深度学习编译器模型训练负载均衡优化方法
2024-01-11赵雅倩李仁刚郭振华
王 丽,高 开,赵雅倩,李仁刚,曹 芳,郭振华
浪潮电子信息产业股份有限公司 高效能服务器与存储技术国家重点实验室,济南 250000
对于计算密集型的人工智能(artificial intelligence,AI)训练任务,随着AI算法模型参数从千万级增至千亿级,单个AI 硬件设备的算力和内存远远不能满足深度学习模型训练的需求,模型训练并行化成为增强其应用时效性的迫切需求。近年来面向AI分布式训练的硬件加速器层出不穷,如中央处理器(central processing unit,CPU)、图形处理器(graphic processing unit,GPU)、现场可编程门阵列(field programmable gate array,FPGA)、AI 芯片等,为AI 算法模型并行训练提供了硬件基础。同时,国内外研究人员也在致力于推出适用于不同应用场景的深度学习框架,主要 有TensorFlow[1]、PyTorch[2]、MXNet[3]、PaddlePaddle[4]等。随着深度学习框架和AI 硬件设备的持续多样化,单纯基于手工优化来实现AI 算法模型在深度学习框架和AI 硬件设备之间的高效映射,越来越容易出现性能瓶颈。
为了充分利用各种硬件资源,减轻手动优化每个硬件运行模型的负担,研究人员试图通过深度学习编译器解决框架的灵活性和性能之间的矛盾[5]。深度学习编译器的通用设计架构如图1所示,其主要功能是基于编译优化技术将不同深度学习框架描述的AI 算法模型在底层各种AI 硬件设备上生成有效的代码实现,并根据模型规范和硬件体系结构完成对生成代码的高度优化,解决了手工优化带来的AI模型的性能和效率问题。
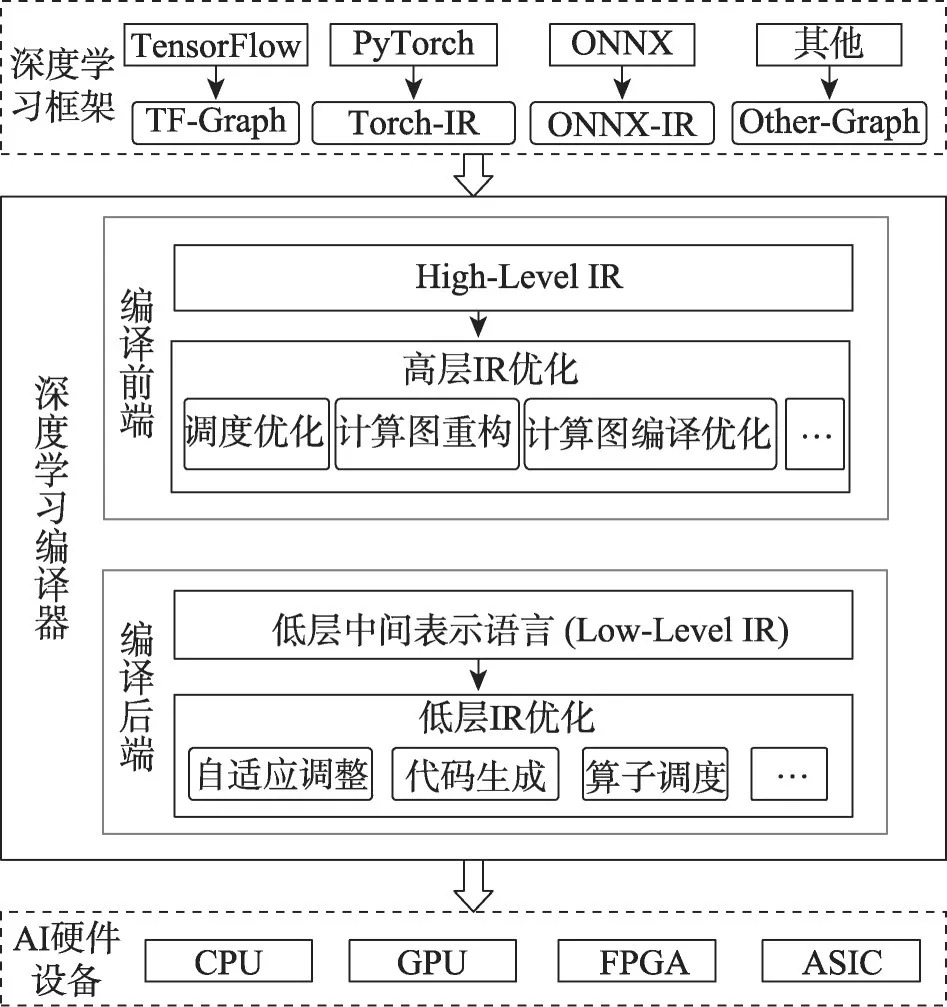
图1 深度学习编译器通用设计架构Fig.1 General design architecture of deep learning compiler
对于AI 模型并行训练,研究人员需要将计算任务映射到多个AI 加速设备上并行计算,基于深度学习编译器完成模型训练任务到底层硬件设备自动高效映射的同时,如何实现训练任务在多个加速器上的负载均衡,从而进一步提升训练效率,已经成为深度学习编译器面临的难点问题。当前,业界针对大规模AI 并行训练提出了各种并行优化方法,以提高模型训练的效率。其中PipeMare[6]、Wavelet[7]、Chimera[8]等基于流水并行优化方法尽可能减少训练过程中设备闲置时间,以提高硬件设备资源利用率;Taskflow[9]、Gavel[10]等通过设计不同的调度算法和策略,实现模型训练任务在多GPU 上的高效分配。但是,上述研究考虑了整体训练效率的优化,没有分析模型训练期间硬件设备之间的负载均衡问题,且主要面向深度学习框架进行,在当前的深度学习编译器中尚没有涉及。
本文致力于研究面向模型训练的深度学习编译器计算图负载均衡优化方法。目前业界已经提出几种主流深度学习编译器,例如Google XLA[11](accelerated linear algebra,加速线性代数编译器)、Apache TVM[12]和Glow[13]等,主要面向AI 应用进行图层级或算子级编译优化。其中,Google XLA 旨在为TensorFlow 提供后端的灵活性支持,其集成在TensorFlow内部,基于TensorFlow 前端接口实现对模型训练任务的支持,XLA 编译器支持算子融合等图层级优化,但对于流水调度、负载均衡等优化需要基于TensorFlow 的分布式训练策略实现;TVM、Glow 主要面向推理应用场景进行算子级编译优化,对于训练任务的支持处于开发阶段;nGraph[14]目前作为核心映射模块集成到Intel 高性能推理引擎OpenVINO[15]中,转向推理应用进行性能优化,不再支持AI 算法模型训练任务,因此,当前主流深度学习编译器均无法实现面向AI模型训练任务的图层级负载均衡优化。
针对以上问题,本文结合训练任务的性能瓶颈特点,提出面向模型训练的深度学习编译器计算图负载均衡优化方法,包括数据加载与模型训练的负载均衡优化设计、计算图分层调度优化设计以及计算图分层自动流水优化设计,完成了模型训练任务中CPU 与后端设备之间以及后端设备内部任务调度的负载均衡优化,从而提高了模型训练任务从深度学习框架到AI硬件设备映射的计算性能和硬件设备资源利用率,并提升了系统整体能效。本文的贡献主要有以下三点:
(1)提出数据加载与模型训练的负载均衡优化设计方法,为数据加载提供最优的并行线程数,在CPU 负载最小的情况下,实现数据加载与模型训练的负载均衡。同时,通过数据搬运与模型训练之间的多线程流水并行控制,掩盖计算设备等待数据搬运时间,提高模型训练任务的整体性能。
(2)提出计算图分层调度优化设计方法,通过启发式分层查找算法自动寻找计算图的分层和算子调度策略,得到计算图的最优分层,实现编译器中计算图在后端设备上的负载均衡,并通过子图并行调度,进一步提升了计算性能。
(3)提出计算图分层自动流水优化设计方法,提出分层后计算子图间的并行流水设计,解决训练过程中反向计算和参数更新的依赖,利用二分查找算法自动优化微批次划分,实现计算图分层流水并行计算,进一步提高计算过程中AI设备的资源利用率。
1 背景介绍
深度学习编译器前端优化是基于高层中间表示(intermediate representation,IR)的图层级优化,虽然不同深度学习编译器前端计算图在高层IR 的数据表示和算子定义上有所不同,但独立于硬件的前端优化均可以分为节点级、块级和数据流级三个层次,每个层次的优化方法都采用深度学习特有的编译优化技术,减少计算冗余,提高算法模型在图层级的性能。
