基于深度迁移学习的凤凰单丛茶叶病害识别方法
2024-01-20谢森林王春武董晓庆林一帆
谢森林,王春武,董晓庆,林一帆,王 畅
(韩山师范学院 物理与电子工程学院,广东 潮州 521041)
潮州市是广东省代表茶区、中国乌龙茶四大产区之一、中国工夫茶文化的重要传承地和发祥地,也是国内特色小众茶——凤凰单丛茶的原产地,已建成广东省级茶叶产业园、专业镇、专业村100 多个,茶叶种植面积达23万亩,年初制茶产值超过64亿元,带动就业超过50万人.
潮州地属亚热带海洋性季风气候,具有高温高湿气候特点,茶树易滋生细菌.病害可造成茶叶变色、变形、枯萎、脱落进而影响茶树的生长发育,且部分病害具有传播性,严重的可以影响整个园区,严重影响茶叶产量;病害也影响了茶叶的品质,造成茶汤浑浊、茶味苦涩,给茶农造成严重的经济损失[1].因此及时准确地发现茶树病害的类别,精准防治,对提高茶叶的产量和质量有重要意义.
茶叶病虫害鉴别及防治存在很多难题,诸如茶树病害种类多、某些病症相似性高、不同季节、不同地区有不同的表现等[2-7].由于大部分茶农专业知识匮乏,易出现误诊,而茶园大多依山而建,面积、海拔跨度大,植保专家难以全面开展现场指导.因此,研究有效的茶叶病害自动识别方法具有较大的实际意义.
农作物病害的识别和分类算法,有经典的机器学习方法和使用深度学习网络模型等两种方法.经典的机器学习方法实现植物病害分类是通过病害的特征提取和专家知识完成的,分类器识别性能的好坏,与病害特征描述是否完整,以及专家知识是否正确有关;此外,与分类器设计是否合理、概括性强,且先验知识是否有较好区分度有关.图像特征通常通过形状、颜色、纹理特征来描述,经典算法有SVM、小波分析、灰度分析、直方图分析、灰度共生矩阵等.Sun Y 等[8]提出了一种将SLIC(简单线性迭代聚类)与SVM(支持向量机)相结合的算法,对261 幅病害图像进行测试,准确度达到96.8%.Billah M 等人[9]提出使用小波变换提取彩色茶叶图像特征,基于自适应神经模糊推理系统的茶叶病害诊断系统,在作者的数据库上仅仅以45 张图片作为训练集,30 张图片作为测试集,获得95.7%的识别正确率.以上两种以SVM 和小波分析为代表的经典机器学习算法,优点是模型结构层次较浅、计算量较小、计算时间较短,不需要以大量的图像为基础,即可完成图像的识别分析;另一方面,缺点也同样明显,无法从原图像中获取更高层次的语义特征和深度特征,当受到人为以及外界因素的干扰,图像识别率较低,面对大规模数据集的情况下,若离开人为设计即无法获取图像特征,算法泛化性差[10].近年来兴起的深度学习技术,因其可提取更深层次的图像特征,且图像特征表达更丰富,实用效果较好,应用广泛.如Hu[11]使用GAN 技术扩充仅有120张病害的茶叶数据库,再使用VGG 实现病害分类,获得90%的平均识别率,准确率远高出传统机器学习算法;牟文芊等[12]提出了一种基于SENet和深度可分离卷积胶囊网络的茶树叶部病害图像识别算法,训练数据库来自山东省泰安市茶溪谷人工采摘的15 000 张茶叶图片,最终识别准确率达到94.20%.Zhang 等[13]使用Efficient Net 训练识别2 816 张黄瓜病虫害图片,最高正确率达96.00%;王春山等[14]使用Multi-scale Res Net识别PlantVillage、AI challenge 数据集中三种植物病虫害19 517 张图片,最高正确率达95.95%.上述方法使用深度学习网络对植物病虫害分类开展研究,取得了较好的分类准确率.
