基于多帧聚类的紧凑型HFSWR虚假点迹识别方法
2024-01-30孙伟峰赵林林纪永刚戴永寿
孙伟峰, 赵林林, 纪永刚, 戴永寿
(中国石油大学(华东)海洋与空间信息学院, 山东 青岛 266580)
0 引 言
高频地波雷达(high-frequency surface wave radar, HFSWR)是海上目标超视距探测与跟踪的重要手段[1-3]。目标探测用的地波雷达接收天线通常采用大型阵列式,需要占用稀缺海岸资源,部署、维护的难度大,限制了其推广应用[4]。与之相比,紧凑型HFSWR系统因其空间需求小、部署和维护灵活等优点成为地波雷达系统的一个发展方向[5-7]。然而,紧凑型HFSWR的接收天线阵列孔径小且发射功率低,导致其对目标方位角的估计精度降低,目标探测时的信噪比低,且受电离层杂波、海杂波以及射频干扰等影响[8],导致回波信号中包含大量杂波信号,增加了目标检测与跟踪的难度[9-10]。
对HFSWR回波信号进行解距离、解速度处理后,可以得到包含目标与杂波的距离-多普勒(range-Doppler, RD)谱。为了在RD谱上有效地检测出目标,国内外学者发展了多种方法。其中,恒虚警率(constant false alarm rate, CFAR)[11]检测方法通过对比待检单元与参考单元的功率估计值检测目标。然而,在密集杂波环境下,CFAR检测的虚警率较高。对此,Wang等人[12]通过字典学习的方法统计杂波信息,以获得更优的CFAR检测阈值。Jangal和Li等人[13-14]利用小波变换的多尺度特性,通过图像的低频和高频分量将杂波与目标点分离。这些方法在特定条件下取得了较好的检测效果,但是检测结果受到小波变换的尺度、完备字典的选取等参数设置的影响,在缺少先验知识的情况下,参数难以设置准确,虚警率会提高。在目标智能检测方面,Wu和Zhang等人[15-16]将图像处理、机器学习等方法应用于目标检测,但也存在虚警率较高、鲁棒性较差等问题。
通过上述分析可知,现有的目标检测算法难免存在一定程度的虚警,尤其是应用于紧凑型HFSWR低发射功率、低信噪比的检测环境下,虚警率会大幅增加,因此会产生大量的虚假点迹。这些虚假点迹不仅会增加跟踪系统的计算负担,而且容易导致航迹断裂、产生虚假航迹。为了剔除虚假点迹,林强等人[17]通过选取点迹的特征参数(如多普勒速度、幅度等)组成特征向量,首先采用核主成分分析法进行降维,然后使用加权K近邻算法鉴别杂波点迹,但是此类方法依赖于目标的回波特征,对不同体制的雷达并不具备普适性。袁子寅[18]提出了一种高频雷达点迹滤波算法,通过统计连续多帧点迹的距离变化,并计算其标准差,若标准差大于设定的阈值,即判断为虚假点迹,但此方法并不适用于目标机动的场景。Cheng等人[19]首先将雷达点迹聚类成簇,而后对簇分类;张迪[20]利用聚类算法将虚假点迹聚类。以上两种方法利用目标点迹和虚假点迹的密度差异,可大致确定虚假点迹的范围,但不适用于多目标交叉、目标点迹与虚假点迹叠加的场景。
综上所述,现有的虚假点迹识别方法或是局限于利用点迹的特征参数,而紧凑型HFSWR探测到的虚假点迹与目标点迹特征参数较为相似,仅利用点迹特征难以对其进行有效区分;或是依赖于对目标运动模型的假设,但是由于船只运动的机动性,建立准确的运动模型较为困难;或是利用目标点迹和虚假点迹的密度差异,但无法做到准确识别。为此,本文从海上船只目标的运动规律出发,利用目标点迹与虚假点迹的时序变化差异,将多帧点迹聚类与分类算法相结合,提出了一种级联的虚假点迹识别方法。该方法首先将潜在目标点迹聚类成簇,而后对簇内点迹分类,以实现对虚假点迹的准确识别。
