利用自相似性实现医学图像合成的生成对抗网络
2024-01-16李帅先谭桂梅刘汝璇唐奇伶
李帅先,谭桂梅,刘汝璇,唐奇伶
(中南民族大学 生物医学工程学院,武汉 430074)
医学图像在临床诊断中起着至关重要的作用,它为医生提供了非侵入性的方法,帮助医生观察和分析病人体内的内部结构,更准确地诊断疾病[1-3].然而,由于技术、设备、成本和患者安全等因素的限制,有时并不能获得所需的医学图像[4].医学图像合成技术可以根据已有的图像数据,通过计算机算法和人工智能技术生成逼真的医学图像,有效地解决数据不足、成本高昂等问题.
在从核磁共振成像(Magnetic Resonance Imaging,MRI)的T1 加权图像合成T2 加权图像中,T1 加权脑图像可以清晰地显示灰质和白质组织,而T2加权脑图像可以描绘皮层组织中的流体,两种图像组合可以帮助医生更准确地识别异常病变组织,更准确地诊断疾病.在从MRI 的3T 图像合成7T 图像中,由于3T 图像的空间分辨率受到限制,很难观察到较小的大脑结构,如海马体等.但是,7T 图像可以提供更高质量的图像.由于7T 图像的成本相对较高且不普及[5],但医学图像合成技术可以用来生成近似于7T的高质量图像,为医生提供更准确、全面的诊断依据.
近年来,深度学习在医学图像合成领域取得了实质性的突破[6-8].基于深度学习的图像合成方法共享一个通用框架,该框架使用数据驱动的方法进行图像强度映射.工作流程通常包括一个网络训练阶段,用于学习输入与其目标之间的映射,以及一个预测阶段,用于从输入中合成目标图像.相比于传统的基于地图集、字典学习等方法,基于深度学习的方法更具有普适性,可以更好地解决医学图像合成问题[9].
GAO 等[10]基于深度卷积神经网络(Deep Convolutional Neural Networks,DCNN),即编码器-解码器神经网络架构,以学习源图像和目标图像之间的非线性映射,实现图像合成.LI 等[11]使用卷积神经网络(Convolutional Neural Network,CNN)从相应的MRI 数据中估计缺失的正电子发射断层扫描(PET)数据.QU等[12]通过在UNet网络中加入来自空间域和小波域的互补信息,实现了从3T MRI 合成7T MRI 图像的任务.CHARTSIAS 等[13]提出了一种用于MRI 图像生成的网络结构,能够自动用现有的模态图像还原缺失的模态图像.ZHANG 等[14]提出了一种双域CNN 框架,该框架分别在空间域和频域中使用两个并行的CNN,通过傅里叶变换相互交互,从3TMRI合成7T MRI图像.
基于生成对抗网络(Generative Adversarial Networks,GAN)的医学图像合成是近年来备受关注的研究热点之一[15-18].NIE 等[5]将GAN 结合自动上下文模型和全卷积神经网络,从MRI 图像合成CT 图像、3T MRI 合成7T MRI 图像.WOLTERINK 等[19]使用GAN 将低剂量CT 图像转换为常规剂量CT 图像.KAWAHARA 等[20]基于具有两个卷积神经网络的GAN 预测框架,实现T1 加权的MRI 图像和T2 加权的MRI 图像的相互生成.YANG 等[21]基于循环一致性生成对抗网络(Cycle Consistent GAN,CycleGAN)模型用于非成对的MR 图像到CT 图像的合成.YANG 等[22]通过利用条件生成式对抗网络(Conditional GAN,CGAN)的深度学习模型,实现T1加权和T2加权的MRI图像的互转.
当前利用卷积神经网络处理医学图像合成任务中,通常依靠堆叠大量卷积层来增加网络的深度或宽度,以更好地拟合非线性关系.此外,一些网络结构如残差结构、U-Net 结构也被广泛应用于医学图像合成,以提高性能和改善效果.然而,很少有工作专注于医学图像本身的特点,缺乏对其特有特征的考虑,导致网络在深层特征提取的能力和表征方面存在不足.
医学图像中存在大量特征相似性较高的图像块.图1呈现了不同患者的7T MRI脑图像(Sample1、Sample2、Sample3),其中相似的图像块可能在同一张切片内不同位置之间(绿色框),或者在连续的切片中同一位置之间(红色框).医学图像具有自相似性特点,即重要的结构和特征在不同空间位置上以相似的方式出现.
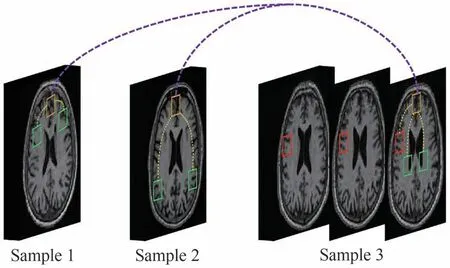
图1 7T MRI图像在不同样本下的内部切片示例Fig.1 Internal slice examples of 7T MRI images in different samples
为此,本文提出了两种注意力块.首先,图结构方法可以模拟不同CT 切片之间的结构连续性和相互作用[16].本文在图像的连续切片下构建了以图像块(patch)为单位的拓扑结构,通过图注意力捕捉医学图像连续切片的关联性,使网络在不同切片之间共享和传递信息,提高特征的学习能力.该方法通过图注意力块(Graph Attention Block,GAB)实现.其次,本文同样构建以图像块为单位的全局块注意力块(Global Patch Attention Block,GPAB)来捕捉同切片下的非局部相似性,建立全局的相互关系,使网络更好地理解同一切片中不同区域之间的关联性,并通过设计一个并行的特征提取单元,该单元通过将GAB和GPAB结合,来进行深度特征提取.
