基于异构特征的强化联邦学习模型融合方法∗
2024-01-23赵潇楚张元杰
禹 发 赵潇楚 谷 牧 张元杰
(1.中国石油大学(华东)计算机科学与技术学院 青岛 266580)(2.中德智能技术研究院 青岛 266071)(3.航天云网科技发展有限责任公司 北京 100039)(4.青岛文达通科技股份有限公司 青岛 266555)
1 引言
AlphaGo[1]在围棋上接连战胜人类顶尖选手李世石与柯洁,让人们逐渐意识到了人工智能(AI)所拥有的巨大能量,期待将其应用到各行各业中来。当AI 真正要落地到各个行业之中时,效果往往差强人意,究其原因,最重要的问题在于数据,大多数行业数据的数量和质量都无法满足AI 技术的需求,大多数行业中,数据都是以孤岛的形式存在,行业中各个企业集团之间存在竞争壁垒,同时涉及到安全和隐私以及其他问题,几乎不可能形成一个统一的完备的行业数据集。随着整个互联网世界对于数据安全性和用户的数据隐私意识的增强,加剧了数据获取的困难性。
数据的隔离和对数据隐私的重视正成为人工智能的下一个挑战,但联邦学习为我们带来了新的希望。
它可以在保护本地数据的同时为多个企业建立统一的模型,从而使企业可以在以数据安全为前提的情况下共同取胜。
联邦学习[2~5]的概念起初由谷歌提出,他们的主要想法是建立基于分布在多个设备上的数据集的机器学习模型,同时防止数据泄漏。最近的改进集中在克服统计挑战[6~7]和提高联邦学习的安全性[8~9]。还有一些研究努力使联邦学习更具个性化[10]。联邦学习的出现使在数据保持不交换的情况下,进行大规模的协同模型训练。
文献[11]中使用联邦学习来帮助训练入侵检测的模型,解决了单个机构数据集有限性而导致的模型泛化性不强的问题;文献[12]基于联邦学习设计了FRL 框架,提高分部学习模型质量,同时在应用于北京PM2.5 监控的实验中表现出了高于中心化训练三到五倍的效率。在边缘计算方面,文献[13]将联邦学习应用于边缘设备的轻量级模型训练上,并在提高准确率的情况下,缩减了模型训练时间。Kwon[14]等将联邦学习应用于水下物联网设备的训练中,并加入了强化学习来对联邦学习中的通信传输进行优化,提高了通信链路的效率。但是,以上对于联邦学习的应用仍存在在需要解决的问题。
由于客户端设备硬件条件(CPU、内存)、网络连接(3G、4G、5G、WiFi)和电源(电池电量)的变化,联邦学习网络中每个设备的存储、计算能力和通信能力都有可能不同,加上联邦网络中设备上数据集数量与质量上的非对称性以及设备算力的差异,各节点训练的模型有好有坏同时联邦这些异构特征给联邦学习的建模、分析和评估都带来了很大挑战。传统的联邦学习算法,会将各个节点上传的模型按照等权重进行平均融合,如果某个节点模型质量差或者存在错误,会影响联邦学习全局的模型准确率,降低效率。
本文提出一种基于异构特征的强化联邦学习模型融合方法,针对于联邦学习中异构特征问题,提高容错能力,保证学习效果,加入强化学习,能够动态地通过联邦网络中个设备的状态信息,调整模型融合时的权值,代替传统的平均融合方法,更好地对全局模型进行更新。
2 基于异构特征的强化联邦学习模型融合方法
为了解决联邦学习中的异构特征问题,需要针对不同的节点情况,在融合时自适应地调整各节点的权值,得到最优的权值进行融合。我们希望这个过程可以自主地进行,并能通过训练次数增加,不断学习,更准确地得到最优权值。而强化学习可以通过代理(Agent)与环境(Environment)不断交互,去学习得到最优结果,这恰恰可以应用于联邦学习的模型融合时,权值的选择。
