不同残差网络模型的HEp-2细胞荧光图像分类比较
2024-01-08许晗
许 晗
(黎明职业大学 信息与电子工程学院,福建 泉州 362000)
21世纪以来,慢性病患者的比例逐年上升,致死率也在逐步升高。研究发现对HEp-2细胞(Human Epithelial type-2)进行免疫荧光检测可用于鉴定抗核抗体(ANA),这在识别自身免疫性疾病中起着重要作用。HEp-2细胞是人体喉癌上皮细胞,常用于检测血清中的抗核抗体,进而判断是否具有自身免疫性疾病和对应的疾病。
目前,检测ANA主要采用的方法是传统的手工评估法,一般可分为以下三个步骤:图像预处理、特征提取(特征选择)、特征分类。[1]尽管传统方法已经能够达到较高的准确率,但手工设计的特征都是基于人的先验知识,而不是主动地从数据中挖掘信息;同时,在这些方法中,先进行特征提取,再进行分类,所以分类的准确率很大程度上依赖于特征提取;另外,如果这些特征的提取阶段有大量参数,则会导致人工调节参数较为繁琐。近年来,许多研究者致力于开发HEp-2细胞分类的计算机辅助判读系统,但是这些自动化的判读方法大多还是依赖于手工设计的特征提取方法和与之分离训练的分类器,同时这些系统的判读性能与专业医生相比仍然存在很大的差距。[2]
本文受自然图像识别领域的深度卷积神经网络的启发,基于深度残差网络[3]对HEp-2细胞荧光图像进行分类研究,采用了ResNet18和ResNet34两种深度学习模型对HEp-2细胞的ICPR 2012数据集进行分类,并取得了良好的效果。
一、基于深度残差网络的HEp-2细胞分类
(一)HEp-2数据集
本文使用的是ICPR 2012数据集,[4]该数据集来自2012年ICPR竞赛的细胞分类部分,包括来自28个自身免疫性疾病病人的1 455个不同细胞样本的荧光模式图像。图像由荧光显微镜先通过40倍(目镜*物镜)放大,再通过参数为6.45 um的CCD数字相机捕捉,最终数据集由两个以上的专家通过手动分割和标注后得到。[5]整个数据集包含均质型图像388张、粗斑点型图像228张、核仁型图像127张、着丝点型图像200张、致密斑点型图像345张、细胞质型图像222张。根据荧光强度的不同,图像被分为positive(显性)、intermediate(中性)两类。完整的数据集中标明了每张图像的ID,以及它们对应的染色模式类别。图1显示了该数据集中六种HEp-2细胞染色模式示例图。
为了方便分割和其他图像处理,以及避免其他物质对细胞的干扰,竞赛方还为每一个细胞图像提供了掩膜,如图2所示。

图2 掩码图像
(二)深度残差网络
近年来,以Alex Net,VGGNet,Google Net,ResNet为主导的一系列CNN方法在图像分类任务,尤其是Image Net大规模图像分类竞赛中脱颖而出。[6]经过测试发展,与传统网络层数越深、生成的模型参数就越好的观点不同,传统的CNN网络结构如果一味的增加网络层数,准确率不再上升,训练错误率和测试错误率甚至会提高。[7]参数在神经网络中被反向传播时,梯度是需要被不断传播的,但是如果网络层加深,传播过程中梯度会逐渐消失。网络无法对前面的参数进行有效调整,也就得不到好的训练效果,这称之为网络退化问题。目前,技巧、初始权值选择和权值共享等是深度学习的主要进展方向。[8]
2015年Image Net图像分类比赛冠军ResNet网络深度达到了152层,他们使用了残差学习(Residual Learning)结构,[9]利用一个152层的深度网络将错误率下降到了3.57%,成功解决了网络退化问题。该方法没有使用传统的神经网络去拟合所需要的实际映射关系,而是创新性地提出了残差映射的方式。这样,成功使得每一部分权重的调整都能被有效进行,调整作用更明显,更容易训练。
图3是常规的神经网络形式。每层有激活函数和权值,图中采用的是Relu激活函数,目的是为了避免梯度消失的问题。图4是残差网络的基本单元。在残差网络中,刚开始输入的x,按照常规的神经网络进行权值叠加,其结果通过激活函数后第二次进行权值叠加,随后再把输入的信号和二次输出结果叠加并第三次通过激活函数,这就是残差网络的工作原理,而那条线称为捷径连接(shortcut connections)。在线性拟合中的残差指的是数据点距离拟合直线的函数值的差,即这里的x就是拟合的函数,而H(x)就是具体的数据点,那么通过训练使得拟合的值加上F(x)就得到具体数据点的值,因此F(x)就是残差。[10]

