数字平台算法决策歧视的认定与规制
2024-01-15牛彬彬
牛彬彬
(湖州师范学院沈家本法学院, 湖州 313000)
随着大数据技术与人工智能产业的发展,自动化决策系统引发的歧视与差别待遇问题也日益受到关注,弗吉尼亚·尤班克斯在其著作《自动不平等》一书中,揭示了AI 自动化决策系统的使用如何影响个人和社会。她通过走访与调查弗吉尼亚州因为自动化决策系统的使用而被影响的个体,说明自动化算法的使用可以导致更深层次的不平等以及社会分化与分层。由算法的歧视与偏见所引发的问题日益严重,学界也开始将算法歧视的应对治理作为研究对象。根据理论界的讨论,算法歧视的成因大致有如下几点:1)数据偏见;2)选样偏见;3)设计中产生的偏见;4)运行中产生的偏见[1]。学界也针对这些歧视成因纷纷给出因应之策,但这些规制建议也多立足于治理视角,形成“重规制轻认定”的研究格局。可见,算法歧视的事前防范固然重要,但同样不得忽视算法歧视认定理论,算法歧视的认定与归责也是算法歧视治理的关键环节,缺少责任认定机制,我们也无法评估算法治理的有效性。算法歧视认定规则需要更加细致的理论研究与规范认定。
一、问题缘起:平台的“算法重塑效应”对传统反歧视理论的拷问
算法歧视产生的根源在于算法运行所遵循的数理逻辑与多元社会价值评价体系之间的矛盾,算法去场景化的评价与决策机制,导致了算法的重塑效应。算法通过用户画像分析完成对用户的个体化评估,其包括收集数据、建立预测模型、应用模型评估用户几个步骤。然而,算法的评估可能不准确,因为在处理大量不同形式和来源的数据时,可能会丢失有意义的上下文信息,或者解析无关的信息,由此,用户从“物理世界”被映射入“数字世界”时,经历了一个“数据扁平化”的过程。在数据主体的身份越来越依赖于算法的量化表达时,算法对数据主体的评价也存在日益严重的失真风险。
算法不仅改变个体特征,也影响社会关系的形成。无论是监督学习还是无监督学习,算法通过对数据集群的划分来理解数据的意义。算法借助于量化、估值和分类社会关系,将数字集群划分为不同群体,加强了对社会群体的分类系统,或者发现新的数据群组。然后,算法根据其认知的内容,对不同群体进行评价,并重新分配数字资源。这就是算法重塑社会关系的核心——以数理逻辑评价为核心分配社会资源,歧视和差别待遇也由此产生。基于算法重塑效应所引起的算法决策歧视,也挑战了传统的歧视认定规范体系,体现在如下3 个方面。
1.如何认定算法歧视中的“故意”?
传统歧视理论认为,构成歧视的前提在于行为人主观故意,即针对存在受保护特征的群体存在歧视的故意,但算法作为技术工具,除非设计者故意设计变量,其决策过程很难为人所知晓。这种缺乏主观歧视故意的行为,能否构成传统反歧视理论中的“故意”则有待考证。可能有学者认为,应当注意对“反从属理论”的应用,因为反从属理论并不强调歧视认定中的“故意”。但即便如此,如何确定受保护群体与受保护特征仍然是一个有待解决的问题。
2.算法歧视中的受保护特征如何确定?
按照传统反歧视理论,歧视的认定要求被歧视对象具备受保护特征。算法由于片面地追求效率,经常会进行忽略伦理或者社会意义的关系分析,这导致被歧视对象超脱出传统意义上的受保护群体。算法决策在大多数情形下是通过用户画像影响人类行为的自动化过程,该过程更多地依赖人工智能来检测模式、建立相关性和预测数据主体的特征,并在此基础上实现“画像创建——画像分配——基于画像决策”的自动化决策过程。而算法对数据主体的这种概率式陈述有时则会模糊掉数据主体的真正的特征,将本不具有某种特征的用户错误地划拨到具有特定属性的群体之中,产生基于“特征剥夺”或“特征误判”所引致的歧视性结果。所谓“特征剥夺”是指由于用户画像颗粒度较低等原因,导致算法筛选器将本不属于某一群体的数据主体错误地划归到某一群体之中,进而导致算法对其做出不利的决策。例如,算法模型根据模型预测出该区域90%的人都会有迟延支付账单的习惯,银行基于此拒绝了该地区所有居民的贷款申请,包括那些10%的按时支付账单的人。10%的守约者因为其地域原因而被归类为“信用较差”的群组中,被忽视了其按时守约支付账单的特征。“特征误判”则是指算法运算依赖于受污染的数据集,或者是由于样本代表性缺失[2],导致对数据主体的特征推断错误。例如,某男性互联网用户由于经常浏览时尚杂志网站,而被算法基于“时尚杂志”与“女性群体”的高度关联推测为女性,这些都是算法重塑效应的体现。算法的映射与重塑功能给算法歧视的认定带来这些难题,冲击着传统的反歧视理论,学界也开始逐渐关注到算法歧视的认定问题。
3. 基于“特征剥夺”或者“特征误判”所引致的歧视性结果如何评价?
传统的反歧视理论中,无论采用“反歧视理论”还是“反从属理论”,一个共同的要求是,被歧视对象须具有受保护特征或与该受保护特征相关的其他特征。但由于算法对于个体用户以及社会关系的重塑与塑形效应,导致数字世界中的用户并非完全是物理世界中的映射。在重塑个体的过程中,以“深度学习”为特点的AI 智能是通过自行分组并关联的方式进行特征提取强化,进而产生对特定用户的“特征剥夺”与“特征误判”。因此现象导致的对特定用户的歧视,又应当如何认定?
