知识驱动的对话生成模型研究综述
2024-01-11许璧麒马志强周钰童贾文超
许璧麒,马志强,2+,周钰童,贾文超,刘 佳,吕 凯
1.内蒙古工业大学数据科学与应用学院,呼和浩特 010080
2.内蒙古工业大学内蒙古自治区基于大数据的软件服务工程技术研究中心,呼和浩特 010080
对话系统作为人工智能领域最重要的分支之一,目标是使机器通过人类语言与人进行交互,并具有极大的学术价值和商业价值,而同时也面临着巨大的挑战。早在1950 年,图灵在Mind[1]上发表文章提出了采用人机交互的方式来检验机器智能,之后国内外研究者们对如何建立对话系统展开了深入的研究。目前主要的对话系统主要包括任务型对话系统和开放域对话系统。任务型对话系统致力于帮助用户完成任务,而开放域对话系统的主要目的是产生与人类相似的回复,从而提高用户的使用体验。开放域对话系统的良好表现是人机交互的最终目标,因此成为了自然语言研究领域最具吸引力的领域之一[2-6]。尽管研究者们提出了多种用于对话生成的模型,但这些模型通常会生成通用的回复,并不能提供适当的信息,原因在于这些模型仅能从对话数据中学习语义交互,而并不能深入理解用户输入、背景知识和对话上下文。因此,研究者们发现,外部知识是人类在对话中打算使用的知识信息,如果模型能够访问和充分利用外部知识,那么它就可以更好地理解对话,从而生成恰当的回复,推动对话的顺利进行。最近,为了解决这一问题,研究者们尝试通过引入外部知识来增强对话生成模型对输入语句的理解,使对话生成模型利用外部知识中提供的信息来生成拟人的回复。
知识驱动对话生成任务旨在利用不同形式的知识来强化对话生成模型来生成更合理、更具多样性、更富含信息量和拟人的回复。Lowe等[7]和Dodge等[8]最早尝试在对话系统中引入外部知识,提出了知识驱动的对话生成任务。目前,研究者们针对对话生成模型引入外部知识展开了一些研究,这些引入的知识可以分为结构化知识和非结构化知识。结构化知识也可以被称为知识图谱,以知识三元组的形式存在,目前常用的知识图谱根据储存内容的不同可以分为:通用知识图谱、行业知识图谱和任务知识图谱。其中通用知识图谱有YAGO[9]、Wikidata[10]、Freebase[11]、DBpedia[12]、ConceptNet[13]等;行业知识图谱有MusicBrainz[14]、GeoNames[15]、DrugBank[16]等;任务知识图谱有WikiM[17]、DB111K-174[18]、IsaCore[19]等。结构化知识便于检索,能够有效地表示出不同实体之间的关联信息。Xu 等[20]将一个结构化的特定领域的知识库整合到一个具有回忆门机制的对话生成模型中。Zhu 等[21]提出了一个使用复制网络的端到端的对话生成模型,并引入结构化知识。Zhou 等[22]将大规模的常识知识引入到对话生成模型中,使用动态注意力促进模型更好地生成回复。Liu等[23]将知识图谱和文本文档互相融合,产生了相互强化的优势,进一步强化了模型生成对话的能力。然而,由于结构化知识存在着有效信息少的问题。越来越多的研究者们开始关注如何引入非结构化知识到开放域对话系统中,这种知识通常由文本形式的事实描述组成,其中包含了丰富的语义信息,可以有效促进对话生成,在开放域对话场景中得到广泛应用。Zhou 等[24]提出了一个基于文档的数据集,并且将文档中的知识和对话历史拼接在一起送入解码器中以生成回复。Li 等[25]设计了一个增量变换器来编码多回合的话语以及相关文档中的知识,来提高对话生成模型对话上下文的一致性和知识相关性。
