基于注意力的循环PPO算法及其应用
2024-01-24吕相霖臧兆祥李思博王俊英
吕相霖,臧兆祥,李思博,王俊英
(1.三峡大学 水电工程智能视觉监测湖北省重点实验室,湖北 宜昌 443002;2.三峡大学 计算机与信息学院,湖北 宜昌 443002)
0 引 言
未知环境中的智能决策过程又称为部分可观测马尔可夫决策过程(POMDP),智能体通过掌握局部环境的观测信息进行问题分析与建模并智能化地做出后续决策。POMDP问题符合现实中很多实际应用,并且现已被广泛用于军事兵力推演[1-2]、自动驾驶[3-4]、资源调度[5-6]、机器人控制[7-11]、游戏[12-13]等领域。
目前在POMDP下构建状态的方法主要有使用历史信息、信念状态和循环神经网络。王学宁等人[14]提出了基于记忆的强化学习算法CPnSarsa(λ),通过对状态进行重新定义,智能体结合历史信息来区分混淆状态。在部分可观测环境中,信念状态[15](belief,表示隐状态的分布)常被认为是具有马尔可夫性,根据这一特点,Egorov[16]使用POMDP任务的信念状态作为DQN输入对策略进行求解。Meng Lingheng等[17]通过将记忆引入TD3算法,提出了基于长短时记忆的双延迟深度确定性策略梯度算法(LSTM-TD3)。Matthw Hausknecht[18]等通过将长短期记忆与深度Q网络相结合,修改DQN以处理噪声观测特征。刘剑锋等人[19]在DDQN算法中引入对比预测编码(CPC)通过显式地对信念状态进行建模获取历史的地图编码信息进行训练。耿俊香等人[20]将注意力机制引入到多智能体DDPG算法的价值网络中,有选择地关注来自其他智能体的信息,使其在复杂的环境中成功实现智能体间合作、竞争等互动。刘国名等学者[21]尝试了将智能体与环境交互收集到的环境信息经过卷积神经网络处理后输入到LSTM神经网络,利用历史信息引导智能体的探索起到了很好的效果,但在收敛速度上仍存在着不足。在此基础上,该文提出了一种融合注意力机制与循环神经网络的深度强化学习算法(即ARPPO算法)进行POMDP的探索任务研究。实验结果表明ARPPO算法在存在动态改变的POMDP环境中有着更强的探索能力与适应性,且收敛速度较已有的A2C,LSTM-PPO等算法更快。
1 相关技术
