基于混合Transformer模型的三维视线估计
2024-01-16童立靖王清河冯金芝
童立靖,王清河,冯金芝
(北方工业大学 信息学院,北京 100144)
在计算机视觉领域,三维视线估计是一个具有挑战性的研究课题,它在人机交互[1]、教育[2]、医学[3]、商业[4]等领域发挥着重要作用.三维视线估计方法主要分为两大类:基于模型的方法和基于外观的方法[5],基于模型的方法通常需要专用硬件,这使得它们在不受约束的环境中难以适用.而基于外观的方法可以直接从获取的图像中估计出三维视线方向,表现出不错的视线估计结果.
近年来,随着深度学习的发展,提出了许多新的基于外观的三维视线估计方法.然而,个人和环境因素(如头部姿势、面部外观和光线明暗等)的影响复杂多样,这些因素分散并融合在整个外观之中,让基于外观的视线估计问题变得更加复杂且具有挑战性[6].这意味着深度学习模型所学习的映射函数应该是高度非线性的,并具有很好的处理整个外观的能力,否则会导致视线估计的准确度不够高.因此,更为有效的视线估计模型至关重要.
由于深度学习方法可以对图像和视线之间的高度非线性映射函数进行建模,相比传统方法,可以取得更好的视线估计效果.ZHANG 等[7]首先提出了一个基于VGG 模型的卷积神经网络架构,使用单目图像预测视线方向.此后,他们又设计了一个空间权重卷积神经网络[8],给那些与视线相关的面部区域赋予更多权重来提高视线估计精度.CHEN等[9]采用扩张卷积方法,在不降低空间分辨率的情况下,利用从图像中提取的高级特征,捕捉人眼图像的细微变化.SHA 等[10]提出了离散化视线网络DGaze-Net(Discretization Gaze Network),通过将视线角度离散化为K个容器,将分类约束添加到视线预测器中,视线角度在使用真实视线角度回归之前预先应用了分箱分类,以提高视线估计的准确性.但是,这些基于单个卷积神经网络模型进行视线估计的方法,相比目前的一些深度学习方法,网络模型结构的复杂度不高,特征提取能力不强,因而视线估计的准确度不高,难以达到预期的精度.
受到双眼不对称性的启发,CHENG等[11]提出了基于面部的非对称回归评估网络FARE-Net(Facebased Asymmetric Regression Evaluation Network),采用非对称方法,为每只眼睛的损失权重赋予非对称权重,分别估计两只眼睛的三维视线角度,来优化视线估计结果.CHENG 等[12]提出了一种粗到细的自适应网络CA-Net(Coarse-to-fine Adaptive Network),首先使用面部图像预测主视线角度,然后利用眼部图像估计的残差进行自适应.LUO 等[13]提出了一种协作网络模型CI-Net(Consistency estimation Network and Inconsistency estimation Network),通过两个网络协作,加入注意力机制,自适应分配眼睛和面部特征之间的权重来估计视线.这些通过多个卷积神经网络合作进行视线估计的方法,导致模型的参数量急剧上升.此外,这些方法对提取到的特征利用还不够有效,提取到的特征和视线估计之间的建模效果还不够理想.
CHENG 等[14]首次提出了使用Transformer[15]模型GazeTR(Gaze estimation using Transformer)进行视线方向估计.其后LI 等人[16]使用卷积结构取代了SwinTransformer 的切片和映射机制,使得Transformer 可以进行多尺度特征学习.但是,原始Transformer 模型的特征提取能力较弱,无法准确有效地提取视线估计特征,致使视线估计的准确度相比使用多个卷积神经网络的模型并没有太大提高.
针对上述问题,本文提出一个基于混合Transformer 的视线估计模型,在模型参数量保持在较低水平的同时,能够较为准确地估计出视线方向,主要步骤如下:
(1)在MobileNet V3[17]网络基础上,将压缩-激励注意力机制SE(Squeeze-and-Excitation)替换为坐标注意力机制CA[18](Coordinate Attention),并修改MobileNet V3 网络的输出层,增加一个1 × 1 的卷积层,以充分有效地提取人脸图像中的视线特征,并将其输入到Transformer模型中;
(2)在Transformer 模型的前向反馈神经网络层,加入一个卷积核大小为3 × 3 的深度卷积层,提高了模型的表达能力,以输出较为准确的视线估计.
1 本文模型
本文模型包括特征提取模块和视线估计模块两部分.首先将人脸图像送入基于改进的MobileNet V3网络特征提取模块,然后将提取的特征输入到改进后的Transformer 模型,并最终输出视线方向的估计结果.本文模型的整体结构如图1所示.
