采用局部子图嵌入的MOOCs知识概念推荐模型
2024-01-11居程程
居程程,祝 义,3+
1.江苏师范大学 计算机科学与技术学院,江苏 徐州 221116
2.江苏省教育信息化工程技术研究中心,江苏 徐州 221116
3.高安全系统的软件开发与验证技术工业和信息化部重点实验室(南京航空航天大学),南京 211106
近年来,伴随着现代信息技术的迅猛发展,以人工智能为代表的新兴技术在教育领域得到了广泛应用,引发了学习理念和方式的深刻变革。在这种大背景下,MOOCs(massive online open courses)超越了时空的限制,得到了蓬勃发展,为学习者“随时随地”学习提供了更多的可能性[1-2]。
然而,随着课程资源共享平台的不断增加,网络共享资源的数量逐年稳步增长,在线课程的整体完成率却通常低于7%[3-5]。其中导致辍学率居高不下的主要原因是在线学习平台忽视了“以学习者为中心”的现代教学理念,不能根据用户的个性化需求准确提供学习资源[6]。为此,相关研究大多集中在了解辍学或拖延行为[1,7-10],或推荐用户可能感兴趣的课程和学习路径等内容[11-16]。
但课程涵盖了一系列视频,其中每个视频都与一些知识概念相关联,课程或视频推荐忽略了用户对特定知识概念的兴趣。不同教师的课程在微观上可能会有很大差异,可能会从不同的角度教授这些知识概念,用户可能会对不同教师的各种视频片段或学习材料产生不同的兴趣。因此,从更细粒度的角度了解用户的学习需求并预测用户可能感兴趣的知识概念对课程资源推荐任务来说非常重要[17-19]。
目前较为流行的有基于协同过滤的推荐方法,根据用户的相似度或者课程内容的相似度进行资源推荐[11-13,20-22]。其优势在于不需要太多特定领域知识,易于实现,但无法解决数据稀疏问题,过度偏向推荐热门资源。另一种较为流行的是基于矩阵分解的方法[13,23-26],在协同过滤的基础上加入了隐向量,一定程度上增强了模型处理稀疏矩阵的能力,但不易添加用户、课程资源之间的上下文关系信息。
为能够利用更多有效信息,相关研究引入了异构图。在课程资源推荐任务中,用户、课程资源等实体及其关系被建模为异构图,上下文信息得到有效利用,课程资源推荐效果得到显著提升[17-19]。然而,基于图卷积算法需要在训练期间对全图拉普拉斯算子进行操作,即假设预测与训练节点(用户和知识概念类型实体)在一个图中,要求在训练过程中图上所有节点都已被考虑进去[27]。需要大量的计算成本和内存,将其应用到大图是不可行的。此外,由于它们在一个固定的图上直接生成最终的节点嵌入,图的结构稍微有所变化,就需要重新训练[28]。
基于上述问题,本文提出了一个端到端模型Mooc-Sage(massive online open course sampler and aggregate),用于MOOCs 课程资源推荐中的知识概念推荐。通过构建异构图引入实体间丰富的上下文关系信息,缓解数据稀疏问题。为充分挖掘不同类型实体间丰富的语义关系,将异构图分解为用户/知识概念相关的多个基于元路径的子图,每个子图关联特定的语义和结构信息。采用随机游走算法在子图上采样富有影响力的局部邻域,并在局部邻域上进行图卷积平滑各节点表示,实现高可扩展性。不同的子图对用户/知识概念来说可能有不同的重要性,使用注意力机制自适应地融合不同子图下用户/知识概念的图嵌入表示[29]。最后,通过扩展矩阵分解优化模型参数,获得推荐列表[30]。在公开的MoocCube 数据集[31]上进行了综合实验,用以评估MoocSage 的性能。与目前最先进的基线方法相比,MoocSage 的有效性得到了全面的证明,可以高效地为用户推荐感兴趣的课程资源。
本文的主要贡献可概括如下:
(1)提出了一种端到端的基于图采样聚合的归纳式推荐算法,有效利用丰富异构上下文信息辅助知识概念推荐的同时大幅减少现有方法过多的计算资源需求。
(2)构建了一个与推荐任务相关的异构信息网络,可有效捕获MOOCs 平台中不同类型实体之间的复杂交互信息。
(3)扩展了基于随机游走的采样方法,在多个元路径的引导下以注意力的方式传播用户的偏好并发现用户的潜在兴趣。
(4)使用公开的MoocCube 数据集进行大量实验,全面评估了所提出模型的性能,与一系列强基线相比,综合证明了所提出模型的有效性。
1 相关研究
1.1 基于矩阵分解的推荐