深度学习在目标检测、分类的应用上效果出众,但需以大量训练数据为前提[15].另外,不同种类植物病害特征各异,不同产区、不同品种茶叶病害也有所不同,并没有普适性的自动识别方法.如Mohanty等[16]将在PlantVillage数据上训练的深度学习模型,应用于识别另外一个同类型植物数据库上时,正确率下降到50%以下.目前,较多的研究是在高质量的公开数据库上开展的,而基于茶叶病虫害数据库较少,基于潮州凤凰单丛茶的数据库到目前为止未有记载.因此,本文借鉴上述成果,探索基于深度学习算法的潮州凤凰单丛茶病害自动识别的可行性,重点研究:
1)以潮州凤凰单丛茶“鸭屎香”品种为对象,采集自然环境下的不同季节、不同光照条件下的茶叶病害照片,联合潮州市茶叶科学研究中心专家对茶叶病害进行标注,构建高质量茶叶病害数据集.
2)搭建基于深度学习算法的茶叶病害识别平台,选取VGG、ResNet 和Vision Transformer 等三种深度学习算法进行测试,验证潮州单丛茶病害自动识别方法的可行性.
1 茶叶病虫害数据集
茶叶病害图片数据集采样于:饶平县大岽山茶业有限公司茶苗培养基地,构建数据库以本地典型品种“鸭屎香”为研究对象.为了更好还原光照情况,在不同时段和不同天气环境下,以4 024×3 036像素分辨率现场拍摄茶叶病害图片.选用本地产见的三种病害,如图1 所示,分别是云纹叶枯病、炭疽病、赤星病,加上健康茶叶共四类构成数据库.数据集中包含图片1 258张,其中健康茶叶166张、赤星病126 张、炭疽病582 张、云纹叶枯病384 张.它们以8∶2 的比例将数据集分成训练数据集和测试数据集.云纹叶枯病的主要特征是:开始是黄绿色或黄褐色,后期变为褐色,有波状褐色、灰色相间的云纹;炭疽病的主要特征是:先在叶缘或叶尖形成病斑,色泽淡褐色或黄褐色,最后呈灰白色,其上散生黑色小点,病斑无轮纹;赤星病的主要特征是:叶片上产生小型圆形病斑,后扩展成灰白色中间凹陷的圆形病斑,边缘具暗褐色或紫褐色隆起线,中央红褐色,后期病斑中间散生黑色小点.

图1 茶叶典型病害特征图
2 实验设置与实验结果分析
2.1 实验平台和参数配置
实验平台操作系统使用Window10,CPU 选择Intel(R) Core(TM) i7-10700 CPU @ 2.90GHz;GPU 选择NVIDIA GeForce RTX 3080 10GB;CUDA 版本号是11.6.使用Anaconda 配置模型训练开发环境,使用的编程语言是Python3.7,深度学习框架是Pytorch1.9.
本实验选用经典的深度学习算法:VGG16、Resnet34和Vision Transform.为了更好地对比实验结果,三个实验模型均采用相同的参数配置.实验中采用Adam 网络优化算法,在训练中的学习率设置为0.000 1.模型训练过程采用批量训练的方法,Batch Size 大小设置为128,模型处理完全部训练图片和测试图片为一次迭代(Epoch),实验共100个Epoch.
2.2 数据预处理
为了加强数据的多样性、全面性,进而提高模型的泛化能力,实验中将训练图片进行随机范围裁剪、缩放和旋转等操作.为了改善梯度消失和梯度爆炸的问题,使用数据标准化处理,权重初始化,以及通过BN[17](Batch Normalization),达到加速网络的收敛并提升准确率的目的.
2.3 实验结果分析
2.3.1 实验1:使用经典深度学习算法验证数据集可行性
训练结果如图2、图3所示.其中图2是训练误差收敛情况,横坐标Epoch 为迭代的代数,纵坐标train loss代表训练误差.经过100次迭代训练,Vision Transform 误差稳定在1.04左右,VGG16稳定在0.64,Resnet34 稳定在0.23,误差总体较大.图3 是验证集的识别准确率,其中Epoch 表示迭代的代数,纵坐标表示验证集识别准确率.经过100次迭代训练,Vision Transform 验证准确率稳定在55%左右,VGG16验证准确率平均值69%,Resnet34验证准确率平均值77%,准确率未达实用要求.
