基于特征优化和GAN 的红外与可见光图像融合算法
2024-01-15郝帅李嘉豪马旭何田孙思雅李彤
郝帅,李嘉豪,马旭,何田,孙思雅,李彤
(西安科技大学 电气与控制工程学院,西安 710054)
0 引言
图像融合作为一种重要的图像增强方法,旨在从同一场景不同模态传感器捕获的图像中提取互补信息并进行融合,从而增强视觉效果,辅助人们对场景进行理解[1-2]。红外热成像和可见光成像作为两种最常用的探测手段已有广泛应用。红外传感器主要通过目标场景的热辐射信息成像,能够捕获物体的热显著目标,具有不易受外界天气、光照强度等环境因素影响的优点,但其图像分辨率往往较低,纹理细节信息相对较少。可见光传感器依据物体的反射光线成像,能够捕获丰富的细节及背景信息,其图像细节分辨能力强,但易受外界光照强度变化、异物遮挡等因素干扰[3-4]。因此,结合两类图像各自优势,将其进行融合,可以得到纹理细节丰富、目标显著及视觉效果好的图像。目前,该方法已在目标检测[5]、目标跟踪[6]、侦察[7]和医学图像分析[8]等领域展开广泛研究和应用。
根据特征信息提取方式不同,红外与可见光图像融合算法可以分为两类:传统融合算法和基于深度学习的融合算法。传统融合算法主要通过相关数学模型来获取原始图像不同层次信息,再通过手工设计合适的规则对信息进行融合,主要包括基于多尺度变换和基于表示学习的融合算法。基于多尺度变换的融合算法主要将原始图像在频域中分解为不同分辨率、不同尺度的若干层子图像,然后根据设定的融合规则对分解的子图像进行组合,最后通过多尺度逆变换得到融合图像。常见的多尺度变换方法有金字塔变换、小波变换、轮廓波变换等。CHEN Jun 等[9]利用拉普拉斯金字塔变换将原始图像分别分解为低频带和高频带,对高频带使用最大绝对值融合规则,低频带由分解的红外低频信息来确定融合权重,最后使用拉普拉斯逆变换来重建融合图像。基于表示学习的融合算法是直接在空间域上处理图像像素,常用的主要包含稀疏表示和低秩表示。LU Xiaoqi 等[10]利用核密度估计聚类和奇异值分解数学模型提取出目标区域,并对背景信息进行稀疏表示,从而实现红外与可见光图像融合。然而,这些传统融合算法通常需要手工设计融合规则,计算过程较为复杂。
近年来,由于卷积神经网络(Convolutional Neural Network,CNN)具有较强的特征提取能力,基于深度学习的融合算法被相继提出。LI Hui 等[11]提出了用于红外和可见光图像融合的DenseFuse,该算法通过设计编码器和解码器网络来分别提高特征提取能力和重建能力。LIU Yu 等[12]基于CNN 构建了图像融合模型,通过活动水平测量和权重分配来实现图像融合。JIAN Lihua 等[13]结合残差网络构建了一种对称编码器-解码器结构,该结构可以有效保留每层卷积提取的特征信息。然而,由于红外与可见光图像融合任务难以定义融合效果标准,且没有Ground Truth 指导网络训练,导致该类方法在训练过程中无法有效估计原始图像特征分布,易产生特征分布不均衡的融合结果。
MA Jiayi 等[14]提出了一种基于生成对抗网络(Generative Adversarial Network,GAN)[15]的融合算法,生成器负责提取红外与可见光图像特征并生成融合图像,而判别器用于将融合图像与可见光图像进行区分,使融合图像在对抗博弈中能够保留足够的梯度信息。在此基础上,MA Jiayi 等[16]又构建了双判别器生成对抗网络模型,通过设计红外和可见光双判别器网络来区分融合图像与原始图像之间的结构差异,从而使融合结果能够同时保留原始图像特征信息。
