两阶段文档筛选和异步多粒度图多跳问答
2024-01-24张雪松李冠君聂士佳张大伟陶建华
张雪松,李冠君,聂士佳,张大伟,吕 钊,陶建华
(1.安徽大学 计算机科学与技术学院,安徽 合肥 230601;2.中国科学院自动化研究所 模式识别国家重点实验室,北京 100190;3.清华大学 自动化系,北京 100084)
0 引 言
问答(Question Answering,QA)是自然语言处理中的一个热门话题。随着深度学习的蓬勃发展,QA模型已经取得了重大进展,甚至在简单QA基准测试中超过了人类[1]。然而大部分QA模型为单跳QA,主要聚焦从单篇文档中寻找答案。当单篇文档不足以获得正确答案时,单跳QA通常缺乏从多篇文档中推理答案的能力。
为了提高QA模型在多篇文档中的推理能力,近年来,学者们提出了多跳QA模型,并且设计了多个专门用于评估多跳推理能力的多跳QA数据集。例如目前流行的WikiOmnia[2],HotpotQA[3]和NarrativeQA[4]。这些数据集对应的QA任务十分具有挑战性,因为它们要求QA模型能够在多篇文档和文档噪声干扰下进行多跳推理,以获得问题答案。尤其是在HotpotQA数据集中,QA模型除了需要预测答案,还需提供答案的支撑事实。图1显示了来自HotpotQA数据集的一个示例。除了“3,677 seated”这个答案外,HotpotQA数据集还在文档中标注了答案的支撑事实句子来解释答案。

图1 HotpotQA数据集的示例(只显示了两篇文档)
直观地说,如果一个问题需要通过多篇文档才能得到正确答案,通常模型需要两个步骤:(1)筛选文档;(2)在筛选出的文档中预测出问题答案并找到支撑事实。
在步骤1筛选文档任务中,大多数早期的工作要么将所有文档作为输入,要么单独处理文档,而不管大多数文档是否与问题有关,或者对找到答案是否有帮助。一个准确的文档筛选模块可以提高多跳QA模型的可伸缩性,且不会降低性能[5]。最近的工作包括Tu等[6]和Wu等[7],他们附加一个多头自注意力层(MHSA)来鼓励文档间的交互。Fang等[8]设计一个级联文档检索模块,但其词法匹配引入太多的噪声,使得检索性能不佳。以上的工作旨在找到所有与问题相关的文档,然而并非所有的相关文档都对找到答案有所帮助。
为此,该文在相关文档的基础上进一步提取答案所需的支持文档。将筛选文档任务分为两个阶段。第1阶段通过处理每对文档间的信息来对文档进行评分并选出文档得分超过阈值g的文档作为相关文档,此外通过设置较小的g来尽可能多地获取文档,保证文档的高召回率;第2阶段训练一个递归神经网络(Recurrent Neural Network,RNN)对问题答案的推理路径进行建模,在第1阶段获取相关文档的基础上再次提取文档,保证文档的高精确率。