与自然语言序列中的位置信息类似,图像中不同像素之间的位置关系也可以提供重要的上下文信息(黄色框、黄线),对这些位置关系进行位置编码可为网络提供更多的语义信息.此外,在不同样本下的相同位置的切片中(黄色框、紫线),也存在相似的空间结构和位置关系,通过加入位置编码使网络进一步提高对数据特征关系的理解和学习能力.
本文在GAN 框架下,提出了基于图注意力块和全局块注意力块的生成对抗网络(Graph Attention Block and Global Patch Attention Block Generative Adversarial Networks,GGPA-GAN),在生成器加入GAB 和GPAB 以及二维位置编码,丰富语义信息和提升特征表达能力,提高图像合成的精确度.
1 方法
为了更好地实现源图像到目标图像的合成,本文使用生成对抗网络作为框架进行学习.如图2所示,GGPA-GAN由两部分组成:生成器(G)和判别器(D).生成器由编码器、深层特征提取单元和解码器组成,目的在于生成与真实目标图像相似的合成目标图像.判别器由卷积神经网络和全连接层组成.判别器的任务是评估生成器生成的合成目标图像是否与真实目标图像足够相似.在训练过程中,生成器会不断优化自己的参数,最小化其生成的图像与真实图像之间的差异.同时,由于判别器的存在,生成器也会受到来自判别器的反馈,不断改进自己的生成策略,以尽可能地欺骗判别器.通过这种对抗训练方式,生成器和判别器可以互相协作,不断提高网络的性能,最终生成高质量的图像.
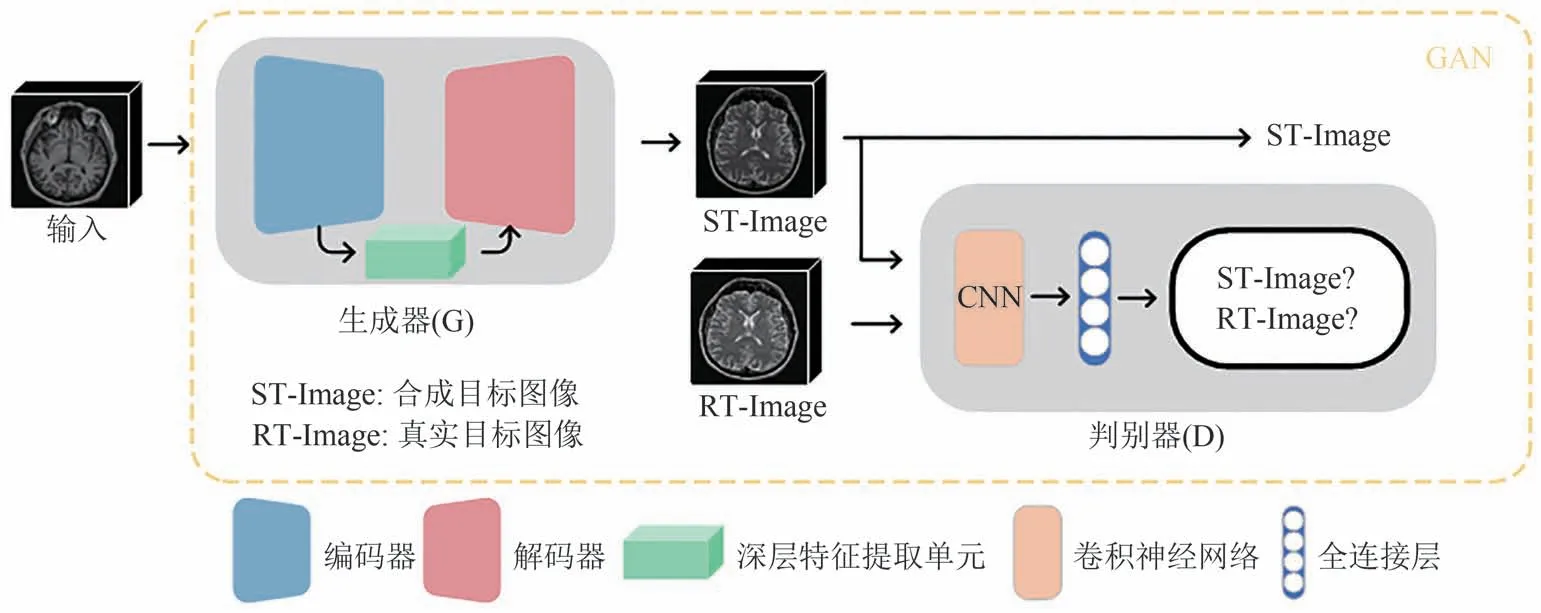
图2 GGPA-GAN的内部结构Fig.2 Internal structure of GGPA-GAN
1.1 生成器网络结构
生成器可以分为3 个阶段,第一个阶段是编码阶段,编码器通过逐层的卷积操作实现下采样来捕捉图像不同层次的特征.第二个阶段是深层特征提取阶段,通过由GAB 和GPAB 构建的深层特征提取单元加强网络对图像特征的感知和提取.第三个阶段是解码阶段,对各层特征图进行整合后使用解码器实现上采样,最后经过1 × 1 的卷积进行通道降维,完成输出.这个阶段是对前面阶段提取的特征进行重建和还原.生成器的结构采用了逐层提取、加强感知能力、逐层重建的策略,通过多层次的处理来捕捉图像的不同特征,以合成高质量的图像输出.如图3 所示为生成器网络内部结构.