二、理论争鸣:算法歧视认定理论的争议梳理
针对算法歧视的认定,学界的争议图景已经初步显现,大致包括如下3 种观点。
1.传统反歧视理论——主观状态难以认定
传统反歧视理论中,包括直接歧视和间接歧视两种类型,前者以“歧视故意”作为成立要件;后者则要求歧视是针对用户特定的受保护特征。但是在算法的重塑效应之下,歧视大多并非产生于平台使用方或者数据控制者,而是由于算法本身的运作机理所导致,由此造成算法歧视中主观要件的认定困难①。
为了解决算法歧视认定中的主观状态难题,有学者主张继续沿用传统的反歧视理论框架。张恩典[2]认为,算法歧视认定应当重视“间接歧视”,尤其是“反从属理论”的使用,因为其不需评估行为人的主观歧视故意。也有学者采用故意推定的方式,例如,在使用用户敏感信息造成歧视性结果时,应当推定数据处理者存在主观歧视故意[3]。但这样一来,很容易导致歧视认定的泛化。
显然,继续沿用传统的反歧视框架会面临诸多问题。有学者曾经在5 个方面详细阐述了这种挑战,其中有两个问题最为棘手:第一,受保护特征的有限列举同基于算法决策的歧视中歧视特征的不确定性;第二,基于特征预测错误导致的算法歧视,完全挣脱当前的反歧视规范框架,这一问题应当如何解决。出于这些问题的考量,该学者认为,采用当前反歧视理论框架来认定与规制算法歧视是“有必要但不充分的(necessary but not sufficient)”[4]。其一方面肯定传统反歧视规范框架在认定算法歧视时的作用,另一方面也反映了当前反歧视理论框架进行补充或修正的必要性。
2.反歧视规范框架的修构——“关联性歧视”概念的提出
为了解决传统反歧视框架下受保护特征不确定造成的规范适用难题,有学者提出了“关联性歧视”(discrimination by association)这一概念。其包括直接的关联性歧视和间接的关联性歧视。此种歧视形式并非直接基于数据主体的敏感信息,而是基于同其相关主体(例如家庭成员等)所产生的、针对数据主体的歧视。此种歧视也被称为直接的关联性歧视,由S. Colemanv.Attridge Law and Steve Law 一案所确立。根据该案判决,对直接歧视的保护不仅适用于具有有关受保护特征的人,也适用于因与受保护群体“联系”而遭受歧视的人②。间接的关联性歧视,是对间接歧视概念的目的性扩张。所谓间接歧视,是指某项规定、标准或做法看似中立和平等,实际上却将某人或某类人置于极其不利的地位。而间接的关联性歧视,则是指主体基于某种看似中立的关联性的特征或者推测兴趣而致使自己处于一种不利状态。间接的关联性歧视是CHEZ Razpredelenie Bulgaria ADv.Komisia za zashtita ot diskriminatsia 之后确立的③。间接的关联性歧视不同于直接的关联性歧视,其允许个人提出某人针对自己假设的特征所产生的歧视,也即被歧视对象实际上并不具有某种受保护的特征或者属性,仅仅被推测可能具有某种特征,而被错误归入到某种分类中,而导致不利影响或者差别待遇。
关联性歧视的概念在很大程度上契合“算法重塑效应”技术背景下对歧视性算法决策的认定。目前大多数公司都不会直接使用受保护特征进行决策,而更多地使用不涉及受保护特征的假设性的特征或信息进行决策,这就涉及间接的关联性歧视,这也是基于自动化算法产生歧视的主要方式。例如,时尚杂志的订购者与阅读者大概率与“女性”这一性别特征联系起来。关联性歧视回应了因算法对数字主体的扁平化概率式陈述所导致的“特征剥夺”和“特征误判”所引起的歧视。引入关联性歧视这一概念的优势在于,它允许关联个人基于其假定特征提出反歧视主张,而不仅仅是基于受保护特征[5]。但也存在一些有待解决的问题:第一,可操作性存疑,数据主体如何知晓自己因被错误归类而导致歧视;第二,将关联性歧视引入算法歧视的认定方案中,算法歧视认定的泛化风险仍然存在,即任何受到算法不利评价的人,都可认为自己被错误归类而受到不利差别评价。如若在后续的理论应用中能够解决上述难题,“关联性歧视”这一概念应用也不失为一个解决问题的工具。
3. 冲破传统框架的理论革新——基于“博弈锁定”的歧视认定
为了解决“算法歧视泛化”问题,有学者尝试突破传统的反歧视理论框架解决算法歧视的认定问题。例如,有学者认为在算法应用中,尤其在私法关系中,构成算法歧视的前提在于用户对平台之间存在算法博弈锁定的行为,这种博弈锁定包括博弈退出锁定、博弈规则锁定和博弈结果锁定。结合反垄断法相关理论,综合平台市场地位以及用户可替代性选择的空间等因素指标,评估平台算法对用户的支配程度认定“博弈锁定”要件,并旨在打破平台对用户的横向博弈封锁,避免平台的不利决策[6]。其理论具有一定的创新性,尤其对电商场景中的价格歧视认定具有启发意义,但仍存在局限:一方面,该文将算法歧视的讨论范畴局限于私法场景,尤其是大型平台之中,探讨范围相对局限;另外,算法究竟在具备何种程度“可博弈性”时才会被认定为非歧视,也是这一理论未能说明之处,因为用户每一次在平台上浏览、点击的行为,都会不成比例地增强数字平台的力量,用户个人很难实现与大型数字平台的博弈自由[7];最后,其也未能解决因“特征剥夺”或者“特征误判”所导致的歧视认定问题。
除此之外,也有观点认为私法层面的算法歧视并非仅仅是从反垄断的角度进行认定,例如,有学者认为价格歧视本身并不构成违法性歧视,但是当平台将其歧视与某些不当影响的行为(例如助推或影响消费者的不当感知等)结合在一起时,才可能会构成违法歧视[8]。
上述理论研究为我们探索算法歧视的认定方法提供了一定的参考(见表1)。算法的重塑效应是引发算法歧视的重要原因,因此构成算法歧视的一个重要前提在于,算法对用户产生了一种实质上的支配和控制关系,这是认定算法歧视的前提性要件;其次,关联性歧视概念的提出,能够在一定程度上解决算法重塑效应所带来的受保护特征与受保护群体不确定的难题;最后,再结合传统反歧视理论中的受保护特征、差别待遇、不利影响等因素,梳理出算法歧视认定大致框架。
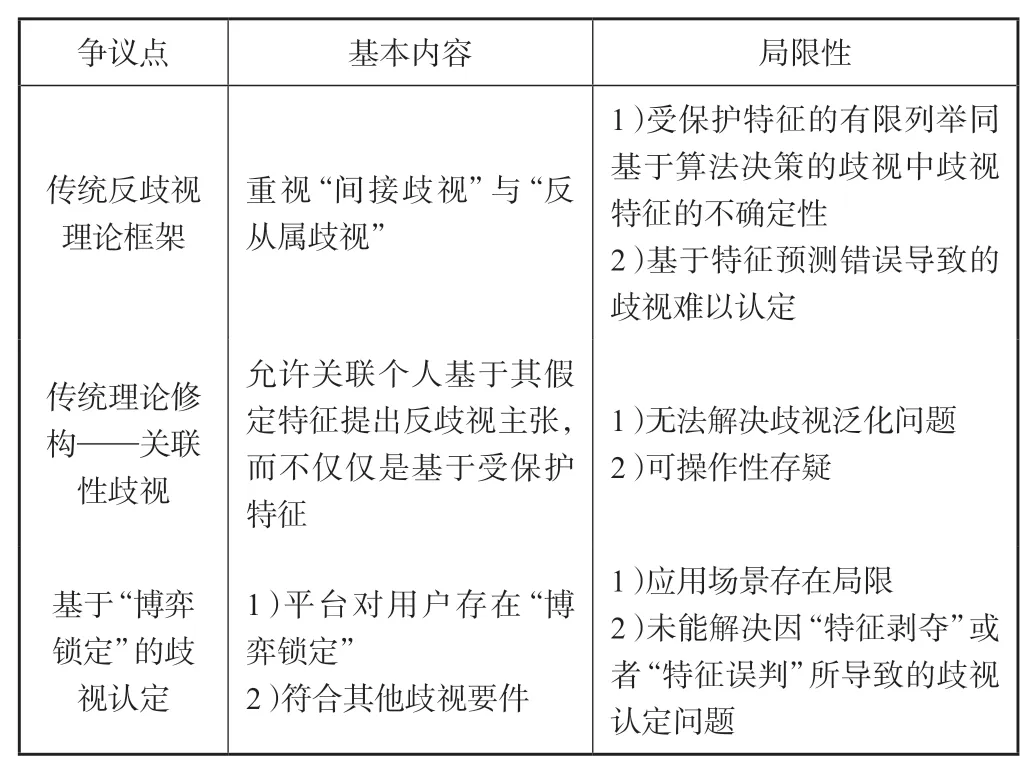
表1 算法歧视认定的观点梳理
三、规范认定:算法歧视的一般构成要件