1.1 LSTM神经网络
循环神经网络(RNN)由于在当前时间片会将前一时间片的隐状态作为当前时间片的输入,故在时序数据的处理上表现优异。LSTM神经网络是一种改进的RNN,主要用于解决RNN存在的长期依赖问题。它通过引入3个门控结构和1个长期记忆单元控制信息的流通和损失,从而避免梯度消失和梯度爆炸问题,其结构如图1所示。
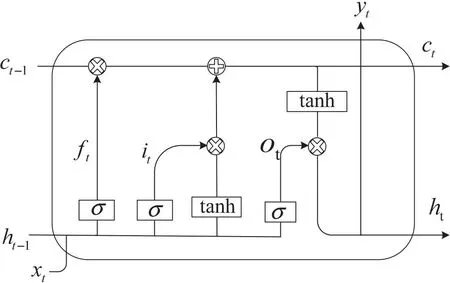
图1 LSTM网络结构
其中,f表示遗忘门,i表示输入门,o表示输出门,c表示记忆细胞状态。前一时间的隐状态ht-1与序列xt输入到网络中,yt为网络最终的输出结果,同时更新隐状态和记忆细胞状态。其计算公式如式1~式5所示。
ft=σ(Wfxt+Ufht-1+bf)
(1)
it=σ(Wixt+Uiht-1+bi)
(2)
ot=σ(Woxt+Uoht-1+bo)
(3)
ct=ft⊗ct-1+it⊗tanh(Wcxt+Ucht-1+bc)
(4)
ht=ot⊗tanh(ct)
(5)
其中,Wf,Wi,Wo,Uf,Ui和Uo表示权重矩阵;bf,bi,bo和bc为偏置向量;σ代表Sigmoid激活函数;⊗表示哈达玛积;tanh为双曲正切函数。
1.2 注意力机制
自注意力机制利用特征本身固有的信息进行注意交互。神经网络通过引入自注意力机制,解决了模型信息过载的问题,提高了网络的准确性和鲁棒性。自注意力机制的计算分为两个部分,第一部分是计算输入的序列信息中任意向量之间的注意力权重,第二部分是根据所得注意力权重计算输入序列的加权平均值,图2为自注意力机制原理。
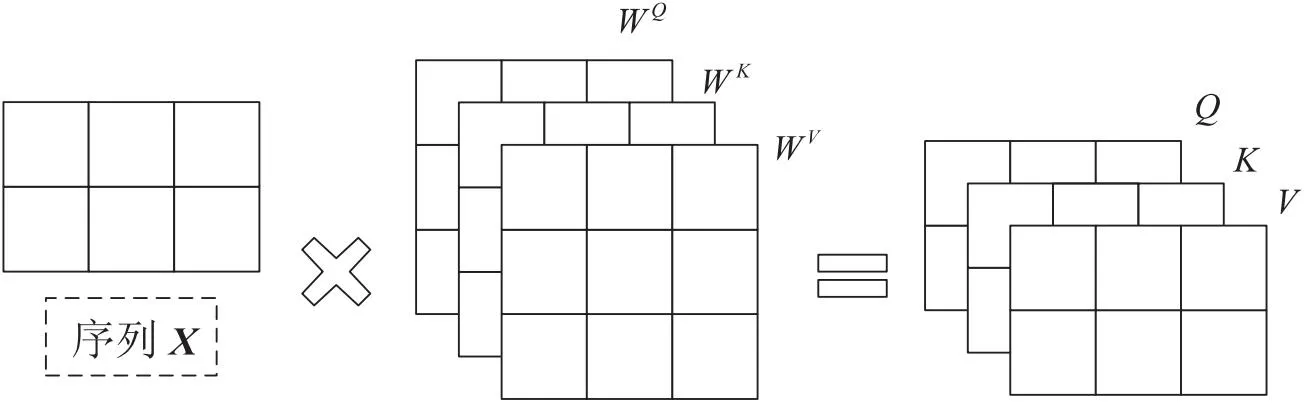
图2 自注意力机制原理
其中,X表示输入的序列数据,其详细计算公式如式6~式9所示。
Q=XWQ
(6)
K=XWK
(7)
V=XWV
(8)
(9)
其中,Q,K和V分别表示查询矩阵、键矩阵和值矩阵,它们由输入的X分别与对应的权重矩阵相乘所得,Attention(Q,K,V)由Q与K矩阵的转秩相乘的结果除以Q,K和V维数的平方根,然后乘以矩阵V所得。
多头注意力能够使模型在多个不同位置上关注到更多来自不同子空间的信息,最后将各空间所得信息进行拼接,能够更好地对重要信息增加权重,其计算公式为式10和式11,WO表示计算头部注意力实例线性变换的矩阵。
