基于BiGRU 与胶囊网络的中文新闻标题文本分类
2024-01-17黄玉兰刘瑞安徐宇辉
黄玉兰,刘瑞安,胡 昕,任 超,徐宇辉
(天津师范大学,天津 300000)
当下,第五代移动通信技术(5G)正发展得如火如荼,人类迎来了信息多元化时代,文本数据呈现浪潮式激增,其中新闻文本占据重要地位。利用自然语言处理技术(Natural Language Processing,NLP)可以识别新闻文本中的实体、情感、类型等信息,把文本划分为多个独立的类别,有助于更好地传播新闻资讯,满足人们查找信息的需求。
近年来,文本分类技术广泛应用在情感分析、智能电子商务及医疗等多个领域,文本分类算法也经历了一系列的演变。在早期,知识工程是主流的分类方法,其类别规则由专业人员制定,通过人工标注大量文本形成数据集,因而这种方法存在费时费力、错误率极高且类别缺乏客观性等缺点。后来,机器学习技术的出现,基于浅层学习的文本分类方法逐渐兴起,并逐步替代了传统的知识工程方法。具有代表性的是朴素贝叶斯分类器(Naive Bayes,NB)[1]、支持向量机(Support Vector Machine,SVM)[2]、K 近邻(K-Nearest Neighbor,KNN)[3]以及决策树(Decision Tree,DT)[4]。但此类方法容易丢失文本内的前后位置关系和语境,导致单词语义理解不准确。自2010 年代以来,文本分类逐渐转向深度学习模式。2011 年,Ronan 等[5]首次将浅层深度学习框架应用于NLP 领域,结果甚至超越了当时现有的其他自然语言处理方法,于是大量的深度学习方法应用于文本分类任务。2014 年,Yoon 等[6]最早将卷积神经网络(Convolutional Neural Network,CNN)用于文本分类,我们也将该CNN 网络叫做textCNN。2022 年,张甜等[7]提出使用2 个不同尺寸的BiGRU 和胶囊网络进行文本情感分类研究,在电影评论IMDB 和SST-2 数据集上有效提高了文本情感分类的效果。
本文提出一种融合BiGRU 和多头注意力机制的混合神经网络模型-BMCapsNet 模型。使用BiGRU 提取上下文特征,结合多头注意力机制重新进行权重分配,利用胶囊网络进行更深层次的语义信息提取,最后通过类别胶囊进行文本分类,弥补了CNN 的缺陷。
1 胶囊网络
针对CNN 着力于检测特征图中的重要特征而忽略高层特征和低层特征之间的位置与姿态关系,2011 年Geoffrey 等[8]首次提出胶囊的概念。具体做法是从输入图像中提取姿态,以原始姿态输出变换后的图像,输出的向量既代表特征存在的概率又含有实例化参数。2017 年Sara 等[9]率先将这一概念应用到神经网络中,采用一种新的动态路由算法来选择重要的高层胶囊,实验表明,在图像分类领域,胶囊的鲁棒性明显优于CNN。2018 年Zhao 等[10]将胶囊网络迁移到文本分类任务中,提出了2 种胶囊网络结构,均由N-gram 卷积层、初级胶囊层、卷积胶囊层以及全连接胶囊层组成。