注记文件系统模型的建立
2024-01-16孙爽郑波尽胡丽君
孙爽,郑波尽,胡丽君
(中南民族大学 计算机科学学院,武汉 430074)
无论文件中储存的是工作学习文档还是日常生活中音频视频的数字化文件,随着设备中文件数量增长,文件都难以管理,并且文件管理又和档案管理[1]、个人信息管理[2]、信息行为[3]、信息检索[4]等领域联系紧密.
数字内容以文件的形式表示可追溯到20 世纪60 年代[5].这种方式已经成功地在计算机领域中应用了60 多年[6].虽然受到过质疑[7],并被指出需要进行改善[6],但它仍然是计算机领域中使用最久和最普遍的一种处理计算机数字内容方式,比如在Windows、Mac OS、Linux、DSB、Solaris、Android、iOS、Windows Mobile等系统中.
文件存储在目录中,目录系统具有简单、直观和适用面广的特点,这使它一直沿用至今.但是目录系统有其局限性,就像文献[8]的名称“Hierarchical file system are dead”所言,SELTZER 和MURPHY 早在2009 年就提到分级文件系统已经不再适用于当时[8].DINNEEN 也指出用户会花费大量的时间去执行文件和文件夹的操作[9].
面对具有多个分类属性的文件时,目录结构的创建变得困难[10].具有多个分类属性的文件在目录系统中通常属于多个子目录,比如在某一所学校里有A、B两个班级[图1(a)],现有一份文件(inf.txt)中记录的是关于这两个班级的信息,在两个班级中挑选一个存放[图1(b)]或者两个班级中都进行存放[图1(c)]是目录系统中的两种不同做法.第一种方法无法完全表述文件记录2 个班信息的含义,第二种方式一份文件却保存了两份.

图1 多分类文件举例Fig.1 Example of multi-class files
在文件查询上,文件的许多操作都是建立在查询之上,比如文件修改,只有先找到目标文件才能对文件进行修该;文件移动也需要先找到目标文件再找到目标目录才能完成文件的移动,但是随着文件数量的增加,文件查询效率却在降低.
上述问题的原因是目录系统在逻辑上是树形结构,采用自上而下的设计哲学,即先有目录结构再有文件,以结构为中心来管理文件,用户虽然可以轻松地创建一个类似植物学或者动物学的分类系统[11],但是这种设计方式使目录结构的创建受到限制,并且查询文件必须从指定目录开始,导致文件查询的效率不高.
为了解决上述问题,人们发展了以元数据为基础的文件管理系统,它将丰富的元数据与文件联系起来,使文件的多个分类属性可以用多个元数据进行表示,并且有比传统的文件系统更加高效的文件检索能力[9].BARREAU 等[12]设计了一种纯元数据文件系统,将广泛而丰富的数据集同文件关联起来,AMES 和BOBB 等[13]提出名为LiFS 的文件系统,它将元数据存储在非易失性存储器中,用来确保用户或者应用程序赋予文件的属性以及文件之间所具有的联系;随后AMES 又和GOKHALE 等[14]提出了一个名为QMDS 的元数据管理服务,其中集成了所有文件的元数据,抽象成具有节点和边的图数据模型.ALBADRI 和WATSON[11]则使用基于元数据的“TreeTags”模型并引入查询语言的方式改进文件管理系统.而董豪宇等[15]设计了一种纯用户态的网络文件系统RUFS(Remote userspace File System),将元数据采用基于键值存储与blobstore的元数据协同管理,在保证元数据操作的原子性和并发性的同时,使其具有更高的性能.但是这种方式需要在系统中附加独立于文件系统的元数据管理服务,导致出现这两个系统难以同步.
面对上述问题,本文基于第一性原理,以自下而上的设计哲学,提出了注记文件系统,即先有文件再向文件添加注记的方式将文件和其描述信息进行关联,使文件目录系统和元数据注记系统合二为一.以文件为中心,注记文件系统将目录信息转化为注记,在解决多分类文件目录创建困难问题的同时提高了文件的查询效率.
1 目录文件系统介绍和注记数据库介绍
1.1 目录系统
常见文件系统有FAT、NTFS、EXFAT、EXT、HFS等,它的作用是在存储设备上管理和存储文件信息,文件系统的建立需要对文件和目录进行实现,这里以EXT2为例进行介绍.
