基于集群信息熵的分布式网络入侵数据自主防御方法*
2024-01-25赵可英
牟 凯,赵可英
(1.四川商务职业学院 实践教学中心(信息中心),四川 成都 611131;2.内江师范学院 数学与信息科学学院,四川 内江 641100)
分布式网络由于自身的局限性以及开放性等特征,导致遭受攻击的现象频繁发生。尽管当前针对网络攻击的检测以及防御研究已经积累了一定经验,但是与之对应的攻击方式也在不断升级,因此,必须提出更加全面的防御模式,以应对层出不穷的网络攻击。随着网络攻击技术不断演进和复杂化,自主防御研究变得尤为关键。通过深入研究分布式网络入侵的特点和方式,建立先进的威胁识别和防御系统,有助于提高网络的安全性,保护重要数据免受不法分子的侵害。有学者基于弹性搜索,对网络入侵数据防御控制展开研究,将探测器、中央处理器和存储器应用于设计系统中,同时结合采用数据预处理器、入侵规则分析器进行辅助,并通过入侵警报模块和节点控制模块,实时监测网络运行情况,实现对网络入侵数据的自主防御控制[1]。还有研究人员通过隶属度函数(Membership Function, MF)的预检测方法检测网络流量数据的轻量级异常,采用深度学习(Deep Learning, DL)的神经网络模型对异常数据流量进行高精度分类,基于隶属函数检测机制和深度学习检测机制,设计了一种DDoS攻击快速防御方法,并利用Anti-Fre响应算法实现流量定向阻断,完成主动防御[2]。虽然上述方法能够实现入侵数据的自主防御,但是在检测出攻击行为后,通常都是根据节点漏洞之间的关联,匹配出对应的防御规则,从而展开防御响应,导致带宽利用率较高。因此这种单向入侵检测后再触发主动防御属性已经无法满足当前网络发展趋势。
为解决上述方法的不足,本文基于集群信息熵,设计了一种分布式网络入侵数据自主防御方法。集群信息熵作为有监督离散化算法中的重要组成部分,能够集中体现出数据结构的混乱程度。对于入侵数据的检测与自主防御具有重要作用。因此,在集群信息熵的推动下,研究分布式网络入侵数据的自主防御方法具有较高的上升空间。
1 检测分布式网络攻击行为