图3 生成器网络内部结构Fig.3 Internal structure of the generator network
1.1.1 编码器与解码器
图4 为生成器网络中的编码器内部结构,编码器包括卷积层、激活层、池化层和位置编码.在每个卷积层中,输入图像会与一组内核进行卷积运算,每个内核可以捕捉图像的局部特征,使网络能够有效地学习图像的特征表示.激活层使用整流线性单元(ReLU 激活函数)为神经网络增加非线性运算,其将负输入替换为零,并保持正输入不变.池化层使用最大化池化(MaxPool)用来提取特征图中的最显著的特征,并降低特征映射的维度.位置编码可为网络提供位置信息,该方法将在下文进行介绍.此外,引入残差连接可以使网络更容易学习恒等映射,提高网络性能和训练效率.该网络使用三个卷积层(Conv1、Conv2 和Conv3)以增加网络深度.其中,Conv1 和Conv2 是一个3 × 3 内核大小、填充为1、步长为1 的卷积层.Conv2 的卷积核数量是Conv1 的两倍,以使特征通道数增加.通过卷积核大小为2 ×2,步长为2 的MaxPool 使特征图大小缩小一半.本文中,编码器和解码器具有相同的网络结构和层数,唯一区别在于解码器将编码器中的池化层替换为反卷积层,用于将低维特征图恢复为高维特征图.解码器中的反卷积层使用的卷积核大小为2 × 2、步长为2.本文中的生成器网络包含4个编码器和4个解码器.
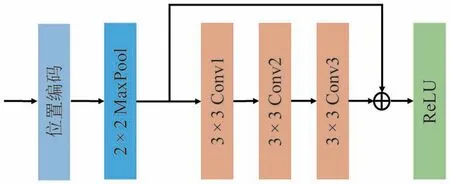
图4 生成器网络中的编码器内部结构Fig.4 Internal structure of the encoder in a generator network
1.1.2 深层特征提取单元
本文的深层特征提取单元位于图3 蓝色框区域.该单元将GAB 和GPAB 相结合,其中GAB 用于捕捉切片之间的相似性,而GPAB 用于捕捉切片内不同图像块的相似性.同时,通过引入残差连接来保留图像的细节信息.原始特征图经过这两种块并行处理后,再将它们的输出进行通道连接.最后,使用卷积核大小为1 × 1 的卷积操作,将通道数恢复为原始的通道数.
1.2 判别器网络结构
判别器包括3 个卷积核大小依次为8 × 8,4 × 4,4 × 4的卷积层、批量归一化层(BN)、ReLU 激活函数层,紧接着还有3个全连接层将数据扁平化,卷积层的卷积核数量依次为8、64、256,全连接层中输出节点数为256、64和1.在最后一层,利用tanh 激活函数作为评估器,得出输入图像是真实图像的概率.图5为判别器网络内部结构.
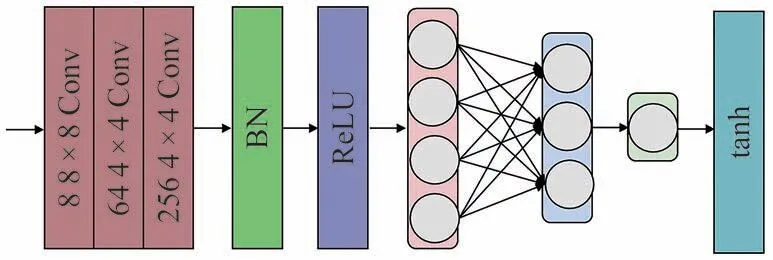
图5 判别器网络内部结构Fig.5 Internal structure of the discriminator network
1.3 位置编码
对于医学图像合成,医学图像通常具有较高的空间分辨率和较复杂的结构.因此在医学图像合成中准确地捕捉到这些空间位置信息对于合成图像的质量至关重要.位置编码是一种将空间位置信息嵌入到特征表示中的方法,通过位置编码学习到图像中不同位置的特征和相对位置之间的关系,从而提高模型的空间感知能力.
如图6 所示为本文的位置编码内部结构,H、W、D分别为特征图的高度、宽度和通道数.本文将Transformer 模型[23]中提出的1D 位置编码技术调整为2D,公式如(1)~(4)所示:
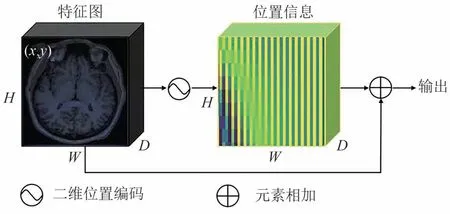
图6 二维位置编码内部结构Fig.6 Internal structure of the two-dimensional position encoding
式中:x和y指定为水平和垂直位置坐标值,即(x,y)为二维空间的一个坐标点;i,j是[0,D/4)中的整数.位置编码得到的位置信息图具有与特征图相同的大小和维度.位置编码的每个维度都由特定频率和相位的正弦信号组成,表示水平方向或垂直方向.本文使用的时间范围从1到10000.不同的时间尺度等于D/4,对应于不同的频率.对于每个频率,在水平/垂直方向上生成正弦/余弦信号.所有这些信号被串联成D个维度,前一半维度为水平位置的编码,后一半维度为垂直位置的编码.最后将位置信息和特征图相加,作为输出.该位置编码具有不向神经网络添加新的可训练参数的优点.
1.4 图注意力块(GAB)
在图注意力块中,将图像数据转换成一张图结构,将不同的图像块作为图中的节点,节点之间的关系构成了图中的边.通过连接不同切片中相同坐标位置的图像块起来,构建出一张具有结构连续性的图.选取其中一切片内的图像块作为中心节点,将其相邻两个切片同坐标位置的图像块作为邻居节点与其关联.这些图像块间存在着不同细节的信息,导致它们之间存在差异.故在中心节点附近选取了若干个节点作为补充.这一点在于图像的任何一个图像块并不是单独存在,图像块会与周围数个像素信息相关联,使中心节点与邻居节点进行相互交互的同时,中心节点可以从周围像素组中弥补缺失.