节点级优化包括节点消除和张量消除优化方法,编译器根据计算图判断不参与计算的无用节点和张量,并进行删除[5,12]。块级优化包括代数简化以及算子融合、算子分解等神经网络相关优化方法,编译器分析计算图中各算子之间的基本运算关系,利用结合律、交换律等基本方式调整计算顺序,简化计算,执行算子融合,提升计算性能[16-17]。近期Rammer[18]、DNNFusion[19]、Unity[20]等工作将代数简化、算子融合、并行优化等技术结合,联合优化,加速了模型训练。数据流级优化包括公共表达式消除、数据布局转换、静态内存分配等优化方法[21],编译器基于公共表达式消除、死代码消除等数学优化尽可能减少重复和无用计算,并结合就地内存共享和标准内存共享的方式,执行静态内存规划优化,以实现内存缓冲区重用,Zhao 等[21]最新研究通过优化数据布局,消除通信过程中数据子集的相互移动,提升了模型训练过程中通信效率。
针对上述编译优化方法,各深度学习编译器具有不同的实现方式。表1 统计了面向AI 模型训练任务的深度学习编译器前端优化方法,以及主流深度学习编译器对各优化方法的支持。统计表明,现有深度学习编译器采用基本一致的编译前端优化方法,包括节点级优化、块级优化和数据流控制优化,而对于AI 算法模型训练过程中,需要考虑的计算图负载均衡优化并未涉及。

表1 编译器前端优化方法Table 1 Front-end optimization methods of compiler
为了实现深度学习编译器对模型训练任务的支持,进一步提升模型训练任务在编译器中的计算性能,同时降低系统整体能耗,本文提出了面向模型训练任务的计算图负载均衡优化方法。该方法从系统全局的角度对计算图进行分层划分,并且实现分层划分后计算子图间的流水并行调度,使得整个编译优化过程处于负载均衡状态,以提高AI 硬件设备的资源利用率,主要包括数据加载与模型训练负载均衡优化、计算图分层调度优化以及计算图分层自动流水优化。
数据加载与模型训练负载均衡优化主要是解决CPU上数据读取任务和后端AI硬件设备上模型训练任务之间的负载不均衡问题。一般通过开启多线程流水控制,掩盖数据读取的时间,以提高模型训练的性能和效率。AI 算法模型训练过程中,数据搬运的复杂度显著提高,容易带来计算开销无法覆盖传输开销的问题,因此数据加载也是影响整体训练性能的关键因素。OneFlow[22]在计算图中显式地表达数据搬运,将模型训练任务过程中的数据读取、数据传输等输入输出(input output,IO)操作封装成与计算图同一标准的计算子图,实现数据搬运与模型训练之间的自动流水并行控制,为深度学习框架在AI 模型训练中性能优化开启了新的思路;TensorFlow[1]通过建立文件名队列和任务队列,采用多线程流水控制的方式从文件名队列中读取图片数据,进行数据解析,并将解析后的数据加入任务队列中为训练任务提供输入数据,实现了数据加载与训练任务的并行流水。但是上述实现均没有考虑数据加载过程中的多线程数量优化问题,仅通过开启固定单线程或者最大线程数的方式实现数据加载与模型训练的流水并行,并没有解决数据加载与模型训练的负载均衡问题,容易带来AI 设备资源的利用不均衡,降低AI算法模型的训练效率。
计算图分层调度优化以及分层自动流水优化属于计算子图在后端设备上调度的负载均衡优化。Xiao、Woo 等[23-24]提出面向分布式训练的GPU 并行调度系统,旨在提高大规模分布式集群中模型训练的GPU 设备资源利用率,但以上研究主要针对数据并行训练任务;Gpipe[25]、DAPPLE[26]、Chimera[8]等工作提出细粒度流水并行优化设计方案,尽可能减少流水并行训练过程中GPU 设备空闲时间,提高硬件设备资源利用率以及模型训练性能。但在当前的深度学习编译器系统中,调度优化主要涉及内存调度以及硬件指令相关的循环调度,在编译前端对计算图进行模型并行训练相关的计算图分层和流水并行调度优化在当前主流深度学习编译器中尚未涉及。
2 计算图负载均衡优化
为了充分利用深度学习编译器后端各种AI硬件资源,满足计算密集型模型训练任务的算力需求,研究人员需要采用大规模AI硬件协同计算提高模型训练速率,实现模型训练任务到底层硬件设备的高效映射。目前单一的局部优化算法能够带来局部性能提升,但系统整体的计算负载难以达到均衡状态,导致AI 设备加速器计算效率低下,降低了AI 计算平台的硬件资源利用率。
本文从编译器系统全局负载均衡的角度出发,针对目前主流深度学习编译器有限支持模型训练任务,以及模型训练过程中设备之间和设备内部资源利用不均衡等特点,搭建了面向AI 模型训练的深度学习编译器框架,并提出了计算图负载均衡优化策略,主要包括以下两个方面:第一,通过数据加载与模型训练的负载均衡优化技术提供数据读取阶段最优并行线程数,实现CPU 上数据加载任务和后端设备上模型计算任务之间的负载均衡;第二,通过计算图的分层调度优化以及多级分层后的自动流水优化技术实现计算图在后端设备内部调度的负载均衡。
2.1 面向模型训练的深度学习编译器
本文首先搭建自研深度学习编译器Mofang。Mofang 是基于开源编译器nGraph[14]开发的一套面向模型训练任务的深度学习编译器框架,主要实现模型训练任务从编译器前端到编译器后端AI硬件设备的解耦化映射,其前端支持Tensorflow、PaddlePaddle、ONNX 格式训练模型的导入,后端支持Intel CPU、NVIDIA V100 GPU以及F10a FPGA加速设备。