传统反歧视理论之所以将“故意”视为前提性要件,其目的在于防止“歧视泛化”。但是在算法歧视应用中,由于决策是基于算法运算程序做出,算法设计者故意设计歧视变量的情形少之又少,更多的则是由于“数据偏见”或者“选样偏见”所导致的歧视,若坚持将“故意”作为算法歧视的主观要件,则诸多算法歧视行为将难以规制。因此,算法歧视的认定应当摒弃“故意”要件。但并非算法所有的负面评价都需要纳入“歧视”的范畴之中,在摒弃“故意”要件的同时,也需要新的限定性要素以防止歧视泛化。正如上文所述,算法歧视产生的原因在于算法的重塑效应,在摒弃主观要件后,为了防止算法歧视在司法实践中被“泛化”,一方面需要框定受保护场景,即在哪些应用场景中,基于算法的“偏见”或者“差别待遇”可能会引发歧视问题;另一方面,需要以平台对用户存在相当程度的支配或控制为前提。
1.前提要件——取代“故意”的算法支配关系
(1)受保护应用场景。算法并非在所有应用场景中都会产生重塑效应,因此,受保护场景的框定是认定算法歧视的前提。就目前来看,算法评价中的受保护场景应当具备以下几个要素。
第一,从算法对个体的重塑效应看,要求算法对个体的描述或重塑对数据主体的权利义务有实质性影响。而这也对认定算法歧视的应用场景提出要求,即数据主体处于受保护的应用场景之下。例如,数据主体在申请商业信贷时,受到评价较低的用户,可能妨碍他人缔约自由;或者数据主体受到算法负面评价导致监禁期延长等。
第二,从算法对社会关系的塑形效应看,受保护的应用场景涉及算法对社会资源的分配。人们对特定社会资源的主张或者诉求是社会关系产生的前提和基础,其嵌入各种社会关系中,成为人们进行社会交往的纽带。算法的社会关系重塑效应所影响的是社会资源的分配方式和分配路径,其并非系指资源的均等分配,而是社会成员之间获得社会资源的机会均等。例如,在利用算法进行福利资源分配的场景中,应当公平分配社会福利资源,不得因为种族、民族不同而在资源分配问题上有所不同;在就业类应用平台中,男性与女性应当具有相同的机会准入条件,算法应当向不同性别群体均推送工作信息。具体而言,社会资源的分配公平在于两个方面,第一,资源的平等分配,这主要体现于公法场景中,例如社会福利资源、教育资源的分配等;第二,机会的均等获得,这主要体现于市场环境下个体的市场准入公平、信息资源的获取机会以及就业机会均等等方面。机会均等也是罗尔斯正义理论的核心内容。
总之,在算法歧视的认定中,应当尤其注意下列应用场景:就业、社会福利分配、接受商品或者服务、信用评估、健康医疗、教育、行政与司法等可能对数据主体的权利义务有实质性影响的应用场景。当然,受保护的应用场景并非可以被穷尽列举,需要在司法实践具体个案中,结合上述两个条件进行具体认定与裁断。
(2)受保护场景中的算法支配。用户被平台操纵和支配是认定算法歧视成立的另一重要因素,因为只有平台与用户之间存在算法支配关系,算法决策才有可能对用户权利产生实质性影响,算法塑形效应才可能显现。在算法支配关系下,算法对数据主体的支配主要体现为“控制”和“影响”两种形式。
1)算法控制。所谓“控制”,即算法决策过程排斥人的干涉与被决策博弈,径行做出决策的过程。例如,行政机关利用自动化算法对行政相对人做出行政决定;银行金融机构利用信贷算法决定是否同意申请人的贷款申请以及贷款额度。这种单向的、固定式的算法决策过程,即算法控制。
2)算法影响。在某些应用场景中,算法虽然并未直接对用户作出相应的决策,但平台可能会通过潜在的、不易令人察觉的支配形式干扰用户决策进程,进而实现算法对用户的操控目的,有学者将其称为“助推”的方式[9]。当助推策略与数字化技术结合,助推行为的诱导力和影响力将会进一步增强,因此也有学者称其为“数字助推”。由此网络服务提供商可以诱导互联网用户做出更加符合商家利益的行为决策。例如,数据处理通过分析用户的行为倾向、习惯偏好向用户推送定向广告,影响用户消费习惯,甚至在某些情形下直接影响数据主体的行为。定向推广、利用自动化系统进行的差异化定价,这些依托于自动化算法决策系统给数据主体带来负面影响的报道经常见诸报端,它以十分隐蔽的形式差别化地操纵人们的行为,压缩数据主体意思自治的空间[10],间接操纵数据主体的行为。
2.核心要件——基于受保护特征的差别待遇
(1)受保护特征。1)存废之争。算法歧视中的受保护特征认定,一直以来是一个困扰学界的难题。为了防止算法歧视认定的泛化,欧盟一直将受保护特征限制于特定的特征范畴之中。学者Malleson[11]认为,受保护特征必须满足以下条件:某种定义和分类稳定性,它们必须广泛反映人们对社会现实和生活经历的理解,它们必须与社会中最重要的歧视轴心保持一致。2010年,英国《平等法》将其国内各种反歧视相关规范合并,扩张了其受保护特征的范围④,但同时指出,由于人类身份与生活经验日益变得复杂与多样,未来在确定受保护特征时,可能需要采取基于场景(context-based)的方法[12]。当然,也有学者认为,算法歧视的区分事由具有复杂性、动态性和伪中立性,如若坚持受保护特征这一要素将会导致大量算法歧视行为超脱规制范畴,因此在算法歧视的认定中,应当舍弃受保护特征这一要件,尤其是在私法关系中更应当如此。
在笔者看来,受保护特征在算法歧视的认定中仍然十分必要。歧视作为具备违法性的差别待遇,总是以具有某种特征的个体或者群体为参照系,舍弃受保护特征也就意味着没有可供参照的对象,又何以体现出差别待遇?但是,受保护特征的确定需要将其限制于合理范畴之内。在这一点上,Malleson 教授的观点具有一定启发意义,在其看来,受保护特征需与社会中最重要的歧视特征轴心保持一致。
2)如何确定受保护特征?算法歧视产生的根本原因在于依循自身逻辑的概率式陈述与数理式塑形,歧视性后果的产生有时是基于用户自身真实的受保护特征,有时是基于算法的错误假设,甚至是在塑形新的社会关系过程中,可能产生的新型歧视诱因。因此,笔者将算法歧视中受保护特征的认定分为3 种基本类型:基于映射的核心特征复现、基于关联的核心特征辐射和基于应用场景的新型受保护特征。
第一,基于映射的核心特征复现。需要明确受保护特征需要严格依照我国目前的规范规定。我国并没有制定统一的反歧视法律,相关的反歧视规范皆散见于各种规范性文件之中。目前我国立法明确禁止的歧视事由包括7 类,即种族、民族、宗教信仰、性别、残疾、传染病携带源、社会出身。这些特征可以用来检测是否存在针对某类群体的歧视。如若判断某项算法决策中是否存在性别歧视,无论算法的决策过程如何,我们只需要以性别为标准,判断特定算法决策中,不同性别的人群获得算法正面/负面评价的比例即可,如若获得算法正面肯定评价的人中男性与女性的比例为4:1,则该算法有可能涉嫌对女性的歧视。
