《环境科学》课程思政知识库自动构建方法研究
2024-01-08郭胜娟彭东来
郭胜娟 杨 梅 彭东来
(1.武汉城市职业学院 湖北 武汉:430064;2.武汉大学 湖北 武汉:430072)
课程思政是指在专业课程的教学过程中将课堂知识与思想政治有机地融合,通过课程教学来培养学生的思想政治觉悟、理论素养和道德品质,将党的理论、政策和核心价值观融入到课程教学中,以达到“育人”与“育才”的目的。自2016年12月习近平总书记在全国高校思想政治工作会议上明确指出:“把思想政治工作贯穿教育教学全过程”,课程思政的理论研究和实际应用广泛开展,课程思政的教学模式也与专业课程进行紧密结合[1]。《环境科学》是一门综合性的学科,主要研究与环境有关的各种问题,包括环境污染、环境保护、生态学、资源管理、环境经济学、环境法律等方面的知识[2-3]。该课程的研究内容与生活实践是密不可分的,与习总书记倡导的“绿水青山就是金山银山”的发展理念一脉相承。因此,如何快速建立课程知识体系与新闻时政的联系,如何构建适合课堂教学的环境科学课程思政知识库,成为学科教师亟待解决的关键问题。
知识库作为一种特殊的知识结构,得到了全世界专家学者的广泛关注。已构建的具有代表性的知识库有WordNet、KnowItAll、Freebase、DBpedia、 WikiTaxonomy、YAGO、ReadTheWeb。东南大学开发的zhishi.me开放知识图谱首次尝试构建中文通用知识图谱[4]。在生态环境知识库方面,有的学者也会针对特定的知识构建领域本体知识库。缪少豪[5]从地理课本中获取相关领域知识,提取本体及本体的属性,并以此构建了基于本体的知识库。宋立博[6]通过图数据库Neo4j 构建标准图谱库,实现生态环境标准知识图谱。郭胜娟等人[7]研究了知识图谱的知识获取、整合与可视化的方法。但是,目前并没有环境科学课程思政知识库构建的报道。因此,本文根据《环境科学》的知识点,采用爬虫技术、Neo4j图数据库、自然语言处理、ChatGPT等计算机技术,在人民网等国家主流媒体获取时政要闻的基本信息,形成时政要闻的知识素材,并对知识素材进行非结构化存储,形成课程思政素材库。
1 知识点自动提取
1.1 知识点提取流程
为了自动生成知识库,本文以《环境科学》教材的“水污染及其防治”一章为主要分析对象。该章的学习目标是“认识水污染物的危害,掌握污水的物理、化学、生物治理方法的原理以及污水处理流程组合的原则”。为了实现该章节的学习目标,构建课程思政知识库,首先采用Jieba工具对教材的相关章节进行分词,采用TF-IDF算法统计该节内容的高频词汇,形成高频短语作为关键词。基于该关键词,应用大语言模型工具Chat GPT分析教材内容,形成所选择内容的教学知识点。具体知识点提取流程如图1所示。
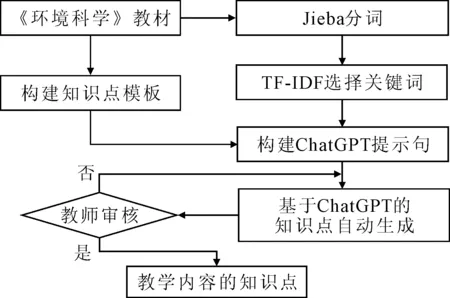
图1 知识点提取流程图
1.2 关键词自动提取
关键词是文本内容中具有特殊重要性和标志性的词语,它对于理解文本的主题、内容和重要性起着重要的作用。关键词在文本中的出现具有频繁性和代表性,通常在文本中频繁出现多次。根据该特征,可以采用词频分析方法统计出不同词汇出现的次数,并据此分析《环境科学》教材中主要关键词。
Jieba是一种常用的中文文本分词工具,它能够将连续的汉字文本切分成有意义的词语,识别连续文本中的不同词性,有助于文本处理、自然语言处理和信息检索等应用。因此,可以采用Jieba对教材内容进行分词,实现教学内容的名词提取。例如水污染处理技术的分词格式如下:“污水/处理/技术/就是/采用/各种/方法/将/污水/中/所含/有/的/污染物质/分离/出来/,或/将/其/转化/为/无害/和/稳定/的/物质,从而/使/污水/得以/净化/。”
TF-IDF是一种常用的关键词提取和文本分析的统计学方法,其基本原理是统计每个词在文档中出现的频率(TF)和表示词语在文档中的重要程度的逆文档频率(IDF),然后将词频(TF)与逆文档频率(IDF)相乘,得到TF-IDF得分。TF-IDF方法能够帮助环境科学教学中的教师快速理解文本的重要内容,并识别出与课程内容相关的关键词。例如,在“水污染及其防治”一章中,我们提取到高频关键词为“[水体:0.568, 污染:0.243,水中:0.186,污染物:0.162,水质:0.154,有机物:0.138,…]”
1.3 知识点自动生成
知识点在环境科学教学中具有至关重要的角色,它有助于我们更好地理解环境问题的本质,能指导我们制定环境科学课程思政素材自动获取方法。因此,如何根据教学内容自动生成知识点,成为环境科学课程思政库知识库构建的关键问题之一。
本文以ChatGPT为辅助工具,基于关键词自动构建ChatGPT的提示词,并根据预先设计的知识点模板,由ChatGPT自动根据课程内容生成知识点。例如,根据上述获取的高频关键词“水体:0.568,污染:0.243”,构建“请根据以下教学内容构建教学知识点,重点内容是‘水体’”。ChatGPT生成如图2的知识点。