在6 个标准数据集上进行了一系列的实验,结果表明胶囊网络在6 个数据集中有4 个达到最佳结果,验证了胶囊网络的有效性。近年来,胶囊网络在文本分类领域得到了广泛的研究。2020 年胡春涛等[11]提出LSTM连接胶囊网络模型用于文本分类,证明了胶囊网络的文本特征提取能力优于CNN。2021 年朱海景等[12]利用分组反馈路由机制,将胶囊分组方法运用于文本分类任务中,实验证明,其在参数数量和训练时间上有明显减少。
2 模型设计
本文提出的BMCapsNet 模型如图1 所示,该模型由全局特征提取模块、胶囊网络分类模块组成。

图1 模型结构
2.1 全局特征提取模块
2.1.1 BiGRU
循环神经网络(RNN)适用于处理序列数据用于预测,但却受到短时记忆的制约。在反向传播过程中,还面临梯度消失的问题。针对RNN 的缺陷,学者们提出了LSTM,而GRU 是其的一个变体。它们都具有称为“门”的内部机制,可以调节信息流。这些“门”可以选择性地保留序列中的重要数据,删除不相关的信息。与LSTM相比,GRU 使用隐藏状态来进行信息的传递,减少张量运算,提高训练速度。GRU 单元结构如图2 所示。
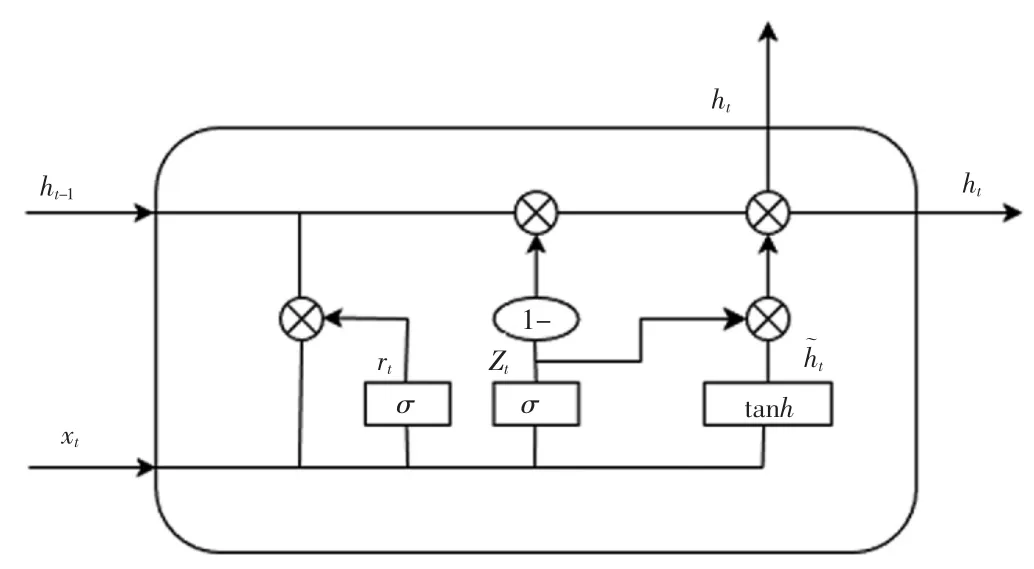
图2 GRU 单元结构
该单元结构由重置门rt和更新门zt组成。重置门允许我们控制可能还想记住的过去状态的数量;更新门允许我们控制新状态中有多少个是旧状态的副本。GRU 单元在时刻t 的更新过程如式(1)—式(4)所示
式中:xt为当前时刻的输入;ht为当前时刻的隐藏状态;ht-1为前一时刻隐藏状态;σ 为sigmoid 激活函数;Wr、Wz、Wc、Ur、Uz、Uc为权重矩阵;br、bz、bc为偏置项;*表示向量间的点乘运算。
在GRU 中,状态是从前往后顺序输出的。如果在文本分类过程中,当前时刻的输出同前一时刻状态及后一时刻状态都产生联系,那将更有利于文本深层次特征的提取,本文借助BiGRU 来建立这种联系。2 个单向、方向相反的GRU 组成一个BiGRU,输出由这2 个GRU 的状态共同决定。t-1 时刻的前向隐层状态和反向隐层状态加权求和得到BiGRU 在时刻t 的隐层状态,计算如式(5)—式(7)所示:
2.1.2 多头注意力
注意力机制源于人对外部信息的处理能力。人在每一时刻接收的信息庞大且复杂,远远超过人脑的处理能力。因此人在处理信息的时候,会将注意力放在需要关注的信息上,过滤无关的外部信息,这种处理方式被称为注意力机制。而多头注意力机制是将注意力机制扩展到多个头,从而增强模型对于不同特征的关注度。
首先,将经过BiGRU 层提取后的句子矩阵线性变换并分割为3 个矩阵:值向量(V),键向量(K),查询向量(Q)。其次,将V,K,Q 线性投影到不同的子空间,得到多个头。再次,对每个头进行自注意力计算,得到该头的输出
