Point Cloud Processing Methods for 3D Point Cloud Detection Tasks
2024-01-12WANGChongchongLIYaoWANGBeibeiCAOHongZHANGYanyong
WANG Chongchong, LI Yao, WANG Beibei,CAO Hong, ZHANG Yanyong
(1. Anhui University, Hefei 230601, China;2. University of Science and Technology of China, Hefei 230026,China;3. Institute of Artificial Intelligence, Hefei Comprehensive National Science Center, Hefei 230026, China)
Abstract: Light detection and ranging (LiDAR) sensors play a vital role in acquiring 3D point cloud data and extracting valuable information about objects for tasks such as autonomous driving, robotics, and virtual reality (VR). However, the sparse and disordered nature of the 3D point cloud poses significant challenges to feature extraction. Overcoming limitations is critical for 3D point cloud processing. 3D point cloud object detection is a very challenging and crucial task, in which point cloud processing and feature extraction methods play a crucial role and have a significant impact on subsequent object detection performance. In this overview of outstanding work in object detection from the 3D point cloud, we specifically focus on summarizing methods employed in 3D point cloud processing. We introduce the way point clouds are processed in classical 3D object detection algorithms, and their improvements to solve the problems existing in point cloud processing. Different voxelization methods and point cloud sampling strategies will influence the extracted features, thereby impacting the final detection performance.
Keywords: point cloud processing; 3D object detection; point cloud voxelization; bird's eye view; deep learning
1 Introduction
3D object detection is critical for applications such as autonomous driving, robotic system navigation, and automation systems. The goal of 3D object detection is to locate and identify objects in 3D scenes. Specifically, its purpose is to estimate oriented 3D bounding boxes and semantic categories of objects from point cloud data and provide important information for subsequent analysis and processing.3D point cloud object detection is a challenging task. Here are some major difficulties:
1) Occlusion: In complex scenes, target objects may be occluded by other objects, which affects the performance of detection algorithms.
2) Sparsity: Due to the working principle of light detection and ranging (LiDAR), point cloud data are usually sparse,which means that there are fewer effective points on the target object.
3) Point cloud noise: Noise points may be generated during the LiDAR scanning process, which will interfere with the performance of the detection algorithm.
4) Real-time requirements: 3D point cloud object detection usually needs to be completed in real time.
The object detection algorithm is a computer vision technology that can identify and locate specific objects in images or point clouds and is divided into 2D object detection[1-3]and 3D object detection[4-8]. These algorithms typically use deep learning techniques. Object detection includes tasks such as classification, localization, detection, and segmentation. Classification refers to obtaining what type of object is included in the image or point cloud data. Localization refers to the position of the given object. Detection refers to locating the position of an object and judging the category of the object. Segmentation refers to determining which object or scene each point or each pixel belongs to. Object detection algorithms are widely used in many fields, such as face recognition, automatic driving, and industrial inspection. For example, in face recognition, object detection algorithms can be used to automatically detect and track human faces and recognize the detected faces. Unmanned driving applications rely on object detection algorithms to give the poses of other traffic participants to deal with complex road conditions.
The point cloud processing method is a primary part of the 3D point cloud object detection algorithm. It can be roughly divided into the following two categories: the voxel-based point cloud processing method and point-based point cloud processing method.
The voxel processing method converts point cloud data into voxel representations, which are then processed using 3D convolutional neural networks (CNN). The point-based method is directly applied to the raw point cloud data, without converting it into grids. The point-based method can preserve the original characteristics and information of the point cloud and have lower computational cost and memory consumption.
However, the point-based method also faces some difficulties, such as dealing with the irregular structure and varying density of the point cloud and designing suitable algorithms or models for the points. Two major types of methods exist for processing the points: clustering-based methods[9-10]and deep learning-based methods[11-12]. Based on the clustering method, the appropriate clustering algorithm is selected and the clustering parameters are determined by the characteristics of the data. After denoising and merging adjacent clustering operations, the processing results are obtained. The method based on deep learning needs to prepare labeled data,select and train an appropriate deep learning model, and use the trained model to process the point cloud.
Our contribution can be summarized as follows:
1) We summarize voxel-based point cloud processing methods and find that the voxel-based methods can improve the processing performance of point clouds by optimizing the voxel partitioning scheme, improving the network structure for voxelized point clouds and the data structure for point clouds.
2) We summarize point-based point cloud processing methods and find that the point-based methods can improve the processing performance of point clouds by improving the sampling strategy of point clouds, combining the advantages of voxel-based methods, and optimizing the representation of points.
2 Basic Concepts and Metrics
1) Voxelization
Point cloud voxelization in Fig. 1 refers to the process of converting point cloud data into a voxel representation. Voxelization is to divide the point cloud into a spatially uniform voxel grid and generate many-to-one mapping between 3D points and their corresponding voxels.
The voxelized point cloud data will be stored in memory in an orderly manner, which is beneficial to reduce random memory access and increase the efficiency of data calculation.Moreover, voxelization enables the ordered storage and downsampling of data, which allows such methods to handle much larger point cloud data. The voxelized data can also leverage spatial convolution effectively, which facilitates the extraction of local features at multiple scales and levels.
2) BEV
The bird’s eye view (BEV) based algorithm is an advanced computer vision technique used in the field of autonomous driving. Using a combination of sensors and cameras, the algorithm creates a high-resolution overhead view of the vehicle’s surroundings. The BEV perspective is shown in Fig. 2.
One of the advantages of BEV is that it provides a comprehensive view of the environment, providing a complete picture of the environment, unlike other computer vision techniques that only focus on specific objects in the environment. The perspective can provide more information for subsequent planning decisions. Another advantage is accuracy. A highresolution top view can provide more accurate information.One disadvantage of the BEV-based algorithm is that BEV requires high computing power, which is challenging in realtime systems.