图注意力网络(Graph Attention Networks,GAT)既能充分结合局部特征又能保留整体的结构信息[24-25].本文构建以图像块作为节点的图结构.其中图像块的大小为h×w,相邻切片的同位置共有n1个图像块相连接,输入维度为[h×w,n1].其中的中间切片的图像块与周围相邻的k个像素相连接,将k个元素重塑为一个矩阵,使输入维度为[h×w,n2].最终,特征向量的总输入维度为[h×w,n],其中,n=n1+n2.
以图7为例,不同颜色的方块代表着一个像素,图中以2 × 2 个像素大小为一图像块,首先将相邻三切片提取的三个图像块(3 × 2 × 2个像素)重塑为4 ×3 的矩阵,然后将与中间切片的图像块相关联的12个像素重塑为4 × 3 的矩阵,将所有矩阵拼接后可得到4 × 6 大小的特征矩阵.特征矩阵的每一列可以被视为该图的一个节点,每对列之间相似性可以视为图的一条边.根据特征矩阵与构建的拓扑结构,得到邻接矩阵,来描述图中节点之间的连接关系.在邻接矩阵中,如果节点i和节点j之间有连接,则邻接矩阵的第i行第j列和第j行第i列的元素值为1,否则为0.最后,通过同时输入邻接矩阵和特征矩阵到GAT 层进行计算,完成对图数据的处理.对于特征图X∈RH×W×C(H、W、C分别为特征图的高度、宽度和通道数),图像块的大小为H/n×W/n,其中n为尺度因子,使图像块能够与特征图的尺寸相匹配.
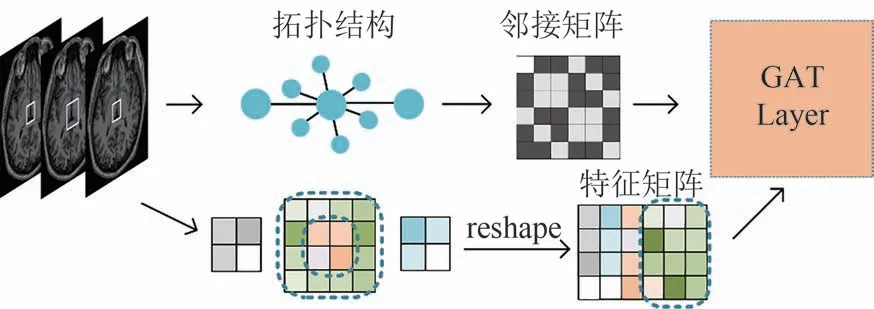
图7 图注意力块(GAB)的内部结构Fig.7 Internal structure of the Graph Attention Module(GAM)
如图8(a)所示,该图以第i个节点的节点特征,以及相关联的5 个节点为例描述GAT 层的计算过程.图注意力层的输入是一组节点特征,h=,通过利用相邻节点的相似性,得到一组新的节点特征为了更新特征,一个可学习的共享线性变换权重矩阵W将应用于每个节点,以生成更深层的特征.然后在节点上执行一个共享的自注意机制e,e:Rd×Rd→R,eij为每条边(i,j)的注意力分数,表示为相邻节点j对节点i的重要性.
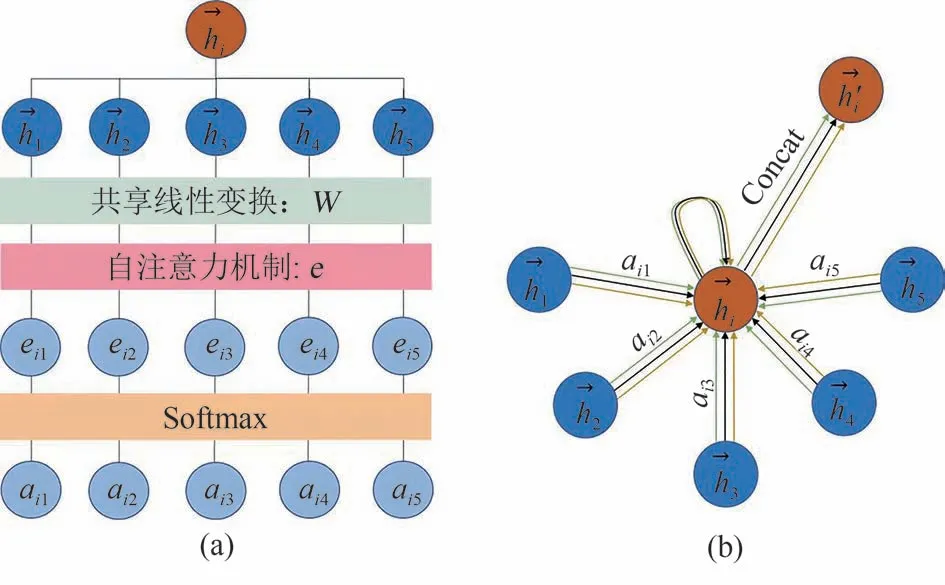
图8 图注意力层流程图与多头图注意力机制Fig.8 Process diagram of the Graph Attention Layer and the Multi-head Graph Attention Mechanism
式中:a∈R2d′,W∈Rd′×d被学习,||表示向量串联.LeakyReLU 为一个非线性激活函数.这些注意力分数在所有邻居j∈Ni中经过Softmax 标准化,注意力函数定义为:
通过标准化注意系数计算相邻节点变换特征的加权平均值(σ是非线性函数),作为节点的新表达形式:
多头注意力机制是提取深层特征的有效扩展方式.在图8(b)中,红色圆圈和蓝色圆圈分别代表第i个节点及其最近的5个相邻节点.不同颜色箭头表示独立的注意力计算,图中展示了3 个注意力头.假设对于每张图结构均使用M个独立的注意力机制,每个注意力机制都能够使用公式(7)来获取第i个节点的更新特征.将M个独立的注意力机制更新后的特征向量连接在一起,进行平均处理,得到最终的节点特征.这个过程可以从不同的注意力机制中获取更加丰富和准确的特征信息,提高模型的性能.此过程如下所示:
1.5 全局块注意力块(GPAB)
为探索医学图像同切片内的特征相似性,本文提出在图像切片内基于图像块的全局块注意力块(GPAB),该块可以通过从全局范围内获取图像中的信息,因此能够更好地捕捉长距离依赖关系,增强局部特征.如图9 所示为GPAB 的内部结构.该块以图像块为单位进行相似度匹配,将每个图像块的特征作为全局特征的一部分,并通过在全局特征中计算相似度矩阵来衡量每个图像块与全局特征关系,此相似度矩阵是多维度的.对多维相似度矩阵进行Softmax函数运算,得到一组注意力权重.最后,每个图像块与全局特征按照对应注意力权重通过哈达玛运算进行加权求和,得到该图像块的最终表示.给定图像特征图X,该注意力定义为:
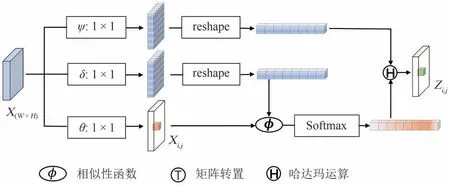
图9 GPAB的内部结构Fig.9 Internal structure of GPAB
式中:(i,j)、(g,h)和(u,v)是特征图X的坐标元组,φ(·,·)为相似性函数,被定义为:
式中:θ(X)、δ(X)、ψ(X)是特征表达函数,通过1 × 1的卷积实现.θ(X)=WθX,φ(X)=WφX,ψ(X)=WψX,其中,Wθ,Wφ,Wψ为可学习的参数;Xi,j,Xg,h,Xu,v为大小、维度相等的图像块.GAB 与GPAB 相同,图像块的大小设置为H/n×W/n,其中n为尺度因子.
1.6 基于对抗性学习下的损失函数
本文将对抗性损失应用于生成器网络及其判别器网络.对抗性损失函数可以定义为:
式中:G表示生成器,D表示判别器,IX表示输入图像,IY表示相应的真实图像.训练中,生成器G试图生成与真实图像IY相比足够逼真的合成图像G(IX).判别器D的任务是区分真实的医学图像IY和合成的医学图像G(IX).生成器G试图最小化该损失函数,而判别器D则试图最大化该损失函数,即:G*=argminGmaxDLGAN(G,D).
除了对抗性损失函数外,生成器的损失函数还包括L1损失来引导生成器生成高质量的图像.生成器G的L1损失项:
GGPA-GAN网络的整体损失函数为:
式中,λ用于控制L1 损失函数和对抗性损失函数之间的权重分配.
2 实验
2.1 数据集
本文的3T-7T MRI合成任务使用的图像数据来自HCP 数据集[26](Human Connectome Project,人类连接组项目).本文的T1-T2 MRI合成任务使用的图像数据来自ADNI 数据集[27](Alzheimer′s Disease Neuroimaging Initiative,阿尔茨海默症神经影像学倡议).针对3T-7T MRI 任务,本文使用80 例成对的3T MRI 和7T MRI 图像,并对所有3T MRI 和7T MRI 图像进行尺寸固定,空间分辨率为180 × 256 ×256,体素分辨率为1.0 mm × 0.8 mm × 0.7 mm.针对T1-T2 MRI任务,本文同样使用80例成对的T1 MRI和T2 MRI 图像,并将所有T1、T2 MRI 的空间分辨率固定为180 × 256 × 256,体素分辨率为0.9 mm ×0.9 mm × 3 mm.所有采集图像均为具有清晰脑部纹理、丰富细节特征的高质量数据,且均经过类间、类内的刚性配准,以保证严格对齐.对于每例数据,将原始强度值线性缩放到[-1,1].将所有数据分为训练集与测试集,每个任务随机选取62例用于网络训练的训练集图像,18 例用于测试网络泛化性能的测试集图像.测试集与训练集不重叠,以确保模型的泛化性能和可靠性.
2.2 实验环境
硬件设备:CPU:Intel Xeon Gold 6240@2.60 GHz × 72;GPU:NVIDIA TITAN RTX 24 G × 2;内存:64 G;软件配置:操作系统为64 位Ubuntu18.04.6 LTS;Python 3.7;Pytorch 1.6.0.
2.3 实验参数设置
在训练过程中,Batch-size 设置为32,每个批次大小为16 × 256 × 256.使用ADAM 优化器实现网络参数优化,网络总轮数设置为300轮.初始学习率0.0002,动量参数为0.9,权重衰减为0.005.
2.4 评价指标
本文采用峰值信噪比(Peak Signal-to-noise Ratio,PSNR)和结构相似性指数(Structural Similarity Index,SSIM)以及平均绝对误差(Mean Absolute Error,MAE)三种指标来评估合成图像的质量.其中,PSNR是一种广泛应用于评估图像清晰度的指标,它基于像素点之间的误差来衡量合成图像与真实图像之间的差异.在计算PSNR 时,均方误差(Mean Squared Error,MSE)越小则PSNR 越大,代表着合成图像的效果越好.峰值信噪比PSNR的计算公式如下:
式中:I(i)表示真实图像中某个像素点的像素值,Syn(I(i))表示在体素空间中合成图像相应像素点的像素值.