Mofang 充分利用nGraph 提供的框架bridge(转换层)解耦机制,通过bridge 层将不同框架的AI 算法模型输入转换至使用其高层中间表示语言描述的统一格式(High-Level IR),并对其进行硬件无关的优化,实现了计算图重构。由于nGraph 由同时支持训练和推理的软件生态,改变为只支持推理任务,且移除了分布式通信接口,本文基于nGraph 添加CPU、GPU、FPGA等AI硬件加速设备的分布式通信算子接口,并集成OpenMPI、NCCL等优化版的通信算子库,实现了深度学习编译器对AI 分布式训练任务的支持,Mofang整体实现架构如图2所示。
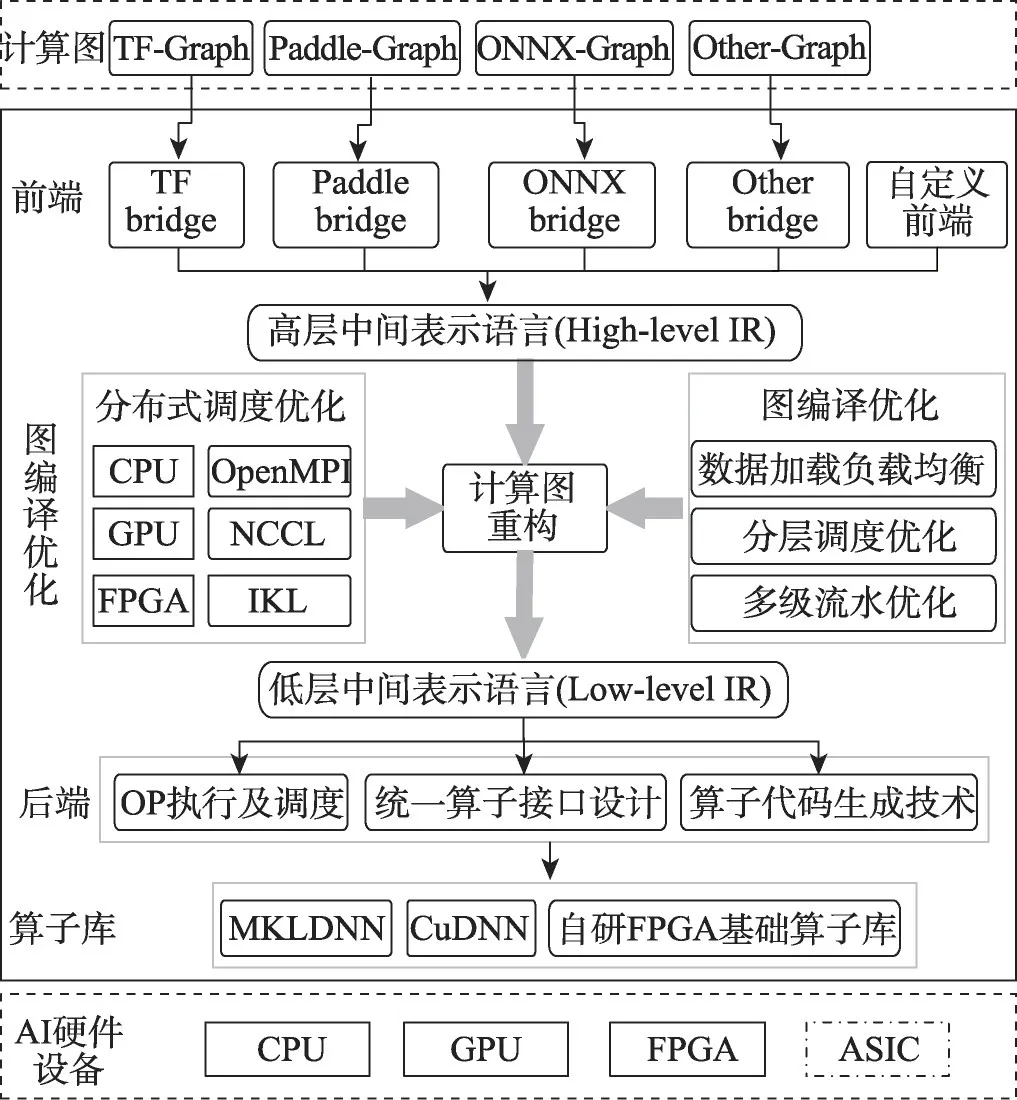
图2 Mofang深度学习编译器整体架构Fig.2 Overall architecture of Mofang deep learning compiler
为了提升模型训练的性能以及后端设备资源利用率,本文在Mofang 框架中实现了数据加载与模型训练的负载均衡、计算图分层调度以及分层后自动流水优化等编译优化技术,其中数据加载与模型训练的负载均衡优化在Mofang 自定义前端实现,计算图分层以及分层后自动流水优化基于Mofang高层中间表示实现。
2.2 数据加载与模型训练的负载均衡
本节首先分析了目前深度学习框架中数据加载和模型训练任务之间的调度流程。为了解决数据加载的性能瓶颈问题,现有框架通常在CPU 上开启多线程并行读取数据,以提高数据加载的效率,使其能够满足模型训练过程的数据读取需求,数据加载与模型训练两个阶段通过建立数据队列缓存的方式实现流水并行执行,主流深度学习框架TensorFlow 中数据加载与模型训练流水并行的实现流程如图3 所示。TensorFlow 数据加载过程首先建立文件名队列和数据队列,由左至右分为文件名获取、写入文件名队列、按照文件名读取数据、解析数据、将数据写入数据队列五个阶段。其中按照文件名读取数据和解析数据的过程采用启动固定数量的CPU 线程的方式并行执行,以保证数据读取和解析的速率能够满足训练任务获取数据的需求,训练模块只需要按照流程从数据队列中读取解析后的数据,执行计算过程,减少了训练阶段等待数据加载的时间消耗。
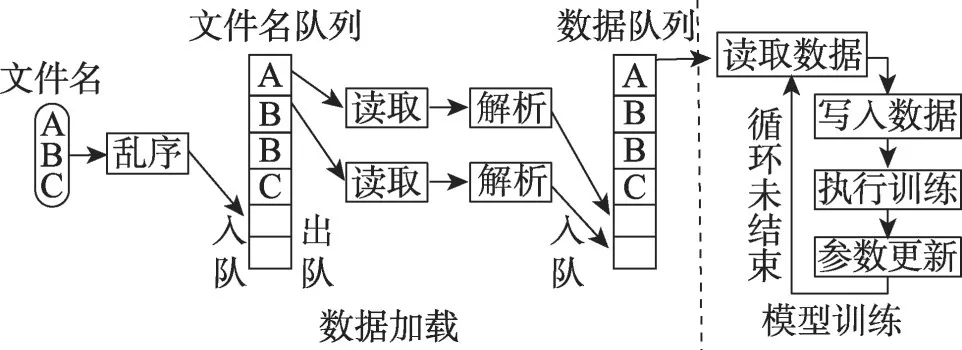
图3 TensorFlow深度学习框架中的数据加载Fig.3 Data loading in TensorFlow deep learning framework
对于不同的模型训练任务,模型训练性能存在较大的差异,单纯开启固定线程数进行数据加载的方式容易导致数据加载与模型训练任务负载不均衡。例如,当数据加载速度过快,超过模型训练模块的数据读取需求时,会导致数据队列缓存溢出;而数据加载过慢,不能满足模型训练模块的数据读取需求时,会出现训练过程等待数据的问题,降低了训练性能。
本文测试了在CPU 上开启不同数量的线程时数据读取模块的性能,统计结果如表2所示。线程开启数量与读取性能在一定范围内呈现线性增长的趋势,但是当开启最大CPU线程数64时,数据读取解析性能呈现下降趋势。这是因为此时开启最大的线程数,会占用更多CPU 硬件资源,影响系统整体运行,导致数据读取性能下降。

表2 线程数量对数据读取性能的影响Table 2 Impact of the number of threads on data read performance
TensorFlow 等深度学习框架通过人工经验去定义各个阶段的线程数量来实现流水,最常用的方式是针对性能瓶颈模块开启最大线程数来提高整体性能。根据表2统计结果,开启最大线程数的方式容易导致占用过多CPU 资源,存在大量的资源浪费,而且会影响其他程序运行。因此在实际模型训练任务中,需要根据不同的数据批处理大小(batch_size)、AI硬件设备类型以及AI硬件设备数量等对性能瓶颈阶段设置不同的线程数量,才能够使整个系统的流水处于负载均衡状态,提高硬件资源利用率。通常情况下,训练时batch_size越大,使用的硬件设备数量越多,阶段3 模型训练的性能就会越高,因此在CPU 上需要开启的处理数据读取的线程数量越多。
为了更直观地分析数据加载与模型训练过程的整体性能瓶颈,本文对整个过程进行多阶段划分,如图4 所示。数据加载与模型训练过程主要分为三个阶段,其中阶段1 为文件名读取,阶段2 为数据的读取解析,阶段3为模型训练。目前主流深度学习编译器中,阶段1 和阶段2 以多线程的方式运行在CPU 处理器上,第三阶段模型训练过程经过前端和后端优化后运行在编译后端AI 硬件设备上。在AI 模型训练任务中,数据读取阶段的耗时最多,容易成为整个流水过程的性能瓶颈;而不同的优化方法以及AI 硬件设备对阶段3模型训练的性能影响较大,容易导致三个阶段的负载不均衡。

图4 数据加载与模型训练阶段划分Fig.4 Data loading and model training phase division
针对上述问题,本文针对深度学习编译器的自定义前端提出一种自动调整线程数量的方法,进一步优化数据读取解析阶段的线程数量,从而实现三个阶段的负载均衡。
本文提出反向查找的方法自动寻找数据读取阶段线程的最优配置,即找出整个系统达到最佳性能时数据读取阶段需要开启的最少线程数量。假设当数据批处理大小为batch_size时,第三阶段经过特定后端优化之后的预估时间为T3,第二阶段每个线程处理一个数据的预估时间为T2,第一阶段的预估时间为T1。假设CPU 的最大线程数量MAX_thread,线程加速比为∂n,如果第二阶段在CPU上开启了n个线程,在流水执行状态下,那么整个系统的消耗时间就是执行时间最长的阶段的时间,如式(1)。因此,本文研究如何开启最少的线程数,即n尽可能得小,使得整个系统的时间T最小。系统整体时间T的计算公式如下所示:
由于在batch_size固定时,对于同一种AI加速器,T1和T3是固定的,对于式(1),变形后有:
要使得T最小,则有:
在满足式(4)下选取n的最小正整数即是最优解。
通过上述方法选取的数据读取阶段的线程数,能够在满足第三阶段模型训练数据读取需求的同时,尽可能地节省CPU的资源占用,使得CPU在负载最小的情况下,数据加载与模型训练两个阶段的任务达到负载均衡的状态,即提高了CPU 的资源利用率,减少CPU资源浪费,进一步节省了系统的能耗。
2.3 计算图分层调度优化
深度学习编译器中模型训练通常以计算图的方式在后端AI 硬件设备上进行调度,由于计算图参数逐渐增大,算子间依赖关系愈加复杂,容易出现算子调度不均衡,模型训练过程中后端设备资源利用率波动较大的问题[27]。传统的顺序调度算法、贪心调度算法以及算子的变形融合优化(TASO(tensor algebra superoptimizer for deep learning)[28])技术都存在算子调度不均衡的问题。本文提出了计算图的分层调度优化算法重新规划算子间依赖关系,使得计算图每个阶段算子的调度达到负载均衡状态。
本文以InceptionV3 的部分网络结构(图5)为例说明不同的调度算法对算子调度顺序以及设备利用率的影响。该网络结构包括五个卷积操作,每个卷积的通道数和卷积核大小不尽相同。图6 展示了深度学习编译器常用的卷积算子的变形融合优化,首先通过补零扩展卷积核的方式把1×1 的卷积扩展为3×3的卷积如图6(a)所示,再通过简单堆叠的方式把具有同样卷积核的Conv(a)、Conv(b)和Conv(d)三个卷积合并为一个卷积Conv(a)(b)(d)。合并后的网络结构如图6(b)所示,卷积合并优化之后需要增加一个split 算子,用来处理合并算子的输出,优化之后的计算图在执行过程中减少了两次内核的启动,能够获得相应的性能提升。
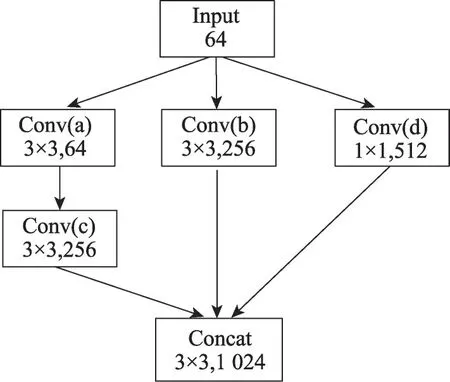
图5 InceptionV3模块Fig.5 InceptionV3 module
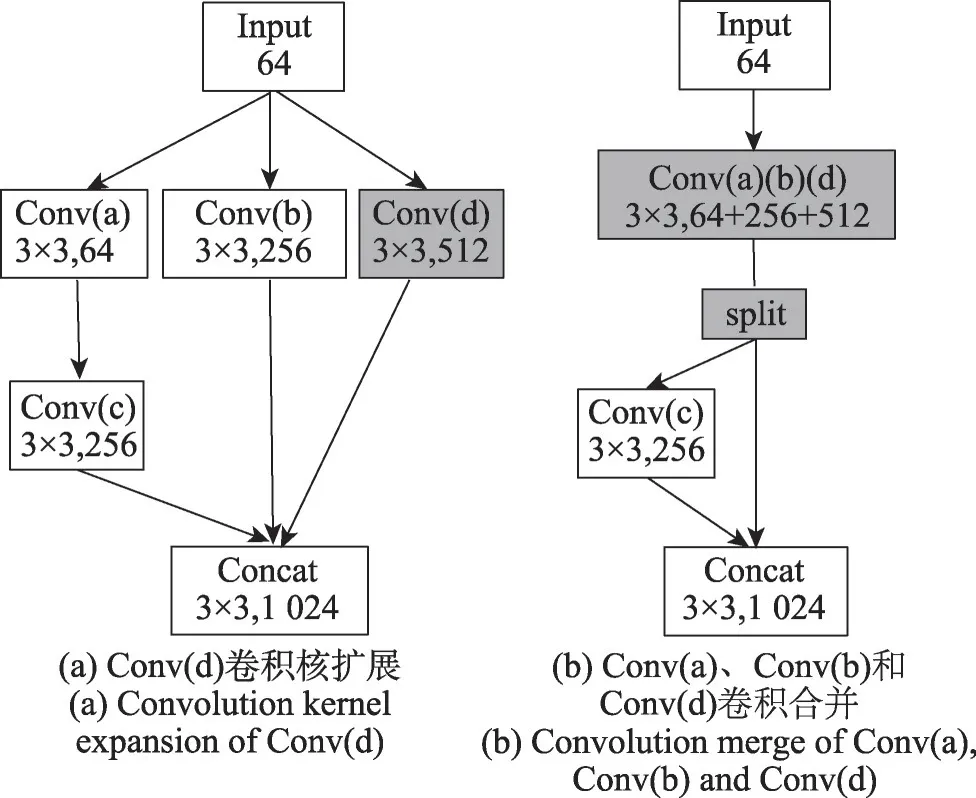
图6 深度学习编译器卷积算子合并优化Fig.6 Deep learning compiler convolution operator merging optimization
本节首先基于传统深度学习框架使用的贪心算法进行算子变形融合优化前后,AI 硬件设备的资源利用率分析。基于算法原理,贪心算法每次将最大限度地调度可调度的算子,而不考虑算子的负载均衡问题。在原始的网络结构中(图5),Conv(a)、Conv(b)、Conv(d)同时获取输入数据,不存在依赖关系,因此在第一阶段,贪心算法会同时调度Conv(a)、Conv(b)和Conv(d)三个算子,此时三个算子的调度存在激烈的资源竞争,GPU 的资源利用率会达到顶峰;而在第二阶段只调度Conv(c)一个算子,由于计算量小,GPU的利用率大幅降低,导致GPU 硬件资源利用不足,存在资源浪费。
经过卷积算子变形融合技术优化后,贪心算法在第一阶段会调度合并后的算子Conv(abd),由于该算子通道数量合并为三个卷积的通道数量之和,在调度该算子时同样会占用大量的GPU 内存资源,第二阶段调度的算子也只有一个,同样会由于Conv(c)算子的计算量小,导致资源利用率不高。因此,算子变形融合优化不能解决计算图前后算子的调度不均衡问题。
基于以上问题,本文提出算子分层调度优化策略,该策略重新定义算子的调度依赖关系,使整个计算图的调度达到均衡状态,如图7所示。首先根据计算图卷积算子的数据依赖关系,对计算图执行分层操作,算子Conv(a)和算子Conv(d)为第一层,算子Conv(b)和算子Conv(c)为第二层;然后根据算子卷积核和通道数等参数特点,将第一层中的算子Conv(a)和算子Conv(d)进行算子变形融合优化,形成合并算子Conv(a)(d)。为了提高第二阶段AI 设备的资源利用率,将第二层的算子Conv(b)和算子Conv(c)执行并行计算,计算图第一层和第二层由于存在数据依赖关系,执行串行调度。
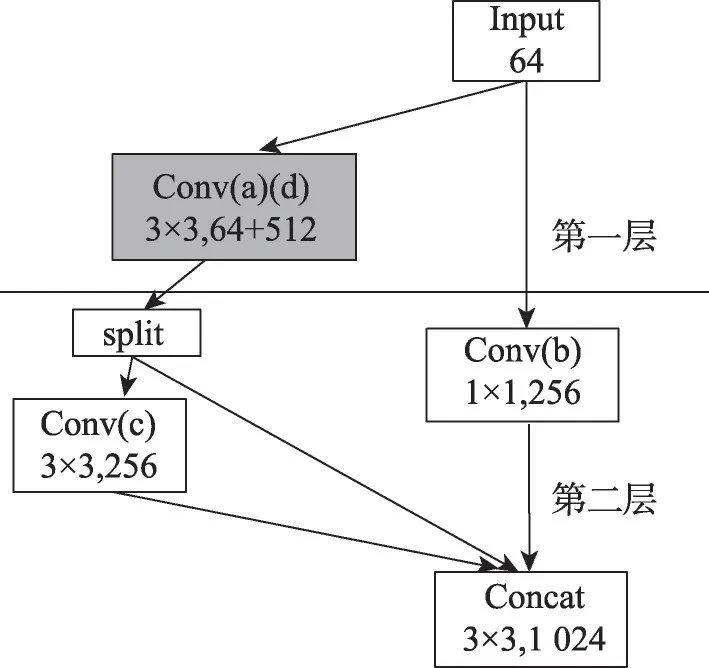
图7 算子分层调度优化策略Fig.7 Operator hierarchical scheduling optimization strategy
为了保证层与层之间的串行调度,本文在层之间增加新的result节点,插入result节点后的整个计算图如图8所示,该节点负责上一层计算结果的汇总和下一层输入数据的分发。

图8 插入result节点增加层间依赖后的计算图Fig.8 Calculation graph after inserting result node to add interlayer dependencies
为了解决复杂计算图中,计算图高效分层划分问题,本文提出了一种启发式分层查找算法,自动计算查找计算图的最优分层策略。假设计算图G的所有算子节点集合为V,从V的顶点开始按照算子依赖遍历整个计算图,得到一个子集U,子集U将V分成U和V-U两部分。计算图的最优调度延迟用cost来表示,那么状态转移公式为:
即V的最优延迟是所有可能分层U的延迟和剩余顶点集V-U的最优延迟之和的最小值。