为了在目标数量未知、存在大量虚假点迹的情形下确定潜在目标点迹的位置,本文采用聚类算法,将多帧点迹数据中属于同一目标的潜在点迹聚类成簇[21-22]。基于密度的噪声应用空间聚类(density based spatial clustering of application with noise, DBSCAN)算法可以发现任意形状的簇,且能够自动确定簇的数量并剔除离群点[23],比基于划分的聚类方法[24]、基于层次的聚类方法[25]等更加适用于解决目标点迹聚类问题。但是将该算法直接应用于多帧目标点迹聚类,存在以下问题。首先,DBSCAN需要人为设定邻域半径和邻域最小点数目两个参数[26],这两个参数的设置不当易造成聚类错误、计算量增大等问题;其次,属于同一目标的点迹在连续多帧中近似于线性分布[1],且受量测噪声影响存在波动,但并非任意形状,直接使用DBSCAN易降低聚类的准确度;最后,DBSCAN算法主要适用于密度聚类,在多帧聚类中无法体现点迹的时序关系。为此,本文在分析DBSCAN算法应用于多帧聚类优势与不足的基础上,提出了基于最优邻域尺寸的多帧聚类方法(multi-frame clustering method based on optimal neighborhood size, MFCONS)。该方法通过设定聚类中心点、优化邻域尺寸以及改进邻域设计等方式,可有效解决多帧目标点迹聚类问题。
将潜在目标点迹聚类后,需要采用分类器进一步判别簇内的待识别点迹是否为虚假点迹。由于目前获取的紧凑型HFSWR点迹数据量较少,因此并不适合采用深度学习分类方法。在常用的分类方法中,支持向量机(support vector machine, SVM)[27]具有较强的分类能力,但其存在训练速度慢,对参数调整较为敏感等问题。反向传播(back propagation, BP)[28]网络泛化能力较弱,容易出现“过拟合”现象,分类准确率低。与之相比,极限学习机(extreme learning machine, ELM)[29]是一种泛化性能好的单隐层神经网络,可以随机初始化输入权重和偏移,而无需在训练过程中进行调整,在保证分类精度的情况下计算效率更高。因此,本文采用ELM模型进行分类。
综上所述,本文提出了一种基于MFCONS与ELM相结合的虚假点迹识别方法。首先利用MFCONS完成多帧目标点迹聚类,将待识别点迹区分为潜在目标簇或孤立的虚假点迹;然后,使用ELM将潜在目标簇内的待识别点迹进一步辨识为目标点迹或虚假点迹。仿真及实测数据实验结果验证了提出方法的有效性。
1 虚假点迹特性分析与识别原理
紧凑型HFSWR可以获取目标的距离、多普勒速度和方位角等参数,单个雷达点迹即代表船只目标。由于紧凑型HFSWR对海上船只目标探测时,多普勒速度、距离精度较高,而方位角精度低[1],故本文将多普勒速度和距离作为目标的特征参数。
海上船只目标一般按照特定的模式运动,若在连续多帧的距离多普勒(Range-Doppler, RD)谱中均可以检测到其点迹,其点迹位置序列能够反映目标的运动趋势。而RD谱中的某些分辨率单元受系统内部以及外界环境的瞬态噪声、海杂波等片状噪声影响,形成的虚假点迹在连续的数据帧中不会呈现有规律的运动趋势。
从实测数据中提取的连续五帧(第[t-2,t+2]帧,并将第t帧定义为中心帧)点迹的RD速度(RD velocity, R-V)图如图1所示。该图中既包含目标点迹,也包含虚假点迹,目标点迹的多普勒速度和距离呈有规律变化,而虚假点迹或是孤立出现,或是与目标点迹掺杂在一起。在某一特定时刻获取的数据帧中,虚假点迹的R-V特征与目标点迹相似,难以区分。因此,可以从多帧的角度,首先将符合船只运动规律的待识别点迹确定为潜在目标点迹,而后利用分类器进一步将其辨识。