EXT2 中文件内容是保存在数据块中,同一个文件系统中的数据块大小相同,数据块的大小由文件系统指定,一个文件所占用的空间以数据块为单位进行分配.EXT2 中利用索引节点(inode)来代表一个文件,每一个inode 都有一个唯一的整数标识符,其中记录文件的元数据,比如文件大小、访问权限、时间戳、文件所占用数据块等.
在Linux 系统中有一句经典的话:一切皆是文件.不仅普通的文件和目录,就连块设备、管道、socket 等,也都统一交给文件系统管理.与普通文件中保存文件内容不同,目录作为特殊的文件,其中保存目录项列表,每个目录项中记录目录项的索引节点、名称以及名称长度,并且每个目录的前两个目录项都是“.”和“..”,用来代表当前目录和父目录.多个目录项之间关联起来,形成了目录结构.
1.2 注记数据库
注记数据库是一个被设计用于处理少量数据的数据库,它利用增量式方法为现实世界建模.它是一种采用自下而上设计方法,先有数据再通过为数据加注记或关联注记的方式来存储和管理数据之间的关系.注记数据库中注记是一种对多语义数据的表述方法,表示用户为检索信息的标注.不同于自由注记,注记数据库中的注记用来表示复杂的数据之间的关系,实现关系数据库的功能.
注记数据库中为每个数据和注记都分配id,分别记为Did和Zid,通过将Did和Zid进行关联完成对数据标注.注记数据库中包含普通注记和识别注记两种注记,根据被标注数据中是否具备识别特征来判断注记为何种注记,普通注记用于表达关系数据库中的普通属性,识别注记用于表达关系数据库中的键属性.对于识别注记则为被标注数据标识,对于普通注记则将数据和识别注记进行关联,在数据之间产生关联.注记数据库在理论上和关系数据库等价,它能很大程度上提高数据库存储数据的灵活性,在数据库中保证数据之间关联的同时保证了数据的语义信息.
2 注记文件系统
注记是文件的描述信息,注记文件系统是一个被设计用来方便多分类文件存储和提高文件查询速度的文件系统,它以元数据为基础,采用为文件加标签的形式进行建模,使文件和注记之间建立联系,在保证文件具有语义的同时让文件能够依靠注记进行文件查询.对第1节中多分类文件的例子,在注记文件系统下的形式如图2,将两个班级抽象为两个注记,同时对文件inf.txt 进行关联,在能很好地表达该文件所描述的信息同时又保证了文件不会重复保存.本章主要介绍注记文件系统的理论模型和物理实现.

图2 注记系统下多分类文件存储图Fig.2 Multi-class file storage diagram under the annotation file system
2.1 注记文件系统逻辑模型
文件所在位置的各层目录名和文件名在对文件进行描述的作用上和注记的功能相同,可以将各层目录名和文件名看作文件的注记,这里把目录系统中文件的目录名和文件名提取为注记,通过把文件和注记转换到注记系统中的方式来介绍注记文件系统的逻辑模型.假设目录系统存在如图3 的文件 实例,其中file_1、file_2、file_3、file_4、file_5 和file_6 为6 个文件,A、B、C、D、E 和F 分别为其文件名,dir_1、dir_2、dir_3、dir_4和dir_5为目录.
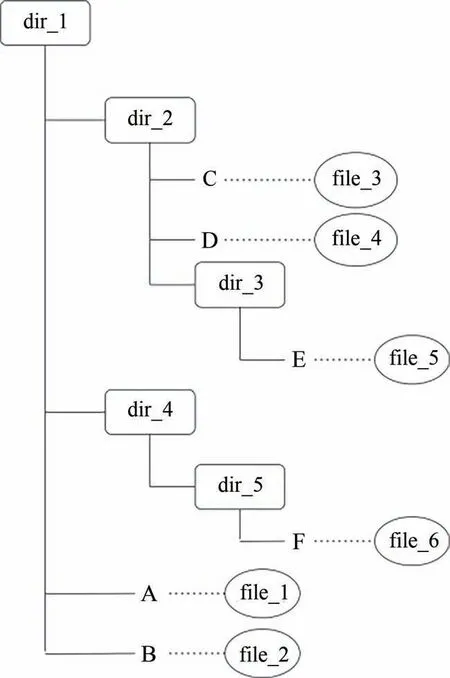
图3 目录系统下文件实例Fig.3 File instance under the directory system
提取文件名和目录名作为注记,并在注记和文件之间进行连接,转换到注记文件系统中,如图4所示,此时到注记文件系统的逻辑模型是一种具有注记和文件两种节点的二分图,模型的定义如下:

图4 注记系统下的文件实例Fig.4 File instance under the annotation file system
G=(F,N,E).