分布式网络的攻击行为检测作为主动防御的基本依据,具有重要地位。由于在实际应用环境中,大部分攻击代码和攻击手段都比较复杂,单一的检测程序存在漏检和误检的现象。因此,需要详细描述攻击手段的攻击路径以及带来的危害。在僵尸网络攻击类型中,主要是利用服务器与多台计算机之间的紧密联系进行攻击。而当主服务器的职责包括服务器和客户端2种任务时,其被感染后的攻击性会在原有基础上升级。DDoS攻击在发动攻击之前,会先联系主控制器,以获取对应的用户信息,并将正常访问行为反馈给服务器。在这种情形下,服务器通常会采取利用域名变化隐藏IP地址的方式避免被封闭。在此环节引入马尔科夫链算法,建立网络攻击行为规则库。在已知分布式网络攻击样本集的条件下,将历史攻击行为映射到同质马尔科夫链中,则本次攻击行为发生的条件概率数学公式如下:
(1)
其中,s表示攻击行为样本集,m表示前一次的攻击行为,n表示当前攻击行为。由此可知,分布式网络攻击行为具有一定的周期性。在扫描分布式网络和相关设备的过程中,通常情况下检测时间有限,无法实现理想化的检测效果。因此,需要重新建立服务器域名,并适当减少逆向破解环节所消耗的时间。近年来,一次分布式网络攻击行为能够成功模拟用户正常访问行为,并同步上传有关信息。此外,勒索病毒网络攻击频繁地出现在大众视野中,这种攻击行为能够通过DNS查询,采用公钥加密文件的形式,对注册表信息等文件进行破坏,导致无法正常读取文件。在上述描述的基础上,完成检测分布式网络攻击行为的步骤。
2 基于集群信息熵提取流量特征贡献度
集群信息熵作为机器学习算法中的重要体现,主要用于描述数据的概率分布。为了能够快速明确分布式网络流量数据集的特征,将分布式网络入侵数据看作一个随机事件。利用集群熵信息能够总结出不同攻击行为数据集概率分布的相似程度,并以此作为区分是否正常访问行为的判断依据。在能够确定分类标签的基础上,描述主动防御方法中分类模式的熵,具体如下:
(2)