对于每一种可能的分层U,给出一个启发式评价函数来评估分层的好坏。该启发式函数如式(6)所示,通过计算分层后的两层的计算量差别来评估分层结果的质量。
其中,com(U)为分层U的计算量。
具体来说,整个分层包括以下实施步骤:
(1)枚举计算图V所有可能的算子分层{U0,U1,…,Um}。
(2)根据启发评价函数τ计算所有可能分层的评估指标,按照指标由小到大排序,设定阈值φ,若对于Ui,τi>φ,则删除对应的分层Ui,得到新的集合{U i,Ui+1,…,Uj}。
(3)通过仿真模拟预估出每层的耗时,划分后的每层都有两种调度策略:贪心调度和顺序调度。根据预估结果选择耗时较小的调度策略。预估每层的时间消耗时,将每层的输入I、层的图结构G、调度策略S作为输入参数,该层的耗时T为在某种调度策略下完成整个层计算的时间。
(4)根据分层后的模拟预估数据,选择出两层耗时之和最小的分层{Uk},将该分层结果{Uk}作为第一次分层的最优结果。
(5)对于(4)得到的最优分层[Uk,V-Uk]。将Uk和V-Uk分别赋值给V,重复(1)(2)(3)(4)。
(6)若分层之后的所有可能分层的耗时之和都大于未分层前耗时,即∀Ui∈{Ui,Ui+1,…,Uj},cost(V-Ui)+cost(Ui)≥cost(V),则分层结束。
图9是启发式分层的流程示意图,首先从第一个节点a开始广度优先遍历,遍历过程中需要保证图的连续性,禁止跳跃节点。枚举出所有可能的分层U∈{{a},{a,b},{a,c},…,{a,b,c}}。通过启发式评价函数得到不同分层的指标{τ1,τ2,…,τm},通过τi>φ条件剔除评价较差的分层得到子集{τ2,τ3}。对子集中所有可能的分层结果,通过仿真模拟预估出每种情况下的调度耗时cost(U)和cost(V-U)。最后选择耗时之和最小的分层,即完成第一轮分层。完成第一轮的最优分层之后,分别对U和V-U重复上述过程。直到下一次所有可能的分层预估耗时之和都不小于未分层之前的耗时,此时结束整个分层优化,详细流程见算法1。
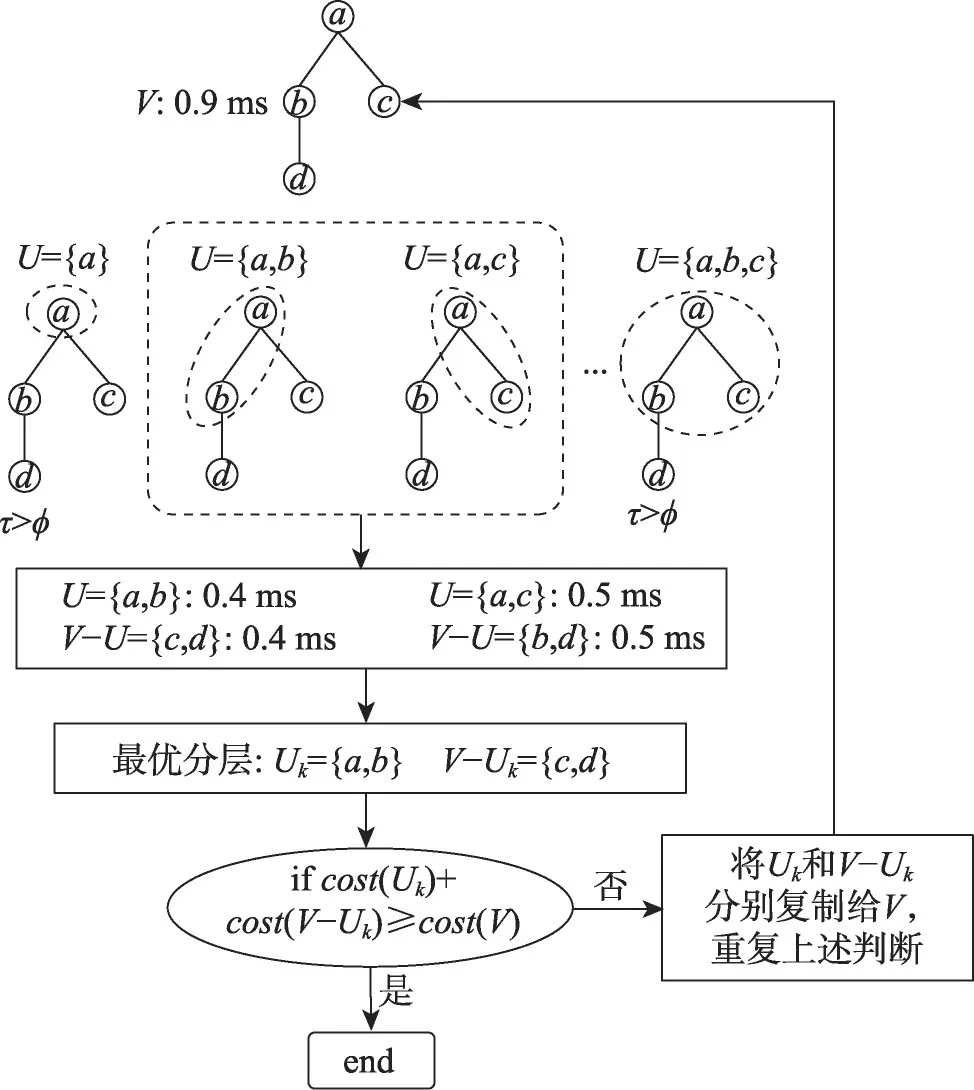
图9 启发式分层查找算法Fig.9 Heuristic hierarchical search algorithm
算法1启发式分层查找算法
启发式分层查找算法的主要计算量集中在寻找计算图的所有可能分层上,本文进一步分析评估启发式查找算法的时间复杂度,以更直接地统计计算图可能分层的数量。本文给出以下定义:计算图的宽度w,即在图中可以找到最多w个算子同时并行执行;计算图的长度h,即在图中能够找到最多h个算子必须串行执行。
通过设置合适的启发式评价函数的阈值,可以降低启发式搜索算法的复杂度,假设通过启发式函数剔除一半的可能分层,则算法的时间复杂度降低为O((N/w+1)w)。
为了更好地评估启发式分层查找算法自动寻找计算图分层调度优化策略的执行效率,本节分析了典型神经网络模型的时间复杂度和经过启发式算法优化之后的时间复杂度,结果如表3所示。数据分析显示启发式分层查找算法可以大大降低搜索的复杂度。
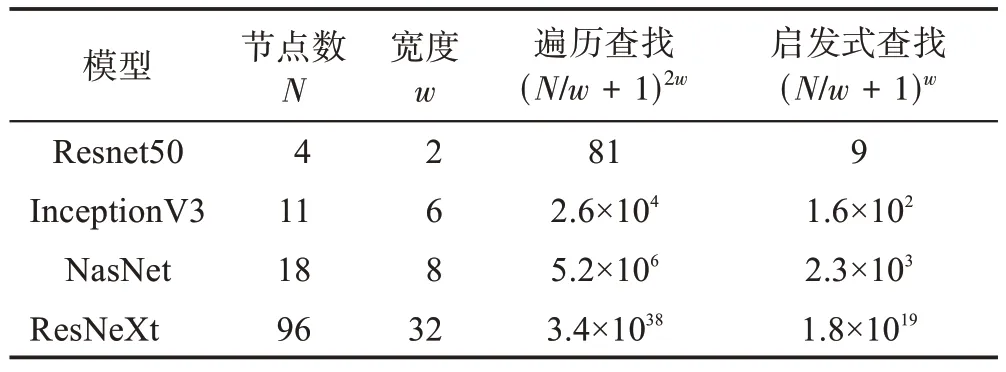
表3 不同模型的时间复杂度Table 3 Time complexity of different models
2.4 计算图分层自动流水优化
计算图分层调度策略可以有效地优化算子的调度顺序,减缓后端设备利用率的波动。深度学习编译器中计算图在经过分层调度优化之后,每层的计算量分布相对均衡,模型训练过程中后端设备的利用率趋于平稳,但是远远达不到100%。
为了进一步提高编译器后端设备的资源利用率,本文基于分层调度优化提出了多级自动流水优化策略。通过在层与层之间添加多个Result 数据缓存节点,实现层与层间的流水计算,如图10所示。首先在层与层中间添加两个Result 节点Result0 和Result1。模型训练过程中,在T0阶段,第一层读取第一批次数据(Batch_0)进行计算,并把计算好的结果传递给Result0 节点;在T1 阶段,第二层读取Result0的数据进行第二层的计算,同时第一层读取第二批次输入数据(Batch_1)进行计算,并将计算结果传递给Result1,为下一阶段的第二层计算提供输入数据;第二层只需交替从Result0 和Result1 节点读取输入数据。因此在计算图划分为两层的情况下,从T1 阶段开始,计算图第一层和第二层即可实现层间流水计算,后端设备需要同时计算第一层和第二层,进一步提高了硬件设备的资源利用率。
当计算图在经过分层调度优化之后被划分的层数较多时,如果直接进行流水并行,会带来设备的超负载问题,如图11 所示。计算图被划分为6 层,且每一层单独运行时设备的利用率分别为:0.5、0.4、0.3、0.4、0.5 和0.4,如图11(a)所示,在没有流水的情况下,各层依次执行计算任务,设备的利用率十分平稳。当6层的计算实现完全流水时,设备资源理论利用率理论上应该达到250%,如图11(b)所示。此时设备资源已经不能满足计算需求。

图11 计算图分层流水效果Fig.11 Pipeline result after layering of calculation graph
本文设计多级自动流水策略,通过重新划分流水级解决设备的超负荷问题,如图12 所示。首先将计算图的分层划分为多级流水,每一级流水包含计算图的多个分层,其中流水级内的分层串行执行,每级流水中设备的利用率为该级流水所包含的分层在单独计算时设备利用率的最大值。达到完全流水状态时,设备性能为所有流水级的性能之和,没有超过100%。
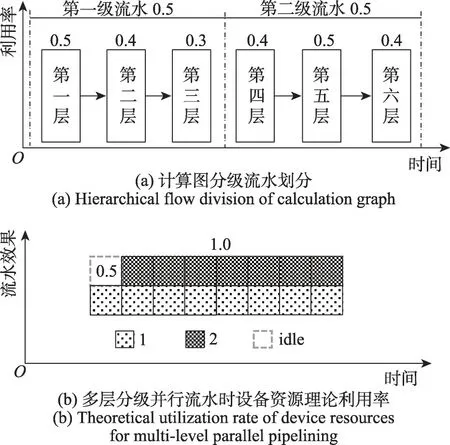
