程序代码集到特征矩阵文本特征提取算法的研究∗
2024-01-23孙令成肖铁军
孙令成 肖铁军
(江苏大学计算机科学与通信工程学院 镇江 212000)
1 引言
随着计算机科技的高速发展,以现代化的网络教学手段解决传统实验教学的不足,学生能够进行线上实验,以现代化的网络教学手段解决传统实验教学的不足,让学生通过网络远程访问实验室设备完成实验的探索势在必行[1]。这可以实现理论教学与实践操作一体化、虚拟仿真和真实环境一体化、教学过程与教学管理一体化[2]。而抄袭现象作为一个一直困扰学术界多个领域的问题,不论是学生作业还是实验设计等,都或多或少存在抄袭现象[3]。
目前已经有多种检测代码抄袭的算法,每种算法也有各自的优缺点。基于KR 和Winnowing 的程序代码相似度检测算法[4~5],李晗[6]基于TF-IDF 的程序代码抄袭检测算法,展佳俊等[7]基于多特征值的源代码相似度检测算法,马申[8]以及Nickolay等[9]基于网络流的代码查重算法,Sanjay 等[10]基于语言不可知代码抄袭分类的可靠代码抄袭检测方法,Feng Zhang 等[11]基于流程图生成的源代码相似性检测,Junaid 等[12]基于索引的文件级粒度可伸缩代码抄袭检测特征提取技术。Lisan 等[13]基于ES-Plag抄袭检测工具的代码查重算法。
本文基于Verilog 语言,从其词法分析识别单词开始,结合TF-IDF算法获取其文本特征值,再通过语法分析使用语法树节点的哈弗曼值作为其结构特征值,联合使用文本特征值和结构特征值构成代码向量,对代码向量使用奇异值分解获取其潜在语义空间,再潜在语义空间上余弦相似度获取学生代码之间的相似度值。实现了一种高效的程序代码集到特征矩阵文本特征提取算法。
2 多维余弦相似度代码特征提取的算法设计
本文提出多维余弦相似度代码特征提取的算法。主要由三部分组成:1)特征值提取模块;2)潜在语义空间获取模块;3)相似度计算模块。
2.1 文本特征值、结构特征值提取模块
