Prediction and driving factors of forest fire occurrence in Jilin Province,China
2024-01-26BoGaoYanlongShanXiangyuLiuSainanYinBoYuChenxiCuiLiliCao
Bo Gao · Yanlong Shan · Xiangyu Liu · Sainan Yin ·Bo Yu · Chenxi Cui · Lili Cao
Abstract Forest fires are natural disasters that can occur suddenly and can be very damaging,burning thousands of square kilometers.Prevention is better than suppression and prediction models of forest fire occurrence have developed from the logistic regression model,the geographical weighted logistic regression model,the Lasso regression model,the random forest model,and the support vector machine model based on historical forest fire data from 2000 to 2019 in Jilin Province.The models,along with a distribution map are presented in this paper to provide a theoretical basis for forest fire management in this area.Existing studies show that the prediction accuracies of the two machine learning models are higher than those of the three generalized linear regression models.The accuracies of the random forest model,the support vector machine model,geographical weighted logistic regression model,the Lasso regression model,and logistic model were 88.7%,87.7%,86.0%,85.0% and 84.6%,respectively.Weather is the main factor affecting forest fires,while the impacts of topography factors,human and social-economic factors on fire occurrence were similar.
Keywords Forest fire · Occurrence prediction · Forest fire driving factors · Generalized linear regression models ·Machine learning models
Introduction
Climate change has increased forest fire occurrence worldwide in recent years,and many countries and regions have endured severe forest fires,such as the 2019 bushfires in Australia which destroyed millions acres of eucalyptus forest in the country’s southeast,emitting approximately 7 × 108tons of CO2(van der Velde et al.2021).Forest fires in China’s Xichang Liangshanzhou in March 2020 scorched 3,047 ha and 19 firefighters lost their lives.In recent years,the number of wildfires have significantly increased in California,USA,due to persisting drought and the scale of wildfires in August 2020 reached a record high with an area of 41,800 ha burnt (Keeley and Syphard 2021).As a harmful and destructive natural force,forest fires threaten the ecological environment as well as the safety of human life and property (Jolly et al.2015;Senande-Rivera et al.2022).It is obvious that prevention of forest fires is more important than fighting them.Thus,research on predicting the occurrence and spread of forest fires has been a priority.Systems of forest fire danger rating such as the Canada Forest Fire Danger Risk System (CFFDRS) and the National Fire Danger Rating System (NFDRS) in the United States,and systems of forest fire behavior prediction,including BehavePlus Fire Modeling System and Fire Area Simulator (FARSITE) of US Dept.of Agriculture have been successfully applied in forest fire forecasting and suppression (Finney 1998;Taylor and Alexander 2006;Hardy and Hardy 2007;Andrews 2014).
Prediction of forest fire occurrence is used to forecast the probability of occurrence,the frequency and burnt area over a certain time period in a region through mining of fire data,including historical fire data and remote sensing hot spot data (Peterson et al.2010;Yang et al.2010;Šturm and Podobnikar 2017;Rijal 2018).A number of studies have shown that variations in the driving factors of forest fires,including weather,topography,vegetation,human and social-economic factors,can result in differences in forest fire conditions in different times and regions,ultimately affecting forest fire occurrence(Boubeta et al.2019;Kim et al.2019;Milanović et al.2020).Prediction of the probability of occurrence is essentially a binary problem,i.e.,whether a forest fire occurs or not (Phelps and Woolford 2021).The generalized linear regression model is one of the most effective methods to solve such problems,and has been widely used in forest fire prediction,disease diagnosis and in other fields (Ghosh and Chinnaiyan 2005;Nurdiati et al.2022).Among all generalized linear regression models,the logistic regression model is one of the most commonly used in forest fire occurrence prediction due to its strong universal adaptability,and it has been widely used in the screening of driving factors of forest fires,spatial distribution patterns and the prediction and analysis of lightning-caused fires (Díaz-Avalos et al.2001;Andrews et al.2003;Ordóñez et al.2012;Guo et al.2016a).However,the spatial relationship between the driving factors affecting the occurrence of forest fires is not considered in the logistic regression model and may decrease the accuracy of the prediction.Therefore,researchers have applied geographically weighted regression (GWR),a model that fully considers the effect of geographical and spatial factors on forest fire occurrence into the prediction of occurrence,and results have shown that it could dramatically improve the accuracy of prediction (Martínez-Fernández et al.2013;Rodrigues et al.2014;Šturm and Podobnikar 2017).In recent years,with the development and wide use of computer technology,machine learning techniques such as random forest,support vector machine and artificial neural networks have also been applied to solve binary classification problems and are gradually being applied in the study of forest fire prediction (Elia et al.2020;Coughlan et al.2021;Sharma et al.2022).Gigović et al.(2019) predicted forest fire occurrence in Serbia using the support vector machine and random forest model.Kim et al.(2019) applied the random forest model to predict the probability of forest fire occurrence in Korea and found a strong correlation between the probability of occurrence and human activities.Elia et al.(2020) predicted wildfires in different regions in Italy using an artificial neural network and found vegetation and climate were important variables that affecting forest fire occurrence.Coughlan et al.(2021) developed a prediction model for lightening fires in Australia based on machine learning,with an accuracy of 71%.Milanović et al.(2020) compared the performances of the logistic regression model and the random forest model in predicting the occurrence of forest fires and the results showed that the random forest model was more accurate.