基于GAN 的融合算法在一定程度上解决了传统融合算法的不足,可以更高效地提取图像特征信息,且通过网络模型对抗训练有效地平衡了原始图像特征分布,但依然存在不足:1)现有的融合算法主要集中在融合模型的构建,并未考虑原始图像质量对最终融合效果的影响;2)生成器中大都采用单一尺度卷积提取图像特征,易造成图像特征提取不充分,进而导致融合图像无法全面保留原始特征信息;3)由于没有考虑原始图像局部特征的全局依赖性,使得局部特征没有得到细化和增强,从而导致融合图像丢失重要目标特征信息。
针对上述问题,本文提出一种基于特征优化和GAN 的红外与可见光图像融合算法。考虑到原始图像质量对融合结果的影响,设计了一种基于变色龙算法(Chameleon Swarm Algorithm,CSA)[17]的目标函数自适应特征优化模块以增强可见光图像的纹理细节和红外图像的对比度。为解决生成器中采用单一尺度卷积层提取特征造成特征提取不充分的问题,构造了一种多尺度密集连接模块(Feature extraction module based on Multi-Scale Dense Connection,MSDC-Fem),从而增大网络感受野特征提取范围,以全面提取图像的深层语义特征和浅层纹理特征。为减小融合过程中重要目标特征信息损失,在特征融合层设计了基于空间和通道的并联型注意力模型。通过将红外与可见光图像特征信息分别同时送入空间和通道注意力模型中,捕捉不同模态特征之间的相关性和依赖关系,提高网络对关键信息的表达能力,从而更好地聚焦红外图像中的热显著目标和可见光图像中的纹理细节。
1 相关知识
1.1 潜在低秩表示
低秩表示(Low Rank Representation,LRR)[18]是在确定学习字典情况下,将原始数据矩阵表示为字典矩阵下的线性组合且表示系数矩阵低秩,以实现数据的空间分割与特征提取。但LRR 无法保留图像局部结构信息,在LRR 基础上,潜在低秩表示(Latent Low Rank Representation,LatLRR)[19]通过考虑隐藏数据信息对学习字典的影响来提取数据全局结构信息和局部结构信息,其相较于LRR 具有更强的特征提取能力。LatLRR 的数学模型可表示为
式中,B为原始数据最优的LRR 系数矩阵,D为显著系数矩阵,N为稀疏噪声矩阵,‖ ⋅ ‖*为核范数,‖ ⋅ ‖1为L1范数,X为原始数据矩阵,λ为正则化平衡参数且大于0。
将式(1)通过增广拉格朗日乘子法求解,得到系数B和D。以红外图像为例,假设红外图像为XI,经过LatLRR 分解后可表示为
式中,BXI表示低秩分量,DXI表示显著分量。
1.2 生成对抗网络
GAN 是使用对抗性模型来估计样本分布并生成新数据的无监督网络模型,它主要由生成器(Generator,G)和判别器(Discriminator,D)两部分构成。生成器学习训练集数据特征,并在判别器指导下,将随机噪声分布尽量拟合为训练数据的真实分布,从而生成具有训练集特征的相似数据。判别器负责区分输入是真实数据或生成器生成的假数据,并将判断结果反馈给生成器。两个网络交替训练,直到生成器生成的数据能够以假乱真,并与判别器的能力达到一种纳什均衡状态。G 与D 的对抗关系为
