一种基于FastText 的恶意代码家族分类方法
2024-01-10张宇迪冯永新赵运弢
张宇迪,冯永新,赵运弢
(沈阳理工大学信息科学与工程学院,沈阳 110159)
随着网络普及率越来越高,网络信息交互越来越多,网络攻击者会编写影响范围更广、更具隐蔽性的恶意代码以达到破坏网络、窃取信息等非法目的[1],该类恶意代码大多使用变形或多态技术躲避计算机杀毒软件的检测。 恶意代码家族是指具有相似功能、相同来源和不同演进程度的恶意代码集合[2],其分类研究可以视为对不同恶意代码的相似性、关联性判断,有助于研究人员发现同类型的变异代码并快速了解恶意代码感染策略、威胁级别[3]等信息,进而采取针对性措施防止恶意代码对网络的破坏。
目前已存在多种恶意软件和快速更新的反检测技术[4],恶意代码的检测可根据是否实际运行代码样本分为静态检测和动态检测。 与动态检测技术相比,静态检测技术具有能耗低、风险低、速度快和能识别非触发性、潜伏性的恶意行为等优点。 在针对API 序列的静态检测技术中,人工神经网络与词向量的结合显示出独特优势[5]。 例如,使用长短时记忆网络(LSTM)和循环神经网络(RNN)提取相关特征的模型和使用Apigraph技术[6]加强训练的Android 和Windows 恶意代码检测系统。 王博等[7]将二进制序列分割成RGB三通道,采用VGGNet 模型针对恶意程序变种的代码复用进行分类检测,该模型的准确率可达96.16%。 杨宇夏等[8]将N-grams 特征与恶意代码灰度图相结合,用于解决样本大小不一的问题并从文本和灰度图两个维度同时提取特征,实验结果表明该文提出的融合特征模型准确率可达98%。 王栋等[9]基于VGG 模型构建了一维卷积分类网络模型ID-CNN-IMIR,相较于其他深度学习模型具有更好的性能,准确率可达98.94%。 静态分析的缺点是容易受到混淆的影响,可直接分析原始程序代码的语法和语义,进而提取到更深层次的特征。
在针对 API 序列的静态检测中, 常用word2vec 模型将 API 序列映射为词向量。word2vec 首先生成词典,再将此词典中的所有API 函数映射为词向量。 所生成的词向量仅是样本语义到向量的简单映射,局限于API 函数的顺序特征且依赖词典,缺乏对词典外的API 函数表征能力。 恶意代码随着混淆技术的发展,执行程序的复杂程度大大提升,如何进一步表征API 序列的内在特征变得尤为重要。
1 面向恶意代码检测的FastText 框架分析与设计
在恶意代码家族分类中,受文献[10]启发,本文对收集的API 数据进行向量化。 由于卷积神经网络(CNN)和长短时记忆(LSTM)网络在特征提取方面效果突出,二者相结合的深度学习模型对局部特征的提取更加完备,因此采用基于词嵌入的CNN + LSTM 作为主要网络模型。 针对word2vec 只是对样本语义的简单映射[11],对低频和相似API 函数映射不准确的不足,采用基于Ngram 特征的FastText 框架结合负采样技术进行向量化,使用CNN +LSTM 的深度学习模型进行训练,称为FastText +CNN + LSTM 模型。 FastText模型是Facebook 公司一个开源的NLP 工具[12],主要应用于文本序列的向量化和快速分类。 其词向量的训练既可以有监督也可以无监督,训练完成后的词向量可进一步应用于其他模型或特征选择等任务。 FastText 模型本质上是对word2vec 中词袋模型(CBOW)的改进,并配合一个预训练好的线性分类器[13]使用,可采用逻辑回归模型、支持向量机等。 本文首先通过实验研究FastText 框架中每个API 函数被分解的最小字段长度n取值对模型整体性能的影响,确定最佳的n值,并与传统的embedding +CNN+LSTM 模型和word2vec模型进行对比,最后通过十折交叉实验对模型性能进行验证。
1.1 基础框架
FastText 的组成主要分为输入层、隐藏层和输出层三部分。 通过输入层将样本文本转为对应的N-gram 特征向量[14],在隐藏层中进行输入向量的叠加平均,输出层采用归一化指数函数[15](Softmax)预测结果。 本文使用FastText 输入层对API 调用序列进行向量化,该层主要结构如图1 所示。

