断增长的空域流量在安全、效率、容量和环境性能等方面对空中交通管制(air traffic control, ATC)提出了挑战,而数字化和自动化正是应对这些挑战的有效途径。ATC通信目前依赖于两种方法,陆空通话和数据链路通信。陆空通话属于半人工语言,管制员与飞行员通过甚高频语音通信系统进行沟通交流,而数据链路通信旨在通过数据交互界面传输管制指令。数据链还无法完成全部管制信息的传送(其不包含地面和塔台的管制术语),两种通信方法将在过渡阶段并行存在相当长的一段时间。国际民航组织表示:“为了在飞行的关键阶段尽量减少飞行员头朝下的时间和潜在的分心,管制员应使用语音与地面以上10 000英尺以下的飞机进行通信”[1]。因此,陆空通话仍然是进近阶段信息交换的主要方式。
然而到目前为止,陆空通话这种模拟通信还被排除在数字化进程之外,但是通话内容对自动化系统至关重要。如果能及时将陆空通话中隐含的管制员指令输入到当前的空中交通管制系统,并准确地推断出指令的意图,就能检测并进一步避免所列出的所有安全风险。因此,对陆空通话的内容进行深度分析与意图挖掘,自动提取意图信息,并形成ATC系统可理解的结构化信息是当前人工智能时代亟需解决的问题,也是“自动收集和处理空中交通通信的语音数据”(automatic collection and processing of voice data from air-traffic communications, ATCO2)项目当前旨在开发和改进的任务。这样不仅可提高管制员的态势感知能力,使其能够提前发现和处理紧急情况,提高ATC的安全性,还可用于管制决策和事后分析过程,并减轻管制员的工作量[2]。有研究表明,使用自然语言处理技术处理陆空通话自动语音识别的输出效果更好,直接对文本数据进行分类优于声级分类[3]。因此,本文的目标为对语音转录而来的陆空通话文本进行意图挖掘、知识提取,包括呼号、管制单位、指令、值的识别与提取。
陆空通话有别于自然语言,通话双方格式固定,存在领域特性,与通用文本的信息提取相比,更具有挑战性,主要表现为以下3个方面:① 大规模的陆空通话文本是模型训练的基础,但陆空通话数据通常被认为是“稀缺”的,且大多数均为非公开,难以获取,当出现频率干扰或飞行员与管制员通话复杂度高且存在口音差异、精神疲劳时,语音转录文字效果不好,价格昂贵,需要大量的人工修正[4]。文本数据的缺乏以及多样性不足等问题会导致模型的过拟合以及泛化能力弱。② 陆空通话伴有英文或数字的联合表达与缩写,语义关系联系紧密且存在一词多义现象,如航向值“010”和跑道号“010”,地点“北京”和管制单位“北京进近”。③ 一条陆空通话的语句中可能隐含着不止一种意图,如“左转”和“上升”,可能包含着许多状态信息,这些意图都需要与对应航班准确匹配且正确提取,在精确度和召回率方面都需要具备较高性能。
针对上述问题,本文提出一种融合本体的基于生成对抗网络(generative adversarial network, GAN)-双向转换编码器(bidirectional encoder representations from transformers, BERT)-双向长短时记忆(bidirectional long short-term memory, BiLSTM)-条件随机场(conditional random field, CRF)的联合意图挖掘模型,用于从陆空通话中识别意图信息、提取意图信息、结合航班池信息进行合理性校验。提取信息的问题又被定义为一个自动实体命名识别和分类任务。本文的主要内容有以下4个方面:① 提出基于改进GAN的陆空通话智能文本生成方法,进行数据增强,解决实体数量少且分布不均等问题,扩充语料库;② 实体的分类和标注结合欧洲单一天空空中交通管理项目(single European sky air traffic management research, SESAR)定义的PJ.16-04的本体规则[5],类型分为航空器呼号、管制单位、垂直意图、水平意图、速度意图、报告意图、天气意图、管制移交、修正海压、航路点、进离场程序、单位等20类;③ 提出基于BERT-BiLSTM-CRF的联合模型对陆空通话进行意图挖掘,提取呼号、指令等意图信息;④ 从飞行计划或广播式自动相关监视数据(automatic dependent surveillance-broadcast, ADS-B)中引入航班池信息,通过编辑距离(edit distance, ED)算法(也称Levenshtein距离算法)进行意图信息合理校验并修正,提高意图识别准确率。
全文其他内容的组织结构如下:第1节对针对智能文本生成和陆空通话意图信息提取的国内外研究现状进行了展开介绍。第2节对本文所提的基于GAN的陆空通话生成模型、融合本体的意图分类标注、BERT-BiLSTM-CRF联合模型以及合理性校验模块进行了详细阐述。第3节在介绍实验数据集以及环境设置的基础上,与主流模型进行了对比并进行结果分析。第4节总结了本文结论并提出了前景展望。
1 相关工作
本文针对民航陆空通话内容进行文本处理,涉及文本生成以及信息提取两大部分内容,第1.1节和第1.2节分别介绍了当前智能文本生成以及陆空通话意图挖掘的国内外研究现状。
1.1 智能文本生成
