基于并行反向投影的图像超分辨率
2024-01-16熊承义李雪静高志荣孙清清刘川鄂
熊承义,李雪静,高志荣,孙清清,刘川鄂
(中南民族大学 a.电子信息工程学院;b.智能无线通信湖北省重点实验室;c.计算机科学学院,武汉 430074)
近年来,单幅图像超分辨(SISR)在计算机视觉任务中应用广泛,包括医疗图像[1],图像生成[2]等领域.SISR 旨在从退化的低分辨率图像(LR)中产生一个视觉良好的高分辨率图像(HR).因为SISR 是一个不适定问题,所以近期比较流行的做法是通过学习LR 到HR 的非线性映射来构建一个HR 图像.主流方法可以分为两类:一类是搭建深度神经网络(DNN)[1,3-8],另一类则是搭建非深度神经网络[9-12].
对于DNN 方法,网络从LR 图像中获取特征图,并通过增加一个或多个上采样层来不断增加图像的分辨率,以此构建HR 图像.然而单纯的向前传播很难展现LR 和HR 的关系,所以人们开始尝试用反馈连接来指导最后的重构图像.
最初将反馈连接有效应用在超分辨率(SR)算法中的是迭代反向投影[13].它迭代地计算重构误差,并据此调整HR 图像.尽管提升了重构图像质量,但重构图像仍然有响铃和棋盘效应.此外,这个方法对迭代次数以及模糊因子很敏感,不同的参数可能会导致不同的结果.
HARIS等[14]提出了深度反向投影网络(DBPN),运用迭代的上下采样层来构建一个端到端的网络结构,不仅解决了重构图像的响铃和棋盘效应,还在高放大因子下实现了图像超分辨率的提升.然而,DBPN只考虑了一个尺度上的特征学习和重构,忽略了下采样操作可能导致的信息丢失,进而影响最终的重构效果.因此,本文提出了基于并行反向投影的图像超分辨率网络,即在多级的反向投影模块中新增一条通路,进行与之相反的上下采样操作.随后,分别对两条通路进行残差操作,得到不同频段上的高频信息,并将其叠加到与原始的通路中去.通过这样的方式,不断增强图像的高频特征,扩大感受野,避免了因下采样操作造成的信息丢失.不仅如此,还在多级残差融合后对其进行通道注意力的增强,以便学到更多的关键信息,提升图像的重构效果.实验结果表明,本方法重构的图像较同类方法在超分辨率性能上有明显提高,且在模型复杂度和性能方面取得了良好的平衡,实用性更强.
1 相关工作
最近,SISR 因其广泛的应用和优秀的性能而被越来越多的研究人员关注.其中,迭代反向投影和通道注意力增强都取得了令人瞩目的成果.
1.1 迭代反向投影
反向投影是减少重构错误的一种有效手段.最初,反向投影被用来实现多个LR 图像的输入.然而,TIMOFTEN 等[15]发现反向投影可以提高SR 图像的质量.随后,ZHAO 等[16]通过一个迭代的投影操作来调整高频图像的纹理细节.所有这些研究都证明了迭代反向投影可以有效处理高频特征,提升重构图像的质量.
在反向投影网络中,如果仅输入一个LR 图像,则反向投影的公式可表示为:
其中,p是一个连续的反向投影核,g是一个单独的模糊滤波,↑s和↓s分别代表上下采样操作是第t次迭代输入的LR 图像分别是第t次迭代中生成的HR 和LR 图像代表输入LR 图像与生成LR 图像之间的残差是此残差上采样的结果,则是第t层迭代最终产生的SR图像.
1.2 通道注意力增强
人类视觉在处理整幅图像时,会倾向关注重点区域,忽略其他无用信息,提高视觉信息处理的效率和准确性.受此启发,许多研究围绕着如何聚焦最有用的信息展开.HU 等[17]提出了一个“压缩与激励”(SE)块,通过建立通道之间的相互依赖性来自适应地校准通道间的特征响应.据此,通道注意力机制证明了其在指导特征学习上的有效性,并在SISR领域中受到了越来越多的重视.