研究知识驱动的对话生成模型是非常有价值的研究方向,目前相关工作仍处于初期探索阶段。对于知识驱动对话生成模型这一方向尚未形成一致的明确定义和通用的框架,并且现有成果还未经过全面梳理和系统总结。本文将知识驱动的对话生成模型作为研究对象,归纳并详细描述了知识驱动的对话生成研究涉及的问题,同时重点阐述了研究者们针对解决每个问题的相关研究,最后聚焦于知识驱动的对话生成未来的发展方向。
1 知识驱动的对话生成任务和问题描述
根据对知识驱动的对话生成任务和知识驱动的对话生成现状的研究。大多数现有的知识驱动对话生成任务都是在知识获取、知识表示、知识选择以及知识融入对话四个方面进行深入研究。
知识获取:主要侧重于对话生成模型如何从文本或从其他知识来源学习各种知识的过程。即给定对话上下文U={U1,R1,U2,R2,…,Ui,Ri,…,UT}和其他知 识K={K1,K2,…,Ks,…,Km},对话生成模型M从对话上下文U和其他知识K中获取知识k={k1,k2,…,ks,…,km}。
知识表示:主要侧重于对话生成模型如何在其密集的参数中编码、存储和表示知识。对知识表征机制的研究将有助于更好地理解和控制模型中的知识,也可能激励研究者们更好地理解人类大脑在对话中的知识表征。即对话生成模型M对获取到的知识k={k1,k2,…,ks,…,km}进行知识表示。
知识选择:主要侧重于关注对话生成模型如何从获取的知识中选择正确的知识或删除不需要的信息。即给定对话上下文U={U1,R1,U2,R2,…,Ui,Ri,…,UT}和获取的知识k={k1,k2,…,ks,…,km},对话生成模型M通过对话上下文U和获取的知识k选择出符合当前上下文语境的知识ks。
知识融入:主要侧重于关注对话生成模型如何有效地利用选择的正确的知识生成合适的、高信息量的回复 。即通过给定上下文U={U1,R1,U2,R2,…,Ui,Ri,…,UT}和选择出符合当前上下文语境的知识ks,对话生成模型M生成包含知识的回复
2 数据集
当前的知识驱动的对话生成模型的研究都是需要大量的数据驱动的,因此知识驱动的对话数据集的质量和多少制约着知识驱动的对话生成的效果。许多研究者们收集并整理了大量的知识驱动的对话数据集,对这些数据集进行处理后,就可以用处理后的数据集来训练知识驱动的对话生成模型。表1 为具有代表性的知识驱动的对话数据集。

表1 知识驱动的对话数据集Table 1 Knowledge driven conversation dataset
3 知识驱动的对话生成模型研究
目前,研究者们对知识驱动的对话生成模型的研究主要针对如何知识获取、知识选择、知识表示和知识融入四个方面做出了大量的工作。本章将针对这四个方面分别从知识获取模型、知识表示模型、知识选择模型和知识融入的对话生成模型四个方面进行介绍。
3.1 知识获取模型
在知识获取期间,对话生成模型从不同的知识来源学习知识,目前,知识获取主要有两个来源:文本数据和结构化数据。本节将根据知识来源对知识获取模型进行分类,分为基于文本数据的知识获取模型和基于结构化数据的知识获取模型。
3.1.1 基于文本数据的知识获取模型
目前,为了从文本数据获取知识,对话生成模型通常在大规模文本语料库上进行训练学习,本小节将重点关注基于文本数据的知识获取模型如何从纯文本数据中获取知识的方法。
因果语言建模的目标是预测输入序列中的下一个标记。Radford 等[38]、Brown 等[39]、Ouyang 等[40]以及Scao 等[41]在捕获上下文依赖和对话生成方面证明了因果语言建模具有良好的有效性,因果语言建模的一个局限性是模型以单向的方式获取知识,它只能从左到右捕获上下文信息。Devlin 等[42]和Liu 等[43]为了从文本数据中获取知识,通过掩码语言建模建立知识获取模型,掩码语言建模的目的是随机屏蔽输入中的一些标记,然后预测基于序列其余部分的掩码标记,如图1所示。