图1 连续多帧点迹的R-V图Fig.1 R-V diagram of continuous multi-frame plots
根据以上对目标点迹与虚假点迹特性的分析,本文提出了一种基于多帧聚类与ELM的虚假点迹识别方法,总体流程如图2所示。首先将连续多帧点迹的距离、多普勒速度参数输入至MFCONS,将与待识别点迹属于同一潜在目标的点迹聚类成簇,并识别出孤立的虚假点迹。然后,分别计算出潜在目标簇内的待识别点迹与其相邻帧点迹的距离和多普勒速度的差分,并将其作为特征输入至ELM分类器,以识别出簇内的虚假点迹。

图2 虚假点迹识别流程Fig.2 False plot identification process
2 基于最优邻域尺寸的多帧聚类方法
海上船只一般按特定规律运动,因此属于同一目标的点迹在连续多帧中,其多普勒速度、距离参数会呈现以下时序特点:① 多普勒速度参数相近,距离参数呈递增或递减趋势;② 两者随时间推移呈现明显的运动规律。而虚假点迹则不具备以上两种特点,因此可以利用多帧聚类的方式,将与待识别点迹属于同一潜在目标的多帧点迹聚类到同一个簇中,以识别出潜在的目标点迹与孤立的虚假点迹。
为此,本文提出了MFCONS。该方法在保留DBSCAN自动确定簇的数量、剔除离群点的基础上,提出了如下改进:① 在邻域设计方面,引入聚类中心点[24]的概念,并将待识别点迹设为聚类中心点,划定多层矩形邻域,以此突出目标点迹与虚假点迹的时序特点差异;② 为了获取最优的邻域尺寸,以簇内目标点迹数量、虚假点迹数量以及聚类时间为特征建立目标函数,遍历经验范围内的邻域尺寸值,目标函数取最大值时对应的邻域尺寸值即为最优邻域尺寸。
2.1 多帧滑窗
采用滑窗的形式,将连续多帧点迹的距离和多普勒速度参数作为MFCONS的输入。滑窗长度取2M+1,包含第t帧与其前后各M帧点迹,其中M≥1。点迹集合AFRt可表示为
AFRt={FRt-M,FRt-M+1,…,FRt,…,FRt+M}
(1)
(2)

2.2 邻域设定方法
MFCONS在邻域设计方面,提出了以下两点改进:① 取中心帧的点迹为待识别点迹,并作为聚类中心点。中心帧与其他帧点迹存在M个时间帧差,因此设置M层邻域。利用M层邻域分别判断时间帧差为k的点迹是否位于第k层邻域内,其中1≤k≤M,以此突出目标点迹的时序特点;② 采用矩形邻域,可针对目标在连续帧内的距离、多普勒速度参数的不同变化量,更灵活地调节矩形邻域的长和宽,因此更加适合对目标点迹聚类。此外,与DBSCAN相比,MFCONS避免了乘法运算和开方运算,降低了计算复杂度。


图3 多帧滑窗与邻域关系图Fig.3 Multi-frame sliding window and neighborhood relationship graph
(3)
由聚类中心点以及其邻域内的点迹组成一个簇,若聚类中心点的邻域内没有任何点迹,则将其定义为孤立点,孤立点即判别为虚假点迹。需要指出的是,本文方法通过分析目标在连续多帧内的RD参数变化规律,利用非中心帧点迹的距离和多普勒速度参数识别中心帧点迹(聚类中心点),对于没有划归到任何一个类簇的非中心帧点迹,本文将不作处理。
使用MFCONS进行聚类的伪代码如算法1所示。

算法 1 MFCONS的伪代码输入 AFRt、L^k、S^k,其中1≤k≤M输出 潜在目标簇,孤立点1.标记所有待识别点迹为unvisited;2.do3.随机选择一个unvisited的待识别点迹p1;4.标记p1为visited;5. if p1的多层矩形邻域内存在点迹6. 创建一个新簇C1,并将p1添加到C1,用NO(p1)表示点迹p1在其多层矩形邻域内点迹的集合;

7. for NO (p1)中的每个点迹p1'8. if p1'是簇C2的成员9. 把簇C1添加到簇C2;10. end if;11. end for;12. else标记p1为孤立点;13. end if;14.until 没有标记为unvisited的待识别点迹。
2.3 邻域最优尺寸的设定方法
邻域尺寸的设定方法应考虑以下3点:首先,要保证属于同一个目标的点迹在同一簇中出现;其次,要保证簇内虚假点迹数量少,以减轻ELM分类器的计算量;最后,应保证算法的实时性。本文参考线性优化理论,确定以上3点在线性组合下的最优邻域尺寸。
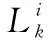
最优尺寸由以下步骤确定。