从直观上看,矩阵分解就是将评分矩阵近似分解为两个低维矩阵的乘积,分别表示用户与物品的隐语义,其假设实际的交互数据是在一系列隐变量的影响下产生的。文献[13]提出将非负矩阵分解应用于主题建模来寻找用户之间的相似性以进行基于内容的过滤,向用户推荐感兴趣的课程资源。文献[23]考虑到成绩容易受到学术特征的影响,将学生和课程按照特征划分为多个组,结合基于邻域的用户协同过滤、矩阵分解和基于流行度的排名方法设计成绩预测和Top-k课程资源推荐模型,帮助学生选择合适的课程。文献[25]提出了一种新的基于概率的邻域方法,作为标准的K 近邻方法的进一步改进,缓解了协同过滤推荐系统的一些最常见的问题,分析研究用户对在线课程的满意度与学生保留率的关系。文献[26]基于矩阵分解模型,结合协作过滤算法,利用外部资源的信息(用户、课程特征)预测用户对课程的偏好,并根据偏好程度进行评分预测。文献[24]针对学生难以在日益拥挤的课程论坛中寻找有用主题这一挑战,基于自适应特征的矩阵分解框架,提出线程推荐用以解决线程过载问题,向学生推荐他们可能感兴趣的主题。这些方法在一定程度上能够增强模型处理稀疏矩阵的能力,但不易添加用户、课程资源和上下文关系信息。
1.2 基于异构图推荐
异构图多用于表征推荐任务中复杂、异构的数据,使得丰富的上下文信息得到有效利用,进一步缓解数据稀疏问题。文献[30]提出了一种基于异构图嵌入的推荐方法(heterogeneous network embedding based recommendation approach,HERec)。HERec 在元路径的基础上使用随机游走策略生成节点序列,将所生成的节点序列作为语料输入到Skip-gram[32]模型进行用户和项目的嵌入表示。考虑到不同元路径下的嵌入表示存在不同的语义信息,HERec 将不同元路径的嵌入表示进行加权融合,将融合后的实体的嵌入表示馈送到扩展矩阵做预测评分任务。HERec 整合异构信息网络(heterogeneous information network,HIN)中的各种嵌入信息,增强推荐性能,但受限于Skip-gram模型,仅能聚合有限的邻域信息。文献[17]提出一种基于图卷积注意力异构图深度知识概念推荐模型(attentional heterogeneous graph convolutional deep knowledge recommender,Ackrec),用于MOOCs中的知识概念推荐,Ackrec 将推荐问题视为评分预测任务,其中用户对知识概念的评分为用户和概念之间的交互次数。Ackrec 通过图卷积网络学习实体的表示,在元路径的指导下传播用户偏好,使用扩展矩阵分解进行课程资源评分推荐。Moocir(Mooc interest recommender)[19]在Ackrec 的基础上进行了改进,提出并研究了不同的注意力机制与目标函数,将评分预测改为点击预测,提升了推荐效果。Ackrec与Moocir 在一定程度上缓解了数据稀疏问题,实体内容信息与实体间的上下文信息得到了有效利用,但受限于图卷积算法,需要极高的计算成本,将其应用于大图是不可行的。
1.3 大规模推荐
针对传统的图卷积算法无法扩展到大规模推荐这一问题,PinSage(pinterest sample and aggregate)[33]使用单个节点多次短随机游走的方法进行节点采样,根据L1-范数选取目标节点的重要邻居节点,动态构建计算图进行局部的图卷积,实现Pinterests 上大规模item2item 推荐,具有高度可扩展性,能够适配数十亿节点和数百亿边的网络。PinnerSage(pinner sample and aggregate)[34]利用从PinSage 中得到的物品表示,将用户较长时间内交互过的物品表示聚成若干类,检索每一类表示的最近邻表示,融合作为用户的表示,实现Pinterests 上大规模user2item 推荐。Pinterest 包含丰富的图像和文本信息,各实体间关系隐式地包含在实体的内容特征中,仅使用user-item的交互信息就能得到很好的推荐效果。但其他传统推荐数据集,通常只有各实体名称信息、类别信息,仅考虑user-item 的交互容易受到数据稀疏性问题的影响,无法进行有效推荐。
针对以上问题,本研究通过构建异构图引入用户、课程资源之间的上下文关系信息,将异构图分解为多个子图,扩展随机游走算法并结合图采样聚合方法捕获丰富的异构邻域信息,以注意力的方式适应性融合不同子图下的嵌入表示,缓解数据稀疏问题的同时具有较强的可扩展性。
2 问题陈述与模型架构
2.1 问题陈述
本文基于这样一种假设:兴趣偏好相同的用户或存在相连关系的知识概念彼此间有着相似的表示,在嵌入空间的位置更为邻近。理论上,各实体根据自身特征(用户信息/知识概念信息)进行嵌入表示后,结合实体间上下文关系信息进行平滑处理,可使得存在相连关系的实体存在相似表示。具体如图1所示。

图1 问题陈述Fig.1 Problem statement
