基于机器学习方法的空气质量预测与影响因素识别
2024-01-24李佳成梁龙跃
李佳成,梁龙跃,2
(1.贵州大学 经济学院,贵州 贵阳 550025;2.贵州大学 马克思主义经济学发展与应用研究中心,贵州 贵阳 550025)
1 引言及文献综述
改革开放以来,随着中国工业、制造业和城市化进程的飞速发展,空气质量受到严重污染。空气中的污染物主要包括二氧化硫(SO2)、一氧化碳(CO)、二氧化氮(NO2)、臭氧(O3)等气体污染物以及PM2.5和PM10等小型可吸入颗粒污染物,对身体健康和生态环境具有严重危害(吴春芳等,2021[1])。党和国家一直高度重视空气质量污染问题,“十四五”规划明确指出要深入打好污染防治攻坚战,建立健全环境治理体系,不断改善空气质量。党的二十大报告指出要广泛形成绿色生产生活方式,碳排放达峰后稳中有降,生态环境根本好转,美丽中国目标基本实现。因此,对空气质量进行精准预测并识别其影响因素,对区域空气质量治理具有前瞻性和针对性的指导意义。
空气质量问题长期受学者的关注,研究范围主要涉及空气质量预测和影响因素分析两个方面。空气质量预测主要采取数值预测模型、统计预报模型和机器学习模型。数值预测模型预测精度高,现用于国内多个城市环境监测中心,但其专业性要求高,各模型适用范围单一(王自发等,2006[2];王哲等,2014[3])。统计预报模型在国内外均有应用,但受线性统计关系限制,难以模拟复杂多变的大气污染变化(沈劲等,2015[4];Bai等,2016[5])。机器学习模型能够解决统计模型的非线性问题,具有较高预测精度和较强泛化能力等优点(杨思琦等,2017[6];陈建坤等,2022[7]),深度学习模型属于机器学习方法的一种,预测精度高,但存在模型结构复杂、解释性较差等不足(李栋等,2020[8];蒲国林等,2018[9])。空气质量影响因素现有大量研究,有学者在全国层面上运用回归模型研究不同城市的空气质量影响因素(陈永林等,2015[10];赵艳艳,2021[11]),有学者运用统计学和OLS方法研究城市群层面上的空气质量影响因素(李慧等,2021[12];金自恒等,2022[13]),还有学者在省级(直辖市)层面上运用空间计量和面板计量方法探究空气质量影响因素(刘利等,2021[14];丁镭等,2016[15])。