第二,基于关联的核心特征辐射。面对算法重塑效应带来的受保护特征不确定的难题,关联性歧视或许是解决这一问题的重要方法。即便用户实际上并不具有某种受保护特征,但是由于算法重塑效应导致对用户的特征误判,也可能会导致对用户的歧视,此即由于算法特征剥夺或者特征误判所导致的歧视。当歧视是由于某一受保护特征的关联特征所引起的,用户也可以核心特征辐射的关联特征作为其受保护特征,宣称其可能被算法误判为此类群体而受到不利的差别待遇。至于此类歧视面临的可操作性难题,本文将在第四部分举证责任小节加以详述。
第三,基于应用场景的新型受保护特征。歧视是由人们对某一群体的刻板印象和态度所引起,但是算法偏见,尤其是算法所引起的新型偏见,大多是由于算法(特别是深度学习算法)对目标效率价值的片面追求,以及监督制约机制的匮乏而导致的算法反身与自我强化效应。这种内嵌于算法逻辑之中的、对目标效率的单向度追求,可能会导致算法对特定群体的系统性歧视对待:一方面,算法可能对不符合算法效率价值导向的群体通过给予负面价值评价加以排斥;另一方面,算法也可能对契合其效率价值的个体或者群体进行过度压榨。因此,在确定新型应用场景中的受保护特征时,可以尝试以算法效率为基准确定相关变量标签。以“大数据杀熟”为例,消费者支付意愿的确定是与算法运行效率直接相关的因素,数字平台对消费者购买意愿的判断决定了平台对消费者所实施的定价策略,这也直接影响到后续缔约内容、权利义务安排。因此,可将支付意愿作为受保护特征之一,但也并非针对高支付意愿的用户进行高定价就意味着算法价格歧视成立,其仍然需要判断“算法支配”的有无与强弱。这种强“支配力”的认定,从行为方面需要判断是否允许用户修改删除不适当的用户标签,以对抗算法决策循环。另一方面需要判断算法推送策略是否破坏了高消费群体的理性决策能力,例如,若算法对高消费群体产生强支配力,即大部分高支付意愿群体最后都承诺支付了高价(如80%以上),或定价超过必要限度,则可能涉嫌对高消费群体的价格歧视。
(2)差别待遇。认定“差别待遇”需要一定参照。在理论上,根据参照对象的不同,可以将差别待遇分为历时性的差别待遇和共时性的差别待遇。有学者认为,所谓历时性的差别待遇,即如果以用户自身过去经历作为对照,证明其因某项事由发生变化或被揭露,而相比之前遭受不利差别对待,可以认定将其作为差别对待的依据。但需要指出的是,在进行历时性差别待遇的比对时,其所参照的仍然是其他同类群体,其在本质上仍然属于横向比对的范畴。基于算法的歧视所造成的差别待遇包括个体意义上的差别待遇以及群体意义上的差别待遇。第一,个体意义上的差别待遇,即违背了“相同情况、相同处理”的形式正义原则。例如在人工智能裁判的场景下,在两个被告人的行为能力、所触犯的罪名、罪行严重程度等条件皆相同的情况下,算法作出了不同的裁决。此时便违反了以“相同情况、相同处理”为原则的形式公平。例如在Johnsonv. Allstate Ins. Co.一案中,原告诉称该保险公司对类似客户使用不同的保险评分算法,由此引发了原告针对被告保险公司的诉讼,此案中保险公司亦违反了形式公平原则⑤。
第二,群体意义上的差别待遇。此处的不同群体,应按照数据主体在特定场景下的受保护特征加以确定。例如,算法评价结果在不同性别之间存在结构性失衡,导致对某一性别人群的评价占总人群的比例畸高或者畸低,且此种“不合比例性”没有符合伦理的理由加以正当化。比如,在银行利用信贷算法对贷款申请人进行评估决策后,女性获得贷款审批的概率如果远远低于男性,则该算法可能涉嫌对女性的歧视。但是这种差别待遇必须达到一定的程度,在这一方面,各国似乎并没有一个规范标准,欧洲的判例法曾经在西班牙一个关于兼职歧视的判例中作出如下决定:如果80%受到影响的群体是女性,则不利行动可能会构成歧视[12]。此即统计显著性检验,作此种统计性检验的优点在于,确保差别性影响并非因偶然因素所导致[13]。由此,群体差别待遇的差别化影响需要达到相当程度,即影响到不同群体之间就某种事项的平等的机会概率,才可以被认定为违法,否则难以认定其存在歧视。
3.结果要件——类型化视角下的“不利影响”认定
算法对用户的不利影响是算法歧视认定的结果要件。有学者认为,不利影响包括不利后果以及社会排斥风险,也即,不利影响不仅包括当前的不利决策,而且也包括远期影响。某些类型的算法歧视其不利影响表现得较为隐蔽,或者表现为算法决策循环中由于衍生数据的偏差所导致的歧视风险,亦或者表现为对于特殊群体的决策误差偏高,这些“不利”类型虽然并未直接表现为决策的不利,但却可能使得用户陷入某种负面决策逻辑循环中,最终对用户造成损害。因此,算法歧视中的不利,需要满足两个条件,即决策性不利和归因性不利;其中决策性不利可以分为两种类型,单纯的决策不利和错判率不利,归因性不利需满足两个条件,即与受保护特征至少有关联且存在针对相似群体的歧视待遇可能。
(1)决策性不利。从类型上看,决策性不利又包括两种类型,即单纯的决策不利和错判率不利。前者系指相关群体受到算法的不利评价,后者系指算法评价结果在群体之间造成的误差比率高低。
1)单纯决策不利。这种决策性不利的判断是基于差别待遇。差别待遇是构成决策性不利的前提之一。单纯的决策性不利即指数据主体在特征场景下,相对于其他群体而言,在特定的受保护场景下受到算法的负面评价,以及由此引致的不利待遇。这种不利,既包括个体意义上的不利,也包括群体意义上的不利,前者系指不同主体在同等条件下未能获得算法的公正评价,后者则指概率层面的不利,如若算法评价结果在受保护群体之间产生结构性失衡。例如,基于性别这一受保护特征,算法向女性推送高薪职位的比重与男性相比过低,该算法可能涉嫌对女性的歧视。
2)错判率不利。平台算法如若针对某类群体的错判率畸高,这种误差本身也可能会构成歧视。错判率不利是群体意义上的,即平台算法对于两个不同的、相互参照的群体的判断准确率不同,如对其中一类群体的判断准确率过低,则有可能涉嫌对这一群体错判率不利。