拟解决的问题:给定各用户在MOOCs 上的历史交互记录及MOOCs 中各实体间的关系信息,计算用户对各知识概念的偏好分数,为用户推荐可能感兴趣的知识概念,保持高推荐性能的同时降低计算资源需求。具体来说,根据用户(User,u)的历史交互记录(例如,u302750:“地址解析”“数据传输”)及所涉及到的相关实体间的上下文关系信息(例如,网络技术与应用),训练预测函数f用于为u进行Top-k知识概念推荐(例如,“Ip 地址”“单播”),f:u→{ki|ki∈K}。
2.2 模型架构
本研究提出的知识概念推荐模型MoocSage 的架构如图2所示。由以下子模块组成:
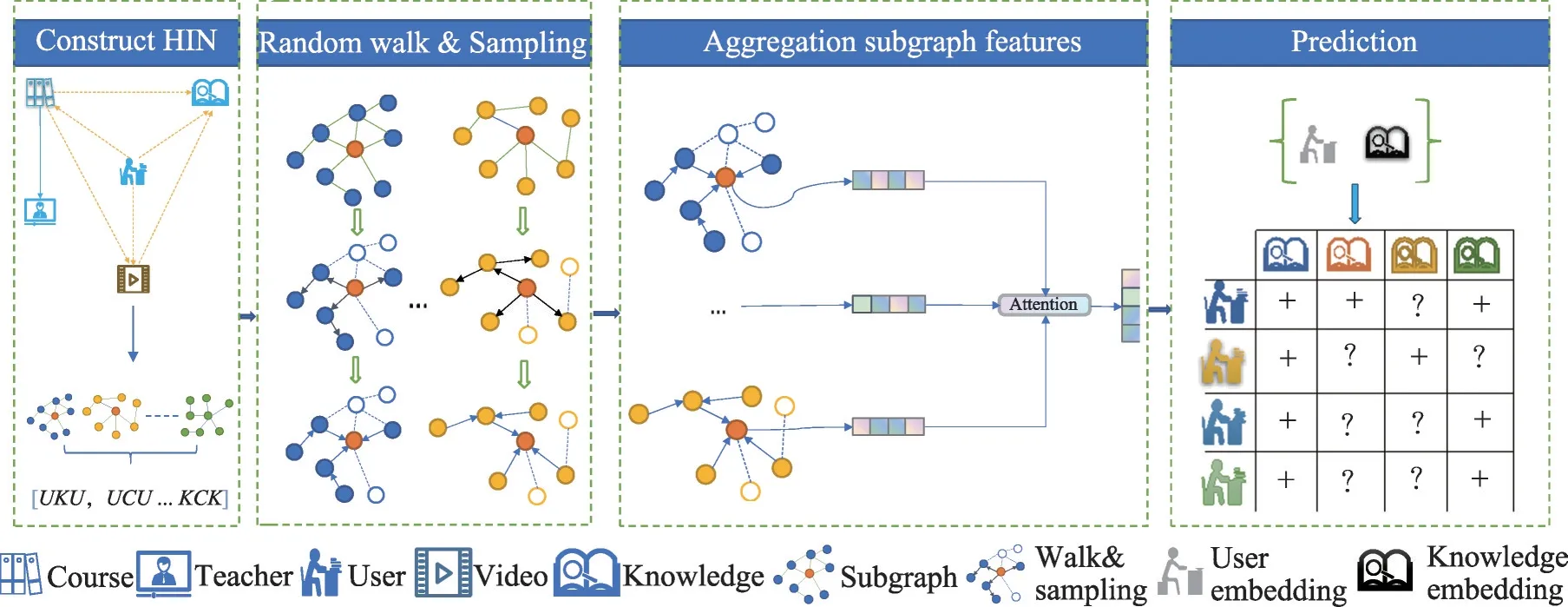
图2 MoocSage模型架构Fig.2 MoocSage model architecture
(1)构建异构图:提取实体特征,通过实体及各实体间关系构建异构图,根据所构建的异构图选择有效元路径用以描述实体之间的上下文关系,基于元路径将异构图分解为多个子图。
(2)逐层游走聚合特征:在各子图中操作局部图卷积进行多层邻域信息聚合,平滑邻接节点表示。
(3)组合子图特征:每个子图关联特定的语义和结构信息,基于不同子图可得出目标实体的各种表示。不同的子图对用户/知识概念类型实体来说可能有不同的重要性,使用注意力机制自适应地融合来自不同子图的实体表示。
(4)预测评分:在生成用户/知识概念类型实体的低维表示后,通过扩展矩阵分解优化模型参数,获得推荐列表。
3 主要方法
3.1 构建异构图
本节将详细介绍如何提取实体内容特征、选择上下文信息,如何学习知识概念和用户类型实体表示,以及如何基于学习到的实体表示进行知识概念推荐。
3.1.1 实体内容特征
在课程资源推荐任务中,用户类型实体属性存在一定的缺失。针对这个问题,本研究使用Metapath2vec[35]模型进行各实体的预训练嵌入,最大化不同实体表示的差距,将对比学习结果作为实体的内容特征,如图3所示。

图3 预训练实体内容特征Fig.3 Pre-training entity content features
3.1.2 实体间上下文关系
除了实体自身内容特征外,实体间还存在着丰富的异构信息,为了有效利用这些不同实体类型间的上下文信息,缓解数据稀疏问题,在用户学习活动中考虑以下关系:
Mu-c:用户-学习-课程(course,c)邻接表,用于描述用户和课程类型实体之间的关系,邻接表中每个交互对[ui,ck]表示用户i学习过课程k。
Mu-v:用户-观看-视频(video,v)邻接表,用于描述用户和视频类型实体之间的关系,邻接表中每个交互对[ui,vk]表示用户i观看过视频k。
Mc-kc:课程-包含-知识概念(knowledge concept,kc)邻接表,用于描述课程与知识概念类型实体之间的关系,邻接表中每个交互对[ci,kck]表示课程i包含知识概念k。
此外,为了使上下文关系更为紧密,缩减随机游走采样时间,在原有关系的基础上,添加了多跳上下文关系,例如用户与知识概念类型实体间的多跳关系由用户与视频类型实体之间、视频与知识概念类型实体之间的关系组合而成。
Mu-kc:用户-学习-知识概念邻接表,用于描述用户和知识概念类型实体之间的关系,邻接表中每个交互对[ui,kck]表示用户i在学习过程中点击了知识概念k这一活动。
Mu-t:用户-学习-课程-教师(teacher,t)邻接表,用于描述用户和教师类型实体之间的关系,邻接表中每个交互对[ui,tk]表示用户i学习过k老师教授的课程。
基于以上关系构建MOOCs 网络模式[36],如图4所示。

图4 MOOCs网络模式Fig.4 MOOCs network model
3.1.3 元路径选择
定义1(异构信息网络)异构信息网络也被称为异构图,是一种特殊的图[30]。如G=(V,E),其中V和E分别表示节点与边的集合。此外,异构信息网络存在节点类型映射函数φ:V→A与链接类型映射函数φ:E→R,A和R表示异构图中节点与链接类型集合,且|A|+|R| >2。示例见图5。

图5 MOOCs异构信息网络Fig.5 Example of MOOCs heterogeneous information network
定义2(元路径)元路径(meta-path,mp)代表异构图中各节点间的复合关系[37],定义为(简写为A1A2…Al)形式的对象序列,表示节点类型A1与节点类型Al之间的关系组合。在本研究中,A1与Al代表同一类型。基于元路径构建子图,即从异构图分离出包含特定语义的子图,其上所有实体类型、实体间关系与元路径描述一致。如图6给出的示例。
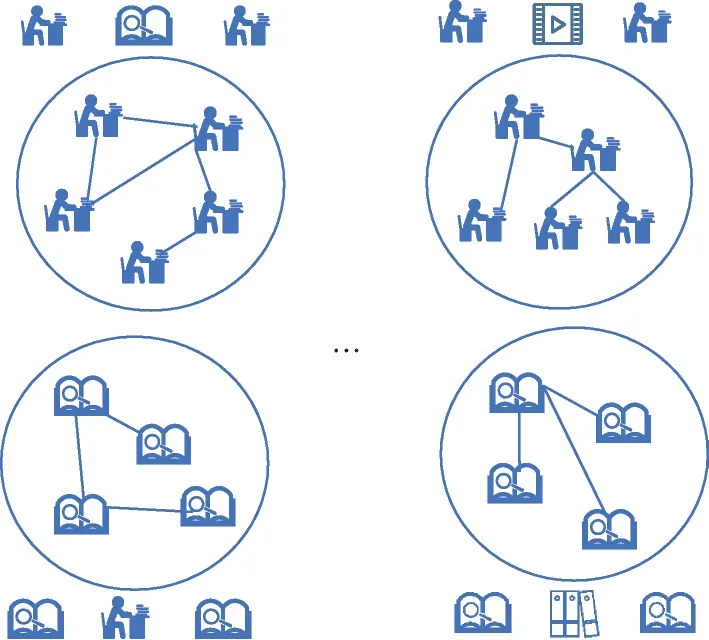
图6 基于元路径的子图Fig.6 Subgraph based on meta-paths