BEV is currently a very popular point cloud processing perspective. The methods related to BEV are proposed in Refs.[13-17]. Ref. [18] demonstrates the robustness capability of the BEV method.
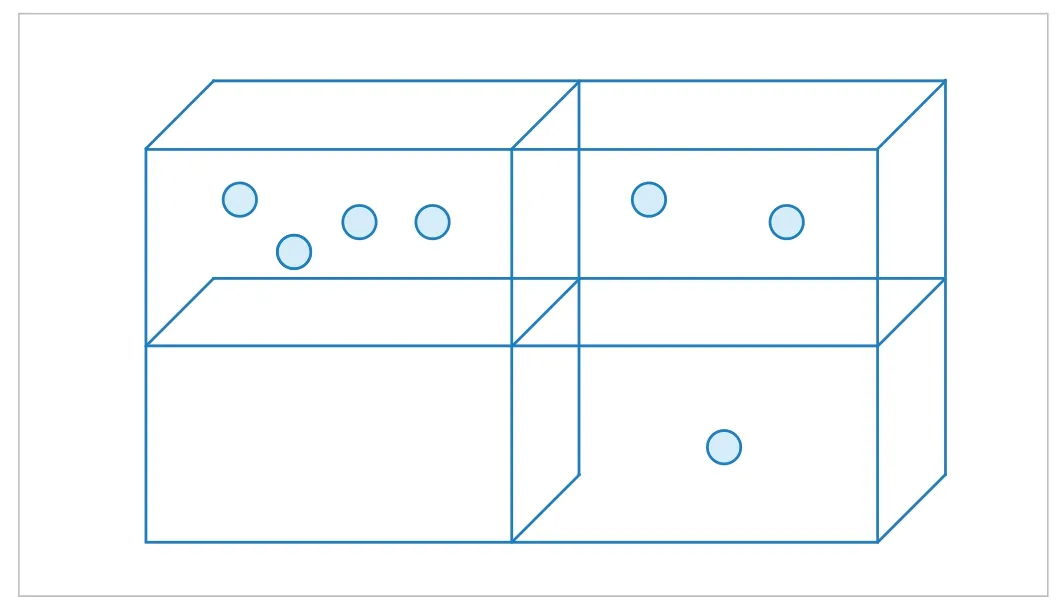
▲Figure 1. Schematic representation of point cloud voxelization. Due to the sparsity and uneven distribution of point clouds, the number of point clouds in each voxel is unevenly distributed. There are even many voxels without point clouds. The voxel feature encoding (VFE) layer balances this through sampling
3) FPS
Farthest point sampling (FPS) is a commonly used sampling algorithm, especially suitable for LiDAR 3D point cloud data.It can guarantee uniform sampling of samples, so it is widely used. For example, in PointNet++[12], a 3D point cloud deep learning framework, sample points are sampled by FPS and then clustered as the receptive field; in VoteNet[19], the scattered points obtained by voting are sampled by FPS and then clustered; in PVN3D[20], a 6D pose estimation algorithm, it is used to select eight feature points of the object to vote and calculate the pose.
The principle of the FPS algorithm is: Given a point cloud withNpoints, a pointP0is selected from the point cloud as the starting point to obtain a sampling point setS= {P0}. Then we calculate the distance from all points toP0to form anNdimensional arrayL, select the point corresponding to the maximum value asP1, and update the sampling point setS={P0,P1}. Then we calculate the distance from all points toP1.For each pointPi, if the distance toP1is less thanL[i],L[i] =d(Pi,P1) is updated. Therefore, the storedLin the array is always the shortest distance from each point to the sampling point setS. The point corresponding to the maximum value inLis then selected asP2and the sampling point setS= {P0,P1,P2} is updated. The above steps are repeated untilN’ target sampling points are sampled.
Several evaluation metrics are commonly used to assess the performance of an algorithm in 3D object detection. Here are some of the most common ones:
· Average precision (AP): This is a widely used metric that measures the accuracy of object detection algorithms. It is calculated by computing the area under the precision-recall curve. AP is often used to compare the performance of different algorithms on a given dataset.
· Intersection over union (IoU): This metric measures the overlap between the predicted bounding box and the ground truth bounding box. It is calculated as the ratio of the intersection area to the union area of the two boxes. IoU is often used as a threshold to determine whether a detection is true positive or false positive.
· Mean average precision (mAP): This metric is similar to AP, but it is calculated by taking the average of AP values across multiple object categories; mAP is often used to evaluate the overall performance of an object detection algorithm.
· Precision: This metric measures the proportion of true positives among all detections. It is calculated as TP/(TP +FP), where TP is the number of true positives and FP is the number of false positives.
· Recall: This metric measures the proportion of true positives among all ground truth objects. It is calculated as TP/(TP+FN), where TP is the number of true positives and FN is the number of false negatives.
These metrics are important for evaluating 3D object detection because they provide a quantitative measure of the object performance. By comparing these metrics across different algorithms, researchers can identify which ones are most effective for a given task.
3 Voxel-Based Point Cloud Processing Methods
Voxel-based 3D point cloud object detection methods convert irregular point clouds into compact-shaped voxelized representations and then efficiently extract point cloud features for 3D object detection through 3D convolutional neural networks. During voxelization, the point cloud data are divided into a certain number of voxels, and these voxels are grouped and down-sampled. Since the point cloud data need to be down-sampled during the voxelization process, some detailed information will be lost. The degree of information loss is closely related to the chosen resolution.