图1 FastText 输入层结构图Fig.1 FastText input layer structure diagram
FastText 模型的输入层由两部分向量组成[16],分别是分词词典中对每个API 函数的词嵌入(embedding)向量{wj,1,wj,2,…,wj,n}和经过Ngram 特征取词后的embedding 向量{wt,1,wt,2,…,wt,n},其中j和t分别为同个API 函数两个分向量的编号,n为两个分向量的维度,通过两个向量相加操作得到模型需要的词向量{wj,1+wt,1,wj,2+wt,2,…,wj,n+wt,n}。 由上述过程可以看出,Fast-Text 模型对API 序列处理具有N-gram 特征。
为达到分类的效果,FastText 模型的目标是将极大似然转换为对数似然,并最小化该目标函数。 目标函数的计算方法为
式中:Yi表示第i个恶意样本对应的标签值;k为负样本数;f表示使用Softmax 函数预测类别;是权重矩阵[17];Xi为第i个样本特征向量。Xi表达式为
式中:func 是叠加平均函数,计算输入API 函数序列的特征向量;是权重矩阵;(v1,v2,…,vn-1,vn)是输入样本中的N-gram 取词后的词向量。
1.2 面向API 序列的负采样FastText 模型优化
FastText 根据前后API 序列预测当前位置API 函数出现概率,其训练需要通过输入样本不断调整神经元的权重提高对目标预测的准确率。当文本较复杂时,需要消耗较大的算力调整模型,并且向量化的API 函数数量众多,会导致对低频API 的映射精确度下降[18]。 因此,本文引入负采样技术对FastText 模型进行优化。 负采样技术通过引入负例,每次只更新与目前待训练API 有关的部分神经元,降低了运算量并改善了输出词向量的质量。
负采样优化首先确定中心API 函数并设置窗口长度,以中心API 函数的前后序列作为正样本,采用词汇表中其余API 函数为负样本,通过二元逻辑回归求解每个API 函数对应的待训练参数[19]和中心API 对应前后序列每个API 的词向量[20]。 将正负样本采用二元回归模型进行分类,根据链式法则和激活函数以梯度上升法对二元回归模型的可训练参数进行优化。 基于负采样优化的FastText 模型及其训练流程如图2 所示。