因果语言建模只能以单向方式获取信息,而掩码语言建模可以从左到右和从右到左两个方向捕获上下文的知识。Raffel 等[44]和Song等[45]通过序列到序列模型(sequence to sequence,Seq2Seq)语言建模建立知识获取模型,使用解码器-编码器架构进行训练,首先向编码器提供掩码序列,而解码器用来预测掩码标记。Lewis等[46]使用自编码器建立知识获取模型,首先用随机掩码符号破坏输入序列,然后将输入码输入到双向编码器中,用自回归解码器计算输入的概率。
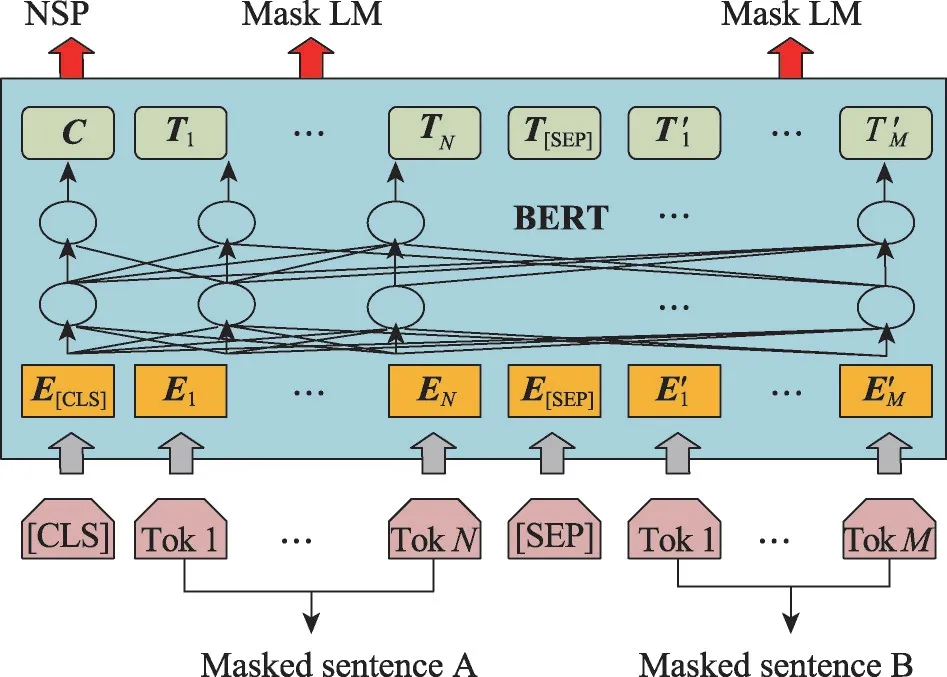
图1 掩码语言建模的知识获取模型结构Fig.1 Structure of knowledge acquisition model for mask language modeling
知识获取模型通过训练学习来获取文本数据中的知识,但是知识获取模型如何获得知识的潜在机制仍然有待探索。为了了解其中的潜在机制,一些研究者们研究了模型训练的过程,Achille等[47]试图找出模型在训练学习中是否存在获取知识的关键时期。Liu等[48]致力于在神经网络中寻找知识获取的数学解决方案。Saphra 和Lopez[49-50]分析了长短期记忆网络(long short-term memory,LSTM)[51]在训练过程中获取知识的关键时期,使用奇异向量分析方法[52]和LSTM构建知识获取模型,如图2所示。
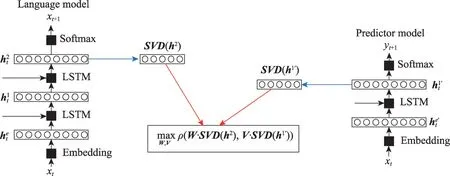
图2 奇异向量分析的知识获取模型Fig.2 Knowledge acquisition model for singular vector analysis
现在的大多数研究者们的研究都集中在结构相对简单的神经网络上,只有部分的研究者们在大规模的语言模型中考虑获取知识。Chiang 等[53]首先研究了ALBERT(a lite BERT)模型[54]在训练过程中知识是如何获取的。具体来讲,他们研究了模型在训练期间的语法知识、语义知识和外部知识,发现模型学习过程因知识而异,有更多的训练步骤不一定会增加模型知识获取的能力。Perez-Mayos 等[55]研究了训练的语料库的大小对RoBERTa(robustly optimized BERT)模型[56]知识获取能力的影响,发现在更多数据上训练的模型包含更多的语法知识。Liu等[57]也研究了RoBERTa 对各种知识的知识获取过程。研究发现,与能够快速、稳健地学习的语言知识相比,外部知识的学习速度缓慢。ChatGPT 是一种基于大模型的聊天机器人,ChatGPT通过训练一个大型的神经网络模型,建立词向量和语言模型,学习通用的语言规则和语义表示,为对话生成提供支持,并通过预测任务学习和微调学习优化模型来获取知识。
表2为各类基于文本数据知识获取模型的原理、优点及缺点。

表2 基于文本数据的知识获取模型Table 2 Knowledge acquisition model based on text data
从文本数据中获取知识的方法可以很容易地进行扩展,而且知识来源也很容易获得。但是模型获取知识的潜在机制不是很清晰,由于知识获取过程是隐性的,会导致模型产生错误的预测。
3.1.2 基于结构化数据的知识获取模型
除了从文本数据中获取知识外,研究者们还可以通过向对话生成模型中注入结构化知识来获取知识。为了从结构化数据中获取知识,目前研究的重点是将不同类型的结构化数据的知识注入到对话生成模型中。结构化数据的主要类别包含实体知识、事实知识、常识知识和语言知识。