错判率作为一种不利影响的类型存在于美国地方司法体系中,COMPAS 是一款被广泛应用于预测被告再犯风险概率的评估软件。基于一系列复杂的历史数据,包括年龄、性别和已有的犯罪记录,COMPAS 预测案件行为人被再次逮捕的概率,并计算得出危险分(risk score)供法官参考,分数越高,其被再次逮捕的概率就越高,人身危险性和社会危害性也就越大。但是,COMPAS 计算结论的公平性很快受到质疑,Pro-Publica(美国的一家为公众利益进行调查报道的非盈利新闻编辑部)审查了COMPAS 分类的公平性,通过对释放出狱罪犯的实际再犯情况同预测结果的比对,判断其是否存在种族歧视的可能。ProPublica 利用公开数据,分析了佛罗里达州布劳沃德县(Broward County)1.8 万人的COMPAS 分数和犯罪记录,得出了一个惊人的发现:尽管COMPAS 的正确预测率达到了61%,但在它的系统里,黑人与白人的分数分布却明显不同。黑人更有可能被误判,即虽然目标个体被预测具有再犯的高风险,但实际上却没有再犯;白人则更有可能被漏判,即被预测为低风险,但实际上却再次犯罪。不同种族间的假阳性(false positive) 和假阴性 (false negative) 率的差距可以高达近80%。COMPAS 算法更加倾向于认为黑人具有更高的再犯风险,但事实却并非如此,显然,算法对黑人存在歧视。自从COMPAS 一案引发争议以来,错判率问题也日益受到人们的关注,例如,算法经常会将诚实纳税的公民预判为可能会偷税漏税的不法者,也可能将一个信用良好的申请人评价为可能会迟延还款的人。错判率的公平性目前也多被用于检测人脸识别算法的公平性,如果某人脸识别算法在识别某一种族人口时错误率畸高,则可能涉嫌对该种族人口的歧视[14]。
(2)归因性不利。单纯的决策性不利并不能直接认定为存在歧视,决策性不利需归因于特定的受保护特征,归因性不利是构成算法歧视中“不利”的另一个必要条件。所谓“归因性不利”是指,平台算法将数据主体与某种可能招致负面评价的目标变量联系起来的行为。此种不利是因为算法错误地将自己归类为在算法评价中存在不利因素的一方,算法评价参数所代表的即是一种令人不快的或者有辱人格的变量因素。但需要注意的是,认定成立归因性不利的前提,是数据主体能够知晓算法对其进行分组的变量带有明显的消极色彩,甚至未来可能成为算法对其作出不利决策的重要原因。归因性不利既包括直接将种族、肤色、性别等受保护特征作为区别待遇考量因素的显性歧视,也包括将与受保护的特征高度关联的代理变量作为决策考量因素的隐性歧视。归因性不利需要满足如下两个条件。
1)归因性不利之“因”至少与受保护特征存在合理关联。导致决策性不利的原因不仅仅只有“归因性不利”中的带有消极的、易受歧视的特征性因素中的“因”,相反,导致算法对数据主体决策性不利的,可能就是一个没有任何意义的位置信息或者时间信息。但无论算法歧视中的“归因”为何,其皆能与特定场景下的受保护特征存在合理关联,属于受保护特征合理辐射的范畴。
2)归因性不利有存在群体不利的可能。不能仅仅以数据主体存在受保护特征且受到差别待遇为由,认定算法存在歧视的嫌疑,其仍然需要达到针对群体歧视的可能。如果仅仅是受保护群体中的个体遭受差别待遇,则可能是由于算法运行错误所致,而很难被认定为是算法歧视的结果。例如,在Newmanv. Google LLC.一案中,原告认为,被告的过滤和审查工具分析了原告的种族身份,平台剖析、使用和考量原告的种族、个人身份和观点,以干扰、限制或阻止其视频上传平台或在平台内的传播,因此导致其无法充分行使其在平台内的各种权利和自由⑥。在本案中,原告确实拥有受保护的种族身份,但是不能以此直接将决策性不利归因于其种族身份特征,如若与其具有相同身份特征的大部分群体并未遭受如此待遇,则难以将不利结果归因于这种受保护特征。本案原告的主张最终也未能得到支持。
(3)由不利地位引致的影响——数据主体的机会损失。如若数据主体在算法评价中仅处于不利地位也不宜直接认定成立歧视,还需上述行为的确对数据主体造成损害。这在美国某些判例中也体现的极为明显⑦。但是如何界定算法歧视案件中的损害,目前理论和司法实践中仍然存在争议。美国判例法对如何确定基于算法的平台歧视损害积累了一定的经验,在很多情形下,原告所声称遭受的损害大多是物质性的。在 Spokeo, Inc.v. Robins 一案中,法院要求损害必须为:1)实际上受到的伤害,2)可以追溯到被告的质疑行为,3)有可能通过有利的司法裁决来解决的伤害⑧。在 Bradleyv. T-Mobile US, Inc.一案中⑨,法院则要求原告证明这一事实,即原告需要从一般社会意义上说明,其对被告涉嫌就业歧视的特定工作感兴趣。
由于算法歧视所招致的损害后果,主要包括两种类型,一种是直接的名誉利益或者人格尊严利益的侵害;另一种则是由于算法歧视所招致的机会损失,后者是最为主要的损害类型。对于前者,数据主体需要证明算法推送内容已经对其达到名誉侵害的程度,而且已经造成数据主体的社会评价降低;后者需要证明其符合获得该机会的初步资格,由于算法歧视导致机会丧失。规范意义上的“机会”是指,获得利益和避免损害的可能性[15]。例如,算法在经过分析之后发现,女性更加倾向于选择薪水较低的职位,由此系统在向女性求职者推荐职位时,自动过滤掉薪水较高的职位,而向其大规模推送低薪岗位[5]。此种分配极大限制了特定人群的可选择空间,导致数据主体获得某种待遇的机会概率被迫降低,加剧社会成员不平等的现状,激化社会矛盾。在被广泛讨论的“意大利户户送算法歧视案(Tribunale di Bologna,sez.Lavoro.)”中,由于算法不考虑骑手不赴约的真实原因,使骑手荣誉排名降低,进而导致其优先选择工作的机会丧失[16]。同样,在算法价格歧视中,高支付意愿的群体也由于畸高定价丧失获得公平定价的机会。当然,这些损失需要以算法支配关系成立为前提。
综上所述,算法歧视的构成,实际是在算法针对受保护群体的强支配力的前提下,由对受保护群体的负面评价所引致的不利,进而导致数据主体在受保护场景下的机会损失。
4.阻却要件——符合比例原则的差别待遇
如果上述要件全部符合,也不可一概认定为是违法性歧视。因此,衡量算法决策的合理性仍需要结合比例原则,判断算法的差别待遇是否适当。比例原则一般包括适当性原则、必要性原则和均衡性原则。