图2 FastText 模型及其优化流程示意图Fig.2 FastText model and its optimization process diagram
负采样优化的FastText 首先从输入API 序列(长度为m)中随机抽取一个样本{x1k,x2k,…,xCk},其中C为样本维度数,经过FastText 模型处理生成一个词汇表,以中心API 函数和其前后序列包含的API 函数作为正样本,通过负采样技术在词汇表中抽取负样本。 每个正样本经权重矩阵初始化后在隐藏层进行求和运算,得到词向量;再与输出权重矩阵进行相乘得到中心API 前后序列的输出向量;经激活后得到该向量的概率分布,最大概率索引的API 为FastText 预测的API 函数。由此,最小化输出向量的目标函数由式(1)转变为
式中:AContext为正本集合;P(wt|AContext(wt))表示wt为正样本的概率。
优化后正样本的似然函数为
式中:AContext和BNEG分别表示正负样本集合;Xw为正样本中各API 函数的向量和;θa为隐藏层与输出层间待优化的映射参数;Lw(a)用于判别分类情况,模型判定为正样本时为1,否则为0。
本文模型所用损失函数可进一步表示为
通过随机梯度上升法迭代更新FastText 训练词向量时所需参数组为Xw和θa,Loss函数用于计算参数组的损失函数和梯度,Xw是正样本中心API 函数所对应的前后窗口中所有向量的加和。在迭代过程中,θa的梯度加和会影响前后序列中API 函数对应的向量,每个API 函数对应的词向量也会根据Xw和θa进行更新。
在恶意代码家族分类的应用中,本文所提出的FastText + CNN + LSTM 模型相较于传统word2vec 模型具有以下优点:
1)由于引入了N-gram 特征,使模型对低频API 函数的映射加强了局部表征能力,提升了对低频和相似API 函数的映射准确度,进而提升了模型性能;
2)对未收录在token 词典中的API 函数仍可从字符级的N-gram 特征中构造词向量,因而可以对词典外API 函数进行向量化,增加了模型的普适性。
2 FastText +CNN +LSTM 恶意代码家族分类模型的构建
本文在FastText 框架下搭建模块化的深度学习分类模型FastText +CNN +LSTM,该框架的恶意代码家族分类模型面向Windows 系统文件,主要分为数据预处理模块、恶意代码特征预提取模块和深度学习模块。 FastText 恶意代码家族分类模型示意如图3 所示。
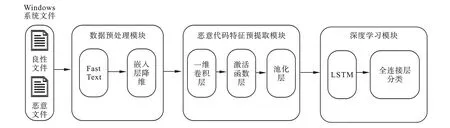
图3 FastText 恶意代码家族分类模型示意图Fig.3 Schematic diagram of FastText malicious code family classification model
2.1 数据预处理模块
数据预处理模块的主要功能是获取样本文件并从文件PE 头中提取该样本的API 调用序列,最终在FastText 中完成向量化。 PE 头中提取特征保存为.json 格式,再转存到Windows 系统的.csv文件中;根据预先标注信息为数据添加标签;使用NLP 工具进行分词、生成token 词典等;使用Fast-Text 生成词向量。
传统的word2vec 会把token 词典中的每个单词视为一个基本单位,然后针对每一个基本单位训练该单位所对应的唯一多维向量,word2vec 忽略了单词内部形态特征的联系。 例如在Windows系统创建网络链接和重定向到网络中常调用的API 函数“WNetAddConnection2A”和“WNetAddConnection2W”,两个API 函数功能完全一致,字符组成(内部形态)极为相近,但word2vec 框架分别对其生成对应的向量,单词内部形态信息因为分别进行的向量化而丢失,导致对包含两个API函数的样本学习时产生偏差。
通过计算不同框架对相似API 函数映射向量的距离和相似度,可以清晰对比两种模型处理相似API 函数的性能区别。 表1 列出了n=7 时FastText 框架对上述两个API 函数取子词顺序,并对比了word2vec 框架和FastText 框架对两个API 函数的映射词向量、向量间欧氏距离和向量间相似度。 表中“ <”和“ >”分别代表前缀和后缀,是边界符号。

表1 word2vec 词向量与FastText 词向量对比表Table 1 Comparison of word2vec word vector and FastText word vector
通过表1 中拆解两个API 函数所对应的子词信息可以看出,二者只有最后两个子词不同,本文模型先将API 函数对应的子词映射为向量,再与词典中的embedding 信息所映射的向量相加,映射成该API 函数在FastText 框架下的向量,送入后续模型进行训练。 因此,字符组成上相近的API 函数对应的词向量也较为相近,FastText 生成的两个词向量相似度高于word2vec。 通过表1 中计算两者欧氏距离可发现,FastText 生成的相似API 词向量具有更小的多维空间距离,相较于word2vec 减小了约60%,相似度提升约6%,说明FastText 可有效处理相似API 函数之间的映射问题。
恶意代码程序的API 序列包含操作较多,若将其转换为one-hot 编码,稀疏性通常较大,不仅会导致算力浪费,还会影响模型的性能。 因此,数据集向量化后需经过词嵌入层进行初步降维。 嵌入层的核心思想是将高维的稀疏向量映射到低维的密集向量。 在恶意代码API 序列生成的字典中,经过FastText 框架预处理后,共有1 860 个单词(API 函数),嵌入层的输出维度与FastText 相同,输出维度为50,该层接受的序列最大长度为200。
2.2 恶意代码特征预提取模块
词嵌入层降低了原始单词向量的维数,但向量维数仍然较高,LSTM 无法准确提取向量中的重要特征[21],导致算力的浪费和模型性能的低下。 因此,数据在深度学习模块之前需要在特征预提取模块中处理,以提取API 向量的初步特征,有助于提升训练速度和特征提取的精确度。 该模块采用一维卷积层[22],其卷积核大小为3 ×3,步长为1,激活函数为ReLU,输出矩阵维度为200 ×128。
卷积层的参数误差引起的估计平均值偏差,是API 词向量卷积运算的主要误差。 采用最大池化层可以有效地避免该误差[23],并保留更多纹理信息用于后续学习。 恶意代码的API 序列中的非异常操作并不罕见,在良性代码中也很常见,而该特性会影响模型性能,在恶意代码分类领域加强背景纹理信息对于准确识别具有重要作用。 在进一步提取最大池化层的特征后,网络所需的参数数量和算力将大大减少,也有利于防止网络的过拟合。 卷积层采用下采样卷积,池化层的池化窗口为2 ×2。
3 实验
3.1 实验环境
本文所实现的静态恶意代码家族分类针对Windows 系统下的样本程序,神经网络模型采用Keras 搭建。 实验采用的硬件环境为因特尔酷睿CPU(i7-10875H)、16 GB 内存。 软件环境为Windows10 系统、Python3.8、Tensorflow2.5.0 和Keras 2.5.0。
3.2 数据集与预处理
本文使用Ember 数据集,可以用于以静态方式训练恶意代码家族分类的机器学习模型,是恶意代码家族分类领域中常见的数据集。 数据集包含Ramnit、Lethic、Sality、Emotet 和Ursnif 五个恶意代码家族及其变种,以及2018 年及之前扫描的超过100 万个PE 文件的集合。 PE 文件的功能被拆解并保存为.json 格式,包括90 万个训练样本和20 万个测试样本。 数据集中的样本分布如表2 所示。