步骤 2由于各特征的数值差别较大,因此对Ti、Fi、Hi进行归一化:
(4)

步骤 3计算每组训练样本的目标函数值G(i):
(5)

(6)
(7)



图4 各特征随邻域尺寸的变化趋势Fig.4 Variation trend of each feature with neighborhood size
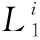
3 基于ELM的点迹分类器
将多帧点迹进行聚类后,可以得到潜在目标簇,但是簇内的待识别点迹可能为虚假点迹。因此,需要使用点迹分类器,将簇内待识别点迹区分为目标点迹或虚假点迹。
文献[30]提到目标位置的差分可以反映目标的运动趋势。因此,通过计算簇内待识别点迹与其相邻帧点迹的距离和多普勒速度的差分,并将其输入至ELM网络,从而对待识别点迹进行准确辨识。
3.1 ELM模型
ELM网络模型如图5所示。

图5 ELM模型结构Fig.5 Structure of ELM model
若存在可分为EM类的EN个数据,具有EL个隐藏层节点的ELM网络如下所示:
(8)
式中:i=1,2,…,EN;Ek=1,2,…,EM;g(x)是激活函数;wEj是输入权重;βEj是输出权重;bEj是第Ej个隐藏层节点的偏置;xEi与yEk分别为ELM输入与输出。用矩阵表示为
Hβ=Y
(9)
式中:
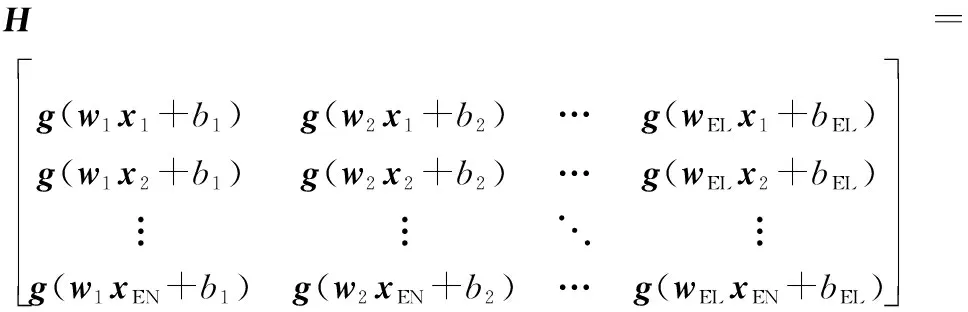
β=[β1,β2,…,βEM]T
ELM网络的目标是最小化输出误差,即
(10)
式中:T=[Et1,Et2,…,EtEN]T为期望输出,即
(11)
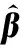
3.2 特征提取
对于簇AFCt中的点迹,可表示为
AFCt={FCt-M,FCt-M+1,…,FCt,…,FCt+M}
(12)
(13)
为了充分反映目标的运动趋势,而又不把处于起始或终止阶段的目标航迹错判,本文将分别计算出待识别点迹与其前M帧或后M帧点迹的距离和多普勒速度的差分,如图6所示。

图6 特征提取Fig.6 Feature extraction
特征λ1=[Δ1V1Δ1R1,Δ2V1Δ2R1,…,ΔMV1ΔMR1]T为待识别点迹与第[t-1,t-M]帧点迹的多普勒速度和距离的差分,ΔkV1和ΔkR1(k=1,2,…,M)的计算方法如下所示:
(14)
特征λ2=[Δ1V2Δ1R2,Δ2V2Δ2R2,…,ΔmV2ΔmR2]T为待识别点迹与第[t+1,t+M]帧点迹的多普勒速度和距离的差分,ΔkV2和ΔkR2(k=1,2,…,M)的计算方法如下所示:
(15)
3.3 点迹分类步骤
基于ELM的点迹分类流程如图7所示。对于簇内的待识别点迹,通过分别遍历第[t-1,t-M]帧与第[t+1,t+M]帧的点迹,组成Pt-1×Pt-2×…×Pt-k×…×Pt-M个特征λ1,以及Pt+1×Pt+2×…×Pt+k×…×Pt+M个特征λ2,并将以上特征分别放到ELM进行遍历,若存在测试结果为真,则停止遍历,并将该待识别点迹标记为目标点迹;否则,将该点迹标记为虚假点迹。