F:文件节点集合,其中每个元素f代表一个文件.
N:注记节点集合,其中每个元素n表示一个注记.
E:E={(f,n)|f∈F,n∈N},如果文件f具有注记n,则边(f,n)存在,否则不存在.
对于通过多个注记对文件进行查询的问题可以描述为:
存在图G=(F,N,E),求和给定注记集合M中所有元素m之间都存在边的F节点集合I,且满足∀m∈M,m∈N,∀i∈I,i∈F.
算法如右栏算法1,当图G中与M中度数最小元素之间具有连接的F节点的个数为x(x≤|F|),并假设这x个节点平均又和y(y≤|N|)个N节点之间有连接.此时上述算法的时间复杂度T(n)=n+x(y+1)=Θ(a×b),其中a为N节点的个数,b为F节点的个数.
2.2 注记文件系统物理模型
如上一节中介绍的,在注记文件系统中需要记录注记信息、文件信息以及注记和文件之间的关系信息,注记信息存储方式如图5所示,表中记录所有的注记,并为注记分配一个索引号nid.
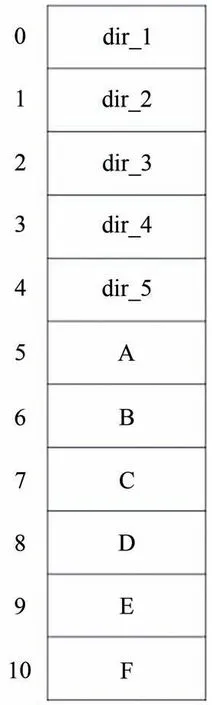
图5 注记存储表Fig.5 Annotation storage table
注记和文件之间是多对多的关系,即一个文件对应多个注记,一个注记对应多个文件.将注记索引号nid 作为注记节点,文件的inode 号作为文件节点,使用注记哈希表和文件哈希表分别表示上面两种关系,注记哈希表中每个注记项后面跟着具有这个注记文件inode 号组成的链表,结构如图6 所示.


图6 注记哈希表Fig.6 Annotation hash table
文件哈希表中每个文件项后面跟着该文件所拥有注记组成的链表,结构如图7所示.其中使用-1作为链表结束标识符.
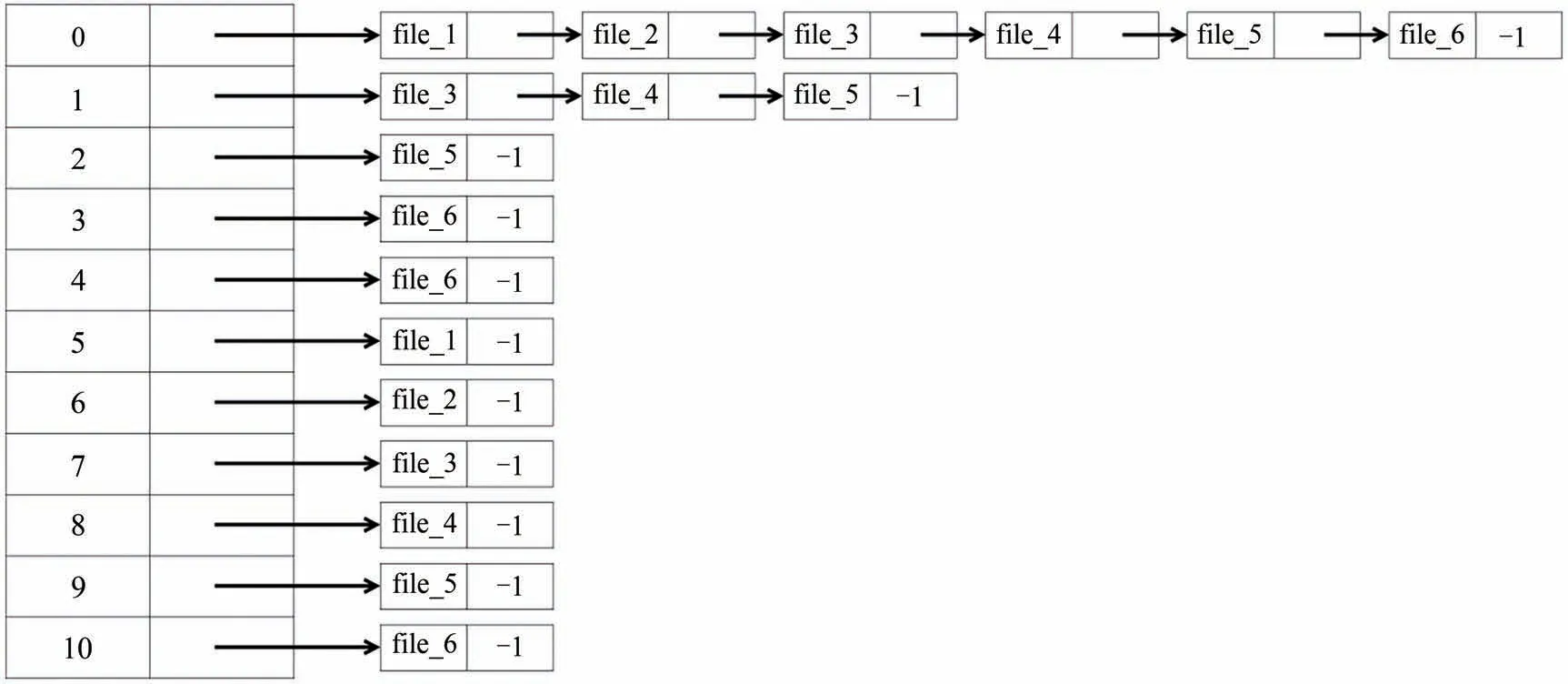
图7 文件哈希表Fig.7 File hash table
3 注记系统和目录系统对比
在任何2 个目录名都不相同的情况下,注记系统和目录系统可相互转化,但是前者在逻辑上是一种网状结构而后者则是树形结构,这使得文件的操作方式不同.结构决定性质,树形结构决定每次的文件查询需要从根目录开始,而网状结构则需要从节点出发,这使得文件的查询方式也不相同.
影响文件查询速度关键因素是查询过程中需要进行对比的次数,注记文件系统中不同注记相关联的文件数量不同,不同注记的排列组合,在多注记查询中文件集合合并所需要比较的次数也将不同.为保证可比较性,注记系统中的文件查询分析将目录系统中文件转换到注记系统中进行,并且规定目录系统中不存在两个相同名称的目录,每个文件夹下的文件个数和文件名相同.
3.1 文件操作方式比较