式中,x表示输入样本,z表示输入到生成器的噪声,Pdata(x)表示真实数据分布,Pz(z)表示噪声分布,D(x)表示判别器判断真实数据是否真实的概率,D(G(z))表示判别器判断生成数据是否真实的概率。
由于GAN 具有在无监督情况下学习真实数据分布的能力,故利用生成器生成融合图像,并通过判别器以期使融合图像在对抗学习中能够尽可能地保留原始图像的丰富信息。
2 算法原理
本文所提算法框图如图1 所示,主要由三部分构成:特征优化模块、生成器和判别器。特征优化模块旨在对原始红外和可见光图像进行增强,提高其特征表达能力;生成器的主要任务是对输入图像的特征进行提取、融合及重构,生成融合图像;判别器由可见光判别器(Discriminator-VIS)和红外判别器(Discriminator-IR)两部分构成,分别与生成器进行对抗学习,从而保证融合图像中既保留红外图像的对比度信息又具有可见光图像的梯度信息。
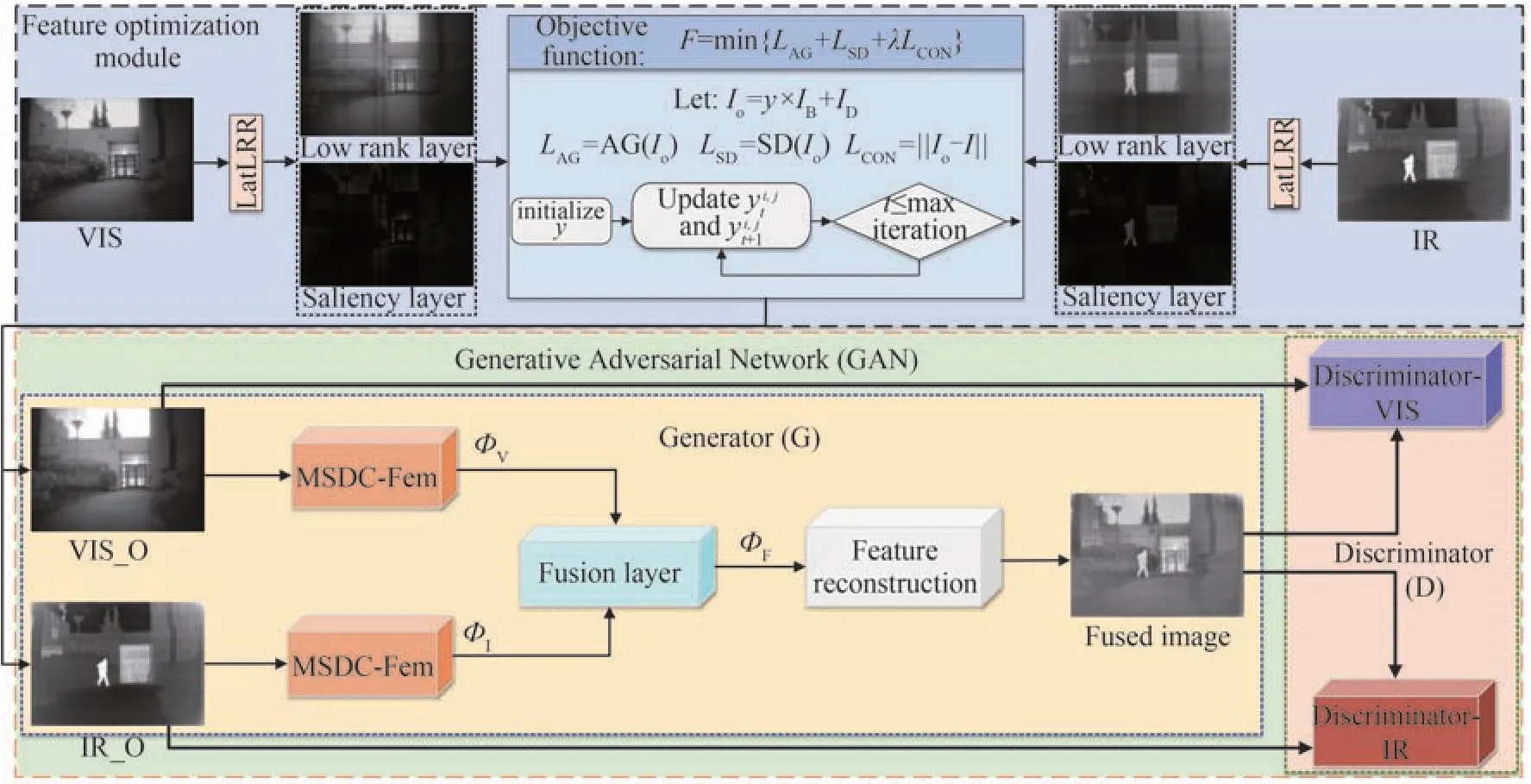
图1 本文算法框图Fig.1 Block diagram of the proposed algorithm
2.1 自适应特征优化模块设计
由于受外界环境影响,可见光图像会因光照强度变化导致纹理细节不清晰,而红外图像受热辐射成像机理影响,易出现目标对比度低等问题,会影响最终的图像融合效果。为此,设计了一种自适应特征优化模块,以增强原始图像特征表达能力。首先,利用LatLRR 对原始图像进行分解;然后,构建目标函数并设计优化模型对其进行迭代寻优;最后,得出优化因子y,进而获得优化图像,为后续图像融合奠定基础。优化图像可表示为
式中,Io为优化后的图像,y为优化因子,IB为图像低秩层,ID为图像显著层。
2.1.1 基于LatLRR 的图像分解
由于LatLRR 充分考虑了图像数据的全局结构、局部结构和稀疏噪声等方面,不仅能够从源图像中提取全局结构信息和局部结构信息,还可以在一定程度上分离图像中的噪声分量,减小视觉伪影。因此利用LatLRR 分别对原始红外与可见光图像进行分解,并得到各自对应的低秩层和显著层,如图2 所示。从图中可以看出,低秩层主要包含目标整体及背景细节信息,显著层则主要体现局部显著区域及边缘信息。

图2 LatLRR 分解结果Fig.2 LatLRR decomposition results
2.1.2 目标函数构建
为了较好地增强原始图像纹理细节,突出显著目标,选取梯度变化、对比度变化和内容损失作为约束条件,构造目标函数F为
式中,LAG为平均梯度函数,LSD为标准差函数,LCON为内容损失函数,λ表示保持两项平衡的正则化参数,取λ=1/300。
平均梯度(Average Gradient,AG)用来度量图像梯度信息,且可以在一定程度上反映图像的细节纹理[20]。AG 值越大,图像包含的梯度信息越多,LAG定义为
式中,∇Iox(i,j)=Io(i,j)-Io(i+1,j),∇Ioy(i,j)=Io(i,j)-Io(i,j+1),M和N为图像宽和高,(i,j)为图像横、纵坐标。
标准差(Standard Deviation,SD)主要用来反映图像对比度信息[21],SD 值越大,图像的对比度越高,视觉效果越好,LSD定义为
式中,ϕ表示图像的平均值。
为了衡量优化过程中的目标信息损失程度,设计了内容损失函数LCON,定义为
式中,I表示原始图像。
2.1.3 基于CSA 的目标函数自适应优化
