在线社交网络中的多主题谣言溯源
2024-01-24戴树兴夏正友
戴树兴,夏正友
(南京航空航天大学 计算机科学与技术学院,江苏 南京 211106)
0 引 言
现今人们的生活离不开网络,网络给用户提供信息交流的平台。随着手机、电脑等通信设备的快速普及,社交网络平台也逐渐开始兴起,例如Twitter、Facebook、微博。用户之间通过社交网络平台进行信息分享。同时,信息的快速传播也会产生不同的影响,例如用户可以通过网络获取天气预报、股票市场情况变化等信息,但同样也会受到虚假信息的影响,由于虚假信息具有新颖性,抓住人们的猎奇心理,从而导致虚假信息比真实信息具有更强的传染性。此外,对各种各样信息的真实性进行检测是困难的,这导致了谣言在社交网络中传播的问题,恶意用户发散各种不实信息,可能会影响社会的稳定,产生严重的后果[1]。
为了确保社交平台的公信力,以及减少错误信息在社交网络中的影响,追踪识别散播谣言的源头是非常重要的一步,通过了解这些谣言源头有助于平台设计有效的策略遏制谣言的散播。而且感染源头检测技术在其他领域有着很多成功的应用,例如找出污水网络中的病毒、流行传染病的最初感染者[2]。
目前谣言溯源的工作集中于对单一主题的谣言进行源头检测,且大部分为单源检测,这些工作并不全面。考虑到一个更为现实的场景,在同一社交网络中,会有多个不同主题的谣言从多个源头同时传播,每个用户可以同时接收到这些不同主题的谣言。因此,该文将单主题谣言溯源的工作拓展到多主题谣言溯源。在这种情况如何高效地对谣言源头进行追溯是一个很有挑战性的课题。经过一段时间后,在只知道底层的社会网络结构以及时间t的感染子图情况下,如何确定谣言的来源。要解决这个问题,需要解决几个关键挑战。首先,在多主题多源谣言传播的场景下,信息是在网络中如何扩散的;其次,如何确定每个感染节点为源头的可能性;最后,对谣言源头进行识别的方法是否有近似保证,是否会产生较大的偏差。
在单主题谣言传播中,独立级联模型[3]被广泛应用于各项研究中。而多主题谣言传播已经有研究证明其影响是异质的[4]。因此,需要重新证明激活节点目标函数的子模性质,子模能够保证解的良好逼近。该文提出了一种谣言传播的多主题独立级联模型,基于该模型定义了多主题谣言溯源问题,并证明了该问题是NP难的,以及目标函数具有单调、子模的性质。从目标函数的性质出发,提出了一种基于影响力最大化的贪婪算法来进行谣言源头识别,该算法能保证(1-1/e)的比例逼近最优解。
1 相关工作
Shah和Zaman首次提出了谣言溯源问题[5],他们假设单一感染源在树状网络下满足SI模型传播,并提出谣言中心性的概念估计谣言来源。Cai等人[6]研究了在一般传播时间分布条件下,SI模型对单一源多次独立网络快照的检测概率。