(10)
Multi(Q,K,V)=Concat(headi,…,headh)WO
(11)
1.3 近端策略优化算法
在深度强化学习领域中,通常将无模型的深度强化学习算法分为Q值函数方法和策略梯度算法[22]。近端策略优化算法(Proximal Policy Optimization,PPO)属于策略梯度算法,其原理是将策略参数化,通过参数化的线性函数或神经网络表示策略。
PPO算法其中的一个核心是重要性采样,主要目的是用于评估新旧策略的差别有多大,重要性采样比很大或者很小就会限制新策略,不能让新策略和旧策略偏离太远,其公式如式12所示。
(12)
另一个核心是梯度裁剪,PPO算法的目标函数表达式为:
LCLIP(θ)=E[min(r(θ)A,clip(r(θ)))]
(13)
A=Q(s,a)-V(s,a)
(14)
其中,θ为策略参数,A为优势函数,Q(s,a)代表在状态s下采取动作a的累积奖励值,V(s,a)为状态估计值。clip为裁减函数,梯度裁剪的作用则是使各动作的概率分布保持相近,基于上限1+ε与下限1-ε处进行截断操作,以此避免策略更新出现较大差异。 PPO算法的参数更新公式如下:
(15)
通过基于优势函数的Actor-Critic方法进行回报值估计,则会产生方差较小而偏差较大的问题。该文采取的PPO算法采用了泛化优势估计(GAE)权衡方差和偏差的问题,公式为:
(16)
λ=0时,advantage 的GAE表示退化成时序差分方法(one-step TD);λ=1时,advantage的GAE表示退化成蒙特卡洛方法;λ在(0,1)区间时,表示在偏差和方差之间做出折衷。
2 融合注意力与LSTM的ARPPO模型
如图3所示,融合注意力机制与LSTM网络的近端策略优化算法主要分为4个模块,即卷积网络模块、注意力模块、长短时记忆网络模块和PPO算法模块。

图3 ARPPO模型
具体步骤如下:
(1)对智能体与环境交互获取的图像编码信息进行卷积处理后提取特征。
(2)将提取的特征输入到注意力网络,捕捉信息的关联性,一定程度上实现多变量解耦或部分解耦。
(3)将注意力网络输出的数据信息,引入LSTM网络提取数据的时域特性。