为得到优化因子y,采用变色龙优化算法(CSA)进行求解。CSA 主要模拟了变色龙在树木、沙漠和沼泽附近寻找食物时动态行为。该算法具有寻优能力强、收敛速度快、精度高等特点。为此,针对设计的目标函数F,即式(5),将CSA 引入到优化机制中,利用CSA 进行寻优,从而求解优化因子y。CSA 步骤为:
1)初始化。初始种群是根据搜索空间中均匀随机初始化的变色龙数量和空间的维数创建的,即
式中,yi为第i个变色龙的初始位置,uj和lj分别表示搜索区域在第j维的下界和上界,r为[0,1]范围内均匀生成的随机数。
2)搜索猎物。变色龙觅食过程中的运动行为可以采用以下位置更新策略进行建模。
式中,T为最大迭代次数,t为当前迭代次数,γ、α、β用于控制搜索和发现的能力,分别设置为1、3.5、3。
3)眼睛旋转发现猎物。变色龙的眼睛能360°旋转进行猎物搜索,并根据猎物的位置来更新自己的位置,位置更新数学描述为
4)捕获猎物。当猎物离变色龙较近时,变色龙便利用舌头攻击并捕获猎物。位置更新数学描述为
综上,通过搜索猎物、眼睛旋转发现猎物和捕获猎物三阶段的位置迭代更新可求得最佳位置y。在迭代寻优过程中,针对变色龙的位置解,利用目标函数F计算其适应度值,变色龙个体根据当前的位置和适应度值,采取一定的策略进行移动,并寻找更优的位置。根据新位置再次计算更新后的适应度值,进而更新全局最优解。如果达到最大迭代次数或满足目标函数F的要求,则优化结束,输出最优解y,否则继续进行迭代更新寻找最优解,进而得到优化因子。伪代码如表1 所示,原始图像优化前后效果如图3 所示。

表1 基于CSA 的目标函数自适应优化Table 1 Adaptive optimization of objective function based on CSA

图3 优化前后对比Fig.3 Comparison chart before and after optimization
从图3 红色框标注区域可以看出,相较于原始图像,经过特征优化模块后,可见光图像的纹理细节和目标轮廓更清晰,红外图像的对比度和清晰度也更加明显,为后续图像融合奠定了良好基础。
2.2 融合注意力模型的GAN 网络
2.2.1 生成器
生成器网络主要由特征提取、特征融合以及特征重构三部分构成。
2.2.1.1 基于多尺度密集连接的特征提取模块
红外和可见光图像具有不同的成像机理,其特征表现形式往往有所差异。为此,设计了双支路特征提取网络,分别提取可见光图像的梯度信息和红外图像的对比度信息,如图1 所示。两条支路结构相同、参数独立,能够有效降低模型复杂度。同时,为解决单一尺寸卷积核特征提取不全面的问题,构造了一种基于多尺度密集连接的特征提取模块(MSDC-Fem),如图4 所示。
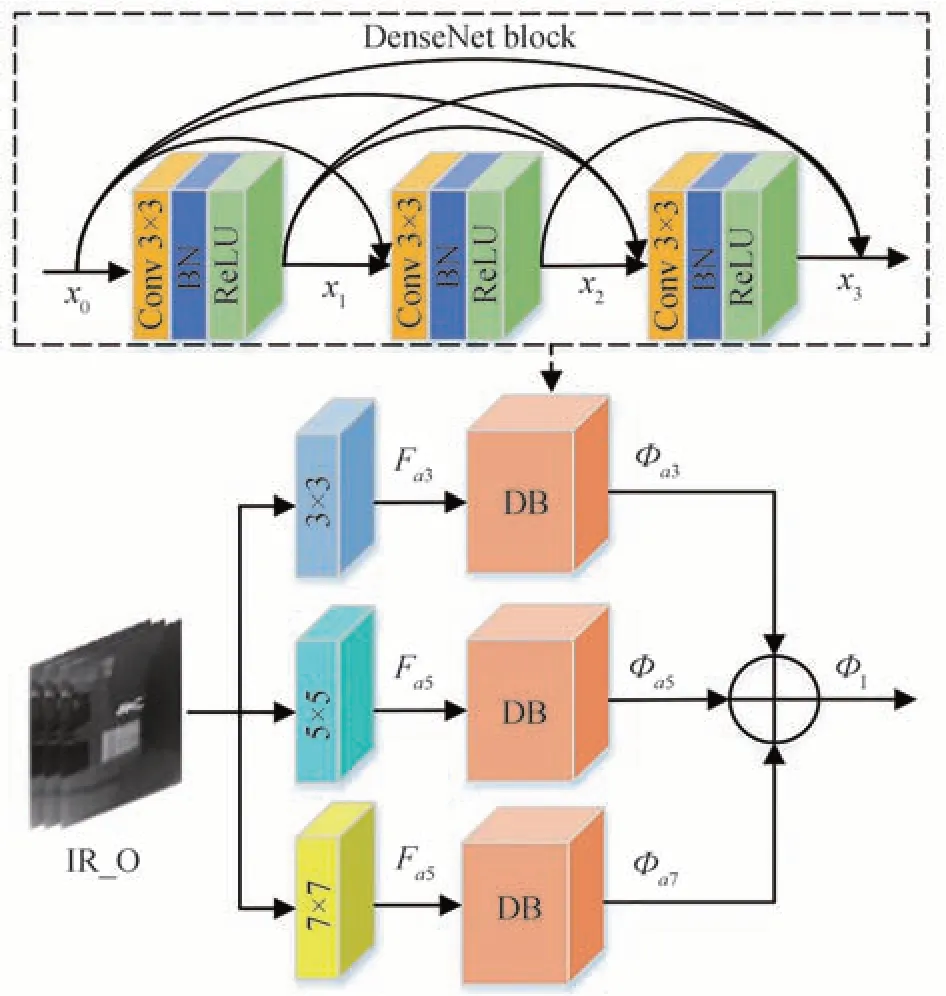
图4 MSDC-Fem 结构Fig.4 MSDC-Fem structure diagram
以经过特征优化后的红外图像IR_O 为例,首先,分别使用三个卷积核大小为3×3、5×5、7×7 的卷积层对输入图像进行多尺度特征提取。然后,为避免特征提取时中间层信息丢失问题,在每个不同尺度的卷积分支后分别接入密集连接网络(Densely Connected Convolutional Network,DenseNet)[22]进行更深层次特征提取,增强特征传递及重用,使生成器能够更有效地利用原始图像特征信息,同时还可以减轻网络梯度消失。该密集连接网络模块由3 个密集连接的卷积层组成,各卷积层的卷积核大小均为3×3。最后,将提取的多尺度深层特征进行融合得到局部融合特征。因为在特征计算时所采用的补0 策略都是“SAME”,所以不同尺度卷积得到的特征图尺度一样,可以直接进行相加。图4中,利用MSDC-Fem 对输入图像进行特征提取时,可以表示为