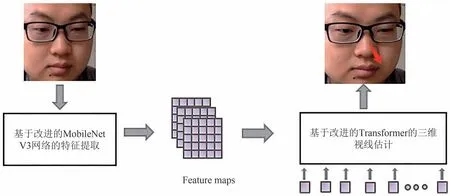
图1 混合Transformer模型网络结构Fig.1 Network structure of hybrid Transformer model
1.1 基于改进的MobileNet V3网络的特征提取
MobileNet V3 使用网络架构搜索NAS(Network Architecture Search)技术,并结合NetAdapt算法[19]对卷积核和通道进行优化组合.卷积操作上,使用深度可分离卷积(Depthwise Separable Convolution)替代了传统的卷积,并引入线性瓶颈结构(Linear Bottlenecks)和倒残差结构(Inverted Residual Blocks).此外,在原始MobileNet V3 中还使用了压缩-激励注意力机制,通过全局池化操作,将特征图压缩为一个全局特征向量,此全局特征向量包含了整个特征图的全局信息;然后使用两层全连接层,将全局特征向量映射为一个注意力向量,这个注意力向量可以根据特征的重要性来调整每个特征的权重.
为了更好地提取图像特征,并降低模型的整体复杂度,本文改进了MobileNet V3网络,加入了多层坐标注意力机制,来替换压缩-激励注意力机制,提高特征提取的有效性,并新增一个1 × 1 的卷积层,替换原始输出层的池化和全连接操作,最终输出准确有效的人脸图像视线特征图.
在本文的视线估计方法中,对于给定的人脸图像I∈RH×W×C,使用改进的MobileNet V3 网络进行特征提取,其中H、W分别为图像的长度和宽度,C为通道数.改进的MobileNet V3 网络将原有网络中的压缩-激励注意力机制替换为坐标注意力机制,压缩-激励注意力机制只使用全局特征向量,因而在特征图中缺少位置信息,而坐标注意力机制通过编码操作可以嵌入精确的位置信息,从而能够更好地捕捉特征图中的位置关系,提高了模型的特征提取能力;同时,坐标注意力机制与压缩-激励注意力机制相比,单层坐标注意力机制在特征提取时主要使用的是1 × 1 的卷积,而单层压缩-激励注意力机制在特征提取时主要使用的是两层全连接层.1 × 1 卷积在计算时是对输入通道的线性组合,而全连接层的计算则是输入与权重相乘并相加,再加上偏置项,因此就单层的计算成本而言,这两种方法变化不大.此外,在原始MobileNet V3 网络中使用的是8 层的压缩-激励注意力机制,而在改进的MobileNet V3 网络中,使用的是3层的坐标注意力机制,因此模型的总体复杂度有所降低.坐标注意力机制结构如图2所示,它通过精确的位置信息对通道关系和远程依赖进行编码.
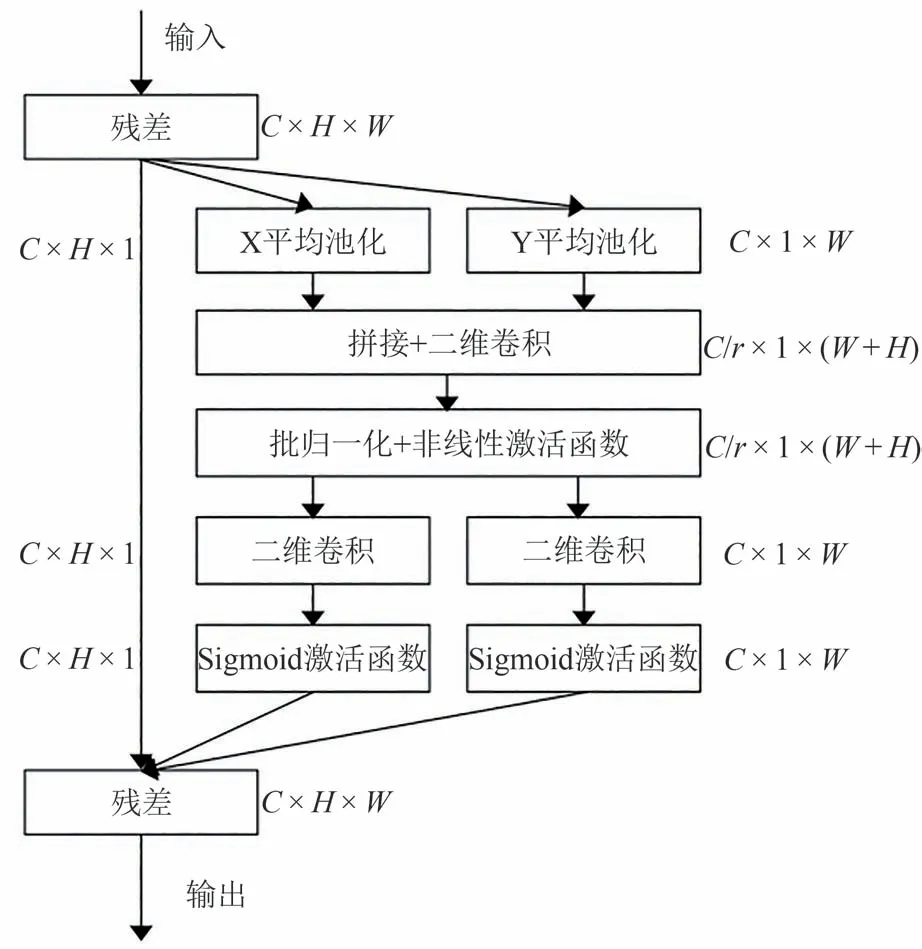
图2 坐标注意力模块Fig.2 Coordinate attention module