为了明确地学习实体知识,许多研究者提出了对话生成模型的实体知识导向任务。Sun 等[58]和Shen 等[59]使用整体级掩码来增强模型的知识获取能力,该模型首先识别句子中的命名实体,然后对这些实体对应的所有标记进行预测。Xiong等[60]提出了一种实体检测方法,该检测将句子中的命名实体随机替换为相同实体或相同类型的其他实体,知识获取模型应该确定哪些实体被替换。Yamada 等[61]将单词和实体视为独立的标记,并分别进行掩码语言建模,以学习上下文的单词表示和实体表示,增强模型的知识获取能力。Fevry 等[62]提出一个EAE(entities as experts)模型,将实体检测与掩码语言建模联系起来,将文本中的实体与特定的实体记忆相匹配,如图3所示。Logeswaran 等[63]和Gillick 等[64]在知识获取模型中引入实体知识的其他信息,如实体描述,以进一步帮助模型学习实体知识。Peters 等[65]和Yamada 等[61]利用单词对实体的关注来使模型获取知识。
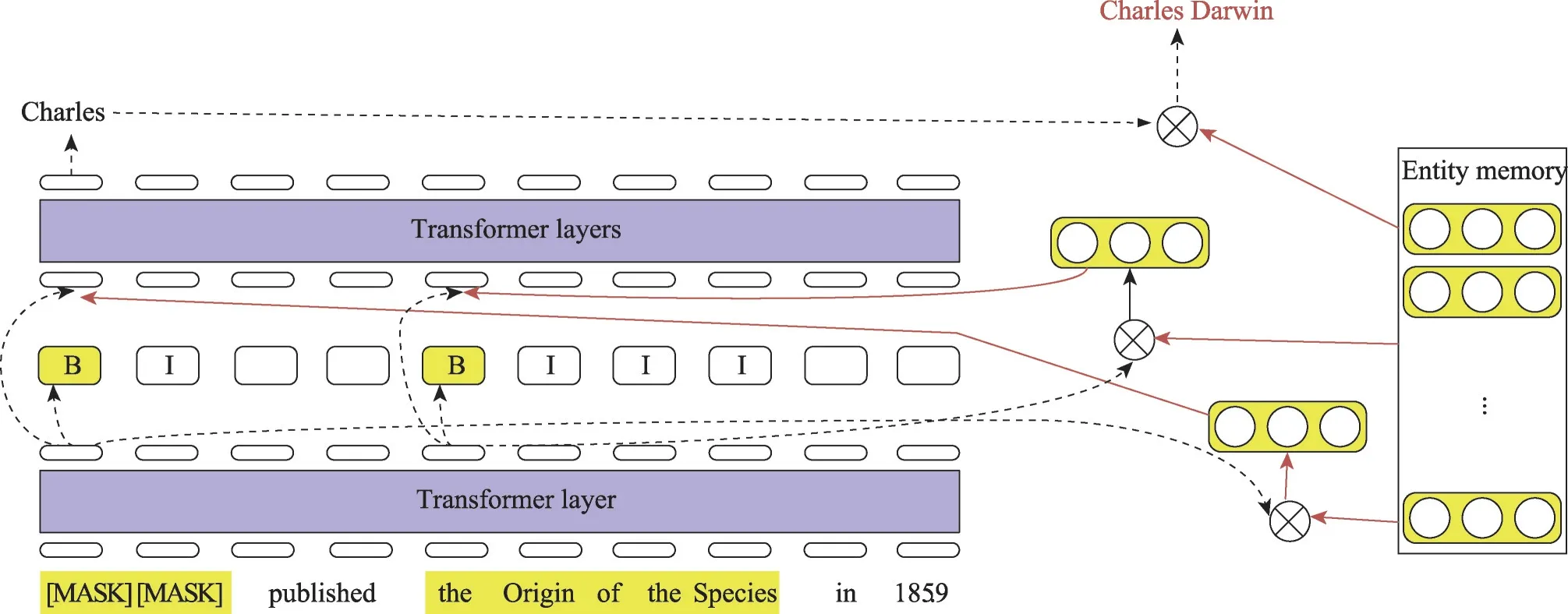
图3 EVE模型结构Fig.3 Structure of EVE model
在结构化知识中,事实知识通常表示为三元组(主体实体,关系,对象实体)。近年来,研究者们一直致力于帮助对话生成模型获取更多的事实知识,以更好地生成回复。研究者们在知识获取模型中引入知识图谱来获取知识,Zhang 等[66]提出了一种聚合器,将文本中实体中相应的知识嵌入和标记嵌入相结合。Wang等[67]同时训练掩码语言建模模型和知识图嵌入模型,提出了一个KEPLER(knowledge embedding and pretrained language representation)模型,模型既可以产生信息文本又可以知识嵌入,如图4 所示。Wang 等[68]添加了一个适配器,将知识注入知识获取模型中,而无需更新原始参数。该适配器经过训练,以确定标记之间的关系类型。Qin 等[69]提出了实体识别任务来预测给定主体实体和关系的对象实体,以及关系识别任务来预测关系对之间的语义连接。Liu 等[70]认为,将整个知识库整合到知识获取模型中可能会导致知识噪声问题,并建议从与每个输入句子相关的特定子图中学习。Soares 等[71]提出,通过“空白匹配”的目标,仅从整个链接文本中学习关系知识,首先用空白符号替换文本中的实体,然后当它们具有相同的实体对时,使关系表示更接近。知识获取模型中学习常识知识最常见的策略是在训练之前将知识转化为自然的语言表达。Bosselut 等[72]、Guan 等[73]、Shwartz 等[74]首先将常识知识三元组转化为自然语言,然后根据这些知识增强数据对对话生成模型进行训练。Ma等[75]将结构化常识知识转化为模型学习自然语言的问题。
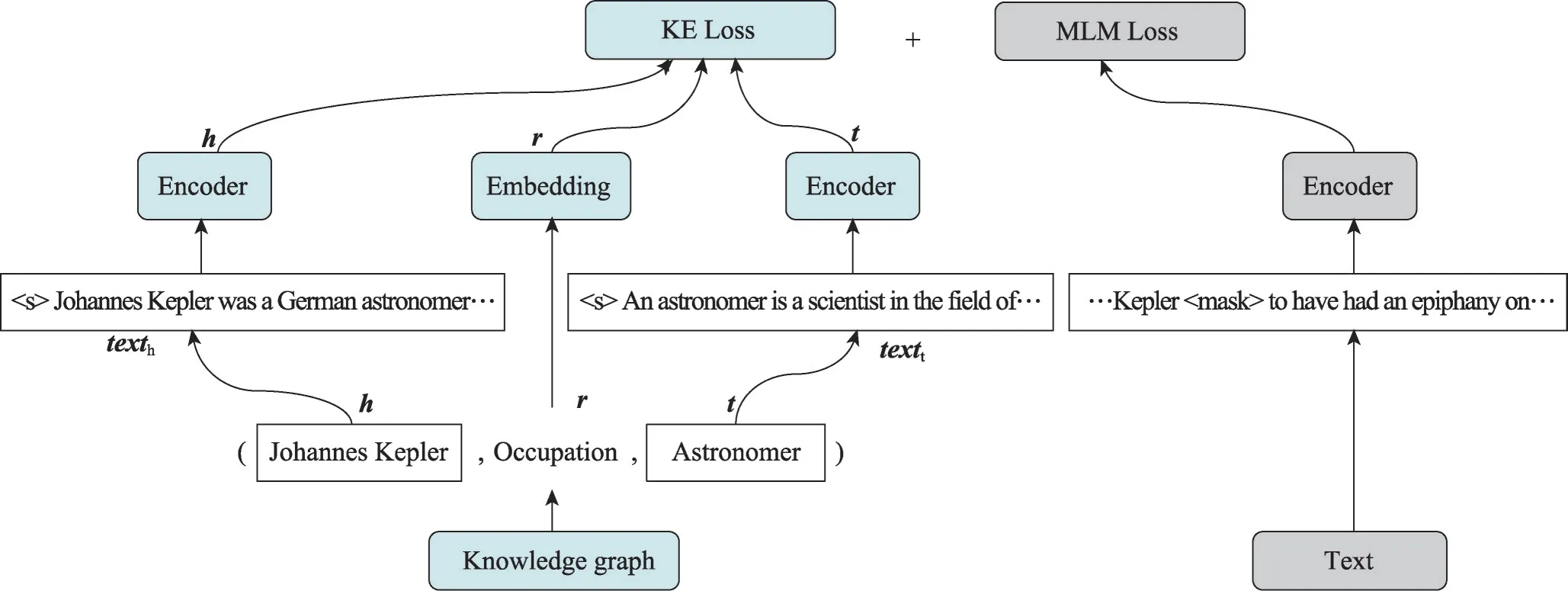
图4 KEPLER模型结构Fig.4 Structure of KEPLER model
研究者们发现知识获取模型还可以明确学习语言知识,如情感知识、词汇知识、语法知识等。为了让知识获取模型获得情感知识,Ke 等[76]首先用POS标签和情绪极性标记每个单词,然后将单词级和句子级情绪标签与掩码语言建模结合起来。Tian 等[77]提出了一个SKEP(sentiment knowledge enhanced pretraining)模型,从未标记数据中挖掘情感知识,然后利用这些情感信息进行情绪掩码、情绪词预测和词性预测,如图5 所示。在词汇知识方面,Lauscher等[78]首先从WordNet[79]和BabelNet[80]获取单词相似性信息,然后在BERT 训练前还添加单词关系分类。