内容自适应超像素分割网络∗
2024-01-23黄睿徐斌
黄 睿 徐 斌
(中国石油大学(华东)计算机科学与技术学院 青岛 266580)
1 引言
超像素分割是一种将图像分割成在颜色和其他低级特征上具有可比性的图像部分的技术。与像素相比,超像素可以更有效地表示图像信息。这种简洁的形式可以大大提高视觉相关算法的计算效率[1~3]。超像素分割通常用于执行图像处理之前的预处理步骤。在密集分割领域结合超像素可以在检测对象边界的同时减少处理时间和内存消耗。在与图相关的领域中紧凑和规则的超像素可以产生更好的结果。因此,超像素性能的三个关键标准:1)粘附边界的能力,也称准确度;2)规则与紧凑性;3)计算速度。
由于采样设备的采样精度不断提高,高分辨率图像变得越来越普遍,对高精度图像的计算机视觉应用的需求也在增加。超像素作为一种有效地最小化图像基元数量以供未来处理的方法,已广泛应用于计算机视觉的各个领域,例如语义分割[4]、目标检测[5]、显著目标检测[1,6~7]和光流估计[8~10]。
超像素分割通常是先将图像划分为网格单元,然后估计每个像素和其附近网格单元的隶属度,然后对它们进行分组。传统的超像素生成方法通常采用手工特征、基于聚类或基于图的算法来估计像素与其相邻像素之间的相关性[11~15],但这些方法存在需要手工设计特征的缺点,并且难以集成到其他可训练的深度框架中。受深度神经网络在许多计算机问题上的成功启发,研究人员最近尝试将深度学习方法应用于超像素分割。U-net 架构被AINet[16],SCN[17]和SSN[18]等流行解决方案用于预测像素与周围九个单元之间的相关概率,以了解每个像素与周围网格单元之间的相关性从而分配像素。因为可以更好地提取特征,这些基于深度网络的方法具有良好的性能。
超像素的特征包括颜色、梯度、纹理、空间、平滑度和尺寸,其中颜色、梯度和纹理特征常用于实现准确性,而空间、平滑度和尺寸特征常用于管理紧凑性。当超像素的边界趋向于粘附物体的轮廓时,超像素的形状往往是不规则的,这导致超像素的精度和紧凑性之间存在一些相互干扰。但是,当紧凑性约束太强时,超像素粘附轮廓的能力就会受到损害。在这种情况下追求更高的边界粘附性会导致图像中颜色一致、纹理丰富的部分出现不规则的超像素,例如天空、草原、地面,但这种粘附性毫无意义。追求更高紧凑性时,由于过于紧凑,导致某些信息丢失,或者单个超像素区域包含多个具有不同语义的像素,影响后续任务。这种情况的根本原因在于在这些超像素方法中,基于颜色、梯度和纹理信息的准确性与基于空间、平滑度和尺寸的紧凑性之间的增强相互平衡。此外,由于生成超像素的约束条件作用于所有像素,因此在准确性和紧凑性之间总是存在实质性的权衡。