表2 数据集样本分布Table 2 Dataset sample distribution
首先,读取包含API 函数和标签的数据集,使用jieba 分词工具提取API 函数并将其转换为独立的单词,为后续提取字符集的N-gram 特征提供基础。 使用Tokenizer 工具将分词后的文本转换为词典,本文生成的token 词典如表3 所示。

表3 token 词典Table 3 Token dictionary
在FastText 框架下对输入样本进行向量化,本文生成词向量如表4 所示。

表4 词向量Table 4 Word vector
FastText 生成的词向量矩阵如表5 所示。
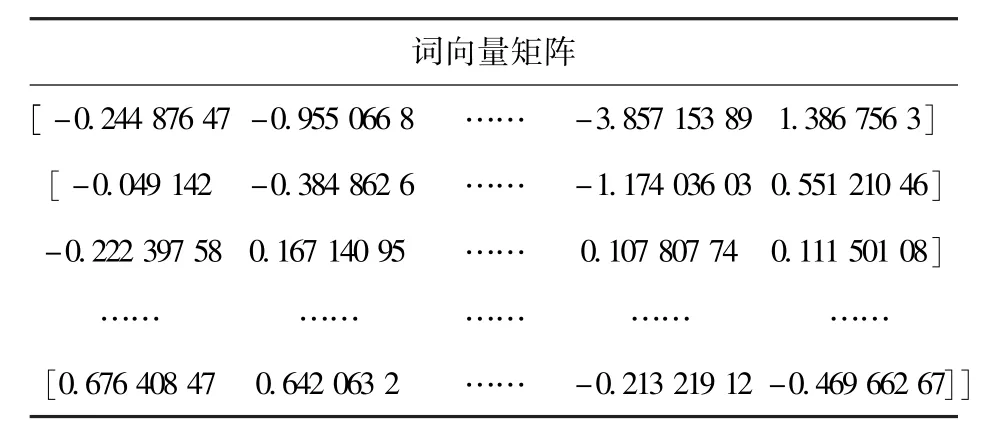
表5 FastText 词向量矩阵Table 5 FastText word vector matrix
3.3 实验结果与分析
在恶意代码家族分类的研究中,模型对不同恶意代码家族的分类精确率不同,主要是因为数据集本身的不均衡性和不同家族的恶意代码为了达成主要目的所需API 函数不同。
根据实验结果,首先研究FastText + CNN +LSTM 模型提取的N-gram 特征中n值对不同恶意代码家族识别精确度的影响, 然后对比word2vec+CNN +LSTM 模型和FastText +CNN+LSTM 模型性能,最后对本文模型进行十折交叉验证。
FastText + CNN + LSTM 模型N-gram 取词时,n值在[1,10]区间内模型对数据集中五个恶意代码家族的分类精确率影响如图4 和图5所示。

图4 n 在[1,5]区间取不同值对模型的影响Fig.4 The influence of taking different values of n in the [1,5] interval on the model