为了选出一幅图片中最有用的信息,利用全局信息作为指导来分配权重是必要的.这是因为卷积神经网络的局部操作使得每一个输出值难以代表整个图片的依赖关系.令输入X=[x1,…,xc,…,xC],维度H×W包含C个特征映射.通道注意力的步骤如下所示.第一步,通过一个全局平均池化获得全局统计数字,即Z=[z1,…,zc,…,zC].Z的第c个元素定义为:
其中,xc(i,j)是c特征映射xc在(i,j)上的值.FGAP(·)代表全局平局池化.第二步,对不同通道上非线性交互和非相互排斥的关系进行注意力学习(AL),用公式表示为:
其中,FAL(·)代表用注意力学习每个通道合适的权重,s和δ分别是sigmoid 函数和ReLU 函数[18].W1和W2是两个全联接层(FC)的参数.假设Z 有C个通道,则第一个FC 层的输出有个通道(r代表压缩比),第二个FC 层的输出有C个通道.第三步,应用学习到的权重因数W 对输入进行重新分配,这样输出Y的第c个特征映射yc就可以表示为:
其中xc和wc分别代表输入X 的第c个映射和其对应的权重因数.据此,输入可以自适应地聚焦到最重要的特征.
2 提出的方法
本文提出的基于并行反向投影的超分辨率重构网络,通过迭代的上下采样层,增强HR 图像在不同尺度上的特征提取.不同于DBPN[14]中单路的上下采样投影单元,本文网络包含两个并行的通路,不同通路得到图像在不同尺度上的投影结果.一个通路按照DBPN 提出的上下采样模块进行特征学习,而另一个通路进行与之相反的上下采样操作.在得到不同频段上的高频残差信息后进行叠加融合,实现对原有尺度特征信息的增强.最后,将叠加的特征信息进行上采样,融合初始高频特征并对通道进行注意力增强,实现重构图像质量的提升.
2.1 网络结构
如图1所示,网络的整体结构由三部分组成:浅层特征提取模块(SFES)、反向投影模块(BPS)和深度重构模块(DRS).图中绿色块代表卷积操作(conv),深蓝色块代表上投影单元(Up projection),深棕色块代表下投影单元(Down projection),浅蓝块代表上采样操作(Up Block),浅棕块代表下采样操作(Down Block),深紫块代表通道注意力操作(CA),浅橙块代表级联操作(concat).
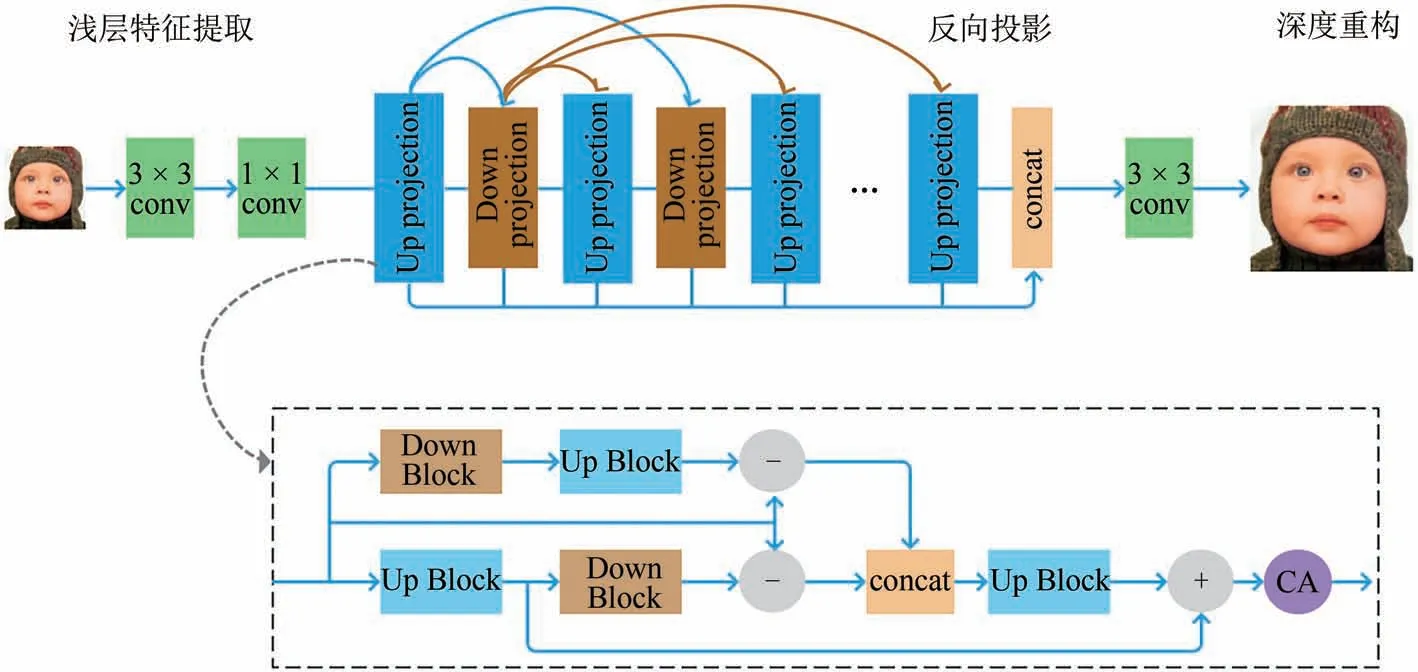
图1 网络的整体结构框图Fig.1 Block diagram of the whole network structure
在浅层提取模块中,通过一个3 × 3卷积提取原始的LR 图像特征.接着用一个1 × 1卷积来降维,使其在进入反向投影模块前保持维度的一致性.假设提取到的浅层特征为H0,则有:
其中ILR代表网络的输入(LR 图像),FSFES(·)表示卷积操作.随后,H0作为输入被喂到下一个反向投影模块(BPS)中来调整LR 到HR 的特征投影.因为通过密集连接,输出可以联系到前面的每一层,则第t层的输出可以表示为:
其中,FBPS(·)代表一系列的反向投影层,t=1,2,…,T.不同阶段的层级信息都作用于最后的重构阶段,所以将所有的信息全局化地融合到一起.关于BPS 网络的更多细节将在2.2 节中给出.最后,将融合后的信息[H1,H2,…,Ht]作为重构单元的输入以产生最终的SR图像,模型最终的输出ISR可以表示为:
其中FDRS(·)表示一个3 × 3 的卷积操作,[H1,H2,…,Ht]代表每一个上采样单元特征投影的级联.
选择L1损失函数来最优化网络.给定N 对图像作为训练集,可以表示为其中,一对图像中包含一个LR 图像的输入和其对应的HR 图像.所以,最优化的目标可如下所示:其中代表预计从中恢复出的SR 图像,θ代表网络的学习参数,FPDBPN(·)表示网络总体结构的函数表达式.
2.2 并行反向投影模块
通过在不同尺度上进行连续的上下采样操作,能够保留HR 的特征,并学习到更深的高频特征.因此,用一个端对端的可训练结构指导SR图像运用相互联系的上下采样层来学习LR 和HR 图像之间的非线性关系.具体地说,上投影单元产生HR 图像的特征投影,然后下投影单元又将其返回到LR 空间投影中.
上投影单元的定义如下所示:
其中*代表空间卷积操作,↑s和↓s分别代表缩放因数为s的上下采样操作,pt,gt和qt代表在t阶的卷积或反卷积层数.
上投影单元的示意图如图2(a)所示.将之前提取的LR 特征投影Lt-1和Ht-1分别作为两路通道的输入,第一路上采样得到一个中间投影变量,第二路下采样得到一个中间投影变量;之后,分别将其投影回LR 和HR 得到算出两路的残差后使之级联,得到并再一次投影到HR上,产生一个中间残差投影
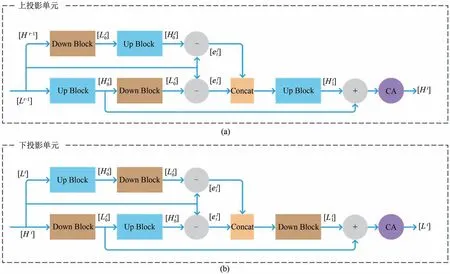
图2 上下投影单元的内部结构Fig.2 Internal structure of up and down projection unit
考虑到注意力机制能够增强网络对特征通道的判别能力,进而提升网络性能,在投影单元的最后引入通道注意力(CA)块,如公式(20)所示:
其中FCA(·)代表通道注意力操作.在将两个HR 上的中间投影变量相加后,对其进行通道注意力增强,来选择性提升有用的高频特征信息并抑制对性能影响较小的无用特征.虽然增加了一定的系统复杂度和重构时间,但其有效提升了网络的模型性能,更多细节见3.3 节中的消融实验与分析.最终得到了该单元的输出Ht.