(4)分别输入到强化学习的Actor-Critic框架中进行策略提升与训练。
卷积网络模块对图像编码信息进行特征提取,考虑到计算复杂度与过拟合问题,设计了两层卷积网络提取数据的深层多维信息。第一层卷积网络输入通道数为3,输出通道数为32,卷积核大小为4,步长为1。第二层卷积网络输入通道数为32,输出通道数为64,卷积核大小为4。
注意力编码模块由多头注意力网络、全连接层、dropout层和batch-norm层组成。多头注意力网络中采用多头数为8。第一层全连接网络使用64个输入通道和2 048个输出通道。第二层全连接网络使用2 048个输入通道和64个输出通道。卷积输出的信息进入注意力网络层进行权重叠加,并使用全连接层进行数据调整。两层norm使用的eps值为10-5。并且模型使用了dropout层防止出现过拟合现象。
PPO算法基于Actor-Critic框架,其中Actor网络通过输入处理后的特征信息获取当前各项动作选取的概率数组,Critic网络对当前所处状态进行评价与估量,返回一个状态评估值。Actor网络中的第一层全连接层的输入通道数为64,输出通道数为64。第二层全连接层输入通道为64,输出通道为7。Critic网络中的第一层全连接层的输入通道数为64,输出通道数为64。第二层全连接层输入通道为64,输出通道为1。
3 实验设计
3.1 实验环境
为验证所提出的ARPPO算法基于部分可观测环境的训练效果与学习情况,采用Gym-Minigrid[23]网格环境。该环境中智能体在导航时仅能获取其朝向方向7×7大小的图像编码信息,且无法感知墙壁后方信息。该文基于Minigrid已有的环境做出改动,设计了Empty-16×16-v1和FourRooms-v1两种不同难度的地图环境,旨在验证算法对于动态变化环境的性能与表现。

图4 Empty-16×16-v1
图4为改进的环境Empty-16×16-v1,智能体在障碍物左上侧位置上随机初始化朝向,智能体仅有的视野范围内学会在相应位置保持正确朝向并行进,且需要在受中间围墙的视野影响下学会找到围墙中间区域出现的门并且学会开门动作,获取围墙另一侧的环境信息,最终找到右下方的目标点。并且每一回合产生的门位置是随机变化的。图5为改进的环境FourRooms-v1,智能体同样位于左上角位置朝向随机,智能体需要在仅有的视野范围内离开左上方的房间并且找到右下角的目标点, 不同的是该环境存在更多的动态变化因素, 每一回合地图中的四堵墙的缺着口是变化的,这为智能体探索目标点带来了相应的困难,该环境旨在测验算法应对动态环境的可适用性。