图7 ELM分类流程Fig.7 Procedure of ELM classification
4 实验结果与分析
为了验证本文提出的虚假点迹识别方法的有效性,分别利用仿真数据和实测数据进行测试。本文方法实验平台硬件为Intel i7-6498U (2.5 GHz) CPU、12 GB。
4.1 仿真数据实验
船舶自动识别系统(automatic identification system, AIS)能够记录船舶的真实航迹。将紧凑型HFSWR点迹以及航迹数据与同时段AIS航迹进行对比,可以得到部分目标点迹与虚假点迹,以此为训练集。另外,取雷达探测区域内的10条AIS航迹,并将其转换为紧凑型HFSWR点迹数据,数据率设置为1帧/分钟,共200帧,以此为测试集。对于测试集点迹数据,根据紧凑型HFSWR目标点迹参数的误差范围[1],分别给距离、多普勒速度加入不同强度的高斯白噪声,而后加入虚假点迹。虚假点迹的数量服从参数为λ的泊松分布,出现位置在观测区域内随机均匀分布。
4.1.1 不同杂波数量下,MFCONS邻域层数选择对整体方法的性能影响
取邻域层数分别为1、2、3,对应滑窗长度分别为3、5、7。杂波密度参数λ分别取10、50、100、150、200。为了评估虚假点迹识别性能,本文采用虚假点迹识别率Ft以及目标点迹误判率Pf作为指标,定义如下:
式中:FY表示本方法正确识别的虚假点迹;FA表示虚假点迹总数;TN表示本方法将目标点迹误判为虚假点迹的个数;TR表示目标点迹总数。
λ和邻域层数M取不同值时,本文方法的性能对比如图8所示。

图8 不同杂波密度和邻域层数下本文方法性能对比Fig.8 Performance comparison of the proposed method under different clutter density and number of neighborhood layers
如图8所示,当M=2时,虚假点迹识别率高于M=1和M=3,表明2层邻域时,对目标的运动特征提取效果最好。M分别取1、2、3时,目标点迹误判率均维持在1%左右,且随着邻域层数增多,平均每帧所耗时间骤增。综合分析,在M=2时,虚假点迹识别率维持在95%以上,且计算速度仅次于M=1,此时最适用于密集杂波背景下的工程实现。
4.1.2 不同杂波数量下,MFCONS与ELM分类器性能对比
为了测试MFCONS和ELM分类器分别在不同杂波密度下的虚假点迹识别性能,参数λ分别取10、50、100、150、200,MFCONS邻域层数取2。
在不同杂波密度下,MFCONS和ELM分类器的性能如图9所示。
参数λ由10增加到200时,虚假点迹密度增大,因此聚类之后的孤立点数量降低,故MFCONS的虚假点迹识别率降低。此时,有更多虚假点迹进入到ELM分类器,因此ELM分类器的虚假点迹识别数量提高,识别率上升。

图9 不同杂波密度下MFCONS和ELM分类器性能对比Fig.9 Performance comparison of MFCONS and ELM classifiers under different clutter density
4.1.3 不同聚类方法性能对比
在本节中,在参数λ取50的情况下,分别使用DBSCAN与MFCONS进行实验。MFCONS邻域层数分别取1、2、3。DBSCAN的邻域尺寸采取第2节中最优尺寸的设置方法,邻域中最小点数设置为2。
为了评估聚类方法的性能,本节采用目标点迹聚类率CT与虚假点迹聚类率CF作为指标,定义如下:
式中:TC和FC分别表示参与聚类的目标点迹数目和虚假点迹数目。
MFCONS在1、2、3层邻域均保持较高的目标点迹聚类率,并且随着聚类层数的增加,CT、CF和平均每帧所耗时间都呈明显上升趋势,如表1所示。同时,与DBSCAN相比,MFCONS速度更快,虚假点迹参与聚类的比例更少,减轻了ELM分类器的计算负担。

表1 不同聚类方法性能对比
4.1.4 不同机器学习方法性能对比
在本节中,MFCONS邻域层数取2,参数λ取50,首先使用MFCONS进行聚类,而后使用不同的机器学习方法进行了仿真。Ft和Pf为两级方法整体的识别性能,平均每帧所耗时间仅统计机器学习方法的所耗时间,如表2所示。对于BP网络,训练周期总数设置为1 000,学习速率定义为0.01。SVM的核函数设置为多项式函数,最高次幂为3次,惩罚因子设置为200。