首先,需要考察算法造成差别化不利影响的适当性。所谓适当性是指所采取的手段必须适合于目的的达成,如果选择的手段与目的无关,即违反了适当性的要求。正如上文所述,造成算法歧视的根源性因素之一,在于算法对效率价值的追求,其表现为对所设目标的最优化实现,而这一过程通常缺失公平要素的考量。但是,如果不利影响的差别待遇在特定的应用场景下,系为达到特定目标所必需,其便具有适当性。例如,雇佣就业场景下,经过算法对求职者简历的筛选程序,女性入选面试的比例要远远高于男性,可能会涉嫌对男性的歧视,但如果是特殊的就业岗位,比如为女性宿舍工作人员、女性监狱工作人员、医院护士等,女性会不可避免地在获取面试资格以及录取比例上较男性更加占据优势,这是为现实的场景要求所必需,另外包括为了实现合同目的或者公共利益所必需。也就是说,某种不利后果的差别待遇虽然在外观上可能涉嫌对特定数据主体或者群体的歧视,但是如果能够证明其结果具有一定程度的适当性,则可以证成其合理性,进而阻却算法歧视侵权。
其次,需要考察不利差别待遇的必要性。即在所有的能够实现目的的手段中,应当选择对权利主体损害最小的手段。例如,为了在献血过程中防止艾滋病的传播,如果使用大数据对潜在的献血者进行分析推测,并在此基础上推断出性生活混乱群体、男同性恋群体等可能感染艾滋病的高风险人群,并将其排斥在血液捐献群体之外。那么使用用户画像的形式确定献血群体不仅可能导致歧视(例如将数据主体纳入到性活跃群体、男同性恋群体中皆属于归因性不利,可能直接造成对特定群体的歧视),而且某些数据主体可能因算法错误分类导致不利待遇。所以,如欲防止献血活动中艾滋病的传播,只需要做好事前的血液安全检测以及严格落实抽血活动的操作规范即可实现目的,使用算法分析预测的功能筛选适格主体实无必要。一旦数据主体被动地介入到数据分析与用户画像,则有可能导致算法对数据主体失真性重塑。
最后,还需要按照狭义的比例原则,考察不利差别待遇的均衡性。基于算法的数字歧视所造成的损害结果需小于其所获得的收益。例如在COMPAS 案件中,虽然预测再犯风险的模型准确率高达61%,但是黑人误判率与白人误判率的差别已经相差近80%[17],由此可见,这种高准确率的获得是以对黑人的歧视风险为代价的,其并不符合均衡性原则,因此COMPAS 所使用的算法(系用于预测被归类为高风险的白人或黑人被告是否会再次犯罪的算法),可能涉嫌对黑人群体的歧视。再者,在信贷类算法中,低收入人群似乎容易得到算法不予放贷的决定,此一决策虽似乎存在对低收入人群的差别化待遇甚至歧视,但是此种评估方式在实际上也将低收入人群的利益考量在内:如若批准此类人员的贷款,则有很大概率该主体难以偿还贷款,从而造成更大的信用风险,进而导致此类低收入人群在未来难以从金融机构获得任何贷款。根据狭义的比例原则,虽然该类算法可能涉嫌对低收入人群的差别化待遇,但是从长远来看,其仍然有利于低收入人群,故而符合均衡性原则,不构成对低收入人群的歧视。
总之,比例原则在算法歧视认定中的主要制度功能,在于确保算法决策结果的可预期与可解释。如若一项貌似歧视的决策算法,其决策结果是在可预期范围之内的,则可以阻却歧视的认定。
四、制度接榫:规范条文法理阐释与制度配套
1.请求权规范基础的完善——细化“自动化决策公平、公正”的规范内涵
《个人信息保护法》第24 条中对自动化算法决策应用提出相当具体的要求,可以作为反算法歧视重要的规范基础,也是未来数据主体针对歧视性算法决策提起诉请的请求权基础,但是该规范基础中,最为关键的,仍然是对决策“公平、公正”的界定问题。
“算法公平”的概念有广义和狭义之分。法国数据保护局[18]、英国信息专员办公室(ICO)[19]、以及欧盟《一般数据保护条例》(GDPR)序言第71 条对于算法公平的观点——考量结果对个人的影响,防止错误、不准确和歧视性的结果,这一观点注重结果层面的公平与公正,即狭义的算法决策公平;而广义的算法公平,则源自挪威奥斯陆大学法学教授拜格雷夫的观点,其指涉整个信息处理系统的可信与透明,其更像是一种价值理念,所评价的对象是作为整体的数据处理系统,旨在减少信息处理过程中的不对称与不透明。由此可见,狭义的“算法决策公平”概念内含于广义的“算法公平”之内,着眼于算法决策本身。而“算法公平”的概念内涵中应天然包含算法决策的公平合理的规范内涵[20],两者相互区别,又存在紧密联系。《个人信息保护法》第24 条中所指涉的自动化决策的“公平、公正”所强调的,是算法运算结果的公平性,故而是一种狭义上的算法公平。
这也是数字平台承担保障决策公平性的注意义务。“算法决策公平”主要有两个层面内涵:其一,个体公平,即同等情况同等对待;其二,群体公平,即平台算法对于用户的评价需要在群体之间保持均衡,除非存在正当事由。经过笔者的整理,群体公平大致有以下几种检测手段:1)有意识的公平(fairness through awareness)[20];2)无意识的公平(fairness through unawareness)⑩;3)解耦⑪;4)统计均等[19];5)机会均等⑫;6)误差率均衡⑬。这几种提高算法公平性的手段,皆有与其最相匹配的应用场景,例如,针对群体中极其少数的群体可使用解耦技术;教育提倡教育对象多样性,可采用统计均等技术实现公平;在商业贷款中,可采用机会均等的技术手段。另外,可采用多重技术手段实现目标,以保障算法结果的公平性,并要求数据处理者说明为确保算法公平所采用的技术方案及其合理性。
2.权利类型丰富与内涵延展——归因性不利下衍生信息的知情与修改权
算法歧视产生的一个重要原因在于算法对个体画像进行概率式陈述时产生分析错误或者不当。《个人信息保护法》第24 条虽然赋予数据主体以自动化决策的拒绝权,但该权利仅仅是提供给数据主体在结果层面的、针对个体而言的、阻却不合理算法决策影响的权利,难以应对算法分析式决策所引起的连锁性效应[21]。出现了针对个体的概率式陈述的错误,则应当配合个人信息更正权,将个人信息的更正权扩展到分析的个人数据,从而为数据主体提供更加有效的权利救济途径。
为防止归因性不利中不断往复的决策循环可能使用户陷入决策式负面螺旋之中,数据处理者应当在某些决策场景中,向用户揭示某些归因标签,即明显带有负面、否定评价的标签类型。一方面,此类标签信息可能是算法做出对用户不利评价的直接、关键依据,对于此类标签的揭示,在一定程度上满足了决策过程透明的要求;另一方面,此类标签的说明,也有利于及时发现某些因特征剥夺或者误判引起归因错误而导致的算法不利决策,用户也可基于此及时行使信息更正的权利。