Although research on the prediction of forest fire occurrence has developed rapidly in recent years,challenges still exist.Existing models cannot be widely applied in different times and regions due to the influence of different fuels,fire sources,climate,social and economic conditions.More investigations are necessary to determine the more suitable model for predicting forest fire occurrence.Jilin Province in central northeast China,is an important province for forestry.Effective forest fire prevention and control has protected the province for 42 consecutive years from major forest fires up to 2022.However,as combustible biomass accumulates,the surface fuel load increases and the risk of fire significantly increases.In this paper,the prediction models on the probability of forest fire occurrence in Jilin Province were developed from the historical data of forest fires from 2000 to 2019.The models have taken a number of relevant factors into account,including climate,topography,vegetation,human and social-economic factors,using generalized linear regression models and machine learning models.Methods were also screened for accurately predicting forest fires in Jilin Province,and the major factors affecting fire occurrence were determined to reduce the risk of occurrence in this region and to provide the basis for effective forest fire management strategies.
Materials and methods
Study site
Jilin Province (121°38′ -131°19′ E,40°50′ -46°19′N) is in the middle of northeast China,with elevations from five to 2691 m (Zhu et al.2021),and it is an important forestry province.The terrain is high in the southeast,low in the northwest,with the east mountainous,and the midwest generally flat.The province has a temperate continental monsoon climate with distinct seasonal changes.Temperature are highest in July,from 34.8 -39.5 °C,and lowest in January at–38.0 --39.8 °C.Total annual sunshine is 2630 -2930 h,and relative humidities 52% -61% (Guo et al.2018).The major soils include dark brown soil,chernozem,alluvial soils,meadow soils,and saline-alkali soil.Forests cover 7.85 × 106ha,approximately 41.5% of the province.Dominant tree species includePinus sylvestrisvar.mongolica,Larix olgensis,Pinus koraiensis,Picea asperata,Quercus mongolicaFisch.ex Ledeb.,andBetula platyphylla(Li et al.2022).
Dependent variables
Data on forest fires were generated from the historical forest fire data from 2000 to 2019,provided by the Jilin Provincial Archives and the Jilin Provincial Forestry and Grassland Bureau.Major parameters included the occurrence and ending time of the fire,its location,fire source,total area burned and other relevant information of the sites.A total of 1322 data points were generated based on the location of the fire after removing data with missing information.The extent of the fire or area burnt was simplified into a circle for each fire point in order to separate fire and non-fire points clearly.A buffer zone was generated for each site with the ignition point as the center according to the total area burned.Nonfire data were generated randomly within the remaining area after buffer zones were eliminated.The total number of nonfire points was set at 1.5 times the fire points,with the distance between points at least 500 m (Catry et al.2009;Guo et al.2016b).Time information was randomly set for each non-fire point using Excel.
Independent variables
Prediction models for fire occurrence were developed with the data,including climate,topography,vegetation,and human and social-economic information (Table 1).Data of 32 meteorological stations were created based on locations.The nearest weather station to each fire and non-fire point was determined by the proximity analysis tool,and meteorological data for each were based on the location of the weather station and the fire time of the data.

Table 1 Independent Variables and Data Sources
Information on elevation,slope,aspect index,normalized difference vegetation index (NDVI),population density and gross domestic product (GDP) are in the form of raster data,and for slope and slope orientation were obtained by analyzing the digital elevation model (DEM) data of Jilin Province from GDEMV2 30 M resolution digital elevation dataset.Slope orientation was in degrees with a range of 0° -360°,and a flat slope was displayed as -1.Since the original data of slope orientation was not in an appropriate format to describe the correlation with the probability of forest fire occurrence,raster data of slope orientation were converted into aspect index (also in the form of raster data) from Eq.(1) using a grid computer (Guo et al.2017).Datasets of population and GDP included historical data from 2000,2005,2010,2015 and 2019.For missing years,information was calculated based on historical data and information from“China Statistical Yearbook”,and raster data of the other 15 years were generated using raster calculator.Values of elevation,slope,aspect index,NDVI,population density and GDP were based on the locations and time of each fire and non-fire point.
where,α is the value of slope orientation in degrees.
Vector data of railways,roads,settlements,and river systems were obtained from 1:1,000,000 basic geographic information database.The nearest distance to each fire and non-fire point was calculated to set values for the nearest railway,road,settlement and river system.
The spatial distribution of forest fire driving factors and meteorological stations are shown in Fig.1.

Fig.1 Spatial distribution of forest fire driving factors (a shows the spatial distribution of settlements and railways;b,c,d,e,and f show the spatial distribution of roads,river systems,elevation,slope,and aspect index,respectively;g,h,and i show the spatial distribution of NDVI,population density,and GDP in 2019.);meteorological stations shown in c

Fig.2 Spatial distribution of coefficients of GWLR model
Data processing
Data were normalized before using to eliminate the influence of dimension on the prediction of the models,and divided into two groups with 60% of the data as the training samples and the rest as the validation samples.Prediction models were based on the training samples and then were evaluated with the validation samples.Multicollinearity diagnosis was performed on the independent variables before modelfitting.Seventeen independent variables passed the diagnosis(VIF <10) used to develop the prediction models.Eighty percent of the training samples were randomly selected as the subset of samples.The process was repeated five times and the results were labeled as Sample 1–5.Model variables were selected based on the five samples,and the variables that showed up at least three times were set as the predicting variables for fitting the model with the training samples.The purpose of the process was to eliminate the influence of sample division on model prediction (Ma et al.2020).