图3 常规神经网络形式

图4 残差网络基本单元
图4 中,通过“shortcut connections(捷径连接)”,原来的结果变为H(x)=F(x)+x,若F(x)=0,则H(x)=x,即恒等映射。[11]这时,网络的学习目标由原来的调整全部的参数,变成去调整每一小块的参数,使每一块的参数得到最优解。也就是,所谓的残差就是:F(x)=H(x)-x,如果F(x)=0,这时H(x)=x,也就是每一小块的参数得到了最优解,网络的目的就变成了学习H(x)与x的差值,使差值接近于0。经过这样的转变,当网络层数加深时,错误率也不会上升。
这种结构是跳跃式的,即前一层的结果不仅可以传输给下一层,还可以跳跃着传输给下面的某一层。该结构使得神经网络内部可以叠加多层网络,解决了深度学习的模型错误率不降反升的难题。正是因为这个思想,神经网络的层数可以增加到很多层,甚至上千层,使得传统的神经网络难题得到解决。
残差学习模块如图5所示,其中x表示输入向量,y表示输出向量。该模块通过添加短路连接实现公式F(x)+x,目的是使输入与输出的差值最小。x经过若干网络层后得到实际映射H(x),而F(x)=H(x)-x,即整个网络由原来的拟合H(x),变为拟合残差函数F(x),这也使得网络更加高效、便捷。[12]深度残差网络的原理是把全部训练分成许多个非常小的块(block)去训练,让每一块训练的误差最小,从而整体误差最小,就能够减少出现梯度弥散的现象。

图5 残差学习模块
由图6中ResNet网络基本结构可知,在这些基本结构中,有一些“shortcut connections”是实线,有一些是虚线。造成这样的原因主要是经过连接后,如果x和F(x)的通道是一样的,则H(x)=F(x)+x;如果他们的通道不一样,就不能直接相加,而是需要再经过一些操作。因此,需要依靠实线和虚线来区分这两种情况:①当输入和输出的维度是相同的,在网络结构上可以连续串联,以加深网络的深度,从而直接用公式H(x)=F(x)+x来计算。②当输入和输出的维度不同,则在网络结构上不能连续串联,卷积块的作用就是为了改变网络的维度,此时不能用公式H(x)=F(x)+x计算,应该使用H(x)=F(x)+Wx,其中W是卷积操作,用于调整x的维度。[13]
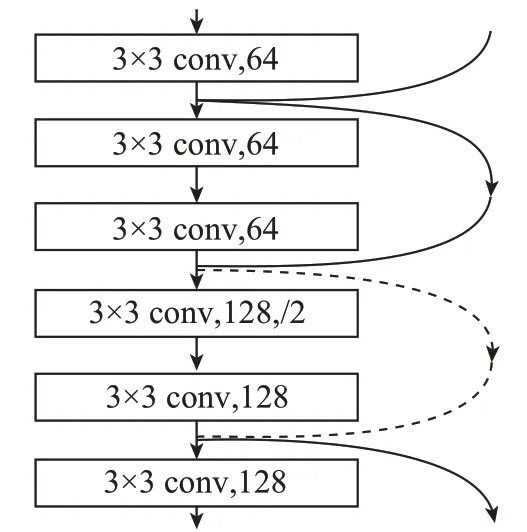
图6 ResNet网络基本结构
二、实验设置与结果
(一)预处理
本文选取ICPR 2012竞赛数据集中所有positive图像作为实验数据,其中的六类模式图像(Homogeneous,Coarse Speckled,Fine Speckled,Nucleolar,Centromere,Cytoplasmic)各自按照8∶2分为训练集和测试集,得到671张训练集、168张测试集。另外,本文还使用ICPR 2016竞赛数据集中的13 596张图片作为实验数据,同样将其中的Centromere、Golgi、Nucleolar、NuMem、Homogeneous、Speckled 六类模式分别按照8∶2分为训练集和测试集,得到10 874张训练集和2 722张测试集。为避免图像尺度不同对结果产生影响,实验中将细胞图像尺度均统一成100×100的尺寸。
(二)模型训练
本文采用的训练模型为ResNet18和ResNet34,其中ResNet18具体除由输入层、卷积层、池化层、全连接层、输出层这些基础的网络结构组成外,还包括四个作为映射的残差块。ResNet18包括(8*2+1)个卷积层+1个全连接层。ResNet34与ResNet18基本结构相同,包括(16*2+1)个卷积层+1个全连接层。数字代表网络的深度,18指的是18个带有权重的层,包括全连接层和卷积层,不包括BN层和池化层。
每个模型使用200 个epoch 进行网络收敛,batch size为8。损失函数为交叉熵损失函数,LR为0.1;激活函数为Relu函数。表1为Resnet网络结构模型。