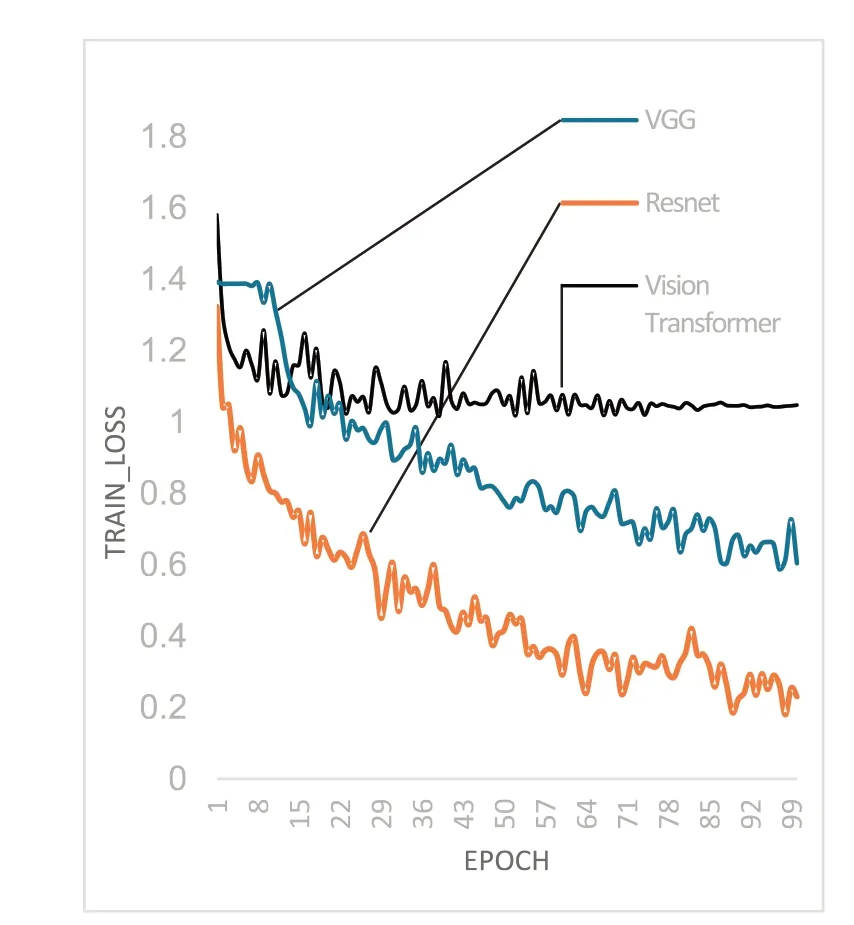
图2 无迁移学习训练误差收敛情况
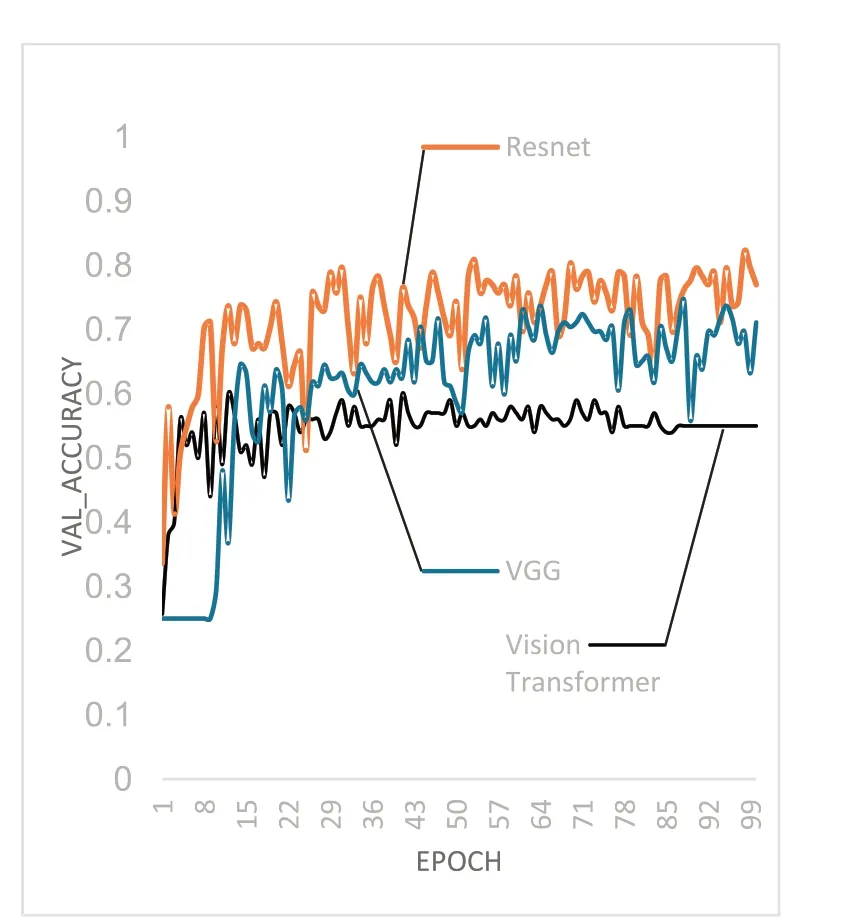
图3 无迁移学习验证集的识别准确率
实验结果表明:1)同样是使用卷积来提取特征的深度学习网络,Resnet 比VGG 网络有更快的收敛速度和更高的验证精度,原因是Resnet网络中加入残差结构,使得误差可以传播到更深层网络,一定程度上解决了网络退化问题,使得Resnet可以拥有更深的网络和更好的训练效果.2)Vision Transformer网络,在识别率和收敛速度的表现上都不如VGG 和Resnet网络.原因是Vision Transformer 结构缺少一些CNN 先天的归纳偏置(归纳偏置指的是卷积结构带来的先验经验),比如平移不变性和包含局部关系,因此在规模不足的数据集上表现没有那么好[17].
2.3.2 实验2:加入迁移学习的深度学习算法验证数据集可行性
从训练结果来看Vision Transformer、VGG 和Resnet 的识别精度分别为:50%、60%、70%左右.从实验精度看,三种方法的识别率都不高,达不到应用的程度.这可能与数据集中图片的数量较少有关.Yosinski等人[18]研究深度学习中各个layer特征的可迁移性(或者说通用性),提出:通常情况下第一层与具体的图像数据集关系不是特别大,而网络的最后一层则是与选定的数据集及其任务目标紧密相关的;浅层feature 称之为一般(general)特征,最后一层称之为特定(specific)特征,使用迁移学习可以有效提高模型的泛化性能.