针对智能文本生成问题,如机器翻译、文本摘要等,学者们对深度生成模型开展了广泛的研究[6]。主流方向是对目标文本进行特征提取与风格模仿,生成任务所需的文本内容。现阶段的深度学习算法如卷积神经网络(convolutional neural network, CNN)、循环神经网络(recurrent neural network, RNN)、编码器-解码器框架、长短时记忆(long short-term memory, LSTM)网络[7]等在文本生成问题的研究中存在着一些问题,如偏差暴露、错误累计[8]、流畅度不够,且在训练时参数的更新都直接来自目标文本,参数训练繁琐,很难确定一个合适的标准来评价生成的内容。
Koo[9]提出了GAN,其基于二人零和博弈思想,具有强大的数据学习和数据生成能力,可以解决前面提到的疑难问题。Zhang等[10]则提出了文本GAN(text GAN),生成器使用LSTM,判别器使用CNN,利用了协方差矩阵的差异化度量,缓解了原始GAN训练中的模式崩溃问题。Yu等[11]提出了序列GAN(sequence GAN, SeqGAN),生成器使用LSTM,判别器使用CNN,将GAN与强化学习相结合,文本生成质量有所提高,但针对长文本的生成效果不好。Che等[12]提出了最大似然增强离散GAN(maximum-likelihood augmented discrete GAN, MaliGAN),对生成数据分布和真实数据分布的差距进行直接计算,提高了生成文本的多样性,但是拟合能力较弱。Li等[13]将GAN应用于文本对话生成中,生成器采用序列到序列模型(sequence-to-sequence, Seq2Seq),判别器则采用层次解码模型,能直接对部分生成或完全生成的序列计算奖励值,但是也会使得判别器更不准确。Guo等[14]提出了一个存在泄露信息的GAN(GAN with leaked information, LeakGAN),通过判别器泄露的信息更好地指导生成器的生成,但生成的文本多样性有待提高。Kim等[15]将GAN用于摘要生成,提出了一种基于特征与两级推理架构的GAN模型,用于多专利摘要的生成与总结。
在实际应用中,GAN已经用于诗歌生成、法律文本生成等多个场景,在文本领域的发展值得不断思考[16]。但在民航陆空通话文本生成方面,只有邱意等[17]提出了一种使用one-hot词向量训练GAN模型的陆空通话文本生成方法,其生成器为LSTM模型,判别器为CNN模型,该方法生成的部分文本不符合陆空通话语法规则且不够通顺。
1.2 陆空通话信息提取
信息提取是利用机器自动化地从文本中识别和抽取特定的实体、关系或事件信息[18]。文本实体识别技术是文本处理中的关键任务,为信息检索、知识图谱构建奠定了基础[19]。现有的方法可以分为3大类:依赖于词典规则的方法、传统机器学习方法和当前主流的深度学习方法。
基于规则的方法依赖于人工制定的、基于模式匹配的规则从非结构化文本数据中识别和提取目标信息。邓学鸣[20]利用正则表达式的方法对陆空通话中的管制信息进行匹配与抽取,并将其实时反馈,能有效避免危险情况的发生。在此基础上,杨昱昕[21]利用前缀因子过滤法对正则表达式进行了改进,优化了有限自动机并加入了过滤算法,管制信息及参数的提取更为准确。王煊等[22]提出了一种基于语言学的陆空通话语法分析技术和基于语法学的结构化模板生成技术,通过构建语义网,确定出谓词、论元和关系组成的三元组结构,再利用贝叶斯网络模型填补空范畴,形成结构化模板。传统的基于规则的方法虽然操作较为简单,且有助于对管制指令进行解析,但其太过依赖于规则,无法列举出所有的模板与之配对,可移植性差。
基于机器学习的信息提取方法包括支持向量机和最大熵马尔可夫模型等[23]。经典的机器学习算法特征工程较为复杂,而深度网络模型不需要特征工程,且鲁棒性强,精确度也有大幅提升。近些年来,深度学习算法渐渐成为信息提取的主流算法,并向各垂直领域延伸[24]。在事件安全分析方面,Liu等[25]提出一种基于数据增强和BiLSTM-CRF的实体识别方法,可对铁路事故报告进行文本挖掘与风险预测,并可拓展至其他事故语料中。在医学领域,Luo等[26]将改进的BERT模型用于文本生成与特征挖掘,可解释性更强且可以实现并行计算。在陆空通话领域,Lin等[27]将BiLSTM与多层感知机结合来提取管制意图和管制参数。Lin等[28]还将BiLSTM与全连接层(fully connected layer, FC)结合,更好地挖掘陆空通话文本意图。FC分为管制意图推理和槽填充两部分,管制意图推理被处理为一个序列分类任务,而槽填充提供关于已识别指令的详细信息。张兴明[29]在陆空通话信息提取中使用了BiLSTM-CRF网络,并在其中引入了注意力(attention, ATT)机制,形成BiLSTM-ATT-CRF,取得了不错的识别提取效果。Kocour等[30]提出了一种基于BERT的自然语言理解模型,可以从陆空通话文本中提取知识,进行呼号识别、飞行员分类与实体识别。
上述方法存在着语料库较少、实体分布不均等问题,且多意图挖掘准确率有待提升,未达到理想水平。本文提出的融合本体标注的GAN+BERT-BiLSTM-CRF联合意图信息挖掘模型首先对陆空通话原始数据集进行数据增强,之后基于本体分类标注,将数据送入BERT-BiLSTM-CRF模型进行意图挖掘、信息提取并校验修正,可有效解决多义词问题,且充分捕获文本关联信息的多重特征。
2 民航陆空通话意图挖掘方法
民航陆空通话意图挖掘模型的整体方案如图1所示。