Xu和Chen提出一种新的源检测方法[7],设置一些监视器节点来获得谣言传播的速度,以此提出一种多项式算法计算节点的可达性并进行重要性排序。谣言源头检测概率取决于监视器数量。
文献[8]中作者在经典传染病模型的基础上进行改进,加入了新的“辟谣者”状态,并基于贪婪算法识别源头。文献[9]提出一种SIOR传染病模型,并研究了在该模型下的谣言溯源问题。文献[10]提出一种SEIR模型,研究了基于网络观测快照下的单一来源检测问题。
Choi等人[11]提出了基于查询的方法,首先向节点进行一次简单的查询并根据回答生成网络。然后使用交互式查询,询问节点从谁接收到谣言。该方法保证了在规则树网络中的检测概率。文献[12]中,作者在基于监视的观察下,通过监视器节点发送“反谣言”,并用最大后验估计器来检测谣言来源。
在多源检测工作中,Wang[13]首次将谣言中心度拓展到了多源检测。Dong等人[14]提出了一种基于深度学习的谣言溯源模型,在缺乏底层网络信息传播模型的先验知识下,依然能检测到多个谣言来源。
Nguyen提出了基于排名和优化的方法将感染节点按可疑性排序,找出前k个可疑节点[15]。李城等人[16]基于最长公共子序列改进了LCS算法。
叶增炜等[17]提出了一种基于有责量和免责量的谣言溯源方法。廖艺等人[18]基于谱优化社区划分算法将感染子图划分为两个社区后寻找谣言来源。
2 谣言来源检测和问题描述
在这一节内容中,首先将介绍谣言的基本传播模型,然后给出了改进后的多主题谣言传播模型,接着描述了相关问题的描述以及证明。该文将独立级联模型拓展到多主题独立级联模型。
2.1 独立级联模型
在独立级联模型中,社交网络被视作为一个有向加权图G=(V,E),每个节点v代表不同的用户,每条有向边e=(u,v)∈E代表用户u和用户v之间的关系,每条边会被分配一个权重p(u,v)∈[0,1],代表用户u对用户v的影响程度。
在谣言传播过程中,每个节点只有两种状态:活跃和非活跃。在时间步t时,当节点u被激活为活跃状态时,该节点会依次向其每个邻居v以概率p(u,v)进行谣言传播,如果激活成功,邻居t+1在第u时刻转化为活跃状态。在后续传播过程中,节点u将不再尝试激活其邻居。当没有新的节点被激活时,谣言传播过程结束。
2.2 多主题独立级联模型
独立级联模型研究单个主题的信息传播过程。但是考虑到多个不同主题的谣言可以同一时间传播,同一用户可以在短时间内同时接收到不同主题的谣言。不同主题的谣言不仅内容不同,传染力也可能不同。娱乐八卦类的谣言比农业、军事等类型的谣言传播更广,影响人数更多。而且同一用户传播不同类型的谣言时,对邻居产生的影响也可能不同。
