基于大数据分析的水产养殖中鱼类行为识别方法
2024-01-19程玮杨智玲
程玮,杨智玲
(1.厦门海洋职业技术学院 海洋机电学院,福建 厦门 361100;2.厦门市智慧渔业重点实验室,福建 厦门 361100)
0 引言
随着科学技术的进步,水产养殖技术也得到了快速发展,特别是计算机视觉技术在水产养殖领域得到了广泛应用。在水产养殖规模迅速扩大的状况下,为了更加精准地获取养殖鱼类的状态信息,对鱼类行为进行实时监测与识别变得尤为重要。由于水产养殖环境的复杂性和鱼类行为的复杂性、多样性等特征的共同影响[1-2],致使传统视觉特征识别类方法在大范围、高精度识别养殖鱼类行为的过程中,出现识别偏差较大,局部识别成功率偏低的问题。因此,尝试引入大数据分析技术,在传统视觉识别方法的基础上,对其特征图像的识别参量加以优化,以实现提升识别效果的目的。通过与文献[3]、文献[4]中两种不同的识别方法对各鱼种行为进行识别试验对比,可知本文方法对水产养殖鱼类行为识别的准确度更高,应用效果更好。
1 识别优化参量的设定与计算
1.1 基于大数据的鱼类行为图像数据预处理
为了更好地分析水产养殖鱼类的行为特征,需要对获得的数据进行预处理。其中主要包括4个部分:
1)行为图像采集。一般情况下,鱼类行为数据需要通过多点位视频采集设备进行获取,保证图像清晰度满足数据分析要求,采集的鱼类图像如图1所示。

图1 采集的鱼类图像
2)采集图像的初步筛选。为了更好地提取鱼类行为特征数据,根据行为特征的复杂程度,采用大数据分析算法对采集到的图像进行特征前景与背景像素划分,进而根据不同前景特征所对应区域的面积完成子图划分。
3)基于大数据分析的鱼类行为特征语义分割。 根据划分子图中有效行为特征数据对应的语义类别,建立语义分割模型,在模型中通过语义网络连通相同行为特征数据,并通过式(1)筛选出鱼身运动特征集中位置分布子图。
4)行为特征语义的大数据解析。利用大数据强大的比对分析能力,根据不同形态分布位置对模型中子图信息包含的鱼头、鱼尾与鱼身3个位置点的分布情况进行行为特征轨迹溯源、行进速度与运动变化系数计算。
(1)
式中Pn为行为特征语义分割模型中的子图,D为子图下包含行为特征信息的像素总量,Dt为背景像素总量。
为了进一步提升数据预处理效果,需对其像素点进行高斯混合处理,在大数据分析辅助下完成每一像素的高斯分布赋值[3-4],由此得到用k个高斯分布表示的行为特征图像更新模型。在更新模型中,对于任意一个高斯混合像素的对应值为Xt,其对应时间点为t时的背景像素出现的概率P(Xt),由此可以得到:
(2)
(3)
(4)
ωi,t=(1-α)ωi,t-1+αMi,t,
(5)
式中:k为全局图像的高斯分布总像素,根据历史经验[5-6],本方法中取值为4;ωi,t为大数据分析过程中第i个行为特征像素点在高斯分布作用下的加权系数;η(Xt,μi,t,Σ)为全局高斯分布概率的均值密度函数;μt为单位区域下行为特征像素的高斯分布均值;Σ为不同类别行为特征之间的协方差矩阵;n为Xt的维数;σk为行为特征像素的标准高斯分布系数;I为单位矩阵;α为大数据分析速率;若某一行为特征像素点满足第i个高斯分布时,Mi,t=1,否则Mi,t=0。
此外,考虑到预处理过程中部分行为特征图像的像素点不满足第i个高斯分布要求[7-8],此时可按照式(6)~(7)完成σ与μ的高斯分布更新。若此时行为特征图像的像素点与全局背景均不匹配,则可判定当前预处理的像素点为前景特征像素点,其位置分布在目标鱼鱼身构成像素中。将k个行为特征像素按照高斯分布效果进行ω/σ的从大到小排序,并选取前B个高斯分布的加权值联合生成鱼类行为特征预处理模型。
μt=(1-ρ)μt-1+ρXt,
(6)
(7)
ρ=αη(Xt|μk,σk),
(8)
(9)
式中ρ为σ与μ的大数据行为特征分析更新速率,T为预处理模型的加权系数。
1.2 基于大数据的鱼类行为特征训练模型
根据预处理模型所得数据,对其进行特征训练模型构建。通过训练模型将行为特征数据参量转化为仅包含卷积核为3×3的卷积处理网络[9-10]。在转换的训练网络模型中,网络构建基于大数据分析网络,其中每一个卷积处理后都匹配一个NM特征量化。构建的训练模型中,首先将每一个行为特征转换卷积层与NM层融合,通过大数据分析将融合后的数量按照3×3的尺度进行卷积核划分,最后根据所得训练卷积结果,将多个卷积层进行合并,获得最终的训练模型(图2)。
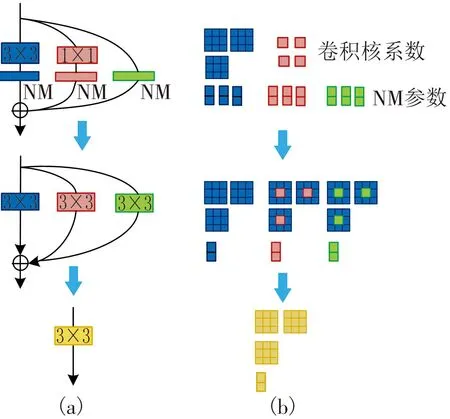
图2 大数据分析下多卷积层合并训练模型
根据前述训练过程,可得到行为特征转换卷积层与NM层融合过程中不包含偏置卷积[11-12],因此其计算公式可以表达为
Conv(x)=W(x),
(10)
式中W为行为特征转换卷积核。
大数据分析所对应NM层的处理过程可以描述为