为保证每份学生作业文件格式的统一,因此需要对学生作业文件进行预处理。必须删除所有的注释、制表符( )、换行( )以及多余无用的空格。根据Verilog 语言的相关词法以及文本相似度的计算,为了同时体现程序语言的特征和文本语言的特征,先将所有可能识别到的单词分为六类,如表1所示。
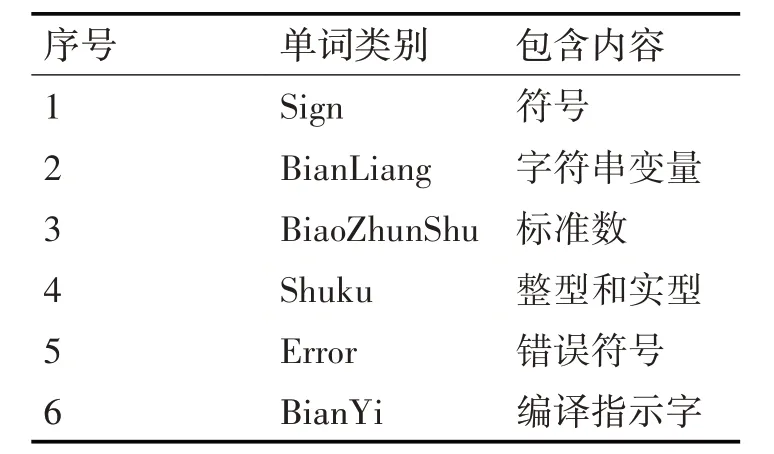
表1 单词类别表
文本特征值的提取流程如图1 所示,首先对每一份作业依次进行词法分析,读取作业文件中的每一个单词并且记录和分类。在读取完该实验项目下所有的学生文件后,再使用TF-IDF 算法计算分类中每一个单词的对应的TF-IDF 值,将该值存储为文本特征值。

图1 词法分析器实现流程图
TF值的计算公式如式(1)所示:
其中ni,j是该单词在文件dj中出现的次数,分母则是文件dj中所有单词出现的次数总和。
IDF值的计算公式如式(2)所示:
|D|是在做完语料库中的文件总数。|{j:ti∊dj}|表示包含词语ti的文件数目(即ni,j≠0的文件数目)。
结构特征值的提取过程分为如下几步:1)生成学生作业的抽象语法树;2)仿照哈夫曼编码,在抽象语法树的基础上获取每个单词的哈弗曼值,并将该值转换成10 进制;3)根据词法分析的单词类别对单词进行分类,相同单词进行均值处理,并用该均值作为结构特征值。
抽象语法树(Abstract Syntax Tree,AST)[13~14]是源代码的抽象语法结构的树状表示,树上的每个节点都表示源代码中的一种结构,之所以说是抽象的,是因为抽象语法树并不会表示出真实语法出现的每一个细节。哈希算法可以把任何一种数据通过散列算法变换成固定长度的输出。
如下的if-else结构的verilog代码:

图2 if-then-else的语法树结构
在抽象语法树的基础上,仿照哈夫曼编码,二叉树中结点引向其左孩子的分支标‘0’,引向其右孩子的分支标‘1’;每个节点的编码即为从根到每个叶子节点的路径上得到的0,1 序列。如此得到的即为二进制前缀编码作为每个单词的哈弗曼对单词进行分类,对于重复出现的相同单词进行均值处理,并用该均值作为结构特征值。
2.2 潜在语义空间获取模块