本文提出了一个内容自适应超像素分割网络来处理这个权衡问题。通过边缘检测技术将图像划分为边界和非边界区域,对图像像素动态应用不同的边界粘附和紧密度权重,在边界区域中形成具有高边界粘附性的超像素,而在非边界区域中产生具有高紧凑性的超像素。
在BSDS500[19]和NYUv2[20]数据集上进行定量和定性实验,结果表明该方法优于当前的超像素分割方法。
2 相关工作
2.1 超像素分割
Ren 和Malik[21]在2003 年提出了超像素分割,从那时起它越来越受欢迎。基于图的方法和基于聚类的方法是传统超像素算法的两种类型。为了构建图结构,基于图的算法将临近像素之间的连接强度视为图的边。在这种情况下,超像素分割可以被认为是一个图分割问题,如FH[22]和ERS[14]算法。另一方面,基于聚类的算法使用传统的聚类技术,如K 均值聚类,计算锚像素与其临近像素之间的连接性,常见的算法有SLIC[11]、LSC[13]、Manifold-SLIC[15]和SNIC[12]。近年来,深度学习技术的出现鼓励研究人员尝试使用深度网络来了解每个像素在其周围网格单元中的隶属度。Jampani等[18]使用传统的SLIC 方法创建了第一个可微分的深度网络。Yang 等[17]使用FCN 框架进一步简化了超像素生成框架,实现了超像素端到端的创建。Wang等[16]在此基础上进一步提出了一个AI 模块来提高超像素的精度。
作为弱标签或先验知识的一种形式,预先计算的超像素分割有助于众多下游任务的实现。通过将超像素集成到深度学习管道中作为指导,可以更好地保留一些重要的图像属性[23-27],例如边界信息。Kwaj等[2]使用超像素分割执行区域池化,提高了池化特征的语义紧凑性。Chen 等[28]使用超像素作为伪标签,通过在图像中定位额外的语义边界来改进图片分割。除了帮助图像分割或特征池化之外,超像素还提供了一种灵活的图像数据编码方式。He 等[1]使用超像素将二维视觉模式转换为一维序列表示,从而允许深度网络研究图像的远程上下文以进行显著性检测。Liu等[29]创建的框架学习不同超像素的相似性,然后基于学习到的超像素相似性合并元素以构建不同的纹理分割区域。
2.2 内容自适应超像素
为了克服超像素精度和紧凑性之间的冲突,Ye 等[30]使用了一种两阶段分水岭方法。首先在第一阶段生成具有高边界粘附性的超像素。此时超像素精度高,但紧凑性低。之后使用梯度、颜色和纹理过滤器来寻找内容无意义的区域,即远离图像边界的有着相似内容的区域,仅根据空间属性重新标记这些区域的边界像素。在第二阶段中根据新标记在内容无意义的区域重新创建紧凑度高的超像素。最终,内容有意义区域中的超像素边界始终与目标的轮廓相关联,而内容无意义区域中的超像素边界变得紧凑且规则。尽管内容自适应超像素解决了准确性和紧凑性之间的相互约束问题,但两阶段分水岭技术仍然需要手工设计特征,并且难以融入深度网络。