因此,在多主题谣言传播的情况下,需要重新对信息扩散过程进行建模。而独立级联模型并不能处理这种情况,因为它很难体现不同主题之间的复杂相关性。已经有相关研究证明,当采用多主题信息级联时,计算激活节点的目标函数不再是子模的[19-20]。
在多主题独立级联模型中,在线社交网络用G=(V,E,P)表示,其中V为节点集,E为边集,且|V|=n,|E|=m。每个节点v代表不同的用户,每条有向边e=(u,v)∈E代表用户u和用户v之间的关系,每条边会被分配一个初始影响权重p0(u,v)∈[0,1]代表用户u对用户v的影响程度。用Ni(v)表示节点v的传入邻居节点集,No(v)表示传出邻居节点集。

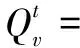
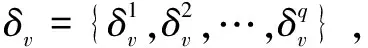
2.3 问题描述
该文的目标是在已知底层网络结构以及第t个时间步感染子图的情况下找出一组节点,而这组节点被认为是最可能的谣言来源。现实中谣言源头想通过影响尽可能多的用户以达到某种目的,因此在直觉中如果能找出影响最大的一组节点,那么这组节点中为谣言来源的可能性非常大。利用这一特点,基于影响力最大化的原理将活跃集合S中每个节点根据可疑性程度进行排序,其中前k个节点被视作最可疑的节点。
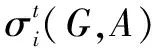
定义1(k-可疑节点):在线社交网络用有向加权图G=(V,E,P)表示以及给出带有q个主题的感染节点集S={S1,S2,…,Sq},利用多主题独立级联模型来模拟信息扩散过程。目标是在已知感染子图G'=(V',E',P')时找出一组不超过k个可疑节点集A⊆S,使得激活节点数均值φ(G',A)=E(|σ(G',A)∩S|)最大。
一些关于影响最大化问题是NP难的证明可以在文献[3,20-21]中找到。接下来给出在多主题独立级联模型下的k-可疑节点问题是NP难的证明。
定理1:基于多主题独立级联模型的k-可疑节点问题是NP难的。
证明:为了证明k-可疑节点问题是NP难的,用背包问题归约到k-可疑节点问题。而背包问题是公认被证明的NP完全问题。
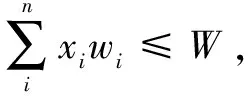
令π1=(X,W)是背包问题的一个实例,令π2=(G',S,k)是k-可疑节点问题的一个实例。其中S是谣言的源头节点,k是确定的前k个可疑节点。对于接下来构造从π1到π2的一个归约,如图1所示。