图1 民航陆空通话意图信息挖掘方法的整体框架Fig.1 Overall framework of civil aviation radiotelephony communication intent information mining method
图1的上侧为基于GAN的智能文本生成模型,其重点在于文本生成器和文本判别器的不断学习和对抗训练,将整个过程视为强化学习的序列决策过程,目的是使生成器生成与真实数据集无法区分的文本,使得判别器的奖励最大化,可以实现数据的有效增强、平衡各类意图信息分布和扩充数据集。
图1的下侧为陆空通话的意图挖掘模型,主要包括结合本体的意图分类与标注、意图信息的识别与提取、航班池信息的合理性校验与修正几个部分,最终可形成ATC系统可理解的结构化信息。
2.1 基于GAN的陆空通话智能文本生成技术
民航陆空通话文本字向量的转换利用Word2vec的连续词袋(continuous bag of words,CBOW)模式来实现。本文使用基于LSTM的编码器-解码器框架[13]来训练一个参数为λ的文本生成器,如图2所示。生成器的输入为真实的陆空通话文本,定义了在给定陆空通话文本下生成响应的策略,目的是更好地捕获全局语义信息,尽可能地拟合真实样本的分布,输出假样本来欺骗判别器。

图2 基于改进GAN的陆空通话文本生成模型架构Fig.2 Text generation model architecture for radiotelephony communication based on improved GAN
GAN的优势在于生成器的更新直接来自于判别器的反向指导,本文使用CNN并引入交叉熵函数来训练一个参数为μ的判别器,其输入为真实陆空通话文本和生成器生成的文本,输出的值为0~1之间的数。
由于GAN在处理离散数据时会遇到反向传播梯度难以下降和判别器不能评估残缺的序列的困难,在对抗训练中引入强化学习概念,把文本生成器看作代理,将当前已经生成的序列Y看作状态s,将下一个要生成的词看作动作a,将判别器给出的分数看作奖励,其目标函数如下所示:
(1)
式中:G为生成器,D为判别器,Q为动作-价值函数,公式的含义为希望参数为λ的生成器在s处做出最佳选择,获取最大奖励回报,而如何选择动作又取决于动作的价值Q。
Q是由D来判定的,D只能对完整的序列打分,在序列不完整时,本文在t-m时刻使用蒙特卡罗搜索算法补全,其采样策略与Gλ一致,P次采样的蒙特卡罗搜索被表示如下:
(2)
其动作价值函数如下所示:
(3)
生成器生成的文本更接近真实陆空通话文本,判别器迭代更新其参数,使得真实标签和预测概率之间的交叉熵最小[11],如下所示:
(4)
生成器的参数是通过策略梯度进行更新的,如下所示:
(5)