(11)
式中μ为单位区域下行为特征像素均值,σ为行为特征像素的标准差,γ、β为大数据分析过程中卷积核训练的倍率与偏差。
经过进一步整合操作,得到式(10)与式(11)结合后的公式为
(12)
融合后每一个卷积处理过程均可以被看作一次行为特征训练,训练偏差直接对应卷积核W下的偏置b,其关系函数为
(13)
为了保证训练尺度的统一,将每一个训练卷积核的大小均调整为3×3。具体过程如图2(b)所示,其中空白特征像素对应的卷积用白色图块表示。
1.3 基于大数据的鱼类行为特征识别
根据前述训练结果可知,空白特征像素所对应的像素值为0,由预处理过程中像素点分布位置判定可知,该像素点位置位于鱼身组成像素中,因此在对鱼身行为特征识别的计算中,为了便于大数据对特征信息的识别处理,将背景像素值统一调整为255px[13-14],在对其进行像素二值化形态运算,提取行为特征像素点的同时,需去除特征像素中的孤立像素点。
基于前述操作,可以获得目标鱼鱼身行为特征像素所在坐标系位置为
(14)
(15)
式中N为构成行为特征的鱼身像素总数,xc与yc为行为特征像素中心点坐标,xi与yi为任意时间点下第i个行为像素点的坐标。
通过大数据分析数据库中鱼类游动速度[15],可以计算得到两个相邻行为特征像素点在相同时间点下的位移坐标(图3),计算公式:

图3 两个相邻行为特征像素点位移
(16)
(17)
式中un与υn分别为tn时刻下目标鱼所在x轴与y轴方向上的移动速度,(xn-1,yn-1)与(xn+1,yn+1)分别为tn-1和tn+1时刻目标鱼动作构成像素的位置,Δt为行为特征像素识别的时间步长。
完成目标鱼鱼身行为特征识别后,将对其头、尾行为特征进行识别(图4),根据前述大数据分析识别方法,提取鱼身以外的鱼头像素坐标C1(x1,y1)、鱼尾像素坐标C2(x2,y2),根据鱼身像素C特征点,关联C1与C、C与C2;通过关联分析获得鱼头与鱼尾构成像素的位移方向向量a1、a2,通过式(18)可以实现对鱼头、鱼尾行为特征的识别(图5)。

图5 鱼尾行为特征识别图
(18)
式中:a1为关联C1和C的鱼头像素位移方向向量;a2为关联C和C2的鱼尾像素位移方向向量;a为鱼的行为特征像素位移距离;A为鱼尾像素初始位置系数,A=1时鱼尾像素向鱼身右侧位移,A=-1时鱼尾像素向鱼身左侧位移,A=0时鱼头与鱼尾处于同一直线上。
2 性能测试