Prediction models of the probability of forest fire occurrence
In this paper,we propose five binary classification models to predict the probability of forest fire occurrence in Jilin Province including,the logistic model (LR),the geographical weighted logistic regression model (GWLR),the Lasso regression model (Lasso),the random forest model (RF),and the support vector machine model (SVM).For many years,the three generalized linear models,LR,GWLR,and Lasso,have been widely used in research on the forest fire occurrence prediction (Nadeem et al.2019;Rodrigues et al.2019;Milanović et al.2020;Su et al.2021).Considering the data volume and research scale of this study,the two machine learning models,RF and SVM,were selected for modeling.
The LR model is widely used in predicting fire occurrence probability converts the predicted value of the linear model into the probability value of [0,1] using logit function(Miranda-Aragón et al.2012).If the probability of fire occurrence isP,then the probability of fire not occurring is (1-P).Therefore:
where,β0is a constant,the independent variablesXnare the driving factors of forest fires after selection,βnare the coefficients of individual independent variables.
The glm function of R was used for LR model-fitting and the predict function used to predict the probability of fire occurrence in the validation samples.
The GWLR model is an extension of the LR model and introduces spatial factors.It has overcome the influence of spatial non-stationarity on the prediction model by estimating the parameters on each sample point (Lu et al.2014).[If the probability of fire occurrence isP,then the probability of forest fire not occurring is (1-P).] Therefore:
where,(ui,vi) are the coordinates of thei-th point;β0(ui,vi) is the constant of thei-th point;independent variablesXi1,Xi2,Xi3…Xinare the driving factors of forest fires after screening from thei-th point;βn(ui,vi) are the coefficients of individual independent variables of thei-th point.
The GWLR model was established by Gwmodel S software.The kernel function was set as "gaussian".The bandwidth type was adaptive,and the number of nearest neighbors 297.Parameters of each sample point were estimated,and the Empirical Bayesian Kriging method used to calculate the spatial interpolation of the coefficients to estimate the coefficients in the non-sampling region with no observed values.
The Lasso model is a regularization method that effectively solves multicollinearity and overfitting problems (Tibshirani et al.2005).The coefficients can be compressed by adding a penalty term to the loss function of the traditional regression model (Strobl et al.2012).If the coefficient of an independent variable is compressed to 0,the variable is removed,through which the independent variables can be selected.
where,Plasso(β) is the penalty function,λ the adjustment parameter to control the compression degree of the regression coefficient,βiis thei-th coefficient of the regression model.
The cv.glmnet function of the glmnet package in R was used for Lasso model fitting and the minimum model deviation plus one standard error coefficient was used as the final coeffi-cient of the model.The predict function was used to predict the probability of forest fire occurrence in the validation samples.
The RF model is a machine learning algorithm used for both regression analysis and classification research.It is a combination of tree predictors.It obtains ‘m’ sample sets by randomly conducting ‘m’ times of random replacement sampling from the training samples and builds the tree predictors.For the regression model,the result is determined by the mean of the predicted values from all decision tree models involved,and for a classification problem,the final result is determined by the voting from all decision tree models (Breiman 2001).
The SVM model is a machine learning algorithm proposed by Cortes and Vapnik (1995) based on the Vapnik–Chervonenkis theory and the principle of outcome risk minimization.It is useful in both pattern recognition and function estimation (Cortes and Vapnik 1995).As a classification model,SVM maps data to high-dimensional space through the kernel function and classifies data through constructing an optimal hyperplane.It can be used to solve linearly inseparable problems.
The caret package in R was used to perform variable selection for the RF and SVM models and developed using the randomForest and e1071 packages,respectively.The accuracy of the validation samples was calculated using the predict function.
Model evaluation
Rand Gwmodel S were used to develop prediction models of fire occurrence and Origin was applied to plot the receiver operating characteristic (ROC) curve of each model.Goodness-of-fit was evaluated by the area under curve (AUC)of the ROC curve of each model.The range of AUC was between 0.5 and 1.The greater the AUC,the better the accuracy,sensitivity,and specificity of the model.Youden index was calculated according to the sensitivity and specificity of the ROC curve,the maximum of which was used to determine the cut-off point.The accuracy of the validation samples was also calculated.
Youden index=sensitivity+specificity– 1.
Results
Variable selection
The 17 initial independent variables were screened to reduce the complexity of the model.In LR and GWLR models,independent variables were selected using the step function inRby applying stepwise regression for samples 1–5.In the Lasso model,samples 1 to 5 were fitted using the glmnet package inR,and the cv.glmnet function was used for tenfold cross-validation.The independent variables were selected by the regression coefficient,which was compressed according to the λ value determined as the minimum deviation of the model plus one standard error.In RF and SVM models,the rfe function in the caret package inRwas used to conduct 10-fold cross-validation and screening variables for samples 1–5.The methods “rfFuncs”and “lrFuncs”were used and the results obtained by calling the "optVariables" of the models.Table 2 shows the screening results of independent variables for the five models.