2.2 基于SESAR本体的意图分类与标注
本体一词源自希腊,意思是事物的本质,在计算机学科里被广泛用于知识表示、信息系统、人工智能等领域。本体定义了抽象概念及其之间的关系,主要用于在计算机程序之间以数字形式交换知识,知识可以包括一般知识和专业知识,术语本体论建立在计算机科学中,在语义网和自然语言理解领域确立了自己的地位。
2020年,SESAR出资成立的PJ.16-04解决方案开发了一个陆空通话指令转录本体[5]。本体的主要组成有两部分:呼号和指令。指令部分的元素如图3所示。

图3 陆空通话指令转录本体的元素组成Fig.3 Elemental composition of transcription ontology of radiotelephony communication instructions
从图3可以看出,陆空通话的一条指令是由一条必须的命令(深绿色部分)和一个或多个可选的条件(黄色部分)组成的,其中命令由类型、参数、单位和可选的限定词组成,并非所有的命令都需要参数和单位,但类型是必须的;可选条件由连词和需要达到的某些要求组成,不是必须的。一条陆空通话针对同一个呼号,可以包含多个指令。
指令又细分为4大类:① 垂直制导指令:包括爬升、下降、保持以及飞行高度相关参数等;② 水平制导指令:包括航向的左转、右转以及保持等;③ 滑行制导指令:包括滑行到…、滑行经过…、进跑道等;④ 其他命令类型指令:包括速度指令、报告请求指令、频率改变指令、着陆许可指令和信息指令等。
基于上述本体,依赖于专家知识,进一步对陆空通话内容细化,将意图信息划分为航空器呼号、管制单位、水平意图、水平参数、垂直意图、垂直参数、速度意图、速度参数、管制移交、通信频率、进离场程序、航路点、修正海压、应答机编码等20类,详细的意图分类如图4所示。

图4 融合SESAR本体的陆空通话意图标签分类Fig.4 Classification of radiotelephony communication intent tags incorporating SESAR ontology
随后,按照BIEO标注策略,“B”代表实体开头部分的第一个字,“I”代表该实体的中间部分,“E”代表实体的最后一个字,“O”代表非实体,使用Label Studio进行标注。标注示例如表1所示。

表1 陆空通话实体标注示例
2.3 陆空通话BERT-BiLSTM-CRF联合意图信息挖掘模型
本文所提出的民航陆空通话意图挖掘模型包括3个模块,分别是BERT预训练模型、BiLSTM特征提取模型和CRF推理预测模型。首先将陆空通话语料库的文本序列输入BERT层进行预训练,得到包含字、位置和句子信息的向量,之后将向量送入BiLSTM层进行特征提取,捕获文本数据过去和未来的信息,输出每个字对于每个标签的得分概率,最后的CRF层学习捕获依赖信息并且对其加以规范约束,获得全局最优结果。模型整体架构如图5所示。