2.3 边缘检测
边缘检测的目的是从自然图像中提取目标的边界和边缘,同时保留图像的主要内容并忽略意外特征,这对于图像分割和目标检测等高级视觉任务至关重要。He 等[31]提出了BDCN 网络,它是一种用于边缘检测的双向级联网络。大体思路是假设真值等于每个尺度的特征图之和,从真值中减去其他特征图可以近似作为当前特征图的监督信息。研究结果表明,对不同特征图的不同尺寸监督可以显著提高边缘质量。
3 方法
在本节中,将介绍提出的内容自适应超像素分割网络。在3.1 节,解释了在规则网格上直接预测超像素的方法,在3.2 节讨论了网络设计和基本损失函数,最后在3.3节,介绍了内容自适应模块。
3.1 在规则网格中学习超像素
为了分割H×W大小的图像I,一种流行的超像素分割技术是采用大小为h×w的规则网格,并将每个网格单元视为初始超像素,或称为超像素的种子。通过找到一个映射G将每个像素p=(u,v)分配给超像素S=(i,j)。从数学的角度,可以将这个映射写为:如果第(u,v)个像素属于第(i,j)个超像素,Gs(p)=Gi,j(u,v)=1,否则为0。
实际上,由于像素在分配超像素时只考虑周边的超像素,将每个像素与每个超像素进行比较没有意义且计算成本很高。因此,将特定像素p的搜索限制在相邻网格单元的集合Np中,其中|Np|=9。如图1 所示,对于红色框中的每个像素p,只考虑绿色框中的9个网格单元进行分配。

图1 对于红框中的每个像素p,只考虑绿框中的9个网格单元进行分配
本文中将使用深度神经网络学习这种映射。不使用映射G,而是使用软关联Q∊ℝH×W×|Np|来创建可微的目标函数。qs(p)表示一个像素p被分配给它周围的每个超像素s∊Np的概率,其中。最终每个像素被分配给概率最高的网格单元,得到超像素s*=arg maxsqs(p)。
3.2 网络设计和基础损失函数
如图2 所示,本文采用带有跳层连接的编码器-解码器结构来预测超像素关联映射Q,并使用内容自适应模块生成紧凑性因子以引导损失函数进行反向传播,最后生成内容自适应像素-超像素关联映射。
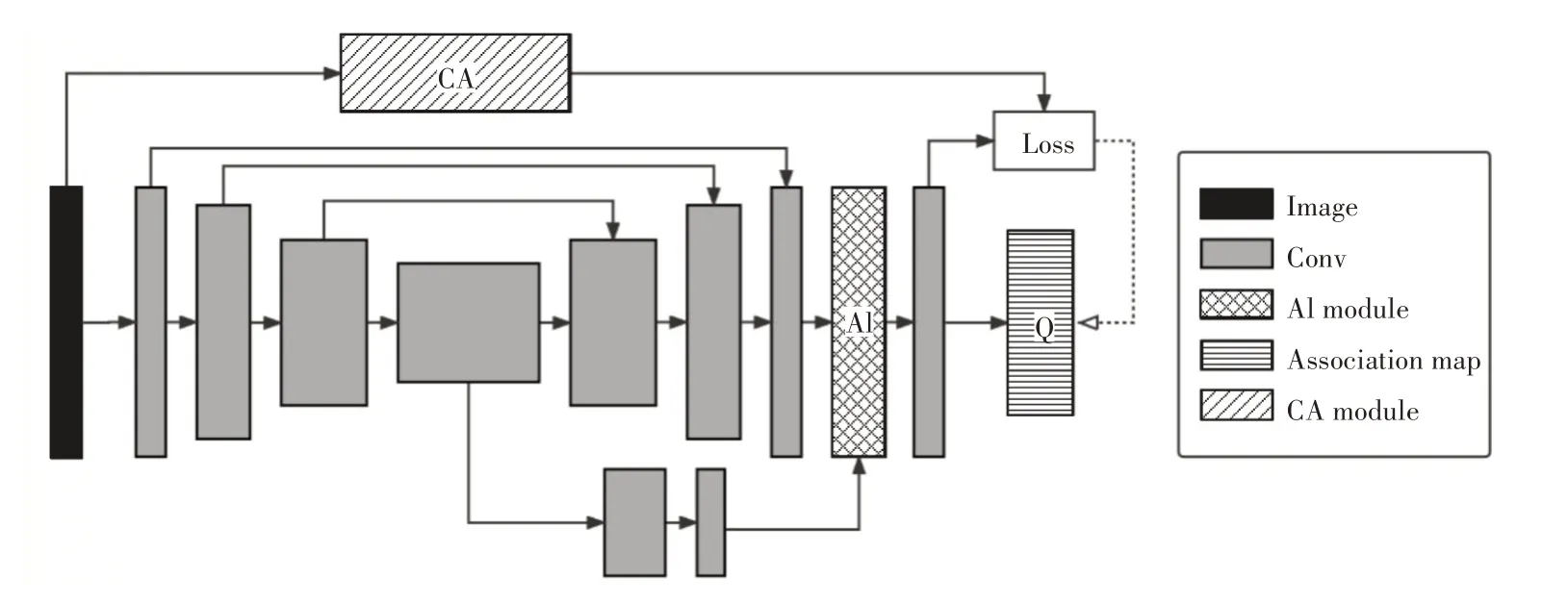
图2 内容自适应超像素网络框架
对输入图像I进行卷积以获得像素嵌入E∊ℝH×W×D,然后将其提供给编码器模块以生成被称为超像素嵌入的特征图C∊ℝh×w×D′,超像素嵌入对网格单元的特征进行了精确编码,其中h=H/S,w=W/S,S是超像素采样间隔。像素p的像素嵌入为ep∊ℝD。使用两个3×3 卷积运算对超像素嵌入C进行扩展,生成植入过程所需的特征图,然后将超像素嵌入提供给解码器模块以重新组装成像素嵌入E′。AI 模块接收超像素嵌入C′和重构像素嵌入E′,并将超像素嵌入植入到像素嵌入中。具体来说,对于像素p从左到右,从上到下选择其9 个相邻超像素嵌入,使用3×3 卷积自适应展开,并在像素周围直接植入适当的超像素嵌入,其中w和b是卷积的权重和偏差。使用式(1)和式(2),遍历E中的所有像素嵌入以创建新的像素嵌入。最后,使用softmax生成像素-超像素关联映射Q。