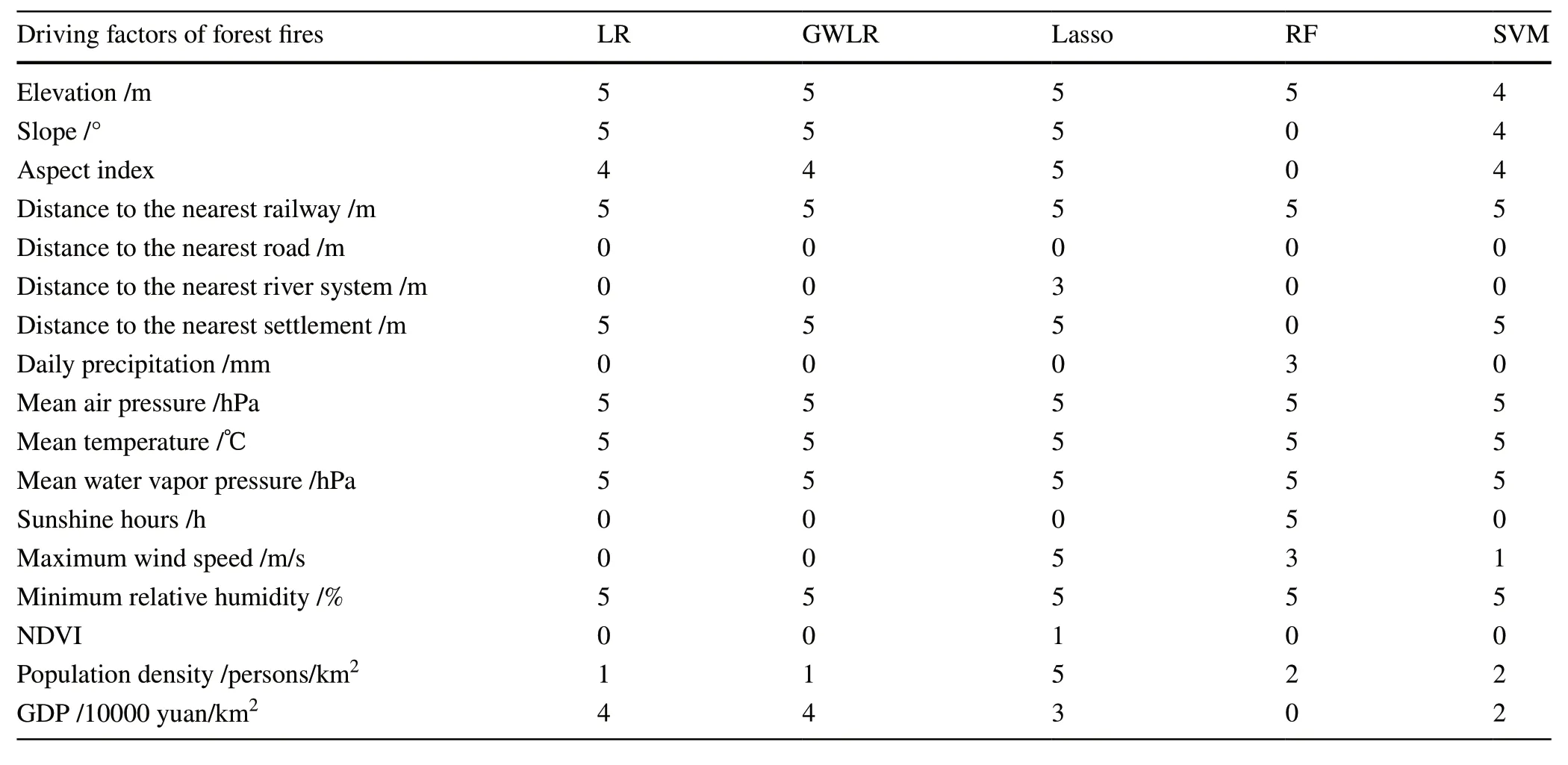
Table 2 Number of independent variable filters entering the model
Prediction of forest fire occurrence probability based on the LR model
The 10 independent variables (elevation,slope,aspect index,distance to nearest railway,distance to nearest settlement,mean air pressure,mean temperature,mean water vapor pressure,minimum relative humidity,and GDP) which passed the variable screening by stepwise regression were used to fit the training samples into the LR model.The result is presented in the following equation.All independent variables passed the significance test (P<0.05).
where,Pis the probability of forest fire occurrence,x1elevation,x2slope,x3aspect index,x4distance to nearest railway,x5distance to nearest settlement,x6mean air pressure,x7mean temperature,x8mean water vapor pressure,x9minimum relative humidity,andx10is GDP.