目录结构下常用的文件基础操作有查询、删除、移动、创建等.
(1)文件查询.
在查询文件上,注记的作用和目录相同,都是用来将文件的字符串名称映射到定位文件所需要的信息上.目录系统下文件查询使用遍历文件的方式,层层筛选直到找到目标文件.注记系统下每个注记对应一组文件,取目标文件所具有的注记组中每个注记对应文件集合的交集即为查询结果.
(2)文件删除.
目录系统中删除文件需要删除目录项中记录的同时删除inode并回收所占用的磁盘空间.注记文件系统下需要删除文件和文件所具有注记之间的关联,即删除文件哈希表和注记哈希表中的记录,同时删除inode并回收文件所占用的磁盘空间.
(3)文件移动.
目录系统中文件移动是在目标目录项和当前目录项之间进行修改.而在注记文件系统中对应的是修改文件的注记,注记修改需要删除原来注记和文件之间的关联并创建新的关联,即文件哈希表和注记哈希表中链表数据的删除和添加.
(4)文件创建.
目录系统中文件创建需要创建文件的inode 并在目录项中加入文件inode号.注记文件系统中同样的需要创建文件的inode,不同的是不再修改目录项中的记录而是在文件和注记之间建立关联,即在文件哈希表和注记哈希表中加入关联信息.
3.2 目录系统文件查询分析和顺序注记文件查询分析
为了方便计算,假设目录系统下目录深度为m每层文件夹中都具有x个文件和y个文件夹,此时目录中一共有ym个文件夹和ym×x个文件.以遍历文件夹的方式进行文件查询,对每个文件夹中文件进行判断直至找到目标文件目标文件.假设查询文件目录深度为n,最好情况下,每次都进入正确的文件夹,此时的对比次数为n+1,在最坏情况下,直到最后才能查找到目标,此时文件的对比次数T(n)的计算方式如下:
当n=1时:
由式(1)、(2)归纳得出:
注记文件系统中每个注记都有一个与之关联的文件集合,文件查询的结果是取注记集合中的每个注记元素对应文件集合的交集.注记是从目录转换而来,顺序注记文件查询是将注记按照目录由浅至深进行排列,从注记文件系统中查询然后取交集.此时,目录深度为n的文件具有注记n+1 个,查找到目标文件的对比次数T(n)的计算方式如下:
当n=1时:
由式(4)、(5)归纳得出:
当m=n时,式(3)和式(6)相等.此时顺序注记文件查询同目录系统中最坏情况下的查询方式一样,这是由于该方法总是从低目录深度开始筛选,而在注记文件系统中低目录深度的注记所对应文件的数量比高目录深度注记对应文件的数量多,因此这种方式会产生大量的文件对比.从两种文件查询对比次数结果可知:当查询文件所处位置在目录中越深,两种方式的查询对比的次数也越接近.