图2 水体知识体系的自动生成
2 课程思政素材获取方法
2.1 思政素材自动获取流程
网络爬虫是一种程序或脚本,用于自动地从互联网上收集大量数据。它通过遍历网页并提取有用的信息,然后将这些信息存储在数据库或文件中,以供进一步分析和利用。在现代信息时代,网络爬虫已经成为了数据挖掘和信息获取的重要手段,出现了Scrapy、Beautiful Soup、cheeio、puppeteer等网络爬虫工具。
本文采用cheeio和puppeteer工具实现网络爬虫,其获取数据的过程如图3所示。首先需要确定爬取的网站和需要收集数据的关键词,弄清网站的页面结构和数据组织方式,确定如何从页面中提取需要的数据,获取到数据后,将提取的数据存储到本地或数据库中,便于后续处理和分析。

图3 素材爬取示意图
2.2 思政素材爬取的实现
根据上文获取到的关键字,从习近平系列重要讲话数据库、中华人民共和国生态环境部和人民网这三个网站,检索“水体”“污染”等关键字进行初步筛选,发送HTTP请求到给定的URL,并从返回的网页内容中提取特定数据,如标题、时间、来源和内容等 ,然后将这些数据插入到数据库中,其核心代码如图4。

图4 网络爬虫核心代码
3 知识表示与存储方法
3.1 结构化数据存储
