基于合成图像的语义分割任务域适应算法研究∗
2024-01-23徐淑怡
徐淑怡
(南京理工大学计算机科学与工程学院 南京 210018)
1 引言
1.1 研究背景
深度卷积神经网络(DCNN)使计算机视觉领域发生了革命性的变化[1],在诸如图像分类,语义分割,目标检测等多种任务中实现了超高性能[2~5]。这种强劲的表现可归因于目前数量庞大的有标签训练数据集。但对于语义分割任务来说,在数据注释方面需要大量人力物力以获得密集的像素级标签。从CITYSCAPES 数据集获取单个图像的逐像素标签的注释就需要约1h,难度也很高。在数据收集方面,虽然自然图像更容易获得,但在一些领域,例如医学成像,收集数据和请专家精确标记这些数据都非常昂贵。
解决上述问题的一种方法是利用生成的数据参与训练。然而,由于数据集之间存在域位移,因此在合成数据上训练的模型在真实数据集上往往表现不佳。域适应就是解决该域位移问题的一类技术。因此,本文重点是研究用于语义分割的领域自适应算法。这类问题最普遍也最有难度的一种情况是,没有来自目标域的标签可用。这类技术通常被称为无监督域适应。
1.2 研究现状
全卷积神经网络(FCN)的发展[4]见证着域适应研究重点从各种距离度量及其变体[6]转移到以端到端方式学习域不变特征。传统方法在分类问题上取得了成功,然而它们的性能改进无法很好地为语义分割问题所用。这促使我们开发适合于语义分割的域适应技术。
我们专注于对抗性方法。Revgrad[7]通过在特征空间中应用对抗性损失来完成域自适应,而PixelDA[8]和CoGAN[9]在像素空间中进行操作。虽然这些技术适用于分类任务,但很少有针对语义分割任务的方法。目前来说,文献[10]和文献[11]提出解决这一问题较好的两种方法。FCN in the wild[10]提出了两种对齐策略:1)全局对齐,它是文献[7]对分割问题提出的域对抗训练的扩展;2)局部对齐,将其定义为类别特定统计多实例学习问题。另一边,文献[11]提出了课程式学习方法,首先学习估计地标超像素上的图像和局部分布的全局标签分布的简单任务。然后训练分割网络,使得目标标签分布遵循这些推断的标签属性。
2 网络模型原理与实现
我们提出一种方法,该方法采用生成模型来对齐特征空间中的源和目标分布。首先通过使用L1和对抗性损失的组合训练重建模块,将使用DCNN获得的中间特征表示投影到图像空间。然后,通过强制网络学习特征来强制域对齐约束,使得源特征在传递到重建模块时产生类似目标的图像,反之亦然。这是通过采用一系列对抗性损失来实现的。随着训练的进行,生成质量逐渐提高,同时,特征变得更加领域不变。
2.1 模型设计
令X∊RL×W×C为任意输入图像(带有C通道),Y∊RL×W是相应的标签图。给定输入X,我们将CNN 的输出表示为,其中NC是类的数量。是表示CNN 输出的像素位置(i,j)处的类概率分布的向量。源(s)或目标(t)域由上标表示,例如Xs或Xt。
2.2 处理源和目标数据
给定源图像和标签对{Xs,Ys}作为输入,首先使用F 网络提取特征表示。分类器C 将嵌入F(Xs)作为输入,并生成图像大小的标签映射。生成器G重建以嵌入为条件的源输入Xs。在图像生成工作之后,我们没有明确地将生成器输入与随机噪声向量连接,而是在整个G网络中使用丢失层。如图1所示,D执行两个任务:1)将真实源输入和生成的源图像区分为源—真或源—伪;2)产生生成的源图像的像素标签图。