为了解决训练样本不足的问题,本文引入了迁移学习.使用在大数据库上训练的模型,浅层参数全部直接迁移,最后的全连接层删除后重新训练.
具体步骤:1)下载相同的网络结构,并该模型已经在ImageNet 数据库上完成训练,该数据库的规模约120万个样本,1 000分类;2)创建一个新的神经网络模型,即目标模型,然后将预训练模型的权重参数全部加载到目标模型中;3)将加载了预训练模型的目标模型1 000分类的输出层删除,并重新映射到4分类输出层;4)为了对比,修改超参数设置,与实验1保持一致.
由于VGG 与Resnet 属于同类型网络,且在实验1 中,VGG 网络的训练效果全面落后Resnet 网络,因此实验2 只对比Resnet 和Vision Transformer 网络.为了方便对比,将两次实验训练结果列举在表1中.

表1 加入迁移学习前后实验效果对比表
在实验2中加入迁移学习,训练误差相比实验1收敛快,表现在:Resnet在实验1训练的第100Epoch 时训练误差为0.23,而实验2 如图4 所示:在第16 个Epoch 就收敛为0.06;Vision Transformer 网络在实验1 的第100Epoch 时训练误差为1.04,实验2 在第50 个Epoch 就收敛为0.45.从训练误差来看,加入迁移学习后,训练误差收敛快,且最终误差也小.
