基于PointPillars 改进的点云目标检测算法∗
2024-01-23何俊杰任明武
何俊杰 任明武
(南京理工大学计算机科学与工程学院 南京 210094)
1 引言
目标检测[2]作为一种重要的计算机视觉技术,能够高效地分类和定位场景中的目标。随着人工智能技术发展,基于深度学习的目标检测[3]方法层出不穷。与此同时,传感器[4]技术的不断突破促使业界对三维目标检测技术产生了需求。三维目标检测技术作为二维目标检测的拓展,更注重对环境中的空间结构信息进行处理,迅速成为学术界和工业界的研究热点,被广泛应用至自动驾驶[5]、机器人[6]等多个热门领域。
根据点云目标检测[7]的方法流程,可分为一阶段(one-stage)的方法和两阶段(two-stage)的方法。早期的点云目标检测方法以两阶段为主,主要包括PointRCNN[8]、PointRGCN[9]、STD[10]、VoteNet[11]等,这些方法能够充分地结合原始点云的空间信息,因此能够取得较高的精度,但计算成本较大,检测效率受限。随之出现了一阶段的点云目标检测方法,直接提取原始点云特征并回归目标检测结果。近年来,Vote3Deep[12]、VoxelNet[13]、SECOND[14]等一阶段方法被不断提出,仅需要单次推理即可得到点云目标检测的结果信息,取得了较高的检测速率。
2019 年,一种名为PointPillars[1]的一阶段点云目标检测方法被提出。该方法提出一种新型的点云特征处理方法,参数量更小,取得了比主流方法显著提高的检测速度,具有很高的工程应用价值。但PointPillars 在特征提取时主要关注点云的局部特征,因此在自动驾驶等领域的实际应用时,对车辆、非机动车和行人等多尺度目标的综合检测能力受限。
本文首先简要介绍PointPillars 方法的整体架构,接着基于多尺度特征融合和3D注意力机制,对PointPillars 的网络结构进行改进,并在KITTI[15]数据集上进行相关测试。改进方法在维持高效率的前提下,对多尺度目标具有更高的检测精度。
2 基本理论
2.1 PointPillars整体网络结构
PointPillars 的主体网络架构如图1 所示,主要由柱状特征提取网络(Pillar Feature Network)、二维特征提取网络和一个检测头(Detection Head)组成。

图1 PointPillars主体网络架构图
单帧待检测的原始点云输入网络后,通过柱状特征提取网络转换为点云数据的伪图像。在柱状特征提取网络中,原始点云数据首先被划分为若干均匀的柱状网格(Pillar),每个柱状网格使用一个九维的向量来表示网格中所有点云的信息。借助柱状划分,整个原始点云就可以使用一个张量进行表示,之后,再借助简化版的PointNet 的思想,通过特征提取和最大池化层对张量进行降维,并转换为类似二维图像的点云伪图像。接下来使用二维特征提取网络进一步进行伪图像的特征提取,最后使用一个类似SSD 的检测头部分来对伪图像特征进行三维包围盒的回归。
2.2 二维卷积部分
输入PointPillars 的原始点云经过柱状特征提取网络转换为一个伪图像后,PointPillars 使用一个二维的卷积神经网络对其进行处理。该二维卷积部分的具体结构如图2所示。

图2 PointPillars二维卷积神经网络结构图