具体来说,描述不同用户观看同一视频关系的元路径可以定义为,在该路径的指导下从包含多个类型节点的异构图5 中分割出拥有特定语义的子图。比如u1与u2在该子图上存在链接关系,可以表示为,子图的语义表述为u1与u2观看过同一个视频v6,代表u1与u2在图结构上存在着相似性。原异构图中包含用户、课程、知识概念等多种类型实体,而分离出的子图仅包含用户类型实体,图上实体间连接关系为观看过同一视频。
基于元路径构建子图旨在通过构建子图减少运算规模,降低图卷积所需计算资源。此外,将原有异构图分解为多个包含特定语义的同构图,能得到更有意义的实体嵌入[38]。

图7 子图采样聚合Fig.7 Subgraph sampling aggregation
3.2 子图游走采样聚合
本研究在PinSage 的基础上进行了改进,采用元路径的指导的方式对各目标节点进行多次短随机游走,根据L1-范数选取目标节点的重要邻居,构建相关子图。具体流程如算法1所示。
算法1SubgraphSample
使用局部卷积模块为子图中节点生成嵌入方式进行目标节点的邻域信息聚合。节点表示取决于节点的输入特征与该节点周围的图结构信息,使用图卷积平滑各节点表示,缓解数据稀疏问题。具体流程如算法2所示。
算法2SubgraphAgg
图神经网络最初是为图分类任务而设计的,特征转换、非线性激活等神经网络操作可能对推荐任务贡献较小[39]。基于此,本研究在PinSage 提出的局部卷积算法的基础上进行了改进,去除了非线性激活函数,但考虑到输入节点包含丰富的内容特征,保留了矩阵特征变化,用于特征提取。
对每个目标节点v,首先使用聚合函数AGGREGATE聚合邻域节点信息,具体来说,聚合函数AGGREGATE根据相邻节点权重α进行邻域特征集合的加权求和,结果表示为节点v的邻域表示hN(v)。其次将hN(v)与目标节点v的特征hv进行拼接,并通过矩阵变化进行特征提取,最后进行归一化操作,即生成包含了节点v自身以及节点v局部图邻域的嵌入表示zv。
每应用一次邻域卷积聚合操作(算法2),会得到新的节点表示,堆叠多个卷积,可获得关于目标节点v的多阶局部邻域信息。如卷积层数k=2 时每个节点可以最多根据其2 阶邻接点的内容信息学习更新自身的嵌入表示。子图局部卷积过程见图7。
3.3 聚合子图特征
不同子图生成不同的节点表示,使用注意力机制自适应地融合来自不同子图的实体表示。聚合子图过程可见图7。不同的子图对于每个用户/知识概念可能具有不同的权重,在聚合来自不同元路径的用户/知识概念表示时,对每个用户/知识概念区分不同元路径的重要性进行加权合并是非常有必要的。在本研究中,将使用如下的注意力计算机制计算用户/知识概念对不同子图的注意力得分:
3.4 预测评分
在使用注意力机制学习到知识概念与用户的最终表示Zkc与Zu后,使用扩展矩阵分解的方法计算偏好分数为用户进行知识概念推荐。预测评分过程可见图7。
用户u关于知识概念kc的偏好分数可以通过如下的扩展矩阵分解框架计算:
本研究使用BPR(Bayesian personalized ranking)进行模型的优化,基于假设:相比较于用户未与之交互的知识概念列表中的随机知识概念,用户已经学习过的知识概念应该得到更高的分数。BPR 的损失函数表述如下:
其中,(u,i,j)为一个三元组,包括用户u、正样本i(已交互知识概念)和负样本j(随机选取的知识概念)。通过计算用户在正样本和负样本之间的偏好差异,σ表示sigmoid 函数,λ是L2 范数的正则化参数,Θ表示要学习的参数集。
算法3mini-batch训练方法
4 实验
4.1 数据集
本研究使用来自XuetangX平台提供的MoocCube数据集[31]进行实验。在这项工作中,使用文献[19]所提供清洗后的MoocCube 小规模数据集(Mooc-Cube_small,MoocCube_s)进行推荐性能对比实验。其次使用MoocCube 大规模数据集(MoocCube_big,MoocCube_b)进行补充实验,进一步体现模型的泛化性能及其在资源利用率方面的优势。其中2017-01-01 到2019-10-31 的用户活动用于训练,2019-11-01 到2019-12-31 的用户活动用于测试。MoocCube_s 数据集总计2 005 个用户、210 037 个知识概念、600 门课程、22 403 个视频、138 位教师以及这些不同类型实体之间的关系。用户和知识概念之间总共有930 553次交互,858 072次交互作为训练集,剩余72 481次作为测试集。MoocCube_b 数据集总计17 877 个用户、24 289 个知识概念、649 门课程、29 379 个视频、1 599位教师以及这些不同类型实体之间的关系。用户和知识概念之间总共有7 625 850 次交互,5 944 187 次交互作为训练集,剩余1 681 663 次作为测试集。数据集的统计数据如表1所示。

