融合语义特征和统计特征的虚假招聘检测模型∗
2024-01-23谢宁宁杨新凯
谢宁宁 杨新凯
(上海师范大学 上海 200000)
1 引言
近年来,网络招聘已逐步成为企业招聘人才的首选方式。然而,网络招聘平台由于其开放性以及相关制度不健全等原因,使得一些不法企业可以利用其功能发布虚假招聘信息,吸引求职者上钩,谋取不正当利益。虚假的招聘信息可能使求职者陷入就业诈骗,造成经济、精神损失。更有甚者,部分求职者被骗入传销组织,危害人身安全。虚假招聘信息是指不以招聘人才为目的或招聘内容具有煽动性且缺乏真实性的招聘信息。将虚假招聘信息检测抽象为二分类问题,通过算法区分出招聘信息的真假,可以有效降低就业诈骗的发生率。
2 相关工作
目前常用的虚假信息检测方法有基于统计特征的机器学习方法和基于语义特征的深度学习的方法[1]。Vidros 等基于文本挖掘的方法,对招聘信息中特殊短语、HTML 元素等进行分析,提出了21个基本特征表示招聘信息,使用随机森林进行分类[2~3]。Mahbub 等对公司介绍进一步挖掘,将公司介绍中是否提供网址、网站成立是否大1 年等统计特征加入到基本特征集中,提升了模型性能[4]。lal等沿用了Vidros 提出的21 个基本特征,使用集成方法构建虚假招聘信息检测模型[5]。Alghamdi 等使用SVM 进行特征选择,提升了随机森林的预测效果[6]。Mehboob 等首先基于企业特征、职位特征和薪资特征构建了24 个统计特征表示招聘信息,然后使用互信息和相关系数选择了13 个重要特征,输入XGBoost 进行分类[7]。李力钊[8]、李奥[9]等将谣言检测问题抽象为基于语义特征的文本分类问题。马鸣将语义特征和统计特征结合,识别谣言信息[10]。黄学坚等将谣言内容的语义特征、统计特征和用户特征融合,提升了谣言检测的准确率[11]。研究表明,在语义特征中,引入辅助特征能够有效提升模型的准确率。考虑到职位描述语义对于区分招聘信息的重要作用和级联森林优秀的分类性能[12~13],本文提出一种融合语义特征和统计特征的卷积级联森林检测模型。
3 卷积级联森林检测模型
Word2Vec-CNN 是一种提取文本语义特征的基准模型,常用于情感分析领域[14]。本文的研究是在Word2Vec-CNN 的基础上进行的。本文提出的模型一共包含四个部分,首先,基于招聘行为分析构建招聘信息的统计特征。其次,使用Word2Vec-CNN 提取职位描述的语义特征。然后,将招聘信息的统计特征通过全连接神经网络映射成和语义特征相同的维度,进行融合特征。最后,将融合后的特征向量输入级联森林分类器检测虚假招聘信息。
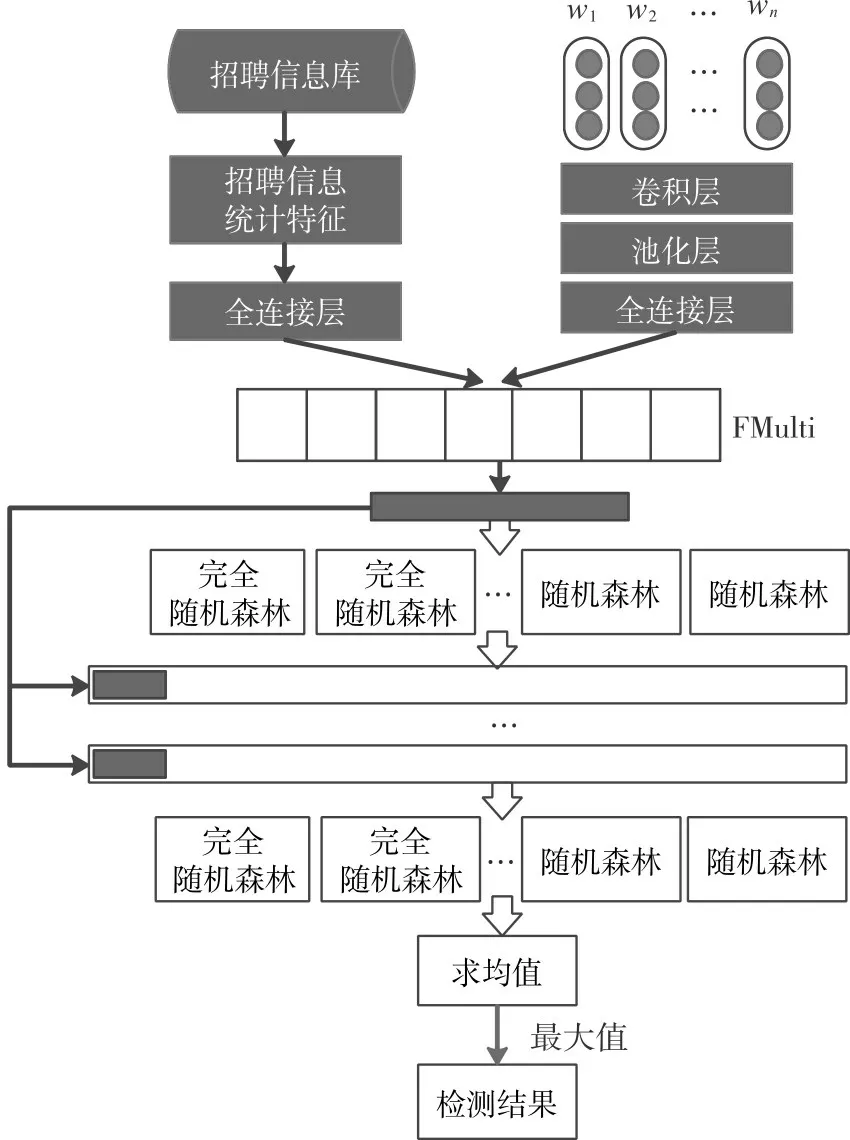
图1 检测模型框架
3.1 统计特征提取
基于文献研究[15],从企业信息、职位信息和薪资信息三个方面分析招聘行为的差异,提取统计特征。
基于企业信息的统计特征描述了企业的可信度。可信度越高的企业,越重视企业形象的维护,发布虚假招聘信息的可能性越低。从招聘信息库中抽取基于企业信息的统计特征为企业名称(FE1)、企业性质(FE2)、企业介绍(FE3)、实名未认证(FE4)、企业规模(FE5)。