为了获取更高的计算效率,这里使用奇异值分解完成对矩阵的分解和压缩[15~16]。奇异值分解的计算公式如式(3)所示,且奇异值分解拥有如下两天重要的数学性质:1)一个m∗n 的矩阵至多有p=min(m,n)个不同的奇异值;2)矩阵的信息往往集中在较大的几个奇异值中。
其中,U ∊Rm*r,S ∊Rr*r,V∊Rn*r且r=rank(A)为矩阵A的秩。
在文本信息处理领域中,这三个矩阵有着非常重要的意义。矩阵U 是矩阵A 经过变换后的标准正交基,每一行对应特定词项,列向量代表文档集中不同的语义维度,(Ur)is给出的文档i 和第s 个语义维度之间的强弱关系。矩阵S 是一个对角矩阵,对角线上的元素是A 的全体奇异值,按行递增排序,表示了矩阵V 中的向量和矩阵U 中对应向量的比例关系。矩阵V 是原始域的标准正交基,每一行对应一个特定的文档,每一列代表文档集中不同的语义维度,(Vr)js给出的是文档j 和第s 个语义维度之间的强弱关系。
由于一个矩阵的信息往往存在与较大的几个奇异值中,因此根据式(3)可以推到出表达式(4)。
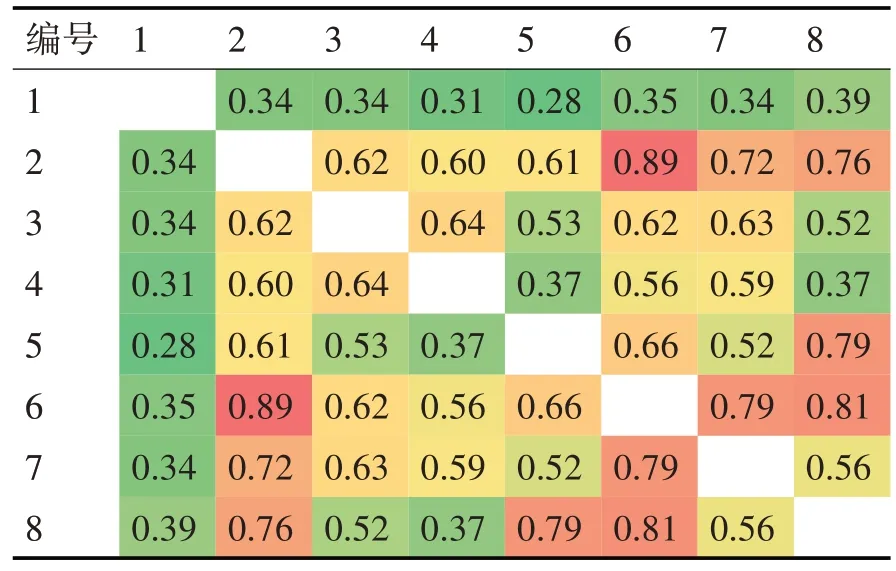
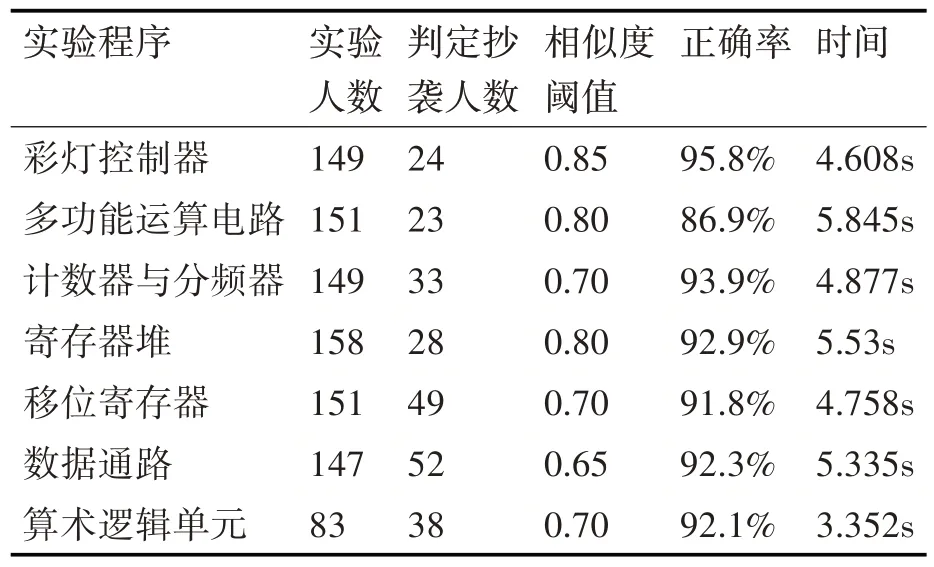
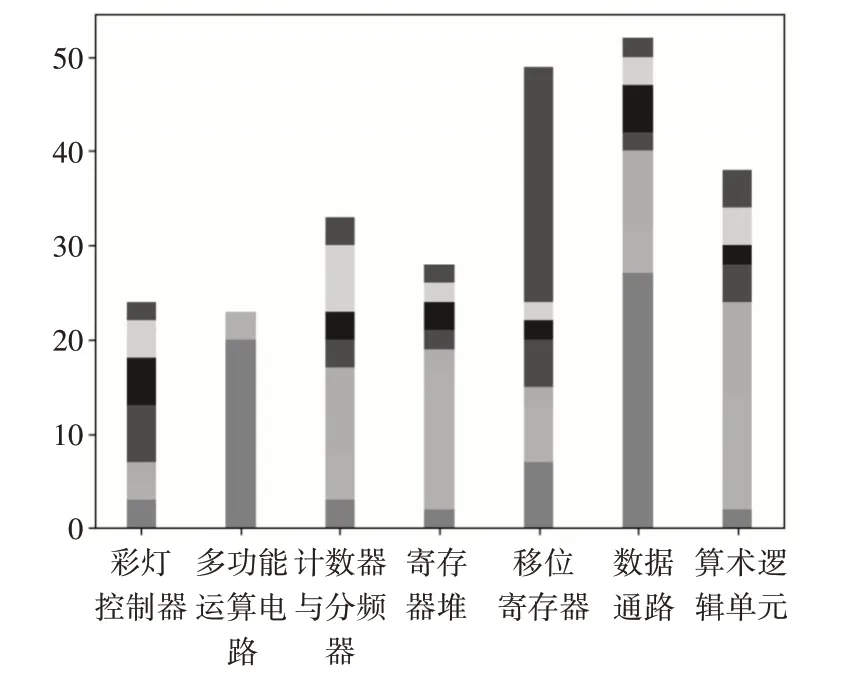
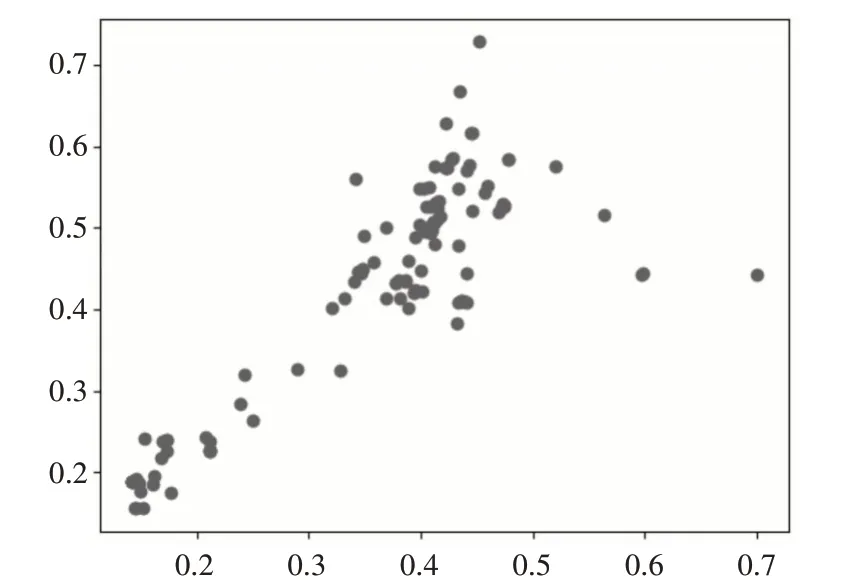
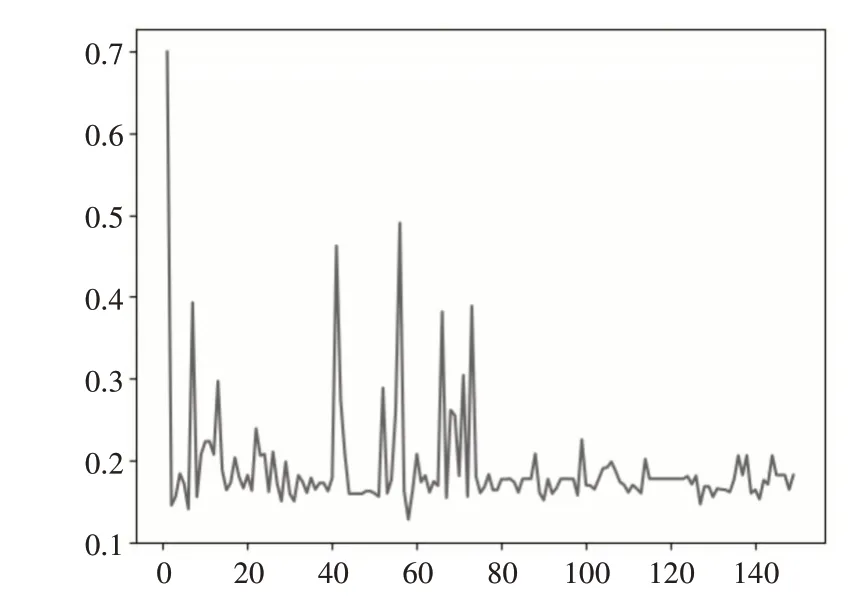
其中k=rank(A)< U ∊Rm*r的全体列向量所组成的r 维线性空间构成文本的潜在语义表示空间,A 中的任一文档可通过Uk映射到该空间得到其在潜在语义空间上的表示。由式(5)推导过程可得原始文档集在潜在语义空间上的表示。 由于使用的TF-IDF算法计算得到的文本特征值,且结构特征值的计算也是基于文本特征值的。所以每一份实验的每一位学生的代码分别按照都可以映射到六个相同维度的向量空间上,此处以符号类别为例,按照单词先后出现的顺序构造出一个M 维的向量,每一位学生的代码可以构成两个向量,一个基于文本特征值的向量,一个基于结构特征值的向量。