表2 不同机器学习方法性能对比
如表2所示,与BP网络和SVM相比,ELM在拥有最高准确度的同时,也展示了最快的速度,保证了实时性。
4.1.5 不同虚假点迹识别方法性能对比
在本节中,分别采用文献[18]和文献[19]中的方法与本文方法进行对比。本实验中,MFCONS邻域层数取2,参数λ取100。
与文献[18]和文献[19]中的方法相比,本文引入了聚类-分类级联方法,首先利用MFCONS确定潜在目标簇,而后对簇内点迹分类,提高了虚假点迹识别率、降低了目标点迹误判率,并提高了方法的实时性,如表3所示。
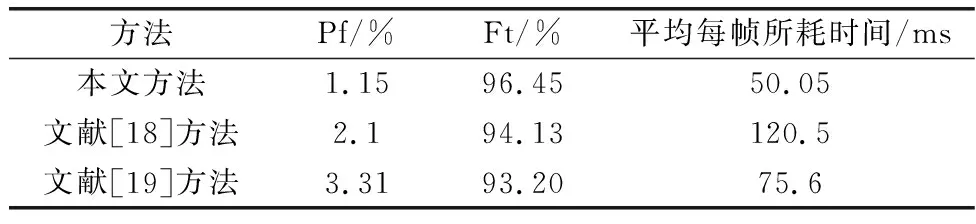
表3 不同虚假点迹识别方法性能对比
4.2 实测数据实验
本节使用实测数据进行实验。由于紧凑型HFSWR海上探测面积较大,海态复杂,尽管AIS设备提供了一些参考信息,但是仍然存在未安装该系统的船只,所以确定所有目标点迹的位置和数量极其困难。因此,本节将识别出的虚假点迹进行滤除,而后使用文献[31]的跟踪器进行跟踪,并将跟踪后得到的航迹(虚假点迹滤除后航迹)与未进行虚假点迹滤除的航迹(原始航迹)进行对比。
以图10中的航迹为例,红色标记处为航迹起点,原始航迹在使用逻辑法进行起始时,受虚假点迹的干扰,出现了错误关联,因此航迹起始速度较慢,跟踪时长为20 min,虚假点迹滤除后的航迹将跟踪时长提升至27 min。

图10 采用实测数据的航迹对比Fig.10 Track comparison of measured data
总体来说,虚假点迹滤除后的航迹数量比原始航迹数量减少了10.4%,且通过对比AIS信息发现,减少的航迹90%以上为虚假航迹。本方法滤除掉的点迹数目占实测点迹总数的37.8%,已滤除点迹与保留点迹的距离、多普勒速度对比如图11所示。
如图11所示,在雷达有效探测范围内,已滤除点迹的距离和多普勒速度大致呈均匀分布。对比跟踪结果可知,在虚假点迹滤除后航迹中,虚假航迹数量大幅减少,目标航迹数量基本保持不变,证明本文方法对实测点迹中的虚假点迹具有良好的识别效果。因此,本文提出的方法可以有效解决强杂波干扰下目标检测虚警率高的问题,减轻了后期目标跟踪的计算负担。

图11 已滤除点迹与保留点迹的对比Fig.11 Comparison of filtered plots and retained plots
5 结 论
本文通过分析紧凑型HFSWR船只目标的运动趋势,提出了一种聚类-分类级联的虚假点迹识别方法。首先,将多帧点迹输入至本文提出的MFCONS,将属于同一目标的潜在点迹聚成簇,并识别出孤立点;然后,通过计算簇内待识别点迹与相邻帧点迹的多普勒速度、距离的差分,并将其作为特征输入至ELM,从而进一步辨识虚假点迹。本文提出的MFCONS,通过遍历经验的尺寸范围,实现了最优尺寸的选取。实验结果表明:MFCONS可实时、准确地解决多帧中船只目标聚类问题;两级级联的虚假点迹识别方法可以对虚假点迹进行准确地识别。
由于存在目标点迹误判率,在使用滤除后的点迹进行跟踪时,丢失了少量真实航迹。降低目标点迹误判率以及在个别目标点迹丢失的场景下进行跟踪,是当前正在开展的工作。