式中:dk是键向量的维度,KT为键向量的权重,利用softmax 相似度进行归一化。最后,将所有头的输出拼接在一起,进行线性变换。可以表示为
式中:h 表示头的数量,headi表示第i 个头的输出,WO是输出变换矩阵。
2.2 胶囊网络分类模块
多个神经元组成一个胶囊,而图像中出现的特定实体的各种属性分别由各个神经元表示。这些属性包含了许多不同类型的实例化参数,例如姿态(位置、大小、方向)、变形、速度和纹理等,而其中一个非常特殊的属性是图像中某个类别实例的存在,它的输出数值大小是实体存在的概率。主要分为初级胶囊层、分类胶囊层和文本胶囊层。
2.2.1 初级胶囊层
在这层中,多头注意力层中的标量输出用矢量输出胶囊替代,从而保留了单词的局部顺序和语义表示。其工作原理主要分为3 步。
第一步,矩阵转化
式中:Ui为低层特征,Wij为低层特征和高层特征的空间关系,Uj|i为由低层特征推出的高层特征。
第二步,输入加权求和
式中:Cij为耦合系数,一层胶囊网络所有的耦合系数和为1,通过动态路由算法自动调整。
第三步:非线性激活
采用向量的新型非线性激活函数,又叫Squashing函数,主要功能是使得Vj的长度不超过1,而且保持Vj和Sj同方向。
2.2.2 动态路由算法
在式(11)中,Cij由迭代动态路由过程确定。通过计算预测向量Uj|i与输出向量Vj之间的一致性来迭代更新权重bij。
整个动态路由算法流程如图3 所示。

图3 动态路由算法流程
首先初始化所有的bij为0,那么
后续一直迭代,根据式(13)更新bij,迭代3 次,得到最终的输出向量V。
2.2.3 分类胶囊层
分类胶囊层的输入为初级胶囊层的输出,包含的是高阶胶囊,此时每个胶囊代表文本可能所属的类别。由于胶囊允许多个分类同时存在,所以不能直接用传统的交叉熵损失,一种替代方案是用间隔损失
式中:k 是分类;Tk是分类的指示函数(k 类存在为1,不存在为0);m+为上界,惩罚假阳性,即预测k 类存在但真实不存在,识别出来但错了;m-为下界,惩罚假阴性,即预测k 类不存在但真实存在,没识别出来λ 是比例系数,调整两者比重。实验中取m+为0.9,m-为0.1,λ为0.5。
2.2.4 文本胶囊层
分类胶囊层的输出被压扁成一个胶囊列表,并送入文本胶囊层。对其进行全连接操作,通过softmax 分类器进行概率预测,完成最后的分类预测。
3 实验
3.1 实验数据
为评估BMCapsNet 模型的有效性,选取THUCNews 新闻标题数据集和今日头条新闻标题数据集进行实验。其中,THUCNews 新闻标题数据集是根据新浪新闻频道2005—2011 年的历史数据筛选过滤生成,收录共74 万篇新闻文档。本文从中抽取了20 万条新闻标题数据,一共涵盖10 个类别,每个类别各2 万条文本数据。今日头条新闻标题数据集包含382 688 条新闻文本,从中抽取10 万条新闻标题数据,涵盖10 个类别,每个类别各1 万条文本数据。2 个数据集中训练集、验证集和测试集的划分比例都为18∶1∶1。