Song 等[81]构造了一个用注意力对齐校准的依赖矩阵和一个用来整合依赖信息的融合模块,知识获取模型可以获取词汇知识。在语法知识方面,Sachan等[82]研究通过在Tranformers[83]的输出上添加syntax-GNN 和使用注意力合并文本嵌入,来为模型注入语法知识。为了进一步获取语法知识,Bai 等[84]使用多个注意网络,每个网络编码语法树中的一个关系。随着大模型研究的极大推进,并在知识获取方面取得了进展,大模型可以通过外部知识库接口、外部模型集成和增强学习等方式来获取结构化知识。这些方法可以丰富大模型的知识库,提高对话生成的准确性、流畅度和智能程度。
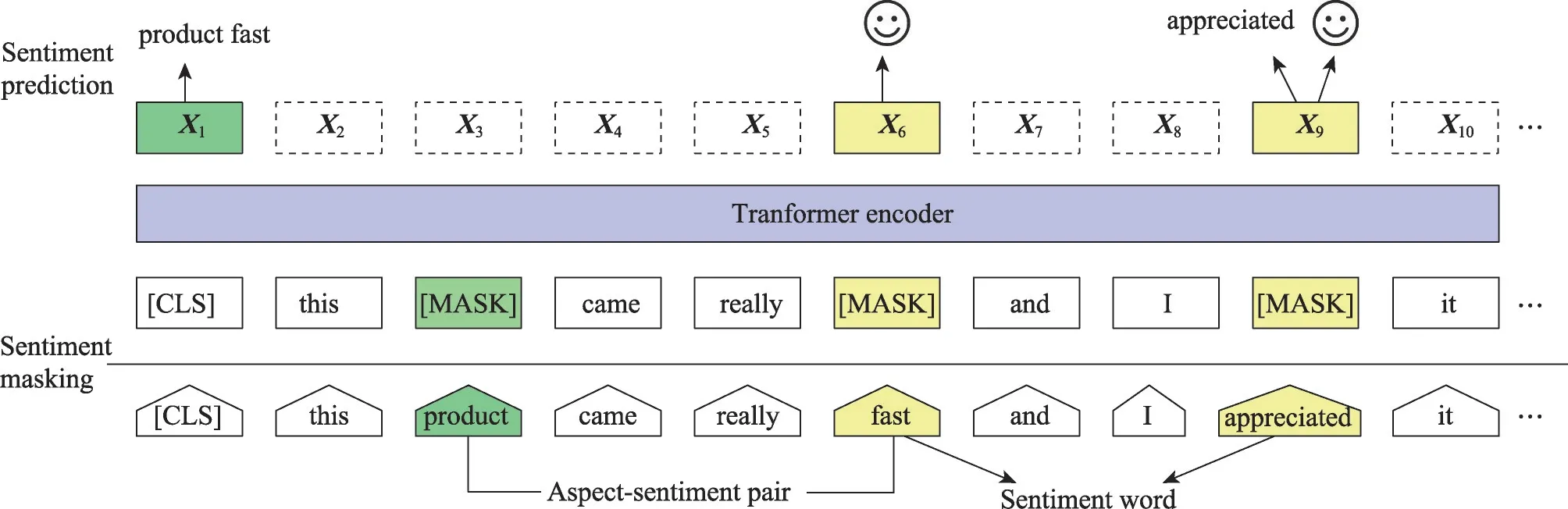
图5 SKEP模型结构Fig.5 Structure of SKEP model
基于结构化数据的知识获取模型如表3所示。
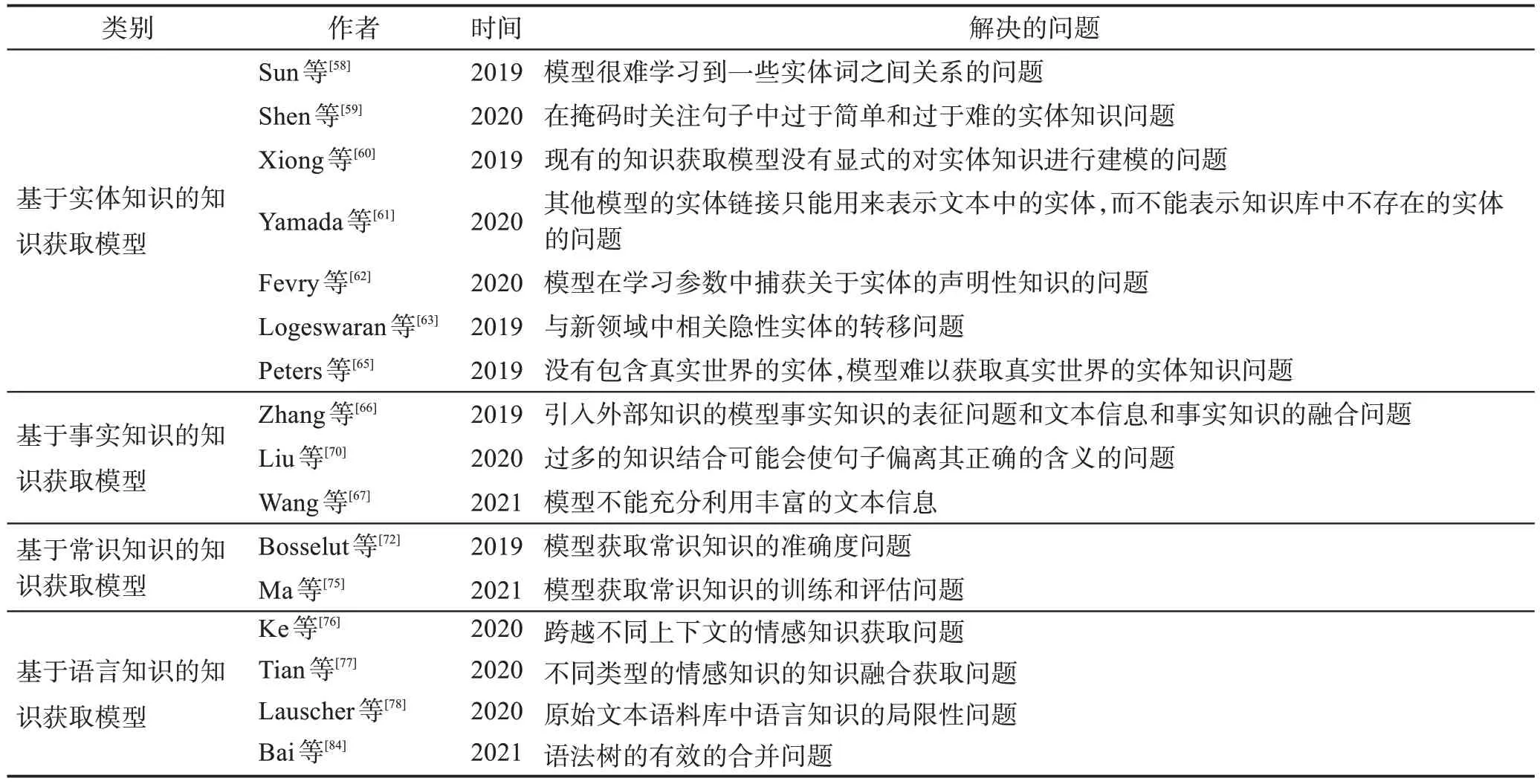
表3 基于结构化数据的知识获取模型Table 3 Knowledge acquisition models based on structured data
结构化数据可以很明确引入到对话生成模型中,但是受到结构化数据的成本、领域、规模和质量的限制,使得模型很难进行扩展和使用结构化数据以外的新的知识。
3.2 知识表示模型
知识表示主要研究了知识表示模型如何编码、转换和存储所获得的知识。在模型中,知识被编码为密集的向量表示,并保存在模型参数中,但每种知识是如何被编码、转换和存储到参数中仍然需要进一步研究。目前,已经开始对知识表示进行了研究,本节将首先根据知识表示的方法对这些研究进行介绍。
3.2.1 基于梯度方法
Dai 等[85]首先引入了知识神经元的概念,这是与事实知识相关的Transformer 神经元,如图6 所示。Geva 等[86]假设知识神经元位于前馈网络中,然后通过向模型提供含有掩码的知识表示提示,识别出在前馈网络中得分最高的知识神经元,并基于梯度的方法进行计算,如图7所示。
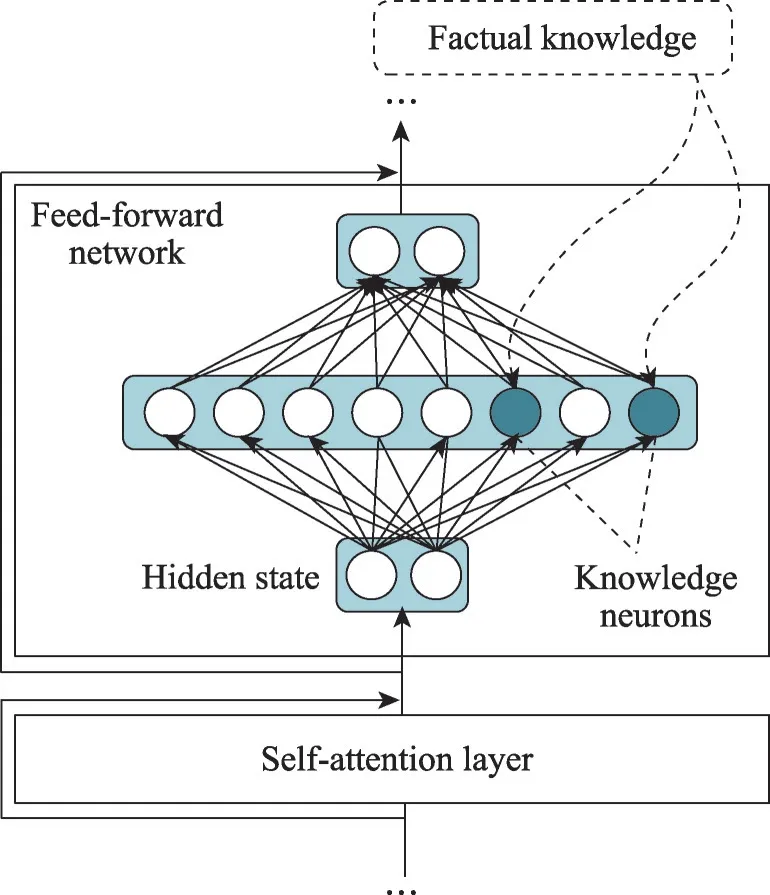
图6 知识神经元表达模型结构Fig.6 Structure of knowledge neuron expression model
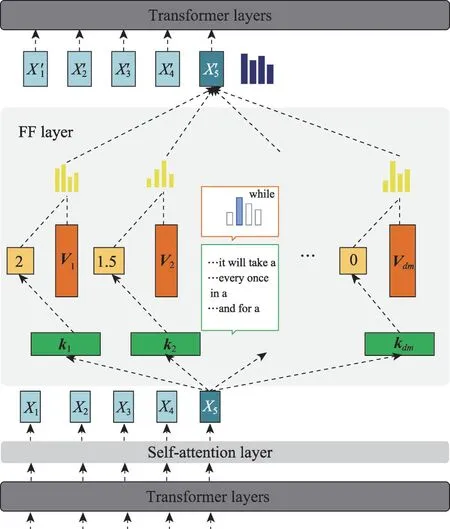
图7 梯度计算的前馈网络结构Fig.7 Feedforward network structure for gradient calculation
3.2.2 基于因果启发方法
Meng 等[87]将Transformer 中的神经元替换成了知识神经元,它们对预测某些事实知识具有最强的因果关系。这些神经元通过因果关系分析来定位。具体来说,他们通过比较token embedding 之间预测的概率变化来计算对事实预测的因果关系。通过实验证明了前馈网络模块在事实知识表示中起到决定性的作用。
3.2.3 基于注意力方法
注意力头也可以编码知识相关信息的表示,Clark 等[88]和Htut 等[89]研究了注意头中编码的语言知识,发现虽然一些注意头与语法的特定方面相关,但语言知识是由多个注意头分布和代表的。Lin等[90]发现,对话生成模型的注意力权重可以编码语法知识信息,编码之后可以更准确地表示这些句法属性。
3.2.4 基于分层方法