对于这两个特征值向量取平均作为学生代码的特征值向量,这样的特征值向量有六个。这样N 位学生的代码可以组成6 个N*M 维度的矩阵。通过奇异值分解和潜在语义空间构造得到的代码矩阵也会有六个。 余弦相似性是通过计算两个向量的夹角的余弦值来表明两者的相似性。由于余弦相似度是通过计算两个向量之间夹角的余弦值得到的,并以此衡量两个个体间的差异。在文本标准化工作中,常用编辑距离度量两个文本的相似度[11~12]。 在文本匹配的算法中,假设属性向量A 和B 是文档中的词频向量,即可以被看作是在比较过程中把文件长度正规化的方法。设文档A 中共有j个单词,文档B 中共有k个单词,两篇文章共有n 个不同的单词,则有: 由于两个向量间的余弦值可以通过欧几里得点积公式求出: 则可以得到余弦相似度similarity 的计算公式如下: 在1.2 节中,一份学生代码通过奇异值分解可以得到6份向量,记作: 其中Ci表示原学生代码在潜在语义空间上的表示,n为该潜在语义空间的维度。 经过在本算法中为各类别定义的权重如表2所示。由此可以得到相似度的计算公式: 表2 单词类别权重表 其中i 为单词分类,共有六类,ni为每一类单词在潜在语义空间上的维度,ASi,j、BSi,j为每一份作业文件的潜在语义空间的向量表示,Pi为每一类单词的权重分。 本设计的实验数据源自于江苏大学的远程FPGA 实验平台上的2019 级信息安全专业的《逻辑与CPU 设计实验》学生的作业。在获取数据的时候,首先要提取出每一份作业中的程序代码,再将其命名为“学院-专业-班级-学号-姓名.txt”的形式。之后再运行实验程序进行读取计算学生代码作业的相似度。在计算完成后,分别输出任意两个学生之间的相似度表格与相似度信息的文件。本设计共采取了三组作业文件进行对照和比较算法效果,分别是存储器实验、单周期控制器实验以及七段译码器实验,再选取七份实验进行验证,分别是彩灯控制器、多功能运算电路、计数器与分频器、寄存器堆、数据通路、算术逻辑单元的实验。各个实验文件的代码均具有一定的Verilog 语言特色,具有代表性。 