上述学者大多基于计量方法分析空气质量影响因素,也有少量学者选用机器学习算法分析大气能见度和PM2.5浓度影响因素(张杨等,2021[16];夏晓圣等,2020[17]),但大多依据单个机器学习模型计算结果进行分析,极可能出现计算结果稳健性较差的情况。该文将多种机器学习算法与特征稳定性选择方法相结合,定量研究多个影响因素对空气质量的贡献。
文章的贡献主要有以下三个方面:(1)将空气质量预测和影响因素分析相结合,弥补现有研究中空气质量预测和影响因素单独研究的不足;(2)选用预测精度高的决策树(Decision Tree,DT)、随机森林(Random Forest,RF)、梯度提升决策树(Gradient Boosting Decision Tree,GBDT)和极端梯度提升(Extreme Gradient Boosting,XGBoost)模型预测北京市空气质量;(3)将Meinshausen和Bühlmann(2010)[18]提出的稳定性选择方法和机器学习相结合,首次将该方法运用于空气质量影响因素定量研究中,为北京市政府和环境保护部门改善空气质量提供有效建议。
2 研究方法及模型构建
现有文献针对空气质量影响因素分析大多采用计量的回归方法度量,其计算结果可能和真实结果有较大差异;此外也有学者选用机器学习算法中的树类模型方法(Ng,2014[19]),因为树类模型不仅能考虑较多变量,并且能够直接算出变量的特征重要性,具有较高预测精度。但是如果只基于单个方法计算结果得出变量重要性,容易出现结果稳健性较差的情况。基于此,文章采用多种机器学习方法对空气质量进行预测,并将机器学习方法作为稳定性选择算法的基模型,定量识别多个因素对空气质量影响。
2.1 机器学习方法选择和介绍
考虑到深度学习方法虽然具有较高的预测精度,但存在模型原理复杂、解释能力弱等不足,为了实现空气质量预测和定量识别其影响因素,选择DT,RF,GBDT和XGBoost四种机器方法对AQI进行预测,并将其作为稳定性选择算法的基模型定性分析空气质量影响因素,接下来逐一介绍模型和算法。