图5 FourRooms-v1
3.2 奖励设计
奖励是对每回合智能体与环境交互产生的回报。该文设计了一种随步数变化而变化的奖励函数,旨在引导智能体在一个episode内以更少的完成步数获取更高的奖励值,避免出现局部收敛使得智能体停止探索任务的情况。具体如式17所示。
(17)
3.3 训练过程与结果分析
实验采用Ubuntu18.04,Python版本为3.9,基于torch1.13搭建的深度强化学习框架。实验设备为含有两张显存大小为8G的GTX 1080显卡的服务器。为验证所提出的ARPPO算法的性能表现,设计了ARPPO算法的消融实验,证明并非仅因LSTM网络或注意力机制使得算法效果提升。同时也选择了A2C算法与RA2C算法(A2C-LSTM算法)进行对比实验,由于ARA2C算法在实验过程中表现效果很差,通过实验测试在两张地图上均不能收敛,故不作为该项实验的比较算法。除特定的注意力编码器和循环神经网络参数以外,所有算法都共用相同的参数:迭代次数为4,训练批大小为256,学习率为0.001,折扣率为0.99,采用optimizer优化器。循环神经网络的recurrence参数设置为4。
基于Actor-Critic框架的网络层采用tanh激活函数,其余使用了激活函数的网络层均为relu激活函数。三种算法结构均使用相同的帧编码器,表1总结了六种算法结构的异同之处。
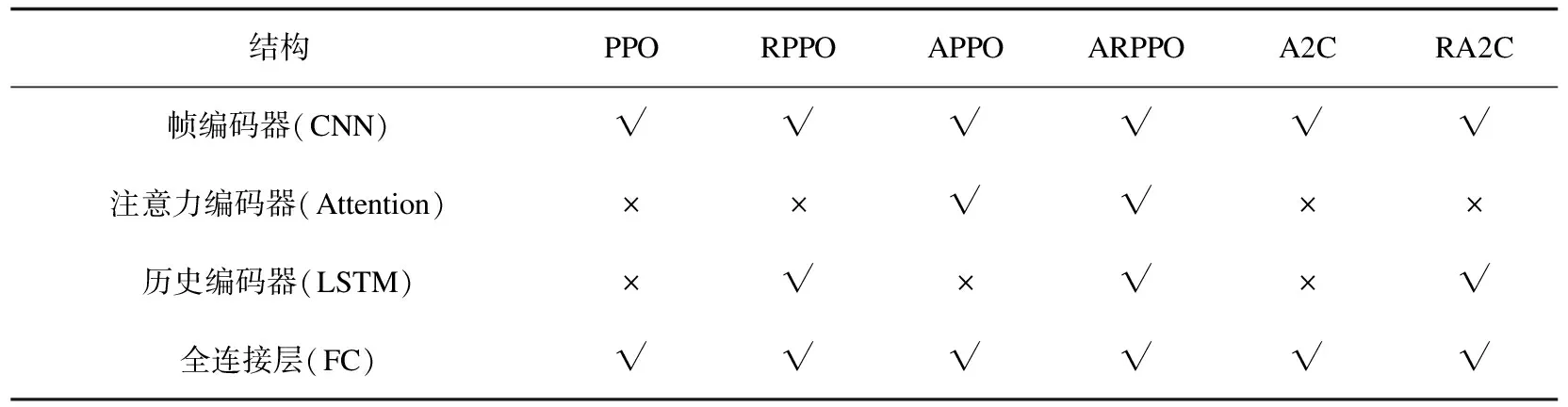
表1 各算法结构设置
在Empty-16×16-v1和FourRooms-v1环境下对六种算法进行了训练效果的测试,采用多进程的训练方式加快深度强化学习算法的收敛。在每个进程中生成随机种子不同的训练环境,智能体每与环境交互128次后将数据信息存入经验池,然后随机从经验池中抽取batch-size大小的数据信息进行参数更新,采用各进程的平均策略损失值与平均价值损失值作为目标函数的loss值项进行反向传播与参数更新,最终平均奖励值体现总体的训练效果。