下投影单元的操作与之类似,如图2(b)所示.公式定义如下:
此外,投影单元应用在不同阶段可以作为自我纠错的手段,即当喂入一个投影错误后,反馈能够迭代地修正最后的重构效果.改变投影单元中滤波器的大小,分别得到×2、×3 和×4 尺度下的超分辨率图像.因为并行迭代的上下采样单元能够在不损失高频特征信息的情况下保留LR 和HR 之间的关系,所以能够重构出质量更好的图像.
3 实验
3.1 实验设置和训练数据
DBPN 网络根据放大倍数的不同而选择不同的投影单元.对于2 倍投影,卷积核为6,步长为2,填充为2.4倍投影的卷积核为8,步长为4,填充为2.而8 倍投影的卷积核为12,步长为8,填充为2.与之对应,2 倍和4 倍的投影单元在参数上与DBPN 网络保持一致,但是在3倍投影中,使用的卷积核为7,步长为3,填充为2.
不仅如此,DBPN 在不同倍数的放大网络中使用的投影单元数量也不同,例如在8倍放大中,共采用了19 个投影单元(10 个向上的和9 个向下的).而放大倍数越小,投影单元越少,参数也越小.与之相比,本文网络采用了统一的投影单元数量,即6个上采样投影单元和5 个下采样投影单元.实验结果证明,该网络可以兼顾参数和重构效果,实用性更高.
具体地,本文的训练集是经过扩增的DIV2K[19]数据集(包括缩放、旋转和任意裁剪),共计51200幅图片.在训练阶段,将每幅HR 图像随机分割成256 × 256 的图像块和不同放大因子(×2,×3,×4)下对应的LR 图像块.在测试阶段,用五个标准数据集:Set5[20],Set14[21],BSDS100[22],Urban100[22]和Manga109[23]进行验证.超分辨率的结果用Y 通道上的PSNR 和SSIM[24]进行评价.运用的学习框架为Tensorflow,在Ubantu18.04系统上使用两张12 GB的Nvidia TITANX 显卡完成所有的训练和测试.BatchSize设置为16,共训练500个周期.学习率初始化为1e-4,并且每10 个周期衰减为原来的0.8 倍.网络通过Adam Optimizer 进行优化,损失函数设置为L1.
3.2 实验结果
在五个标准数据集上对比了本文网络与其他类似的超分辨网络在同等条件下的实验结果,包括SRCNN[25]、VDSR[6]、LapSRN[4]、RDN[26]和DBPN[14].表1列出了在不同放大因子下基准数据集上的对比效果,最好的结果用加粗黑体标出.

表1 不同重构算法在×2,×3,×4放大因子下的PSNR(dB)和SSIM的比较Tab.1 Comparison of PSNR(dB)and SSIM of different reconstruction algorithms at ×2,×3,×4 amplification factors
从表1 可以看出,在公开数据集上的所有放大倍数下的图像超分辨重构实验中,本文网络的效果是最好的.以×4 放大因子上的Set5 数据集为例,提出的方法比RDN[26]和DBPN[14]在PSNR 指标上均获得了0.08 dB 的性能提升,而参数分别减少了16.9 M和4.8 M.这表明该网络能够在保证图像质量的情况下,有效降低模型参数和计算的复杂度.这是因为投影单元在并行通道后用1 × 1 卷积对数据进行了降维,减少了参数量.不仅如此,因为并行通道提高了网络对不同尺度特征的适应能力,能够在较浅的网络下达到更好的学习效果,所以减少了级联的模块个数,增加了网络的普适性.而相较于SRCNN[25]、VDSR[6]、和LapSRN[4]来说,虽然本文参数有所增加,但是在PSRN 上也分别获得了2.07 dB、1.2 dB 和1.01 dB 的性能提升,因此牺牲一定的系统复杂度是有必要的.