DT是一种非参数的有监督学习算法,一般具有运行速度快,无需对参数做假设等优点;但也存在容易过拟合,计算结果方差偏大等缺点。RF由Breiman(2010)[20]提出,是重抽样自举法的集成学习方法的一种,主要用于分类及回归分析,具有训练速度快和预测精度高的优点,但也存在噪声过大,造成回归过程中产生过拟合的可能。GBDT是Hastie 等(2009)[21]提出的一种基于梯度提升树的集成算法,具有并行运算、复杂度可控、泛化能力强的优点,但也存在训练阶段为串行结构速度较慢的不足。XGBoost是Chen和Guestrin(2016)[22]提出的集成方法,是对传统GBDT的提升和优化,属于Boosting集成学习算法,具有预测精度高、不易过拟合和扩展性强等优点,但也存在对噪声敏感和训练时间较长等不足。
2.2 模型最优参数
机器学习建模和预测分析过程中,模型参数对模型的预测效果及性能具有重要影响,采取时间序列交叉验证和网格搜索方法选择模型的最优参数,得出最佳预测效果。具体方法如图1所示。
文章选取时间序列递增窗口的方式。假设原始数据具有100个样本,先将数据集划分为训练集(前80个样本)及测试集(后20个样本),训练集用于交叉验证网格搜索调参,按比例分别被划分为训练子集和验证子集,验证子集用于评估模型性能,测试集作为测试集保留,不用于交叉验证过程,避免最终预测时数据提前“泄露”。在此过程中模型会将各个参数可能的取值进行排列组合,列出所有可能的组合结果,生成“网格”之后再选定使均方误差最小的参数组合作为该方法的最优参数。
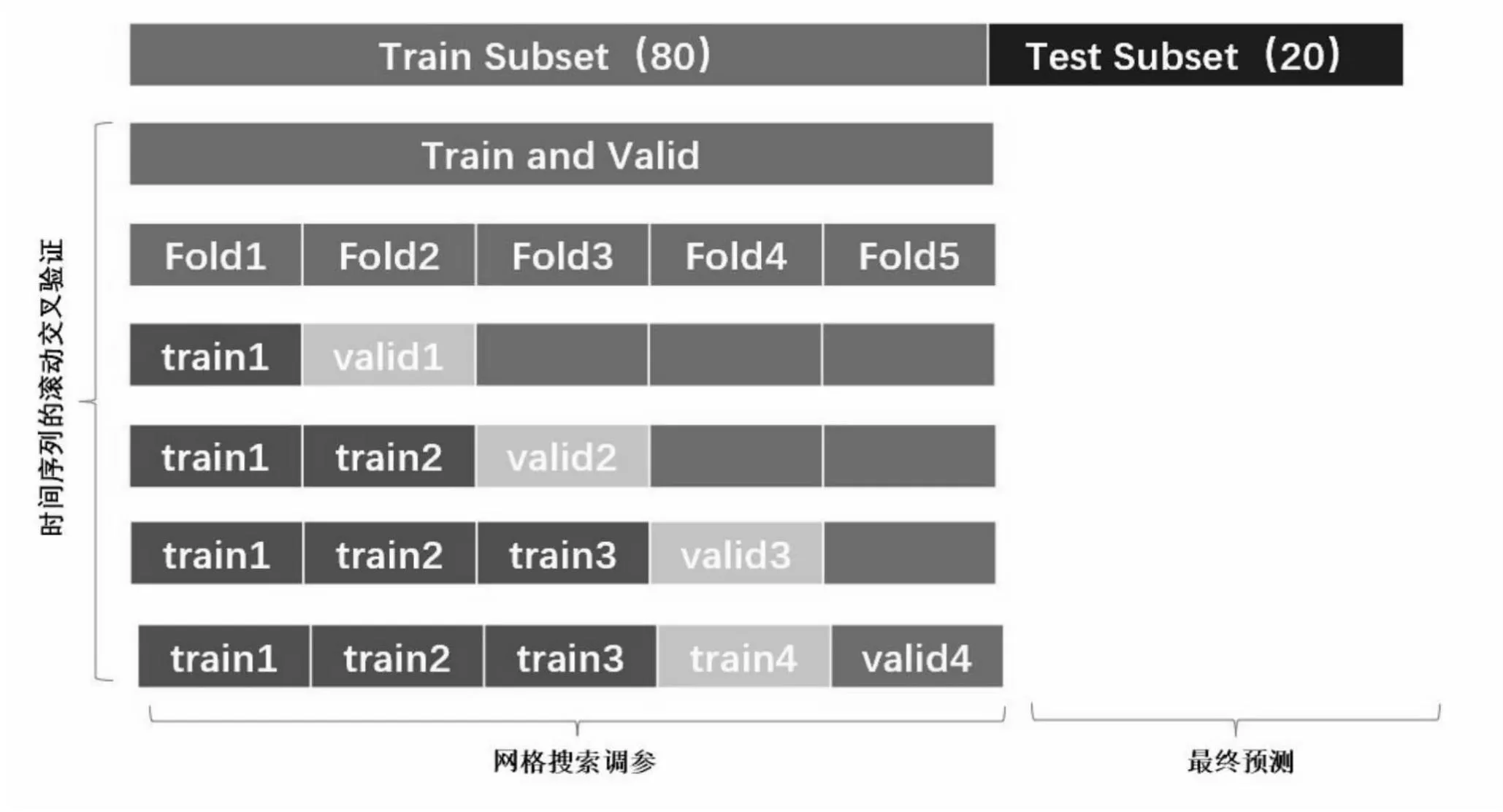
图1 交叉验证和网格搜索方法
通过运用交叉验证和网格搜索方法,对DT,RF,GBDT和XGBoost模型的超参数分别进行运算,得到各个模型的最优参数。其中,DT最优参数中最大深度=15,最大叶子节点数=5,叶子节点最少样本数=1;RF最优参数中最大深度=5,弱学习器个数=200,GBDT最优参数中最大深度=15,弱学习器个数=500,学习率=0.5,随机采样比例=0.7;XGBoost最优参数中最大深度=10,弱学习器个数=150,学习率=0.05,随机采样比例=0.8。
2.3 评价指标选取
为了客观衡量四种非线性机器学习算法的预测性能,采用均方根误差(Root Mean Square Error,RMSE)、平均绝对误差(Mean Absolute Error,MAE)以及精度(Direction Accuracy,DA)作为模型模拟结果与实际值吻合程度的衡量指标,其中RMSE与MAE值越小表明模型预测效果越好,DA值越大表明模型性能越好,DA表示模型在预测趋势上的准确性。各评估指标数学表达式如下:
(1)
(2)
(3)

2.4 稳定性选择方法计算空气质量影响因素
稳定性选择方法是Meinshausen和Bühlmann(2010)[18]提出的,主要思想是利用重采样技术抽取不同的数据子集,然后对数据子集进行训练,得到多个变量的筛选结果,利用这些结果计算出各个特征的重要性大小。稳定性选择方法是采用重采样的思想,根据重采样得到的多个样本训练多个模型,因此最后集成的重要性排序结果要比单个模型的更优,理论上能够得到更加稳健的结果。
鉴于此,文章使用稳定性选择方法计算污染物、气象因素和经济因素对空气质量的重要性得分,下面介绍算法过程。
稳定性选择算法:
输入:
(X,y):训练数据集,其中X∈Rn*p,y∈Rn*1;
M:集成的大小;
Estimator:模型方法;
Λ:模型的N(文中N=50)个正则化参数组成的集合,即Λ={λ1,λ2,…,λN};
πthr:预先设定的阈值;
输出:选择变量的指标集Sstable
稳定性选择算法的主要步骤为:
1.For =1,2,…,M
a.从(X,y)样本集中进行有放回随机抽样,以生成样本量为n/2的子集(X(m),y(m))
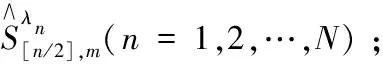
For循环结束
2.计算影响因素被选为重要变量的概率:
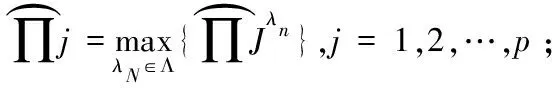
3.确定最后的选择集
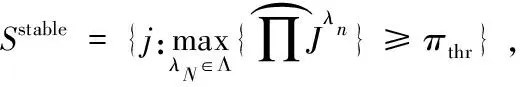
稳定性选择的具体做法是通过计算单个因素在空气质量影响因素集合中被选出的次数,从而计算每个因素的重要性得分,由于稳定性选择模型能够自动识别重要性强弱的因素,因此重要性强的影响因素会有更大的概率被选中,所以其得分会接近重采样的次数N,即50分;重要性相对较弱的影响因素得分会介于0至50分之间,而不相关的影响因素分数则接近0分,最后对每个因素的贡献率大小进行排序,即可确定空气质量的重要影响因素。
3 数据来源及预处理
3.1 数据来源