f(p)表示希望超像素保留的像素属性,例如颜色、纹理和其他特征,而l(p)=[x,y] 表示像素p的图像坐标。给定关联映射Q的任何超像素的中心cs=(us,ls)可以如下所示计算,其中us是属性向量,ls是位置向量。
对于任何像素p,其重构的属性和坐标为
重构损失如下:
其中,CE是交叉熵距离度量,S是超像素采用间隔,m是平衡这两项的权重。
围绕像素嵌入图E的边界对一系列指定大小(如5×5)的补丁B∊ℝK×K×D进行采样,帮助网络适当地分配边界周围的像素。为了简化任务,补丁B仅覆盖来自两个语义区域的像素,即B={f1,…,fm,g1,…,gn},其中f,g∊ℝD,m+n=K2。然后使用分类方法将来自同一类别的特征更紧密地结合在一起,同时保持有着不同标签的嵌入分开。基于分类的损失通过将特征均匀地分为两组来提高对不同语义特征的识别:
其中μf1是f1的平均表示,函数sim(∙,∙)是两个向量的相似性度量:
考虑到所有采样的补丁Bs,边界感知损失为
3.3 内容自适应模块
尽管可以通过修改权重m的值来改变网络生成的超像素的准确性和紧凑性之间的比率,但这种调整会对全局产生影响。过高的权重会使生成的超像素难以匹配图像的边界,导致每个超像素中具有多个不同的语义信息。另一方面,权重过小会在远离边界的区域产生非常不均匀和不紧凑的超像素,即使它们具有相似的特性,也会降低超像素的便利性和结构。通过一个紧凑性因子来动态改变损失函数中的紧密度权重,以使网络能够根据图片内容自适应地权衡准确度和紧密度的权重。
预期生成的超像素将表现出良好的边界粘附性,即在图像边界附近具有很高的精度,而由于远离边界的内部区域的图像特征相似,因此生成规则且紧凑的超像素以保留图像的空间信息。基于这个概念将图像分为两组:边界区域和非边界区域,并为每个区域分配不同的紧凑性因子。为了提取图片的区域划分,应用边缘检测技术来处理输入图像,得到图像的边缘特征图M∊ℝH×W。由于需要使用特征图作为动态权重来指导准确性和紧凑性,对生成的边缘特征图进行标准化操作。此外,为了保证边界区域依旧考虑一定的紧凑性,非边界区域依旧考虑一定的精度,对动态权重的上下限进行了一定的限制。最后计算出权重因子,其中表示每个像素p的权重(在本文中
在本文中使用边缘检测网络BDCN 来获取边缘特征图M。
结合内容自适应模块的重建损失函数为
网络的总体损失函数为
4 实验及结果分析
4.1 数据集