Prediction of forest fire occurrence probability based on the GWLR model
The independent variable selection process of the GWLR model was the same as that for the LR model,with 10 independent variables selected for modeling with the training samples.Figure 2 shows the spatial distribution of GWLR model coefficients.Among the 10 independent variables and constants,the distance to the nearest railway,mean water vapor pressure,minimum relative humidity and the constants were all negatively correlated with the probability of forest fire occurrence,while mean temperature showed a positive correlation.The distance to the nearest settlement was negatively correlated with the probability of fire occurrence in the west,and the opposite was found in the east.Elevation,slope,aspect index and GDP were positively correlated with the probability of fire occurrence in the west but elevation and slope were negatively correlated in the east.Only aspect index in the northeast was negatively correlated.GDP in most part of the northeast showed negative correlation,but there was a positive correlation in part of south Yanbian.The coefficients corresponding to fire and non-fire points in the validation samples were extracted based on the coordinates,and used to calculate the precision and accuracy of the model.
Prediction of forest fire occurrence probability based on the Lasso model
The 13 independent variables,elevation,slope,aspect index,distance to nearest railway,distance to nearest river system,distance to nearest settlement,mean air pressure,mean temperature,mean water vapor pressure,maximum wind speed,minimum relative humidity,population density and GDP,were selected for modeling in the Lasso model.The cv.glmnet function was used to fit the Lasso regression model to the training samples (Fig.3).λ was 0.000530 at minimum model deviation,and 0.0008635 at minimum model deviation plus one standard error.With an increase of λ,the regression coeffi-cient was gradually compressed.Regression coefficients of the Lasso function at λ=0.008635 were extracted using coef function as the final regression coefficient,and the probability of forest fire occurrence in the validation samples was predicted with the predict function.
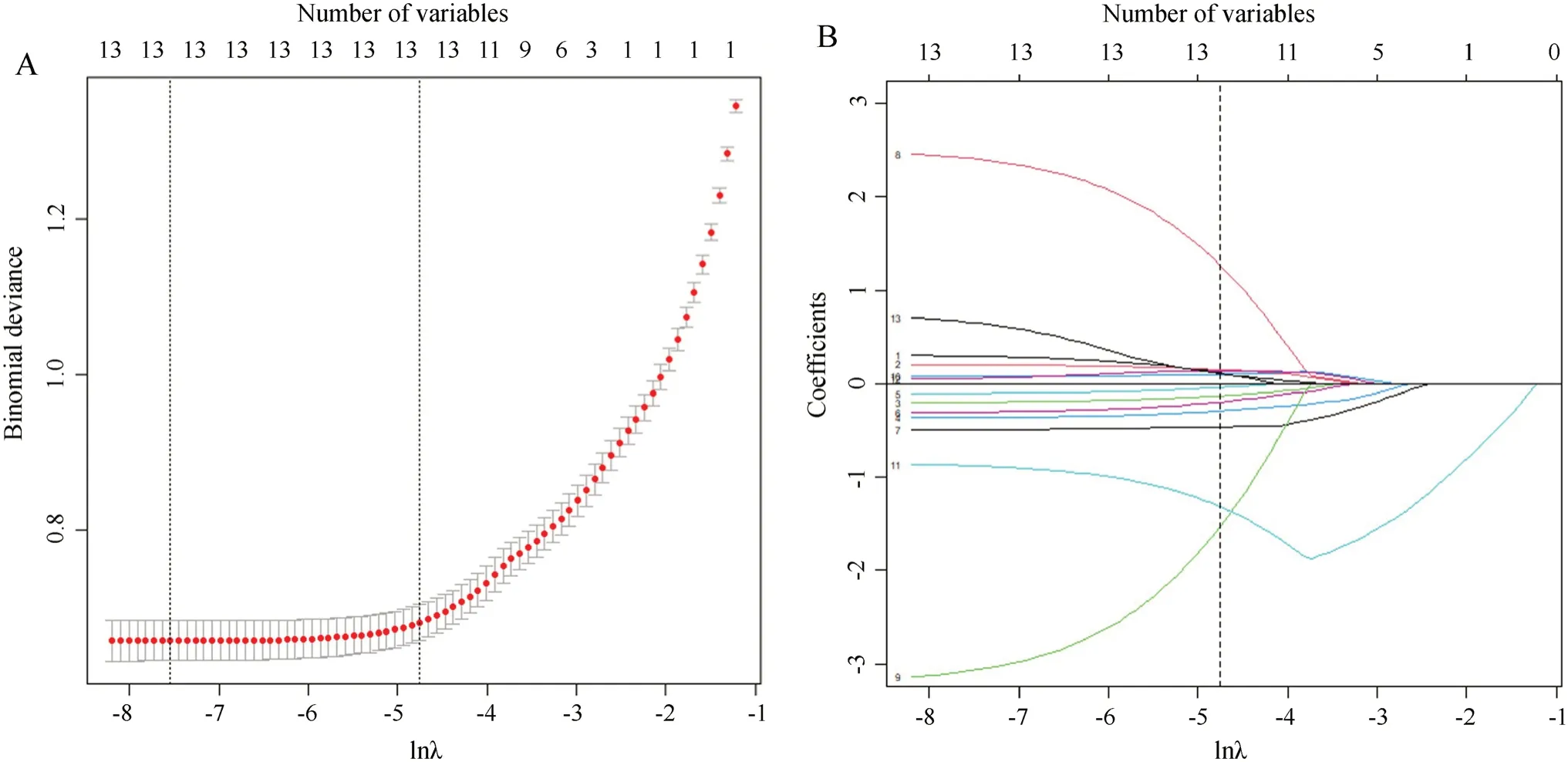
Fig.3 Relationship of deviance and coefficients of Lasso model with lnλ.Note In Figure A two dash lines represent the corresponding lnλ with minimum model division (left),and corresponding lnλ with minimum model division plus one standard error (right).In Figure B,dash line represents the corresponding lnλ with minimum model division plus one standard error,change of the coefficients of x1~ x13 are displayed as curve 1 to 13
The Lasso regression equation is:
where,Pis the probability of forest fire occurrence;x1is elevation;x2is slope;x3is aspect index;x4is distance to nearest railway;x5is distance to nearest river system;x6is distance to nearest settlement;x7is mean air pressure;x8is mean temperature;x9is mean water vapor pressure;x10is maximum wind speed;x11is minimum relative humidity;x12is population density;andx13is GDP.