式中,Fa3、Fa5、Fa7分别表示不同尺度的特征图,Fin为输入图像,*表示卷积操作,f3×3、f5×5、f7×7分别表示3 个不同尺寸的卷积核。
x0、x1和x2分别为三个卷积层的输入,x3为密集块的末端输出,以3×3 卷积支路为例,x0~x3分别表示为
式中,©表示通道连接,Φa3为3×3 支路得到的深层特征。同上,可分别得到另外两条支路的深层特征Φa5和Φa7。最终,红外图像局部融合特征可表示为
同理,经过MSDC-Fem 模块可获得可见光图像局部融合特征ΦV。
2.2.1.2 基于双通道注意力特征融合网络
在融合层设计双通道注意力模型,以使网络从空间和通道两个方向同时聚焦重要目标特征信息,且通过并联连接,网络可以将不同层次的特征信息进行整合,更好地强化重要的空间位置信息和通道特征信息,从而提高网络对关键信息的表达能力。同时,相比于串联方式,并联的双通道注意力机制可以在不同的输入之间进行自由的信息交互,能够更好地捕捉输入特征之间的相关性和依赖关系。具体过程为:将可见光和红外图像对应的局部融合特征ΦV和ΦI经过空间注意力模型,可得到空间区域信息加强后的注意力融合特征图ΦsaF,经过通道注意力模型,可对局部融合特征的通道信息进行增强,得到通道注意力融合特征图ΦcaF。最后,采用加权平均融合规则将两种注意力融合特征图进行融合,得到全局融合特征图ΦF,如图5 所示。
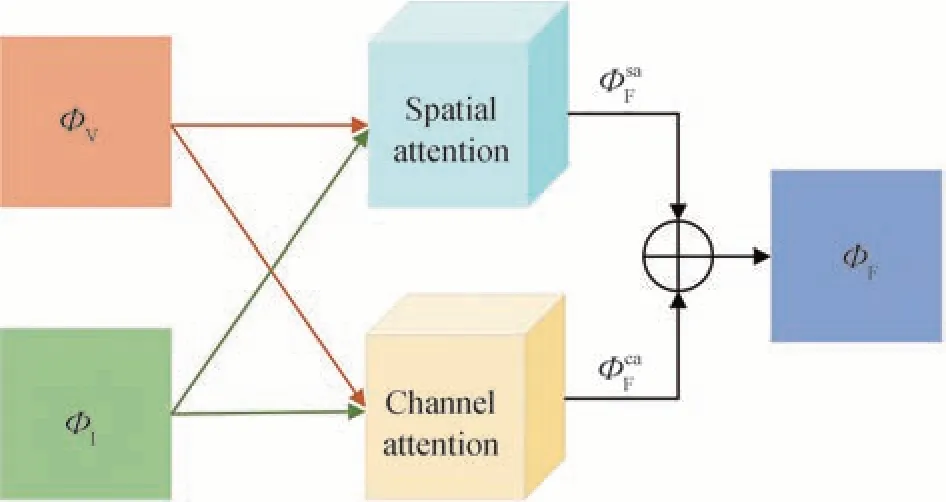
图5 注意力融合过程Fig.5 Attention fusion process
1)空间注意力模型
对ΦV∈RH×W×C和ΦI∈RH×W×C分别通过计算像素向量沿通道维数方向的LP范数得到其初始注意力图[23],即
将空间加权图与局部融合特征图进行相乘,分别得到红外和可见光图像的通道注意力图,即
最后,将两者进行线性叠加得到空间注意力特征图,即
2)通道注意力模型
首先,计算每个通道上特征映射的LP范数,得到初始通道注意向量,即
将通道加权图与局部融合特征图进行相乘,分别得到对应的红外和可见光图像空间注意力图,即
最后,将两者线性叠加得到通道注意力特征图为
3)加权融合
2.2.1.3 特征重构模块
在特征重构部分,通过4 层卷积的解码网络对全局融合注意力特征图ΦF进行重构,进而得到融合图像,如图6 所示。在解码网络中,各卷积层均采用(Conv3×3)+BN+ReLU 结构,滤波器数分别设置为128、64、32 和1。
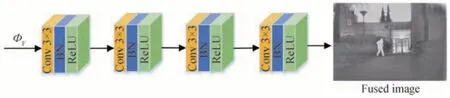
图6 特征重构模块Fig.6 Feature reconstruction module
2.2.2 双判别器
判别器网络主要用于判断生成器生成的图像是否服从真实样本分布。为了同时保留可见光的纹理细节信息和红外图像的显著目标信息,构造了双判别器结构,如图7 所示。Discriminator-VIS 用于区分融合图像和可见光图像,Discriminator-IR 用于区分融合图像和红外图像。考虑到两个判别器之间的平衡,使其具有相同的网络结构,均由4 个卷积层和1 个线性层组成,4 个卷积层均使用3×3 卷积核和ReLU 激活函数,每个卷积层的步长设置为2,滤波器组参数分别为32、64、128 和256。线性层将输入与前4 个卷积层提取的特征进行区分,并输出分类概率。此外,卷积层C1~C3 加入批归一化以缓解网络梯度消失问题。
