遥感图像跨域语义分割的无监督域自适应对齐方法
2024-01-08沈秭扬管海燕
沈秭扬,倪 欢,管海燕
南京信息工程大学遥感与测绘工程学院,江苏 南京 210044
地物分类(语义分割)是遥感地学分析的基础,得到了广泛研究。这些研究引入经典的机器学习方法和深度学习技术,推动了遥感图像语义分割的自动化和实用化。经典的机器学习方法,如支持向量机[1]、人工神经网络[2]、决策树[3]、随机森林[4]及自适应增强[5]等,难以建模深层特征空间的语义信息,难以在遥感图像语义分割任务中取得精度突破。深度学习方法,如卷积神经网络[6-7]、图卷积网络[8]、Transformer[9]及多模态融合[10]等,有效建模高层次语义信息,进一步提高了遥感图像语义分割精度。但是,深度学习模型要求用于训练的源域数据与目标域数据间服从同一分布。在成像传感器和地理环境不同时,同分布要求无法满足,即源域和目标域之间存在域偏移,阻碍了深度学习模型的泛化能力。如图1所示,直接将训练好的模型应用于存在域偏移的目标域数据集上,难以取得预期结果[11]。因此,如何将模型迁移到存在域偏移的目标域数据集上,是当前遥感领域需要解决的重要问题[12]。

图1 源域模型在源域和目标域的分割结果对比Fig.1 The comparison between segmentation results produced by source-domain model in source and target domains
目前,无监督域自适应是解决域偏移问题的有效方法,仅利用源域标签进行训练,便可得到适用于目标域的语义分割模型。无监督域自适应方法分为两大类[13],即基于差异测度和基于生成对抗网络(generative adversarial nets,GAN)[14]的方法。基于差异测度的方法通过不同测度,如MMD(maximum mean discrepancy)[15-16]、CORAL(correlation alignment)[17-18]及CMD(central moment discrepancy)[19]等,来衡量源域和目标域之间的差异,进而实现差异最小化。基于GAN的方法根据应用方式的不同,又可分为两个子类。第1类利用GAN的重构能力,如通过CycleGAN[20]、ColorMap GAN[21]和ResiDualGAN[22]等方法对源域图像进行风格转换,并对转换后的源域图像进行监督训练,从而缓解域偏移问题;第2类则使用GAN在特征[23]或输出[24]空间进行对抗学习,并引入实例[25]和类别[26-27]信息,提取稳健的域不变特征。基于GAN的方法在遥感图像语义分割域自适应任务中应用更为广泛,但由于对抗学习过程的复杂性,GAN难以同时拓展到多个空间。基于此,本文舍弃GAN思想,采用基于差异测度的方法,引入最优传输理论,从数学角度构建源域和目标域对齐途径,并充分利用图像、特征和输出空间信息。
基于最优传输理论的域自适应思想通过减小域间的Wasserstein距离来对齐源域和目标域分布[28]。该思想首先利用最优传输,根据目标域特征迁移源域图像,然后对迁移后的源域图像进行监督学习,并引入参考分布[29]、空间原型信息[30]和注意力机制[31],提高跨域泛化能力。通过最优传输与域自适应理论的结合,模型能够以一种合理的几何方式衡量源域和目标域的特征分布差异[32-33]。但是,目前基于最优传输的域自适应方法主要面向自然图像分类任务,即每一张图像仅对应一个标签,尚无法充分顾及高分遥感图像语义分割任务需求。为弥补以上问题,本文基于最优传输理论,提出一种顾及多空间分布对齐的全局域自适应方法,以解决高分遥感图像语义分割的域偏移问题。本文方法的核心即在图像空间、特征空间和输出空间,利用最优传输理论来减轻源域和目标域的分布差异。本文的创新点如下:①将最优传输理论引入遥感图像语义分割域自适应任务,给出了整合最优传输与语义分割域自适应框架的具体方案;②构建了一种基于最优传输的全局域自适应模型,与现有方法相比,进一步减弱了域偏移影响,取得了更高精度。
1 基于最优传输的无监督域自适应方法
本文方法具体分为3个部分:图像空间风格迁移、特征空间和输出空间对齐。方法的整体框架如图2所示,首先在图像空间计算源域图像和目标域图像之间的最优传输矩阵,利用最优传输矩阵将源域图像风格转换至目标域;其次将转换后的源域图像、目标域图像输入语义分割网络,同时获取源域和目标域的深度特征(对应特征空间)和模型预测(对应输出空间);再次计算源域和目标域特征空间Wasserstein距离(earth mover distance,EMD),作为特征空间损失;然后在输出空间计算源域和目标域之间的EMD,作为输出空间损失;同时为保证模型稳定性,将源域输出空间结果进行上采样,作为源域预测结果,利用源域标签计算交叉熵损失,实现源域监督学习;最后将训练好的模型应用于目标域图像,以完成目标域语义分割。
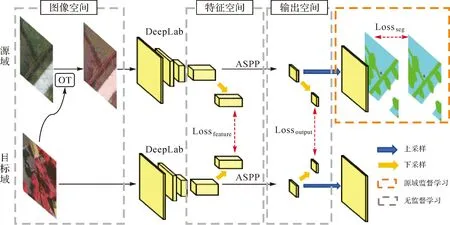
注:OT为最优传输;Lossfeature为特征空间损失;Lossoutput为输出空间损失;Lossseg为语义分割损失。图2 本文方法框架Fig.2 Framework of the proposed method
本文采用基于ResNet101[34]的DeepLab-V2框架作为语义分割网络,并遵循文献[24]的做法,移除最后一个分类层,将最后两个卷积层的步长从2修改为1,使得输出特征的尺寸是输入图像的1/8;网络在最后两个卷积层中应用扩张卷积以增大感受野,其步长分别为2和4;在特征提取后,使用ASPP(atrous spatial pyramid pooling)[35]作为最终预测层。
1.1 最优传输和域自适应
最优传输[36]理论可以找到从一个分布ds(如源域分布)至另一个分布dt(如目标域分布)的最优映射方案。具体而言,最优传输在ds和dt之间搜索一个具有最小传输成本的概率耦合γ∈Π(ds,dt),如式(1)所示
(1)
式中,c是成本函数,可以用来衡量源域样本xs和目标域样本xt之间的差异。Tds,dt可以进一步定义ds和dt之间的p阶Wasserstein距离,具体为
(2)
式中,d(xs,xt)p是一种距离度量,对应式(1)中的成本函数c(xs,xt)。Wasserstein距离在计算机视觉领域也被称为EMD[37]。
在本文的域自适应问题中,源域和目标域的分布ds和dt只能通过离散样本获取,故离散化后的最优传输公式为
(3)