Although the voxelization process causes information loss,it has many advantages. First, the voxelized point cloud data will be stored in an orderly manner in memory, which will help reduce random memory access and increase data computing efficiency. Second, thanks to the ordered storage and down-sampling of data brought about by voxelization, this type of method can handle point cloud data in a large amount. In addition, the voxelized data can efficiently be processed by spatial convolution, which is beneficial for extracting multiscale and multi-level local feature information.
When it comes to voxel-based methods[5,21-24], VoxelNet[21]has to be mentioned, which is a pioneering work. VoxelNet proposes a voxel feature encoding (VFE) layer, which groups points within a voxel in Fig. 1, and the number of point clouds after grouping is not exactly the same. In order to reduce the imbalance of the number of point clouds between groups, reduce the sampling deviation, and save computing resources,the grouped point clouds are randomly sampled so that the number of points in each group does not exceed a fixed valueT. In each group, they apply PointNet[11]to learn features on each point and aggregate point features to obtain voxel-level features.
VFE is an important module. The VFE layer in Fig. 3 voxelizes the original 3D point cloud data and learns voxel-level features. This method combines the original point cloud representation and 3D voxel representation. After extracting features from the point cloud, VoxelNet uses convolutional middle layers and region proposal networks (RPNs)[25]to generate the final 3D detection box.
The key innovation of VoxelNeXt[5]is to omit the steps of anchor, sparse-to-dense, RPN, non max suppression (NMS), etc.,and directly predict objects from sparse voxel features. Based on VoxelNet, VoxelNeXt has better accuracy and a speed trade-off than other detectors in nuScenes[26]. Compared with the CenterPoint[27], fully sparse 3D object detector (FSD)[28]and other methods, VoxelNeXt is more friendly to longdistance object detection in Fig. 4.
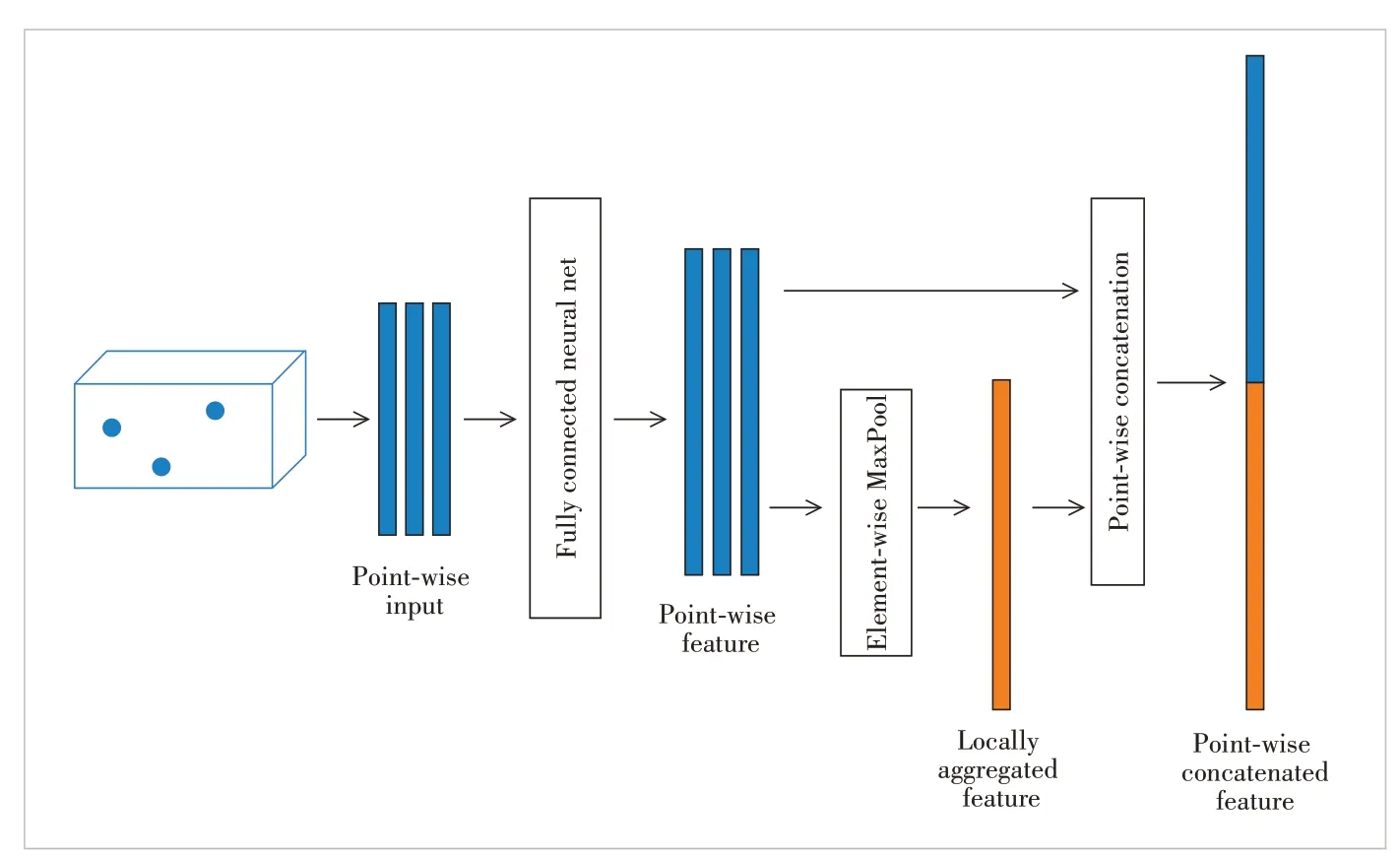
▲Figure 3. Each sampled voxel (the number of point clouds t < T) is transformed into a feature space point by point through a fully connected neural network and then the information is aggregated from the point features to encode the surface shape contained in the voxel. The aggregated features are obtained element by element through max pooling. The point-wise feature and locally aggregated feature connection are then aggregated to get a point-wise concatenated feature