2.3 损失函数设计
损失函数由生成器损失LG和判别器损失LD两部分构成,生成器损失LG包括对抗损失Ladv和内容损失Lcontent,即
式中,λ1为权重系数,用于两者之间的平衡。
式中,N表示融合图像的数量,表示生成的融合图像,D(⋅)表示判别器分类结果,a1和a2分别表示两个判别器的输出概率。对于生成器,不期望判别器能够区分融合图像和真实图像,故取a1=a2=0.7~1.2 之间随机。
内容损失由对比度损失Lcon和梯度损失Lgrad构成,Lcon约束目标物体与背景的对比度,Lgrad约束融合图像的纹理细节信息,即
式中,ξ1和ξ2是平衡两者的正则化参数。Lcon和Lgrad分别表示为
式中,Ifused表示融合图像,Iir表示原始红外图像,Ivis表示原始可见光图像,‖ · ‖F表示Frobenius 范数,∇表示梯度计算。
通过判别器损失函数可以平衡判定融合图像与原始图像的真假性,进而与生成网络模型对抗博弈,使生成的融合图像更趋向于原始图像真实数据分布。判别器损失由红外判别器损失和可见光判别器损失两部分构成,即
式中,air为输入的红外优化图像,bvis为输入的可见光优化图像,d表示融合图像标签,在0~0.3 之间随机选取。
3 实验结果与分析
实验所使用的硬件平台配置:CPU 为AMD Ryzen 5 5600X 6-Core Processor,主频3.70 GHz;GPU 为NVIDIA GeForce RTX 3070 8GB。训练和测试在Windows10 系统上,并采用Pytorch 框架完成。
3.1 数据集与参数设置
采用TNO image fusion 公开数据集[24]进行实验,从中任选32 组已配准的不同场景下的红外和可见光图像,先经过特征优化模块得到优化后的图像,再将此图像作为训练数据集。为了训练一个良好的模型,增强模型的鲁棒性,需对数据集进行扩充。采用滑窗方式对32 组优化后的图像进行裁剪,裁剪步长设为12,裁剪图像块尺寸为120×120,获取24 200 组红外与可见光图像对,并将其灰度值范围转换为[0,1]。
生成器和判别器采用迭代训练方式,两者训练次数之比为p。同时,batchsize 大小为b,总的训练epochs为M。实验中,取p=1/2、b=16、M=300。采用Adam 优化器对网络模型参数进行优化,学习率设为1×10-4。损失函数参数设置为λ1=0.1、ξ1=2、ξ2=5,具体训练过程见表2。

表2 网络模型的训练过程Table 2 Training process of network model
3.2 实验结果分析
3.2.1 主观评价
为验证本文算法优势,从TNO 数据集中任选6 组红外和可见光图像进行主观评价。将本文算法与DenseFuse[11]、FusionGAN[14]、ResNet-ZCA[25]、MDLatLRR[26]、PMGI[27]以及RFN-Nest[28]进行对比,实验结果如图8 所示。为了便于观察和分析,对融合结果局部细节用红框进行标注。

图8 主观实验结果对比Fig.8 Subjective experimental results comparison