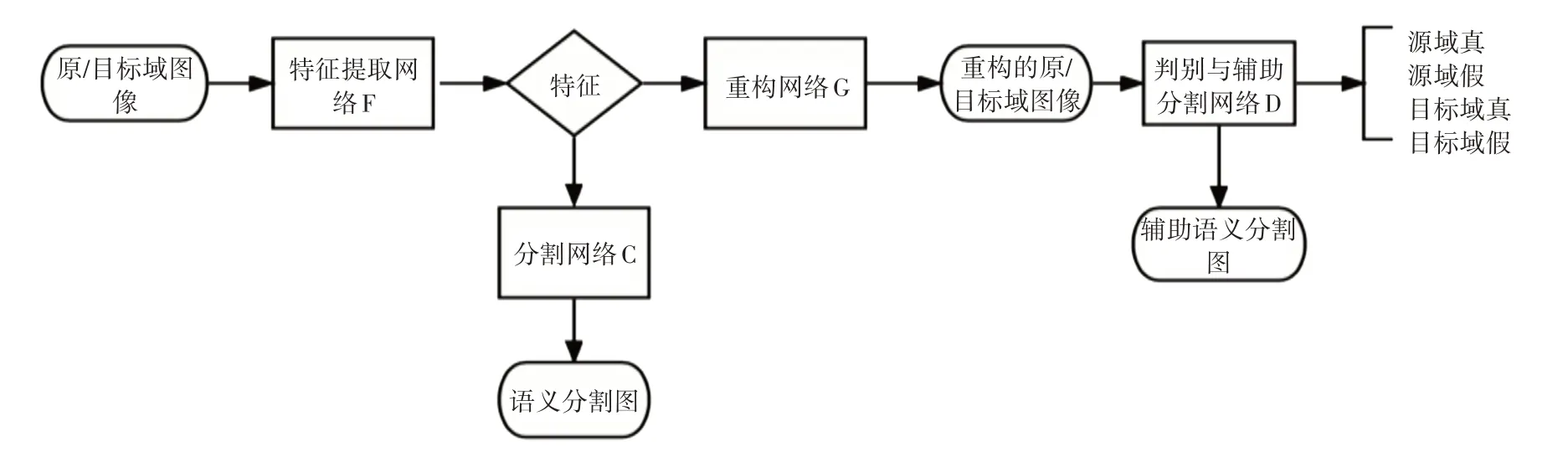
图1 网络模型流程图
给定目标输入Xt,生成器网络G 将来自F 的目标嵌入作为输入并重建目标图像。与之前的情况类似,训练D以区分真实目标数据(目标—真)和从G 生成的目标图像(目标—假)。与前一种情况不同,D 仅执行单个任务,将目标输入分类为目标—真实或目标—伪造。由于目标数据在训练期间没有任何标签,因此当给定目标输入时,分类网络C不活动。
2.3 迭代优化
首先描述方法中使用的各种损失。用于训练模型的不同对抗性损失如表1 所示。除了这些对抗性损失之外,我们还使用以下损失:1)Lseg和Laux像素级的交叉熵损失在分割网络中使用,例如FCN。2)输入和重建图像之间的损失Lrec-L1。

表1 各类损失
3 实验结果与分析
3.1 数据集介绍
SYNTHIA 是具有精确像素级语义注释的虚拟城市渲染照片真实帧的大型数据集。我们使用SYNTHIA-RAND-CITYSCAPES 子集,其中包含9400个带有注释的图像。
使用CITYSCAPES 作为我们的真实数据集。该数据集包含从德国和邻国50 个城市的移动车辆中收集的城市街道图像。该数据集带有5000 个带注释的图像。在本文所有实验中,使用标记的SYNTHIA 数据集作为源域,并将未标记的CITYSCAPES 训练集作为我们的目标域。将来自CITYSCAPES 的val 集的500 个图像指定为我们的测试集。
3.2 实验架构和实施细节
在我们所有的实验中,使用FCN-8 作为我们的基础网络。使用在Imagenet 上训练的VGG-16模型的权重来初始化该网络的权重。图像被调整大小并裁剪为1024×512。我们使用Adam solver 训练我们的模型进行了100,000 次迭代,批量大小为1。F 和C 网络的学习率为10-5,G 和D 网络的学习率为2×10-4。
3.3 实验结果
为了确保实验结果的公平性,我们遵循了先前工作(文献[10~11])所指定的:选择SYNTHIA 和CITYSCAPES 之间的16 个常用类作为我们的标签。对应于其他类的预测被视为属于void类,而不在训练期间反向传播。
表2 展示了我们的方法与文献[10]和文献[11]相比的表现。对于无域适应情况的仅源模型,即仅用源域数据进行训练,本文方法实现了26.9的mIOU。仅目标域模型表示使用CITYSCAPES 训练集(监督训练)训练的模型获得的性能,以它作为域适应性能的粗略上界。我们的方法达到了36.2 的mIOU,将基线提高了9.3个点,与其他方法相比,贡献了更高的性能提升。
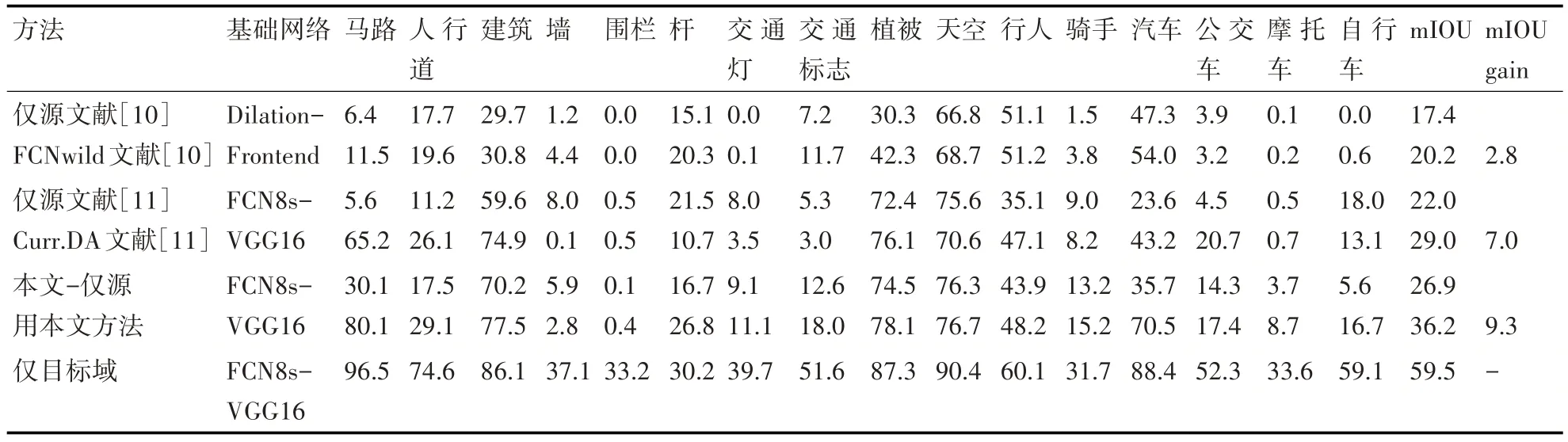
表2 SYNTHIA →CITYSCAPES
4 结语
本文的研究重点是探讨一种适用于语义分割任务的域适应算法,以最大限度地克服语义分割任务中合成图像和真实场景图像之间的域间隙。我们提出一种联合对抗方法,它使用生成器鉴别器对将目标分布的信息传递给特征提取网络。用此方法在大规模数据集上实验并与其他方法对比,实验结果表明了我们的方法优于现有方法,且兼具通用性和可扩展性。