SSIM 从3 个方面评价合成图像与真实图像的差距:亮度、对比度和结构,值的范围在(0,1),值越大表示两张图像越相似.结构相似性指数SSIM的计算如下所示:
式中:μR和μS分别表示真实图像和合成图像的均值,σR、σS为真实图像和合成图像的协方差.c1=(k1L)2,c2=(k2L)2为常数,L是像素值的动态范围,在本文中L=7,k1=0.01,k2=0.03.
MAE 是计算每个像素值之间的绝对差异,再取平均值,因此是一种评估两个图像之间平均差异的方法.MAE 越小,两张图像越相似.平均绝对误差MAE的计算如下:
式中:H和W分别表示图像的高度和宽度,X和Y分别表示合成图像和原始真实图像.
2.5 对比实验及分析
为了验证本文提出的模型性能,本文将其与4 种现有模型进行比较,它们分别是UNet++[28]、TransUNet[29]、Pix2pix[16]和CycleGAN[21].其中,分别将AttentionUNet 和TransUNet 作为生成器网络嵌入到本文的GAN 架构中作为对比,以证明本文生成器网络在深层特征提取方面卓越的成效.
UNet++网络在UNet 基础上进行升级,该网络加入了深度监督机制,将跳跃连接改进为密集的短连接,可以抓取不同层次的特征,并将它们通过叠加的方式进行整合.TransUNet同时具有Transformers和U-Net 的优点,相比于传统的卷积神经网络,TransUNet使用了Transformer结构,使得模型可以自适应地学习到图像中的全局和局部特征.Pix2pix 与CycleGAN 为如今主流的医学图像合成方法.Pix2pix是一种基于条件生成对抗网络(CGAN)的方法,通过专注于保持逐像素的强度相似性来合成整个图像.CycleGAN 是使用对抗性损失函数合成图像,同时通过一个循环一致性损失函数保持图像的原始语义信息.
2.5.1 定性评估