图5 n 在[6,10]区间取不同值对模型的影响Fig.5 The influence of taking different values of n in the [6,10] interval on the model
由图4 和图5 可以看出,本文模型对于Lethic家族的识别精确率最高,不同的n值对该家族影响较小,精确率始终为98%以上。 该模型对Emotet 家族和Ursnif 家族的分类性能受n值影响较大,在n取值为2 和4 时精确率最高,分别为95%和92%。 该模型在Ramnit 家族和Sality 家族上的识别精确率略低于其他家族,两个家族的分类精确率受n取值的影响较大,在n取7 时对两个家族的识别精确率同时达到最大,分别为85%和81%。 综合考虑模型总体准确率和对每个恶意代码家族的识别精确率,设置n=6,此时模型综合性能最符合实际需要。
本文为对比所选框架与传统word2vec 框架的性能,汇总了几种模型的准确率和损失函数,如表6 所示。

表6 模型性能对比表Table 6 Model performance comparison
由表6 可以看出,FastText +CNN +LSTM 的准确率和损失函数两项数据在训练集和测试集上的表现均优于其余两种模型,其准确率相较embedding + CNN + LSTM 方法提升约25%,相较word2vec+CNN+LSTM 提升约4.4%,最终在训练集上的准确率为99.75%。 word2vec +CNN +LSTM 和FastText +CNN +LSTM 准确率对比如图6 所示。

图6 准确率对比图Fig.6 Accuracy comparison chart
由图6 可见,word2vec 框架在训练过程中性能始终低于FastText,主要是因为该框架只是对API 序列的简单映射,造成对词典外和低频API函数映射失真。 由于FastText 引进字符级N-gram特征,训练相对平稳,模型的性能相较word2vec有所提升,最终准确率稳定在99.75%。
图7 为word2vec + CNN + LSTM 模型和FastText+CNN+LSTM 模型的损失函数对比图。
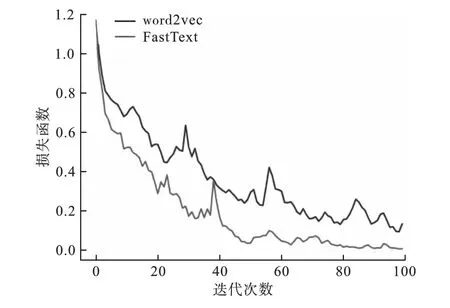
图7 损失函数对比图Fig.7 Comparison diagram of loss function
由图7 可见,在40 次迭代前,二者的损失函数值均快速下降,但是在第40 次迭代时两个模型性能的提升速度均有所放缓,FastText + CNN +LSTM 模型的性能均高于word2vec + CNN +LSTM 模型,最终损失函数为0.004 6。
图8 为FastText +CNN +LSTM 模型十折交叉验证结果。

图8 FastText+CNN+LSTM 模型十折交叉验证结果Fig.8 FastText+CNN+LSTM model 10-fold cross validation results
由图8 可以看出,开始时模型性能较低,在第二个子集末期模型准确率可达90%,在约四个子集后模型准确率可达95%以上,最终模型的准确率为99%。 从十折交叉验证的整体情况可知,该模型由于引入了字符级N-gram 特征,模型收敛速度较快,且可以在性能较高的位置收敛,收敛准确率可满足恶意代码家族分类的实际需要。
4 结论
为解决恶意代码家族分类领域常见模型中对API 调用序列向量化不准确、对低频及词典外API函数映射失真等问题而导致模型准确率无法进一步提升的问题,本文提出了一种基于FastText 的恶意代码家族分类方法。 通过提取样本代码所调用API 序列的字符级N-gram 特征,在负采样技术优化的FastText 中生成词向量,使用词嵌入层进行初步降维,并使用CNN +LSTM 模型进行特征提取和训练,最终在Softmax 全连接层中输出样本所属类别的概率。 通过对实验结果的分析,本文模型的性能高于传统 embedding 模型和word2vec 模型,在与word2vec 模型对比训练过程后证明FastText 模型的训练过程平稳且收敛性更优,说明该模型在恶意代码家族分类领域具有较强的适应性,缓解了word2vec 框架对低频和不均衡API 函数映射失真的问题,进一步提升了恶意代码家族分类的准确率。