为了使注意力机制能够具备捕捉远程空间交互作用的精确位置信息,对全局池化进行了分解,将其转换为一维的特征编码操作.对于输入的图像特征X,每个通道首先使用大小为(H,1)或(1,W)的池化核沿水平和垂直坐标进行编码.因此,高度为H的通道C的输出如式(1)所示:
宽度为W的通道C的输出如式(2)所示:
为了适应视线估计任务,去除了原始MobileNet V3 网络输出层,对于MobileNet V3 网络输出的7 × 7 × 960 特征数据,新增了一个1 × 1 的卷积层,进行通道缩放,其新增卷积层结构如图3所示.
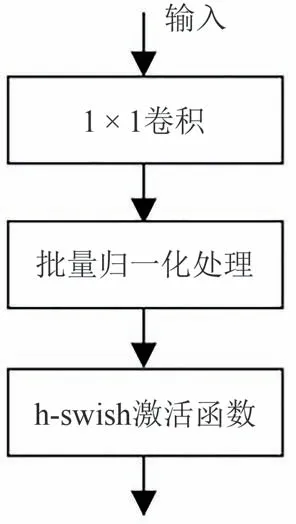
图3 新增的卷积层Fig.3 New convolution layer
1 × 1 卷积后的特征数据,经批量归一化BN(Batch Normalization)操作和h-swish 激活函数处理后得到7 × 7 × 32 的特征图,其中,h-swish 激活函数的计算如式(3)所示.与传统的ReLU 等激活函数相比,h-swish 激活函数更加平滑且具有连续性,能够提高模型的性能和精度.
1.2 基于改进Transformer模型的视线估计
MobileNet V3 网络层输出的特征图经过改进的Transformer模型处理,完成三维视线估计.改进后的Transformer网络整体结构如图4所示.

图4 改进后的Transformer模型结构Fig.4 Improved Transformer model structure
它由多个并行编码层组成,每个编码层包含两个子层:多头自注意力层MSA(Multi-head Self-Attention)和前向反馈神经网络层FNN(Feedforward Neural Network).对于MobileNet V3 网络提取的特征图fimg∈Rh×w×c,首先在嵌入层中调整为2维的图像块fp∈Rl×c,其中l=h·w,h、w分别为图像块的长度和宽度,l为特征矩阵的长度,c为特征矩阵的维度.此外,在嵌入层还向特征矩阵中添加了额外的标记ftoken,ftoken是一个可学习的嵌入向量,并且与特征向量具有相同的维数,即ftoken∈R1×c.然后重新编码每个图像块的位置信息,创建一个可学习位置编码fpos∈R(l+1×c),并加入到图像特征矩阵中,得到最终的特征矩阵如下:
其中[]表示连接操作.
在三维视线估计的多头自注意力模块中,自注意力机制将特征矩阵f∈R(l+1×c),经过线性变换,得到查询向量Q∈Rn×dk,键向量K∈Rn×dk和值向量V∈Rn×dv,其中n为输入序列的长度,dk和dv为每个特征的维度.自注意力机制的计算如式(5)所示:
多头自注意力模块将自注意力机制扩展到多个子空间,通过不同的线性变换对查询、键和值进行N次线性投影,其中N为多头头数.每个头的输出被拼接并经过线性变换得到最终输出.为了稳定训练、加速收敛,每个多头自注意力层之后都进行了层归一化LN(LayerNormalization)和残差连接[20],然后输入给前向反馈神经网络层.