从图中可以看出,该卷积神经网络主要由两个子网络结构组成:第一个子网络对输入的伪图像进行两次下采样操作,不断减小特征图的分辨率,同时提升其特征维度,最终可以得到三个分辨率和特征通道数都不同的特征图;第二个子网络对这些特征图的特征进行融合拼接,首先将这三个特征图进行上采样,把它们的分辨率恢复至相同的大小,接下来对这三个相同尺寸的特征图进行特征融合。具体的融合操作通过一个拼接(concatenation)来完成,在维持特征图尺寸的前提下,对三个特征图的特征通道进行拼接。如此以来,三个尺度的特征图的语义信息能够较好地融合在一起,以提高整个检测方法对多类别目标的检测性能。
3 改进的PointPillars方法
本文提出的方法主要对PointPillars 的二维卷积模块进行改进:首先结合多尺度特征融合的思想,改进原始的一阶段检测流程和相关网络结构,提高其对多尺度信息的提取和检测能力;其次,结合simAM[16]的3D 注意力机制来增强不同尺度下的特征信息。
3.1 基于多尺度特征融合的二维卷积神经网络
PointPillars 将原始点云转换为二维的伪图像后,进行后续的二维特征提取,并对提取后的结果回归目标检测的位置和类别结果。该流程基于RPN 的思想构建二维特征提取网络和后续的检测头,通过one-stage 的形式直接回归结果,虽然兼具高效性和一定的检测精度,但还具有一些问题。首先,原图像仅通过两次下采样得到低分辨率的特征图,该特征图的语义信息不足;其次,该结构没有充分利用低层特征图的空间信息,直接影响了对小尺度目标的检测效果;另外,在上采样还原后,原结构直接进行了通道拼接操作,没有很好地结合高分辨率特征的空间信息和低分辨率特征的语义信息。因此,本文基于多尺度特征融合的思想,对原有的二维卷积网络结构进行改进,改进后的结构如图3所示。
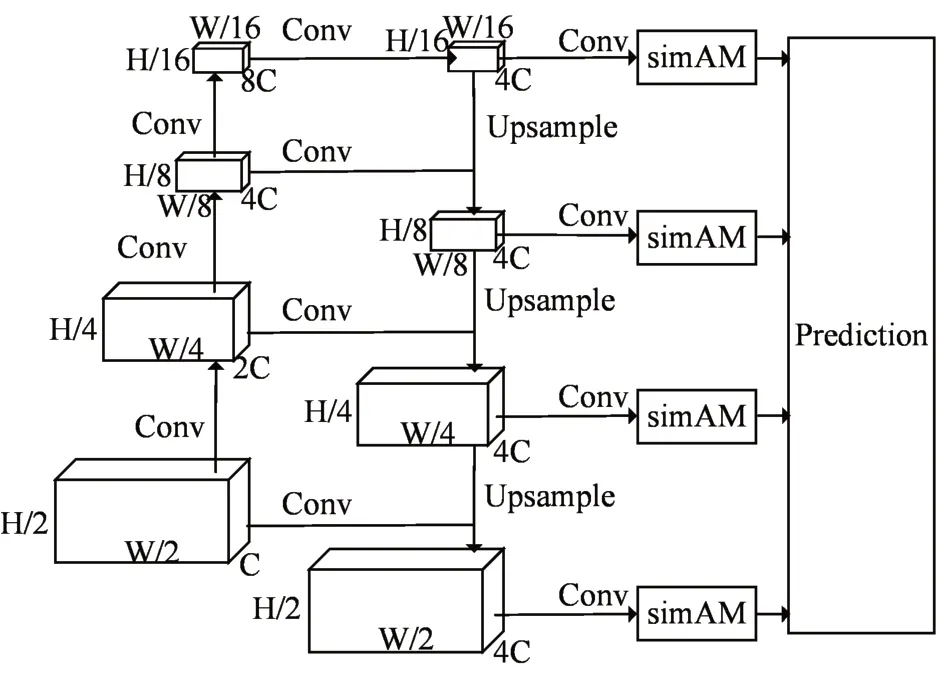
图3 基于多尺度特征融合和3D注意力改进的卷积神经网络结构图
其中,本节对于原有的二维卷积模块进行结构化的改进。首先对原始的特征图进行自底向上的逐级下采样,下采样倍数逐级均匀增加。相比原网络结构,该部分增加了下采样的深度,以更好地结合更小尺度的特征信息。接下来,通过自顶向下的方式进行上采样,具体的上采样通过最近邻插值来进行,在减少计算成本的前提下尽可能保留原特征图的语义信息。特征图在自顶向下进行上采样的同时,与下采样流程中的上一级特征图进行特征融合,得到同时包含语义信息和特征信息的特征图。最后,本结构对融合后的不同尺度特征分别进行卷积核为3×3 的卷积操作,减少上采样插值的重叠带来的影响。如此一来,改进方法对多尺度目标能够具有更强的综合检测能力。
3.2 基于SimAM的3D注意力机制
对原始检测结构进行上述改进后,网络模型对多尺度目标的综合检测能力得到了提升。对于不同尺度的特征,每个特征经过不同层次的融合后都具有较高的通道数。基于此,本文受到SimAM 的启发,基于一种无额外参数的3D 注意力模块来提升对每个尺度特征的利用效率。
其中,SimAM 的3D 注意力权重如图4 所示。相比现有的通道注意力与空间注意力来说,SimAM关注整个特征的3D注意力。为更好地实现注意力机制,该模块评估每个神经元的重要性。在所有神经元中,激活神经元通常会抑制周围神经元,即空间抑制作用。具有空间抑制作用的神经元需要赋予更高的权重。
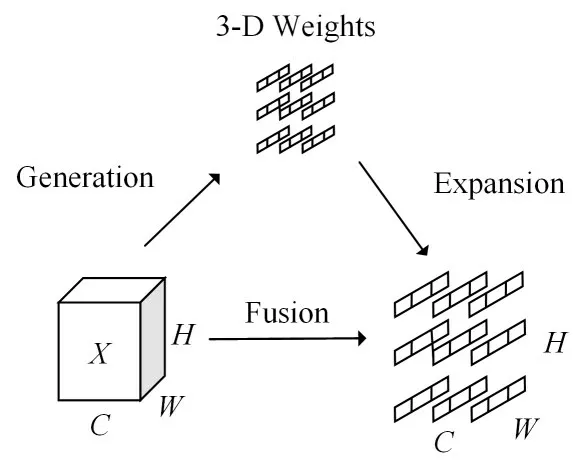
图4 SimAM的3D注意力权重示意图
基于此,该模块使用如式(1)的能量函数来训练神经元之间的线性可分性。对于每个尺寸为C×H×W的多通道特征,其中的每个通道都有M=H×W个能量函数。经过推导,每个能量函数的最小值可以通过式(2)得到。能量越低,神经元的重要性越高,因此其重要性可以通过来衡量。