Lin 等[90]对语言知识进行了分层探测,为每一层训练一个特定的分类器,发现低层编码token 的位置信息,而高层编码更多的成分信息。Liu 等[91]分析了对话生成模型在知识表示上的分层可转移性,发现中间层通常具有更好的性能和可转移性。Wallat等[92]提出利用对话生成模型中每一层的LAMA(language model analysis)[93]来捕获事实知识,并发现大量的知识存储在中间层中。Juneja 和Agarwal[94]还基于知识神经元进行了分层的事实知识分析,并证明了大多数知识(例如,巴黎是“某个国家”的首都)可以归于中间层,在最后的几层中将被提炼为事实(例如,巴黎是法国的首都)。
近年来,学术界和工业界极大推进了大模型的研究,并在知识表示方面也取得了巨大进展,如ChatGPT的推出,引起了广泛关注。大模型在获取到知识后,对于不同类型的知识,大模型需要采用不同的编码方式。例如,对于文本类型的知识,可以采用词向量表示法将其转化成向量格式。对于图片类型的知识,则需要先进行特征提取,然后将提取出来的特征嵌入到向量空间中。在编码的过程中,通常需要考虑向量的维度、采样方法等因素,以便进行后续的研究。
为了更清晰地介绍知识表示模型,表4从各类知识表示模型的原理、优点及缺点进行介绍。
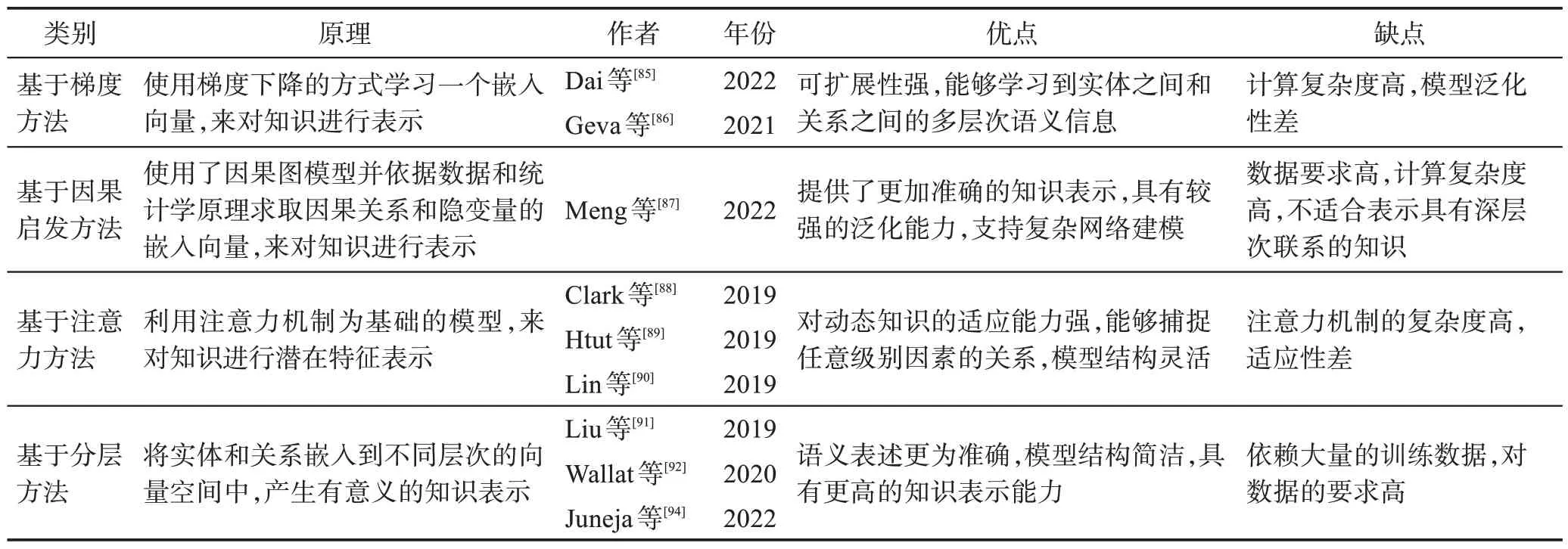
表4 知识表示模型Table 4 Knowledge representation model
3.3 知识选择模型
知识选择是知识驱动对话生成任务中的关键步骤,关于知识选择模型,目前,研究者们一般采用对话历史和知识之间的语义一致性作为知识选择的基础,以及通过带有知识标签的数据来训练模型进行知识选择。而在对话场景下,对话历史和知识之间存在一对多的关系,因此有必要研究不依赖于数据来训练的知识选择模型。尽管当前有许多知识图谱和语料库可用于提取知识信息,但不同对话场景需要的知识信息通常是多样的。因此,知识选择模型需要选择外部知识中与当前对话场景相关的关键信息,以便为该场景提供更符合要求的知识信息。结构化知识包含明确实体信息和实体间关系。因此,研究人员可以考虑将用户消息中的某些实体信息与知识库信息进行对应,以选择关键知识。相比之下,非结构化知识由文本构成,其中蕴含了不同的语义信息。这使得选择相关内容变得更加困难,尤其是在开放域的对话环境中更为复杂。如何在对话中进行知识选择仍是待解决的问题。本节将对不同的知识选择模型进行介绍。
Lian 等[95]提出一个采用新的知识选择机制的知识选择模型,利用知识的先验和后验分布来进行知识选择,从话语中可以推断出知识的后验分布,它确保了模型在训练过程中对知识的适当选择。同时,利用从话语和回复中推断出的先验分布来近似后验分布,以便在推理过程中即使没有响应,也可以选择合适的知识,使得模型能在无知识标签引导的情况下学习如何选择知识,如图8 所示。Zhang 等[96]提出了一个Cake 模型,该模型引入了一个知识预选步骤,利用话语历史语境作为先验信息,选择最相关的外部知识。Dinan 等[97]进行了多次实验,分别利用Seq2Seq 模型和管道式技术来构建知识选择模型,并通过设计损失函数来监督模型的选择过程。实验结果表明,Seq2Seq 模型在利用知识来回复方面具有良好表现,而管道式模型则在知识选择的准确性方面具有优势。
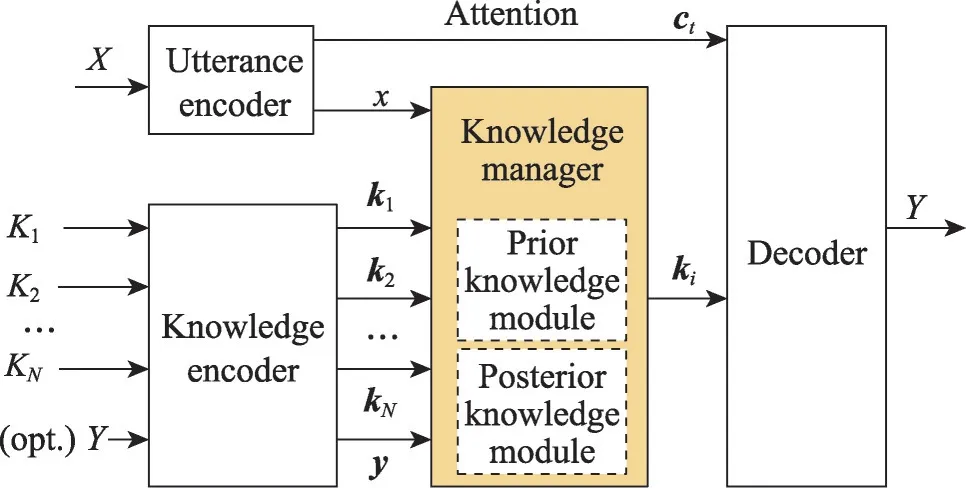
图8 知识选择模型结构Fig.8 Structure of knowledge selection model
