基于YOLOv5的换向器表面缺陷检测算法研究
2024-01-06张晓丽马怡琛仓玉萍董少飞何思思
张晓丽,马怡琛,仓玉萍,董少飞,郝 纳,何思思
(1.西安文理学院 机械与材料工程学院 陕西省表面工程与再制造重点实验室,陕西 西安 710065;2.西安文理学院 机械与材料工程学院 西安市智能增材制造重点实验室,陕西 西安 710065;3.信阳师范大学 物理电子工程学院,河南 信阳 464000)
0 前言
在机械零部件使用过程中,不可避免会产生诸如微小裂纹、凸起等缺陷,这些微小缺陷随着产品的反复使用可能会持续增加,从而严重影响产品的功能和寿命,甚至导致整个系统发生故障。研究显示,80%的机械零部件都是由于缺陷导致疲劳损坏造成的[1]。由于传统的人工检测方式受视觉疲劳、注意力分散等因素的影响,很难达到现代工业生产中高效性和实时性的要求,所以建立机械零部件表面缺陷智能检测系统对零部件质量控制具有极其重要的意义[2-3]。
针对不同工件缺陷检测方法,国内外学者进行了广泛研究。主要集中于基于传统图像处理方法的和基于机器学习的工件表面缺陷方法两种。韩素华等人针对国标51105型号轴承套圈进行了表面缺陷检测实验,提出了基于机器视觉的表面缺陷检测实验系统设计,精度达95%[4]。YoungJin Cha等人基于Faster-R-CNN提出一种多类型损伤的自动检测方法,结合无人机实现混凝土、钢材腐蚀等自主视觉检测,五类缺陷平均检测精度(mean Average Percision,mAP)达到87.8%[5]。Yiting Li等人研究采用改进SSD(Single Shot MultiBox Detection )算法对灌装线集装箱表面缺陷进行检测,采用MobileNetv1替换SSD算法中的VGG16特征提取网络,简化了检测模型,识别率约为95%[6]。综上,采用深度学习中的卷积神经网络可以自动提取工件表面缺陷的有效图像信息,分类精度较高且速度较快。
电机被广泛应用在不同工业现场和行业中,而换向器是直流电动机、直流发电机和交流整流子电动机电枢上的一个重要部位,它在电动机转动的过程中扮演了关键的角色,确保电动机能够持续稳定地运转,其可靠性对整个生产过程具有重要意义[7]。换向器在工作中存在磨损,当换向器磨损严重或者换向器表面发生缺陷如裂纹时,电机在运转时会产生火花,进一步加剧电刷和换向器的损伤,降低电机效率,缩短电机的使用寿命。目前国内对于换向器表面质量是否存在缺陷检测的研究较少。基于以上分析,本文以换向器为研究对象,提出一种基于深度学习的换向器表面缺陷检测系统。该系统首先构建换向器表面缺陷数据集,并对数据集进行类别、位置的标定,其次采用YOLOv5算法进行模型的训练,并且对于已训练好的模型进行检测,最后根据摄像头摄取到的图像,采用训练好的YOLOv5网络模型对换向器表面缺陷进行检测和识别。
1 理论分析
1.1 YOLOv5目标检测算法
YOLOv5是YOLO系列中性能和通用性较强的一款模型,在检测速度和精度上有着较强的优势,能够在保持较高检测精度的同时满足实时性要求,是继YOLOv3之后被广泛应用于工业检测的算法。相对于其他版本的YOLO算法,YOLOv5可以在不降低检测精度的情况下,采用Focus框架将图像切片,加快了训练速度。同时,YOLOv5采用Pytorch框架,使得YOLOv5的大小对比YOLOv3、YOLOv4等版本降低了90%左右,从而使得YOLOv5的部署具有更多的灵活性,同时YOLOv5给出的四个不同大小的模型可以实现在不同精度要求下的检测[8]。因此,YOLOv5训练速度快,模型精度高,内存占用小,可以方便地运用在更多复杂场景。YOLOv5的网络结构主要可以划分为主干(backbone)、颈部(neck)、头部(head)这3个组成部分。其网络结构如图1所示。

图1 YOLOv5网络结构图
YOLOv5的主干网络(Backbone)包括Focus、CBS、C3和SPP模块,目标检测模型中主干网络的作用是实现对输入图像的特征提取。Focus模块在输入图像进入主干网络之前,对图像进行切片(Slice),然后把切片后的结果拼接(Concat)起来。网络结构中的基本单元卷积(Conv)、批量化归一化(BN)和激活函数SiLU组成CBS模块,其结构如图2所示。