基于职位信息的统计特征描述了求职者需要完成的工作、应当承担的责任和胜任职位的基本要求。真实职位的职位描述一般是客观的,没有明显的感情倾向。虚假的招聘职位通常使用感叹号、问号加强语气或在子标题处标注薪资,诱导求职者投递简历。从招聘信息库中抽取基于职位信息的统计特征为职位标题(FP1)、招聘人数(FP2)、学历要求(FP3)、经验要求(FP4)、工作地点(FP5)、子标题包含薪资信息(FP6)、职位描述中包含感叹号的数量(FP7)、职位描述中包含问号的数量(FP8)。
王春鸽的研究表明招聘职位的薪资明显高于同类职位的薪资水平时,求职者需要警惕职位的真实性[16]。从招聘信息库中抽取基于薪资信息的统计特征为职位工资(FC1)、福利(FC2)。
将特征离散化处理,使用式(1)计算招聘信息的统计特征FSta。
式中,FSta 表示招聘信息的统计特征,⊕表示特征级联操作。
3.2 语义特征提取
卷积神经网络包含卷积、池化、全连接等操作,具有卓越的特征提取能力,使用CNN 提取特征可以降低人工提取特征难度。将职位描述文本信息表示成计算机可以识别的词向量输入卷积神经网络。首先,经过卷积层,使用大小不同的滑动窗口进行卷积,提取语义特征。然后,经过池化层进行降维,筛选关键特征。池化层后加入Dropout,设置Dropout 率为0.25,防止过拟合。最后,经过全连接层转化为一维向量。基于卷积神经网络的语义特征提取算法如下。
Step1:去除招聘信息中的非文本部分和停用词,使用jieba 中文分词库将招聘信息进行中文分词。
Step2:利用Word2Vec 将分词处理后的招聘信息表示成词向量T=[w1,w2,…,wn],其中wi表示招聘信息的第i 个词的向量表示。每个词向量wi=[v1,v2,…,vm],m表示招聘信息词向量的维度。
Step3:将招聘信息的将词向量表示输入卷积层,提取高层语义特征FSemk,卷积层的计算公式为
式中,filterk表示卷积核,Tij表示招聘信息的词向量,Fk表示k层的输出特征,f表示Relu激活函数。
Step4:将卷积层的输出,输入池化层,进行池化运算,计算公式为
Step5:最后经过全连接层,得到语义特征向量FSem=[f1,f2,…,fn]。
3.3 特征融合
为了使招聘信息的语义特征和统计特征携带等量的信息。首先,将统计特征向量通过全连接神经网络映射成和语义特征向量同等的维度。映射公式如下:
式中,FSta' 表示映射后的统计特征向量,f 表示激活函数,W为权重矩阵,b为偏置项。
将映射后的统计特征和语义特征进行级联操作,通过式(5)计算招聘信息的融合特征向量FMulti。
3.4 级联森林结构
定义级联森林有d 层,每一层包含R 个随机森林和R 个完全的随机森林,每个森林包含t 棵决策树。完全随机森林中的决策树会随机选择一个信息增益最大的特征做节点分裂,至叶子节点纯净。而随机森林中的决策树则随机选择个特征子集(k 表示输入特征的维度),然后再选择信息增益最大的特征做节点分裂。对于特征f,其信息增益使用招聘样本的信息熵与条件信息熵的差表示,计算公式如下:
式中,S 表示招聘样本,v表示特征f有v个可能的取值,特征f 将招聘样本划分为v 个招聘子样本,Si表示i个招聘子样本,Pij表示Si中类别为j的招聘职位所占比例,j 表示招聘信息的类别,pj表示招聘样本S中类别为j的招聘职位所占的比例。