3.3 非顺序注记文件查询分析
每个注记对应的文件个数不同,先对对应文件少的注记进行查询,再在此基础上对文件集合进行取交集,这种文件查询方式称为非顺序注记文件查询.
假设查询文件的目录深度为n,它最深层目录转化的注记对应的文件有ym-n个,文件名注记对应的文件有ym个.当深层目录转化的注记对应的文件最少,此时查询文件需要对比的次数为:
当文件名转化的注记对应的文件最少,此时查询文件需要对比的次数为:
显然式(7)、(8)的结果都是要小于式(6),因此非顺序注记文件查询的方法具有更少的对比次数,理论上查询的效率也更高.
在不含有两个名称相同的文件夹并且每个文件夹下文件名都相同的目录结构下进行文件查询,并且将查询结果同转化的注记文件系统中文件查询结果进行对比,注记文件系统采用非顺序注记文件查询的方式查询.
根据对比次数计算公式可见:影响文件查询速度的因素主要有3 个,即目录深度、每层文件数量、每层文件夹数量.针对以上3 个因素设计了3 组实验,分别在不同目录深度、文件夹数量和文件数量下进行,为排除硬件的影响,均在相同的磁盘中进行.第1组实验在每层目录都有5个文件和2个文件夹,分别以目录深度为6、8、10 和12 的情况下进行,结果见表1;第2 组实验在每层目录都有5个文件和目录深度为6,分别以每层有2、3、4、5、6个文件夹的情况下进行,结果见表2;第3 组实验在每层目录都有2个文件夹和目录深度为6,分别以每个文件夹下文件个数为5、10、15 和20 的情况下进行,结果见表3.每组实验中的查询进行了30 次,取平均值作为实验结果,单位为ms,并计算方差.

表1 不同目录深度下实验数据表Tab.1 Experimental data under different directory depth

表2 不同文件夹数下实验数据表Tab.2 Experimental data under different folder numbers

表3 不同文件夹个数下实验数据表Tab.3 Experimental data under different file numbers
由上面3组实验可见:随着目录结构变得复杂,两种系统下文件的查询速度均变慢,但总体上注记文件系统的查询速度更快,注记文件系统文件查询速度受每层文件夹数量和文件数量的影响较小,受目录深度的影响较大.
实验是在每个文件夹下文件名称相同的情况下进行,但实际上目录系统中很少出现这种极端情况,当每个文件夹下大多数文件名不相同时,文件名所转化的注记将变为对应文件最少的注记,此时文件查询需要进行比较的次数更少,查询速度也更为迅速.
4 结语
本文指出了目录系统中存在多分类文件目录结构创建困难和文件查询效率低的问题,分析问题的原因是目录系统采用自上而下的设计哲学,以结构为中心的方式来管理文件.以元数据为基础的文件管理系统虽然能够很好地解决上述问题但是却需要附加独立于目录系统的元数据管理服务,使2个系统难以同步.因此本文采用自下而上的设计哲学,以文件为中心,提出了注记文件系统,先有文件,再向文件添加描述信息的方式使文件系统和元数据管理系统合二为一.同时注记文件系统中将目录信息转化为注记,将其作为管理和查询文件的依据,在解决文件多分类问题的同时提高了文件的查询效率.
作为一个文件系统,注记文件系统并不仅限于文件的存储和查询.在云环境下,注记文件系统将比当前的目录文件系统具有更大的优越性,文件的权限控制、版本控制、唯一识别、多设备同步等云原生的文件系统的性质在目录系统下难以实现,或者具有很大的缺陷,而注记文件系统则不同,它能够很好地满足云环境下云原生文件系统的需求,这正是本文后期需要研究的内容.
