多尺度融合卷积神经网络支持下的SAR影像变化检测
2024-01-16刘善伟万剑华MUHAMMADYasir
段 玉,刘善伟,万剑华,MUHAMMAD Yasir,郑 爽
(1. 中国石油大学(华东)海洋与空间信息学院,山东 青岛 266580;2. 自然资源部海上丝绸之路海洋资源与环境网络观测技术创新中心,山东 青岛 266580;3. 山东财经大学公共外语教学部,山东 济南 250014)
合成孔径雷达(synthetic aperture radar, SAR)影像变化检测是用于检测同一区域不同时间内变化的技术[1]。在洪涝灾害检测、海岸线的动态监测等方面发挥着重要的作用[2]。
SAR影像变化检测通常包括3个主要步骤: ①预处理,以抑制图像噪声;②构造差异图 (difference image, DI);③差异图分析,以检测变化或不变的像素[3]。斑点噪声的存在让SAR影像变化检测比光学影像更具挑战性,而降噪对于SAR数据的准确识别和解释至关重要。常用的空间域滤波器包括中值滤波[4]、均值滤波、Lee滤波[5]、Kuan滤波[6]和形态滤波[7]等。中值滤波器等虽然能有效地去除噪声,但其无法区分噪声和信号,去噪过程中会去除一些图像纹理,导致清晰度和质量降低,这在复杂影像或有精细细节的影像中尤为明显。Lee等滤波器则会导致边界和细节信息的丢失,不能满足变化检测的需求。针对这些问题,本文提出一种显著性中值滤波器来抑制图像的背景噪声。根据变化检测的特点,对SAR影像的背景噪声进行分层滤波,在去除背景噪声的同时保留更多细节,以满足高精度变化检测的需求。
差异图的生成是变化检测中至关重要的一步,它影响着后续分析的结果。由于乘性噪声的存在,因此多采用比值算子产生差异图,如对数比算子[8]和邻域比算子[9]等。聚类法是差异图分析中的常用算法,文献[10]使用模糊C均值聚类(fuzzy clustering methods, FCM)和马尔可夫随机场来降低图像噪声。考虑标准FCM对散射噪声具有敏感性,有学者在算法中引入邻域信息,以提高变化检测的稳健性。文献[11]采用空间模糊聚类方法(spatial fuzzy clustering methods, SFCM)降低FCM对噪声的敏感性。近年来,深度神经网络在SAR影像变化检测中发挥着重要作用。基于深度学习的变化检测通常将不同时相的两幅影像作为输入,通过良好的设计进行特征表达和噪声抑制。卷积神经网络(convolutional neural networks, CNN)由于其独特的结构和局部权重共享机制,在各种深度学习网络中脱颖而出,常用于空间的特征提取与表达[11-14]。虽然CNN在提取空间特征方面取得了很好的进展,但是这些网络没有考虑多尺度信息,可能会导致特征表达不足,关键信息丢失,从而降低检测的准确性。
综上,本文提出一种多尺度融合卷积神经网络--squeeze, expand, and excitation network(SEENet),设计一个多感受野通道注意力模块squeeze,expand and excitation(SEE)。SEENet主要由3个SEE模块组成,受Fire模块[15]和squeeze and excitation (SE) block[16]的启发,SEE模块利用不用大小的卷积核获取多尺度信息,并自动学习获取每个通道的重要性,以增强有用特征,抑制无用特征,从而实现对多感受野信息的高效选择。SEENet通过残差设计对多级空间特征进行组合利用来留存更多的变化细节,从而达到令人满意的检测精度。
1 研究方法
本文提出的变化检测方法包含4个步骤: ①显著性滤波去噪;②选择可靠样本; ③数据准备;④构建SEENet。具体而言,首先采用显著性滤波去除图像中的背景噪声;将灰度共生矩阵提取的纹理特征与去噪后的原始图像相结合形成样本。然后采用无监督聚类方法得到粗略的分类结果,并选择置信度较高的样本作为标签,指导SEENet训练。最后采用最小交叉熵损失函数进行迭代,并将所有样本输入SEENet以获得最终的变化检测结果。
1.1 显著性滤波去噪
首先使用显著性提取方法获取显著性图像,以区分图像的前景和背景。前景是可能改变的区域,背景是潜在的不变区域。然后根据显著性值,使用不同大小的窗口对背景进行滤波,在去噪的同时保留变化主体的细节,从而获得更好的变化检测结果。
利用上下文感知显著性检测[17]的方法进行显著性区域提取,该方法基于人类视觉注意力原则,在多个尺度上对像素的显著性值进行评估,提取出具有吸引力和紧凑的显著性区域。将像素的显著性值定义为
(1)