图12 多层次合并分级流水效果Fig.12 Pipeline result after multi-layer merging and grading
本文基于Gpipe[25]微批次划分的方法和多级流水策略,在编译器中实现AI模型训练流水并行优化,利用多级流水策略确定了流水级之后,设置合理的微批次划分来构建流水。
本文通过建立流水级长度和微批次数量之间的关系对Gpipe 中的微批次划分方法进行优化,得到最优的微批次划分策略。当计算图的流水级较少时,流水建立过程耗时较短,如果划分的微批次数量太多,则会导致划分后的微批次(micro_batch)太小影响性能。当计算图的流水级较多时,如果微批次数量较小,则无法充满整个流水线,因此需要划分足够的微批次数量来掩盖流水建立的时间消耗。由于每次训练时总的批次大小是固定的,微批次数量越多,微批次数据就越少,设备的利用率就会变低。因此在微批次划分时,在保证流水建立的情况下,要尽可能地增大微批次的大小,即选取满足流水建立的最小的微批次数量。
假设流水建立时间占比为Ppipe(batch_num),设备利用率损耗为Dloss(batch_num),微批次数量为batch_num,则batch_num需要满足式(7):
满足式(7)的batch_num能够使设备间的流水效果和设备的利用率达到一个均衡的状态,进而整个系统的性能达到最优状态。假设总的处理批量大小为batch_size,设备最大处理批次为batch_device,流水线长度为pipe_num。流水线建立的时间占比为:
式(7)~(9)联合计算得到batch_num,划分后的微批次大小可以通过式(10)计算得到:
最后为了使计算得到的micro_batch为整数,需要对每个micro_batch进行±1微调。
本文通过微批次二分查找法得到batch_num的最优解。batch_num的求解空间为大于1,小于batch_size的正整数,即{1,2,…,batch_size-1,batch_size},通过算法2 在解空间查找得到最优解batch_num。假设模型训练每次处理的总批量batch_size为256,GPU 处理的最大的batch_size为64,对于不同的模型计算得到最优的微批次的划分策略,如表4所示。
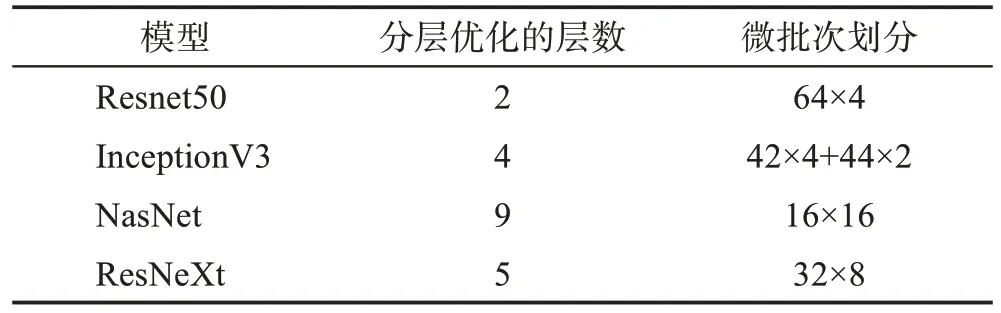
表4 不同模型的分层优化和微批次划分Table 4 Hierarchical optimization and micro-batch partitioning for different models
算法2微批次二分查找法
3 实验
针对AI 模型训练应用任务调度负载均衡,本文提出了三种计算图负载均衡优化方法,在深度学习网络模型训练过程实验中得到了有效的验证。实验环境采用AGX-2 GPU服务器,每台服务器上配置了16块TeslaV100板卡。其他硬件环境配置如表5所示。

表5 硬件环境配置Table 5 Hardware environment configuration
软件环境方面,本文采用2.1 节介绍的自研深度学习编译器Mofang进行计算图负载均衡优化整体实验及性能测试。
3.1 线程数对数据加载的影响
为了更直观地对比数据加载与模型训练的负载均衡优化对训练性能的影响,本节首先基于Image-Net2012 数据集测试了Resnet50 和Resnet18 模型训练时的数据加载、模型计算以及整体训练的性能,同时测试了开启不同数量的数据加载线程对训练性能的影响。
图13 显示了数据加载线程数量对Resnet50 模型训练性能的影响,结果显示数据加载模块开启线程数量的多少不仅影响模型训练的性能,还会影响CPU 的能耗。对于Resnet50 模型,模型计算操作运行在GPU 上,性能稳定且与数据加载线程数量无关;对于数据加载和整体训练过程,当线程数开启到16之前,数据加载和模型整体训练性能随着线程开启数量的增加而线性增加,这是因为此时数据加载依然是整体训练的性能瓶颈,因此增加线程数提高数据加载速率能够提升整体训练的性能;当线程数开启到16 时,数据加载的性能已经足够满足模型计算的需求,继续增加开启的线程数,整体训练性能不再提升,处于平稳状态,造成了CPU资源浪费。

图13 Resnet50训练时线程数量对性能的影响Fig.13 Effect of the number of threads on performance of Resnet50 training
图14 显示了线程数量对Resnet18 模型训练性能的影响,由于模型参数量较小,模型计算性能较高,无论开启多少线程数量,数据加载的性能都无法满足模型计算的性能需求,同时可以看到当数据加载开启最大线程数量时,数据加载的性能会降低,这是因为开启的线程数量过多,线程间存在资源竞争。此时本文启发式查找算法自动寻找的最佳线程数量为48,既能保证数据加载的性能最好,又可以降低CPU的利用率。
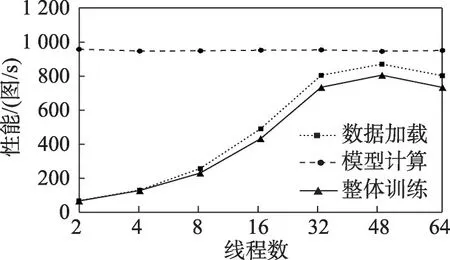
图14 Resnet18训练时线程数量对性能的影响Fig.14 Effect of the number of threads on performance of Resnet18 training
3.2 数据加载与模型训练负载均衡优化
为了验证数据加载与模型训练负载均衡优化技术的可扩展性,本文采用Resnet50网络模型和ImageNet 2012训练数据集在多GPU板卡上进行了分布式训练的验证。本实验分别测试了不同Batch_size 和不同GPU 板卡数量下数据加载与模型训练负载均衡优化技术对模型分布式训练性能的影响。