在步骤2找出问题答案和支撑事实任务中,已有工作证明,图神经网络(Graph Neural Networks,GNN)由于其关系表示能力和归纳偏差,非常适用于多跳QA。根据HotpotQA数据集的特点,大多数工作从构建实体图的实体中选择答案,或通过将实体图的信息传播回文档表示从而在文档中选择答案。然而所构建的图大多仅用于答案预测,不足以发现支持事实。此外,上面的方法在图更新的步骤中同步更新所有节点,忽略了不同节点具有不同优先级以及有序逻辑推理。
因此,在步骤2中将筛选后的文档构建成一个包含问题、实体以及句子的多粒度图,并使用不同的粒度节点执行不同的任务(例如答案预测、支撑事实预测)。此外,该文提出了一种基于多粒度图的异步更新机制来更好地进行多跳推理。具体来说,将该更新分为两个阶段,首先是不同粒度节点之间的更新(例如问题-句子、问题-实体、句子-实体),使节点捕获与其不同粒度节点的线索完善自身信息;其次是相同粒度节点之间的更新(例如句子-句子、实体-实体),比较相同粒度节点之间的描述性信息以更好定位答案和支撑事实,最后将更新后的节点表示传递到预测模块,该模块预测问题的答案、答案类型以及支撑事实。
该文的贡献如下:
(1)提出一种新颖的两阶段筛选文档方法。第1阶段保证文档的高召回率,第2阶段保证文档的高精确率。
(2)针对由文档构成的多粒度图,提出一种新颖的异步更新机制来进行答案预测以及支撑事实预测,以更好地进行多跳推理。
(3)在HotpotQA数据集上进行了对比试验,验证了所提方法的有效性。
1 相关工作
1.1 文档筛选
对于多跳QA数据集来说,一个问题通常提供多篇文档,其中包含许多冗余的文档。当前的预训练语言模型一次接受所有文档作为输入通常是不可行的,因为类似于BERT,其输入的最大长度限制为512。因此,文档筛选是必不可少的。文档筛选的目的是减少噪声信息,为下游任务生成高质量的上下文,即高召回率和高精确率的上下文。Qiu等[9]使用BERT模型单独计算每个文档的相关性,忽略了文档之间的语义关系,因此会在筛选的文档中引入噪声,导致阅读理解任务的表现不佳。因此Tu等[6]和Wu等[7]附加了多头自注意力层(Multi-Head Self-Attention,MHSA)以鼓励文档交互,为了获得更优的结果,Wu等[7]进一步采用一个级联文档筛选模块,该模块将所选的文档作为输入,随后探索它们之间更深层次的关系。此外,由于他们试图同时定位所有相关文档,导致简单的二分类器无法很好地执行。因此,Tu等[6]和Wu等[7]将分类目标重新制定为排名和评分目标,以符合选择器的排名性质。与上面的方法不同的是,该文在相关文档的基础上进一步提取文档用于下游任务。
1.2 多跳QA
多跳QA是机器阅读理解的一个特殊任务,是近年来自然语言理解领域的一个极具挑战性的课题,它更接近真实场景。HotpotQA是最具代表性的多跳QA数据集,因为它不仅要从上下文中提取正确的答案,还需要提供答案的支撑事实。现有的多跳QA工作主要分为两大类:基于记忆检索的递归推理和基于GNN的多跳推理。