表1 MoocCube数据集统计Table 1 Statistics of MoocCube dataset
4.2 评估指标
本研究使用如下常用的推荐系统评估指标评估模型性能。命中率(hit rate,HR),一个基于召回的指标,用于反映推荐序列中是否包含了用户真正点击的知识概念,强调预测的准确性。归一化折损累计增益(normalized discounted cumulative gain,NDCG),一个用来衡量排序质量的指标,用于反映排序列表与用户真实交互列表的差距。平均倒数排名(mean reciprocal rank,MRR),用于反映用户真正点击的知识概念是否在推荐列表更靠前的位置。ROC 曲线下面积(area under curve,AUC),用于反映模型的相对排序能力,即评估正样本是否排在负样本之前。具体来说,为测试集中每一组用户-知识概念交互随机抽样分配99 个负实例,使用各个模型输出各组100个实例的预测分数(1个正例外加99个反例),根据预测分数大小倒序生成推荐列表表示推荐列表中排名第i位的知识概念,k设置为10、20。
N是用于测试的集合总数,Tu表示正样本,即用户真实点击的知识概念,I(x)是一个指示函数,如果Tu出现在推荐列表中I(x)=1,否则I(x)=0。
式中,Z为idcg(idea discounted cumulative gain)。
式中,ranki是指正样本即已交互知识概念在推荐列表中的排名位置。
式中,m、n分别为正负样本数。
4.3 模型参数分析
首先,研究邻居节点数量的设置。实验结果如图8 所示。本研究设置了不同邻居节点数量(50、100、150、200)进行实验,发现当邻居节点数量为100可获得最佳性能。

图8 不同邻居节点数量下的性能表现Fig.8 Performance of different number of neighbor nodes
其次,研究采样聚合层数如何影响模型的性能。如图9 所示,所提出模型的性能随着层数(即1、2、3、4)的不同而变化。实验表明,采样聚合层的最佳数量约为3。

图9 不同卷积层数下的性能表现Fig.9 Performance of different number of convolutional layers
再次,研究节点采样次数如何影响模型的性能。如图10 所示,所提出模型的性能随节点采样次数(500、1 000、1 500、2 000)的不同而变化。实验表明,采样次数1 000即可取得较好效果。

图10 不同采样次数下的性能表现Fig.10 Performance of different number of walks
最后,研究dropout 如何影响模型的性能。如图11 所示,所提出模型的性能随dropout 大小(0.1~0.9)的不同而变化。实验表明,dropout大小为0.5 时取得最佳效果。

图11 不同dropout大小下的性能表现Fig.11 Performance of different dropout
4.4 模型变体
为更好地理解和研究MoocSage 中各模块的贡献,比较MoocSage 变体,以验证所提出模型的主要组成部分的有效性。MoocSage 使用自适应矩估计(adaptive moment estimation,Adam)优化器。
MoocSage-a:MoocSage 的变体,移除attention层,以拼接的方式融合各节点在不同子图下的表示。
MoocSage-b:MoocSage 的变体,使用Moocir 提出的注意力机制,即在计算注意力得分时考虑用户、知识概念的潜在特征。
MoocSage-c:MoocSage的变体,在局部卷积模块中保留非线性激活函数。
MoocSage-d:MoocSage 的变体,使用随机梯度下降(stochastic gradient descent,SGD)优化器。
MoocSage-e:MoocSage的变体,采用手工处理方法解决用户属性缺失问题[17-19],将知识概念的名称作为语料,使用Word2vector[32]进行知识概念类型节点的表示学习,用户向量为用户所点击的知识概念向量的平均值。
MoocSage-f:MoocSage的变体,去除矩阵特征变化操作,使用拼接的方式融合目标节点自身与邻域信息。
4.5 元路径选择