图15 对比了不同GPU 板卡数量下加入负载均衡优化技术的Mofang 框架、TensorFlow 框架以及TensorFlow经nGraph编译器映射后(TF-ngraph)的分布式训练性能。结果显示,随着GPU 板卡数量的增加,三种框架中模型的分布式训练的性能均呈现线性增加的趋势,而本文加入负载均衡优化技术的Mofang 框架性能与TensorFlow 和TF-ngraph 框架相比,提升3%左右。

图15 GPU数量对负载均衡优化性能的影响Fig.15 Effect of the number of GPU on performance of load balancing optimization
图16 对比了不同batch_size 对加入负载均衡优化技术的Mofang 框架、TensorFlow 框架以及TFngraph 的分布式训练性能的影响。实验结果表明在不同的batch_size下负载均衡优化后的性能比另外两种框架有2%到8%的提升,在batch_size=2 时性能的提升更加明显,可以达到8%左右。这是由于batch_size较小,每次模型训练需要加载的数据量小,在CPU 可以开启足够的线程来处理数据加载模块;而随着batch_size 增大,数据加载模块需要开启的CPU 线程就越多,超出CPU负载时会存在一定的性能损耗。
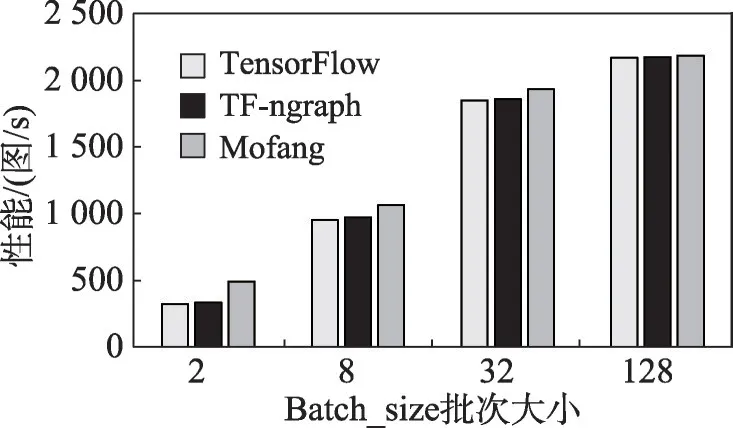
图16 Batch大小对负载均衡优化性能的影响Fig.16 Effect of batch size on performance of load balancing optimization
3.3 计算图分层调度优化
本节基于TensorFlow+Mofang 框架对计算图的各种调度进行了实验分析,计算图经过不同的调度优化后在TeslaV100 GPU 上进行调度执行,不同的调度模式对应算子不同的调度顺序。首先在TensorFlow 中构建计算图,并人为增加算子调度依赖或者算子优化,在确定算子的调度顺序之后分别在GPU平台上执行优化后的计算图,并统计各个阶段的耗时和资源占用。
图17 展示了利用传统贪心算法进行计算图算子调度时GPU 的资源利用率测试结果。数据显示,第一阶段由于同时调度三个算子Conv(a)、Conv(b)、Conv(d),此时GPU 板卡的资源竞争剧烈,GPU 的资源利用率达到95%,第二阶段只调度Conv(c)算子,GPU 的利用率只有20%左右,第一阶段和第二阶段的任务负载存在严重失衡的现象。图18展示了经过算子合并优化后GPU 的资源利用率测试结果,数据显示,第一阶段需要执行合并后的(abd)算子,虽然只有一个算子,但该算子计算量并未减小,由于算子合并后内核启动次数减少GPU 利用率降为90%左右,第二阶段同样调度Conv(c)算子,资源利用率同样为20%。综上,算子合并优化技术没有解决GPU 资源负载均衡问题。
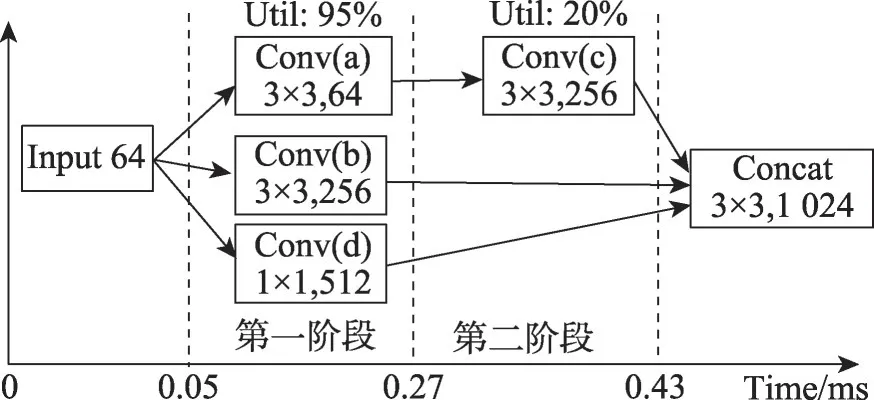
图17 贪心算法实现算子调度时的资源占用分析Fig.17 Analysis of resource occupancy when greedy algorithm implements operator scheduling

图18 算子合并优化后资源占用分析Fig.18 Analysis of resource occupancy after operator merging optimization
图19 展示了经过计算图分层调度优化后,各层的资源利用率和执行时间。由于第一层的算子数量由原来的三个算子Conv(a)、Conv(b)、Conv(d)减少为一个合并算子Conv(ad),GPU 的利用率由90%降为70%,执行时间由0.2 ms 降为0.16 ms。第二层由调度一个算子Conv(c)变成同时并行调度两个算子Conv(c)和Conv(b),GPU 利用率由20%升为50%,执行时间由0.16 ms 上升为0.18 ms。但是整个计算图的执行时间由0.36 ms 减小为0.34 ms。因此经过图分层优化之后的算子调度更加均衡,GPU 的资源利用率在各阶段也更加平稳,同时进一步提高了计算性能。

图19 计算图分层调度优化后的资源利用率Fig.19 Resource utilization after optimization of hierarchical scheduling of computational graphs
3.4 计算图分层自动流水优化
本节基于Gpipe 微批次划分流水算法与本文的分层自动流水算法进行对比测试。图20 为Gpipe 流水示意图,此时微批次划分数目为4,流水级为5。从图中可以看出,整个流水计算过程中由于流水级划分过多导致流水建立时间较长,设备空闲等待的时间占比超过了50%,大部分时间GPU 都处在空闲的状态,带来了资源的浪费。
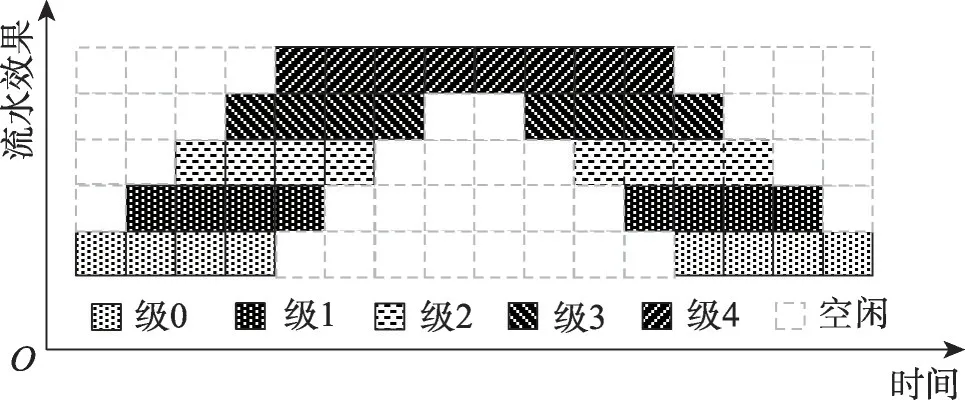
图20 微批次数目为4,5级流水的Gpipe流水效果Fig.20 Gpipe pipeline results with the number of microbatches of 4 and 5-level flow
图21 展示了经过分层多级自动流水优化和微批次数目划分优化之后的流水效果。相比Gpipe,流水级由5 级合并为3 级,微批次划分的数量由4 增大为通过微批次划分查找算法自动查找得到的6,从图中可以看出流水过程中设备空闲的时间占比由原来的高于50%降低为25%左右。