实验的预处理部分首先对2 个数据集进行异常文本处理,去除样本中既包含新闻的标题内容,又包含其正文内容的异常文本,最终THUCNews 新闻标题数据集每个句子长度固定为32,今日头条标题数据集每个句子长度固定为50。其次,对其进行语料清洗、中文分词和去停用词,实现去噪目的。最后,进行词频统计与过滤,本文将词频小于5 的词汇定义为低频词,保留词频大于5 的单词。对剩余单词,构建词典。
3.2 实验设置
为验证BMCapsNet 模型在文本分类中的效果,实验均采用pycharm 集成开发环境,编程语言为python3.8,深度学习框架为PyTorch。服务器配置如下:处理器为10 核Intel(R)Xeon(R)Gold 6148 CPU,运行内存71 GB,GPU 为Tesla V100-SXM2,16 GB 显存。
使用300 维SougouNews 预训练字向量来初始化字嵌入矩阵,使用Adam 优化器,学习率为0.001。胶囊维度为16,胶囊数量为10。GRU 隐藏单元为128,多头注意力头数为8,动态路由迭代次数为3。
3.3 评价指标
本文采用的评价指标为准确率(accuracy)
式中:TP 为本身是正类,结果划分是正类;TN 为本身是正类,结果划分为负类;FP 为本身是负类,结果划分为正类;FN 为本身是负类,结果划分为负类。准确率为所有正确的分类的比重。
3.4 实验结果与分析
为验证BMCapsNet 模型的有效性,将BMCapsNet模型分别与TextCNN、TextRNN、TextRNN+Attention、TextRCNN、DPCNN、Transformer、BiGRU 基线模型和BiGRU-CapsNet 模型进行对比。为减少实验误差带来的影响,准确率均取3 次重复实验的平均值,其中最佳实验结果用粗体标出,实验结果见表1。
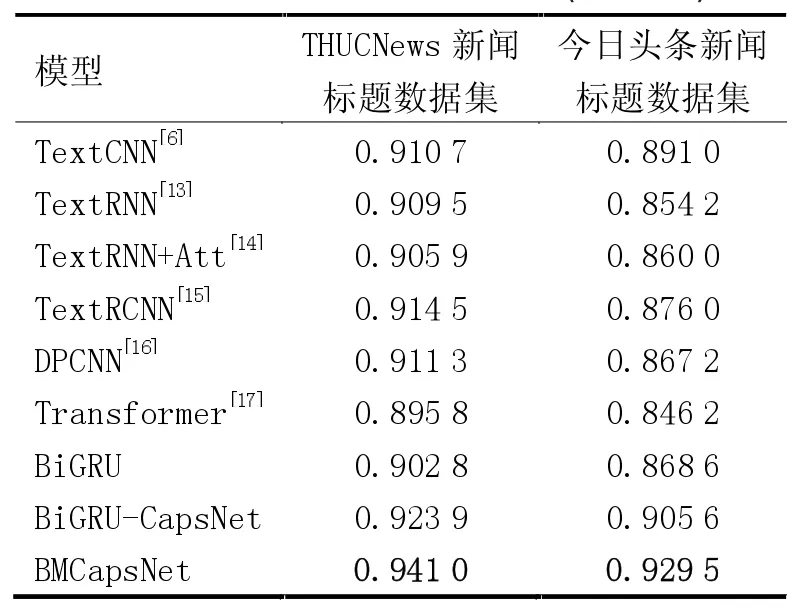
表1 不同模型最优分类结果(准确率)
与其他基线模型相比,BMCapsNet 模型在2 个数据集上准确率均达到最高。相比于TextCNN,在THUCNews 新闻标题数据集的准确率提升了3.03 个百分点,在今日头条新闻标题数据集的准确率提高了3.85 个百分点,验证了模型的有效性。
对比BiGRU-CapsNet 与BMCapsNet 模型发现,BMCapsNet 模型在2 个数据集的准确率均高于Bi-GRU-CapsNet 模型,说明引入多头注意力机制提高了模型的特征提取能力。其将输入数据划分为多个“头”,使模型能够并行捕捉输入数据中的不同特征和模式,提高分类效果,验证了多头注意力对分类准确率的影响。
4 结论
本文提出一种融合BiGRU 和多头注意力机制的胶囊网络文本分类模型,在THUCNews 新闻标题数据集和今日头条新闻标题数据集上证明了其有效性,说明所提模型适用于短文本分类。在后续的工作中,将进一步优化动态路由算法,减少模型参数,进而提高模型的训练速度与准确率。