具体到个人信息更正权的内容,可以从两方面对更正权内容加以概括。首先,对于数据主体而言,如果算法应用针对数据主体的歧视是由于特征提取错误(特征误判、特征剥夺等),数据主体可以在提供相应初步证据的基础上,提出修改其衍生数据信息的申请,其表现为用户标签的修改与删除。第二,如若用户的原始信息存在错误,可能导致后续决策出现偏差或失误的,用户也可申请修改其原始数据,此即更正权条款的目的性扩张。
3.算法歧视侵权的诉讼救济——制度建构和举证责任的分配与承担
(1)诉讼制度的建构。为了保障算法歧视的有效规制,算法歧视的诉讼救济制度建构也是必要的。一方面,诉讼案由中需要明确算法歧视侵权,当发生基于群体的算法决策系统性歧视等大规模侵害事件时,可以考虑由代表机构代替个人行使救济权利。欧盟已经建立起算法歧视侵权的群体救济制度机制。在欧盟《一般数据保护条例》第80 条中,明确了数据主体有权委托第三方机构提出申诉、行使司法救济权,以及获得赔偿[22]。在美国第一例依据《加州消费者隐私法案》提起的诉讼案件,即为因数据泄露所引起的Barnes 向美国童装店Hanna Anderson 和Salesforce 电子商务平台提起的集体诉讼,该案最终以调解方式结案,Hanna Anderson 同意支付给20 273 名成员共40万元的赔偿金,并采取其他补救措施[23]。根据报道,由于脸书(Facebook)在招聘时优先雇佣持有H1-B 美国工作签证的工作人员,没有给予美国公民在雇佣过程中以平等待遇,从而被美国司法部起诉,并获得法院支持。欧洲议会也拟出台新法,允许消费者对违反数据保护的行为提起集体诉讼[24]。我国也可赋予个人信息保护部门、网信办或者人民检察院代表被歧视群体向司法机关提起诉讼的权利。
需要进一步说明的是,由于算法应用导致的个人信息侵权、进而引起算法决策歧视时,其请求权基础究竟为何。因算法应用导致的个人信息侵权案件在司法实践中大致包括隐私泄露、名誉侵权,甚至可能会导致用户财产损失⑭。此时可以直接行使个人信息修改或者删除权利,其请求权基础在于《个人信息保护法》第46 条。但如若因归因性不利引起“不公正”决策时,其可能会产生请求权基础竞合,用户可以根据具体需要选择合适的请求权基础。如若用户只要摆脱算法针对自己的不利决策,则需要借助《个人信息保护法》第24条认定其属于归因性不利,且造成对数据主体的歧视,以此行使针对平台算法自动化决策的反对权;如若用户意欲修正算法对自己的不当分析或者关联导致的个人信息错误,用户可以根据《个人信息保护法》第46条行使个人信息更正或删除权,防止对数据主体持续的不利影响。总之,用户可以根据诉讼目的以及举证的难易程度选择合适的请求权基础。
(2)举证责任的承担。算法歧视的证明,是反算法歧视制度落地的关键,也是《个人信息保护法》第24条可诉化的关键。由于数据主体与数据处理者双方在收集以及处理数据资源能力方面存在较大悬殊,因此原告提供的证据无需达到确实充分或者高度盖然的程度。数据主体只需要证明自己在受保护的应用场景下受到不利待遇的客观事实即可。一个成功的关于差别待遇的起诉,必须在受保护场景下存在一个与不利待遇群体相互对照的群体,这些受保护场景包括但不限于就业、社会福利分配、接受商品或者服务、信用评估、健康医疗、教育、司法场景等。例如,在存在“算法支配关系”的前提下,数据主体因使用某种算法而导致获得就业的机会概率降低,此时数据主体只需要举证证明与自己相同或相似条件的、并使用同一应用软件的数据主体被录用即可。另外,在证明自己受到关联性歧视的场合,数据主体则需要提供证明自己可能被错误归类的初步证据,例如,自己的用户标签存在错判或者错判可能等事由。
基于关联特征的歧视在当前可能面临操作性较低的问题。一方面,用户可能并不知晓自己正在遭受算法歧视,另一方面,用户也难以知晓其基于何种特征关联而遭受歧视。针对这一问题,建议用户可以向法院提供相应的信息浏览记录、平台推送内容等信息,提出引发歧视的某种可能的受保护特征,以此完成提供初步证据的证明责任。另外,数据处理者在数据处理与决策过程中还需要进一步提高透明度,向用户说明其推测的用户信息,尤其是可能的敏感信息。一方面,数据处理者可基于此判断是否可能会产生针对受保护群体的不利决策,另一方面,用户也可基于此提出反歧视的主张或诉求。受保护特征虽然是诱发歧视的一项重要因素,但有学者认为可以通过在算法分析中保留这种可能引起算法歧视的受保护特征因素,从而提高算法决策的公平性[20],笔者也大致赞同这一观点。这种受保护特征可以体现为“用户标签”,并设计用户标签的强制揭示制度,一方面用户可以基于受保护特征提出反歧视主张,另一方面,如若发现这种受保护信息出现错误,用户也可以基于个人信息更正权,提出对分析信息的更正请求。
(3)数据处理者的抗辩事由。针对数据主体所提出的相关证据,数据处理者可在此基础上提出抗辩事由。主要抗辩事由如下:1)不存在算法支配关系,即没有使用或者处理数据主体的个人数据,并在此基础上影响数据主体的行为。如果能够证明数字平台与数据主体之间不存在算法支配关系,则可以直接抗辩数据主体。2)没有歧视数据主体并造成数据主体的机会损失。对于机会损失的判断,可采用反事实(counter-factual)方法辅助判断,即通过调整敏感信息参数的方式进行测试,以判断涉案决策结果产生变动的概率大小。例如,在就业系统软件中,可以通过尝试改变性别参数测试在多大程度上或者有多大概率会改变算法的运算结果。反事实方法目前已被运用于反垄断的法律审查之中[25],其在检验算法决策的公平性程度方面,同样能够发挥重要作用。当然,由于该种测试方式存在技术难度,并且成本高昂,可由法院或者仲裁机构聘请中立的技术第三方进行鉴定,费用由算法设计者或者算法使用者承担。当然,算法结果公平的实现无法回避敏感(或受保护特征)信息的使用,因为某些结果公平的实现技术正是基于受保护特征的分组而实现的,但在数据处理的过程中,如此明目张胆地使用敏感信息,很可能因违反相关规范而造成违法[26]。因此,如果算法设计者以提高算法结果的公平性为目的而使用数据主体的敏感信息,可因此阻却敏感信息使用的违法性。3)差别待遇符合比例原则的检验要求。即从适当性、必要性以及均衡性三个层面证成涉嫌歧视的自动化决策具有合理的理由。
五、结 语