Seq2Seq 模型由于通常简单地利用知识信息,在进行编码过程中,对知识信息的置信度会大大降低,容易导致词语组合出现错误。为了解决这个问题,Lin 等[98]提出循环知识交互机制,通过注意力机制动态地选择知识,在解码过程中产生回复。Kim 等[99]则将知识选择建模转化为序列决策过程,同时考虑对话历史和知识的选择历史,以更好地进行知识选择。Zheng 等[100]提出了一种基于差异感知的知识选择模型,它首先计算当前回合中提供的候选知识句子与前一个回合中选择的候选知识句子之间的差异。然后,将差异信息与上下文信息进行融合或分离,以促进最终的知识选择。通过大量的实验证明,他们的模型能够更准确地选择知识,并生成更多信息丰富的回复。Eric 等[35]评估了开放域对话知识选择的现有状态,表明现有关于知识选择数据和评估的方法存在缺陷。Eric 提出了一个新的框架来收集相关的知识,并基于维基百科语料库创建了一个增强数据集WOW++,可以在知识选择模型上进一步研究。为了更清晰地描述知识选择模型的研究现状,对解决的问题、使用的数据集、涉及的评价指标以及模型的性能进行了梳理,如表5所示。在评价指标方面,A.E代表自动评价,M.E 代表人工评价。A.E 主要包括困惑 度(perplex,PPL)[102]、BLUE[103]、ROUGE[104]、Ent、Dist[105]、知识相关度(knowledgeF1,KF1)以及F1。M.E使用人工的方式对内容层面的适宜性(App)、知识层面的信息性(Inf)、语言流利度(Flue)以及人工评价分数(Avg)等方面对模型性能进行打分。
3.4 知识融入的对话生成模型
开放域对话系统的最终任务是生成富含信息量且多样的拟人回复,而不仅仅是传递描述性的事实信息。这些回复可能包含专有名词或稀有名词等难以处理的词汇。为了在生成回复时融入知识,对话生成模型不能简单地复制已选择的知识到回复中,而需要有机结合对话历史和知识信息。目前,大多数研究者采用将对话历史和知识信息直接拼接的方式进行解码,但这种方法较为简单,融合效率低,生成的回复没有很好地嵌入知识信息。另外一些研究者采用指针网络[106]来融入知识,虽然这种方法提高了模型的生成多样性,但无法学习到知识中的关键信息。因此,如何将对话历史和知识信息有机地融合在一起,是知识驱动的对话生成任务中的重要问题。本节将对不同的知识融入的对话生成模型进行介绍。
Zhou 等[107]提出了一个CCM(commonsense knowledge aware conversational model)模型,它在对话生成模型中引入了大规模的常识知识来促进语言理解和生成。该模型从一个知识库中检索相关的知识图,然后用静态图注意机制对图进行编码,这增强了帖子的语义信息,从而支持更好地理解用户的上下文,如图9 所示。Jung 等[108]提出了AttnIO 模型,它是一种双向图检索模型,在每个遍历步骤中计算注意权重,因此模型可以选择更广泛的知识路径,而不是一次只选择一个节点。在这样的方案中,即使只有目标节点,模型也可以预测足够的路径。Zhang 等[36]提出了一个ConceptFlow 模型,生成了更有意义的对话回复。它通过一个常识性的知识图来探索概念级的对话流。最后,它使用了一个门来决定在词汇词、中心概念词和外部概念词之间生成对话。Xu等[109]将知识图谱作为外部知识来源来控制粗层次的对话生成,对话得到了常识性知识的支持,对话生成模型可以使用更合理的方式引导对话生成。Moon 等[110]提出了DialKGWalker 用于对话生成,他们计算了预测的知识图嵌入和真实的知识图嵌入之间的相关性得分,以促进预测。此外,他们还应用了一个基于注意力的图生成器来生成基于相关性分数的图路径,以完成对话生成。Zhan 等[101]通过结合对话级语境表示和图表示来用于对话生成,他们首先基于编码的上下文和响应对来构建对话图,然后对对话图进行推理,以得到一个图表示。最终的得分是通过将上下文表示和图表示的连接向量传递到一个前馈网络来计算的。知识融入的对话模型研究如表6所示。
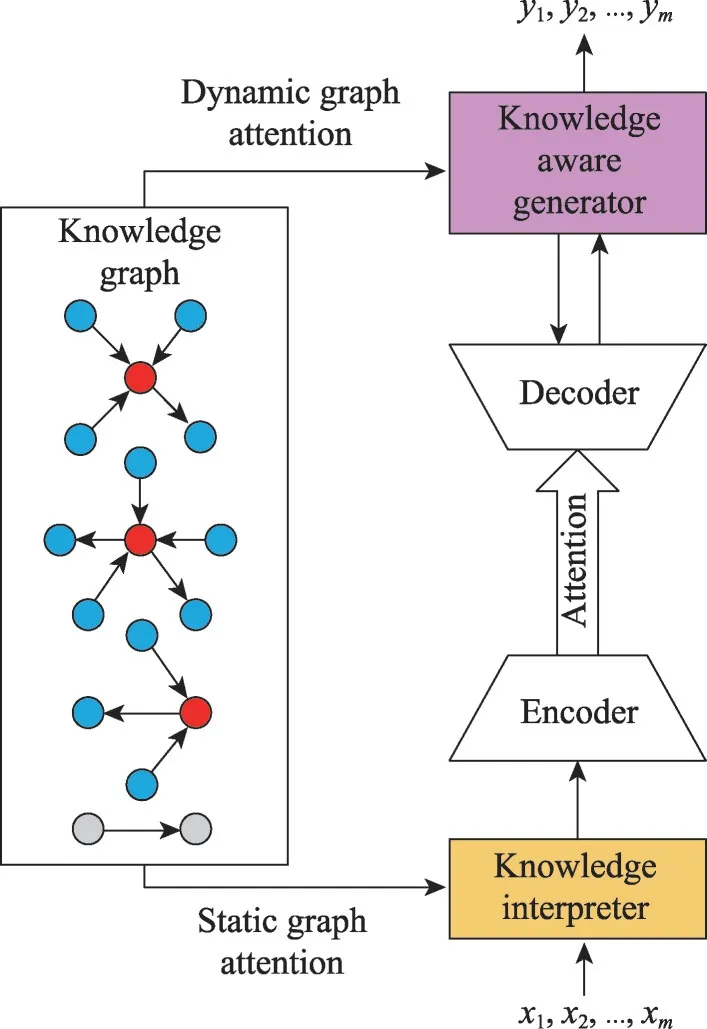