1.2 图像空间最优传输
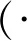
T(xs)=(xs-μs)·A+μt
(4)
式中,A为传输矩阵;xs和xt分别表示源域和目标域样本。值得注意的是,可行传输矩阵A的结果不唯一,但最优可行解,即最优传输矩阵不存在多个解[38]。通过最优传输可以找到一个最优的映射T来最小化源域和目标域分布之间的距离,即
(5)
式中,c的含义和式(1)中的含义一致,即成本函数,本文采用欧氏距离形式。式(5)对应的最优传输矩阵为
(6)
图像空间最优传输的具体步骤如下:
(1) 统计源域和目标域图像色彩空间分布直方图,获取源域和目标域色彩分布参数μs、Σs、μt、Σt;
(2) 根据式(6),计算最优传输矩阵A;
(3) 利用式(4)对源域图像xs进行转换,得到具备目标域色彩风格的源域图像T(xs),如图2图像空间部分所示。
1.3 特征空间与输出空间最优传输
文献[33]提出DeepJDOT方法,最早将JDOT[32]引入深度学习域自适应任务。但是,该方法仅在特征空间进行最优传输,且仅可以应用于图像分类任务。在语义分割任务中,所需传输的样本数量远大于图像分类任务,直接将DeepJDOT应用于语义分割任务是不现实的。若降低输入图像尺寸,则会增加特征空间匹配难度,导致源域和目标域特征错误匹配、传输,降低整体域自适应效果。
针对上述问题,本文提出了以下解决方案:①在不降低输入图像尺寸的情况下,在特征空间进行下采样,进一步压缩需要匹配的样本数量,在保证特征能够成功匹配的情况下降低最优传输计算量;②在输出空间进行最优传输,通过输出空间类别边缘分布保证源域和目标域对齐。
特征空间和输出空间的优化过程为
(7)