(2)
式中,i、j为像素点在图像中的位置;Median为中值滤波器。
对原始影像I1、I2进行显著性中值滤波操作,得到滤波后的两幅影像C1、C2。
1.2 选择可靠样本
对于滤波后的影像C1、C2,首先利用经典对数比算子生成差异图,然后利用空间聚类算法[11]对差异图进行预分类,得到粗分类结果。粗分类结果是一幅包含变化和未变化两类的二值图,其中“0”为未变化区域,“1”为变化的区域,从中选择可靠样本,可以指导神经网络的训练,实现无监督的变化检测。而很多像元在其属于“0”和“1”之间有着模糊的界限,直接使用差异图的粗分类结果来当作标签通常会有很多误差,因此需要进一步筛选,确定置信度更高的样本。当一个像素与其周围的相邻像素相同时,那么这个像素是一个内部点,通常认为它是可靠的;当一个像素的周围像素有一半及以上与它相同时,那么这个像素是一个边缘点,也是可靠的[20]。因此,统计像素D(i,j)周围的8个像素D(i-1,j-1)到D(i+1,j+1)的变化类型,与中心像素变化相同的像素所占比例作为标签的置信度。公式为
(3)
式中,NB(Fij)表示Fij的相邻元素;ε为阈值,本文选取0.75作为阈值,选取大于0.75的像素值作为可靠标签。
1.3 数据准备
将不同的特征进行组合可以提高模型的稳健性和泛化能力,更好地适应各种复杂场景的需求。因此,对原始影像提取纹理特征,连同原始影像组成输入层输入到SEENet中。灰度共生成矩阵[21](grayscale co-generation matrix, GLCM)是一种利用图像灰度空间相关特征描述纹理的通用方法,包含能量、熵、方差等多个标量。其中,能量为GLCM的角二项式矩,可以反映纹理的粗细度和灰度均匀分布程度。因此,本文选择GLCM中的能量标量作为纹理特征,其提取公式为
(4)
式中,G为灰度共生矩阵;i为行号;j为列号;k为灰度值的级数。
通过上述操作,生成I1、I2的纹理特征影像W1、W2,与去噪后的影像C1、C2进行叠加。对于任意一幅影像,以任意像素为中心连同周围m个像素作为网络的输入。利用1.2节挑选出的标签指导样本生成,最后生成n×n×4大小的训练样本,经过旋转等增强手段后,与标签进行组合,输入到SEENet进行训练。最后将所有像素块输入到训练好的网络中,得到最终的分类结果。
1.4 SEENet
将Fire模块和SE Block组合作为一个SEE模块,如图1(a)所示。将1×1的卷积作为squeeze部分对特征图进行大小调整,expand由一组连续的1×1卷积和3×3卷积通过连接操作生成,多感受野可获取多尺度特征,然后利用SE Block得到每个通道的权值,建立通道之间的依赖关系,强调有用特征。为了提升运算速度,本文将SE Block中的全连接层替换为卷积层。

图1 网络结构
SEENet如图1(b)所示,总共设置了3个SEE模块,每个模块都对特征图的大小进行了压缩。本文使用RMSProp优化器和交叉熵损失函数进行训练。SEENet网络结构由1个卷积层、3个SEE模块、1个Fire模块和1个dropout层组成。第一个卷积层的通道数为64个,SEE模块分别有16、24和32个通道。将每个SEE模块生成的特征图通过深度连接后输入到具有64通道的Fire模块中,经过dropout层、分类层得到最终的变化检测结果。
经过3次SEE模块压缩后的特征图大小分别为6×6、3×3和2×2。浅层网络可以获取更多的细节信息,而深层特征具有更强的语义信息和更少的噪声。本文将3个SEE模块的输出特征通过残差连接进行特征融合,在减少噪声的同时保留更多细节。最后经过卷积层分类得到最终结果。
2 结果与讨论
2.1 试验数据
本文在由3个传感器获得的4个真实数据集上进行了试验,以验证本文方法的有效性。如图2所示,黄河数据集由Radarsat-2传感器捕获,包含内陆水数据集(291×444)和农田D数据集(257×289)。渥太华数据集由Radarsat传感器分别采集于1997年1月和8月,大小为290×350像素。旧金山数据集由ERS-2传感器分别获取于2003年8月和2004年5月,大小为256×256像素。在4个数据集的地表真实变化标签中,黑色表示不变的区域,白色表示发生变化的区域。为了更好地评估方法性能,将本文方法与几种传统的变化检测方法广义最小误差阈值(GKI)[22]、SFCM[11],以及深度学习方法极限学习机(extreme learning machine, ELM)[23],深度置信网络(deep belief network, DBN)[20],主成分分析网络(principal component analysis network, PCANet)[24],CWNN[13],双域网络(dual-domain network, DDNet)[25],胶囊网络(capsule network, CapsNet)[26]进行比较。以假阴性(FN)、假阳性(FP)、总体误差(OE)、正确分类百分比(PCC)和Kappa系数为指标,对试验结果进行定量评价。