为了获取知识库,需要对网页爬取的文章进行存储,对于这种规整性的文章而言,可以选择关系型数据库 MySQL 进行存储。该系统主要的结构化数据主要包括环境思政文章和用户实体。文章实体的主要属性包括ID、路径URL、文章内容、文章标题、发表时间和文章来源。用户实体的主要属性包括用户ID、用户名、用户密码和用户许可。文章和用户实体通过“访问”关系构成关联关系,用户可以访问多篇文章,文章可以被多个用户访问。因此可以构建如图5所示的实体关系图。
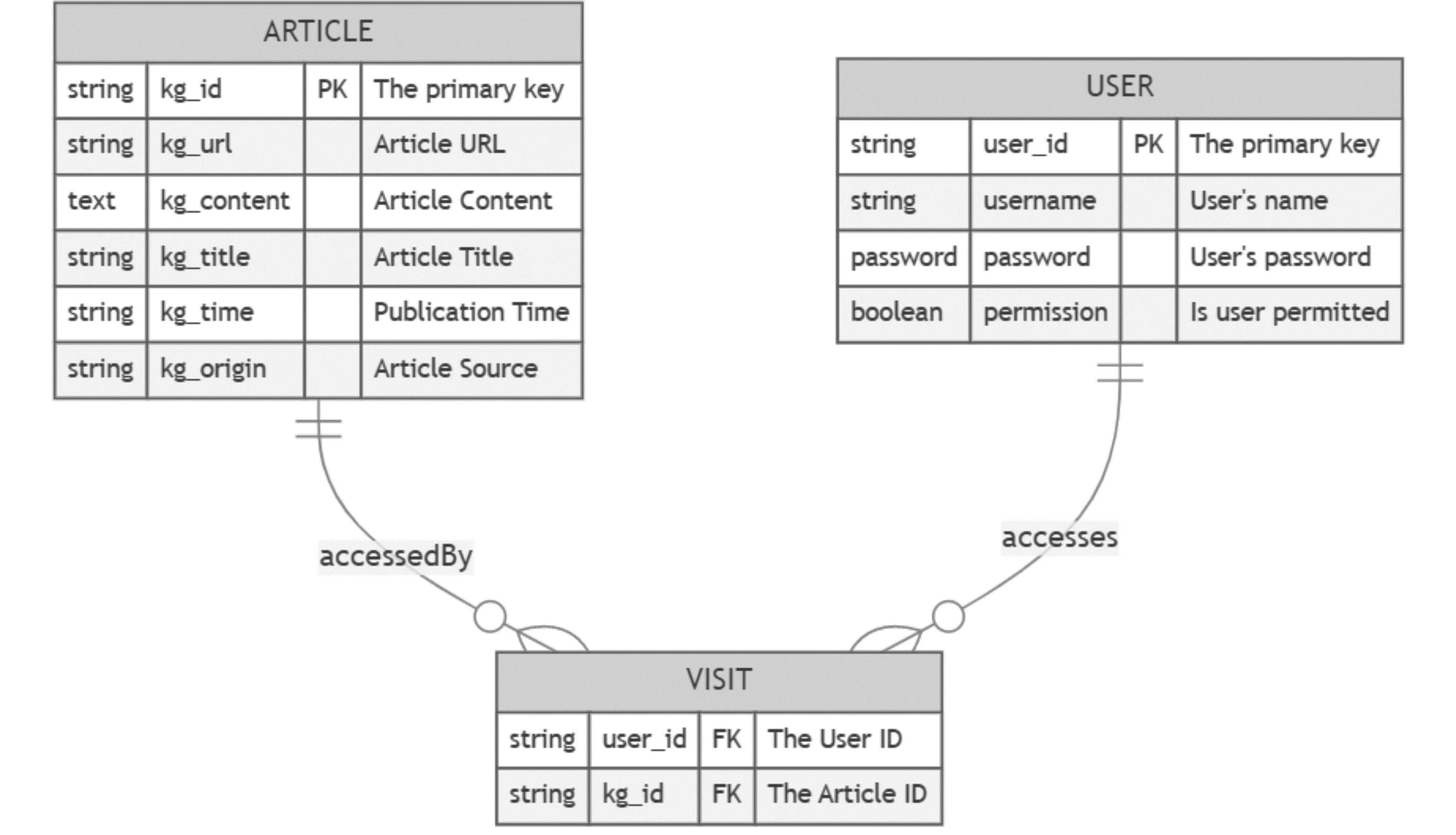
图5 主要实体关系图
其中,环境思政文章的表设计与字段表述如表1所示,其中kg_id 字段为文章的 id,用于区分不同的文章。
3.2 非结构化知识表示
对于爬取的课程思政数据,提取出有关实体、关系和属性的结构化信息。本文采用Jieba分词提取和TF-IDF词频分析技术提取关键词,提取课程思政的关键词,并通过ChatGPT形成关键词的摘要。例如,通过爬虫获取人民网中含有“K1:水体”和“K2:污染”的关键词的网页“非法倾倒工业废水致水体污染”,采用ChatGPT提取出关键字“I1:导致工业污染”和关键句子“S1:(佛山污染事件),在广东省佛山市禅城区,谢某和刘某因非法排放危险废物导致环境污染,被判处有期徒刑六个月、罚款1万元,需支付35.2万元的生态环境损害费和修复费,同时在媒体刊登声明向社会公众赔礼道歉。”