学生代码的评价结果包括存在抄袭现象和不存在抄袭现象两种结果。本文基于召回率(Recall)和精确率(Precision)作为衡量算法准确性的指标。两个指标的计算公式如式(12)、(13)所示。 其中P 表示精确率,R 表示召回率,TP 表示正类预测为正类(计算得出抄袭,人工检测也是抄袭),FN表示正类预测为负类(计算得出非抄袭,人工检测是抄袭),FP 表示负类预测为正类(计算得出抄袭,人工检测非抄袭),TN 表示负类预测为负类(计算得出非抄袭,人工检测非抄袭)。 为展示学生代码之间的相似度情况,制作了作业相似度矩阵。以七段译码器实验为例,在表3中,展示了8名同学代码之间的相似度情况,编号1至8 分别表示不同的学生,而矩阵中的数值则代表该作业的加权余弦相似度,其数值越高,在表中的底色越红,表示这两位同学代码作业的相似性越高;而数值越低,在表中的底色越绿,表示这两位同学代码作业相似性越低。其中,有几位学生的相似度较高,分别是2号和6号、6号和7号、6号和8号。 表3 七段译码器学生作业相似度矩阵 如图6 所示,打开2 号与6 号的学生的代码进行人工核查,发现两位学生代码除了空格与大小写,其他地方包括变量名都一模一样,作业相似度的确较高,属于抄袭范畴,其他几位也与该对作业相似,但是由于实验完成人数较少,且该份代码作业中的标准数均已经由教师给出,很难有说服力,因此需要使用完成人数更多的实验进行验证。 由于完成存储器与单周期控制器的实验人数较多,因此此处以这两个实验作为测试用例,拿存储器实验来说,在将一个班级的学生作业放入程序中运行后可以得到整个班级任意两个同学之间的相似度。由于实验完成学生数量较多,将每个人的作业同时与其他所有人的比较后再查看其抄袭程度,不论是算法查重检测,还是后续人工核查,其效率都较低,因此这里首先选取每个学生作业相对于其他学生作业中最高的相似度值,再选取一定的阈值,对学生作业分别进行人工抄袭检测,这样对于任意一个同学,只要与其代码作业相似度最高的作业进行比较即可,再通过计算召回率与精确率,判断该算法的合理性,具体结果如表4所示。 