其中,V表示分布式网络流量类别集合,E表示攻击行为记录标签,u表示流量种类。同时,如果出现某项特征与流量类型的匹配度较高时,说明对于准确分类的关联性较大。当攻击行为的条件熵接近于0时,说明集群信息增益更趋近于1。此外,为了计算集群信息熵的增益值,必须充分考虑数据集中包含的连续性特征和离散性特征。受集群信息熵的性质约束,需要将数据集中的连续性特征进行离散化处理。当入侵数据的条件熵的不确定性降低之后,整个数据集的熵值也会随之变小,这也说明流量特征的贡献度趋于稳定[3-4]。而一旦整体分布情况基本固定,流量特征贡献度即可等同于数据集的信息增益。以γ为流量特征,将其取值概率作为计算流量特征贡献度的基础数据,则γ的平均条件熵计算公式为:
(3)
其中,L表示样本数,ϖ表示数据集属性,i表示i个取值。同时,根据集群信息熵的具体分裂点数量,定义分割后的数据集属性,分别为二值离散数据和一阶数据。
3 识别入侵数据多阶段特征
在分布式网络规模逐渐变大的背景下,一些入侵者无法直接连接到攻击目标,可能会与实际情况有一定偏差。而在入侵数据逐渐接近攻击目标的过程中,会伴随着时间流逝呈现出不同的阶段性特征。一旦入侵数据完成渗透攻击环节,其破坏范围则会随之变大。入侵数据实时攻击时,首要步骤就是扫描侦查现有的防御手段,然后制作攻击武器,并锁定目标发动攻击。上述步骤皆属于感染阶段,作为发动攻击的初始时期,入侵数据在该阶段的主要目的就是建立相应的据点,通过定位并追踪可利用的主机,对其投递病毒进行入侵。接下来就进入了利用阶段,具体表现为入侵数据的攻击呈现出横向渗透移动的特点。同时,在主机周围持续探测目标,并利用存在的网络漏洞,展开阶段性渗透。最后对目标数据或者文件信息安装植入病毒,对分布式网络的通信及控制模块发动攻击,从而实现窃取数据资产的目的。同时,将该阶段定义为具体损害阶段,并且攻击者主要是为了对敏感数据进行篡改和盗取。由此得出分布式网络中入侵数据的阶段感知表达公式:
Q=∑(R,Y)+max(γ→Y)
(4)
其中,R表示分布式网络中的主机数量,Y表示当前渗透信息表。将(4)式作为高效准确感知入侵数据攻击阶段的已知条件,生成新的状态转移规则。
4 设计自主防御方法
在主动防御架构中,分布式网络的域名服务日志包含了大部分的正常用户访问行为,在获取用户行为规律以及预测攻击行为等方面具有更好的延伸效果。分布式网络的动态IP地址联动能够以最简单的方式将主动防御的流量导向新的客户端中。在无防御场景中,一些分布式网络主机的IP地址是固定的,且主机中不存在部署指纹伪装主机的情况下,假设入侵数据有ε次扫描机会,在随机扫描的场景中,如果入侵数据满足超几何分布,可以得出攻击成功率的数学表达式为:
(5)
其中,φ表示分布式网络中的地址跳变空间,T表示地址跳变状态持续时间,λ表示每次扫描到主机的概率。从主动防御的角度出发,如果对应的地址跳变周期过小或者过大,都无法实现主动防御的最佳效果。因此,在分布式网络正常运行的状态下,保证主动防御状态下的分布式网络最小跳变间隔周期小于攻击分析时间。在实际的主动防御场景中,可以采取主动指纹伪装机制。为了避免流量牵引策略引起入侵数据的怀疑,将伪装源IP地址的方法进行优化升级[7]。除了将防火墙设置在分布式网络的内部和外部的中间地带之外,还可以设置多个具有相同功能的访问控制代理,以增强主动防御方法的抗攻击能力。在此种布置下,入侵数据等攻击者的识别概率可以表示为:
(6)
其中,σ表示入侵数据的初始攻击能力,k表示入侵数据的学习能力线性系数,ψ表示指纹伪装主机的相似系数。通过掌握入侵数据的攻击能力,并对其攻击时间进行预测,从而制定合理的主动防御策略。由于在实际网络攻防过程中存在一定的不确定因素,因此,必须将分布式网络中的数据加以离散化处理,直至符合集群信息熵的增益阈值。
5 仿真实验
5.1 部署实验环境
集群信息熵的开发工具为Python软件,包括Mininet平台、OpenvSwitch交换机和Ryu控制器,然后利用实验工具搭建具体的SDN网络拓扑。电脑的配置为:Windows10操作系统,CPU为Intel(R) Core(TM) i5-7500,内存为SamsungDDR4 4GB。并配置CPU为Intel(R) Core(TM) i5-7500,内存为DDR4 16GB,系统为Ubuntu 18.04 LTS的主机。
5.2 分析实验结果