文章使用的六大污染物(SO2,CO,NO2,O3,PM2.5和PM10)以及AQI来源于中国空气质量在线监测分析平台(https://www.aqistudy.cn),气象数据(平均温度、风速、湿度、气压和降雨量)来源于慧聚数据网(http://hz.hjhj-e.com),经济数据来源于北京市统计年鉴和同花顺iFinD数据库。
变量说明见表1。
3.2 数据标准化处理
考虑不同指标的量纲不同,为提升模型拟合精度,文章对数据进行最大最小标准化处理,将数据置于统一量纲之中,其公式表示为:
(4)
其中,X表示某列原始数据,Xmax和Xmin分别为该列数据的最大值和最小值,X*表示归一化后获取的新数据,经过该方法处理的数据将被映射到[0,1]之间。
4 实证结果分析
4.1 预测效果分析
文章采取DT,RF,GBDT和XGBoost回归算法对AQI数值进行预测,以2014年第一季度至2020年第四季度时间段作为训练集,2021年第一季度至2022年第二季度数据为测试集,经过时间序列的交叉验证和网格调参选出最优参数,然后进行预测,根据预测结果得出两条结论:(1)四种机器学习算法都具有良好的预测性能,其预测结果的RMSE值分别为0.171,0.155,0.169和0.153;MAE值分别为0.140,0.127,0.125和0.119;DA值分别为0.6,1.0,0.8和1.0。(2)在四种机器学习算法中,XGBoost和RF在预测效果上优于DT和GBDT。
4.2 稳定性选择算法对AQI影响因素定量识别
文章以四种机器学习方法作为稳定性选择算法的基模型,运用python定量识别六大污染物、气象因素和经济因素(参见表1)对空气质量的影响,具体影响效果为各个变量对AQI的贡献率大小,参考四种机器学习方法预测效果,其中RF和XGBoost两种模型的预测效果最优,因此将着重分析RF和XGBoost两种模型所计算的各个影响因素对AQI的平均贡献率(下文简称两种模型),同时为了保证结果更加稳健可靠,还将DT,RF,GBDT,XGBoost 四种模型的计算结果取平均值作为对照。下面分别讨论六大污染物、气象因素和经济因素对AQI的贡献率。
4.2.1 六大污染物对AQI的贡献
首先,分析六大污染物对AQI的贡献,其中两种模型对AQI的平均贡献率大小如表2所示,四种模型作为对照,具体结果如表2所示。
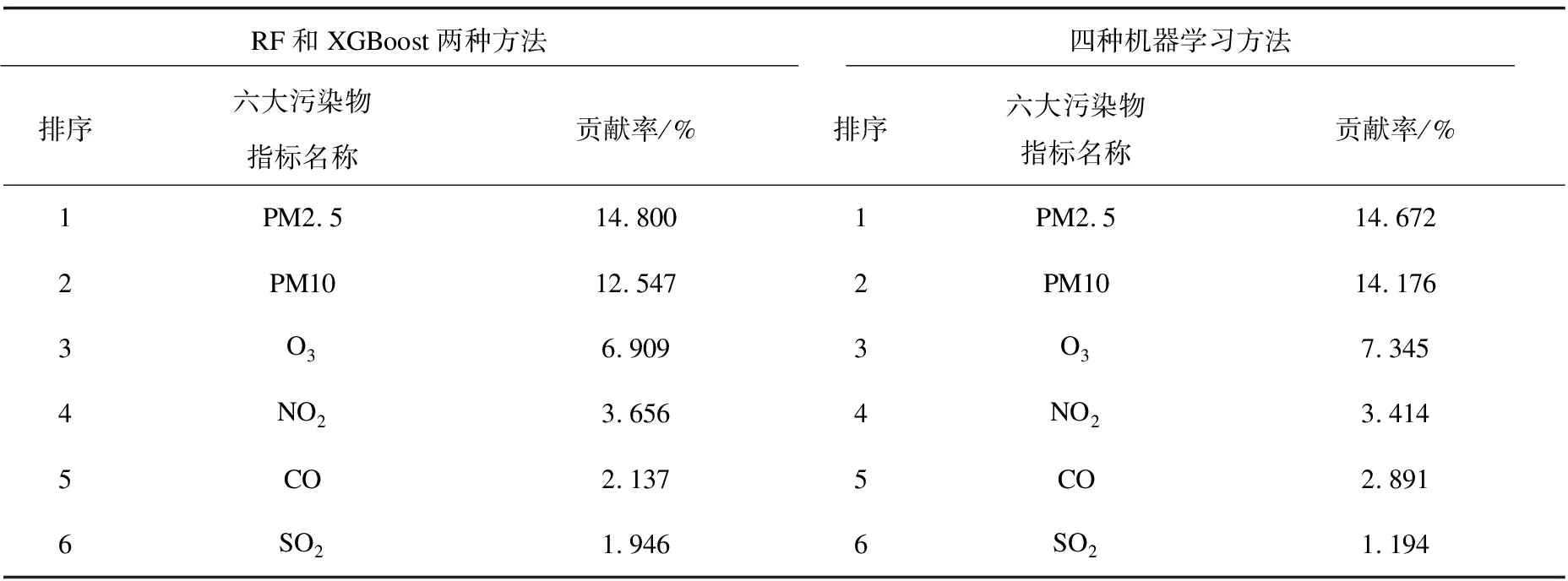
表2 污染物对空气质量的影响及其贡献率