从图8 可以看出:DenseFuse 算法由于采用卷积网络作为特征提取和重建模块,融合图像中较好地保留了纹理细节,但其对红外图像的特征提取能力有一定的限制,所以红外目标信息存在一定的损失,如第4 组图像中人物目标信息不突出;FusionGAN 算法一定程度上保留了红外显著目标,但由于其采用单一判别器结构,造成可见光纹理细节信息的部分丢失,如第1 组图像中树枝和第6 组图像中飞机底支架的纹理细节不丰富、边缘轮廓较为模糊;MDLatLRR 算法采用多级分解并使用不同的融合策略,能够较好地保留原始图像的细节信息,图像的轮廓信息也较为清晰,但红外目标不突出,如第3 组图像中汽车前端红外信息损失严重;RFN-Nest 算法采用两阶段训练,使用自动编码器更注重于纹理细节的保留,而忽略了红外目标特征的保留,如第2 组和第4 组图像中人物热目标不突出、边缘较为模糊;PMGI 算法基于均方误差构建了像素强度和梯度约束,可以生成较清晰的融合图像,但一些局部纹理细节信息不能有效保存,如第5 组图像中路灯边缘较模糊;ResNet-ZCA 算法通过计算权值图并与原始图像结合获得融合图像,取得了较好的融合效果,但目标区域没有突出显示,如第5 组图像中人物背部红外信息不明显;而本文算法通过构造特征优化模块增强图像特征表达能力,并设计融合注意力模型的GAN 网络,使得融合结果纹理细节信息丰富、红外目标突出、目标边缘清晰及视觉效果好,相比于其他对比算法具有明显优势。
3.2.2 客观评价
为了客观评价本文算法优势,从TNO 数据集中随机选取21 组图像进行定量分析。选取的客观评价指标[29]包括:信息熵(Entropy,EN)、空间频率(Spatial Frequency,SF)、相关熵(Joint Entropy,JE)、视觉保真度(Visual Information Fidelity,VIF)、结构相似性(Structure Similarity Index Measure,SSIM)和梯度信息指标(Gradient-based fusion performance,QAB/F)。上述评价指标的数值越大,图像的融合效果越好,对比实验得到的客观评价指标如图9 所示。
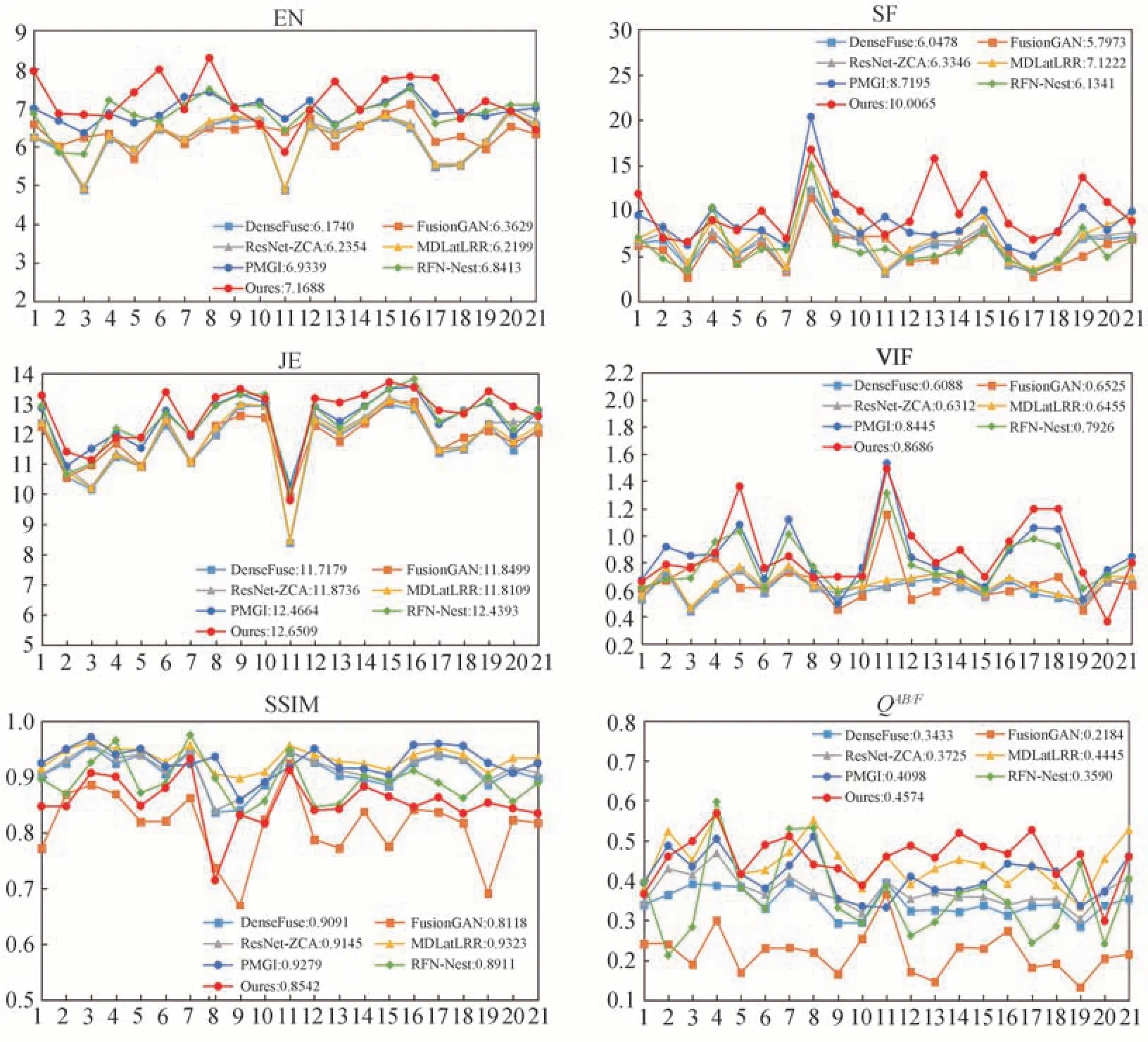
图9 客观实验结果对比Fig.9 Objective experimental result comparison
从图9 可以看出,本文所提算法在EN、SF、JE、VIF 和QAB/F5 项指标中取得最优平均值,且相比于DenseFuse 算法,客观指标分别提高了16.11%、65.46%、7.96%、42.67%和33.24%。SF、JE 和VIF 较高表明融合图像不仅具有较强的细节表达能力,而且符合人类视觉感知。QAB/F和EN 较高表明融合图像信息量更丰富。对于SSIM,其反映了融合图像与原始图像的结构相似性。由于所提算法引入了注意力融合模块,要同时保留红外图像的显著度信息和可见光图像的纹理细节信息,而融合过程通过优化平衡原始特征映射,会导致融合图像中的某些结构和边缘弱化,进而使SSIM 相对较低。
3.2.3 算法运行时间比较
为了进一步评估算法的复杂性和运行效率,在测试集上对比了各算法的平均运行时间,比较结果如表3所示。实验结果表明,本文算法的平均运行时间低于DenseFuse 和RFN-Nest,这是因为本文算法引入了多尺度密集连接模块和注意力融合模块,增加了模型的计算量。