六种算法在Empty-16×16-v1环境下的训练奖励值变化如图6(a)所示,横坐标的frames表示智能体与环境交互的总步数。由于环境中随机波动因素较小,门的位置仅在围墙中间部分波动,智能体在五种算法情况下都能成功找到最终目标。其中,ARPPO能够以较快的速度达到最高奖励值并完全收敛,得益于该算法采用了注意力机制,获取到了更多的重要关键信息,忽略了一些无关紧要的编码信息,并且LSTM网络对历史信息编码,能够对更多的信息进行充分利用,做出更佳的判断与决策。值得注意的是,面对存在小部分随机因素的环境,仅融合循环神经网络或注意力机制模块的PPO算法不能很好地对随机变化的因素进行判断与决策。而且A2C算法对于探索该类非固定场景具有良好的表现,这是由于A2C算法不存在重要性采样,策略更新变化幅度大,对于动态变化因素适应力比PPO算法更强。然而参考历史数据信息进行训练的LSTM-A2C算法表现效果并不理想,某一地图场景训练所得的策略参数很难适用于其他不同场景,训练效果甚至比不上仅用卷积网络处理特征信息的A2C算法。
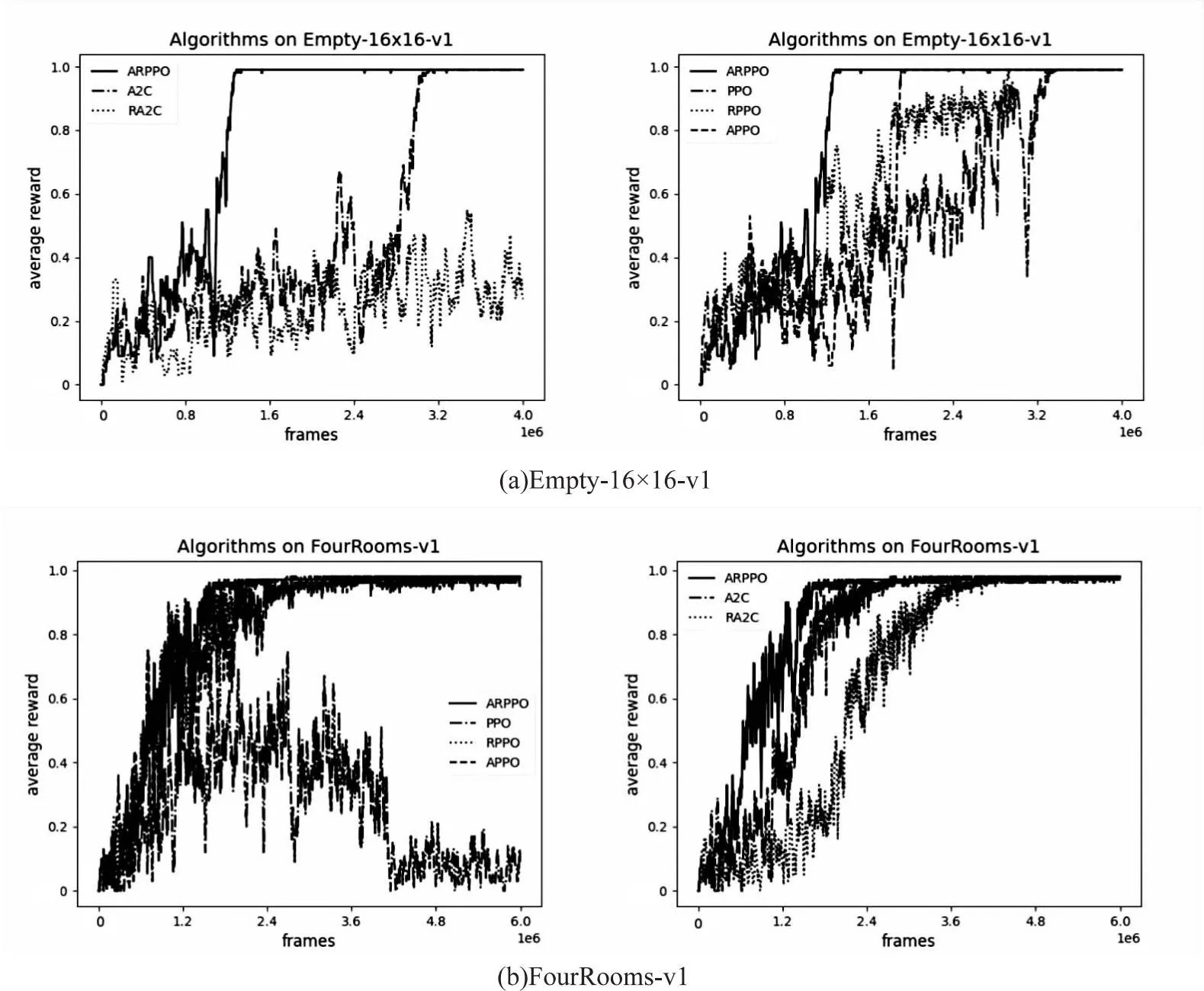
图6 不同算法的性能对比
具有更多动态变化因素的FourRooms-v1环境,每一回合地图中间的四面墙会随机产生一个位置缺口,智能体要学会在每一回合中找到墙壁缺口并最终找到右下角的目标点。六种算法在该环境的训练表现如图6(b)所示。表2体现了表现各算法在两张地图上的详细收敛情况。数据表明ARPPO算法综合收敛速度比表现较好的APPO算法与RPPO算法分别提高了37.96%与37.65%,且从图5与图6的每回合的步数使用情况来看,ARPPO算法在收敛之后的稳定性也不错。综上表明,ARPPO算法明显比RPPO算法收敛更快且收敛之后比APPO算法更具有稳定性,这是由于LSTM网络为样本数据建立时序依赖关系,而引入注意力机制则强化了长距离中重要且关键的样本数据之间的依赖关系,解决了随着时间跨度增加,前阶段所采集的样本数据对后续的策略选择与价值估计的影响呈指数衰减这一现象。
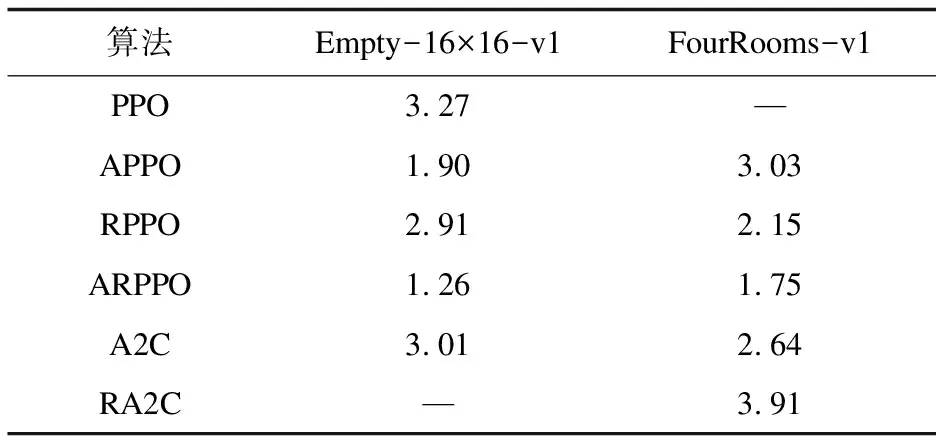
表2 各算法收敛所用的环境交互次数(×106)