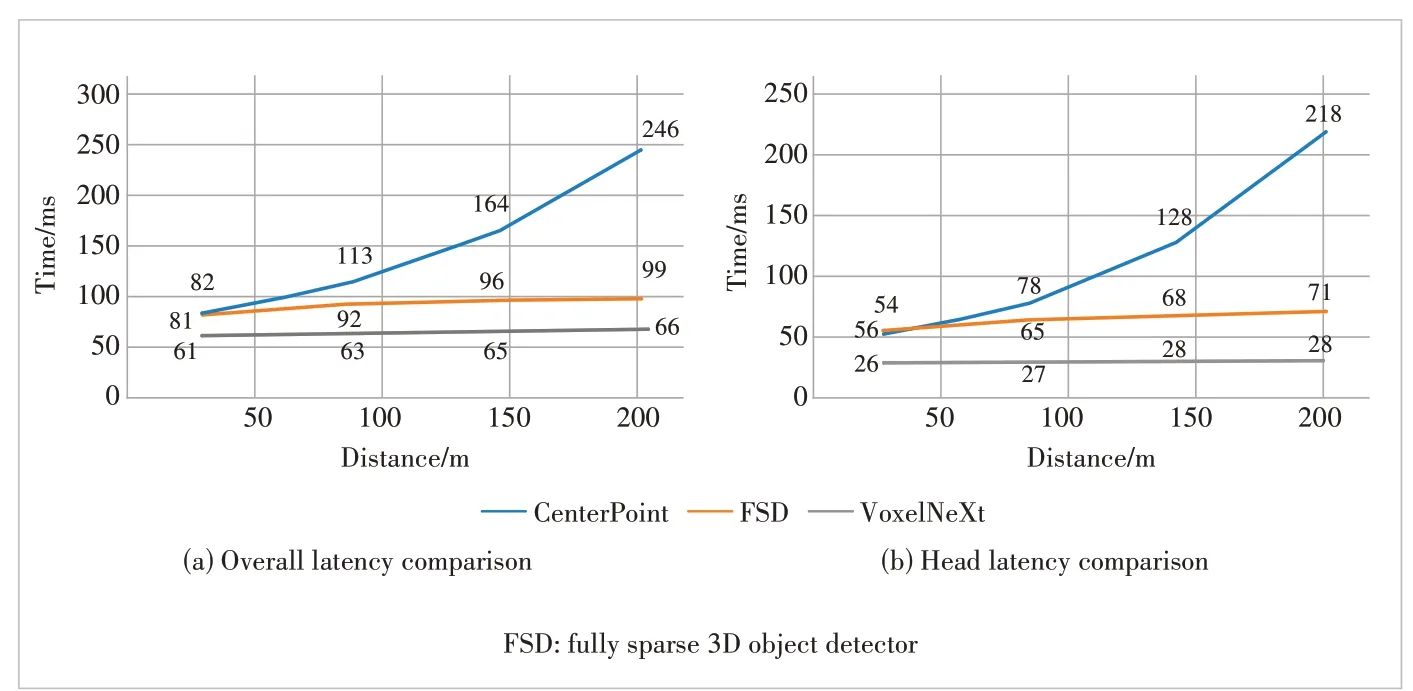
▲Figure 4. Latency on Argoverse2 and various perception ranges
VoxelNeXt shows that fully sparse voxel-based representations are very effective for LiDAR 3D detection and tracking.VoxelNeXt proposed a fully sparse voxel-based network,which uses ordinary sparse convolutional networks for direct prediction. It uses only one extra down-sampling layer to optimize the sparse backbone network, and this simple modification enlarges the receptive field. This simple sparse linkage requires no additional parameterization layers and has a little additional computational cost.
VoxelNeXt places sparse features directly on the BEV plane and then combines features at the same location. It takes no more than 1 ms, but the effect is better than 3D sparse features. VoxelNeXt is entirely voxel-based and continuously clips irrelevant voxels along the down-sampling layer, which further saves computational resources and does not affect detection performance. Using the above-mentioned method to process voxels reduces calculation consumption without degrading performance.
The way of voxelization is not set in stone. For example, the classic Voxel-Net[21]and sparsely embedded convolutional detection (SECOND)[22]divide the point cloud into a voxel to form a regular and dense voxel set, while SECOND uses sparse embedded convolution to improve efficiency.
To make a trade-off between accuracy and computation efficiency, PointPillars converts point clouds into pillars. Specifically, PointPillars divides thexaxis andyaxis of point cloud data into grids, and the data in the same grid is considered as a pillar (Fig. 5). This voxel division method can be considered to divide only one voxel on thezaxis;Pnon-empty columns are generated after division; each column containsNpoint cloud data (more thanNpoints are sampled asNpoints, and less thanNpoints are filled with 0), and each point extracts D-dimensional features.There are nine features in PointPillar,which are (x,y,z,r,xc,yc,xp,yp), wherex,yandzare the 3D coordinates of the point,ris the reflection intensity,xcandycare the distances from the center of the point cloud in the pillar, andxpandypare the offset from the geometric center of the pillar.