为了能够准确估计出视线方向,提高模型的整体性能,本文对Transformer 模型的前向反馈神经网络层进行了改进.Transformer 模型的前向反馈神经网络层能够将多头注意力机制的输出进行非线性变换和全局特征整合.传统的前向反馈神经网络通常由两个全连接层和一个非线性激活函数组成,能够完成序列中不同位置间的关系捕捉.然而,传统的前向反馈神经网络不足以应对三维视线估计任务中的复杂映射,导致其估计精度不高.本文对前向反馈神经网络层进行了改进,在两个全连接层之间增加了一层卷积核大小为3 的深度卷积层.在卷积操作中,只对输入的每个通道进行卷积计算,而不是像传统卷积那样对所有输入通道进行计算,其卷积过程如图5 所示.此深度卷积层能够有效地捕捉序列中的局部空间关系和长期依赖关系,从而加强前向反馈神经网络的非线性表示能力和全局特征整合能力,提高了模型对三维视线特征的捕捉能力.
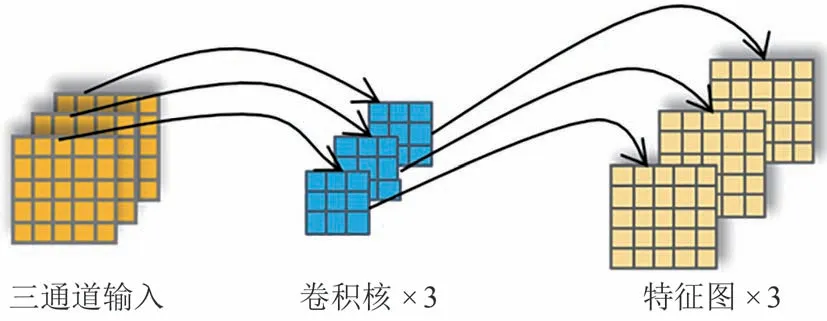
图5 深度卷积的过程Fig.5 Depthwise convolution process
在改进后的Transformer 中,MSA 层输出的特征矩阵x′由具有深度卷积层的前向反馈神经网络进行特征整合,实现非线性映射,如式(6)和式(7)所示:
式中:X为输入的嵌入层特征矩阵,MSA(·)为多头自注意力处理函数,LN(·)为层归一化处理函数,FNN(·)为前向反馈神经网络映射函数,x与X具有相同的维度,即x∈Rn×d,因此模型可设计为N层Transformer的并行处理.
改进后的Transformer 处理嵌入层输入,并输出视线估计特征矩阵.选择第一个特征向量,即ftoken的对应位置,作为视线特征表达,并使用多层感知机MLP(Multi Layer Perception)从视线特征表达中回归视线方向矢量,如式(8)所示:
式中:[0,:]为选特征矩阵第一行,g为估计的视线方向矢量,MLP(·) 为多层感知机映射函数,Transformer(·)的计算如式(6)和式(7)所示.
2 实验和分析
2.1 数据集和评价指标
本文使用MPIIFaceGaze 数据集进行模型的训练和评估,并按照文献[21]对其进行了预处理.经过预处理后,MPIIFaceGaze 数据集包含15 个受试者的45000张图像,使用留一评估法进行评估,角度误差作为评价指标.
2.2 实验细节
本文模型使用PyTorch 实现,在NVIDIA Tesla V100 GPU 上进行训练.训练时,批量大小(Batchsize)设置为512,迭代周期(Epoch)为120,学习率设置为0.0005,权重衰减为0.5,衰减步骤设置为60 个epoch.使用Adam 优化器训练模型,其中β1=0.9,β2=0.99;使用线性学习率进行预热,设置为5个epoch.
实验图像为224 × 224 × 3 的人脸图像,视线估计结果为由垂直偏转角(Pitch)和水平偏转角(Yaw)构成的二维向量.训练过程中的损失函数为L1-loss函数,如式(9)所示:
式中:yi为真实值为估计值|为真实值与估计值之间的绝对误差,n为样本个数为对所有样本的误差取均值,从而得到平均绝对误差MAE(Mean Absolute Error),MAE 越小,估计结果与真实值越接近.
改进后的Transformer 模型执行8 头自注意力机制,前向反馈神经网络层中神经元个数为512,每层中的神经元随机失活率dropout为0.1.