图5 BERT-BiLSTM-CRF意图挖掘模型架构Fig.5 Intent mining model architecture of BERT-BiLSTM-CRF
2.3.1 BERT预训练模型
BERT是一种自监督深度语言模型,主要通过掩码机制对多层双向Transformer编码结构进行文本的训练[31]。其中,Transformer编码器由一种摒弃循环结构、允许并行计算的自注意机制和前馈神经网络组成,其相较于传统的one hot、word2vec等预训练模型可以更好地理解语义信息,将字的上下文信息填充于当前字中,更好地解决语句中的一词多义问题,泛化能力得以拓展。BERT模型的整体结构如图6所示。

图6 BERT预训练模型架构Fig.6 Pre-training model architecture for BERT
模型的输入向量包括字嵌入、句子嵌入和位置嵌入3部分的嵌入相加,字嵌入将输入的文本序列转换为固定维度的向量,句子嵌入包含不同语句的信息,位置嵌入可以对输入文本序列进行顺序编码,经过模型的训练,输出文本序列的向量矩阵。
Transformer中的自注意力机制是模型的重点:
(6)
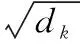
在此基础上,将多个自注意力层通过多头结构拼接起来,得到可解释性更强的多头注意力机制:
MultiHead(Q,K,V)=[head1;head2;…;headn]W
(7)
(8)
式中:“;”表示矩阵的拼接计算;W代表附加权重矩阵;head为注意力头数,i∈[1,n]为head的索引;WQ、WK、WV分别为Q,K,V的权重参数矩阵。此后,为了加快模型的收敛,引入残差网络并进行归一化的处理。
BERT模型的优势在于其包含了两个任务:掩码语言模型(masked language model, MLM)和下一句预测(next sentence prediction, NSP)[32]。MLM的基本思路就是随机地对单词进行遮蔽,遮蔽的词中大部分采用[MASK]替换,部分采用随机替换,其余的保持原样。通过联合训练,可以根据上下文的语境来推测遮蔽的词,更有效地解决一词多义问题。NSP则可以更直观地理解句子前后之间的逻辑关系。两个任务的结合可使模型的语义表达更加充分。
2.3.2 BiLSTM特征提取模型
BiLSTM模型包括前向和后向的LSTM,其对输入的序列进行双向单独编码,能够分别获取文本数据之前和之后的信息,最后将前向和后向两个隐藏层向量拼接组合作为最后的输出,可以更为有效地提取文本上下文特征。
LSTM通过输入门、遗忘门和输出门的共同作用学习序列的长期依赖。在每个时间步长t,输入序列中的一个字向量,当前t的隐藏层向量ht取决于前一时刻的ht-1和当前输入的xt。首先,LSTM的遗忘门丢弃一些信息:
ft=Sigmoid(wf·[ht-1,xt]+bf)
(9)
接着,输入门需要决定储存哪些单元状态信息,具体包括通过Sigmoid函数来更新信息it和通过tanh函数创建新的备选向量两个过程,两个过程结合后,完成单元状态更新:
ct=ft·ct-1+it·tanh(wc·[ht-1,xt]+bc
(10)
式(9)和式(10)中,Sigmoid层和tanh层的权值分别为wf和wc,偏移项为bf和bc。
最后,输出门输出语义特征,具体包括3部分:决定输出信息的部分ot、数值转换并与前一步合并得到时刻t的隐藏层向量ht;然后整合整个序列的信息并汇总成最后的输出hn。
ht=ot·tanh(ct)
(11)
hn=q(h1,h2,…,ht,…hn)
(12)
式中:q为汇总函数。
在此基础上,BiLSTM的计算公式如下:
(13)

2.3.3 CRF推理预测模型
CRF推理预测模块将BiLSTM模块的输出作为输入,其特征灵活,可以学习感知到相邻标签的依存关系,并加以约束性的规则,增强前后之间的约束信息,防止非法标识,得到最终的全局最优的预测标签,确保了结果的合理性与准确性。
设给定的输入向量为X=[x1,x2,…,xn],输出的预测标签为y={y1,y2,…,yn},CRF序列标注的过程可展示如下:
(14)
式中:Score(X|y)为在给定输入x后,预测标签为y的得分;Zt,yt为第t个字符标签为标签yt的概率发射矩阵;Ayt,yt+1代表概率转移矩阵,即从标签yt转移至标签yt+1。随后,归一化的概率计算使用softmax函数实现,再通过极大似然估计法得到概率最大的一组标注序列yLast。
(15)