由异构信息网络引出的潜在元路径可能是无限的,但并不是每条元路径都与特定任务相关。因此,本研究使用文献[40]中所提方法进行元路径的选择,将路径选择问题表述为:给定一组预定义的候选元路径集MP={mp1,mp2,…,mpl},选择一个路径子集MPselected⊆MP,使得任务的泛化性能最大化。通过分析异构信息网络各实体间关系,本文选择元路径{UKU,UCU,UCTCU,UVU}来表征用户对之间的相关性,选择{KUK,KCK}表征知识概念对之间的相关性。具体来说,给定预定义的候选元路径集MP={mp1,mp2,…,mpl},研究用户相关元路径及其组合的性能。如表2所示,各元路径表现出不同的推荐性能。其中单条元路径表现最佳的是元路径{UCU},其次是 元路径{UVU}、{UKU},最后是 元路径{UCTCU}。多条元路径组合方面,路径子集{UKU,UCU,UCTCU,UVU} 综合表现最佳。故本文选择路径子集{UKU,UCU,UCTCU,UVU}进行相关实验。

表2 MoocSage在不同元路径集上性能对比Table 2 Performance comparison of MoocSage on different meta-path sets
4.6 基线模型
本研究与以下基线进行比较,用以评估MoocSage的性能。
Node2vec[41]:综合考虑深度优先搜索邻域和广度优先搜索邻域的图嵌入方法。采用有偏的随机游走采样顶点的近邻序列,优化的目标是给定每个顶点条件下,最大化其近邻顶点出现的概率。Node2vec最初是为嵌入同构图而设计的,本研究忽略节点与边的异构性,在整个异构图上运行随机游走采样语料,用于训练各节点嵌入。
Metapath2vec[35]:基于元路径的表示学习方法,与Node2vec不同的是它利用基于元路径的随机游走来构建节点的异构邻域,以此进行节点嵌入的学习。
Bpr[42]:矩阵分解方法,以贝叶斯方式优化推荐任务的成对排名损失。
Ackrec[17]:基于图卷积的协同过滤算法。将MOOCs数据建模为异构图,使用元路径进行用户(知识概念)的向量表示。
Moocir[19]:基于图卷积的协同过滤算法。在Ackrec的基础上提出并研究了不同的注意力机制与目标函数,构建隐式反馈模型。
PinSage[33]:基于图采样聚合的协同过滤算法,结合了随机游走与图采样聚合生成节点的嵌入表示向量。同时考虑了图结构和节点的特征信息。
Ngcf(neural graph collaborative filtering)[43]:基于图卷积的协同过滤算法,显式建模user-item 间高阶连接性,旨在将user-item 的交互信息集成到Embedding中,完成二部图上的高阶连通性表达建模。
Lightgcn(light graph convolution network)[39]:基于图卷积的推荐算法,在Ngcf 的基础上移出非线性特征变换,保证预测精准度的同时加快了运行速度。
UltraGCN(ultra graph convolution network)[44]:基于图神经网络的推荐系统核心在于通过消息传播机制收集信息,Lightgcn 这类多层卷积堆叠的方式可能会引入噪声、有歧义的关系,易引发过度平滑效应。UltraGCN 在Lightgcn 的基础上进一步简化,跳过了无限的消息传播层进而进行更高效的推荐。相比显式的消息传播,UltraGCN 通过设定收敛方式构建损失函数,从而避免了多层卷积堆叠带来的问题。
Node2vec_mf(Node2vec_Matrix Factorization)、Metapath2vec_mf(Metapath2vec_Matrix Factorization):Node2vec、Metapath2vec 的变体。Node2vec、Metapath2vec等模型最初是为了节点分类任务设计,为充分发挥其性能以更公平地进行比较,参考文献[30]中的方法,将Node2vec、Metapath2vec 学习到的节点嵌入表示集成到扩展矩阵分解模型中进行联合优化,并引入可学习嵌入作为各实体的潜在表示。
Node2vec、Metapath2vec、PinSage、Ngcf 使用深度图库(deep graph library,DGL)[45]中的实现,Node-2vec、Metapath2vec各节点游走次数设置为500,游走长度设置为100。Bpr、Moocir、Lightgcn、Ackrec 参照文献[17,19,39]所提供代码实现,Node2vec_mf、Metapath2vec_mf 参考[30,33,41]等文献所提供代码实现。
4.7 实验结果
4.7.1 模型变体实验分析
表3 总结了MoocSage相关变体在不同指标下的性能。可得出以下结论:

表3 MoocSage与变体模型的性能对比(MoocCube_s数据集)Table 3 Performance comparison of MoocSage and variant models(MoocCube_s dataset)
(1)注意力机制可有效融合各实体在不同子图下的表示。
(2)计算注意力得分时,额外考虑用户、知识概念的潜在特征,一定程度上提升模型在HR 指标上的性能表现,但模型复杂度随之提升,性价比较低。
(3)非线性激活函数降低了模型的有效性,严重影响推荐性能。
(4)相较于Adam 优化器,SGD 优化器收敛速度慢,效果一般。
(5)相较于使用手工处理方法进行相关节点的表示,基于Metapath2vec这类的预训练方法能更好地区分各节点的表示,从而大幅提升下游推荐任务的性能。
(6)矩阵特征变化有助于推荐性能的提升,主要原因在于输入特征较为复杂,加入矩阵特征变化可进行有效的特征提取。
4.7.2 模型推荐性能对比分析
从表4、表5 可以观察到,所提MoocSage 在MoocCube_s、MoocCube_b数据集上的表现均明显优于对比方法。此外,由于MoocCube_b数据量过大,现有计算资源远远不能满足Bpr、Ackrec、Moocir、Ngcf、Lightgcn 等模型的内存需求,也无法在有价值的时间内得到AUC指标。结合实验结果分析各模型推荐性能,可得到如下结论:
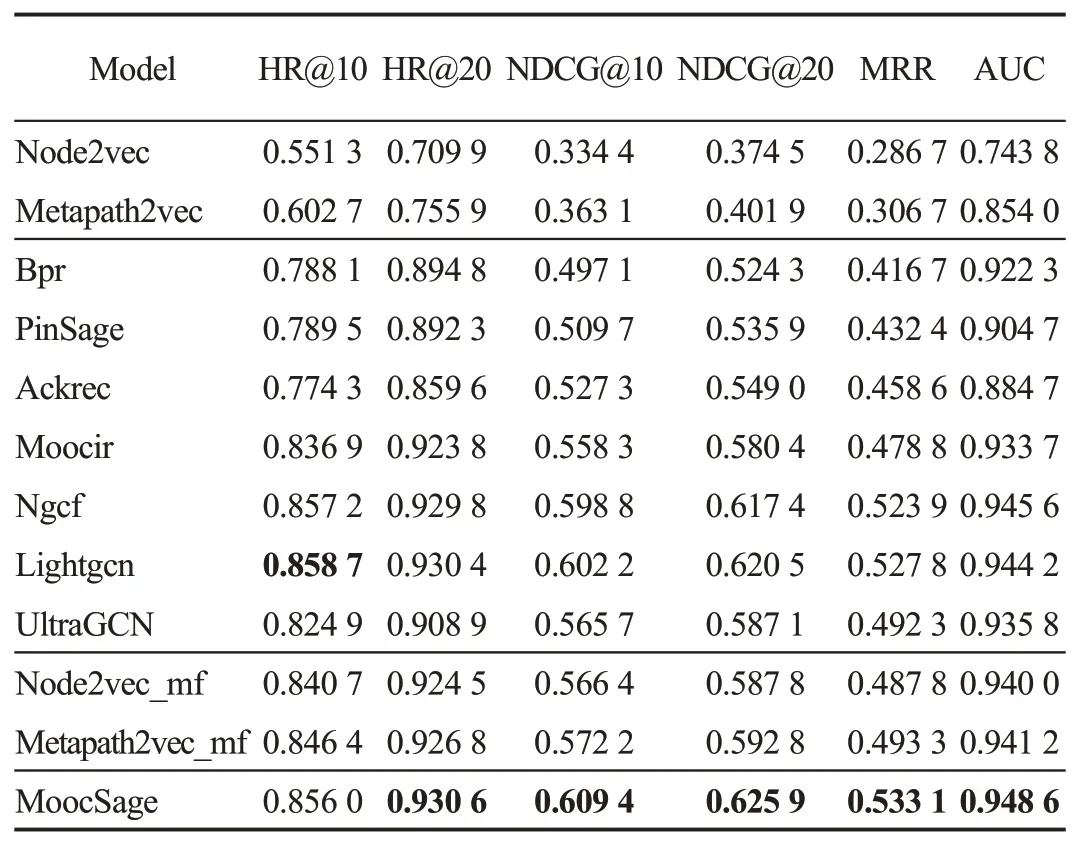
表4 MoocSage与基线模型的性能对比(MoocCube_s数据集)Table 4 Performance comparison of MoocSage and baseline models(MoocCube_s dataset)

表5 MoocSage与基线模型的性能对比(MoocCube_b数据集)Table 5 Performance comparison of MoocSage and baseline models(MoocCube_b dataset)
(1)Bpr的表现显著优于Node2vec与Metapath2vec,但远弱于Node2vec_mf、Metapath2vec_mf。这表明,图表示学习可挖掘出有效的用户与知识概念间的丰富的上下文信息,结合扩展矩阵分解能进一步提升下游推荐任务的性能。相比较Bpr,Node2vec_mf、Metapath2vec_mf的提升来自于用户与知识概念之间的上下文关系的有效利用。
(2)PinSage应用局部图卷积算法,具有较强的可扩展性,但仅考虑用户-知识概念间交互,容易受到数据稀疏问题的影响,推荐性能不如其他基于异构图的模型。
(3)Moocir 相较Ackrec,显著提高预测和推荐性能,隐式反馈方法在点击预测任务上的表现更好。
(4)Ngcf 借助高阶连通性将用户和项目进行关联,能够有效提取协作信号,相较于其他对比方法,在AUC 指标上表现最好,拥有较强的正负样本区分能力。
(5)Lightgcn在NDCG、MRR指标上优于Ngcf,表明去除非线性变换能在一定程度上提升排序质量。
4.7.3 模型捕获交互信息的能力对比分析
根据所能捕获实体间交互信息的复杂程度,将各模型分为两大类,结合实验结果对各模型捕获交互信息的能力进行对比分析。
(1)具有捕获user-item交互信息能力的模型
①Bpr 利用内积捕获user-item 一阶交互信息,但易受到数据稀疏问题的影响。
②Ngcf 通过多层堆叠捕获user-item 多阶交互信息,可有效缓解数据稀疏问题。但受限于计算资源,较难进行高阶交互信息的捕获。
③Lightgcn 在Ngcf 的基础上进行改进,简化模型,去除无关结构,进一步提升捕获user-item 多阶交互信息的能力。但受限于全图卷积算法,高阶交互信息捕获成本仍不能得到有效降低。
④UltraGCN 根据节点的度计算系数,采样邻域节点,减少可训练参数的同时将卷积层数压缩为一层。高阶交互信息捕获成本得到有效降低。但受限于采样方法和较多的超参数,训练较为困难,最终结果一般。
⑤PinSage 基于随机游走采样方法捕获user-item多阶交互信息,具有高可扩展性。在有限计算资源下,仍能通过调整随机游走策略捕获高阶交互信息。但对实体信息特征要求较高,在传统推荐任务中效果表现一般。
(2)具有捕获user-item 及其以外的其他类型实体间的交互信息能力的模型
①Node2vec 通过忽略各实体类型、实体间关系捕获user-item 交互信息及其以外其他交互信息,实体嵌入混乱,推荐效果一般。
②Metapath2vec 在元路径的指导下进行随机游走采样,构建具有特定语义信息的训练语料,有效捕获user-item 及其以外的其他类型实体间的交互信息,此外还可通过调整滑动窗口捕获多阶交互信息。但Metapath2vec 并未根据实体间关系区分交互信息类型,推荐效果一般。