图2 CBS模块结构
YOLOv5的损失函数包括三个部分,分别为分类损失、预测框置信度损失和预测框定位损失。其中分类损失和预测框置信度损失均为二分类交叉墒损失,YOLOv5网络中采用GIOU_Loss作为边界框回归损失计算式[9]:
(1)
(2)
式中:C为两个框中的最小外接矩形;B∪Bgt为预测框与真实框的并集。
1.2 YOLO模型性能指标
模型性能主要包括两个方面:一个是检测精度,另一个是检测速度。性能评估指标有准确率、精确率、召回率、平均精确度等。对于一个二分类算法来说,预测的结果只有两类,分别用“正”和“负”来表示。采用YOLO模型对一组样本进行二分类预测时,根据预测样本类别和实际样本类别,会出现4类情况:
(1)预测结果为正,实际样本也为正。这种情况定义为真正例TP(True Positive)。
(2)预测结果为正,实际样本却为负。这种情况定义为假正例FP(False Positive)。
(3)预测结果为负,实际样本也为负。这种情况定义为真反例TN(True Negative)。
(4)预测结果为负,实际样本却为正,这种情况定义为假反例FN(False Negative)。
这四种情况构成一个混淆矩阵,如表1所示。表格内容为每种类别对应的样本数量,借助混淆矩阵表,可以计算YOLO模型的各种性能指标。

表1 混淆矩阵表
精确率(P)指真正例样本数占预测结果为正(包括真正例和假正例)样本数的比例,计算方法如公式(3)所示[10]:

(3)
召回率(R)指真正例样本数占实际正样本(包括真正例和假反例)总数的比例,计算方法如公式(4)所示[11]:
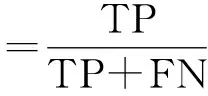
(4)
准确率(Acc)指预测结果正确(包括真正例和真反例)的样本数占总样本数的比例,计算方法如公式(5)所示[12]:
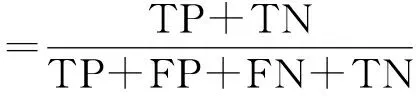
(5)
一般情况下召回率和准确率越接近1代表模型越好,但是这两个指标却存在负相关,因此需要在这两者之间进行取舍,或通过平均精确度(AP)即P-R曲线与坐标轴的面积协助分析,当有n个类别需要识别时,将所有AP值求平均值可得mAP。计算公式如式(6)和式(7)所示[13]:
(6)
(7)
1.3 Mosaic数据增强
YOLOv5在输入端采用了Mosaic数据增强,具体实现如图3所示。Mosaic数据增强是先随机选择4张图像进行翻转、缩放等操作,再将处理后的4张图片拼贴操作形成新的一张图片,之后裁剪训练图像中超出背景的部分,得到模型的训练数据。这样做不仅增加了检测数据集的内容,而且通过随机缩放增加了许多小目标,使得网络的鲁棒性更好,提高了单GPU训练时的表现。

图3 Mosaic数据增强流程图
2 换向器表面缺陷模型构建
2.1 换向器表面缺陷检测系统构建
工业用换向器表面缺陷检测系统如图4所示。系统工作过程如下:

图4 换向器表面缺陷检测系统框图
(1)采用Mosaic数据增强等方法,对数据集进行预处理,将构建的数据集分为训练集和测试集;
(2)采用训练集对YOLOv5模型进行训练,得到效果最佳的网络权重数据和训练模型;
(3)采用训练好的YOLOv5模型对图片进行目标检测,识别出图像中是否有缺陷,如果有,进一步判断换向器表面缺陷的位置。
2.2 数据集创建
本研究采用的数据集是公开的KolektorSDD数据集,这个数据集专门用于换向器表面的缺陷识别。数据集由50组有缺陷的换向器组成,每组包含有8张金属表面图,并有对应的标签。图5为KolektorSDD数据集中部分图像。

图5 公开的KolektorSDD数据集
2.3 数据集预处理
为增加换向器表面缺陷检测精度,采用旋转、裁剪、加噪等操作对换向器原始数据集进行扩展。
旋转是对换向器表面图像的位置进行变换,虽然人眼看到变换后的图像和变换前区别不是很大,由于计算机识别图片是以像素的方式进行,而旋转变换后图像的像素变化较大,变换后图像发生了显著的变化,因此,所提出的方法可以有效地对数据集进行扩充,其旋转效果如图6所示。

图6 旋转对比图
裁剪主要是对换向器表面图像的不同区域进行随机裁剪。在实际工况中,由于受到外界环境影响,被识别的换向器可能会受到遮挡或损坏,而通过裁剪可以模拟这样的场景。这种方法可以扩充换向器图片数量以提高训练网络的泛化能力,使得对换向器表面缺陷的识别精度更高,其裁剪效果如图7所示。