为了测试方法的有效性,本文在两个公共基线BSDS500[19]和NYUv2[20]上进行了试验。BSDS00 数据集共有500张图像,图像的尺寸为321×481像素或481×321 像素。因为其具有由各种不同专家标记的多个语义标签,可以在这些图像上进行语义分割和边缘检测。为了进行公平的比较,本文遵循过去的研究方法[16~18,32]并将每个标注视为不同的样本。NYUv2数据集是一个室内场景理解数据集,包含1449 张带有对象实例标签的图像。Stutz 等[33]删除了边界周围未标记的区域,并对大小为608×448像素的400 张测试照片的子集进行了超像素评估,以评估超像素方法。在BSDS500 数据集上,根据Yang[17]和Wang[16]的建议运行典型的训练和测试工作流程。在BSDS500 上训练的模型直接应用于NYUv2 数据集,并在400 个测试数据上展示结果以评估模型的泛化能力。
4.2 实验细节
随机裁剪的208×208 像素大小的图像用作训练阶段的输入,网络使用Adam 优化器[34]进行4k 次迭代,批量大小为16。最初学习率设置为8e-5,经过2k 次迭代后变为原来的一半。由于采样间隔设置为16,编码器组件执行四次卷积和池化过程以产生13×13×256 大小的超像素嵌入。解码器组件使用四个卷积和反卷积过程生成形状为208×208×16 大小的像素嵌入。超像素嵌入经过两次卷积压缩,然后作为13×13×16 大小的特征图发送到AI 模块。像素嵌入受到补丁大小为5 的边界感知损失的影响。然后将两个卷积层结合起来预测关联图Q,其形状为208×208×9。Wang的方法[16]要求首先使用第一项LCA训练网络进行3k 次迭代,然后使用边界感知损失LB对其进行1k次迭代微调。对于位置重建损失,m设置为0.003/16,对于内容自适应特征,设置为[0.3,0.8]。本文使用Yang[17]相同的方法在测试阶段产生不同数量的超像素。
与各种超像素方法进行性能比较,包括SLIC[11]、ETPS[35]、ERS[14]、SEEDS[36]等经典方法,以及SCN[17]和AINet[16]等深度学习方法。使用OpenCV 实现SLIC 和SEEDS。对于其他技术,则使用其作者推荐的设置和官方的实现方法。
4.3 评价指标
为了分析超像素的性能,本文采用了四个突出的指标:可达到的分割精度(ASA)、边界召回(BR)、边界精度(BP)和紧凑性(CO)。ASA 分数是指超像素标签分割性能的上限,而BR和BP分数与超像素模型识别语义边界的能力有关。通过将每个超像素的面积与具有相同周长的圆的面积进行比较,可以确定超像素的紧密度(CO)。超像素分割性能越好,这些指标的值就越高。在Stutz[33]等的文章中,对这些指标进行了更详细的描述和分析。
4.4 结果分析