将融合特征FMulti 输入级联森林d 层,每颗决策树会计算落入叶节点处的真实招聘信息和虚假招聘信息的概率,然后对同一个森林中所有决策树输出的类概率通过式(10)计算平均值,生成招聘信息的类概率向量PVect。每个随机森林生成一个二维类概率向量,每一层输出4R 个增强特征,将增强特征与输入的特征向量FMuti 级联,输入d+1 层训练,表示为式(10)。
式中,公式中,pjt表示标签为j 的招聘样本落入t 棵决策树的概率,FMultid+1表示级联森林d+1 层的输入向量,表示级联森林d 层的第i 个随机森林输出的类概率向量。
每层训练结束后,都会对分类器的性能进行评价,若没有显著的性能提升,则终止级联过程,自动确定级联森林的深度。然后,对最后一层产生的类概率向量求平均值,选择最大概率值对应的类別作为最终检测结果输出。
4 实验结果与分析
本文采用Anaconda 4.9 和Jupyter Notebook 6.0作为实验平台。实验环境为Windows10 操作系统、Core i7处理器(2.6GHz)、8GB内存。
4.1 实验数据
针对本文研究的问题,爬取了企业在北京、上海、深圳、广州四所一线城市的发布的招聘职位信息。标注了一份17880 的招聘样本,其中5%的招聘职位为虚假职位。将招聘样本的80%作为训练集,20%作为测试集,则实验使用的训练集14304条,用于模型的训练,测试集3576 条用于评估模型的性能。
4.2 评价指标
二分类实验中常用的查准率、查全率作为评价指标。但查准率和查全率为一对相互矛盾的指标,一个指标高会导致另一个指标低。研究中,通常使用F 分数衡量模型的综合性能。在虚假招聘信息检测中,由于虚假招聘职位仅占5%,我们希望检测出更多的虚假招聘信息,需要模型对查全率更敏感。因此,本文使用F2 值和查全率评估模型的性能,计算公式如下:
式中,PreFakeSet表示预测结果为虚假的招聘数据集合,TrueFakeSet表示实际为虚假的招聘数据集合,PreAccSet表示预测正确的招聘数据集合。β取值为2表示F2值。
4.3 对比实验
模型1:从招聘信息中抽取统计特征,然后使用统计特征输入级联森林进行分类。
模型2:使用Word2Vec-CNN 模型提取语义特征,然后使用softmax进行分类。
模型3:融合语义特征和统计特征,然后使用Softmax进行分类。
模型4:融合语义特征和统计特征,使用级联森林结构取代softmax层进行分类。

表1 实验结果对比
1)模型2 相较于模型1,查全率和F2 值有明显提升,说明职位描述的语义可以有效区分虚假招聘信息和真实招聘职位。
2)模型3 较模型2,查全率和F2 值均有明显提升,说明在语义特征中,加入统计特征可以进一步提升模型的性能。
3)模型4 较模型3,查全率和F2 值均有明显提升,说明使用级联森林结构取代Softmax层,可以提升模型的分类性能。
4)本文提出的模型,较其他模型性能更优。
5 结语
基于统计特征的虚假招聘信息检测方法被广泛使用,但是这类方法忽略了职位描述语义的重要性。本文使用卷积神经网络提取招聘信息的语义特征,结合统计特征,使用级联森林对虚假招聘信息进行检测,提升了检测的准确率。虚假招聘信息检测是一个新的研究领域,目前学术界提出的方法和本文提出的方法都只考虑了招聘网站上招聘职位的静态特征,没有将招聘信息发布者的行为特征考虑在内。