为了更好地评估本文中的三种优化技术对不同模型训练性能的影响,本节选取两种不同类型的深度学习网络模型进行实验验证和性能对比:一种是并行分支较少的网络模型,比如Resnet50;第二种是并行分支较多的模型,比如InceptionV3、NasNet、ResNeXt 等。本文分别在上述两种不同类型的模型中进行了数据加载与模型训练负载均衡优化、计算图分层调度优化和计算图分层自动流水优化,并与TensorFlow、TensorFlow-XLA、TensorFlow-ngraph 等未进行相关优化的深度学习框架或编译器进行性能对比。
图22 展示了归一化后四种模型经过数据加载与模型训练负载均衡优化、计算图分层调度优化和分层自动流水优化后的性能。实验结果表明两种不同种类的深度学习网络模型在经过本文提出的三种优化之后模型训练的性能均有所提升,由于不同类型的模型中并行分支数量不一样,性能的加速比也有所不同。对于Resnet50模型,由于该网络模型具有较少的并行分支,分层优化和自动流水方法取得的性能提升只有2%左右;对于InceptionV3这种具有较多分支并行的模型,单独的分层优化方法就可以达到5%以上的性能提升,将分层优化和自动流水两种优化方法结合使用时,相比其他网络模型训练框架性能提升达到10%左右。最终,本文将三种优化技术在Mofang 中同时使用,相比TensorFlow 深度学习框架,Mofang可以提升5%~15%的训练性能。
3.5 资源利用率
为了更好地验证本文提出的计算图分层调度优化方法可以实现计算图算子间的均衡调度,提高设备资源的利用率,本实验在InceptionV3 网络模型训练期间使用自研工具Gsee 实时获取GPU 板卡的资源利用率数据。
图23 统计了InceptionV3 网络模型训练过程中分层优化前后的GPU 板卡利用率。从实验结果可以看出未经过分层优化前,GPU 的板卡资源利用率波动较大,最大值可以达到95%,最小值为20%,存在严重的资源利用率不均衡问题。经过计算图分层调度优化后,每个阶段的算子的调度相对均衡,GPU板卡的资源利用率稳定在50%~60%,在经过多层分级流水优化之后GPU 板卡的设备利用率均达到90%以上。
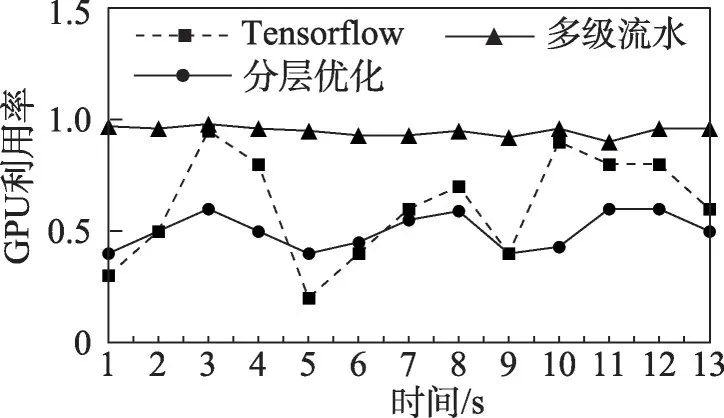
图23 InceptionV3训练过程中GPU板卡利用率对比Fig.23 Comparison of GPU utilization during InceptionV3 training
3.6 系统能耗分析
本节实验使用系统采样的方法统计整个训练过程中CPU 和GPU 板卡的实时能耗,以进一步分析本文设计的优化方法对系统整体能耗的影响。
对于CPU 处理器,其开启的线程数和能耗基本成正比关系,线程数越少,CPU 处理的任务就相应较少,处理器能耗越低。数据加载和模型训练负载均衡优化通过开启满足模型训练需求的最少的线程数,来尽可能地节省CPU 的资源占用,达到了降低CPU处理器能耗的目的。
对于GPU 板卡,本文采用系统采样的方式统计其设备能耗。在模型的训练过程中,每隔1 ms 设置一个采样点,每次采样时读取GPU 当前的能耗。由于不同优化方法,模型训练完成的时间不同,为了实现准确的数据对比,本文统计完成一个epoch 训练时的GPU 设备能耗。选用InceptionV3 网络模型进行能耗统计实验,训练周期为1 个epoch。经过数据加载和模型训练自动负载均衡优化,CPU 的线程数由64降低为48,能耗降比达到25%。
图24 统计了在不同的优化条件下InceptionV3模型训练1 个epoch 时GPU 板卡的能耗变化以及训练1 个epoch 的时间消耗。结果显示,采用计算图分层和流水并行优化后,训练1 个epoch 的时间由30 s降低为20 s左右,提高了整体训练的性能。

图24 InceptionV3训练时GPU板卡能耗变化Fig.24 GPU power consumption changes during InceptionV3 training
本文通过能耗曲线和横坐标围成的面积来计算GPU 的整体能耗。通过数学计算可得,未优化时GPU 板卡的能耗为4 138 W,经过分层优化之后能耗降低为3 521 W,再经过分层自动流水优化之后能耗降低为3 512 W。实验结果表明,本文的分层优化算法能有效降低GPU 板卡的整体的能耗,降比达到15%左右。因此本文的计算图负载均衡优化策略能够在提高硬件设备资源利用率的同时,优化模型训练过程中系统整体能耗。
4 结束语
深度学编译器能够实现前端深度学习框架与后端AI 硬件设备之间的解耦化映射,目前深度学习编译器优化技术已经成为深度学习领域十分重要的分支。本文针对深度学习编译器中前端计算图的负载均衡问题提出了三种优化技术,分别是数据加载与模型训练的负载均衡、计算图的分层调度优化和计算图分层自动流水优化。实验结果表明经过上述优化之后,AI模型训练性能与其他框架相比获得2%到10%的提升,同时还可以通过负载均衡技术提高硬件设备的资源利用率,降低系统整体能耗,促使性能和能耗达到一个相对平衡的状态。
目前本文在计算图的并行调度优化和能耗优化方面做了一些探索性的工作,现阶段本文的优化前端支持TensorFlow 深度学习框架以及编译时自定义前端,后端支持CPU、GPU、FPGA 等硬件设备,后续将继续优化本文的技术方案,支持更多的前端深度学习框架和后端加速设备。此外,如何自动寻找计算图在多种后端设备上更优的联合布局以及如何通过负载均衡技术进一步降低整个系统训练过程中的能耗,也是未来主要的一个工作方向。