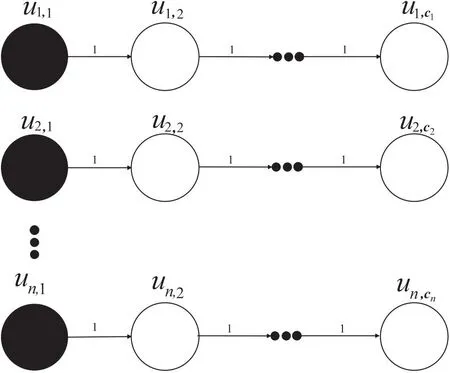
图1 k-可疑节点问题到背包问题的归约
归约:为了构造归约,首先给出一个感染子图G'=(V',E',P')使其满足以下条件:其中存在谣言源头集S,对每个物品的价值ci构造一条含有ci+1个节点的简单路径:S→ui,1→ui,2→…→ui,ci,并设路径的每条有向边权重为1。对任意的ui,1都有wi=1,令k=W和M=C。M是一个正整数。接下来证明π1有解X={x1,x2,…,xn}当且仅当π2也有对应的解A={ui,1|i=1}使φ(G,A)>M,反之亦然。
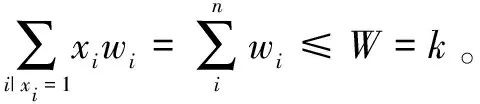
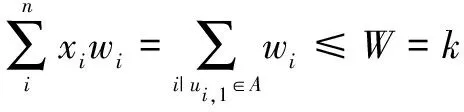
综上可知,背包问题的解是k-可疑节点问题的解,而k-可疑节点问题的解也是背包问题的解。因此k-可疑节点问题是NP难的。
接下来需要证明目标函数是单调且子模的。
定理2:多主题独立级联模型下的目标函数φ(·)是单调递增的子模函数。
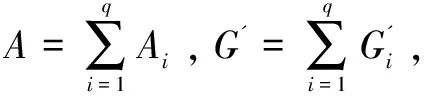
2.4 基于影响力最大化的贪婪算法
前面已经证明多主题独立级联模型下的k-可疑节点问题是NP难的,因此想要求最优解是需要花费指数增长的时间,成本太高。因此,该文提出了一种求解该问题的贪婪算法。由于子模函数的性质,该算法能以(1-1/e)的比例逼近最优解,能够在一定程度内保证解的质量和精度。
在已知某一时刻的感染子图情况下,对任意节点u,如果能感染尽可能多S中的节点,那么该节点为谣言源头的可能性越大。以此计算并排序将所有节点的可疑程度,最后输出前k个最可疑的节点。算法过程如下:
算法1:贪婪算法
输入:感染子图G'=(V',E',P'),以及感染节点集S,模拟次数R,谣言主题数q
输出:k个最可疑节点
I←φ
fori=1 toq
forj=1 tok
foru∈SiIi
form=1 toR
早产的动物在使用机械通气进行治疗的初期其炎症反应的程度就会上升,即使利用表面活性物质进行治疗,也会导致肺部的损伤,动物实验的结果提示早产儿发生BPD可能与机械通气之间有着密切的关联[7]。在对早产儿进行机械通气的过程中,由于参数设置的不稳定和时间过长等因素,有可能使小气道和肺泡的膨胀过度,而且产生大量炎性因子。而呼气末压力的降低,又会使肺单位出现反复的萎缩与张开,此过程构成了对肺泡毛细血管完整性地损害。
end
end
end
end
ReturnI