表3 不同算法平均运行时间(单位:秒)Table 3 Average running time of different algorithms (units: s)
3.2.4 算法收敛性分析
本文算法训练过程中的loss 下降曲线如图10 所示,可以看出,网络仅训练30 轮损失值即下降至0.05,约在100 轮之后达到平衡且最终稳定在0.024 2 左右,表明本文算法取得了较好的训练效果,即损失函数收敛快,稳定数值小,网络训练稳定,图像融合精度高。
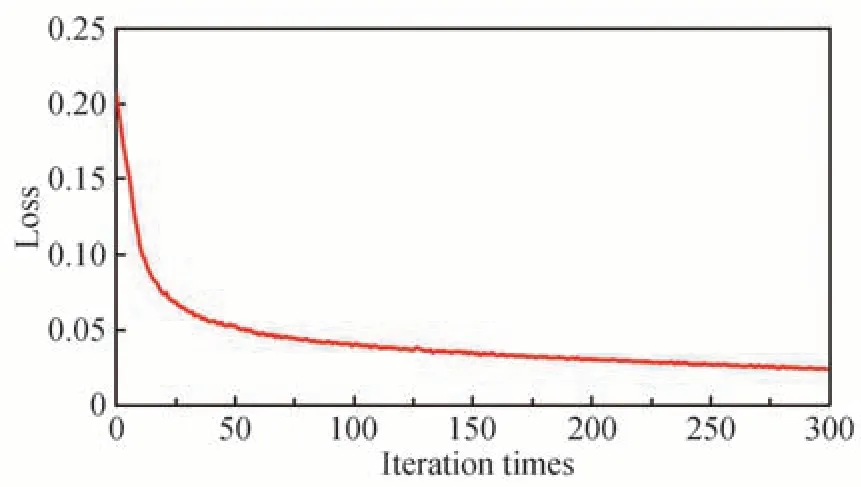
图10 损失函数曲线Fig.10 Loss function curve
3.3 消融实验
所提算法主要包括特征优化模块、MSDC-Fem 模块及注意力融合模块。为验证各模块的有效性,通过加入不同模块对TNO 数据集21 组图像和6 个评价指标进行消融实验,所有实验均使用相同的数据集和参数设置。为了描述方便,将3 个模块分别简记为模块A、模块B 和模块C。其中,在未使用特征优化模块时,网络的输入是原始可见光和红外图像;在未使用MSDC-Fem 模块时,网络改用普通单一尺度卷积提取特征;在未使用注意力融合模块时,网络采用线性叠加的融合规则。21 组图像消融实验客观指标平均值的对比结果如表4 所示,最优值用粗体标注。

表4 消融实验客观结果对比Table 4 Ablation experiments objectively results comparison
从表4 可以看出,相比于原始融合网络(3 个模块均不加入),引入特征优化模块,SF 和QAB/F分别提升了10.30%和14.29%,表明特征优化模块可使得融合结果在感知上更加清晰,细节更加丰富。引入MSDCFem 特征提取模块,SF 提升了21.59%,表明在特征提取过程中多尺度模块增大了网络感受野特征提取范围,密集连接模块加强了特征的有效传递和重用,进而增强了融合结果的细节和结构。引入注意力融合模块,SF 和VIF 分别提升了6.68%和3.85%,表明注意力模型使得红外与可见光图像的关键特征得到更好的保留和强化。不同模块协同训练的结果表明:模块A+模块B,EN、SF 和SSIM 分别提升了7.10%、35.67%和6.18%;模块A+模块C,VIF 和QAB/F分别提升了6.71%和22.44%;模块B+模块C,SF、JE 和VIF 分别提升了45.91%、4.22%和25.49%。本文算法通过融合3 个设计模块,在EN、SF、JE、VIF 和QAB/F5 个指标取得最优值,且分别提升了12.20%、70.64%、5.81%、30.77%和48.99%,验证了算法各模块的优势。
4 结论
本文提出了一种基于特征优化和GAN 的红外与可见光图像融合算法。通过设计基于CSA 的自适应特征优化模块,解决了原始图像纹理细节不清晰、目标对比度差等问题。在生成器中,构造了多尺度密集连接模块,可以使提取的特征更全面丰富;同时,在特征融合网络中设计并联式双通道注意力模型,有效地避免了原始重要信息的丢失。在判别器中,设计双判别器网络结构,既保留了可见光纹理细节信息又保留了红外热显著度信息。实验结果表明,与其他6 种融合方法相比,本文方法不仅具有更好的主观效果,且在客观评价指标EN、SF、JE、VIF 和QAB/F中取得最优值。相比于DenseFuse,客观评价指标分别提高了16.11%、65.46%、7.96%、42.67%和33.24%,表明本文方法具有较好的融合效果。