2.4 陆空通话航班池合理性校验
为了进一步增强意图识别与航班之间的相关性,保证陆空通话意图挖掘的精确性,在联合模型的后面引入航班池的合理性校验模块。首先从管制员所在扇区每个航班的飞行计划或者ADS-B数据中提取航空器呼号和管制单位,生成航班池,之后从意图挖掘模块提取出挖掘到的这两部分信息,最后将上述两部分内容进行文本相似度校验,并将校验结果作为修正的参考。ED算法用于衡量文本的相似性,其原理是计算在两个字符串之间执行允许的编辑操作后从一个字符串转化到另一个字符串的最小次数,编辑距离的大小与文本相似度成反比。其中,语义匹配度Sim(l1,l2)的计算公式为
(16)
式中:l1和l2分别代表两个字符串的长度;Max(l1,l2) 表示取l1、l2长度的最大值;Len表示计算后的编辑距离的大小。在进行合理性校验后,将提取得到的意图信息形成ATC系统可理解的结构化信息。
2.5 模型复杂度分析
本文针对提出的模型,从空间复杂度和时间复杂度两方面进行了分析。其中,空间复杂度即模型的参数量,刻画了模型容量;时间复杂度即模型的计算量,刻画了模型的运行速度,即通过运行产生结果的所需操作数,二者常用O来简化表示[33]。
本文从输入文本的序列长度T、字嵌入的维度D与卷积核的宽度K3个角度表示模型复杂度。以Transformer模型的自注意力模块为例分析:某一序列经过字嵌入后的矩阵为[T,D],在Q与KT点乘的计算过程中,首先,Q中的特定元素会与K的第一行相乘,其复杂度为O(T),而K的第一行中共有D个特定元素,复杂度变为O(TD),因为Q中又共有T行,所以自注意力模块的总复杂度为O(T2D)。
根据不同网络模型的结构进行推导分析,得出本文主要算法的模型总复杂度(包含时间与空间),如表2所示。

表2 算法复杂度比较
3 实验结果与分析
本文针对繁忙的终端区这一场景,进行4个部分的对比实验,分别为基于GAN的陆空通话文本生成实验、基于原始数据集的陆空通话意图挖掘实验、引入增强数据集的陆空通话意图挖掘实验以及航班池合理性校验实验,最后进行结果分析。
3.1 陆空通话数据集这实验
本实验的原始数据集来源于真实的陆空通话记录,经过语音转录以及人工修正得来,语料库共包含12 570条语句,属于短文本,按照8∶1∶1随机划分为训练集、验证集和测试集。智能文本生成实验无需文本标注;意图挖掘实验按照第2.2节所述方法融合本体专家知识进行实体标注,共由两列组成,第一列为数据文本,第二列为其对应的BIEO标签。
3.2 实验评价指标
在对民航陆空通话智能文本生成技术的评估中,使用双语评估替补(bilingual evaluation understudy, BLEU)作为衡量标准,依据的是文本相似度。BLEU采用一种n-gram的匹配准则来比较连续n个单词在生成文本和数据集文本之间的相似度,本文使用BLEU-2、BLEU-3和BLEU-4作为评价指标,其范围为0~1,越靠近1,代表生成文本的效果越好。
本文使用准确率(precision,P)、召回率(recall,R)和综合评价指标(F1)共同作为民航陆空通话意图挖掘方法的度量指标。为了更好地评估意图识别的整体性能,采用宏平均(Macro-averaging)评估指标来计算陆空通话各类意图的Macro-P、Macro-R、Macro-F1值,即分别取其中的P、R、F1的算术平均值,具体的计算公式如下:
(17)
(18)
(19)
3.3 实验环境与参数
本文所有实验都采用Pytorch深度学习框架,在Python3.8 的环境下进行对比分析。智能文本生成技术的参数设置如表3所示,意图挖掘方法的参数设置如表4所示,其中的BERT模块使用BERT-base版本。