为了得出准确度较高的测试结果,采用基于弹性搜索的网络入侵数据防御方法[1]和基于MF-DL的DDoS攻击快速防御方法[2]与本文的分布式网络入侵数据自主防御方法进行对比参照。由于带宽利用率直接影响分布式网络的性能,因此本次仿真实验将带宽利用率作为测试指标。而在实际场景中,过高的带宽利用率会造成网络堵塞,因此网络带宽利用率正常需保持在30%以下。3种网络入侵数据自主防御方法的带宽利用率越低,证明主动防御效果越好。分别测试在UDP Flood和U2R攻击类型下3种方法的带宽利用率变化,具体如图1和图2所示。
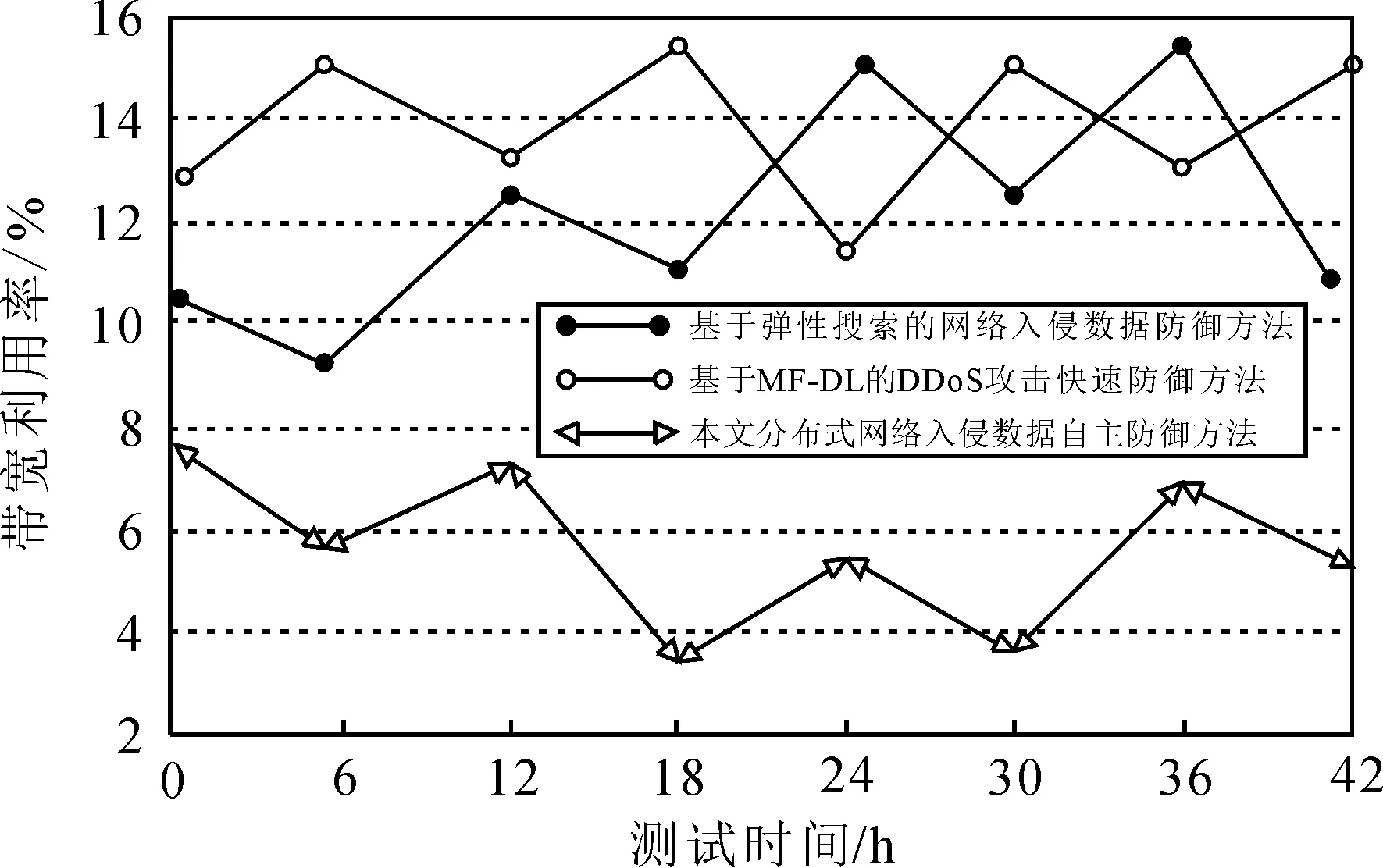
图1 UDP Flood攻击带宽利用率Fig. 1 UDP Flood attack bandwidth utilization
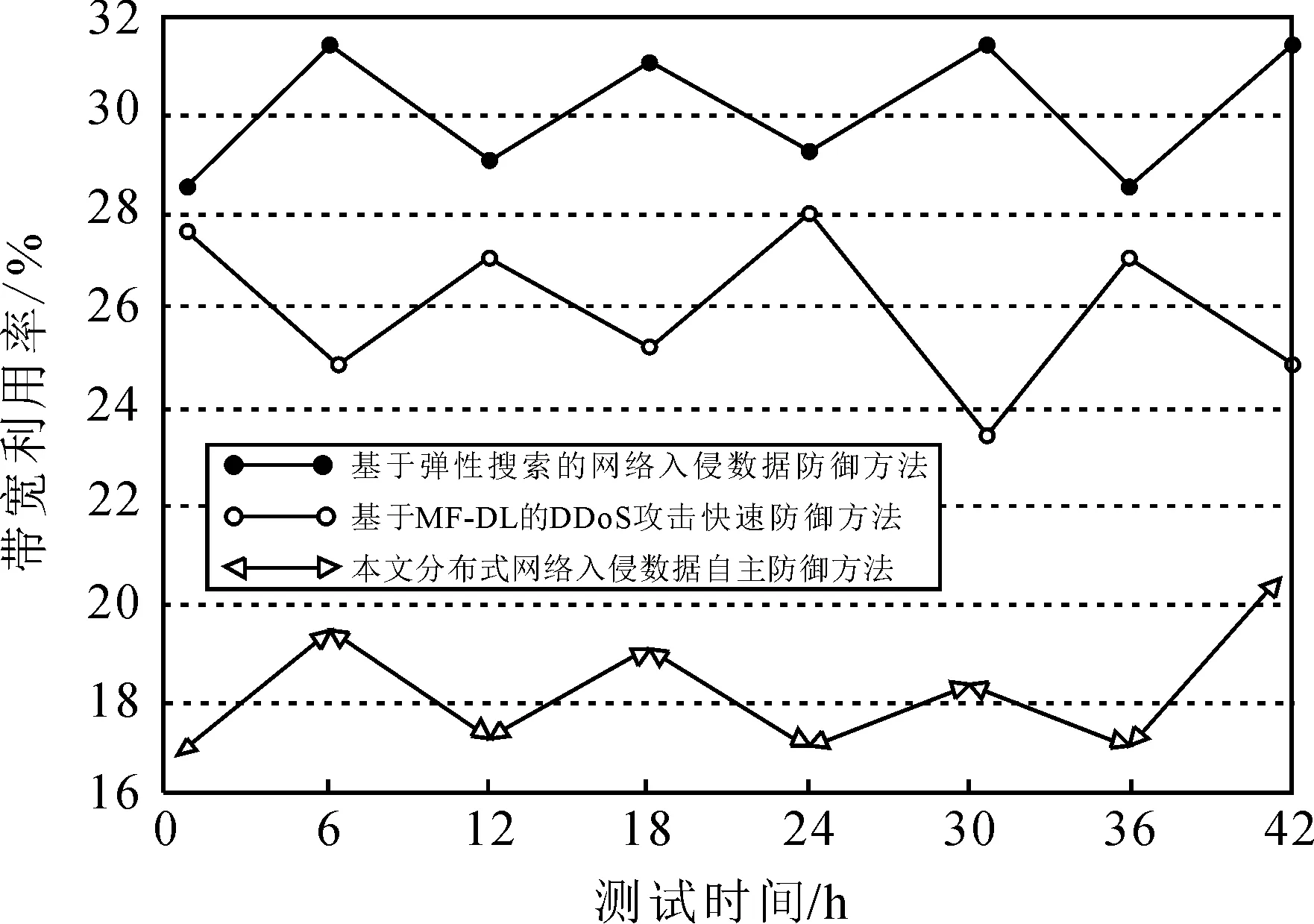
图2 U2R攻击带宽利用率Fig. 2 U2R attack bandwidth utilization
可以看出,UDP Flood攻击相对来说比较容易检测并采取防御措施,因此,整体带宽利用率较低。而U2R攻击类型隐蔽性则更强,3种网络入侵数据自主防御方法的带宽利用率均有所升高。
3种网络入侵数据自主防御方法的带宽利用率均值如表1所示。

表1 带宽利用率均值/%Tab. 1 Average bandwidth utilization/%
根据表1可知,本文的分布式网络入侵数据自主防御方法的带宽利用率均值为14.276%,基于弹性搜索的网络入侵数据防御方法的带宽利用率均值为17.324%,基于MF-DL的DDoS攻击快速防御方法的带宽利用率均值为17.210%。本文设计方法的带宽利用率低于对比方法,具有较好的自主防御效果,在实际应用中具有较好的性能。
6 结束语
为解决现有方法在入侵数据自主防御过程中存在带宽利用率较高的不足,本文基于集群信息熵设计了一种分布式网络入侵数据自主防御方法。对分布式网络攻击行为进行检测,基于集群信息熵提取流量特征贡献度并识别入侵数据多阶段特征,通过主动指纹伪装机制实现分布式网络入侵数据自主防御。实验证明,该方法的带宽利用率较低,均值仅为14.276%,具有较好的应用性能。在未来的研究中还将重点关注入侵数据的更多类型,逐步完善设计方法,提高网络的防护能力,保护网络数据的安全性和完整性,为数据安全和关键信息资产的安全提供技术支持。