第一类专注于多跳问题分解[10],并在循环网络中通过问题和上下文的相互作用来更新潜在特征。Qi等[11]通过迭代重排序检索系统查询缺失的实体。Asai等[12]构建了一个带有超链接的离线维基百科图,构建推理链来进行多跳QA。周展朝等[13]将问题分解视作一个阅读理解任务,更好地捕捉了多跳问题和文档之间的交互语义信息,以此指导多跳问题分解。杨玉倩等[14]提出了一种融合事实文本的问解分解式语义解析方法,对复杂问题的处理分为分解-抽取-解析三个阶段来进行多跳问题分解。
由于GNN具有固有的消息传递机制,可以通过图传播传递多跳信息,因此在找出问题答案和支撑事实方面有着巨大潜力[15]。对于多跳QA来说,基于GNN的多跳推理方法占主导地位。大多数的工作集中在单一层次的粒度表示上。Qiu等[9]提出了一种动态融合图网络,沿着实体图动态探索,从上下文中寻找支撑实体。邵霭等[16]在表征抽取层的神经网络隐藏部分使用参数共享和矩阵分解技术来降低模型的空间复杂度,使用点积计算方式进行答案预测。龙欣等[17]提出了一种多视图语义推理网络,该网络利用全局和局部两种视图的信息共同进行推理。与上述方法不同的是,该文侧重于多粒度图的异步更新。
2 两阶段的文档筛选和异步多粒度图更新多跳问答
在本章节中,将详细介绍文中方法。如图2所示,提出的模型由5个主要模块组成。
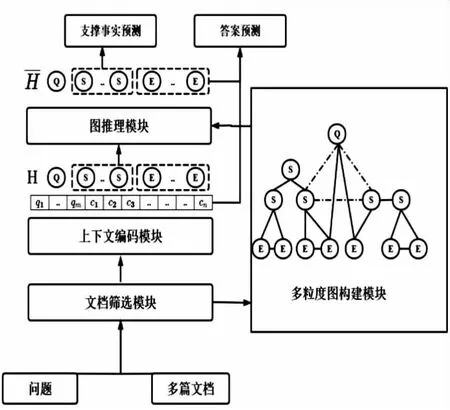
图2 模型框架
(1)文档筛选模块(第2.1节),通过该模块筛选出高召回率和高精确率的文档,然后将其传递给下游任务;
(2)上下文编码模块(第2.2节),通过基于RoBERTa的编码器获得图形节点的初始表示;
(3)多粒度图构建模块(第2.3节),通过该模块构建多粒度图以连接来自不同信息源的线索;
(4)图推理模块(第2.4节),基于GNN的消息传递算法和异步更新机制用于更新节点表示;
(5)预测模块(第2.5节),该模块用来执行寻找支撑事实和预测答案任务。
2.1 文档筛选模块
在这个模块,目标是过滤干扰信息,为下游任务生成高召回率和高精确率的上下文。
如图3所示,在第1阶段中,对于每一篇文档,通过连接“[CLS]+问题+[SEP]+文档+[SEP]”来构建一个输入,供BERT使用。通过BERT对每个问题/文档对进行编码,提取代表全局表示的[CLS]标记作为每个问题/文档对的总结向量。该向量只包含了各个文档自身的特征,但是文档间存在一定的关系,所以通过MHSA让文档间的信息得到交互,再利用一个双线性层来输出每对文档的相关概率。其二元交叉熵损失如下:
(1)
其中,n表示文档数量,i,j表示第i,j篇文档,li,j为文档(Di,Dj)的标签,若Di是支持文档li,j为1反之为0。P(Di,Dj)表示Di比Dj更相关的预测概率。
最后利用评分器SCORE处理每对文档的信息从而获到每篇文档的评分。为了后续g选取操作,将每篇文档评分控制在0到100分之间。
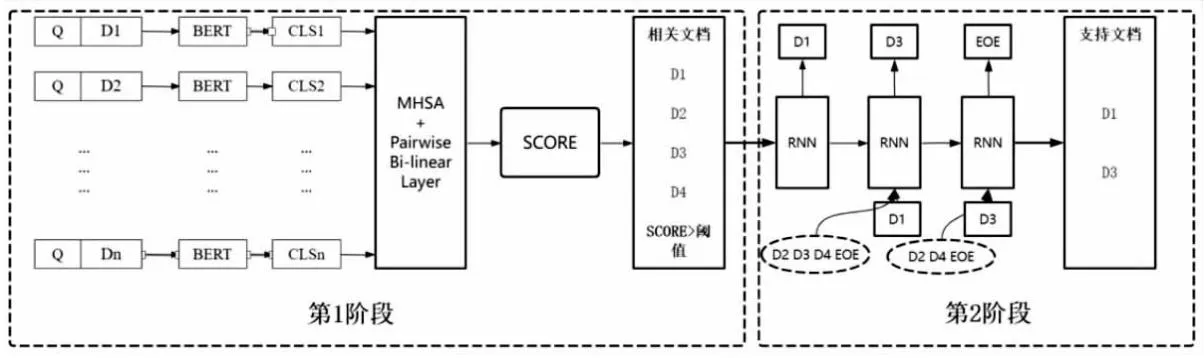
图3 文档筛选模块示意图
其中,D={D1,D2,…,Dn},n是文档的数量。