对3T-7T MRI 和T1-T2 MRI 两个任务进行了定性比较实验,图10 为本文方法与4 种对比方法在相同测试图像下的矢状面和轴位面上进行3T-7T MRI任务测试的定性比较结果.可见大多数对比方法不能很好地恢复图像细节.如CycleGAN 的局部放大结果整体非常模糊,而本文方法合成的图像比对比方法拥有更清晰的细节.图11 所示为本文方法与4 种对比方法在矢状面和轴位面上进行T1-T2 任务中的定性比较结果图.可见与3T-7T任务相比,T1与T2图像具有边界模糊、噪声、对比度差的特点,本文在任务中能较为清晰地还原图像的轮廓与细节特征,边缘也较为平滑.综上,本文方法的合成效果优于其他4种对比的合成方法.
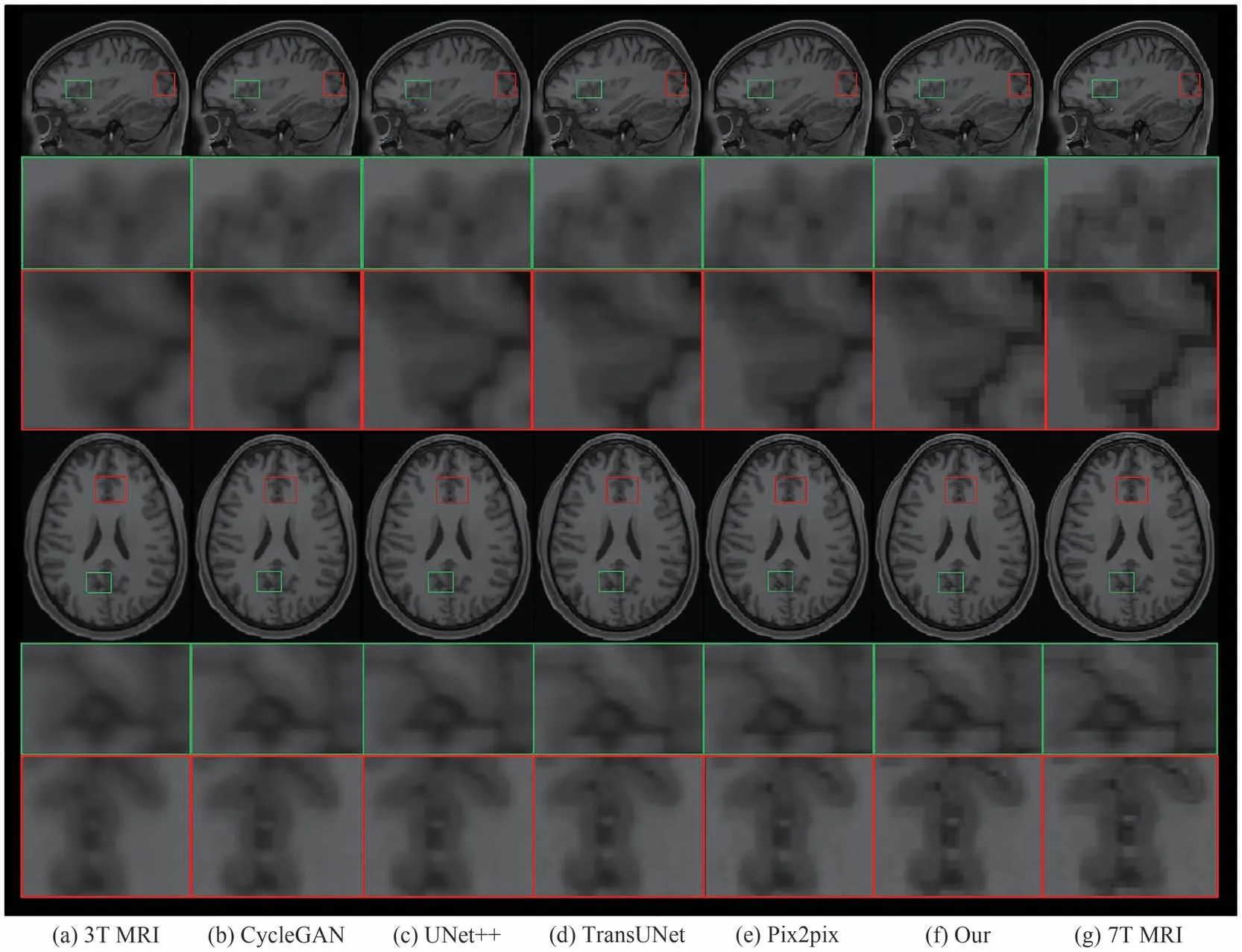
图10 本文方法与 4种对比方法在 3T合成7T MRI任务中的定性比较结果Fig.10 Qualitative comparison results of the proposed algorithm and four comparison algorithms in the 3T to 7T MRI synthesis task
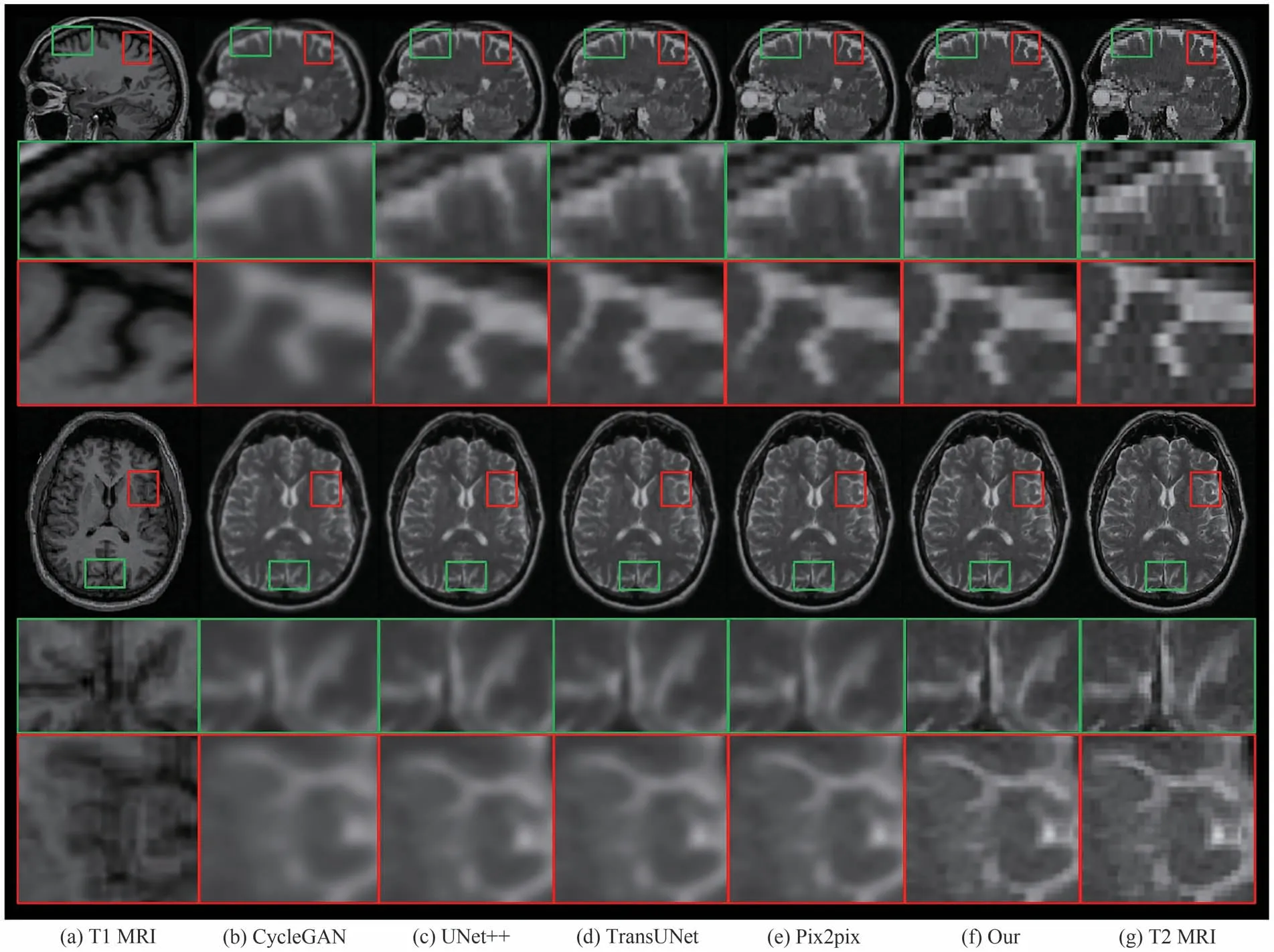
图11 本文方法与 4种对比方法在 T1合成T2 MRI任务中的定性比较结果Fig.11 Qualitative comparison results of the proposed algorithm and four comparison algorithms in the T1 to T2 MRI synthesis task
2.5.2 定量评估
实验利用PSNR、SSIM、MAE 客观评价指标在3T-7T MRI、T1-T2 MRI 两个任务中测试了18 例MRI图像,本文方法的表现均优于对比的4种合成方法,本文方法及4 种对比合成方法在PSNR、SSIM、MAE的测试结果折线图分别如图12-13 所示,其中绿色折线表示本文方法的客观评价结果,评价结果平均值如表1所示.