考虑到在测试过程中鱼类行为存在不确定性,为了降低测试样本差异,确保测试结果的客观性,试验共设置3种识别方法。其中本文方法为验证识别方法A+(简称方法A+),另外两种方法为比对识别方法,基于鱼体运动特征和图像纹理特征的鱼类摄食行为识别方法(文献[3]方法)为比对识别方法A(简称方法A),基于PIT遥测技术的竖缝式鱼道过鱼效率及鱼类行为识别方法(文献[4]方法)为比对识别方法B(简称方法B)。在相同测试条件下,对比3种方法指标,得出测试结论。
2.1 设置测试条件
测试样本抽取15类养殖鱼,1 000组鱼类活动图像作为测试样本图像,通过仿真测试工具配合运动形态测试工具,共同完成测试。其中,仿真测试工具为MATLAB,该测试工具是一种用于图像处理、特征提取等方面的仿真工具,使用MATLAB中的机器学习工具箱构建分类器,可对鱼类行为进行分类和识别。运动形态测试工具为Biomimetics Toolkit,它提供了多种模型和算法,可以模拟各种鱼类的运动行为,方便用户进行更加复杂的仿真和分析。具体测试参量见表1。
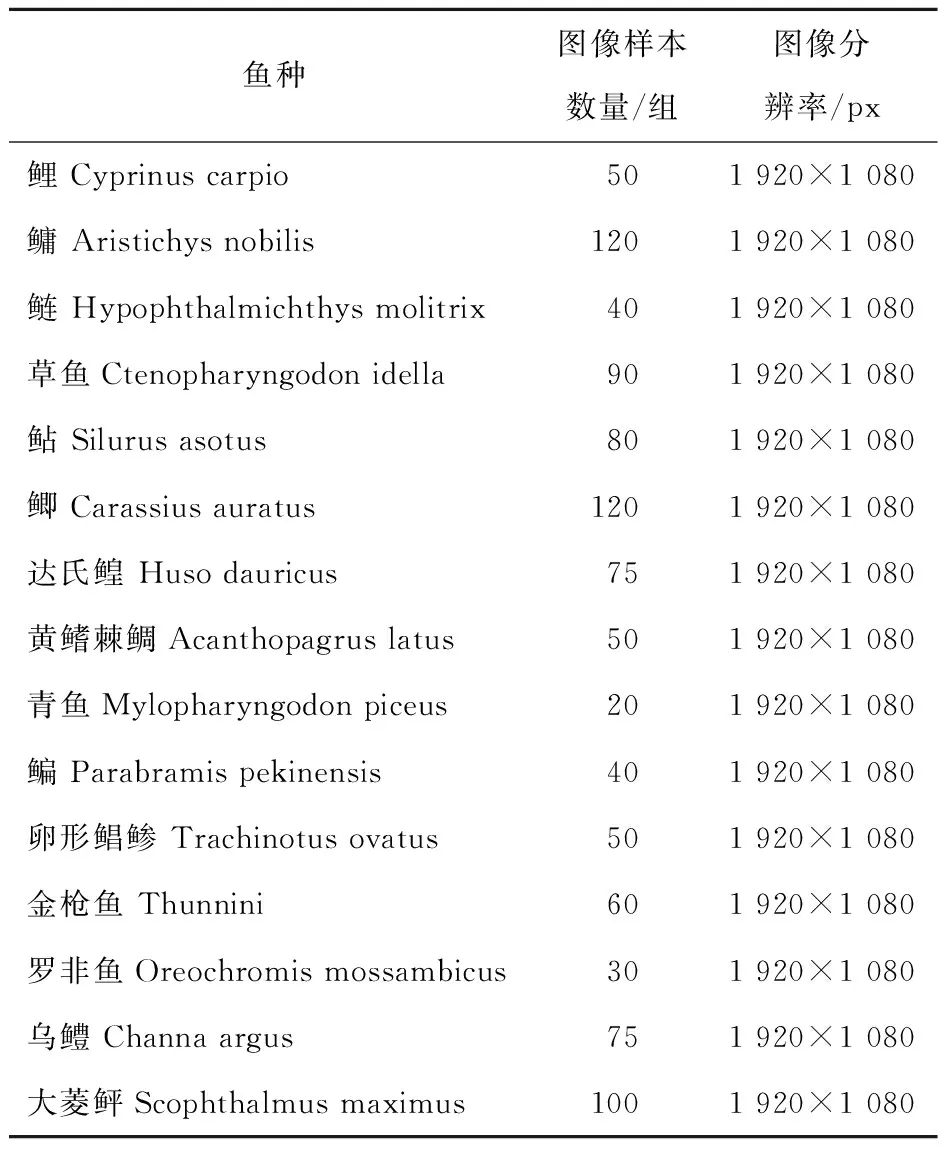
表1 测试样本配置
2.2 鱼类行为识别准确度测试
在设定样本中,抽取鳙、草鱼、鲢、鳊样本各30组,组成测试图像样本,分别由方法A+、方法A和方法B对其进行鱼类行为识别操作,用仿真工具对其识别结果准确度进行记录,经过统计整理后生成统计图(图6),并进行分析:

图6 不同识别方法获得的鱼类行为识别率统计图
1)在鳙样本中,方法A的识别准确率为94%,误差率为6%;方法B的识别准确率为95.7%,误差率为4.3%;方法A+的识别准确率为99%,误差率为1%。由此可以看出方法A+对鳙行为的识别效果最好,方法B的识别效果较好,方法A的识别效果偏差。
2)在草鱼样本中,方法A的识别准确率为97%,误差率为3%;方法B的识别准确率为98%,误差率为2%;方法A+的识别准确率为99%,误差率为1%。由此可以看出方法A+在草鱼行为识别性能表现上与其在鳙行为识别上的表现一致,根据数值大小可以判定方法A+的识别效果最好,方法B的识别效果较好,方法A的识别效果偏差。
3)在鲢样本中,方法A的识别准确率为94.7%,误差率为5.3%;方法B的识别准确率为95.2%,误差率为4.8%;方法A+的识别准确率为98.3%,误差率为1.7%。可以看出方法A+在鲢行为识别性能表现上指标略有下降,但仍优于方法A与方法B,因此,鲢行为识别结果为方法A+最好,方法B的识别效果较好,方法A的识别效果偏差。