Dt={Dt1,Dt2,…,DtM}
Score[Dm]>g,m={1,2,…,M}
(2)
选取集合Dt作为相关文档,其中Dt为D的子集(Dt⊆D),集合Dt中每篇文档评分均大于g。
第2阶段主要是从第1阶段选取的文档中检索出获得问题答案所需的支持文档ySD。受Asai等[12]的启发,该文在Dt中利用RNN和波束搜索来寻找最佳的支持文档路径。选择ySD的过程如下所示:
wi=BERT[CLS](Q,Di)
ht=σ(Wht-1+Uwi+bh)
Ot=Vht+bo
(3)
其中,ht是RNN在第t个推理步骤的隐藏状态,σ是激活函数,W,U,V,bh,bo为参数。使用波束搜索在Dt中进行检索,当选择到结束符号(EOE)时过程终止。最后,输出推理路径,选择得分最高的路径上的文档作为ySD。
(4)
2.2 上下文编码模块
首先,将文档筛选模块中筛选出的文档合并成一个上下文,然后将上下文与问题相连并输入到预先训练过的RoBERTa模型中,得到编码的问题表示Q={q1,q2,…,qm}∈Rm*d的上下文表示为C={c1,c2,…,cn}∈Rn*d,其中m,n分别是问题和上下文的长度,d为隐藏状态的大小。紧接着C需要再经过一层BiLSTM,从BiLSTM的输出M∈Rn*2d中获得不同节点(句子S,实体E)的表示。整张图可以表示为H=diagram{Q,S,E}∈Rz*d,其中z为问题节点、句子节点、实体节点数量之和。
2.3 多粒度图构建模块
不同粒度的节点可以从不同的信息源捕获语义,因此与同质节点的简单图相比,它可以更准确地定位支撑事实和答案。为了将分散在多篇文档中的线索汇总起来,构建一个包含问题、句子以及实体的多粒度图。不同粒度的节点针对不同的下游任务。句子节点主要用于事实预测,此外由于答案可能不在实体节点中,因此将实体节点信息融合到上下文表示中来共同预测答案。
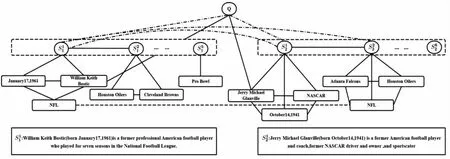
图4 多粒度图的一个示例
图4显示了多粒度图的一个示例。定义了不同类型的边,如下所示:
(1)问题节点与其对应实体节点(问题里的实体)之间的边;
(2)句子节点与其对应实体节点(句子里的实体)之间的边;
(3)出现在同一篇文档中的句子节点之间的边;
(4)出现在同一个句子中实体之间的边;
(5)具有相同实体的句子之间的边;
(6)具有问题中的实体的句子之间的边(问题实体可以不同);
(7)具有相同实体的问题节点和句子节点之间的边;
(8)相同实体之间的边。
设计前4种类型的边使GNN能够掌握每个文档中呈现的全局信息。此外,跨文档推理是通过从问题中的实体跳到未知的桥接实体或比较问题中两个实体的属性来实现的。因此,设计了后4种类型的边,以更好地捕获跨文档推理路径。最后多粒度图由这8种类型的边和3种类型的节点组成。
2.4 图推理模块