图7 裁剪对比图
2.4 数据标定
采用LabelImg标注工具对数据进行标注。标注过程是在标注换向器缺陷的类别信息和位置信息,完成之后会生成对应的文件来存储换向器图片的边界框信息,标注过程如图8所示。标注后将数据集分为训练集和测试集,所采用的比例是8∶2,之后还需从训练集中抽取部分图像作为验证集来测试训练之后的模型,随机抽取的比例为0.2,抽取的图像依然属于训练集。

图8 LabelImg数据标定
2.5 YOLOv5网络模型训练
YOLOv5网络模型训练流程如图9所示,首先输入训练样本,网络参数初始化,对标定好的数据集进行监督学习,并提取特征,之后训练网络反向修正权值、阈值,再判断是否满足设定的结束条件(即设置的迭代次数),如果是,将生成分类模型,结束此次训练。

图9 训练流程图
训练完成后,即可对换向器表面缺陷进行检测。检测流程如图10所示。通过相机采集图像信息,对图像的阈值进行分割和缺陷识别,判断是否有缺陷,如果有,将获取缺陷区域并调用训练好的分类模型,输出检测的结果。

图10 检测流程图
2.6 实验环境的搭建
为了实现换向器表面缺陷和位置的检测,对KolektorSDD数据集进行扩充后采用YOLOv5算法对训练模型进行构建,并进行推理。本实验的运行环境为:Windows 10(64位)操作系统;Genuine Intel(R)CPU @ 2.20 GHz(双核),内存为64 GB;NVIDIA GeForce GTX 1080 Ti GPU,显存8 GB;Tensorflow-gpu版本2.8.0,CUDA版本为11.5,CUDNN版本为8.2.1,Anaconda版本为4.12.0。采用的软件程序是Python语言,开发环境是PyCharm,采用的学习框架是PyTorch。
3 实验结果与分析
PR曲线(Precision-Recall Curve)是一种用于评估二分类器性能的曲线图,在目标检测中被广泛使用。PR曲线更加关注正确率和完整性,PR曲线的横坐标是召回率,纵坐标是准确率。PR曲线的形状与其所对应的每个阈值选择有关。通常会选择某段准确率超过最小要求的那部分数据,在这部分数据中找到召回率最高的阈值作为模型的输出结果。本文换向器表面缺陷检测模型构建中,所得到的PR曲线如图11所示。从图中可以看出,有缺陷检测下的PR的包络面积为0.994,有缺陷加无缺陷检测下的PR的平均包络面积也为0.994,两种分类检测得到的PR曲线比较接近,包络面积均接近于1,即检测的平均精度较高,检测的性能较好。

图11 换向器表面缺陷检测PR曲线
Box用来衡量所构建模型中边界框预测的误差程度,其值越小表示模型边界框预测的更准确;Obj表示目标检测过程中损失的均值;Classification作为分类损失的均值。以上各个损失值越小,表明检测的精确度越高。模型构建中训练集和验证集中其损伤值和迭代次数关系如图12所示。从图中可以看出,当迭代次数为200时,训练集和测试集的分类损失值接近于0,训练集和测试集的边界框损失、目标损失值均低于0.02,表明模型训练在小数据集上性能表现良好。

图12 训练集和测试集损失值同迭代次数曲线
训练集和验证集中精确度和召回率同迭代次数关系如图13所示。从图中可以看出,当迭代次数为200时,精确度数值高于0.99,召回率数值高于0.95,平均精度均值接近于1。同时,损失值较小,因此,所构建网络模型训练效果较好,精度较高。

图13 精确度和召回率同迭代次数曲线
在YOLOv5推理的过程中,首先需要将待检测的图像送入网络模型,经过卷积层和池化层等处理,得到一些特征点和特征向量,然后通过全连接层将这些特征与类别标签相结合,最终可以得到目标检测结果。实验的推理结果如图14所示,不仅可以检测出换向器表面是否存在缺陷,并能检测出换向器表面缺陷的位置,对换向器表面缺陷检测的准确率达到90%。

图14 推理结果
4 结论
本文为减轻在工业用零部件表面缺陷检测中人工检测的成本和负担,提高检测的效率,以工业用典型零件换向器为研究对象,设计了一款工业用零部件缺陷检测系统。以公开的Kolektor-SDD数据集为基础,对数据集进行预处理,构建换向器表面缺陷训练集和测试集。依据构建的训练集和测试集,采用深度学习框架对YOLOv5网络模型进行训练,并对训练的换向器表面缺陷检测模型进行推理测试。实验结果表明换向器表面缺陷检测系统在检测精度和检测速度方面表现良好,换向器表面缺陷的检测准确率达到90%,不仅能有效检测出换向器表面是否有缺陷,还能检测出表面缺陷的位置。本研究可以为工业中换向器零部件的制造和应用进行实时在线监测,及时发现换向器表面缺陷,提高产品的可靠性和安全性。在后续研究中,可以对所采用的方法继续优化,以提高换向器表面缺陷检测算法的精度和效率。