如表2所示,六大污染物对AQI的贡献率排名分别是PM2.5,PM10,O3,NO2,CO,SO2,其中PM2.5和PM10的贡献之和达到27.35%。PM2.5和PM10属于小型颗粒污染物,均为AQI的主要影响因素;当AQI较大时,PM2.5和PM10数值也呈现较高的状态,空气会出现污染状态,北京市可能伴随雾霾和沙尘暴,对人们出行和身体健康具有重大危害。O3,NO2,SO2和CO作为气体污染物,对AQI的影响之和为14.65%,也是现阶段国内面临的污染难题之一,需要针对各自污染源进行逐一解决。将表2的平均结果进行对比,所得结论也基本相同。
4.2.2 气象因素对AQI的贡献
气象条件作为一种自然因素,对空气质量也具有重要影响。有学者研究表明AQI与风速、气温、湿度以及降雨量呈负相关,与气压呈正相关(何振芳等,2021[23],周兆媛等,2014[24])。文章分析气象因素对AQI的贡献,选择两种模型对AQI的平均贡献率进行分析,四种机器学习方法结果作为对照,如表3所示。
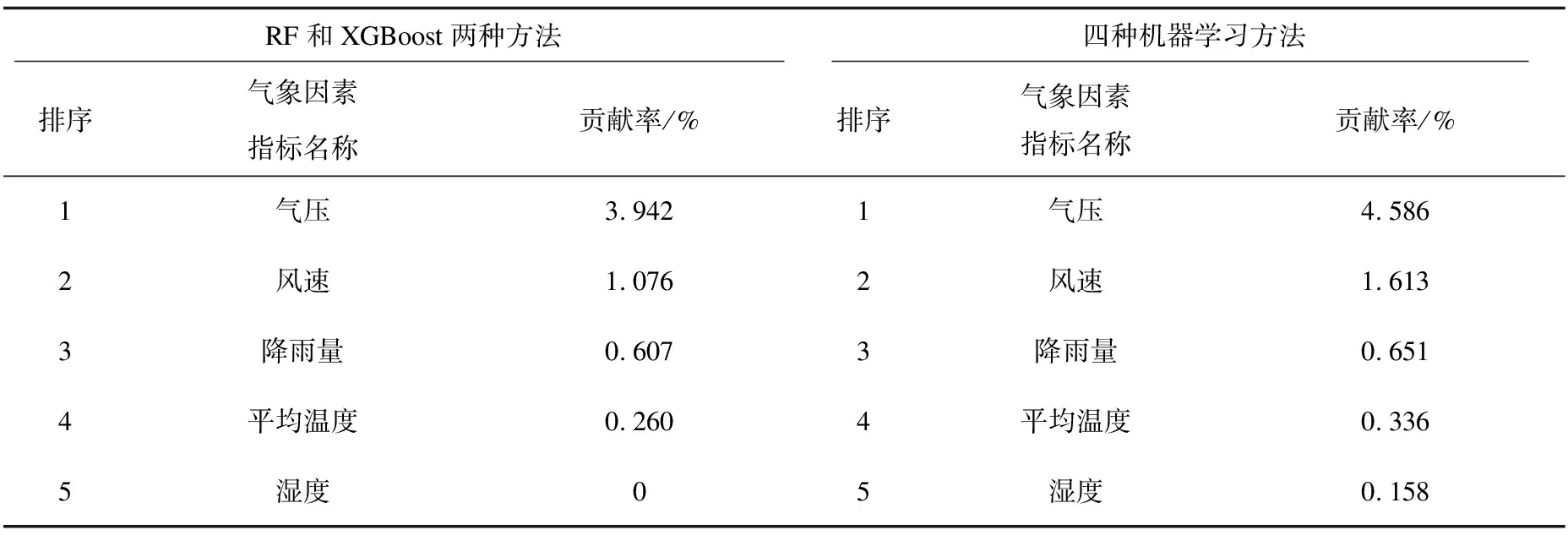
表3 气象因素对空气质量的影响及其贡献率
如表3所示,气象因素对AQI贡献率之和为5.88%,其中气压和风速对AQI贡献率在五个气象因素中最高,分别为3.94%和1.08%,其原因可能有以下两个方面:(1)选取的季度数据中,气压数据的均值为1 012.14,其标准差为8.12,气压值波动平缓并且其值高于标准气压值,导致气压对AQI贡献较大;(2)北京市地处平原,夏季和冬季风大,有利于AQI挥发,所以对AQI影响较大。剩余三个气象因素对AQI贡献较低的原因如下:①选取平均温度,其值低于白天平均温度,并且每日平均温度波动较小,导致模型较难识别其重要性,所以贡献率较低;②湿度对AQI的影响主要是通过影响降雨来降低AQI,而北京市近几年季度降雨量均值较小,导致贡献率也比较低。对比四种机器学习方法,结果也类似。
4.2.3 经济因素对AQI的贡献