2.1 联邦学习
联邦学习(Federated Learning)从本质上讲,是一种分布式的机器学习技术,或者称作一个机器学习框架。推动其产生的背景主要分为三个方面:
1)在人工智能纷纷落地于应用后,逐渐暴露出来的问题是数据量的不足,一个高可用的人工智能应用通常需要依赖于大量高质量的数据集训练,现实生活中,极少有企业能满足这一点。
2)全世界各个机构逐步加强了对数据的保护与监管,例如欧盟的《通用数据保护条例》(GDPR)以及我国的《数据安全管理办法(征求意见稿)》,都对数据的流动做了限制。
3)企业数据通常隐藏着企业机密且存在巨大潜在价值,不允许对外开放,这会导致数据孤岛问题。
为了能够在合乎法律规范的情况下,使企业间在不泄露自己数据的情况下,共用数据集,共同训练模型,以达到提高模型准确率与泛化性的目的,联邦学习应运而生。
2.2 强化学习
强化学习[15~16]是机器学习算法的一个分支,它受行为主义心理学启发而产生,同时与早期的控制论、心理学、神经科学和计算机科学都有关系。强化学习指的是仿照人类的学习方法而设计出的智能体,在动态环境中不断重复“动作-反馈-学习”的方式来进行学习,智能体是强化学习的动作实体。对于自动驾驶的汽车,环境是当前的路况;对于围棋,状态是当前的棋局。在每个时刻,智能体和环境有自己的状态,如汽车当前位置和速度,路面上的车辆和行人情况。智能体根据当前状态确定一个动作,并执行该动作。之后它和环境进入下一个状态,同时系统给它一个反馈值,对动作进行奖励或惩罚,以迫使智能体执行期望的动作。
2.3 强化联邦学习模型融合方法
在传统联邦学习中,各节点上传模型,会在中心节点进行融合,生成全局模型,融合时采用平均融合的方法,即
然而由于各节点数据质量,算力和能量等异构性问题,各节点上传的模型质量参差不齐,如果某个节点数据集质量有错、质量差或者机器算力差会导致此节点上传模型对于全局模型的准确率提升没有帮助,甚至会有害,基于此,我们希望在联邦学习的过程中加入一种可以自适应的模型融合方法,能够根据历史的各节点模型信息,动态调节各节点模型的权重,提高有益节点的权重,降低权重甚至舍弃有害节点。强化学习能通过智能体不断与环境交互,通过奖励机制不断学习,达到最大化奖励或者特定目标。于是,我们将强化学习加入到联邦学习的模型融合过程中来,使用强化学习来代替平均融合算法。
本文以强化学习算法DQN(Deep Q-learning Network)为基础,将联邦学习模型融合过程形式化为一个强化学习问题,进行求解。在一个联邦网络中有N个节点:
状态(State):s∊S={s1,s2,s3,s4…sN},表示N节点在模型融合时的准确率以及上一次的权值。
动作(Action):a∊A={A1,A2,A3,A4…AN},表示为第i个节点分配的权值。
奖励(Reward):R 表示在状态s 下执行动作a,得到的奖励值,在本实验中为融合后模型准确率与上一次准确率的差值。
策略(Policy):π表示在状态s 下选择一个动作,表示为a=π(s)。
价值函数(Value function):奖励只代表某一次动作的奖励值,而价值函数是从长期的角度看待动作的好坏,Qπ(s,a)是策略π在状态s下,采取动作a 的长期期望收益,按照策略执行动作后的回报定义为