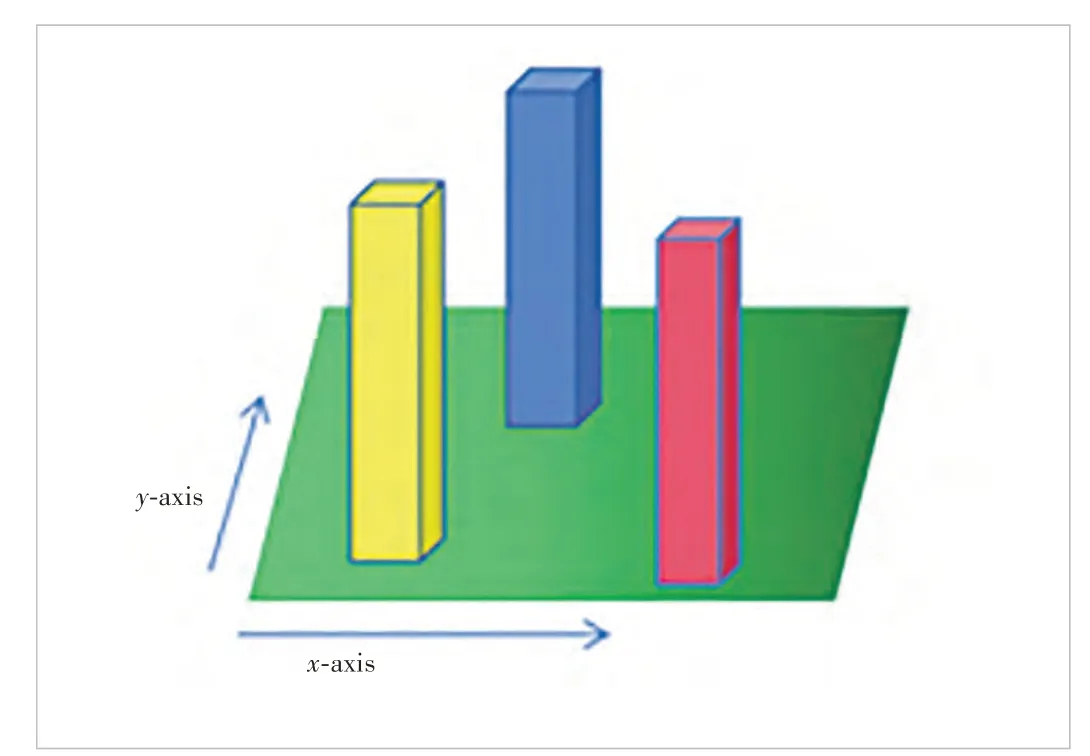
▲Figure 5. Pillar division scheme of PointPillars
In addition to improving the way of voxelization, the use of special data structures can also enhance the detection performance. The Octree-Based Transformer(OcTr)[29]algorithm first performs self-attention on the top level, constructs a dynamic octree on the hierarchical pyramid, and recursively propagates to the lower layer constrained by octants. This method can not only capture rich features from coarse-grained to fine-grained, but also control the computational complexity. Extensive experiments are conducted on Waymo Open Dataset[30]and Karlsruhe Institute of Technology and Toyota Technological Institute (KITTI) Dataset[31], and OcTr achieves new state-of-the-art results.
The performance of different detection models in three categories (Car, Pedestrian, and Cyclist) on the KITTI dataset[31]is listed in Table 1. The voxel-based method can achieve excellent performance by improving the processing method after extracting voxel features. Compared with VoxelNet, SECOND is modified to a sparse embedded convolution method to obtain a performance improvement. PointPillars proposes a way to balance accuracy and computational efficiency. A more appropriate voxel division method can achieve better results.The improvement made by OcTr is to use the transformer and the special octree data structure, which achieves better results. VoxelNeXt directly predicts objects based on sparse voxel features, without the need for sparse-to-dense conversion operations. In summary, voxelization is a method that can process large-scale point cloud data quickly and efficiently.The idea of voxelization is to process the unstructured point cloud into structured data and use the characteristics of CNN to process structured data to extract features from the point cloud. But nothing is perfect. Detailed information may be lost during the voxelization process, and voxelization is a computationally expensive step.
4 Point-Based Point Cloud Processing Methods
The point-based 3D point cloud object detection method is a method to perform object detection on the raw point cloud data. This approach preserves the unstructured form of the point cloud, but achieves a more compact representation by sampling the point cloud from its original size to smaller fixedsizeNpoints. Sampling methods usually include random sampling and FPS, as well as several innovative sampling point methods[32].
Random sampling is achieved by randomly drawing points untilNpoints are selected. But random sampling suffers from the scenario where points in denser regions of the point cloud are sampled more frequently than points in sparser regions of the point cloud. The FPS algorithm can mitigate this bias by using an iterative process to select points based on the furthest distance criterion. In each iteration, FPS first calculates the minimum distance from the unsampled point to the point set (the first point is randomly sampled and the second point is the point furthest from the first point) and then selects the furthest unsampled point .The final result is a more representative point cloud, but this method also suffers from expensive calculation costs.
The effect of PointNet[11]in point cloud-based methods is similar to that of VoxelNet in voxel-based methods. PointNet is a neural network-based approach that directly processes point cloud data for classification and segmentation. Operating directly on the raw point cloud eliminates unnecessary transformations of the data representation.
PointNet is a simple yet efficient point cloud feature extractor. It has three key modules: the symmetry function for unordered input, local and global information aggregation, and alignment network. Key to PointNet is that it can process unsorted point cloud data, when the disorder of point cloud is challenging in point cloud processing.
Based on Pointnet, Pointnet++[12]provides a hierarchical point cloud processing method that can effectively learn the local structure in the point cloud. Pointnet++ can handle more complex tasks such as scene segmentation, shape part segmentation, and 3D object detection.