Prediction of forest ire occurrence probability based on the RF model
The nine independent variables,elevation,distance to nearest railway,daily precipitation,mean air pressure,mean temperature,mean water vapor pressure,sunshine hours,maximum wind speed,minimum relative humidity,were selected for modeling using randomForest package in R.The importance of the model variables was ranked by setting "importance=T",and the probability of forest fires in the validation samples was predicted with the predict function.
Prediction of forest fire occurrence probability based on the SVM model
The nine independent variables,elevation,slope,aspect index,distance to nearest railway,distance to nearest settlement,mean air pressure,mean temperature,mean water vapor pressure,and minimum relative humidity,were selected for modeling using the svm function in e1701 package in R based on the radial basis function kernel.The importance of the model variables was ranked by the fit and importance function in rminer package,and the probability of forest fires in the validation samples was predicted with the predict function.
Analysis of the driving factors of forest fires
The driving factors were analyzed by ranking the importance of variables to the influence of each driving factor on the probability of fire occurrence.Results of LR,Lasso,RF,and SVM models are shown in Fig.4.For the GWLR model,a box plot was used since the odds ratio was not unique.The maximum and minimum values are displayed as the left and right limits,and the mean value as the connecting lines inside the box.From Fig.4,it is seen that meteorological factors,in all models,had the greatest effect on the probability of forest fire occurrence,and the influence of human and social-economic factors,and topography showed little difference.

Fig.4 Ranking of the importance of variables in models
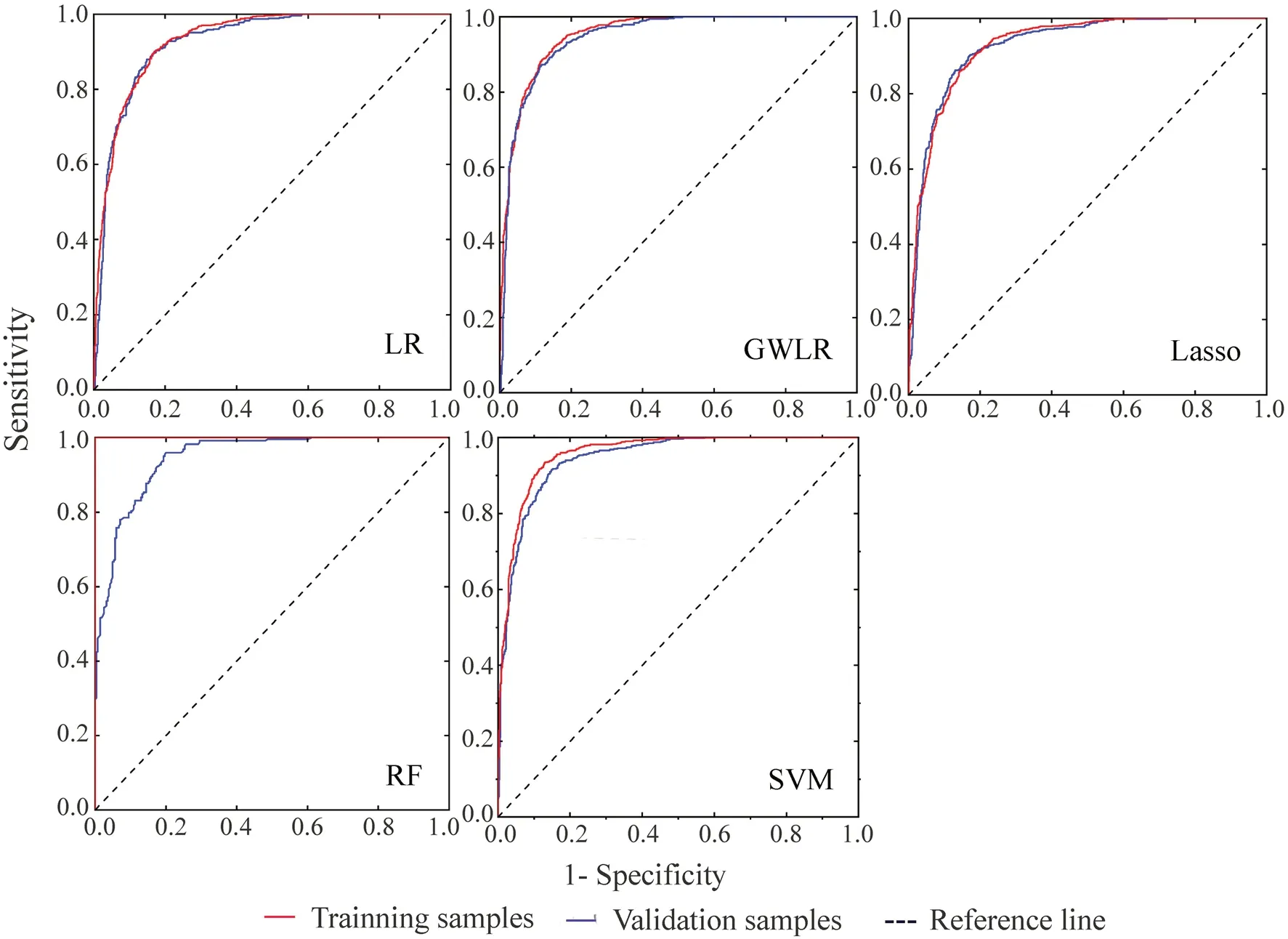
Fig.5 ROC curves of models
Model evaluation
Figure 5 shows the ROC curves of the five models;the AUC values were all larger than 0.9 (Table 3),indicating good performances.Among the models,the fittings of two machine learning models were better than that of the generalized linear regression models,with RF performing better than SVM in the training samples while the two models showed close goodness-of-fit on the validation samples.In the generalized linear regression model,GWLR model had the best fitting on the training samples,followed by the LR model and the Lasso model.Similar goodness-offit were observed when the LR and Lasso models were used to model the validation samples.The Youden index of different models were calculated according to the sensitivity and specificity of the ROC curves.The cut-off value was determined according to the maximum of the Youden index of each model,and the prediction accuracies for the validation samples were calculated.

Table 3 AUC and cut-off values of models