表1 环境思政文章表关键字段设计与描述
采用RDF表示课程思政知识体系[8]。RDF三元组是一种用于表示和描述语义信息的基本数据模型。它由三个部分组成,分别是主题(Subject)、谓词(Predicate)和宾语(Object),构成了一个简单的陈述句,用于描述资源之间的关系。通过RDF三元组可以实现非结构化信息的存储,从而构建知识库。例如,在上述结构化数据中,可以构建(K1,I1,S1)和(K2,I1,S1)两个RDF三元组。
3.3 非结构化知识存储与知识库构建
对于非结构化RDF数据,采用图数据库Neo4j进行存储。Neo4j是一个高性能、可扩展的非关系型数据库,它以节点(Nodes)和关系(Relationships)为基础来表示数据,适合表示和处理复杂的非关系型数据,可以通过使用 Cypher 查询语言进行高效的图查询和分析,帮助用户发现图数据的模式。
例如上述案例中,可以通过Cypher查询语言来创建和查询图形数据如图6所示。

图6 Cypher语言插入Neo4j关系图构建语法
将RDF数据格式导入到Neo4j数据库后,“MATCH (k:Keyword {name: '污染'})-[:CAUSES]->(i:Impact)-[:LEADS_TO]->(e:Event) RETURN k, i, e”语句查询所有节点。
4 应用与分析
本文采用主题探究教学设计策略,将自动生成的知识图谱应用于教学中。主题探究教学策略首先讲解水污染的危害,构建水污染相关知识主题。例如,本文以“环境污染的主要事件”这个主题,引导学生通过查询思政知识库,查找“佛山污染事件”等课程思政的主要知识点,接着提示学生调研该事件的起因、经过和最终处罚。进一步,通过与知识图谱的交互操作,逐步展开在全球范围内水体污染导致的重大事件,学生共同讨论该主题的现实意义,分析这些事件背后的原因,构建学生对水污染防护的重要现实意义。
通过以上教学策略,本文随机选择某学院科学教育专业2个普通班作为研究对象,其中对照班38人和实验班40人。为了比较教学效果,实验从学生课堂参与度、学生满意程度、学生成绩和课程思政能力四个方面进行评测。课堂教学参与度是任课教师根据学生在课堂上的参与程度,包括提问、回答问题、参与讨论的频率等给出的综合评分。学生满意程度是通过如图7的问卷调查获取学生的反馈。学生成绩是通过课堂小测试完成,以百分制计算总得分。课程思政能力是通过问卷调查的方式完成,转化为百分制计分。 如表2所示,实验班成绩在学生课程参与度、学生满意度和课程成绩方面均优于对照班。

图7 课程满意度调查问卷

表2 教学效果对比
5 总结
本文通过采用人工智能的分析方法,结合《环境科学》的教学内容,自动生成教学知识点,并通过ChatGPT、网络爬虫等工具,自动从人民网等国内主流媒体获取课程思政知识库,并将这些知识以知识图谱的方式整合进入课堂教学。通过对比实验分析表明,该方法可以有效提高学生的课程参与度和提高学习成绩,同时也可以有效提高课程思政的效果,让学生通过隐式学习到对“社会环境事件”的关注。