图2 4个真实数据集上的可视化结果 (从上到下为内陆水、农田D、渥太华、旧金山)
2.2 试验结果
图2展示了4个真实数据集及部分性能较好的试验结果。由于每个数据集的噪声水平不一致,如果对模型进行统一训练会导致对模型对不同数据集噪声和细节信息的误判。因此,本文使用模型分别训练每个数据集生成测试结果,并对试验结果进行了定性和定量分析。
由表1中可以看出在内陆水数据集上,GKI、SFCM、CWNN和DDNet方法的假阳性值区域较大。从图2可以看出CWNN和DDnet的结果存在明显的斑点噪声,部分内河边缘被错误识别。对于内陆水数据集,ELM、PCANet和CapsNet方法不能识别右下角部分河流和内河湖的变化,因此存在较大的假阴性区域。由表1中看出,DBN和DDNet方法的OE相同,均为1.59%,差异仅为0.01%。但Kappa系数却相差2.96%,观察发现当FN越小时,KC越高。ELM方法具有较大的FN,尽管其整体精度较高,但其KC相对较低。SEENet方法的PCC为98.60%,Kappa系数为78.44%。

表1 内陆水数据集试验结果 (%)
对于农田D数据集,由表2中可以看出,GKI算法、SFCM算法、DBN算法、PCANet算法及CWNN算法的假阳性率均大于1%;由图2可以看出,CWNN方法的结果有着明显的散斑噪声,这导致了较高的FP。GKI、SFCM、ELM、DDNet、CapsNet和SEENet方法的FN均大于3%。前5种方法的高FN是由于对农田中部的细节识别较差造成的。在表2中阈值法的各评价指标中最差。本文所提出的SEENet的总体误差为3.93%,PCC为96.07%,Kappa系数为86.05%。
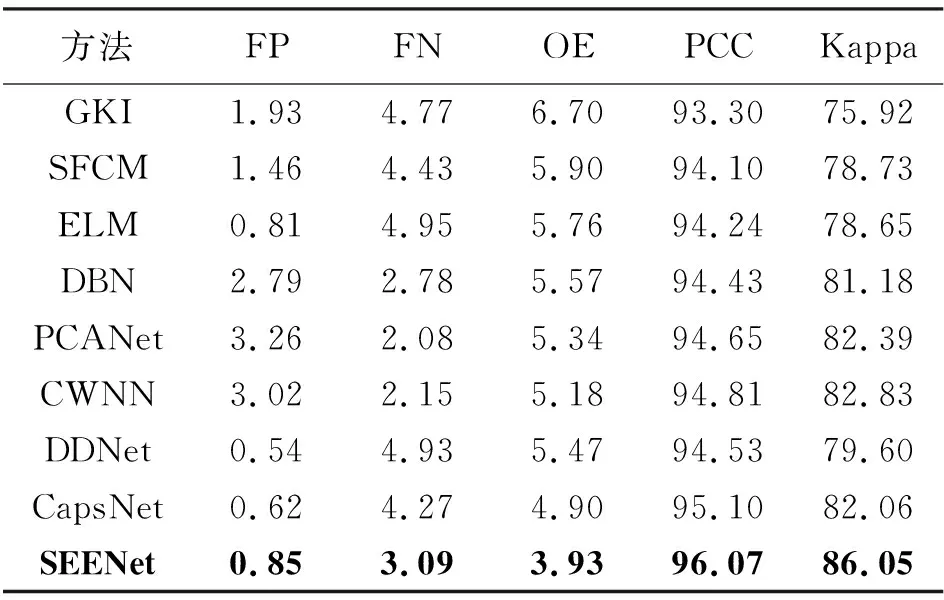
表2 农田D数据集试验结果 (%)
由于渥太华是一个噪声水平相对较低的数据集,因此许多方法都达到了较高的精度。由表3中可以看出,阈值法GKI的试验结果噪声区域较多,FP高达14.95%,总体精度和Kappa较低,分别为84.79%和58.53%。ELM方法错误地将顶部一些变化区域识别为不变区域,导致FN过高。虽然FP较低,只有0.01%,但Kappa系数略低于其他方法,为76.90%。其他方法的结果差异不大,得到的结果图中几乎没有散斑噪声。SEENet方法的Kappa系数和PCC略低于DDNet,分别为93.35%和98.22%。
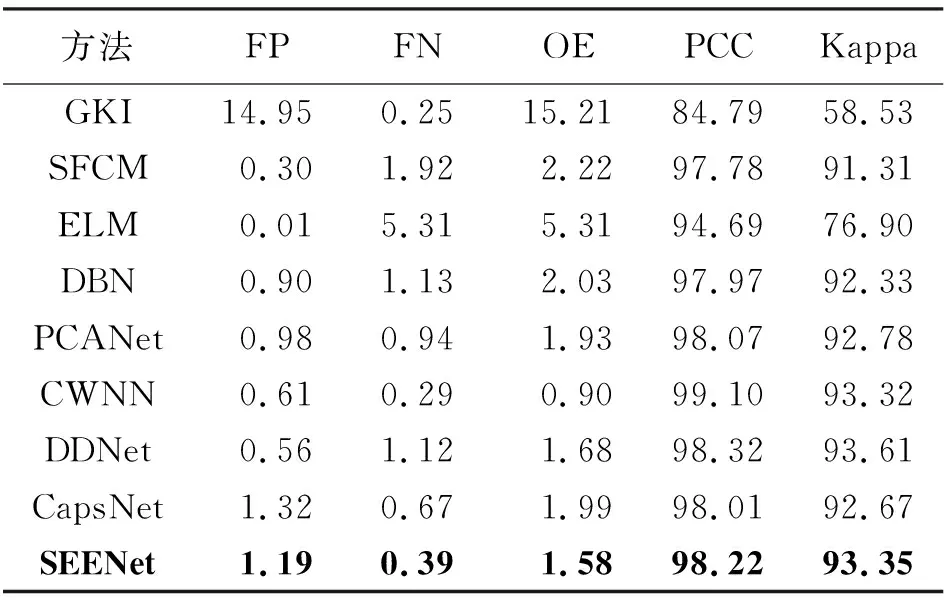
表3 渥太华数据集试验结果 (%)
由于旧金山数据集差异图的区别度较小,因此GKI方法在旧金山数据集上的性能非常差(见表4)。对比GKI结果图和真实标签值,可以发现其有大部分未变化区域被标识为变化区域。精度较低的GKI无法有效地指导DBN训练,导致GKI指导下的DBN方法在旧金山数据集上的识别精度极差。ELM算法具有较高的噪声敏感性,由图2可以看出,它的假阳性区域较大。CapsNet算法的结果图中虽然斑点噪声很少,但是变化主体的细节部分没有被有效识别,变化主体的右部被错误的连接,因此假阳性率也比较高。DDNet算法和SEENet算法的表现良好,噪声较小, Kappa系数较高,分别为91.83%和92.01%。