为了尽可能提高算法的准确性,使用蒙特卡罗方法对多主题谣言传播过程进行R次模拟,对节点可疑程度取平均值并取前k个节点。在时间复杂度方面,假设模拟一次多主题谣言传播过程的时间需要O(m),谣言主题数量为q,那么总花费时间为O(Rmqk|S|)。
3 实 验
该文分别在三个不同的真实在线社交网络上进行了谣言溯源的实验。结果表明,与其他的算法相比,贪婪算法有着更高的准确性。
3.1 实验设置
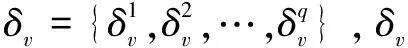
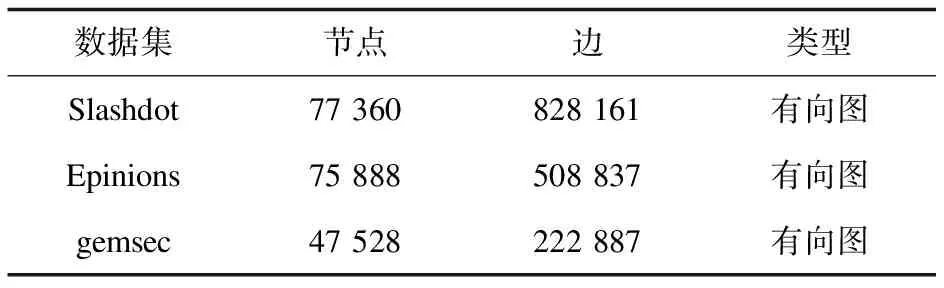
表1 数据集
实验将贪婪算法与最大度算法和随机算法进行了比较。结果表明,在三个不同的真实数据集上以及在不同谣言主题数量的情况下,贪婪算法的表现都要优于最大度算法以及随机算法。
3.2 实验结果
表2和表3分别显示谣言主题数量q=2和q=3的情况下,通过检测概率,误差距离以及平均误差距离用来评估算法的性能。检测概率是指检测谣言来源节点数量与真实源节点数量之比。误差距离是指检测谣言来源节点与真实源节点的最小距离。从表2和表3可以看出,在不同谣言主题数量的情况下,贪婪算法在检测概率、误差距离(1跳之内)以及平均误差距离上的表现都要优于其他两种算法。
3.2.1 检测概率
随着k的增大,检测概率提高。理论上,如果k增大到与感染子图的节点数量一致的话,那么一定包含所有真实谣言来源,但这种做法并不现实。所以实验中将k的最大值设置为10。
由表2可以看出,在谣言主题数量q=2的情况下,在gemsec数据集上,贪婪算法能达到55%的成功检测概率,而最大度算法和随机算法分别只有45%和40%。在Slashdot 和Epinions数据集上,贪婪算法的检测概率能达到70%,最大度算法有35%和30%的检测概率,而随机算法则都只有20%的检测概率。
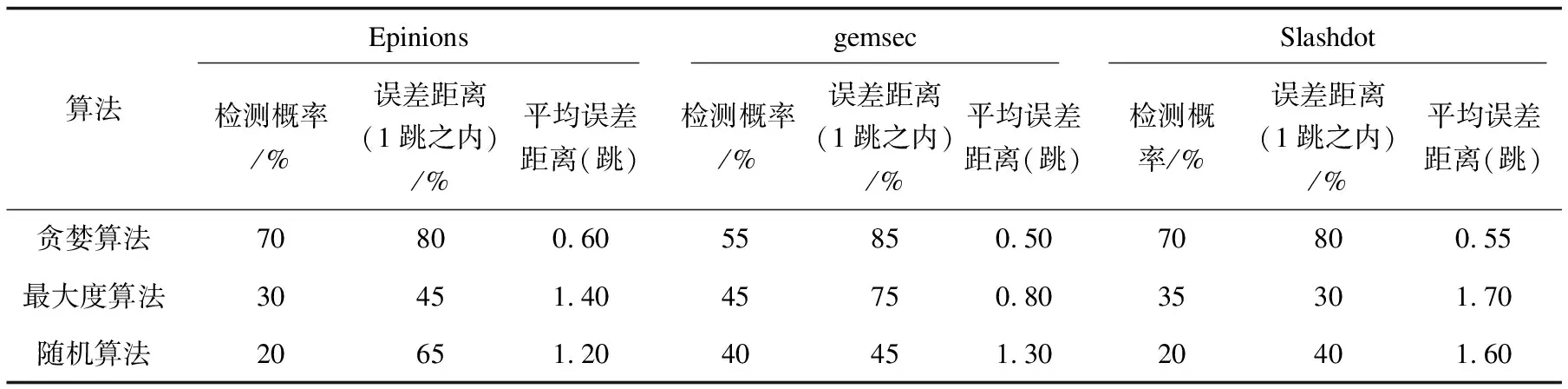
表2 三种算法在不同数据集上的性能对比(谣言主题数量q=2)
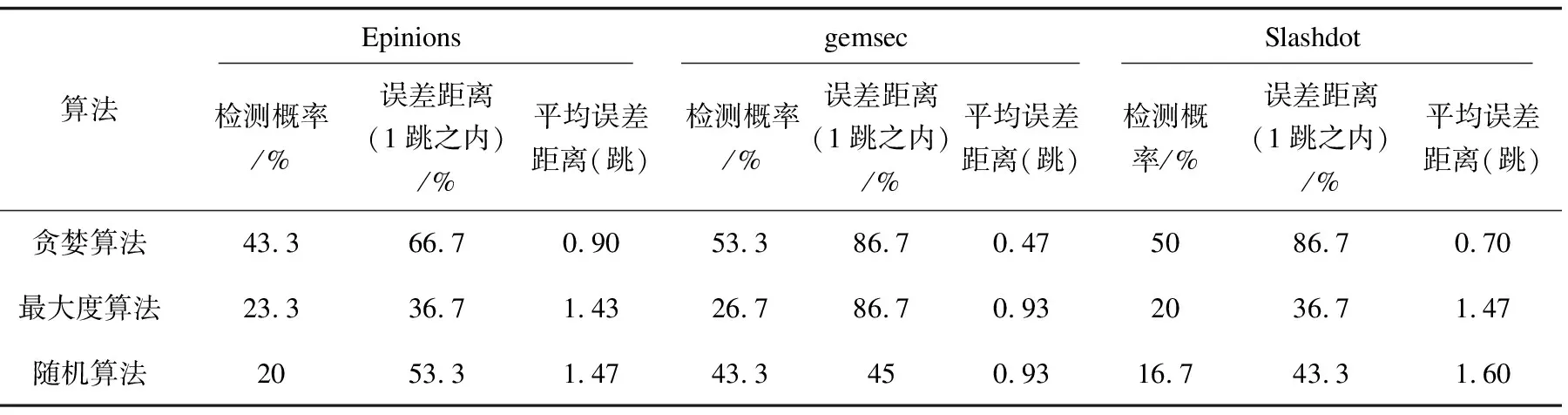
表3 三种算法在不同数据集上的性能对比(谣言主题数量q=3)
当q=3时,由表3可以看出,在Epinions,gemsec和Slashdot数据集上,贪婪算法的检测概率能分别达到43.3%,53.3%和50%。最大度算法的检测概率分别达到23.3%,26.7%和20%。而随机算法则分别达到20%,43.3%以及16.7%。随着谣言主题数量增加,贪婪算法依然明显优于最大度算法和随机算法。
3.2.2 误差距离