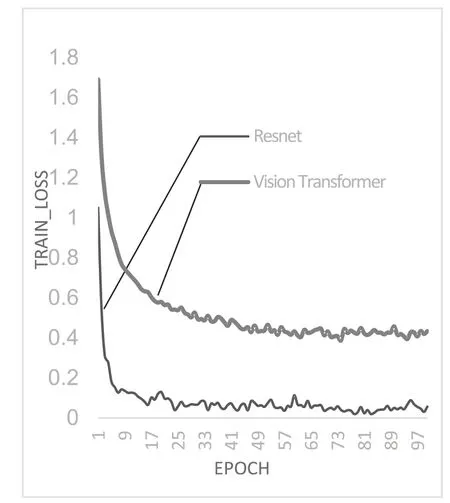
图4 带迁移学习训练误差收敛情况
通过对比图3无迁移学习和图5带迁移学习验证集的识别准确率可得,训练精度方面,Resnet在加入迁移学习前后,训练精度从77%左右上升到88%;Vision Transformer在加入迁移学习前后,训练精度从55%左右上升到86%,因此加入迁移学习对训练精度提升较明显.
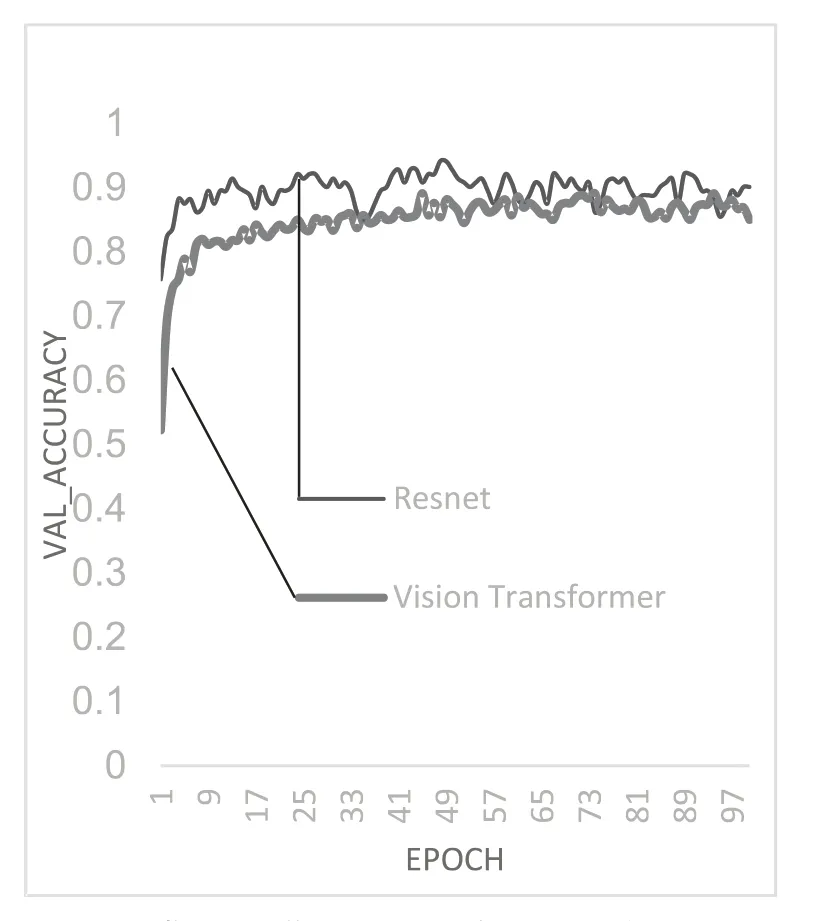
图5 带迁移学习验证集的识别准确率
实验结果表明:使用迁移学习之后,两种网络的收敛速度大大加快且精度有较大提升,最高精度达90%,基本满足实用需求.
3 结论与展望
本文以潮州凤凰单丛茶典型品种“鸭屎香”为例,建立了茶叶病害数据库,通过迁移学习,使神经网络分类模型获得较好的识别率,为深入研究茶叶病害的自动识别提供了有价值的参考.但仍有优化空间,后续将从以下几方面开展研究:
1)扩充数据库,将拍摄更多鸭屎香的病害图片,并尝试在数据中加入其它品种茶叶病害图片,进一步增强数据库的深度、广度和泛化能力.
2)改进网络架构,使其对茶叶病害这个对象有更加好的识别率;并进一步优化网络架构,压缩网络规模,提高识别速度,使其可以移植到边缘运算设备运行.
3)融合多因素进行分类.茶叶病害与季节,外部环境(温度、湿度、通风度)等因素有密切联系,后续将环境因素融入茶叶病害数据库,辅助茶叶病害识别模型,以提高识别率.