在其余四个数据集上,本文方法也比其他同类方法在图像效果上至少提高了0.02 dB,这主要是因为并行反向投影模块可以学习到不同尺度上的高频信息,对信息重构提供了更多的指导作用.并且,该结构还保留了因上下采样而损失掉的特征信息,增强了错误反馈机制的作用.最后,并行结构扩大了感受野,使网络获得了更强的重构能力.
此外,在Set14 数据集(×4)上将本文算法(PDBPN)与其他算法在模型大小、重构时间和性能表现上作了比较,如表2 所示.由表可知,本文算法在平均重构时间上位列中等,但在PSNR 性能表现上排名第一.与RDN[26]和DBPN[14]相比,PDBPN有更小的参数量和更快的重构时间.虽然与其他方法相比,参数量和重构时间有所增加,但是PDBPN 在性能表现上更好.综上所述,本文算法在性能和重构时间上取得了很好的平衡,具有更强的实用性.
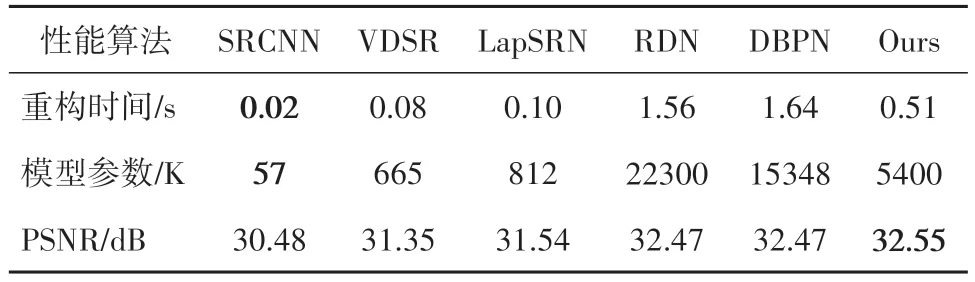
表2 放大因子为×4的Set5数据集上,不同算法在速度、参数、重构性能之间的比较Tab.2 Comparison of speed,parameter,reconstruction performance of different algorithms on Set5 at amplification factor=×4
为了比较不同算法下的视觉效果,下面给出了4 倍放大因数下SRCNN[25]、VDSR[6]、RDN[26]、DBPN[14]和本文方法得出的重构图像.在图3中,重构出的斑马纹理相对于DBPN[14]和RDN[26]来说减少了模糊,边界更清楚,而SRCNN[25]和VDSR[6]分别有不同程度的扭曲变形;在图4中,本研究重构出的文字轮廓更加清晰,其他方法均有不同程度的模糊和重影;在图5中,本方法重构出的图像在鸟喙处更加尖锐,且轮廓相较其他方法更加可辨.从放大细节可以看出,本文网络重构出的图像是最清晰可辨的.

图3 ×4放大因子下不同算法对‘zebra’的重构结果Fig.3 Reconstructed results of image ′zebra′ by different algorithms at ×4 magnification factor

图4 ×4放大因子下不同算法对‘ppt’的重构结果Fig.4 Reconstructed results of image ‘ppt’ by different algorithms at ×4 amplification factor

图5 ×4放大因子下不同算法对‘bird’的重构结果Fig.5 Reconstructed results of image ′bird′ by different algorithms at ×4 amplification factor
3.3 消融实验及分析
为了验证不同模块的作用,测试了×2 放大因子下Set5 数据集上并行结构(PL)、通道注意力机制(CA)和密集连接(DC)对重构性能的影响,如表3所示.

表3 ×2放大因子下的Set5数据集上的消融研究结果Tab.3 Ablation experimental results on Set5 at ×2 amplification factor
从表3中可以看出,并行结构、通道注意力机制和密集连接模块对重构效果都有不同程度的提高,其中并行结构尤为突出.基于此,本文的网络将三个模块一并保留,以此得到更好的重构效果.
4 结语
基于并行通道可以有效获取并增强图像的高频特征,设计了一个基于并行反向投影的超分辨率网络.网络中包含了多级的并行反向投影特征增强模块和通道注意力机制,通过对多级残差信息的融合,使得图像的高频特征得到不断增强.实验结果表明,本文提出的网络可以有效提升超分辨率性能,并且很好地平衡了模型复杂度和性能的关系,具有更强的实用性.