为了实现显式和可解释的图推理,使用基于图注意网络[18](Graph Attention Network,GAT)的两阶段图推理。对图中的节点先进行异质更新再进行同质更新来进行多跳推理。例如句子节点,首先进行异质更新使其捕获不同粒度节点的线索完善自身信息,再通过同质更新,比较句子间的描述性信息以确定支撑事实。具体来说,首先将多粒度图H分为异质更新图H1和同质更新图H2。异质/同质更新图通过屏蔽节点之间相应的连接得到,如图5所示。

图5 多粒度图的分解
对于图节点的更新表示,具体来说,首先从图中某个节点开始推理,关注在图上与该节点有连接的其他节点。然后通过计算它们之间的注意力分数,更新节点的特征表示。假设对于任意节点i,其相邻节点集合为Ni,则节点i(i∈{Q,S,E})的注意力权重由下面公式得出:
Si,j=LeakyRelu(WT[hi;hj]),j∈Ni
其中,W为可训练的线性变化矩阵,Si,j表示两个节点之间的相关度分数,ai,j表示节点i相比于其相邻节点的注意力权重系数。最后通过公式计算出节点i的最终的特征表示:
(5)
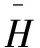
(6)
2.5 预测模块
(7)

模型的训练损失是答案跨度预测、支撑句预测、实体预测和答案类型预测损失的总和。
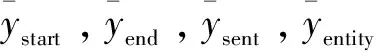
3 实验及结果分析
3.1 实验数据集
使用HotpotQA数据集,这是第一个考虑模型解释能力的多跳QA数据集,也是一个多跳QA任务的流行基准。具体来说,该数据集中包括两个子任务,答案预测(Ans)和支撑事实预测(Sup)。对于每个子任务都有两个官方评估,分别为精确匹配(EM)和部分匹配(F1)。EM表示模型预测的标签中与真实标签完全匹配的百分比。Fl表示模型预测的标签中与真实标签重叠的百分比。EM和F1的联合得分用作整体指标(Joint)。在HotpotQA Distractor验证集上评估模型,该数据集使用整个英文维基百科转储作为数据集的语料库,约有11万个基于英文维基百科的问答对。对于该数据集上的每个问题,提供了2篇相关文档和8篇干扰文档,这些文档是由英文维基百科的高质量TF-IDF检索器收集的。
3.2 基线模型
将所提方案与以下方法进行了对比:
(1)Baseline:将HotpotQA数据集[3]中自带的方法作为基线;
(2)QFE:Nishida等[20]通过考虑支撑事实之间的依赖关系来进行预测;
(3)DFGN:Qiu等[9]根据实体间的关系构造动态实体图,在实体图上进行多跳推理;
(4)GRR:Asai等[12]提出了一种基于图的递归检索查找支持文档,然后扩展现有的阅读理解模型回答问题;
(5)SAE:Tu等[6]提出了一个管道系统,首先选择出相关文档,然后使用所选文档预测答案和事实;
(6)C2F:Shao等[21]认为图结构不是多跳问答所必需的,提出了一种新的自注意力机制来进行预测答案和事实。
3.3 实验结果