The key technology of Pointnet++ is the introduction of hierarchical processing. Pointnet++ adopts a layered architecture.The entire point cloud is first sampled and then subdivided into smaller local areas and local features are learned on these local areas (set abstraction). Finally, these local features are aggregated to obtain global features. A Pointnet++ network consists of an encoder and a decoder. The encoder contains a collection abstraction module and the decoder contains a feature propagation module.
These two methods have promoted the application of point cloud data in the field of 3D vision and achieved remarkable research progress. There are also some extended methods[33-35]. Based on the PointNet series network, the feature extraction is directly applied to the original point cloud data.This type of method is generally divided into two steps. The first step is often to propose a rough candidate frame and the second step is to adjust and refine the position of the candidate frame.
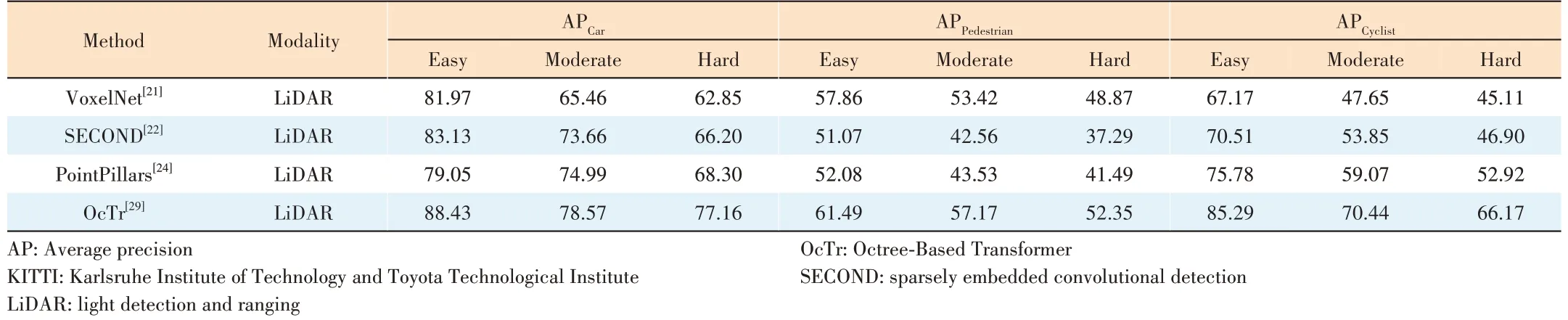
▼Table 1. Performance of VoxelNet, SECOND, PointPillars and OcTr on the KITTI dataset[31]
Down-sampling operations are generally required for point cloud processing. Down-sampling can not only reduce the amount of data, but also remove some noise to improve the quality of point cloud data to a certain extent.
Commonly used point cloud down-sampling methods include random sampling, uniform sampling, furthest point sampling, etc. Different sampling methods have different advantages. Random sampling has the lowest time complexity, but retains relatively few point cloud features. Uniform sampling can preserve the overall distribution of point clouds, but the disadvantage is that it retains fewer point cloud features and cannot retain more detailed information. The advantage of furthest point sampling is that it can retain edge information. It is suitable for large-scale data processing and can quickly complete down-sampling, but it has high time complexity.
1) Improvement of the sampling method. The authors in Ref. [36] propose a lightweight and effective point-based 3D single stage object detector, named 3DSSD and believe that the feature propagation (FP) layer and refining process in the PointNet series methods[33,37-38]will consume more than half of the time, but simply removing these modules and leaving only the set abstract (SA) layer to directly perform a singlestage proposal can result in a decrease in accuracy. They also believe that the down-sampling operation of the SA layer is based on the distance-based furthest point sampling method(D-FPS), which tends to retain background points. Therefore,they propose a new sampling method named F-FPS to filter background points and retain foreground points.
They use both spatial distance and semantic feature distance as the criterion in FPS. It is formulated asC(A,B) =λLd(A,B) +Lf(A,B), whereLd(A,B) is D-FPS,Lf(A,B) is F-FPS, andλis the balance factor. As shown in Table 2, FFPS has the highest recall atλ= 1.0, whereλis the weight of D-FPS and F-FPS. Both the spatial distance and semantic feature distance are the criterion in FPS. In the experiment,3DSSD adopts the method of fusion sampling. The points obtained by the two sampling methods each occupy half. Thepoints are obtained after multi-layer SA as shown in Fig. 6.Then the candidate generation layer and two prediction heads predict the category and bounding box of the objects. 3DSSD greatly improves the speed of 3D object detection, and the speed exceeds 25 fps.
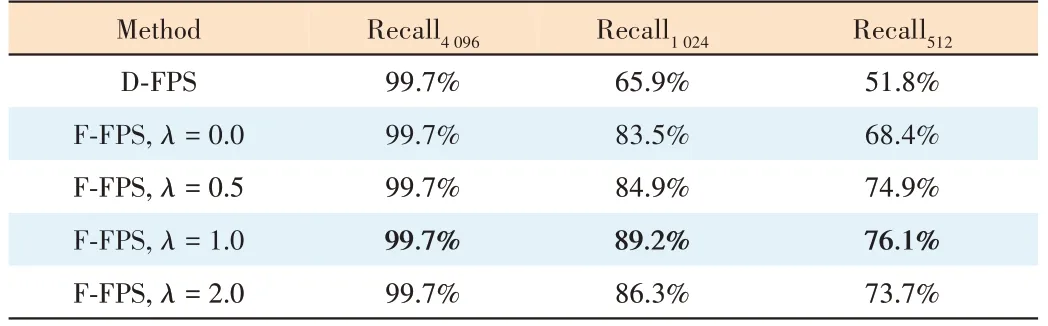
▼Table 2. Points recall among different sampling strategies on the nuScenes dataset. “4 096”, “1 024” and “512” represent the number of representative points in the subset. The first row of results uses only D-FPS.