表4 余弦相似度统计表 在该实验中,共有77 个学生提交了作业,而根据表14 可以了解,如果省去教师人工查重的步骤,根据实验的难易程度,大约选取相似度阈值为前20%~40%的学生判定为抄袭最为合理。一定程度上证明了该算法的合理性。再选取剩下7 个实验作业进行验证,在通过程序过后,分别得到如表5所示。 表5 验证程序正确率 为方便教师对教学效果的审查,制作了如图4的堆叠条形图,它基于学生代码之间的相似度值总结了每个实验任务的小团体,每一个团体的人数都多余两人,对于低相似度的学生没有计入图表中。根据该表的情况,教师可以了解到对于每次实验任务的完成情况,学生是否有大面积抄袭情况的发生。在多功能运算电路、移位寄存器、数据通路这三个实验中,都存在这一个较大的团体,该团体成员的作业相似度较高。图5 展示的是多功能运算电路的相似度散点图,根据改图可以发现,在该实验中存在者两个团体,其中一个团体的规模较大,该情况与图4 反映的结果一致。教师可以根据该图发现班级在该实验过程中的抄袭情况,从而进行教学内容的改进。图6 展示的是多功能运算电路中某一名学生与其他学生作业的相似度折线图,教师可以通过这张图对某一位学生进行详细的观察。通过该表发现,该学生与另一名同学作业的相似度高达0.7,这样就有大概率的可能出现了抄袭现象。 图4 学生实验代码相似小组分类情况 图5 多功能运算电路的相似度散点图 图6 一名学生与其他学生作业的相似度折线图 本文提出并实现了一种高效的程序代码集到特征矩阵文本特征提取算法,根据程序设计语言的特征对代码进行分类,基于Verilog 语言,从其词法分析识别单词开始,结合TF-IDF 算法获取其文本特征值,再通过语法分析使用语法树节点的哈弗曼值作为其结构特征值,联合使用文本特征值和结构特征值构成代码向量,对代码向量使用奇异值分解获取其潜在语义空间,再潜在语义空间上余弦相似度获取学生代码之间的相似度值。该算法从编译层的角度实现了抄袭检测,效率较高,且对于学生代码作业的抄袭检测率效果较好,可以帮助教师更好地完成教学工作。2.3 相似度计算模块

3 实验与分析
3.1 实验数据
3.2 实验评价标准
3.3 实验结果分析

4 结语