图2显示了不同算法在不同真实数据集下的误差距离频率。其中(a1,b1,c1)为谣言主题数量q=2的情况,在Epinions数据集上,贪婪算法有70%的把握能够正确找到谣言来源,且有80%的把握保证检测的谣言节点离真实谣言来源节点的距离在1跳之内。而随机算法和最大度算法分别只有65%和45%的把握。在gemsec和Slashdot数据集上,贪婪算法则分别有85%和80%的把握正确找到真实谣言来源或者只差1跳的误差距离,随机算法则只有45%和40%,最大度算法有75%和30%。
在谣言主题数量q=3的情况下,即图2(a2,b2,c2)中可以看出,贪婪算法的表现依然出色且稳定,在三种数据集上分别有66.7%,86.7%,86.7%的概率能够在1跳的距离之内找到真实谣言来源。而随机算法则分别达到53.3%,45%,43.3%。最大度算法则分别达到36.7%,86.7%,36.7%。随着谣言主题数量增加,贪婪算法优于其他两种算法。
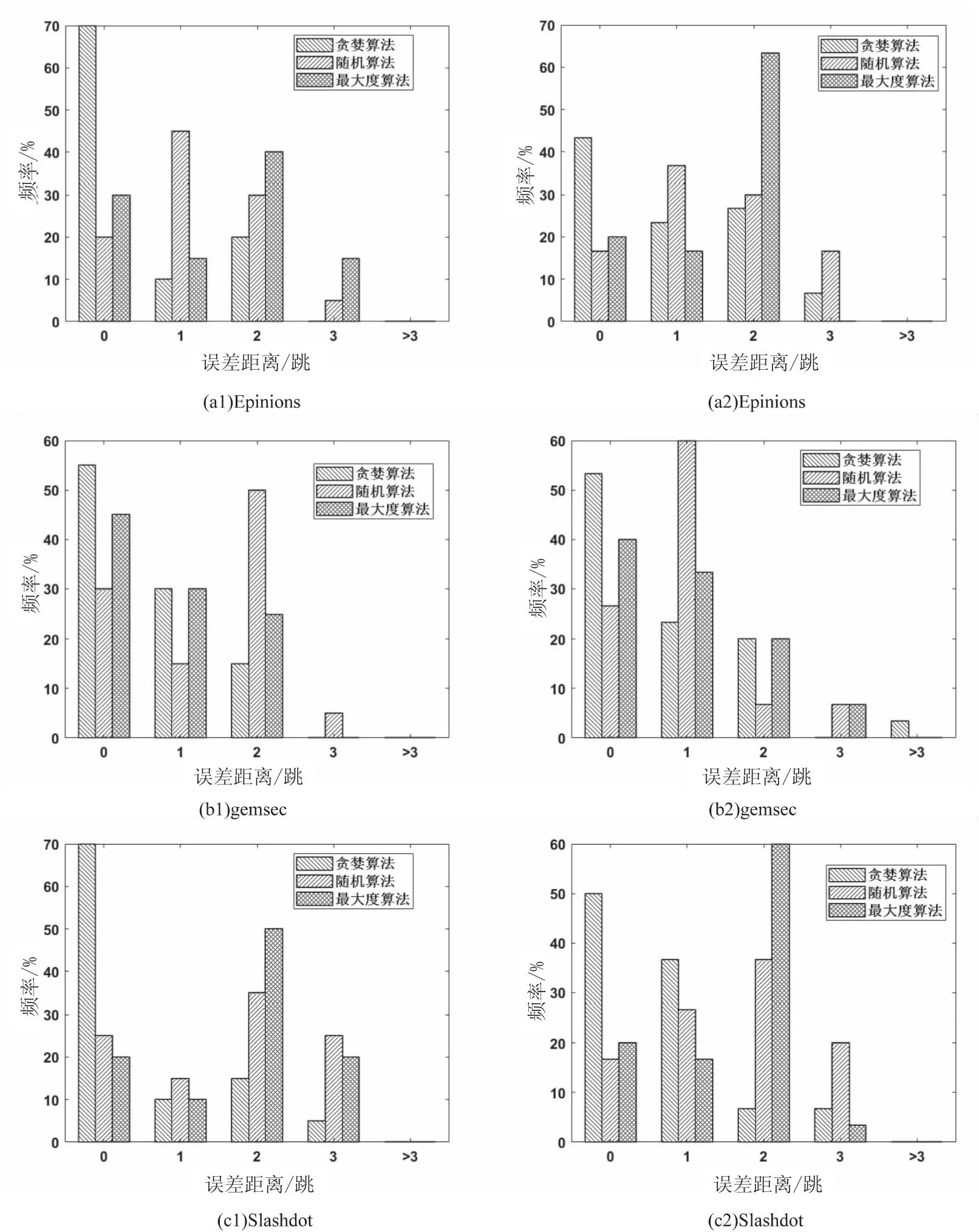
图2 不同数据集和算法下的误差距离
相比于其他两种算法,贪婪算法检测到的大部分谣言节点离真实谣言节点的距离在1跳以内,检测距离达到3跳或者超过3跳的节点不超过10%,表现稳定且高效。随机算法与最大度算法所检测的谣言节点与真实谣言节点的距离随机分布在0~3跳之间,误差较大。

图3 不同算法在不同数据集下的平均误差距离
图3显示了不同算法在不同数据集下的平均误差距离,进行1 000次蒙特卡罗模拟后取平均值。当q=2时,在三种数据集下的平均误差距离分别为0.6跳、0.5跳、0.55跳。而最大度算法分别为1.40跳、0.80跳、1.70跳。随机算法则分别为1.20跳、1.30跳、1.60跳。当q=3时,贪婪算法平均误差距离分别为0.90跳、0.47跳、0.70跳。最大度算法分别为1.43跳、0.93跳、1.47跳。随机算法分别为1.47跳、0.93跳、1.60跳。可以看出贪婪算法明显优于其他算法。
4 结束语
考虑到每个节点可能在同一时间收到多种类型的谣言并传播给邻居的情况,在传统独立级模型的基础上进行了扩展,提出一种多主题谣言传播的独立级联模型。在该模型下,每个节点可以被不同主题的谣言多次感染,因此需要重新定义影响力最大化的溯源问题以及相应的目标函数。
在该模型的基础上,提出了考虑影响力的k-可疑节点谣言溯源问题,即找出前k个影响力最大的节点,这些节点被认为是最有可能的谣言来源。并证明了多主题独立级联模型下的k-可疑节点谣言溯源问题是NP难的,以及对应的目标函数φ(·)是单调递增的子模函数。
提出了一种近似比为(1-1/e)的贪婪算法。实验结果表明,在不同大型网络上,贪婪算法可以有效地识别出不同谣言主题的来源。