③Ackrec、Moocir在元路径的指导下基于全图卷积算法进行相关实体间信息交互,通过层数堆叠的方式捕获各实体间高阶交互信息。但受限于全图卷积算法,捕获高阶交互信息成本较高。
本文提出的MoocSage 在元路径的指导下进行随机游走采样,可有效捕获user-item 及其以外的其他类型实体间的高阶交互信息。
4.7.4 模型资源利用率对比分析
图12 总结了各模型在MoocCube_s 数据集上的内存消耗对比。将各模型分为4类,结合实验结果对模型资源利用率进行对比分析。
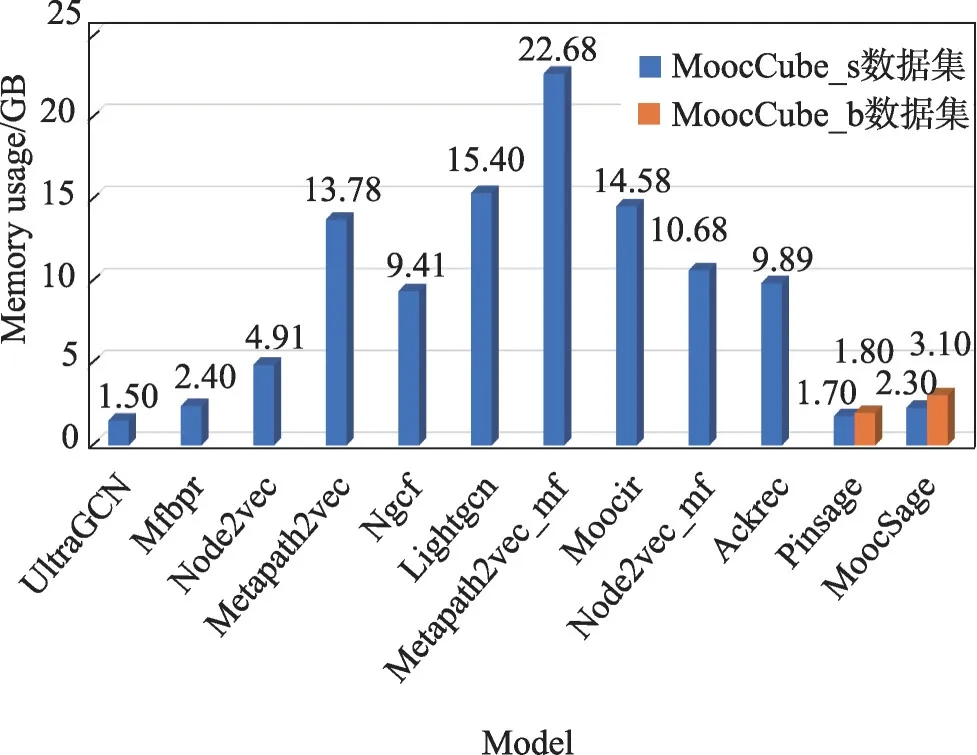
图12 MoocSage与对比模型在MoocCube数据集上的内存使用比较Fig.12 Comparison of memory usage between MoocSage and other models on MoocCube datasets
(1)基于矩阵分解的推荐模型
矩阵分解模型的主要思想是将user-item 交互矩阵分解为user和item特征矩阵,小数据集计算所需内存约为2.4 GB。但因涉及矩阵运算,随着user-item交互矩阵的增加,所需计算资源呈倍数级上升,无法完成大规模推荐任务。算法复杂度为O(mnd2),其中m、n分别代表user、item数,d为user、item特征维度。
(2)基于表示学习的推荐模型
基于表示学习的推荐方法一般分为两步:①构建语料;②使用skipgram 模型进行相关实体嵌入,最大化相邻实体出现概率。基于表示学习的推荐方法所需计算资源与语料、batch-size 相关。对于Mooc-Cube_s 数据集,Node2vec 效果到达最佳计算所需内存约为4.91 GB,Metapath2vec 根据实体间不同上下文关系构建语料,权重矩阵规模较Node2vec 有所扩大,效果到达最佳计算所需内存约为13.78 GB。对于MoocCube_b 数据集,调整至现有计算资源极限,Node2vec与Meta-path2vec推荐效果仍较差。算法复杂度为O(kv),k为中心词的个数,v代表批处理大小。
(3)混合推荐模型
将由Node2vec、Metapath2vec 学习到的节点嵌入集成到扩展矩阵分解模型中进行联合优化。Node-2vec_mf计算所需内存约为9.89 GB,因Metapath2vec学习到的节点嵌入更为复杂,Metapath2vec_mf 计算所需内存约为14.58 GB。因涉及矩阵运算,无法完成大规模推荐任务。算法复杂度与基于矩阵分解的推荐模型相同。
(4)基于图神经网络的推荐模型
①基于全图卷积的推荐模型,需要在训练期间对全图拉普拉斯算子进行操作,如Ngcf、Lightgcn、Ackrec、Moocir,所需计算资源随数据量、层数的增加曾指数级上升,无法完成大规模推荐任务。算法复杂度为,其中k代表卷积层数,Si为i层卷积操作涉及到的节点个数,约为1+N+N2+…+Nk。
②基于局部卷积的推荐模型,通过构建子图的方式进行局部卷积操作,具有高可扩展性,所需计算资源与图大小、batch-size 相关,可有效完成大规模推荐任务。UltraGCN、PinSage 仅考虑user-item 交互,计算所需内存分别为1.5 GB、1.7 GB。算法复杂度,其中b为batch-size。由于采样M个节点而不是全部节点,故k层需要采样的节点个数就变为1+M+M2+…+Mk,其中Mk≪Nk。
本文所提MoocSage 通过构建异构图引入用户、课程资源之间的上下文关系信息,在保持高性能的同时有着极高的存储效率,算法复杂度与Pinsage 相同,两个数据集任务计算所需内存分别为2.3 GB、3.1 GB。特别是与Moocir 相比,MoocCube_s 数据集任务内存需求降低了近1 000%,性能提升近10%。相比Lightgcn,性能提升2%,内存需求降低了近500%。
5 结束语
针对传统推荐方法无法有效扩展到大规模课程资源推荐这一问题,本文在PinSage 的基础上进行了扩展,提出了一种可在异构图上进行user2item 推荐的端到端的神经网络模型MoocSage。为了验证该方法的有效性,分析了多个模型变体,研究了模型的参数,并与现有研究进行了比较。从结果中可以得出结论,MoocSage 在保证高性能的同时大幅提升内存使用效率,可有效完成课程资源推荐任务,且具有高可扩展性。
随机游走方法采样出的样本并不是均匀分布,节点被选中的概率和节点的度成正比关系,下一跳的选择更倾向于高度节点,容易导致对高度节点偏差。接下来将尝试寻找更加高效且准确的加权手段来修正这一问题。