1.3.1 特征空间最优传输
在特征空间,本文采用L2距离衡量源域和目标域特征之间的差异,即
(8)
进而,特征空间的损失函数为
(9)
1.3.2 输出空间最优传输
输出空间包含重要的类别分布信息,通过输出空间对齐,可以减弱源域和目标域的类别分布差异。具体而言,本文采用L2距离衡量源域和目标域输出空间距离,即
(10)
进而,输出空间的损失函数为
(11)
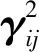
1.4 模型优化
为了保证所提出方法的基础性能,本文添加源域监督学习过程,即根据源域图像的预测结果和其对应的标签信息,计算交叉熵损失,具体为
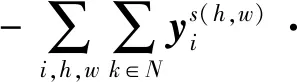
(12)

结合特征空间与输出空间的损失函数,整体模型优化损失为
Loss=Lossseg+β1Lossfeature+β2Lossoutput
(13)
式中,β1、β2为特征空间和输出空间最优传输损失的控制参数。默认设置为β1=0.01,β2=0.01。
需要说明的是,图像空间风格迁移,特征空间、输出空间最优传输,源域监督学习的损失函数计算可以在同一次训练中进行;即本文方法不需要单独训练源域模型,域自适应过程与源域监督学习可以同步进行,有效减少了人工干涉,缩短了训练时间,进一步提高了模型自动化能力。
2 试 验
2.1 试验数据与精度评价指标
本文使用国际摄影测量与遥感学会(ISPRS)所提供的两个高分航空遥感数据集,即Potsdam数据集和Vaihingen数据集。其中Potsdam数据集由38张6000×6000像素图像组成,分辨率为0.05 m,包括IRRG和RGB两种波段组合;涵盖6个常见地物类别,即不透水层、车辆、树木、低矮植被、建筑物和背景。Vaihingen数据集由33张大小不一的图像构成,图像平均大小为2000×2000像素,分辨率为0.09 m,具备与Potsdam数据集相同的地物类别体系,但仅有IRRG波段组合。如图3所示,Potsdam数据集和Vaihingen数据集在图像色彩、地物外观及尺度上均存在较大差异,这为跨域语义分割任务带来了挑战。为定量评估方法性能,本文使用当前主流的交并比(intersection over union,IoU)指数来评估各类别分割精度。同时,本文引入所有类别的IoU精度平均值(mean intersection over union,mIoU),以衡量模型的整体性能。

图3 ISPRS Potsdam数据集和Vaihingen数据集Fig.3 ISPRS Potsdam datasets and Vaihingen datasets
2.2 试验设置
为了充分验证所提出方法有效性,本文对Potsdam数据集IRRG→Vaihingen数据集IRRG、Vaihingen数据集IRRG→Potsdam数据集IRRG、Potsdam数据集RGB→Vaihingen数据集IRRG、Vaihingen数据集IRRG→Potsdam数据集RGB这4组跨域场景进行试验。试验使用Pytorch框架和单个NVIDIA GTX 2080Ti显卡进行训练,并使用动量为0.9、权重衰减为5×10-4的SGD算法优化网络。试验初始学习率lr设置为5×10-4,并以0.9的幂进行多项式衰减
(14)
式中,iter为迭代次数;max_iter是最大迭代次数;max_iter设置为50 000。训练时,模型随机裁切源域图像为1000×1000像素的图像块进行训练,并随机进行图像竖直翻转和水平翻转等增强处理;测试时使用1000×1000像素的滑动窗口进行整幅图像预测。
关于超参数β1和β2的设置,本文通过Potsdam数据集IRRG→Vaihingen数据集IRRG的试验进行了验证。β1和β2代表特征空间和输出空间最优传输在整个训练过程中的影响权重,数值越大,模型在训练过程中对域迁移关注度越高。β1和β2数值为0.010 0时,本文方法取得最高精度(表1和表2)。在逐步增大β1和β2过程中,模型精度略有下降,这是由于模型过度关注源域和目标域分布对齐,而忽略源域语义分割监督训练的结果;在逐步减小β1和β2的过程中,模型精度也缓慢下降,这说明特征空间和输出空间域迁移对精度提升的积极作用。因此,本文将β1和β2的默认值设置为0.010 0。