表1显示了模型在HotpotQA Distractor验证集上的实验结果,可以看到文中模型超过了大部分已经发表的结果。在正确答案的预测上,文中模型得到的精确匹配(EM)为69.3%,F1为82.3%。所提方法与基线相比在答案预测EM上获得24.9%的绝对改进,在答案预测F1上获得24%的绝对改进。在下面实验分析小节中,将详细分析模型性能增益的来源。
3.4 实验分析
文中的实现基于Transformer库[9]。在阈值g的选取上,人为设置阈值g=0.000 001(接近于0),使得文档筛选模块第1阶段尽可能多地选择文档。在多粒度图构建阶段,使用Manning等[22]提出的预训练实体模型来提取命名实体。图中的句子节点数量设置为20,实体节点数量设置为30。
在文档筛选模块中,当设置阈值g=0.000 001时,文档筛选模块第1阶段文档召回率达到99.9%。在第1阶段的基础上进行第2阶段检索再次获取文档,最后将文档筛选结果和DFGN,HGN和SAE中的文档筛选结果进行比较,如表2所示。所提方法在文档精确率和召回率方面分别为96.7%和96.8%,相比于SAE在各个指标上均有提升。
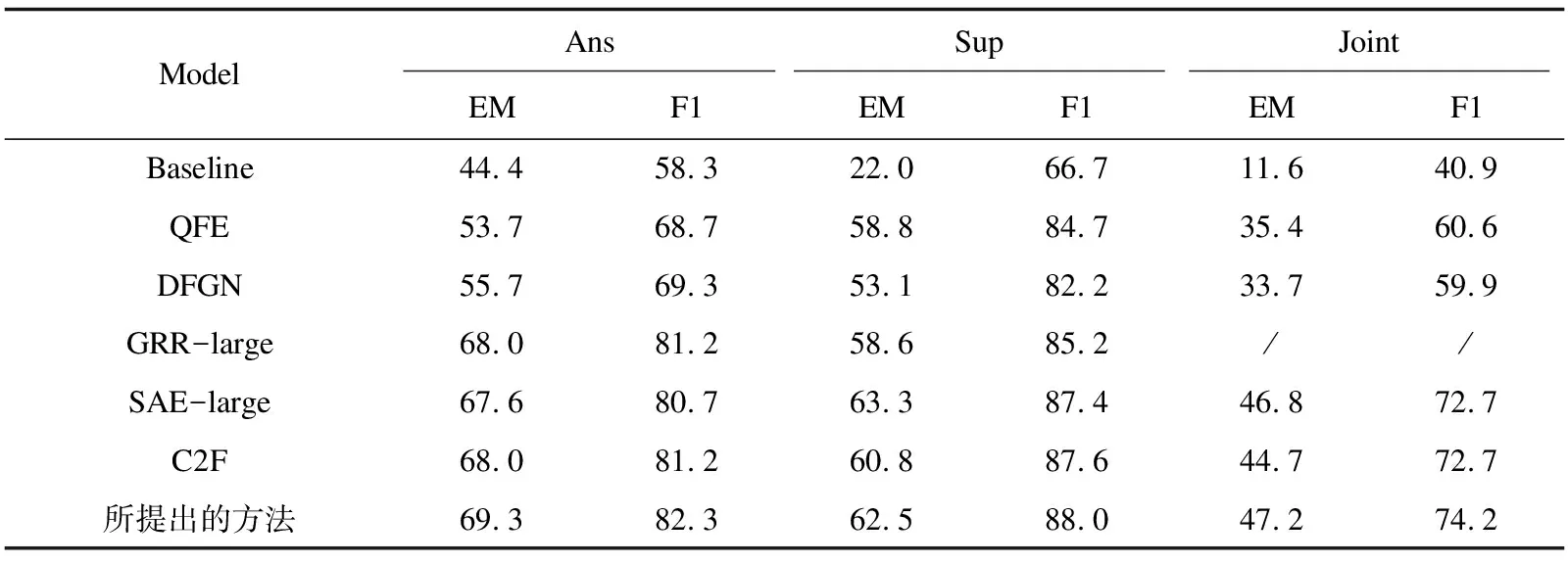
表1 在HotpotQA Distractor验证集上的结果 %
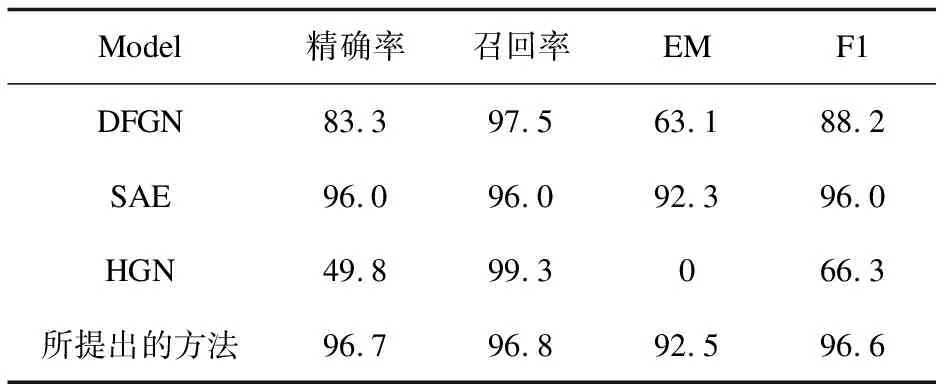
表2 在HotpotQA Distractor验证集上的文档选择结果 %
3.5 消融实验
消融实验结果如表3所示。为了证明提出文档筛选方法的有效性,对文档筛选两个阶段进行了消融研究。在文档筛选模块仅使用第1阶段或仅使用第2阶段中筛选出的文档用于下游任务。从表3中可以看到,仅使用第1阶段筛选出的文档用于下游任务会使模型在Joint F1指标上下降7.8百分点,仅使用第2阶段检索出的文档用于下游任务会使模型在Joint F1指标上下降0.7百分点。在两阶段图推理方面,当去除实体节点时,模型在ANS F1和Sup F1指标上分别下降0.1百分点和0.2百分点。在图节点更新顺序上,比较了3种不同的顺序。观察到从同质到异质的顺序更新节点实验结果较差,低于同步更新的结果。但提出的从异质到同质的方法更新图中节点相比于同步更新在3个指标上均有提升。通过对消融实验结果的分析,证明了所提方法的有效性。
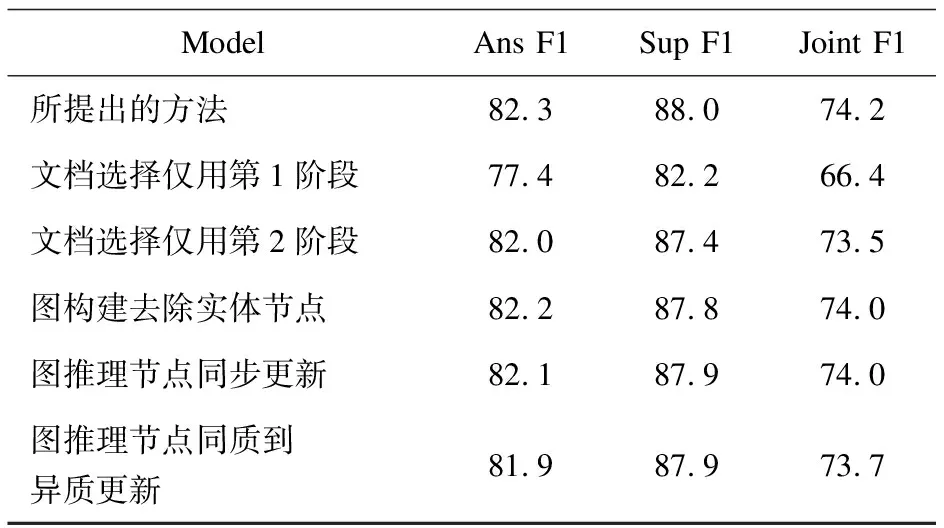
表3 消融实验 %
4 结束语
该文提出一种两阶段的文档筛选方法。第1阶段通过对文档进行评分和设置较小的阈值来尽可能多地获取文档,保证支持文档的高召回率。第2阶段利用递归神经网络对问题答案的推理路径进行建模,结合波束搜索在第1阶段的基础上再次提取文档,保证支持文档的高精确率。最后将支持文档构建成一个图节点为问题、句子和实体的多粒度图,并利用一种新颖的异步更新机制从多粒度图上进行答案预测以及支撑事实预测。实验结果证明了该模型的有效性。在未来工作中,希望结合文本构建图形的新进展来解决更困难的推理问题。此外,希望在其他多跳问答数据集上评估该模型。