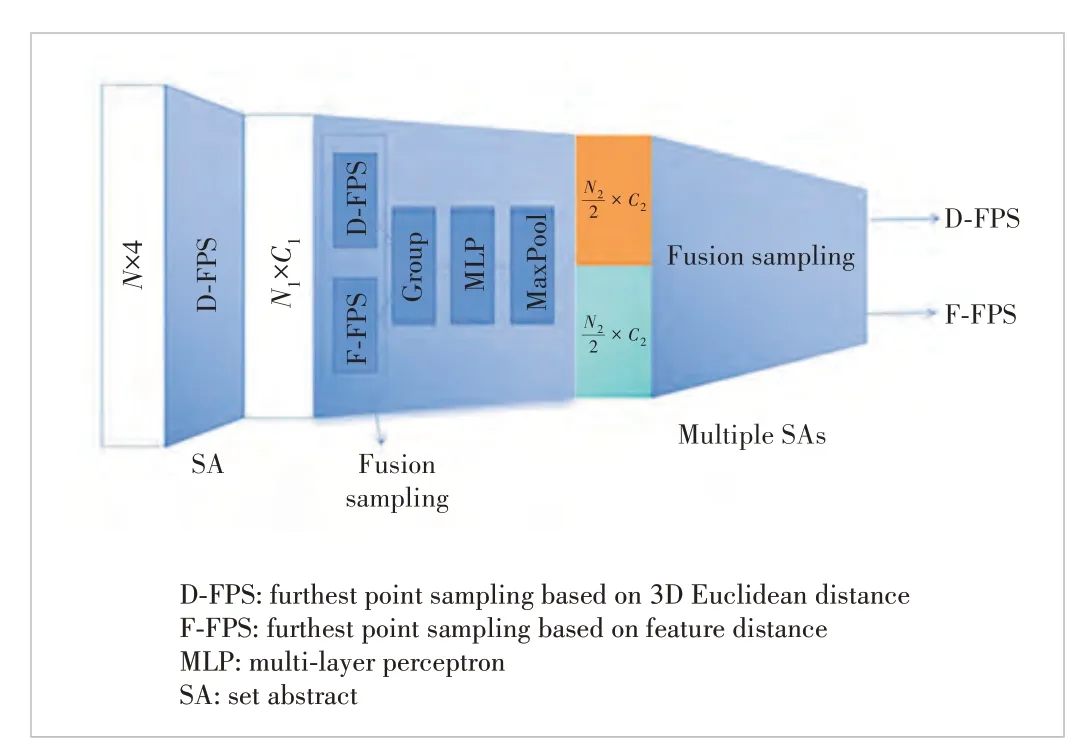
▲Figure 6. D-FPS is first used to down-sample the point cloud once.The point cloud is sampled, grouped, MLP and maximum pooled through the 1:1 combination of D-FPS and F-FPS sampling methods.The point cloud can be sampled multiple times in the same way
2) Combination of point-based and voxel-based methods.There are some special methods that combine point-based and voxel-based methods[38-39]. Since the two methods have different advantages, their combination can bring more advantages.
The 3D object detector (STD)[38]has three main contributions. First, a spherical anchor is used to propose a pointbased proposal generation example, which can achieve a high recall rate. Second, the point-based and voxel-based parts use the PointsPool link to predict efficiency and effectiveness,combining the advantages of VoxelNet[21]and PointNet[11].Last, the alignment between classification scores and localization is achieved through a new 3D IoU prediction branch.
Point-voxel feature set abstraction for 3D object detection(PV-RCNN)[39]is a high-performance 3D object detection framework. It integrates the method of point-cloud voxelization and convolution and the method of PointNet-based set abstraction to obtain better point cloud features. PV-RCNN directly uses the original point cloud, processes the point cloud through 3D sparse convolution after voxelization and performs classification and box prediction through RPN on the BEV plane. At the same time, the FPS is used for key point sampling, and the key point features and the features of nonempty voxels around the key points are collected through the VSA module. These features are used to make up for the information loss during voxelization. Object category and bounding box predictions are refined through a two-part combination.
Both PV-RCNN and STD have achieved good results on the KITTI dataset (Table 3), and their performance outperforms either the voxel-based or point-cloud-based method used alone,demonstrating the benefits of combining these two complementary methods.
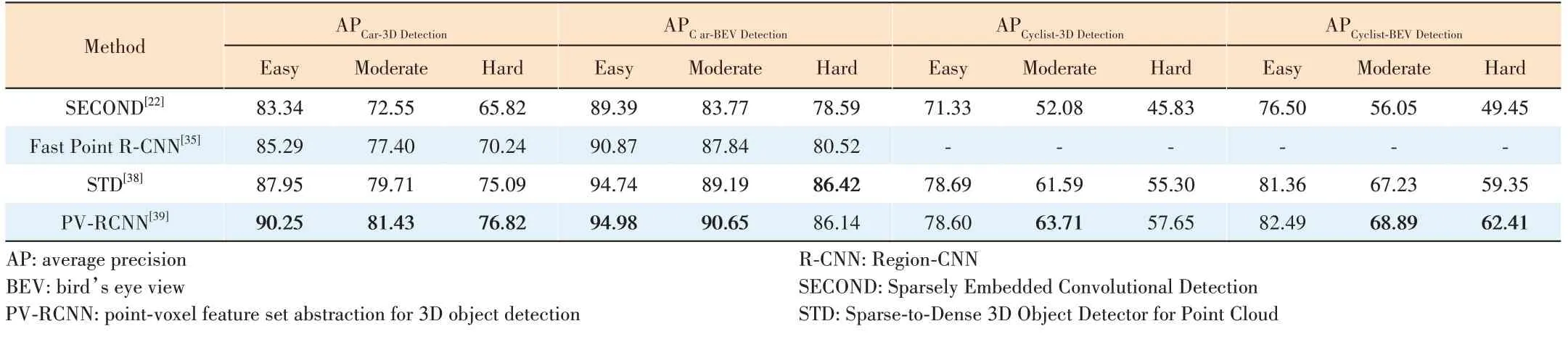
▼Table 3. Performance testing on the KITTI test set. Mean average precision is taken as the evaluation metric. The table shows better performance of PV-RCNN and STD
Besides STD and PV-RCNN, the methods proposed in Refs.[40] and [41] also combine the point-based and voxel-based manners.