表1 超参数β1的选择

表2 超参数β2的选择
为说明本文方法的优势,本文与5种代表性域自适应方法进行了对比。这些方法包括CycleGAN[20]、AdaptSegNet[24]、SIM(stuff instance matching)[25]、CaGAN(class-aware generative adversarial network)[26]和UDA方法[27]。这些方法的语义分割模型均为基于ResNet101的DeepLab-V2。此外,本文加入了“仅源域”(即仅在源域进行监督训练,直接用于目标域预测),并将仅源域训练精度作为几组试验的基线精度。
2.3 试验结果与分析
2.3.1 精度对比与分析
试验精度结果见表3—表6,其中仅源域训练精度最低,这说明不同域之间存在分布偏差,单纯源域训练所得到的模型难以在目标域上取得较高精度。此外,如表3和表4、表5和表6的精度差异所示,即便训练任务中源域和目标域存在相同的域偏移,但由于迁移顺序的差异,仍会带来不同的精度结果,且图像数量较多的源域具备更加多样化的特征分布,可以在迁移至目标域时取得更高精度。CycleGAN方法在Vaihingen数据集→Potsdam数据集迁移任务中,即表4和表6中,较好地减弱了低矮植被与树木两个类别的域偏移问题,但在其他地物类别上精度较低,如表4的不透水层和表6的车辆,相对于仅源域训练的精度有所下降,且CycleGAN方法的mIoU指数提升并不明显,这表明单一的图像空间风格迁移并不能较好地解决域偏移问题。AdaptSegNet方法在多组试验中的表现相对较好,但由于缺乏图像空间色彩分布和特征空间高维特征分布对齐,其在复杂的跨域任务Vaihingen数据集IRRG→Potsdam数据集RGB中表现较差,建筑物类别精度相对于仅源域训练精度有所下降;引入实例和类别信息的SIM、CaGAN和UDA(Chen)方法,进一步缓解了域偏移问题,保证了各类别精度的稳步提升。相比于其他方法,本文方法通过结合多个空间最优传输优势,在仅源域训练的精度基础上,取得了显著的精度提升(表3—表6),mIoU指数分别提高了17.39%、22.02%、16.91%、17.84%,且高于其他方法,这表明多空间最优传输相结合可以有效提高模型总体的域自适应能力。

表3 Potsdam数据集IRRG→Vaihingen数据集IRRG精度结果

表4 Vaihingen数据集IRRG→Potsdam数据集IRRG精度结果

表5 Potsdam数据集RGB→Vaihingen数据集IRRG精度结果
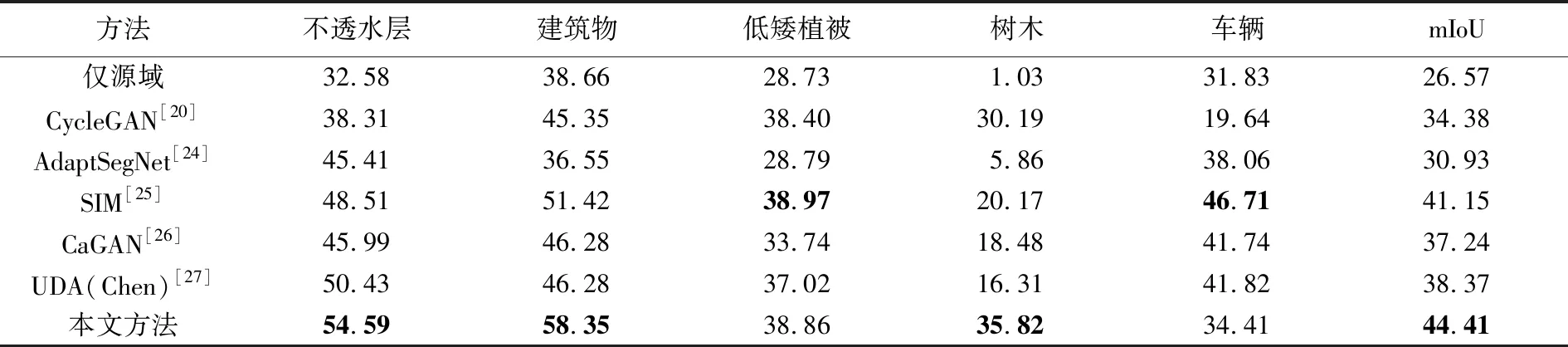
表6 Vaihingen数据集IRRG→Potsdam数据集RGB精度结果
2.3.2 可视化结果与分析
可视化结果如图4—图7所示。在所有测试方法中,仅源域训练的结果最差,在目标域图像场景复杂度较高时(如图6(c)和图7(c)所示),地物的边界完全模糊,预测类别混乱,仅在少量结果中可以看到建筑物的大致轮廓。CycleGAN能够较好解决因色彩差异而导致的域偏移问题,但由于缺少高维特征分布对齐,地物边界存在模糊不清现象,背景类与其他类别混淆严重。AdaptSegNet方法相比于CycleGAN方法具备一定优势,但在源域和目标域图像波段组合不同时,如图6(e)、图7(e)所示,建筑物、低矮植被与背景的分类结果混淆,部分区域存在明显误判现象。CaGAN在输出空间对抗训练的基础上添加了类别信息,进一步缓解了模型在部分类别中的错分问题,但地物边界仍然模糊,且由于高维类别特征分布差异较大,简单的类别特征分布对齐反而带来了负迁移问题,即未能找到源域和目标域分布的合理对齐方式。如图4(a)和图6(d)结果所示,CaGAN将建筑物错分为背景,可视化结果不及AdaptSegNet;SIM和UDA(Chen)方法也存在诸多误判现象,但它们分别采用实例对齐和判别器逐类判别过程,部分解决了遥感图像复杂的类内差异所引起的迁移困难问题。
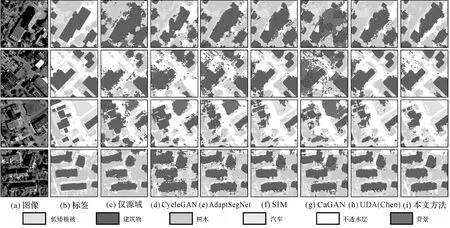
图4 Potsdam数据集IRRG→Vaihingen数据集IRRG可视化结果Fig.4 The visual results of Potsdam IRRG→Vaihingen IRRG