Table 4 shows the prediction accuracies of the five models for the validation samples.The RF model had the highest accuracy of 88.7% and lowest false positive rate (the proportion of non-fire points mistakenly reported as fire points in the validation sample) but it showed highest false negative rate (the proportion of fire points missed and not reported in the validation sample) compared to the other four models.The accuracies of the SVM and GWLR models were 87.7% and 86.0%,respectively,higher than those of the Lasso and LR models.The fitting effect of the Lasso model was slightly lower than the LR model but its accuracy was higher (85.0% and 84.6%,respectively),which could be partially because the Lasso model sacrifices the estimation deviation for better model generalization.In addition,the false positive rates were relatively low in the RF and SVM models but higher in the GWLR,Lasso,and LR models,and the false negative rates were low in the SVM,GWLR,Lasso,and LR models.

Table 4 Accuracies of validation samples of models
Distribution of forest fire occurrence probability
For all the models,the empirical Bayesian kriging method was used to interpolate the probability of fire occurrence.Predictions of the spatial distribution of fire occurrence probability were consistent among the five models (Fig.6).The east and south of Jilin Province is characterized by extensive forests,leading to higher risk of fire occurrence.In addition,the south of Changchun City and the south of Siping City could have forest fires.The two machine learning models,especially the RF model,showed a lower probability of fire occurrence in the western region of Jilin Province such as the Baicheng and Songyuan City.However,LR,GWLR and Lasso models generated higher risk in the same region which may partially result from the high false negative rate of the RF model.

Fig.6 Distribution of forest fire occurrence probability in Jilin Province
Discussion
Discrepancy of models in predicting the probability of forest fire occurrence
Three generalized linear regression models were developed,LR,GWLR and Lasso models,and two machine learning models,RF and SVM models,to predict the probability of forest fire occurrence in Jilin Province based on historical forest fire data in 2000 -2019,and data of topography,climate,vegetation,and human and social-economic data.The results show that the two machine learning models were better in terms of the goodness-of-fit and accuracy,which is consistent with the results from other studies showing that machine learning models were more competitive in prediction (Guo et al.2016b;Milanović et al.2020;Eslami et al.2021) due to their strong data mining capabilities.The RF model has a high tolerance for data outliers,and results are achieved by multiple trees voting,which can effectively reduce the risk of overfitting of the model (Breiman 2001;Wang et al.2015).The SVM performs well in solving linearly inseparable problems with small samples (Cortes and Vapnik 1995) and showed higher accuracy in predicting forest fire occurrence probability.Both models are similarly complex and both include nine independent variables.The RF model was slightly more accurate than the SVM in prediction but had the highest false negative rate (12.7%)among the five models,indicating that it performed better in identifying non-fire points than identifying fire points.Therefore,in forest fire occurrence prediction,the SVM could be chosen for better fire point prediction,although the accuracy is slightly lower.