Some methods use other networks such as graph neural networks (GNNs). They convert the point cloud into a regular grid or voxel and use CNN (point cloud representation in the grid)or deep learning technology to process the point cloud (point cloud in the point set) after obtaining the point set through sampling and other operations (Fig. 7). In addition, Point-GNN[42]constructs the point cloud into a graph. It has three main components: graph construction from point cloud, graph neural network for object detection, and bounding box merging and scoring. Specifically, the points in the point cloud are used asNvertices, with a point as the center andras the radius. Neighboring points in the range are concatenated to construct a graphG= (P,E), for example:
In order to reduce complexity, Point-GNN uses voxel operations to down-sample point clouds in the actual process and the voxels are only used for reducing the point cloud density.Once constructed, the point cloud is processed using a multiiteration GNN[43].
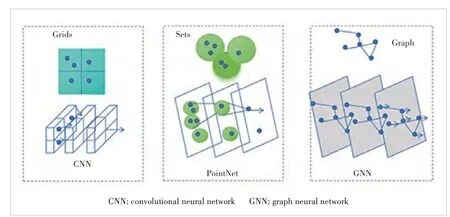
▲Figure 7. Representation of point-cloud grids, sets and graph and their corresponding processing methods
Point-GNN has achieved excellent performance on the KITTI test data set. The average precision of the car, pedestrian and cyclist at the easy level reached 88.33, 51.92 and 78.60, respectively, at the modality levels 79.47, 43.77 and 63.48, respectively, and at the hard level 72.29, 40.14 and 57.08, respectively. The detection performance of the car and cyclist surpasses both the radar-only methods such as STD[38]and PointRCNN[33]and the radar and image fusion methods such as AVOD-FPN[44]and UberATG-MMF[45].
The point-based methods still have several modules that need to be improved. One module is sampling, which can reduce the consumption of computing resources by selecting a subset of points from the original point cloud. However, sampling may cause some information loss, which affects the quality of the features that can be extracted in subsequent operations. Therefore, the choice of the sampling algorithm is crucial for the point-based method. For example, Point-Net++ uses feature propagation to suppress the information loss caused by sampling, and 3DSSD improves different sampling methods to retain more useful information and improve efficiency.
Another module that can be improved is voxelization, which is a special method to introduce voxels into point cloud processing. Voxels are small cubes that divide the three-dimensional space and contain a certain number of points. The advantage of voxelization is to convert point clouds into ordered data and also reduce computational complexity. However, voxelization may introduce quantization errors and lose some fine-grained details.Therefore, some methods combine the information obtained from both voxels and points to improve performance. For example, PV-RCNN uses voxel-based RPN and point-based RoI feature extractors(RoIFEs) to achieve state-of-the-art results on 3D object detection.
The third module that can be improved is the basic network model, which is used to process the point cloud data and extract features. Different network models have different advantages and disadvantages for point cloud processing. For example, GNN can capture the structure and relationship of point cloud data by using nodes and edges. It can handle irregular and unordered data better than convolutional neural networks.
5 Conclusions
In this paper, we summarize the processing of point clouds in object detection. Point cloud processing is the first step in most models and it can greatly affect the performance of subsequent detection operations. Point cloud processing can be divided into two categories: voxel-based and point-based processing, both of which have their own advantages and disadvantages.
Voxel-based processing is a method that divides the threedimensional space into small cubes called voxels and assigns points to voxels according to their coordinates. The advantage of voxel-based processing is that it can convert point clouds into ordered data and reduce computational complexity. However, voxel-based processing may introduce quantization errors and lose some fine-grained details. Many works have improved voxel-based methods by changing the way voxels are divided, changing the network for processing voxels, changing the data structure for processing data, etc. These approaches can reduce time complexity and organize voxel-level features well, further improving performance.
Point-based processing is a method that directly operates on raw points without any transformation or quantization. The advantage of point-based processing is that it can preserve the original structure and information of point clouds. However,point-based processing may face challenges such as irregularity and sparsity of point clouds. Many works have improved point-based methods by improving the way of point cloud sampling, introducing some voxel-based features or directly obtaining the graph structure from the structure of the original point cloud data. These approaches can enhance the feature extraction and representation of points, which can also significantly improve the performance of subsequent detection.
杂志排行

ZTE Communications的其它文章
- Perceptual Quality Assessment for Point Clouds : A Survey
- Spatio-Temporal Context-Guided Algorithm for Lossless Point Cloud Geometry Compression
- Lossy Point Cloud Attribute Compression with Subnode-Based Prediction
- Perceptual Optimization for Point-Based Point Cloud Rendering
- Local Scenario Perception and Web AR Navigation
- Research on Fall Detection System Based on Commercial Wi-Fi Devices