图9 CCM模型结构Fig.9 Structure of CCM model
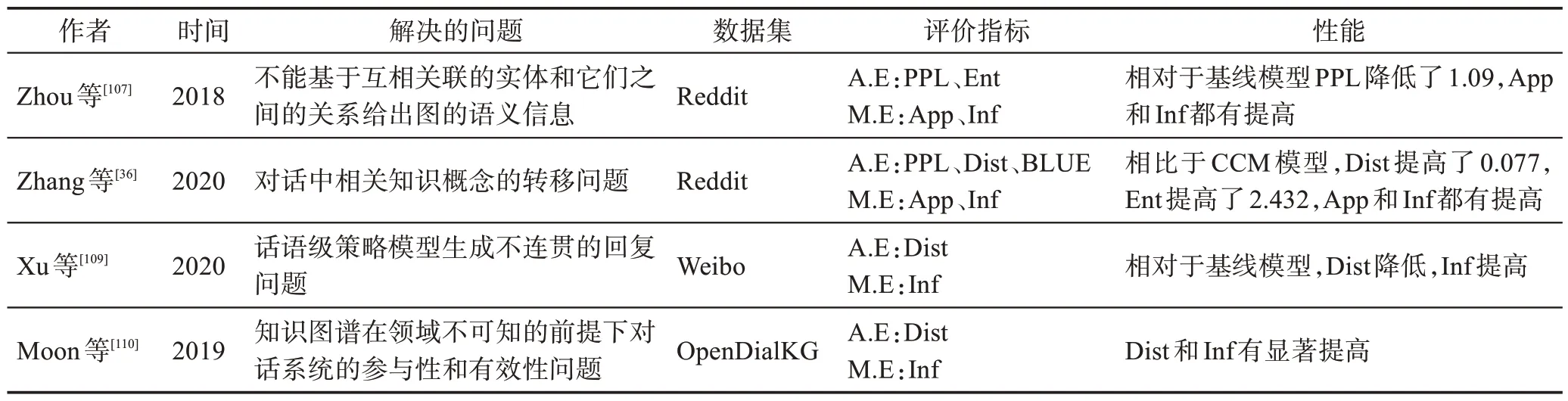
表6 知识融入的对话模型Table 6 Dialogue model for knowledge inclusion
4 未来展望
虽然关于知识驱动的对话生成模型研究已经取得一些成果,由于对话系统还可以向生成高质量和更加拟人化的回复发展,知识驱动的对话生成研究还有非常大的发展空间。随着对知识驱动的对话生成的深入研究与其他相关技术的发展,以下总结的几个方面可能是未来的研究方向:
(1)认知启发的知识表示方法:知识表示是认知科学、神经科学、心理学和人工智能都在关注的问题,本文可以借鉴其他相关领域的思想来设计一种认知启发的知识表示方法。因此,与其他学科进行交叉,借鉴其他学科的思想来设计一种认知启发的知识表示方法是未来研究方向。
(2)对话场景转移下的知识选择:在对话场景转换时,对于学习信息的需求因对话情境而异,这需要模型通过对外部知识中的学习内容进行选择,以获得更符合当前谈话环境的相关信息。在非任务导向的对话环境中,情境更加复杂多变,对话主体会随着会话进程的发展而不断变化,不同主体之间容易混淆,使得内容选择变得更加困难。当前的内容选择技术存在局限性,在遇到不同主题转变的对话情况下,模型缺乏逻辑推理功能,不能从当前对话中推断出正确的内容,导致对话模式无法产生高质量语句。因此,在主题转移等复杂对话场景中提升知识选择的方法是未来研究的方向。
(3)知识驱动情感对话生成:人们在交流信息的活动中,不但涉及文字与语言内容,也涉及到情感内容和情绪状态。对话系统的重要任务就是让机器人在回复用户时掌握人类的情感,而在交流过程中增加情感信息则可以增加使用者的信心,并且情感信息可以促使机器人与用户之间的沟通过程变得更加自然,加入情感信息后,模型回复后生成的语言也变得更加拟人化。现在的知识驱动的对话生成模型中并没有关注情感信息,如何将融入知识的情感信息加入到知识驱动的对话生成模型中是未来研究的方向。
(4)碎片化的知识融合使用:随着互联网的高速发展,信息能够被快速沟通与传播,能供人类使用的信息也就越多。在此情况下,信息通常是零碎的、离散的、杂乱的。部分信息存储在百度百科、维基百科之类的百科类型页面中,但还有很多信息都是包含在大量的非结构化文字中,比如关于知乎等问答社区上的问答内容,以及关于小红书等该类型社区的帖子内容。并且不同信息的内容的形式也不同,有些信息是离散的,有些是连续的。然而并不是所有能够理解的数据都是沟通所需要的,如何高效地控制和利用大量的碎片化数据,可以极大地提高沟通流程的可靠性,也可以增加模型的可理解性,这可能就是未来研究的方向。
(5)基于增量式学习的对话系统:现有语言模型可以生成非常流畅和自然的语言,但它们缺乏多样性和灵活性,而在对话中,多样性和灵活性非常重要。尤其是在处理开放域对话时,回答的多样性和灵活性可以提高对话质量和用户满意度。通过增量式学习动态地向模型中加入新信息和知识,使对话系统可以不断学习和进步,从而实现对话的多样性和灵活性,这可能是未来研究的方向。
5 总结
随着对话系统的发展,知识驱动的对话生成模型已经被越来越多的研究者们关注。生成高质量和更加拟人化的回复的知识驱动的对话生成模型是研究者们努力的方向。本文对知识驱动的对话生成模型研究展开综述,首先对现有的研究进行收集整理并总结出知识驱动的对话生成任务的定义,对构建知识驱动的对话生成模型遇到的问题进行描述;其次对现有的知识驱动的对话数据集进行了总结;针对知识驱动的对话生成模型的问题进行了回顾,包括知识获取、知识表示、知识选择和知识融入,对各个问题进行了相关研究的介绍,并提出了一些未来的发展方向。