The two machine learning models have advantages of high accuracy and low complexity.However,the technology of machine learning lacks transparency due to the internal process in the “black-box”(Rudin 2019),which causes relative high complexity in developing software for predicting fire occurrence.The three generalized linear regression models can effectively solve this problem by giving specific parameters of the model which can be directly used to develop software.In the three generalized linear regression models,the LR and Lasso showed close goodness-offit,while LR was less accurate in predicting the validation samples.This may be because the Lasso model sacrifices part of estimation deviation to obtain better generalization(Ranstam and Cook 2018).Therefore,it is more applicable in modeling the validation samples.However,it showed high complexity with 13 variables involved.In contrast,the GWLR model introduced spatial factors to solve the impact of spatial non-stationarity on the prediction (Lu et al.2014),and it showed better fit and higher accuracy than that of the LR and Lasso models.GWLR was simpler with 10 variables,and predicted the probability of forest fires reasonably well.
Driving factors affecting forest fire occurrence
All five models fitted well with the data (AUC >0.9) and were accurate (>80%).The results also show that weather was an important variable,significantly more than topographic,geomorphic,human,and social-economic factors.Seven of nine variables related to climate passed the variable selection in the RF model.Meteorological factors have always been a decisive factor affecting the occurrence of forest fires,and our results are consistent with research by Bisquert et al.(2012),Gibson et al.(2015) and Guo et al.(2016b).Our prediction is more accurate,indicating that meteorological factors can adequately explain the characteristics of forest fire occurrence in Jilin Province.Among various factors,average air pressure and temperature,mean water vapor pressure,and minimum relative humidity were introduced into the models which affect forest fuels.These factors can increase the fuel load and reduce the water content of fuel under certain circumstances;thus they create conditions for the occurrence of forest fires (Kreye et al.2018;Cawson and Duff 2019).
Although the influence of topographic,geomorphic,and human and social-economic factors were lower than that of meteorological factors,they played significant roles.Topography affects the distribution patterns of vegetation and the spread of fire (Cardille et al.2001;Andrews 2018).Solar radiation and vegetation distribution can result in considerable spatial heterogeneity of surface fuels which will affect the occurrence of forest fires (Nyman et al.2015).One of the main causes of forest fires in Jilin Province is anthropogenic activities.These and social-economic factors reflect the distribution of activities in the study area.The more frequent the anthropogenic activity,the greater the probability of human-caused forest fires (Guo et al.2017).Pham et al.(2020) and Mozny et al.(2021) also noted that humanrelated activities had a greater impact on forest fires than climate-related ones.
In addition,fuel is also important to the occurrence of forest fires.However,there are still some difficulties in its application to the prediction of fire occurrence due to difficulties obtaining the characteristics of the fuel type,fuel load and water content of fuels,especially on a large scale.The development of remote sensing technology in recent years has made it possible to obtain some fuel features through indirect factors such as the NDVI data used in this study.The NDVI can be used to represent the type of fuels,though it has not been included in any prediction model in this paper.In future research,we will introduce more factors describing the characteristics of fuels which may improve their accuracy.
Conclusion and management recommendations
The results provide strong support for forest fire prediction and for formulating scientific fire management in Jilin Province.The southeast is mainly mountainous with high forest cover while the west is mainly flat plains.Therefore,areas at high risk of fires are generally distributed in the southeast,with some in the west.The occurrence of forest fires is periodic;there have been no major forest fires in Jilin Province for 42 consecutive years,and consequently a large volume of combustible materials has accumulated.As a result,the risk of large-scale fire outbreak is extremely high.For Yanbian,Tonghua,Baishan and other areas with high fire probabilities,an effective way to reduce fire occurrence is to strictly manage fire ignition sources.Furthermore,air and ground patrols should be strengthened and the distribution of observation towers should be increased to form an airground multi-angle monitoring system.Another effective step would be to reduce the fuel load through hazard reduction burning,clearing forest undergrowth or biodegradation.Since the weather greatly affects the occurrence of forest fires,artificial rainfall,aircraft water dropping,and other methods can be used under extreme conditions of high temperatures and drought to increase fuel moisture and reduce the probability of forest fires.
We suggest to build a forecasting system of fire occurrence based on the existing forest fire risk forecasting system on the basis of meteorological factors to achieve real-time and visualization of fire prediction.The five forest fire prediction models in this study can be used to develop the forecasting system due to their high precision and accuracy as well as to the accessibility of the variables influencing fire occurrence.The two machine learning models showed close and high accuracy,and it is suggested to apply the SVM(the support vector machine model) in system development because of its low false negative rate.However,machine learning has a high requirement on computer skills which may challenge grass-roots fire prevention departments.To overcome such restrictions,it is recommended SVM be substituted with the GWLR (the geographical weighed logistic regression) model because it is relatively highly accurate and has an extremely low false negative rate,and is well capable to predict the probability of forest fire occurrence.
杂志排行

Journal of Forestry Research的其它文章
- Physiological and psychological responses to tended plant communities with varying color characteristics
- Climate‑change habitat shifts for the vulnerable endemic oak species (Quercus arkansana Sarg.)
- Plant growth and metabolism of exotic and native Crotalaria species for mine land rehabilitation in the Amazon
- Peat properties of a tropical forest reserve adjacent to a fire-break canal
- Impact of cattle density on the structure and natural regeneration of a turkey oak stand on an agrosilvopastoral farm in central Italy
- Climate-growth relationships of Pinus tabuliformis along an altitudinal gradient on Baiyunshan Mountain,Central China