表1 客观评价指标平均值Tab.1 Average value of objective evaluation metrics

图12 本文方法与4种对比方法在3T合成7T MRI任务中的定量结果Fig.12 Quantitative results of the proposed algorithm and four comparison algorithms in the 3T to 7T MRI synthesis task
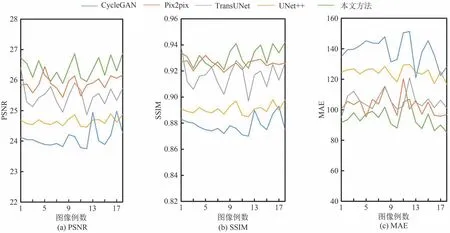
图13 本文方法与4 种对比方法在T1合成T2 MRI任务中的定量结果Fig.13 Quantitative results of the proposed algorithm and four comparison algorithms in the T1 to T2 MRI synthesis task
由表1 可知,利用本文方法进行合成可以获得各项指标的最大均值.在T1-T2 MRI图像实验中,合成具有较高质量和真实感的合成图像是一项具有难度的任务,任务对于网络的非线性拟合的要求更高,本文的取得的成绩更为显著.
2.6 消融实验
2.6.1 多种方法组合下的消融实验
本文所提出的生成器网络包含3 个核心组件,即图注意力块(GAB)、全局块注意力块(GPAB)和位置编码,实验通过不同的组合来研究它们的影响,从图像视觉效果和定量结果两方面进行对比实验.表2显示了HCP数据集上关于这些组合的消融实验的结果,图14 展示了消融实验的视觉效果比较.视觉效果通过差值图的方式呈现.差值图通过将合成图像与真实图像相减得到,用于表示两个图像之间的差异.通过比较差值图的特征,可以对不同方法的表现进行评估和比较.

表2 在HCP数据集中关于不同方法组合的消融实验的定量结果Tab.2 Quantitative results of the differential ablation experiments on different combinations of methods in the HCP dataset

图14 在HCP数据集中关于不同方法组合的消融实验差值图Fig.14 Differential plot of ablation experiments on different combinations of methods in the HCP dataset
2.6.2 关于尺度因子n的消融实验
在图注意力块和全局块注意力块中,本文以图像块作为计算单位.尺度因子n越大,表示图像块的尺寸越小.因此,本文研究了尺度因子n对网络效果的影响,如表3所示,基于HCP数据集进行了尺度因子n的消融实验.尺度因子n分别设置为12、8、4,其中n=12时取得了更好的效果,说明较小的图像块可以作为计算单位进行计算.使用较大的图像块尺寸时,模型的性能会受到一定的影响,由于较大的图像块意味着对图像块之间的相似性有更高的要求.在实际实验中,本文没有将n设置为12,而选择了n=8,原因是当n过大时,计算量也会增加,导致网络在测试时耗时较长,而带来的性能提升相对较小,得不偿失.综上,选择将n设置为8.
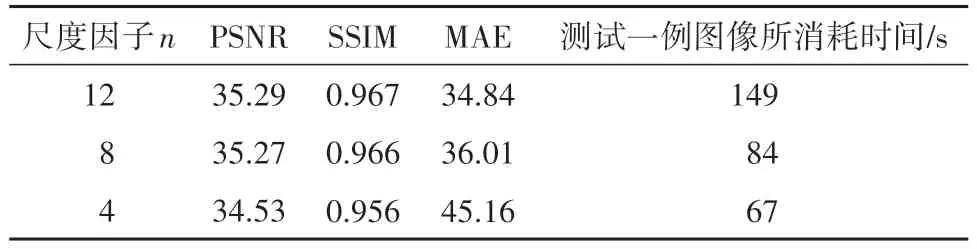
表3 不同尺度因子n的大小的消融实验客观评价指标Tab.3 Objective evaluation metrics for the ablation experiment of different scale factors n
2.6.3 关于GAB中多头注意力机制的消融实验
GAB 使用多头注意力机制,增加注意力头的数目可以增加模型的表达能力,过高会导致过拟合问题.本节中对比了不同头数的多头注意力机制对模型性能影响,表4 展示了使用不同头数的多头注意力机制的最终结果,可见当使用8头注意力机制时,模型达到了最好的性能.
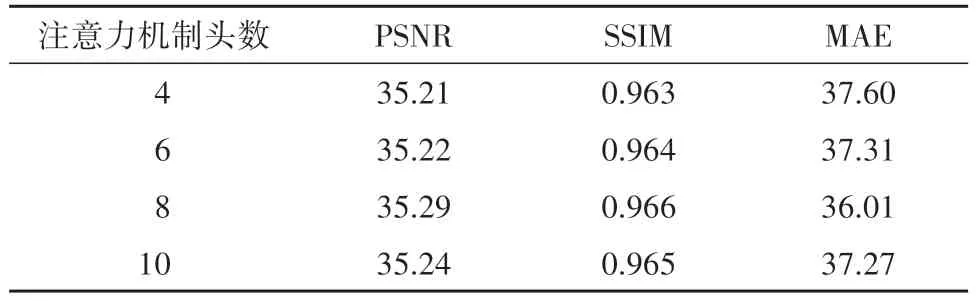
表4 多头注意力机制的消融实验客观评价指标Tab.4 Objective evaluation metrics for the ablation experiments of multi-head attention mechanism
3 结语
经过研究和实验验证,本文提出的自相似增强特征生成对抗网络(GGPA-GAN)在跨模态医学图像合成任务中展现出卓越的性能.与现有方法相比,GGPA-GAN 利用图注意力块和全局块注意力块捕捉医学图像切片间和切片内的自相似性,并通过二维位置编码增强了语义信息的表达能力.在HCP_S1200 数据集和ADNI 数据集上的实验结果表明,GGPA-GAN 在合成3T-7T、T1-T2 脑部MRI 图像任务中达到了最优水平.该研究的成功应用为临床诊断提供了有力的支持,为深入探索医学图像合成领域开辟了新的方向.