其中γ∊[0,1]称为折扣因子,表示对未来奖励的看重性,当其为0时只看重现在。状态s的价值为
状态s下采取动作a的动作价值函数Q为
要得使得在状态s 下动作a 得到最好的效果,则应使最大的价值函数取最大值,根据贝尔曼方程(Bellman equation)可得:
a′表示下一步执行的动作,使用深度学习对此进行求解,我们把一个神经网络来作为策略π,称之为Q-network,其输入为状态s,输出为下一步动作a 的q 值,取在接下来状态′下,执行动作a′后最大q值y=r+γmaxa′Q*(s′,a′)为目标解,即可使用均方误差(Mean Square Error),对其进行梯度下降求解,损失函数为
这样,只需要对神经网络的参数θ进行训练,即可得到策略π的最优解。
整个算法流程如算法1所示。
3 实验分析
3.1 实验数据集
一般传统机器学习使用的是独立同分布的数据集,也称IID(Independent and Identically Distributed)数据集,而在实际联邦学习过程中,基于用户设备、地区、习惯等的不同,数据通常是非独立同分布 的Non-IID(None-Independent and Identically Distributed)数据集。为了与实际联邦学习环境相对应,我们在cifar-100 数据集的基础上,进行了重新划分,将其转换为Non-IID 数据集,如图1 所示,左边为原始cifar-100 数据集,右边为划分以后Non-IID的cifar-100数据集。

图1 正常数据分布图
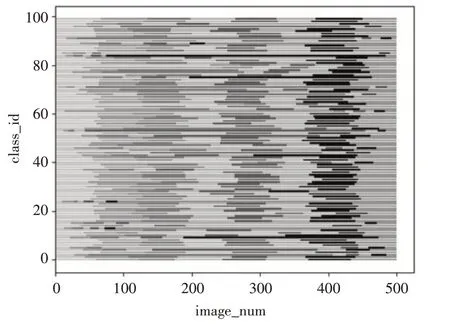
图2 Non-IID数据集
3.2 实验环境
为了模拟联邦学习中异构性的特点,实验中用了多台性能不同的机器当作联邦节点,以此来保证各节点训练出来的模型质量不同,模拟异构性特征,所使用节点信息如表1所示。

表1 实验节点信息
3.3 实验设置
实验在预设的八个节点上进行,使用No-IID数据集进行模型训练,使用网络结构为resnet34,分别使用强化联邦学习模型融合算法与使用传统平均融合算法进行联邦学习过程,比较其结果。
3.4 实验结果
图3 为训练过程中各节点上传模型的准确率,从中可以看出,在Non-IID的情况下,节点8因为数据分布以及机器算力问题,在训练过程中导致了模型准确率一直不高,同时也体现了联邦学习中的异构性问题。
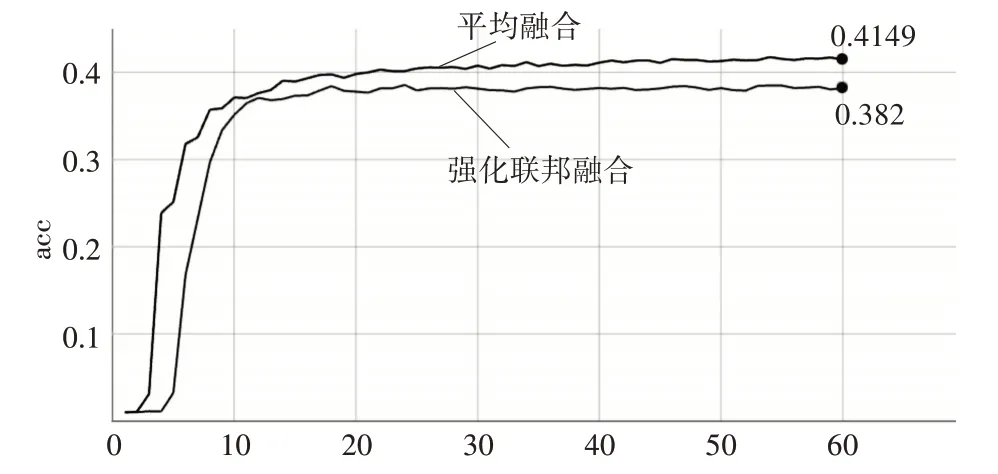
图3 各节点模型准确率
实验结果如图4 所示,在不使用任何训练trick的情况下,传统平均融合算法最后达到38.2%的准确率,使用强化联邦融合算法,弱化了节点8 在融合时的权值,提高了联邦学习鲁棒性,最终到了41.49%的准确率,提高了3.29%。
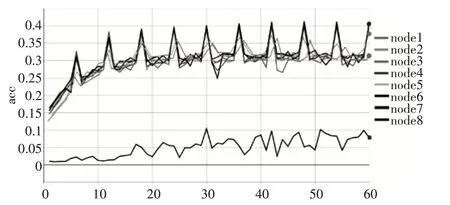
图4 平均融合与强化联邦融合准确率
4 结语
通过实验证明了异构性在联邦学习中的影响作用,同时在联邦学习模型融合过程中,使用强化学习代替传统平均融合,提高了联邦学习的鲁棒性与模型训练的效果。
但是研究仍存在不足,联邦学习除了异构性问题外,联邦学习中更关键的一点是如何抵抗联邦学习中的恶意攻击。在联邦学习中会存在恶意节点,向中心节点发送有毒模型或梯度信息,导致联邦学习无法拟合,实验的下一步研究应放在如何使用强化学习来控制节点权值,以达到免受攻击影响。