表3 基于改进GAN的文本生成模型的实验参数设置

表4 BERT-BiLSTM-CRF意图挖掘模型的实验参数设置
3.4 实验与结果分析
本节共设计了3个部分的实验。第3.4.1节对本文生成模型与其他模型在陆空通话文本生成上的BLEU分值进行了比较分析;第3.4.2节为基于原始数据集的陆空通话意图挖掘实验,对比了其他3类主流模型,分析了该方法的所需改进之处;第3.4.3节为引入增强数据集的陆空通话意图挖掘实验,还比较了不同模型的复杂度,并分析了加入航班池校验修正模块后的提升效果。
3.4.1 基于改进GAN的陆空通话智能文本生成技术BLEU评分
为了验证本文所提文本生成模型的性能,将其与基于极大似然估计(maximum likelihood estimation, MLE)训练的LSTM模型[7]和SeqGAN模型[11]进行比较,用BLEU-2、BLEU-3和BLEU-4衡量文本相似度,表5显示了民航陆空通话文本生成的不同模型的BLEU分数。

表5 3种方法在陆空通话文本生成上的BLEU分值
从表5可以看出,本模型充分利用了文本信息,并且更好地捕获了民航陆空通话语法结构和语义信息,文本相似度更高,实验结果优于其他对比模型。在BLEU-2标准上,本文模型相较于SeqGAN和MLE分别提高了0.048和0.109个BLEU点。在BLEU-3标准上,该模型相较于SeqGAN和MLE分别提高了0.031和0.103个BLEU点。这说明此模型的文本特征提取能力获得了增强且对抗训练更加稳定,在民航陆空通话文本生成上具有更好的性能。
3.4.2 融合本体的BERT-BiLSTM-CRF的意图挖掘模型实验结果
整个实验过程包括BERT预训练向量化、BiLSTM特征提取、CRF标注预测、意图信息提取4个部分。为了更好地验证该模型的意图识别效果,在第3.1节原始融合本体标注的数据集上(数据扩增前),在相同环境下搭建其他3个主流模型并进行对比实验,模型分别为BiLSTM-ATT-CRF、BERT、BERT-CRF,并统计其在20类意图标签上的Macro-P、Macro-R、Macro-F1值,对比结果如表6所示。

表6 原数据集下不同模型的意图识别结果对比
从表6可以看出,BERT-BiLSTM-CRF联合模型的宏平均P、R、F1值分别为96.62%、95.92%和96.27%,均高于对比模型,性能更优。
相对于BiLSTM-ATT-CRF模型,BERT模型的F1值提升了1.77%。由于陆空通话语句中包含较多中文和数字组合形式的表达,BiLSTM-ATT-CRF模型受实体不均衡的影响较大,只能获取上下文语境中的局部语义信息,而BERT模型通过预先训练,以字向量为基础,对全局语义信息进行捕捉,有效解决了一词多义在不同语境中的问题。在BERT模型上加上CRF层后的BERT-CRF模型的F1值相较于前两种对比模型分别提高了2.41%和0.64%,表明CRF借鉴了相邻标签的约束关系,通过动态规划实现了全局最优的序列标记。最后的BERT-BiLSTM-CRF模型的F1值相比之前的对比模型分别提高了2.85%、1.08%和0.44%,表明BiLSTM通过整合上下文信息,有效地提高了编码质量,增强了特征提取能力,同时也显示了BERT与BiLSTM-CRF全局和局部语义的强大互补性。
表7给出了在民航陆空通话原始数据集上,BERT-BiLSTM-CRF模型针对各类意图的识别效果。由表7可以看出,在TII、RTF、SPV、WEI、SCI和RCI这几类意图上(见表7中的红框标记),模型的识别率较低,原因是在转录真实通话的原始数据集中,这几类实体占比较少,不利于深度模型的学习和识别。为了解决这个问题,本文将基于GAN的文本数据增强方法引入到意图挖掘模型中,对原始数据集中数量较少的实体进行扩展,使之均衡分布,并提出了GAN+BERT-BiLSTM-CRF的意图挖掘模型。