表4 旧金山数据集试验结果 (%)
本文方法在4个数据集上都表现出良好的性能。定性来看,所得到的变化检测结果边界清晰,噪声较小;定量来看,本文提出的方法在大多数指标上都有较好的表现,证明了该方法的有效性和稳健性。
2.3 因子分析
2.3.1 补丁大小
补丁大小决定了像素点邻域信息的多少,对试验结果有着重要影响。以黄河数据集为例,Kappa系数为试验的评价指标,进行补丁大小与Kappa系数的关系探究。如图3所示,随着补丁从小变大,Kappa系数表现出先增加后减少的趋势,当补丁大小为7时,Kappa系数最高。因此,选择7作为该试验的补丁大小。

图3 补丁大小对Kappa的影响
2.3.2 显著性中值滤波
为了验证显著性滤波的有效性,将本文方法与Kuan滤波器、Lee滤波器、中值滤波器和均值滤波器通过前述流程生成变化检测结果,并将结果进行对比。试验选用了噪声较大的农田D数据集作为验证数据集。试验结果如表5和图4所示,定性来看,显著性中值滤波器噪声较少,农田部分边界和细节清晰;定量来看,显著性滤波在5个指标上都取得了最好的结果,可以证明显著性中值滤波比其他空间域滤波在变化检测领域更具有优势。

表5 试验结果 (%)

图4 不同滤波器下的结果
3 结 论
本文提出了一种基于显著性中值滤波的SEENet以实现变化检测,该方法在去噪的同时保留了变化检测的细节。显著性中值滤波通过对图像背景信息进行分层去噪减小噪声的影响,与其他滤波器相比可以保留图像更详细的信息,更适用于高精度变化检测中细节的提取。多尺度融合网络SEENet利用3个SEE模块提取多尺度特征,并通过残差将深度特征与浅层特征连接起来,实现多尺度特征的多级利用。在4个不同噪声水平的数据集上的优异表现证明了该方法的稳健性。未来将致力于研究大型SAR影像的变化检测方法,由于大型数据集具有复杂多样的场景,因此这项工作更具挑战。