经济建设与环境保护协调发展是国家一直以来遵循的原则,定量识别经济因素对空气质量的影响,为空气质量改善提出有效建议具有重大的现实意义。文章分析经济因素对AQI的贡献,选择两种机器学习算法对AQI的平均贡献率进行分析,四种算法结果作为对照,结果如表4所示。从表4可以看出,空气质量影响因素的前七个经济变量分别为城镇居民人均可支配收入、第三产业GDP、规模以上工业总产值、北京市GDP、第二产业GDP、社会消费品零售总额和公路旅客运输量,其贡献率分别是12.80%、8.14%、6.28%、6.12%、5.16%、4.53%和3.47%。
对空气质量影响最重要的是城镇居民人均可支配收入,有学者研究发现随着北京市居民收入提高,空气质量改善(王会等,2018[25]);第三产业GDP对空气质量影响次之,其GDP值越高,越能改善空气质量状况;北京市规模以上工业总产值和北京市GDP也是影响空气质量的重要因素之一,但北京市工业在2013年已经进入后工业化时代,其工业主要为偏高端的污染相对较小的产业类型,因此其规模以上工业总产值越大,越能改善空气质量状况(王丽,2021[26]),也有学者研究指出北京市已进入经济与环境协调发展后期阶段,随着北京市GDP的不断增加,空气质量会不断改善(吴玉萍等,2002[27]);第二产业主要指加工制造业等企业,通常消耗大量能源并排放污染气体,是导致北京市空气质量恶化的重要影响因素,政府应该对第二产业的发展与排污进行重点审核,倒逼企业向绿色可持续发展转型;社会消费品零售总额主要包括社会生活消费品,其值越大,表明社会零售商品生产消耗越大,对北京市空气质量具有严重危害;公路旅客运输量和公路货物运输量可代表北京市公路运输状况,公路运输会消耗大量化石能源并排放尾气,是导致空气质量污染的重要原因;建筑业企业在施工过程中会导致废水、粉尘和废弃物等污染物,建筑业企业:签订合同额越大,对北京市空气质量的污染就越严重,政府应该重点管控该行业的污染排放;金融业是指经营金融商品的特殊行业,一般不会造成空气质量污染;此外房地产开发投资、进出口、一般公共预算支出和第一产业均会对北京市AQI造成一定的影响,由于定量分析中这几个经济变量对AQI影响较小,因此不在一一展开论述。对比四种机器学习方法的平均结果,各个经济因素对北京市AQI影响与RF和XGBoost两种方法的结果相似,表明结果稳健可靠。
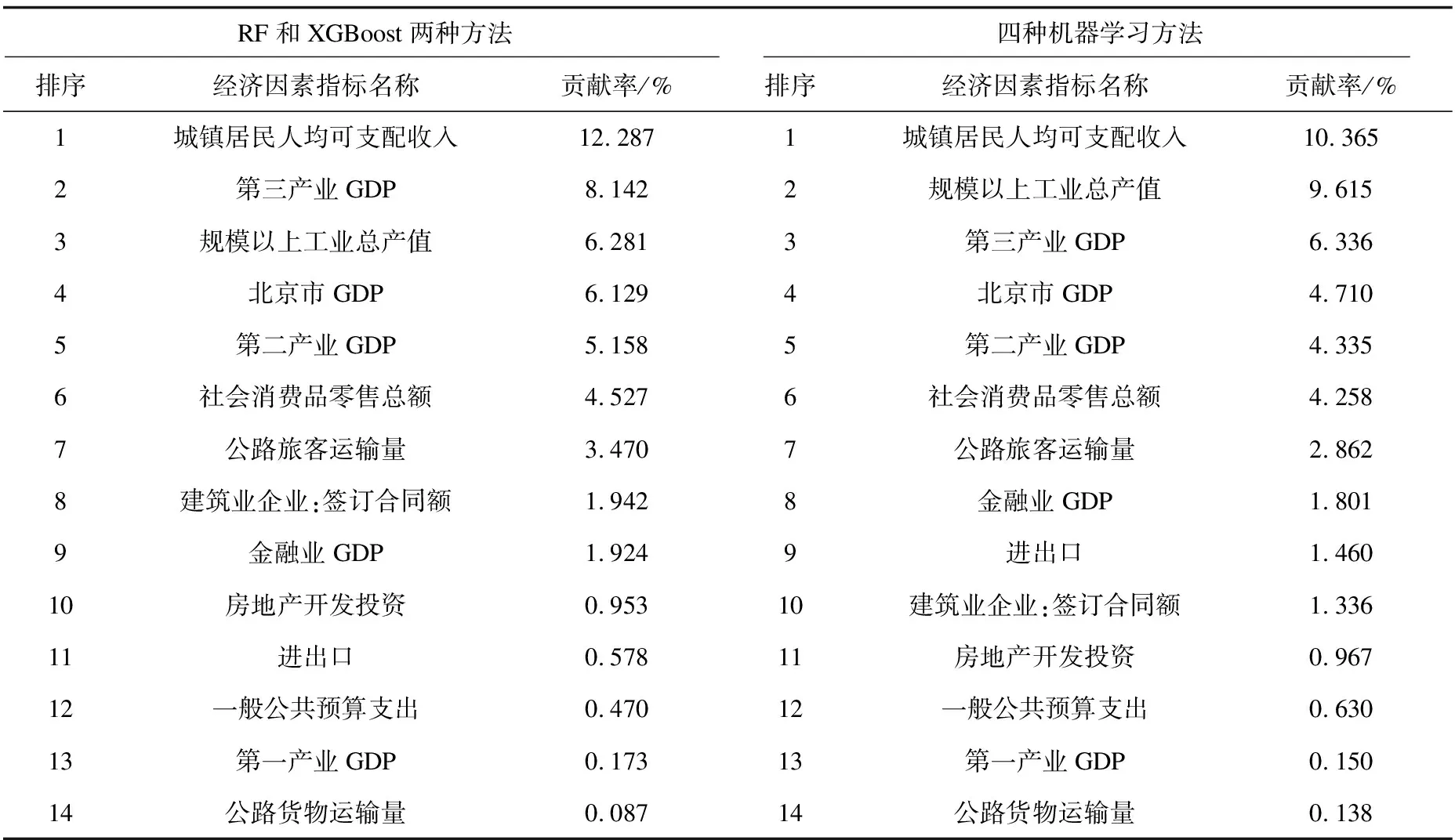
表4 经济因素对空气质量的影响及其贡献率
5 结论及建议
5.1 结 论