图5 Vaihingen数据集IRRG→Potsdam数据集IRRG可视化结果Fig.5 The visual results of Vaihingen IRRG→Potsdam IRRG

图6 Potsdam数据集RGB→Vaihingen数据集IRRG可视化结果Fig.6 The visual results of Potsdam RGB→Vaihingen IRRG

图7 Vaihingen数据集IRRG→Potsdam数据集RGB可视化结果Fig.7 The visual results of Vaihingen IRRG→Potsdam RGB
本文提出多空间结合的最优传输域自适应方法,能够有效结合多空间最优传输优势,在保持地物边界的同时有效区分纹理和色调相近的地物,提高了模型在目标域上的分割效果。如图4(c)所示,本文方法较好地分类了低矮植被,未出现其他方法中常见的低矮植被与背景的混淆问题,这缘于最优传输可以在分布间差异较大情况下,提供具备完备几何意义的距离度量,这对遥感图像复杂场景的分割任务是至关重要的。此外,如图6、图7所示,即便在复杂迁移任务中,本文方法也能够清晰界定地物轮廓,内部噪声较少,相对准确地识别复杂形态地物(如树木)。
2.3.3 模型复杂度分析
为了定量评估模型效率,本文采用参数量和计算量(floating-point operations per second,FLOPs)两个指标,在输入图像尺寸(512×512像素)相同情况下,测试模型运算的复杂度,具体结果见表7。其中,CycleGAN的参数量和FLOPs值显著高于其他方法;本文方法的参数量和FLOPs值最小。这表明,相对于采用GAN的域自适应方法,包括CycleGAN,AdaptSegNet,SIM,CaGAN和UDA(Chen)方法,本文方法的模型复杂度更小,训练更加便捷。
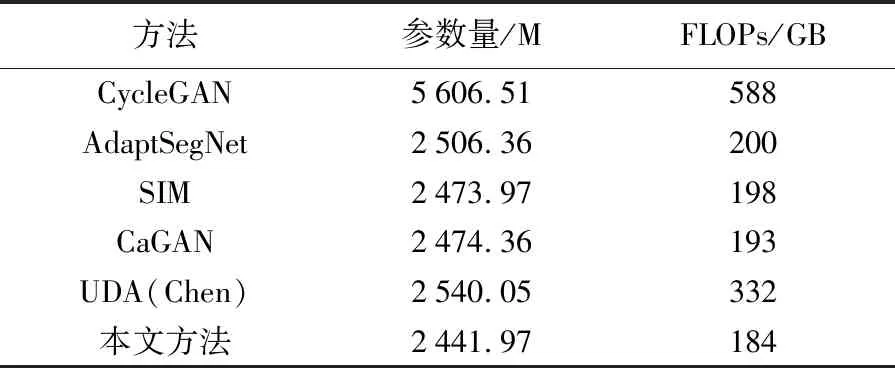
表7 测试模型的参数量和FLOPs
2.4 消融试验与分析
为验证本文方法各模块的有效性,本文在Potsdam数据集IRRG→Vaihingen数据集IRRG迁移任务上进行了消融试验,表8和图8显示了每个模块及其不同组合的作用和可视化效果。在单空间对齐测试中,输出空间最优传输的测试精度最高(mIoU指数达到46.88%),这缘于输出空间同时包含几何和类别信息。同时,即便特征空间维度较高,最优传输理论仍然可以充分考虑特征中隐含的几何结构,因此,特征空间最优传输也能取得精度提升(mIoU指数达到42.11%)。此外,在图像空间最优传输和输出空间最优传输的可视化结果中,地物类别更加准确,而在特征空间最优传输的可视化结果中,地物边界的界定则更加清晰(如上方建筑物)。
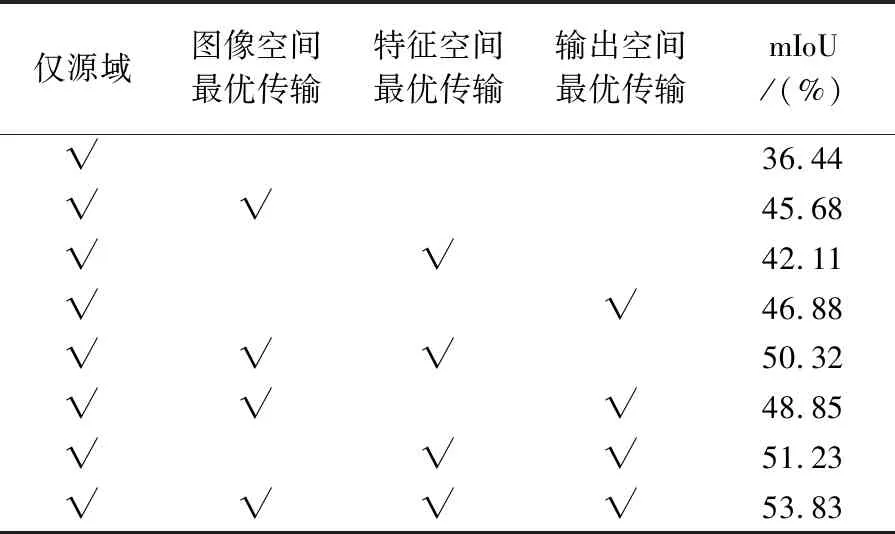
表8 消融试验精度分析