虽然技术层面提出诸多应对算法歧视的尝试,但算法歧视危机的完全消弭仍需时日。算法歧视的规范治理,不仅需要事前的预防与规制,更需要对其进行事后的违法性认定,从而构成算法治理的规范闭环。现阶段我们针对自动化决策仍应持谨慎态度,尤其要严格限制完全自动化决策的应用场合,并强调算法决策中人的作用[27]。为此,受保护场景下的自动化决策算法有必要履行严格的登记义务,在正式投入应用之前,需要进一步强化并证成算法自动化决策的合理性与必要性,并说明特定应用场景中的自动化算法采用了何种技术方法与手段以确保决策公平公正。当然,我们也鼓励采用创新思维与手段应对算法歧视危机,例如,目前有机构提倡采用众包模式化解科技伦理风险,推特(Twitter)即发布了第一个算法偏见赏金(bias bounty),通过邀请和激励人工智能伦理领域的研究人员来帮助识别推特图像剪裁算法的歧视危害与伦理问题。类似这些都是消弭算法歧视危机的有益尝试。
注 释:
①也有学者称之为算法的反身性。参见:Burk D L. Algorithmic legal metrics. Notre Dame L. Rev., 2020, 96: 1147.
②在Coleman 一案中,Coleman 所在工作单位职员都可因照顾孩子而获得较为灵活的工作时间,但是Coleman 因为其儿子残疾而最终没能获得同公司中其他职员相同的、灵活的工作时间,并且遭到公司解雇。Coleman 起诉到法庭,法庭认为,公司对Coleman 的行为已经构成了直接的关联性歧视,也即,在关联性歧视中,被歧视对象,或者获得不利结果的本人,不需要具有受保护特征,而只需要因同其相关的主体具有敏感信息。Coleman 案件为直接的关联性歧视提供了标准。
③在某地区的罗马人经常会受到当地政府的歧视,其中一种歧视形式,即当地政府将罗马人店面的电表安装在距离地面较高的高度,此案围绕着保加利亚的一名店主尼古洛娃展开。她的店面坐落在一个以罗马人居住为主的地区,尼古洛娃本人也不是罗马人的后裔,但她同样认为自己受到歧视,因为她的电表放在离地面6 米的高度,使得她无法监控自己店面的耗电量,而在大多数非罗马人聚居的地区,其电表的安装高度则低得多。法院最终也以当地政府成立间接的“关联性歧视”为由认定成立歧视。CHEZ 案具有这样一个里程碑式的意义,即虽然索赔人不属于受保护群体,或者与受保护群体并无密切关联,其也可以基于相关理由提起反歧视诉讼。
④受保护特征为:年龄、残疾、性别变更、婚姻或民事伴侣关系(仅限就业)、怀孕和生育、比赛、宗教或信仰、性别、性取向。参见《英国伦敦平等法案》Equality Act 2010, s 10.
⑤参见案例:Johnsonv. Allstate Ins. Co. , 2011 U. S. Dist. LEXIS 65318.
⑥参见案例:Newmanv. Google LLC., Case No. 20-CV-04011-LHK.
⑦参见案例:Carrollv. Nakatani, 342 F. 3d 934 (9th Cir. 2003).
⑧参见案例:Spokeo, Inc.v. Robins, 136 S. Ct. 1540, 1547, 194 L. Ed. 2d 635 (2016).
⑨参见案例:In Bradleyv. T-Mobile US, Inc., 17-CV-07232-BLF, 2020 WL 1233924 (N.D. Cal. Mar. 13, 2020).
⑩这一技术的目标是要实现相同情况相同对待,即具备相同条件的人应当获得相似的待遇。此种技术手段对“相似情形”进行数学指标量化,在对群体数据进行正确分类的前提下,对隶属于每一群体之内的数据主体做出相同或者相似的处理决定。参见:Kleinberg J, Ludwig J, Mullainathan S,et al.Algorithmic fairness. AEA Papers and Proceedings, 2018,108: 22-27.
⑪解耦技术可以针对不同类型和属性的群体,分别定义不同的参数、设置不同的算法,根据个体的群体隶属关系对个体进行分类,并对每个群体创建不同的算法,这种方式为不同类型的群体设定不同的计算参数或者参数权重,以实现不同群体的差别对待。参见:Dwork C, Immorlica N, Kalai A T, et al. Decoupled classifiers for group-fair and efficient machine learning.Conference on Fairness, Accountability and Transparency. PMLR, 2018: 119-133.
⑫机会均等确保本应属于低风险人群的社会群体应当被评价为低风险状态的权利。例如,在贷款申请的场景中,都能偿还贷款的男性和女性应当拥有相同的几率获得贷款,确保真正的低风险人群能够得到算法公正的评价。换句话说,平等机会要求给与真正属于积极阶层的群体被归类为积极阶层的机会,并确保群体能够代表所有的社会成员。参见:Besse P, Barrio E D, Gordaliza P, et al. A survey of bias in machine learning through the prism of statistical parity for the adult data set.arXiv:2003.14263,2020.
⑬这一统计方法涉及两个重要概念:假阳性(false positive)和假阴性(false negative),前者是指将本来应当受到消极评价的数据主体进行了积极评价,后者是指将本来应当受到算法积极评价的数据主体进行了消极评价。参见:Polyzou A,Kalantzi M, Karypis G. FaiREO: User group fairness for equality of opportunity in course recommendation. arXiv:2109.05931, 2021.
⑭例如,在“梁某、某实业公司与某科技公司网络侵权责任纠纷”中,原告梁某是原告某实业公司的法定代表人,其无意中发现,被告某科技公司运营的企业信用信息查询平台上,将与梁某无关的失信被执行人信息、限制高消费信息、终本执行案件信息等错误关联至其以及某实业公司名下,并对梁某造成经济损失。参见:https://www.12377.cn/jsal/2023/c0277510_web.html.