在BSDS500 和NYUv2 测试集上的定量比较结果如图3~8所示。通过使用深度卷积网络,CANet、SCN和AINet方法可以胜过标准的超像素算法。当超像素数量最少时,本文提出的CANet具有更高的ASA分数和略低的CO分数。随着超像素数量的增加,ASA分数略微下降,但CO分数却得到了显着改善。因为当超像素太少时,使边缘粘附更重要。当超像素数量较多时,每个超像素的像素较少,两个超像素被边界分隔的可能性较小,紧凑性更为重要。因此,这种变化符合预期。在BSDS500数据集上,CANet 可以显着优于标准方法,如图3~5 所示。在BR-BP得分上,CANet也可以超过深度网络方法SCN 和AINet。适应NYUv2 测试集时的性能见图6~8。

图3 数据集BSDS500上的ASA分数比较
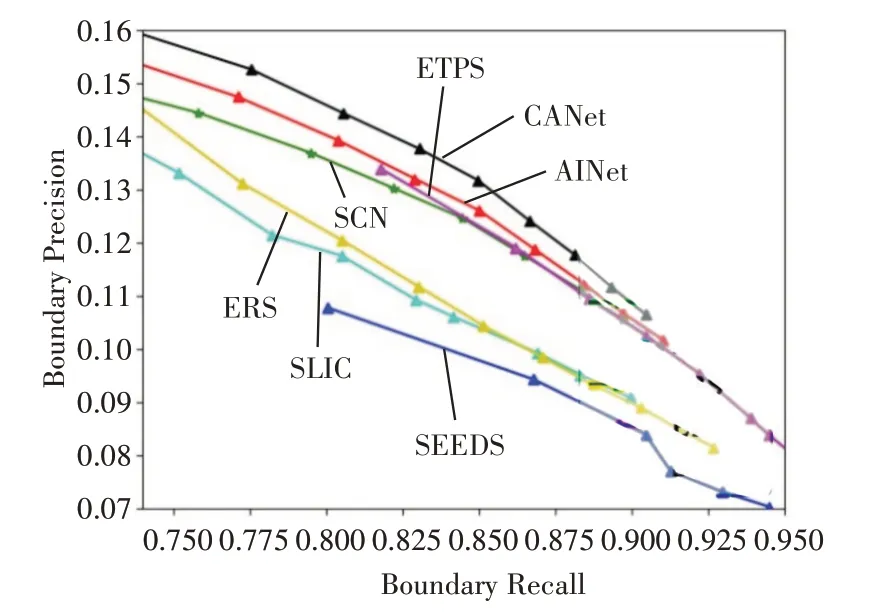
图4 数据集BSDS500上的BR-BP分数比较

图5 数据集BSDS500上的CO分数比较

图6 数据集NYUv2上的ASA分数比较
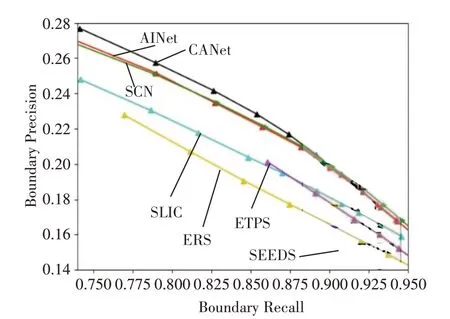
图7 数据集NYUv2上的BR-BP分数比较
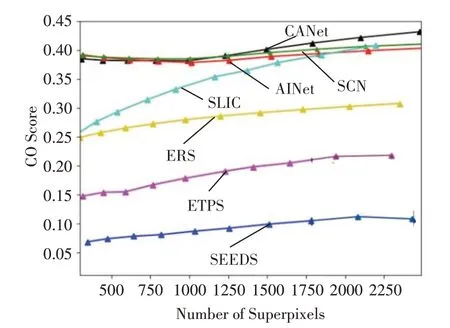
图8 数据集NYUv2上的CO分数比较
可以看到CANet 也有更好的泛化能力。三种最新方法在数据集BSDS500 和NYUv2 上的定性结果如图9和图10所示。相较而言,显示的结果确保了非边界区域的良好边界粘附性和更高的紧凑性。该方法的优越性在视觉上得到了证明。

图9 数据集BSDS500上的超像素分割结果

图10 数据集NYUv2上的超像素分割结果
4.5 推理速度
除了性能之外,推理速度也是一个需要考虑的重要因素。使用BSDS500 数据集研究了三种基于深度学习的方法的推理效率。本文只计算网络推理和后处理过程的时间,以确保比较的公平。所有方法都在同一个工作站上运行,该工作站有一个NVidia GTX TITAN X GPU和一个Intel E5 CPU。三种基于深度学习的方法CANet、AINet 和SCN 的时间成本如图11 所示。由于SCN 方法具有简单的架构,因此它是解决推理问题的最有效方法。由于在AINet 中添加了更多的层和进程,推理速度比SCN略慢。CANet介于二者之间。
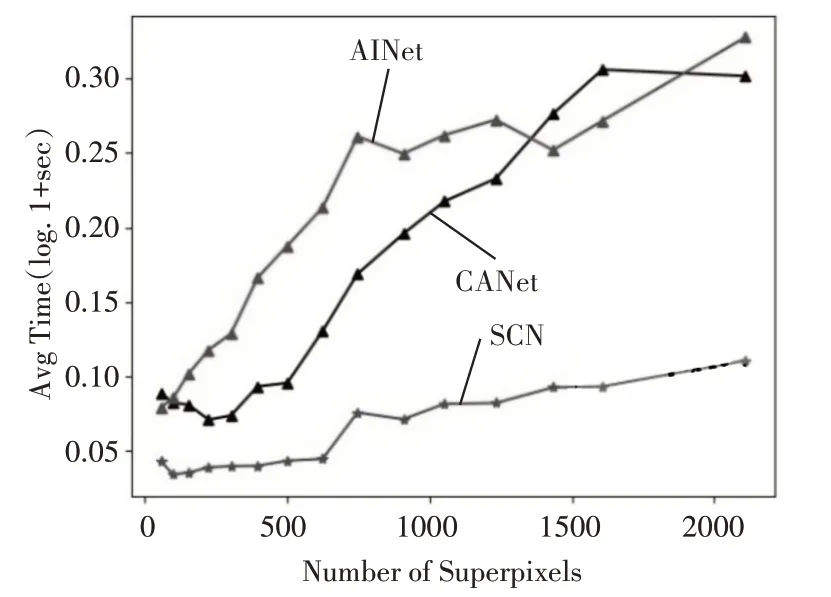
图11 三种基于深度学习的方法的平均时间成本
5 结语
本文提出了一个内容自适应超像素分割网络,可用于生成粘附边界的超像素,并且在远离边界的区域中保持紧凑性,从而降低精度-紧凑性之间的权衡。在两个广泛使用的基准上的实验表明,该方法具有出色的性能和效率,以及高度的泛化性。