表7 融合本体的BERT-BiLSTM-CRF模型在各类意图标签上的识别结果
3.4.3 融合本体的GAN+BERT-BiLSTM-CRF的意图挖掘模型实验结果
根据第3.1节所述基于GAN的民航陆空通话智能生成方法,进行语料库的生成,尤其针对实体数量较少的上述6类意图,平衡各类实体意图的数量,形成包含20 150条语句的扩充语料库。在此基础上,在第3.4.2节相同环境中进行对比实验,结果如表8所示。

表8 增强数据集下不同模型的意图识别结果对比
从表8中的实验数据可以看出,本文模型的综合效果优于其他主流模型,扩充语料库后,4类模型的Macro-P较之前分别提高了3.78%、2.98%、2.26%和2.46%,F1值较之前分别提升了3.30%、2.79%、2.50%和2.45%,在没有BERT模型的BiLSTM-ATT-CRF模型中效果提升最为明显。GAN+BERT-BiLSTM-CRF模型在各类意图上的具体实验结果如表9所示,对比表7中的各项数据,可以看出该方法在各项指标上都有所提升,尤其是识别率较低的几类具体实体。

表9 融合本体的GAN+BERT-BiLSTM-CRF模型在各类意图标签上的识别结果

续表9
为了更好地评估模型,本文对比了不同模型的参数量与计算量,如表10所示,从模型复杂度的角度进行对比分析。

表10 不同模型复杂度对比
从表10的对比数据可以看出,GAN模型通过对抗竞争实现奖励最优化,降低了模型的复杂度以及计算资源,对于大维度生成样本,计算量不会面临类似传统模型的指数级上升。在几类意图挖掘模型中,BERT模型的复杂度较高,说明其表示能力与有效复杂性更高。综合表8与表10的结果可以看出,本文的联合模型与对比模型相比,在时间与空间复杂度差别不大的情况下,意图提取的精度更高。
为了更直观地体现出基于GAN的智能文本生成技术在意图挖掘中的作用,图7展示了在原始数据集与引入GAN数据增强后的数据集上,联合模型在20类意图上的F1值。由图7可以看出,本文模型效果更优,在TII、RTF、SPV、WEI、SCI几类实体上效果提升更为明显。

图7 GAN数据增强前后模型在各意图标签上的F1值对比Fig.7 Comparison of F1 values of the model on each intention label before and after GAN data enhancement
上述结果表明,本文所提联合模型可以丰富民航陆空通话语料库且获得更高的F1值,具有更好的性能且优于当前的其他主流模型。最后,引入终端区场景下的航班池信息,包含航空器呼号和管制单位信息,与本文模型对应提取到的CAL与CUN信息进行合理性校验并修正,校验后整体的F1值提升了0.03%,达到了98.75%,提高了意图挖掘整体的可靠性与鲁棒性,各模型Macro-F1值性能对比如图8所示。

图8 陆空通话意图挖掘中不同模型的Macro-F1值对比Fig.8 Comparison of Macro-F1 values of different models in radiotelephony communication intent mining
4 结束语
本文基于民航陆空通话内容难以获取、意图提取准确率低且尚未被应用于数字化系统这一背景,提出了一种融合本体的基于GAN+BERT-BiLSTM-CRF+ED的陆空通话意图挖掘方法。首先,结合Seq2Seq框架对传统GAN模型进行改进,并在判别器中引入交叉熵,更有效地提取了文本信息的上下语义关系以及关键信息,可以以无监督的方式生成高质量的文本,扩充语料库,解决实体不均问题。其次,进入BERT-BiLSTM-CRF联合模型进行意图识别和提取,BERT通过预训练生成语义信息丰富的字向量,解决一词多义问题,BiLSTM编码充分捕获上下文的文本特征,CRF通过增加约束获取了全局最优效果。最后,合理性校验修正模块进一步提升了航空器呼号和管制单位的准确率。模型在20类意图上的整体效果优于对比模型,可形成ATC结构化信息,为减轻管制员工作负载、监测及可视化终端区管制工作、构建民航领域知识图谱以及航空安全的事后监理提供了新的解决思路。
在未来,还需进一步优化深度学习模型的架构,以获得更好的感知性能,或利用剪枝及知识蒸馏等方法降低模型复杂度,减少算力,还可将意图挖掘的信息应用于其他ATC应用,如流量预测、冲突检测以及管制决策等。