4)在鳊样本中,方法A的识别准确率为98%,误差率为2%;方法B的识别准确率为96.7%,误差率为3.3%;方法A+的识别准确率为99%,误差率为1%。根据指标值可以看出方法A+在鳊行为识别性能表现上与其在鳙、草鱼行为识别上的表现一致,与之前不同的是方法B在鳊行为识别的表现较方法A表现略差,根据数值大小可以判定方法A+的识别效果最好,方法A的识别效果较好,方法B的识别效果偏差。
综合前述不同鱼种行为识别结果,可以判定验证比对方法A+在水产养殖鱼类行为识别应用上的效果最好,识别准确率最高。
2.3 复杂场景下识别可信度测试
为了验证本文方法在实际复杂场景中的识别可信度,在15种鱼类测试样本中,各自抽取20组样本数据,无序混合后组成可信度测试样本,共计300组。按照每30组样本为1轮,实施3种不同识别方法,由仿真测试工具可信度评估模块对其进行可信度评估,连续获得10组可信度指标,见表2。根据指标值大小,对其加以分析并得出测试结论。
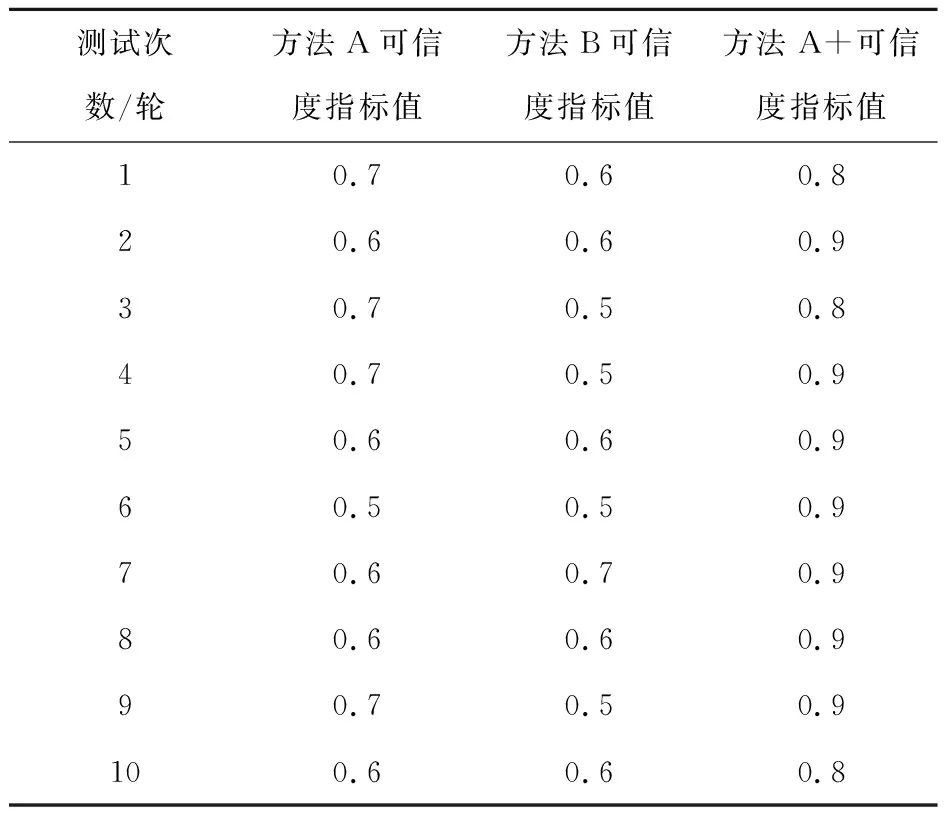
表2 不同鱼类行为识别方法连续性压力测试可信度指标统计
通过表2数据可知,3种方法的可信度指标差异并不大,根据可信度指标取值≥0.5,可以断定对应识别方法所得结果可以满足行为分析需求的标准时,得出3种识别方法均满足测试要求。在此情况下,对比3种识别方法所得指标数值大小,数值越大,可信度越高。由此可以看出方法A+的数值最大,方法A与方法B的数值大小相同,仅分布位置与出现次数不同,为此,对其最大数值出现次数进行统计,最大数值出现次数多的为最佳。因此经过统计后,对比方法A优于比对方法B,故此可信度测试的最终结果为方法A+>方法A>方法B。
3 结语
通过引入大数据分析算法,对鱼类行为信息特征进行训练识别,达到了提升识别精准度,增强识别结果可信度的目的。但本文提出的方法并不完善,在识别条件上还存在局部限制,例如对识别目标鱼最大密度的限制、最大水深的限制以及视频光线反射区域目标鱼行为缺失部分对识别效果的限制。为此,在日后的应用与研究中,需不断积累识别特征信息,添加或借助数据库模型,丰富大数据分析资源,优化自身数据特征样本,以确保提出方法的稳定、高效和精准,使其分析结果时时处于最佳状态。