基于上述原理,simAM 模块通过3D 注意力机制对多尺度的特征进行增强,如式(3)所示。其中,X为原特征,E表示了X特征中所有通道和空间维度的最小能量,sigmoid 函数用于约束可能过大的E值。对X特征中所有具有空间抑制作用的神经元赋予更高的权重,得到增强后的特征。
如图5 所示,在上一节改进卷积网络结构后,本节通过SimAM 模块的优化能量函数推导每个特征的3D 注意力权重,并提升模型对多个维度特征的鉴别能力,最终提升对不同尺度目标的检测效果。
总而言之,simAM 模块促使网络的后续结构更好地学习当前特征图的三维注意力信息,并增强重要的特征,抑制不重要的特征,最终提升模型对多尺度特征的检测精度。
4 实验与分析
为了验证本文方法的实际检测性能,本文基于KITTI 数据集来对提出的改进方法进行检验,并与改进前的原方法进行结果对比。实验使用Pytorch1.3.0 框架,并使用TitanV 显卡进行模型的训练和测试工作。本文使用PointPillars 以及提出的改进方法基于KITTI 数据集进行实验。其中,改进方法的模型训练时的超参数与原方法一致,以进行公平对比。使用的评价指标[17]为对应类别的平均精度(Average Precision,AP),该值越高,检测方法对当前类别的检测精度越高,相关计算公式如式(4)、式(5)、式(6)所示:
其中,式(4)中的NTP代表预测正确的样本数量,NAlldetections代表所有的预测结果数量,p为检测的准确率(precision),表示预测正确的样本占所有样本的比值;式(5)中的NAllgroundtruths代表所有的目标真值(ground-truth),r为检测的召回率(Recall),表示预测正确的结果占所有目标真值的比例。为了衡量多置信度阈值下模型的整体检测性能,引入了准确率-召回率(P-R)曲线这一指标,代表模型在取不同置信度阈值时,对准确率和召回率的取舍。式(6)中的P(R)即P-R 曲线,AP即为P-R 曲线的面积,衡量对应类别的整体检测性能。
使用PointPillars方法和本文改进后的PointPillars 方法,分别使用KITTI 数据集中的验证集,对汽车(Car)和行人(Pedestrian)两种主类别目标进行检测,并比较它们的检测结果。其中,KITTI数据集基于等间距的40 个召回位置(Recall Position)给出对应类别的平均AP 值。实验结果如表1 所示。其中,KITTI 的每一类目标根据遮挡和截断程度分为Easy、Moderate、Hard三个难度级别。

表1 原PointPillars方法与本文改进后的方法在KITTI数据集上的检测结果对比
从中可以看出,相比原方法,本文改进的方法在两种类别的目标检测精度上均有较明显的提升,提升效果约为0.6%到2.8%不等。其中,相比汽车类别,本文改进的方法对行人这类小尺度目标的检测精度提升更明显。另外,表1 还展示了改进后的方法与原方法的测试时间对比。由此可以证明,经过本文改进后的PointPillars方法,不仅对多尺度目标具有更强的检测能力,同时在检测速度上也仅有较小的下降,仍能保留PointPillars方法的检测速度优势,具有较高的工程应用价值。
5 结语
本文结合多尺度特征融合和3D 注意力机制,改进了原方法的网络结构,提出了一种基于Point-Pillars 改进的点云目标检测方法,之后通过KITTI数据集验证了改进方法的有效性。本文改进的方法对多尺度目标具有更高的检测精度,同时仍具有较高的检测效率。