(1)在空气质量预测中,选用DT,RF,GBDT和XGBoost模型,经过时间序列交叉验证和网格调参选取了模型的最优超参数对北京市AQI进行预测,四种机器学习算法均表现出良好的预测性能,RMSE值均低于0.172,MAE值均低于0.141,DA值高于0.6。
(2)六大污染物对空气质量的影响较大,RF和XGBoost方法计算六大污染物对空气质量的平均贡献率为42.00%,PM2.5和PM10的贡献率分别为27.35%和28.85%,气象因素中气压和风速对空气质量影响分别为3.94%和1.08%,对AQI的影响较大。
(3)经济因素在两种方法计算中对空气质量影响的贡献率为52.12%,其中城镇居民人均可支配收入、第三产业GDP、规模以上工业总产值、北京市GDP、第二产业GDP和社会消费品零售总额和公路旅客运输量是空气质量重要影响因素(四种机器学习方法结果类似),其贡献率之和为46%,是北京市政府改善空气质量的重点关注对象。
5.2 政策建议
(1)高度重视高能耗、高污染行业的发展。实证结果表明建筑业企业和第二产业GDP对北京市空气质量具有重要影响,北京市政府应合理规划市内建筑业企业和第二产业的空间布局,因地制宜推进企业进入产业园区,集中建设污染排放处理设备,推进企业转向绿色可持续发展,倒逼企业结构升级转型,改善北京市空气质量(倪琳和郭小雨,2022[28])。
(2)充分发挥“有为政府”职能,推动北京市经济发展。实证结果表明,城镇居民人均可支配收入、第三产业GDP、北京市GDP和金融业GDP对空气质量具有重要影响作用。北京市政府应立足北京市发展现状和发展优势条件,大力推进地区经济发展,针对第三产业、金融业和规模以上工业等提供一系列发展政策和方针,提高北京市GDP和人均可支配收入,达到改善空气质量的目的(Hao 等,2020[29];陈文和王晨宇,2021[30];周侗等,2022[31];王会等,2018[25])。
(3)优化交通运输。实证结果表明公路旅客运输量和公路货物运输量对于北京市AQI具有重要影响。北京市机动车大多行驶在城市人口密集区域,容易造成城市拥堵,进一步增加机动车能源消耗并增加汽车尾气排放,导致城市空气质量恶化(Lu等,2017[32])。北京市政府应优化交通运输现状,大力推广新能源汽车,全市除公交车采用新能源汽车外,鼓励企事业单位购买新能源车辆;对个人和家庭提高新能源汽车购买补贴,减少汽车化石能源消费,改善空气质量。