表1 Resnet网络结构模型
(三)实验结果
本文首先采用了CPR2012数据集进行试验,其结果如图7和表2、表3所示。从图7的结果来看,在ResNet18和ResNet34进行图像分类时,可以发现损失函数,即错误率是逐渐下降的,并且最终错误率降到0.03%,初始时的损失函数不太理想。ResNet18相对于ResNet34来说,调整效果好。
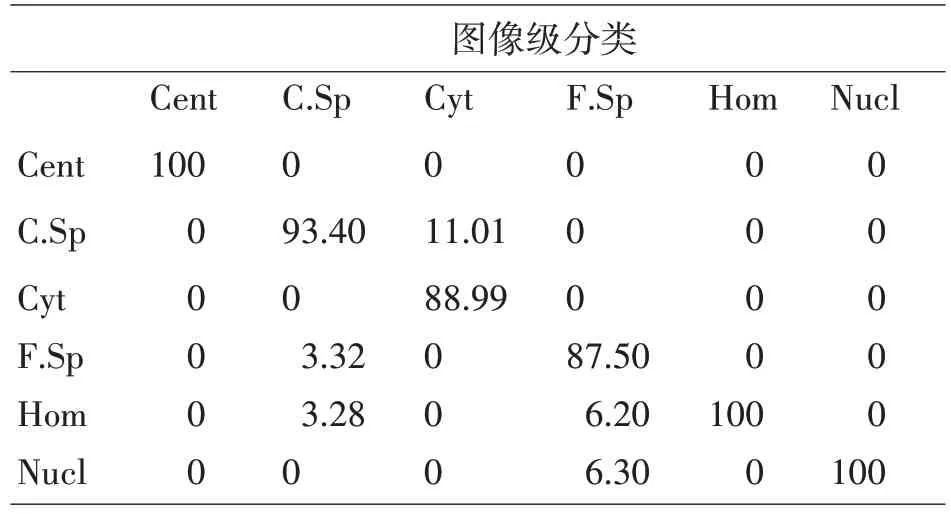
表2 ResNet18图像级检测时的混淆矩阵(%)
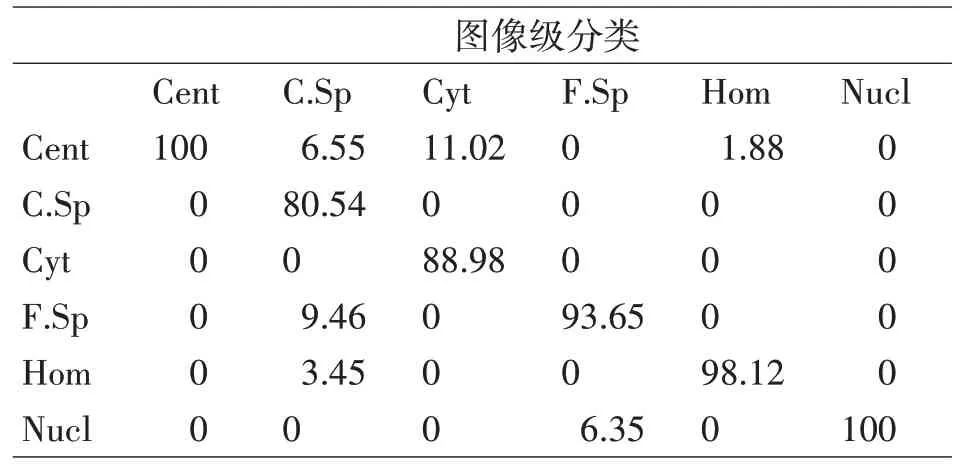
表3 ResNet34图像级检测时的混淆矩阵(%)

图7 ResNet18和ResNet34在训练过程中的损失变化
表2是采用ResNet18方法在ICPR 2012测试用数据集上的混淆矩阵,表格显示图像级检测分类效果比较理想,在Cent、Hom以及Nucl这三类不同的染色模式类别之间,正确率达到了100%;C.Sp这一染色模式类别也达到了93.40%;仅在Cyt以及F.Sp两类染色模式中出现了误判,发生了混淆,但这两类的误判并不多,两者的正确率同样分别到达了88.99%和87.50%。从实验数据可以看出,该方法对图像分类有较好的效果。
表3是采用ResNet34方法在ICPR 2012测试用数据集上的混淆矩阵。实验结果显示,在Cent和Nucl这两类不同的染色模式类别之间,分类正确率达到了100%,Cyt这一类别的分类正确率保持不变,F.Sp类别的分类正确率则是上升了6.15%,这说明增加网络深度有利于降低混淆函数,提高图像分辨的正确率。但Hom以及C.Sp这两类别与ResNet18的方法相比,正确率略有下降,下降了1.88%与12.86%。两种方法对染色模式图像描述的鉴别能力都很强,二者都具有比较理想的鉴别能力。
根据表4可以看出,在ICPR2012数据集上,ResNet18 和ResNet34 的分类结果是类似的,ResNet18在Positive_train-Positive_test的分类结果为94%,比ResNet34的93%略高。

表4 ICPR2012数据集的分类结果比较
三、总结
深度残差网络模型的优势是既能良好提取特征,又可加深网络深度。与传统的机器学习方法相比,由于图片数据量的增大,使得模型的学习效果更好,分类准确率更高,使用深度学习方法可以极大提高实验效率。