为进一步验证算法收敛后的稳定性,选取了最后30个episode的训练情况作为参考对象,从具体步数来探究算法收敛后的稳定性。各类算法在Empty-16×16-v1与FourRooms-v1的训练情况如图7所示。
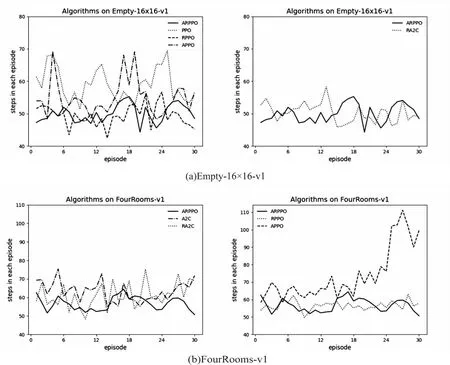
图7 最后30个回合的算法步数变化情况。
由图7中发现,PPO算法与APPO算法收敛后步数变化幅度较大,对于动态随机因素的适应性稍弱,环境发生改变时,并不能选取最优的探索路径。RPPO算法与ARPPO算法收敛后的稳定性很强,对于动态改变的环境仍具有较好的适应能力。
由于环境动态改变的随机性,各回合离目标点的距离不确定,故仅平均步数并不能客观地体现出各算法的稳定性,所以还选取了30个episode的步数标准差作为评估对象。表3中数据前项为平均步数,后项为标准差。综合数据体现出ARPPO算法与RPPO算法的稳定性最优,每回合都能采取更优的探索路径完成探索任务。但在两种算法稳定性相当的情况下,ARPPO算法的收敛速度比RPPO算法的更快。
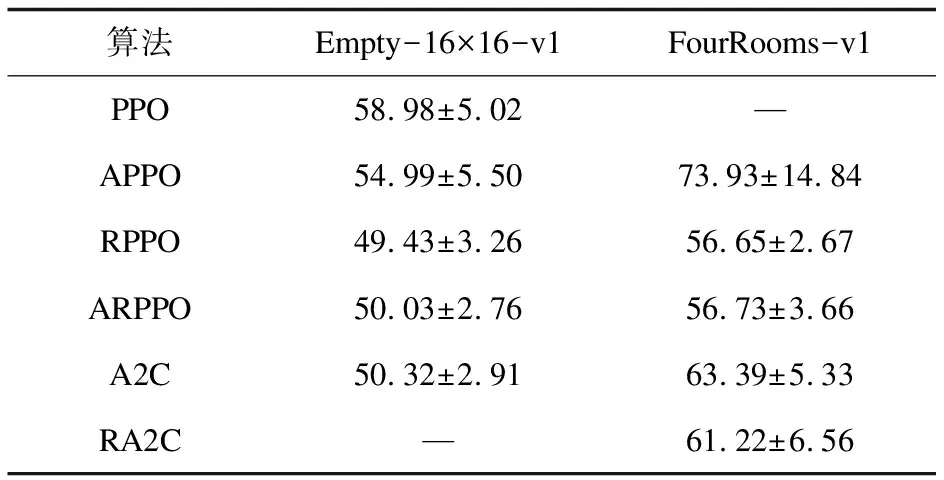
表3 各算法最后30个episode的平均步数与标准差
4 结束语
针对部分可观测环境因缺乏全局信息导致探索困难这一问题,提出了一种基于注意力机制和循环神经网络的深度强化学习算法,即ARPPO算法。该算法引入注意力机制和LSTM网络虽然在计算量和复杂度上有一定的增加,但网络模型结构设计简单,仅设计了一层多注意力模型提高智能体的信息提取能力,相比复杂的注意力模型而言,计算量与复杂度增加相对较小,并且结合注意力与LSTM网络增强了智能体的长时记忆能力,使其能够在动态随机性强的环境保持长时记忆,在环境中获取重要且关键的信息,从而能够快速地学习到有效的探索策略,使得算法达到收敛效果,最终完成探索任务。基于Minigrid设计了两项部分可观测环境的探索任务验证ARPPO算法的效果,实验结果表明ARPPO算法在收敛速度方面优于已有的RPPO,A2C等算法,同时兼顾了稳定性,具有较强的泛化能力。该文为解决部分可观测环境的探索问题提供了一种有效的方法,也为未来的研究提出了一些可能的方向,比如在更为复杂和具有更多动态变化因素的环境中测试ARPPO算法,并尝试使用多层注意力模块或Bi-LSTM网络来进一步提升其性能。