2.3 不同视线估计方法的对比分析
为了评估视线估计的性能,将本文方法与CANet、AGE-Net[22]、GazeTR、L2CS-Net[23]等方法进行了对比实验.本文提出的基于混合Transformer 模型的三维视线估计方法在视线估计精度上均高于其他方法,结果如表1所示.

表1 实验结果对比Tab.1 Comparison of experimental results
此外,本文与使用Transformer 模型进行视线估计的GazeTR 方法,在MPIIFaceGaze 数据集上,对15 个不同对象的视线估计误差进行了分析对比,本文方法在12 个对象中的视线角度误差表现均优于GazeTR,结果如图6所示.

图6 MPIIFaceGaze数据集上15个不同对象的视线估计角度误差结果Fig.6 Angle error results of gaze estimation for 15 different subjects on the MPIIFaceGaze dataset
本文方法与GazeTR 方法的部分结果可视化图像如图7所示,绿色为视线的真实方向,红色为本文方法的视线估计方向,紫色为GazeTR 的视线估计方向.

图7 结果可视化图像Fig.7 Result visualization images
最后,本文方法还与GazeTR、L2CS-NET 方法的模型参数量和视线估计角度误差进行了综合比较,实验结果如图8 所示,其中气泡越大,参数量越大.本文方法在视线角度误差较小时,仍能保持较低的模型参数量.
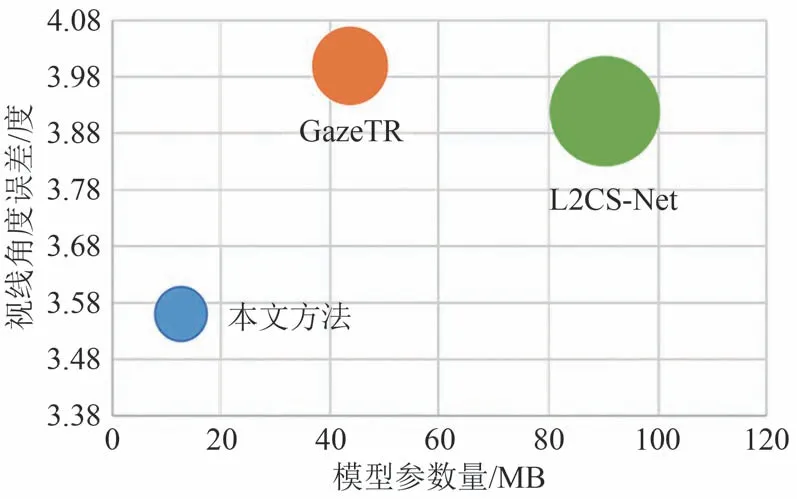
图8 模型大小与视线角度误差的对比Fig.8 Comparison of model size and angle error of gaze estimation
2.4 模型改进前后的性能对比分析
为验证对MobileNet V3 网络和Transformer 模型的改进在三维视线估计任务中的有效性,在MPIIFaceGaze 数据集上,基于相同的实验环境条件,对全部15 个不同人物的45000 张人脸图像,在角度误差、参数量、计算复杂度方面进行了模型改进前后的实验对比,结果如表2所示.

表2 模型改进前后性能对比Tab.2 Performance comparison before and after model improvement
其中DW 表示在Transformer模型的前向反馈神经网络层加入的深度卷积,CA 表示在MobileNet V3网络中引入的坐标注意力模块.分析实验结果可知,在Transformer 模型的前向反馈神经网络层加入一层深度卷积后,模型性能得到显著提高,最后在MobileNet V3 网络中引入坐标注意力模块,视线估计的准确度达到最高.改进后的方法相比原始MobileNet V3+Transformer、MobileNet V3+Transformer+DW 方法准确率分别提高约0.72°和0.31°.另外,本文方法的参数量相比MobileNet V3+Transformer 和MobileNet V3+Transformer+DW 明显降低,本文方法的计算复杂度也比具有压缩-激励注意力机制的MobileNet V3+Transformer+DW 方法略有降低,可见本文方法所做的改进是有效的.
3 结语
本文提出了一种基于混合Transformer 模型的视线估计方法,利用改进后的MobileNet V3 网络构建特征提取器,在MobileNet V3 网络中引入了坐标注意力模块,充分有效地提取图像中的特征,然后将特征输入到改进后的Transformer 模型中,通过在Transformer模型的前向反馈神经网络层加入一层深度卷积,提升了模型在视线估计任务中的准确性.通过与其他方法的实验对比,本文方法可以较为准确地进行三维视线估计,并且模型的参数量能维持在较低的水平.