图8 消融试验可视化结果Fig.8 The visual results of ablation study
在多空间组合对齐测试中,精度普遍高于单空间对齐,这说明多空间最优传输可以有效提高跨域语义分割精度。将图像空间与特征空间或输出空间最优传输进行结合(即图像空间+特征空间最优传输,图像空间+输出空间最优传输),可获取相对完整的预测结果,地物边界相对清晰,类别错分现象有所减少,有效消除单输出空间或特征空间最优传输结果中出现的过分割现象。将图像空间、特征空间和输出空间最优传输相结合(即本文方法),能够获取清晰准确的地物边界,地物内部缺失问题得到改善;并且,图中右侧部分车辆和树木细节的分割结果也较好。这与表8的定量化精度结果相呼应,图像空间、特征空间和输出空间最优传输相结合所取得的精度最高(mIoU指数达到53.83%)。这说明基于最优传输构建的单空间对齐模块可以简单而有效的结合在一起,充分发挥各个模块的优势,提高整体域自适应性能。
3 总 结
本文提出了一种基于最优传输理论的无监督域自适应方法,用于解决遥感图像跨域语义分割时普遍存在的域偏移问题。首先,本文利用最优传输理论构建了一种更为简单的色彩映射方法,在图像空间进行风格迁移,减弱图像空间域偏移影响;然后,将最优传输引入语义分割无监督域自适应框架,分别在特征空间和输出空间使用最优传输理论计算损失,减轻数据分布差异,提升了模型的跨域语义分割性能。试验引入Potsdam数据集和Vaihingen数据集,利用IoU指数,对本文方法进行测试。结果表明,相对于其他单一空间域自适应方法,本文方法能够有效结合高维特征空间、输出空间与图像空间域自适应方法优势;在不同域迁移任务中,本文方法皆表现出较为明显的优势,得到了更高的跨域语义分割精度。
本文方法尚未充分研究并细化源域和目标域潜在的类间关系,在后续研究中,将对该问题进行深入研究,寻求突破。
